Range Joins und andere Non-Equi-Joins gelten in den meisten Datenbanken als notorisch langsam. Snowflake ist zwar bei den meisten Abfragen pfeilschnell, schwächelt aber ebenfalls bei genau diesen Join-Typen. In diesem Beitrag zeigen wir eine Optimierungstechnik, mit der sich Abfragen mit Range Joins um bis zu das 300-Fache beschleunigen lassen 1.
Bevor wir in die Technik einsteigen, ordnen wir kurz die verschiedenen Join-Typen ein und erklären, warum Range Joins in Snowflake so langsam sind. Wenn Sie damit schon vertraut sind, können Sie gerne direkt weiterspringen.
Equi-Joins versus Non-Equi-Joins
Ein Equi-Join ist ein Join mit einer Gleichheitsbedingung. Die meisten Nutzer schreiben Abfragen mit einer oder mehreren solcher Equi-Join-Bedingungen.
select
...
from orders
join customers
on orders.customer_id=customers.id -- example equi-join condition
Ein Non-Equi-Join ist ein Join mit einer Ungleichheitsbedingung. Ein Beispiel wäre die Suche nach allen Kunden, die dasselbe Produkt gekauft haben:
select distinct
o1.customer_id,
o2.customer_id,
o1.product_id
from orders_items as o1
join orders_items as o2
on o1.product_id=o2.product_id -- equi-join condition
and o1.customer_id<>o2.customer_id -- non-equi join condition
Oder alle Bestellungen je Kunde nach einem bestimmten Datum:
select
...
from orders
inner join customers
on orders.customer_id=customers.id
and orders.created_at > customers.one_year_anniversary_date
Was sind Range Joins?
Ein Range Join ist eine besondere Form des Non-Equi-Joins. Man spricht davon, wenn ein Join prüft, ob ein Wert in einen bestimmten Wertebereich fällt ("Point in Interval Join"), oder wenn er nach zwei sich überlappenden Zeiträumen sucht ("Interval Overlap Join").
Point in Interval Range Join
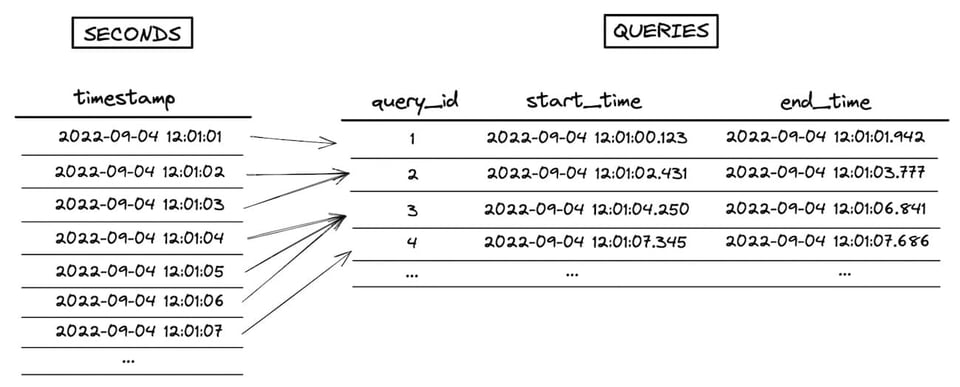
Ein typisches Beispiel ist die Berechnung der Anzahl der pro Sekunde laufenden Abfragen:
select
seconds.timestamp,
count(queries.query_id) as num_queries
from seconds
left join queries
on seconds.timestamp between
date_trunc('second', queries.start_time) and date_trunc('second', queries.end_time)
group by 1
Solche Joins lassen sich auch auf abgeleitete Zeitstempel anwenden. Ermitteln Sie etwa alle Kaufereignisse, die innerhalb von 24 Stunden nach einem Besuch der Startseite stattgefunden haben:
select
...
