I range join e gli altri tipi di non-equi join sono notoriamente lenti nella maggior parte dei database. Snowflake è velocissimo sulla maggior parte delle query, ma anche lui soffre di performance scadenti quando deve gestire questo tipo di join. In questo articolo vedremo una tecnica di ottimizzazione che consente di accelerare fino a 300 volte le query con range join 1.
Prima di entrare nel merito della tecnica, faremo un breve ripasso sui vari tipi di join e sui motivi che rendono i range join così lenti in Snowflake. Se conosce già l'argomento, può passare direttamente alla sezione successiva.
Equi-join e non-equi join a confronto
Un equi-join è un join che prevede una condizione di uguaglianza. La maggior parte degli utenti scrive query con una o più condizioni di equi-join.
select
...
from orders
join customers
on orders.customer_id=customers.id -- esempio di condizione di equi-join
Un non-equi join, invece, prevede una condizione di disuguaglianza. Un esempio potrebbe essere l'individuazione dei clienti che hanno acquistato lo stesso prodotto:
select distinct
o1.customer_id,
o2.customer_id,
o1.product_id
from orders_items as o1
join orders_items as o2
on o1.product_id=o2.product_id -- condizione di equi-join
and o1.customer_id<>o2.customer_id -- condizione di non-equi join
Oppure trovare, per ciascun cliente, tutti gli ordini successivi a una determinata data:
select
...
from orders
inner join customers
on orders.customer_id=customers.id
and orders.created_at > customers.one_year_anniversary_date
Cosa sono i range join?
Un range join è un tipo specifico di non-equi join. Si verifica quando un join controlla se un valore ricade in un determinato intervallo ("point in interval join") oppure quando cerca due periodi che si sovrappongono ("interval overlap join").
Point in interval range join
Un esempio di point in interval range join è il calcolo del numero di query in esecuzione per ogni secondo:
select
seconds.timestamp,
count(queries.query_id) as num_queries
from seconds
left join queries
on seconds.timestamp between
date_trunc('second', queries.start_time) and date_trunc('second', queries.end_time)
group by 1
Questo tipo di join può basarsi anche su timestamp derivati. Per esempio, trovare tutti gli eventi di acquisto avvenuti entro 24 ore dalla visualizzazione della home page da parte degli utenti:
select
...
from page_views
inner join events
on events.event_type='purchase' -- condizione di filtro
and page_views.pathname = '/' -- condizione di filtro
and page_views.user_id=events.user_id -- condizione di equi-join
and page_views.viewed_at < events.event_at -- condizione di range join
and dateadd('hour', 24, page_views.viewed_at) >= events.event_at -- condizione di range join
Interval overlap range join
Si parla di interval overlap range join quando una query cerca di mettere in corrispondenza periodi che si sovrappongono. Immagini di dover trovare, per ogni sessione di navigazione sulla landing page, tutte le altre sessioni avvenute contemporaneamente all'interno dell'applicazione:
select
s1.session_id,
array_agg(s2.session_id) as concurrent_sessions
from landing_page_sessions as s1
inner join app_sessions as s2
on s1.end_time > s2.start_time
and s1.start_time < s2.end_time
group by 1
Perché i range join sono lenti in Snowflake?
I range join sono lenti in Snowflake perché vengono eseguiti come join cartesiani con una condizione di filtro applicata a valle. Un join cartesiano, noto anche come cross join, restituisce il prodotto cartesiano dei record tra i due dataset coinvolti. Se entrambe le tabelle contengono 10mila record, l'output del join cartesiano sarà di 100 milioni di record! Tra gli addetti ai lavori si parla spesso di "join explosion" 💥. L'esecuzione della query può rallentare in modo significativo quando Snowflake si trova a elaborare dataset intermedi così grandi.
Approfondiamo il discorso riprendendo l'esempio del "numero di query in esecuzione al secondo".
select
s1.session_id,
array_agg(s2.session_id) as concurrent_sessions
from landing_page_sessions as s1
inner join app_sessions as s2
on s1.end_time > s2.start_time
and s1.start_time < s2.end_time
group by 1
La nostra tabella seconds contiene 1 riga per ogni secondo, mentre la tabella queries contiene 1 riga per query. L'obiettivo è individuare quali query erano in esecuzione in ciascun secondo, per poi aggregare e contare.