from page_views
inner join events
on events.event_type='purchase' -- filter condition
and page_views.pathname = '/' -- filter condition
and page_views.user_id=events.user_id -- equi-join condition
and page_views.viewed_at < events.event_at -- range join condition
and dateadd('hour', 24, page_views.viewed_at) >= events.event_at -- range join condition
Interval Overlap Range Join
Bei Interval Overlap Range Joins sucht eine Abfrage nach sich überlappenden Zeiträumen. Stellen Sie sich vor, Sie wollen für jede Browsing-Session auf Ihrer Landing Page alle Sessions ermitteln, die gleichzeitig in Ihrer Anwendung liefen:
select
s1.session_id,
array_agg(s2.session_id) as concurrent_sessions
from landing_page_sessions as s1
inner join app_sessions as s2
on s1.end_time > s2.start_time
and s1.start_time < s2.end_time
group by 1
Warum sind Range Joins in Snowflake langsam?
Range Joins sind in Snowflake langsam, weil sie als kartesische Joins mit nachgelagerter Filterbedingung ausgeführt werden. Ein kartesischer Join – auch Cross Join genannt – liefert das kartesische Produkt der Datensätze beider beteiligten Datasets. Haben beide Tabellen je 10.000 Datensätze, kommen am Ende 100 Millionen Datensätze heraus. In der Praxis spricht man hier von einer Join-Explosion 💥. Muss Snowflake derart große Zwischenergebnisse verarbeiten, leidet die Abfrage-Performance erheblich.
Schauen wir uns das anhand des Beispiels "Anzahl der pro Sekunde laufenden Abfragen" von oben genauer an.
select
s1.session_id,
array_agg(s2.session_id) as concurrent_sessions
from landing_page_sessions as s1
inner join app_sessions as s2
on s1.end_time > s2.start_time
and s1.start_time < s2.end_time
group by 1