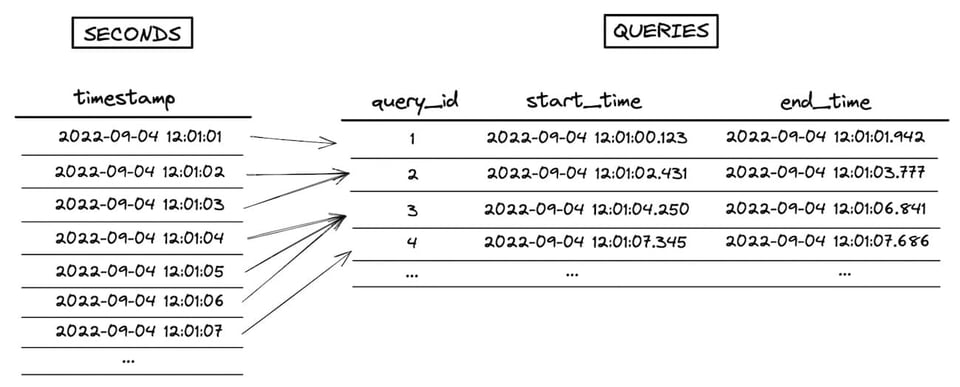
Durante l'esecuzione del join, Snowflake crea prima un dataset intermedio che è il prodotto cartesiano dei due dataset di input. In questo esempio la tabella seconds ha 7 righe e la tabella queries ne ha 4, quindi il dataset intermedio esplode a 28 righe. La condizione di range join che esegue il controllo "point in interval" viene applicata dopo la creazione di questo dataset intermedio, come filtro post-join. Nell'immagine qui sotto può vedere una rappresentazione del processo (apra questa pagina per la versione a schermo intero in alta risoluzione).
{kind=link}
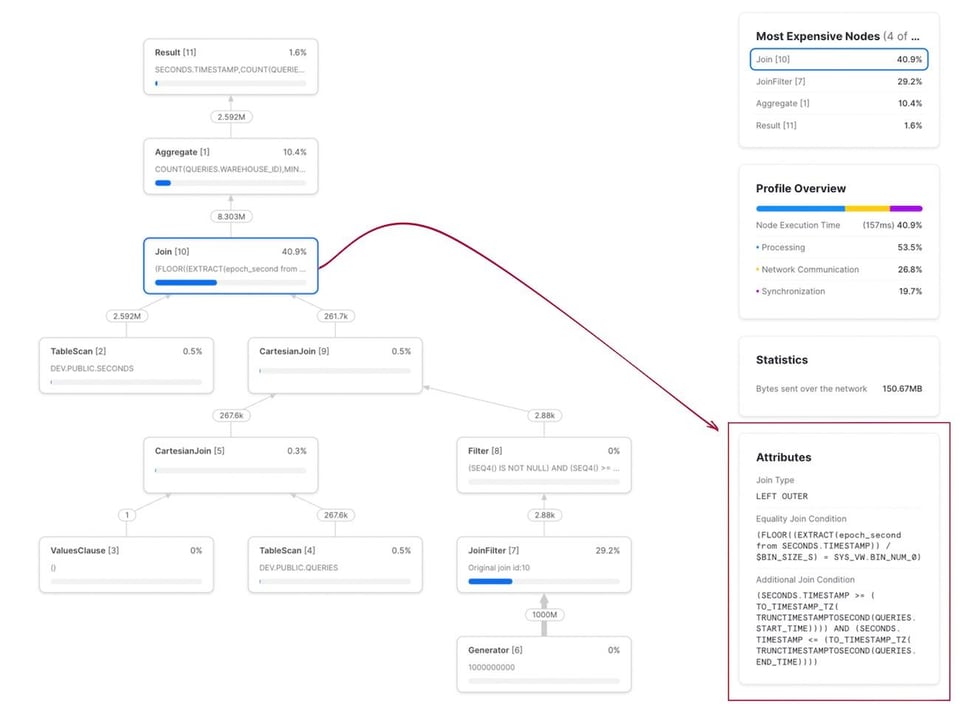
L'esecuzione di questa query su un campione di 30 giorni di dati con 267K query ha richiesto 12 minuti e 30 secondi. Come si vede nel query profile, il join è chiaramente il collo di bottiglia. Si può notare anche la condizione di range join, espressa come "Additional Join Condition":

Come ottimizzare i range join in Snowflake
Nell'esecuzione dei range join, il collo di bottiglia per Snowflake è il volume di dati prodotto nel dataset intermedio prima che la condizione di range join venga applicata come filtro post-join. Per accelerare queste query bisogna trovare il modo di ridurre al minimo le dimensioni del dataset intermedio. Lo si può fare aggiungendo una condizione di equi-join, che Snowflake elabora molto rapidamente tramite hash join. 2
Ridurre al minimo l'esplosione delle righe
Il principio di fondo è intuitivo — rimpicciolire i dataset — ma metterlo in pratica è meno semplice. Come si può ridurre il dataset intermedio prima di applicare il filtro post-join del range join? Restando all'esempio delle query al secondo, viene istintivo aggiungere una condizione di equi-join su qualcosa come l'hour di ciascun timestamp:
select
seconds.timestamp,
count(queries.query_id) as num_queries
from seconds
left join queries
on date_trunc('hour', seconds.timestamp)=date_trunc('hour', queries.start_time) -- NUOVA: condizione di equi-join
and seconds.timestamp -- condizione di range join
between date_trunc('second', queries.start_time) and date_trunc('second', queries.end_time)
group by 1
Sembra promettente, ma l'approccio non regge quando l'intervallo (la durata totale della query) supera l'ora. Dato che l'equi-join si basa sull'ora di inizio della query, tutti i record nelle ore successive verrebbero esclusi dal conteggio.
Si può risolvere il problema creando un dataset intermedio, query_hours, che contiene 1 riga per query per ogni ora in cui la query è stata in esecuzione. A quel punto diventa sicuro fare il join sull'hour, perché avremo 1 riga per ogni ora di esecuzione. Nessun record viene scartato per errore.
with
query_hours as (
select
queries.*,
hours_list.timestamp as query_hour
from queries
inner join hours_list -- dataset che contiene 1 riga per ora
on hours_list.timestamp between date_trunc('hour', queries.start_time) and date_trunc('hour', queries.end_time)
)
select
seconds.timestamp,
count(queries.query_id) as num_queries
from seconds
left join query_hours as queries
on date_trunc('hour', seconds.timestamp)=queries.query_hour -- NUOVA: condizione di equi-join
Espandi codice
Avrà notato che la CTE query_hours contiene a sua volta un range join: non sarà lento anche quello? Applicato alle query giuste, il tempo extra speso nella preparazione del dataset di input si traduce in una query complessivamente molto più veloce
3. Un'altra perplessità potrebbe riguardare il fatto che il dataset query_hours diventi molto più grande di quello queries originale, dato che si espande a 1 riga per query per ora. Ma poiché la maggior parte delle query termina ben prima di un'ora, il dataset query_hours avrà dimensioni simili a quello queries di partenza.
Aggiungere la nuova condizione di equi-join sugli hour aiuta ad accelerare questa query con range join limitando le dimensioni del dataset intermedio. Tuttavia, l'approccio non è ideale per diverse ragioni. Forse hour non è la scelta migliore e converrebbe usare un altro vincolo. Inoltre, come si può estendere questo approccio per supportare range join su altri tipi numerici, come interi e float?