Die Tabelle seconds enthält eine Zeile pro Sekunde, die Tabelle queries eine Zeile pro Abfrage. Ziel der Abfrage ist es, pro Sekunde zu ermitteln, welche Abfragen liefen, und diese dann zu aggregieren und zu zählen.
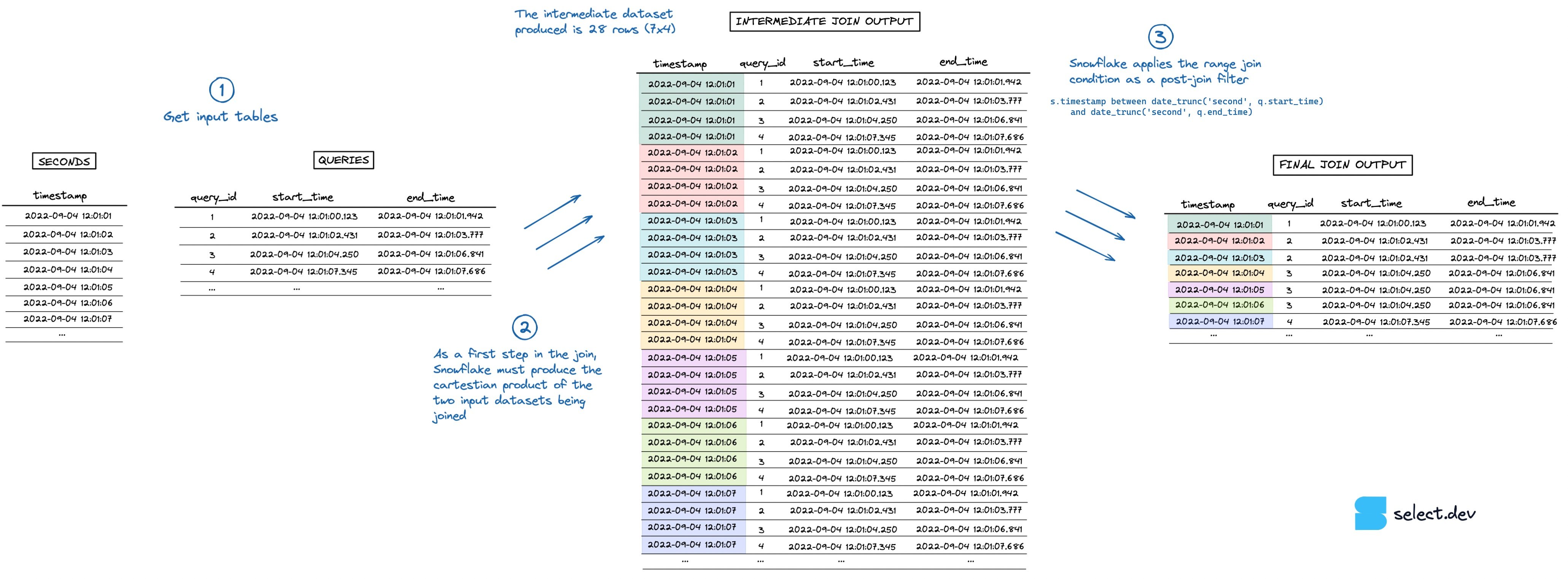
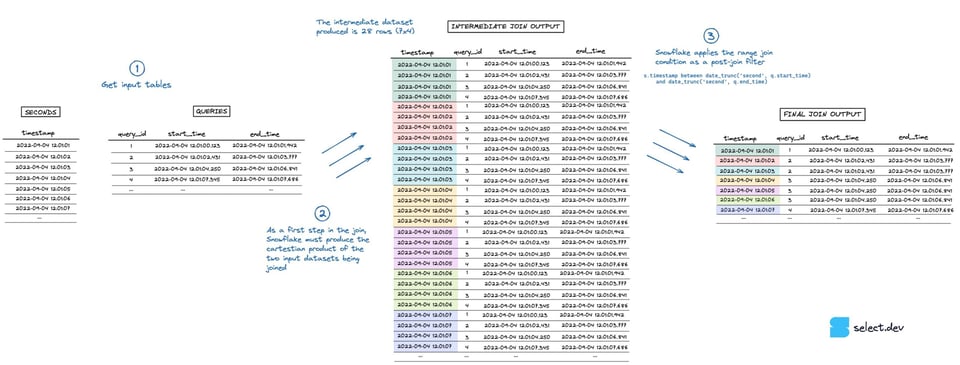
Beim Ausführen des Joins legt Snowflake zunächst ein Zwischen-Dataset an, das dem kartesischen Produkt der beiden Eingangs-Datasets entspricht. In diesem Beispiel hat die seconds-Tabelle 7 Zeilen, die queries-Tabelle 4 – das Zwischen-Dataset wächst dadurch auf 28 Zeilen an. Die Range-Join-Bedingung mit der "Point in Interval"-Prüfung greift erst danach, als nachgelagerter Filter auf diesem Zwischenergebnis. Eine Visualisierung des Ablaufs sehen Sie in der Abbildung unten (eine höher aufgelöste Vollbildversion finden Sie hier).
{kind=link}
Auf einem 30-Tage-Datenausschnitt mit 267.000 Abfragen dauerte die Ausführung dieser Abfrage 12 Minuten und 30 Sekunden. Wie das Query Profile zeigt, ist der Join der klare Engpass. Die Range-Join-Bedingung erscheint dabei als "Additional Join Condition":

So optimieren Sie Range Joins in Snowflake
Die Ideen von oben lassen sich über sogenannte 'Bins' zu einem allgemeineren Ansatz weiterentwickeln 4.
Wenn wir Snowflake anweisen, die Range-Join-Bedingung nur auf kleinere Datenausschnitte anzuwenden, läuft die Join-Operation deutlich schneller. Für jeden Zeitstempel joint Snowflake jetzt nur noch die Abfragen, die in derselben Stunde liefen – statt aller Abfragen des gesamten Zeitraums.
Statt uns auf vordefinierte Bereiche wie "Stunde", "Minute" oder "Tag" festzulegen, können wir Bins in beliebiger Größe nutzen. Laufen die meisten Abfragen zum Beispiel in unter 2 Sekunden, können wir die Abfragen in Bins von je 2 Sekunden Länge gruppieren.
Der Algorithmus sieht in etwa so aus:
- Bins erzeugen und jedem Dataset Bin-Nummern hinzufügen.
- Die Equi-Join-Bedingung über
bin_numals Constraint im Range Join ergänzen – analog zum oben gezeigten Vorgehen mithour. - Das erzeugte Zwischen-Dataset ist nun deutlich kleiner.
- Snowflake wendet den Range Join wie gewohnt als nachgelagerten Filter an – diesmal aber erheblich schneller.
Eine Visualisierung des Ablaufs sehen Sie in der Abbildung unten (eine höher aufgelöste Vollbildversion finden Sie hier).
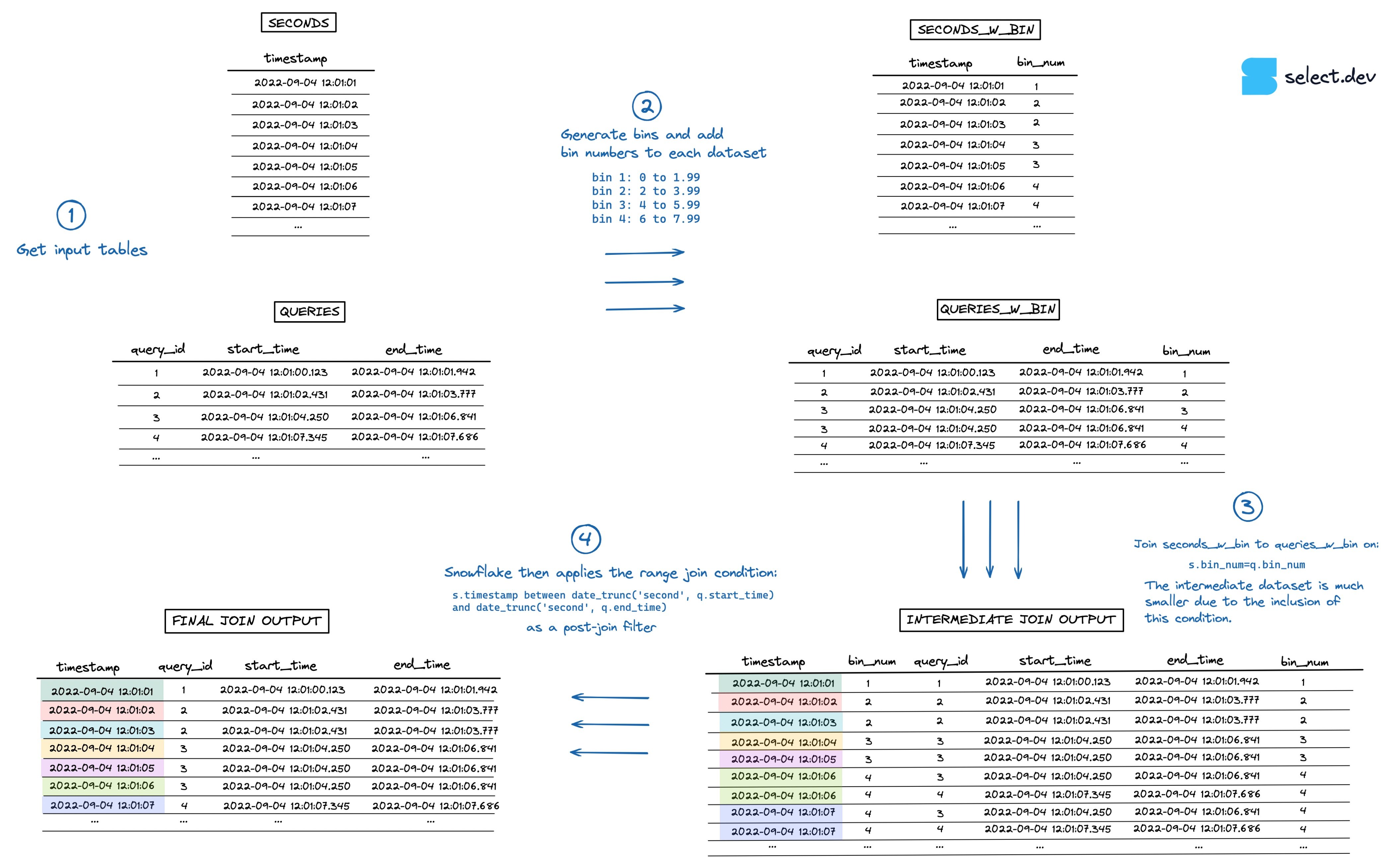{kind=link}
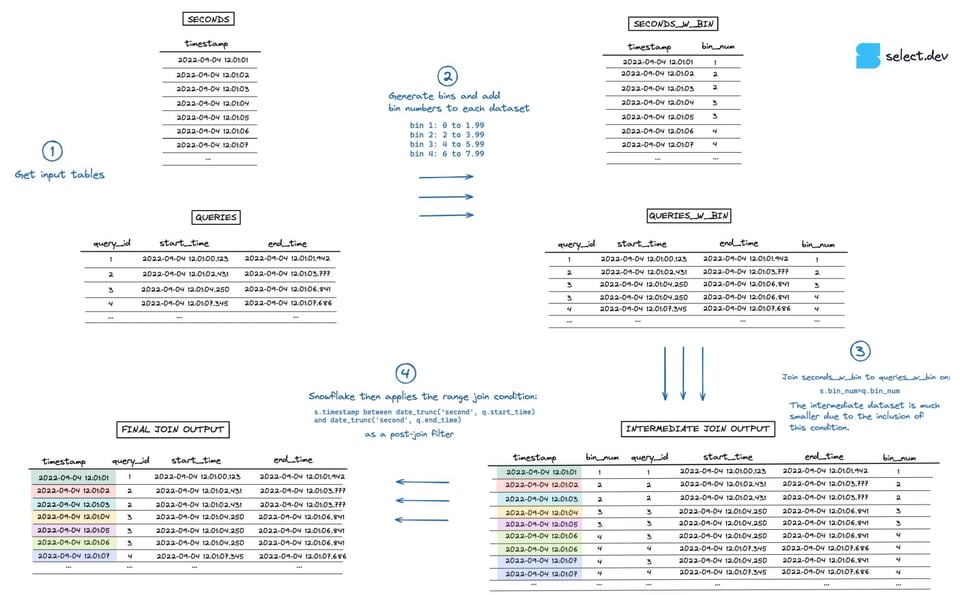
Beispiel für eine Binned-Range-Join-Abfrage
Bin-Nummern sind schlicht Ganzzahlen, die einen Wertebereich repräsentieren. Eine Möglichkeit, sie zu erzeugen: Man teilt den Wert durch die gewünschte Bin-Größe. Bei Zeitstempeln wandeln wir den Wert vorher in Unix-Zeit – eine Ganzzahl – um und dividieren erst dann:
-- for 60 second sized bins
select
timestamp,
floor(date_part(epoch_second, timestamp) / 60) as bin_num
Wir speichern das in einer Funktion get_bin_number
5, damit wir die Berechnung nicht ständig wiederholen müssen.
Folgen wir den oben beschriebenen Schritten, müssen wir als Erstes die Liste der relevanten Bins erzeugen. Dazu lassen wir per Generator eine Liste von Ganzzahlen entstehen und filtern sie anschließend auf die gewünschten Start- und End-Bin-Nummern 6.
set bin_size_s = 60;
with
metadata as (
select
-- this would be a query against your desired time range
min(timestamp) as start_time,
max(timestamp) as end_time,
get_bin_number(start_time, $bin_size_s) as bin_num_start,
get_bin_number(end_time, $bin_size_s) as bin_num_end
from seconds
),
-- need a CTE with 1 row between bin_num_start and bin_num_end
-- have to first generate a massive list, then filter down since you can't pass in calculated values
-- when bins_base is 1 trillion takes 5 seconds to filter down. 106 ms for for 1 million
Code ausklappen
Nun können wir jedem Dataset die Bin-Nummer hinzufügen. Beim queries-Dataset entsteht so ein Ergebnis mit 1 Zeile pro Abfrage und Bin, in dem die Abfrage lief. Im seconds-Dataset wird jeder timestamp auf genau einen Bin abgebildet.