Ottimizzazione binned range join
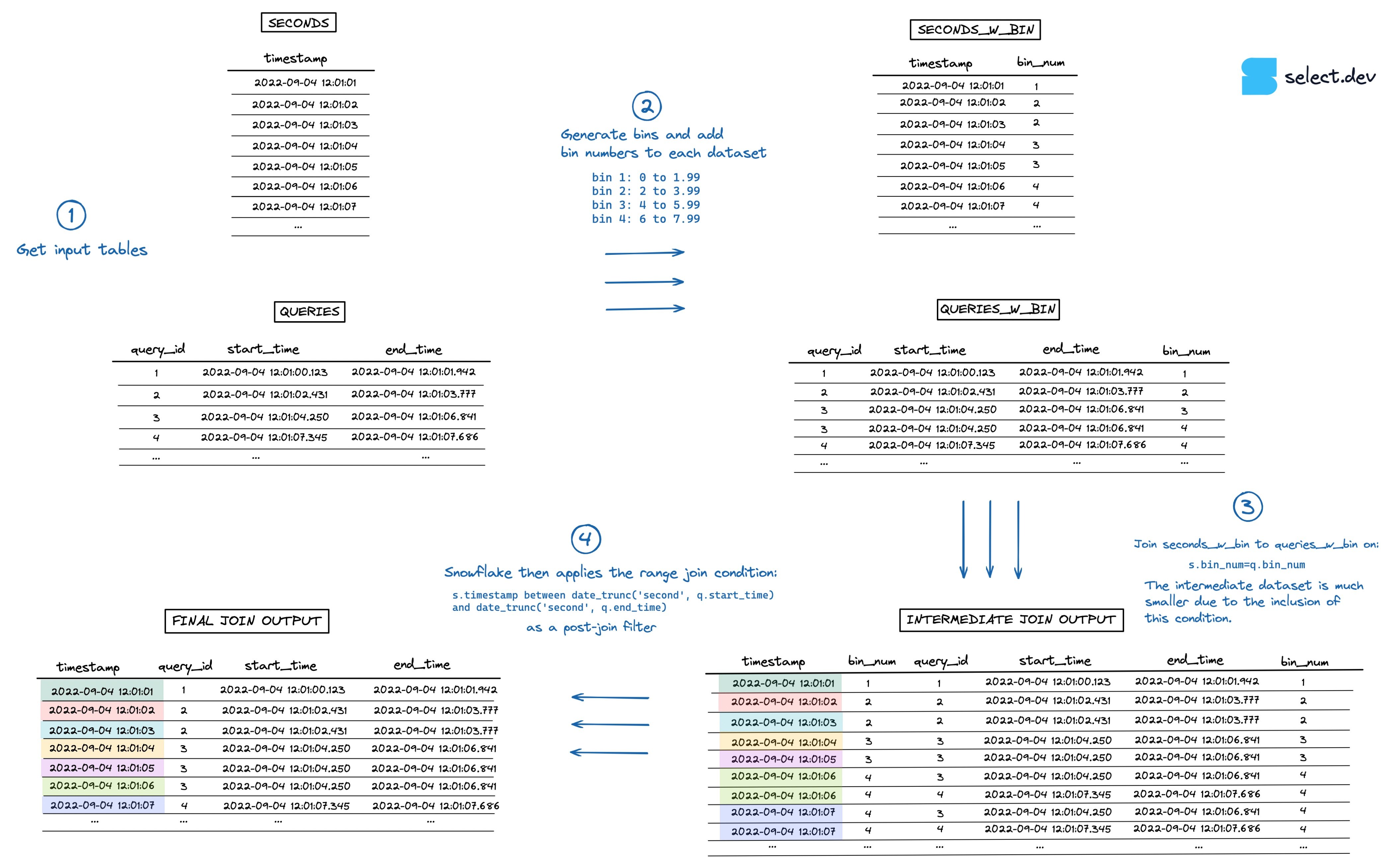
Possiamo estendere le idee viste sopra a un approccio più generico, basato sui 'bin' 4.
Indicando a Snowflake di applicare la condizione di range join solo su sottoinsiemi di dati più piccoli, l'operazione di join diventa molto più veloce. Per ogni timestamp, Snowflake ora si limita a fare il join con le query eseguite nella stessa ora, anziché con tutte le query mai eseguite.
Invece di limitarci a intervalli predefiniti come "ora", "minuto" o "giorno", possiamo usare bin di dimensione arbitraria. Per esempio, se la maggior parte delle query si esegue in meno di 2 secondi, possiamo raggruppare le query in bin da 2 secondi ciascuno.
L'algoritmo sarebbe più o meno questo:
- Generare i bin e aggiungere il numero di bin a ciascun dataset
- Aggiungere il vincolo di equi-join al range join usando
bin_num, in modo analogo a quanto fatto sopra conhour. - Il dataset intermedio creato sarà ora molto più piccolo.