queries_w_bin_number as (
select
start_time,
end_time,
warehouse_id,
cluster_number,
bins.bin_num
from queries
inner join bins
on bins.bin_num between
get_bin_number(queries.start_time, $bin_size_s) and get_bin_number(queries.end_time, $bin_size_s)
),
seconds_w_bin_number as (
select
timestamp,
Code ausklappen
Zum Schluss wenden wir die finale Join-Bedingung an – ergänzt um die Equi-Join-Bedingung auf bin_num:
select
s.timestamp,
count(q.warehouse_id) as num_queries
from seconds_w_bin_number as s
left join queries_w_bin_number as q
on s.bin_num=q.bin_num
and s.timestamp between date_trunc('second', q.start_time) and date_trunc('second', q.end_time)
group by 1
Auf demselben Datensatz wie zuvor lief diese Abfrage{% superscript id=7 /%} in 2,2 Sekunden – die nicht optimierte Variante brauchte 750 Sekunden. Eine Verbesserung um mehr als das 300-Fache. Das zugehörige Query Profile sehen Sie unten. Beachten Sie, dass die Join-Bedingung jetzt zwei Abschnitte enthält: einen für die Equi-Join-Bedingung auf bin_num und einen für die Range-Join-Bedingung.
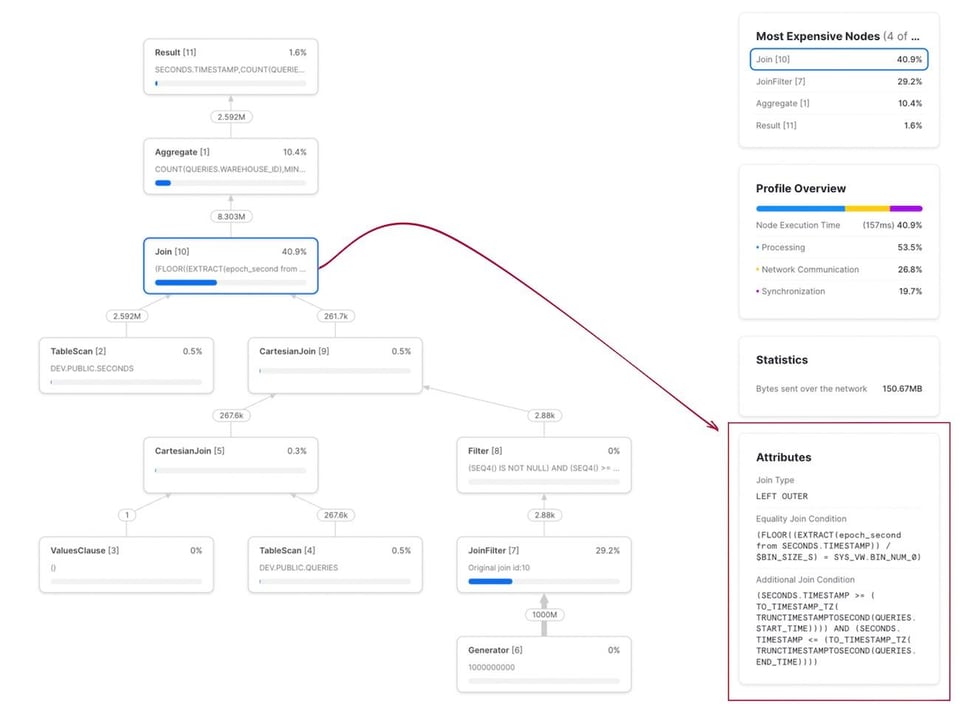
Die richtige Bin-Größe wählen
Entscheidend für den Erfolg dieser Strategie ist die richtige Bin-Größe. Jeder Bin soll einen möglichst kleinen Wertebereich abdecken, damit die Zeilenexplosion im Zwischen-Dataset vor dem Range-Join-Filter klein bleibt. Wählen Sie die Bin-Größe aber zu klein, wächst Ihre "rechte Tabelle" (queries) beim Auffächern auf 1 Zeile pro Bin deutlich an.
Laut Databricks ist es eine gute Faustregel, das 90. Perzentil Ihrer Intervalllänge zu wählen. Berechnen lässt sich das mit der Funktion approx_percentile in Kombination mit DATEDIFF. Hier die Werte für das queries-Beispiel-Dataset, das ich in diesem Beitrag durchgängig verwende:
select
approx_percentile(datediff('second', start_time, end_time), 0.5) as p50, -- 2s
approx_percentile(datediff('second', start_time, end_time), 0.90) as p90, -- 30s
approx_percentile(datediff('second', start_time, end_time), 0.95) as p95, -- 120s
approx_percentile(datediff('second', start_time, end_time), 0.99) as p99, -- 600s
approx_percentile(datediff('second', start_time, end_time), 0.999) as p999, -- 900s
count(*) -- 267K
from queries
Faustregeln sind nicht perfekt. Testen Sie Ihre Abfrage nach Möglichkeit mit mehreren Bin-Größen und prüfen Sie, welche am besten abschneidet. Hier die Performance-Kurve für die obige Abfrage bei verschiedenen Bin-Größen. In diesem Fall machte es kaum einen Unterschied, ob wir das 99,9. oder das 90. Perzentil wählten. Wie erwartet verschlechterten sich die Laufzeiten, sobald die Bin-Größe sehr klein wurde.
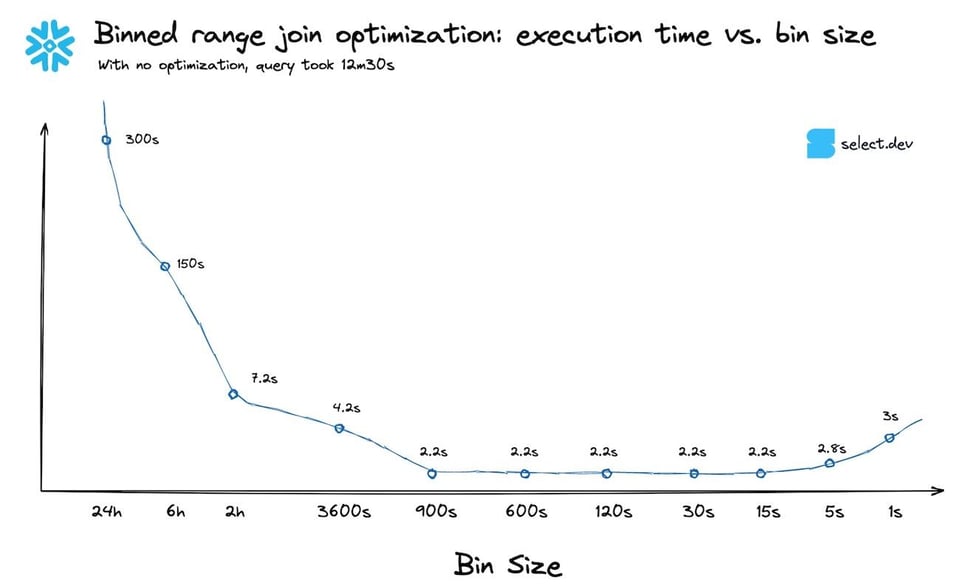
Wie lässt sich das auf einen Join mit festem Intervall erweitern?
- Erklären, wie sich das auf einen Point-in-Interval-Join mit festem Intervall erweitern lässt
- Die Bin-Größe würde auf die feste Intervallgröße gesetzt
Wenn Sie einen Point-in-Interval-Range-Join mit fester Intervallgröße haben – wie die weiter oben gezeigte Abfrage:
select
...
from page_views
inner join events
on events.event_type='purchase' -- filter condition
and page_views.pathname = '/' -- filter condition
and page_views.user_id=events.user_id -- equi-join condition
and page_views.viewed_at < events.event_at -- range join condition
and dateadd('hour', 24, page_views.viewed_at) >= events.event_at -- range join condition
– dann setzen Sie Ihre Bin-Größe auf die Intervalllänge: 24 Stunden.