- Come al solito, Snowflake applica il range join come filtro post-join. Questa volta, però, molto più rapidamente.
Nell'immagine qui sotto può vedere una rappresentazione del processo (apra questa pagina per la versione a schermo intero in alta risoluzione).
{kind=link}
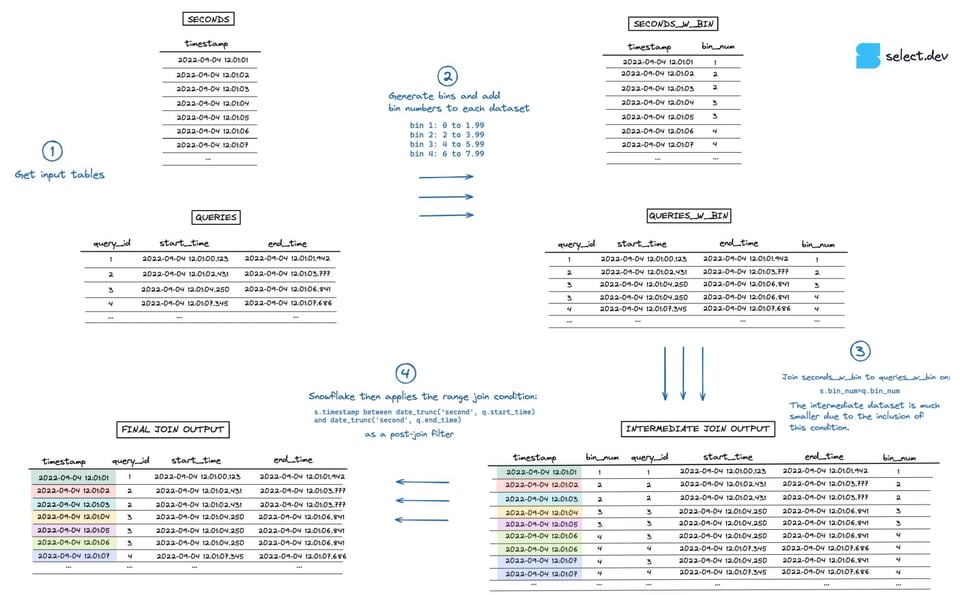
Esempio di query binned range join
I numeri di bin sono semplicemente interi che rappresentano un intervallo di dati. Un modo per crearli è dividere il numero per la dimensione di bin desiderata. Con i timestamp possiamo prima convertire il timestamp in unix time, che è un intero, e poi fare la divisione:
-- per bin da 60 secondi
select
timestamp,
floor(date_part(epoch_second, timestamp) / 60) as bin_num
Salveremo questa logica in una funzione, get_bin_number
5, per non doverla ripetere ogni volta.
Seguendo i passaggi descritti sopra, dobbiamo prima generare la lista dei bin applicabili. Lo si fa utilizzando un generatore per creare una lista di interi, per poi filtrarla in base ai numeri di bin di inizio e fine desiderati 6.
set bin_size_s = 60;
with
metadata as (
select
-- questa sarebbe una query sull'intervallo di tempo desiderato
min(timestamp) as start_time,
max(timestamp) as end_time,
get_bin_number(start_time, $bin_size_s) as bin_num_start,
get_bin_number(end_time, $bin_size_s) as bin_num_end
from seconds
),
-- serve una CTE con 1 riga tra bin_num_start e bin_num_end
-- bisogna prima generare una lista enorme, poi filtrarla perché non si possono passare valori calcolati
-- con bins_base a 1 trilione il filtraggio richiede 5 secondi. 106 ms per 1 milione
Espandi codice
Ora possiamo aggiungere il numero di bin a ciascun dataset. Per queries produrremo un dataset con 1 riga per query per ogni bin in cui la query è stata eseguita. Per seconds, ogni timestamp verrà mappato a un singolo bin.
queries_w_bin_number as (
select
start_time,
end_time,
warehouse_id,
cluster_number,
bins.bin_num
from queries
inner join bins
on bins.bin_num between
get_bin_number(queries.start_time, $bin_size_s) and get_bin_number(queries.end_time, $bin_size_s)
),
seconds_w_bin_number as (
select
timestamp,
Espandi codice
E applichiamo la condizione di join finale, con la condizione di equi-join aggiuntiva su bin_num:
select
s.timestamp,
count(q.warehouse_id) as num_queries
from seconds_w_bin_number as s
left join queries_w_bin_number as q
on s.bin_num=q.bin_num
and s.timestamp between date_trunc('second', q.start_time) and date_trunc('second', q.end_time)
group by 1
Sullo stesso dataset di prima, questa query{% superscript id=7 /%} viene eseguita in 2,2 secondi, contro i 750 secondi della versione non ottimizzata vista in precedenza. Un miglioramento di oltre 300 volte. Il query profile è mostrato qui sotto. Si noti come la condizione di join compaia ora in due sezioni: una per la condizione di equi-join su bin_num e l'altra per la condizione di range join.
Scegliere la dimensione di bin corretta
Un aspetto fondamentale per far funzionare questa strategia è scegliere la giusta dimensione di bin. Ogni bin deve contenere un intervallo di valori ristretto, in modo da ridurre al minimo l'esplosione di righe nel dataset intermedio prima dell'applicazione del filtro di range join. D'altra parte, se la dimensione scelta è troppo piccola, le dimensioni della "tabella di destra" (queries) aumenteranno in modo significativo quando viene espansa a 1 riga per bin.
Secondo Databricks, una buona regola empirica è scegliere il 90° percentile della durata dell'intervallo. Lo si può calcolare con la funzione approx_percentile insieme a DATEDIFF. Qui sotto trova i valori per il dataset di esempio queries usato in tutto l'articolo.
select
approx_percentile(datediff('second', start_time, end_time), 0.5) as p50, -- 2s
approx_percentile(datediff('second', start_time, end_time), 0.90) as p90, -- 30s
approx_percentile(datediff('second', start_time, end_time), 0.95) as p95, -- 120s
approx_percentile(datediff('second', start_time, end_time), 0.99) as p99, -- 600s
approx_percentile(datediff('second', start_time, end_time), 0.999) as p999, -- 900s
count(*) -- 267K
from queries
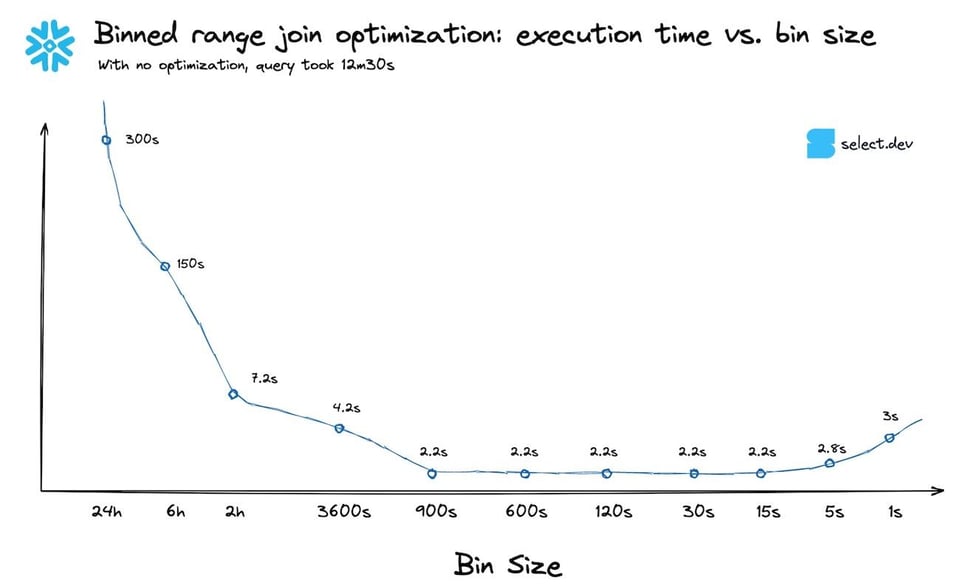
Le regole empiriche non sono perfette. Se possibile, provi la query con diverse dimensioni di bin per capire quale offre le prestazioni migliori. Ecco la curva di performance per la query precedente, al variare della dimensione di bin. In questo caso, scegliere il 99,9° percentile invece del 90° non ha fatto grande differenza. Come previsto, i tempi di esecuzione hanno cominciato a peggiorare quando la dimensione di bin è diventata davvero piccola.