Wie lässt sich das auf einen Interval Overlap Range Join erweitern?
Bei einem Interval Overlap Range Join wie dem folgenden:
select
s1.session_id,
array_agg(s2.session_id) as concurrent_sessions
from landing_page_sessions as s1
inner join app_sessions as s2
on s1.end_time > s2.start_time
and s1.start_time < s2.end_time
group by 1
– können Sie dieselbe Binned-Range-Join-Technik anwenden, nachdem Sie sowohl landing_page_sessions als auch app_sessions auf 1 Zeile pro Session und Bin aufgefächert haben, in den die Session fiel (analog zu queries oben).
Wann sollten Sie diese Optimierung einsetzen?
Vergewissern Sie sich zuerst, dass der Range Join tatsächlich der Engpass ist. Prüfen Sie mit dem Snowflake Query Profile, ob er zu den teuersten Knoten in der Abfrageausführung gehört. Die Binned-Range-Join-Optimierung macht Abfragen schwerer verständlich und aufwendiger in der Wartung.
Die Technik funktioniert ausschließlich für Point-in-Interval- und Interval-Overlap-Range-Joins mit numerischen Typen. Für andere Non-Equi-Joins greift sie nicht – Sie können das Prinzip aber übertragen und nach Möglichkeit eine Equi-Join-Bedingung ergänzen, um die Zeilenexplosion einzudämmen.
Hat das Dataset auf der "rechten" Seite mit den start- und end-Zeiten eine relativ gleichmäßige Verteilung der Intervalllängen, ist diese Technik weniger wirksam.
Anmerkungen
Dieser Wert stammt aus einer einzigen Abfrage – also mit Vorsicht zu genießen. Ihre Ergebnisse hängen von vielen Faktoren ab.
Inspiriert wurde dieser Ansatz von einem Beitrag von Simeon Pilgrim aus dem Jahr 2016 (damals hieß Snowflake noch snowflake.net!). Ich habe ihn lange erfolgreich genutzt, bis ich auf den allgemeineren Binning-Ansatz umgestiegen bin.
Der Range Join auf die
hours-Tabelle läuft deutlich schneller als der Range Join auf dieseconds-Tabelle, weil die Zwischentabelle rund 3.600-mal kleiner ist.Inspiriert wurde dieser Ansatz von Databricks. Sie gehen nicht im Detail auf die Implementierung ihres Algorithmus ein, aber ich vermute, dass er ähnlich funktioniert.
Optional können Sie eine
get_bin_number-Funktion anlegen, um dieselbe Berechnung nicht überall in der Abfrage zu wiederholen:
create or replace function get_bin_number(timestamp timestamp_tz, bin_size_s integer)
returns integer
as
$$
floor(date_part(epoch_second, timestamp) / bin_size_s)
$$
Da Snowflake keine berechneten Werte an den Generator durchreicht, mussten wir das in zwei Schritten lösen. In Kürze stellen wir einige dbt-Makros als Open Source bereit, die diesen Vorgang kapseln.
Die vollständige Beispielabfrage für die Binned-Range-Join-Optimierung:
create or replace function get_bin_number(timestamp timestamp_tz, bin_size_s integer)
returns integer
as
$$
floor(date_part(epoch_second, timestamp) / bin_size_s)
$$
;
set bin_size_s = 60;
with
metadata as (
select
-- Get the time range your query will span
min(timestamp) as start_time,
Code ausklappen
Ian Whitestone · Co-Founder & CEO von SELECT
Ian ist Co-Founder und CEO von SELECT, einer SaaS-Plattform für Kostenmanagement und Optimierung in Snowflake. Vor SELECT leitete er sechs Jahre lang Full-Stack-Data-Science- und Engineering-Teams bei Shopify und Capital One. Bei Shopify verantwortete er die Optimierung des Data Warehouse und den Ausbau der Cost Observability.