Come estendere questa tecnica a un join con intervallo fisso?
- Spiegare come estendere la tecnica a un point in interval join con intervallo fisso
- La dimensione di bin va impostata pari alla dimensione dell'intervallo fisso
Se ha un point in interval range join con intervallo fisso, come la query vista prima:
select
...
from page_views
inner join events
on events.event_type='purchase' -- condizione di filtro
and page_views.pathname = '/' -- condizione di filtro
and page_views.user_id=events.user_id -- condizione di equi-join
and page_views.viewed_at < events.event_at -- condizione di range join
and dateadd('hour', 24, page_views.viewed_at) >= events.event_at -- condizione di range join
Imposti la dimensione di bin pari a quella dell'intervallo: 24 ore.
Come estendere la tecnica a un interval overlap range join?
Se ha a che fare con un interval overlap range join, come quello qui sotto:
select
s1.session_id,
array_agg(s2.session_id) as concurrent_sessions
from landing_page_sessions as s1
inner join app_sessions as s2
on s1.end_time > s2.start_time
and s1.start_time < s2.end_time
group by 1
Può applicare la stessa tecnica di binned range join dopo aver espanso sia landing_page_sessions sia app_sessions in modo che contengano 1 riga per sessione per ogni bin in cui la sessione ricade (come fatto sopra con queries).
Quando conviene usare questa ottimizzazione?
Come primo passo, verifichi che il range join sia davvero un collo di bottiglia usando il query profile di Snowflake per controllare che sia tra i nodi più costosi nell'esecuzione della query. Aggiungere l'ottimizzazione binned range join, infatti, rende le query più difficili da leggere e mantenere.
La tecnica di binned range join funziona solo per point in interval e interval overlap range join su tipi numerici. Non funziona invece per gli altri tipi di non-equi join, anche se è sempre possibile applicare lo stesso principio: aggiungere un vincolo di equi-join ovunque possibile per ridurre l'esplosione di righe.
Se il dataset "di destra", quello con i tempi di start ed end, presenta una distribuzione relativamente piatta delle durate degli intervalli, questa tecnica risulterà meno efficace.
Note
Il dato si riferisce a una singola query, quindi va preso con le dovute cautele. I risultati possono variare in base a molti fattori.
L'approccio si ispira al post di Simeon Pilgrim del 2016 (quando Snowflake era ancora snowflake.net!). L'ho usato con ottimi risultati fino a quando non ho implementato l'approccio più generico basato sul binning.
Il range join con la tabella
hourssarà molto più rapido del range join con la tabellaseconds, perché la tabella intermedia sarà circa 3600 volte più piccola.L'approccio si ispira a Databricks. Non scendono nel dettaglio dell'implementazione del loro algoritmo, ma presumo funzioni in modo analogo.
In via opzionale, può creare una funzione
get_bin_numberper evitare di duplicare lo stesso calcolo in tutta la query:
create or replace function get_bin_number(timestamp timestamp_tz, bin_size_s integer)
returns integer
as
$$
floor(date_part(epoch_second, timestamp) / bin_size_s)
$$
Snowflake non permette di passare valori calcolati al generatore, quindi è stato necessario procedere in due fasi. A breve renderemo open source alcune macro dbt per astrarre questo processo.
La query completa di esempio per l'ottimizzazione binned range join:
create or replace function get_bin_number(timestamp timestamp_tz, bin_size_s integer)
returns integer
as
$$
floor(date_part(epoch_second, timestamp) / bin_size_s)
$$
;
set bin_size_s = 60;
with
metadata as (
select
-- Ottieni l'intervallo di tempo coperto dalla query
min(timestamp) as start_time,
Espandi codice
Ian Whitestone·Co-founder & CEO di SELECT
Ian è Co-founder & CEO di SELECT, piattaforma SaaS per la gestione e l'ottimizzazione dei costi di Snowflake. Prima di fondare SELECT, ha guidato per 6 anni team full stack di data science ed engineering in Shopify e Capital One. In Shopify si è occupato dell'ottimizzazione del data warehouse e dell'aumento della cost observability.