Los range joins y otros tipos de non-equi joins son tristemente lentos en la mayoría de las bases de datos. Aunque Snowflake es extremadamente rápido para casi cualquier consulta, también sufre de bajo rendimiento al procesar este tipo de joins. En este post veremos una técnica de optimización para acelerar consultas con range joins hasta 300x 1.
Antes de entrar en la técnica, repasemos algo de contexto sobre los distintos tipos de joins y por qué los range joins son tan lentos en Snowflake. Si ya manejas el tema, puedes saltar adelante.
Equi-joins versus non-equi joins
Un equi-join es un join con una condición de igualdad. La mayoría de los usuarios suele escribir consultas con una o más condiciones de equi-join.
select
...
from orders
join customers
on orders.customer_id=customers.id -- ejemplo de condición equi-join
Un non-equi join es un join con una condición de desigualdad. Un ejemplo sería obtener la lista de clientes que compraron el mismo producto:
select distinct
o1.customer_id,
o2.customer_id,
o1.product_id
from orders_items as o1
join orders_items as o2
on o1.product_id=o2.product_id -- condición equi-join
and o1.customer_id<>o2.customer_id -- condición non-equi join
O encontrar, para cada cliente, todos los pedidos posteriores a una fecha determinada:
select
...
from orders
inner join customers
on orders.customer_id=customers.id
and orders.created_at > customers.one_year_anniversary_date
¿Qué son los range joins?
Un range join es un tipo específico de non-equi join. Se da cuando un join verifica si un valor cae dentro de un rango ("point in interval join"), o cuando busca dos períodos que se traslapen ("interval overlap join").
Point in interval range join
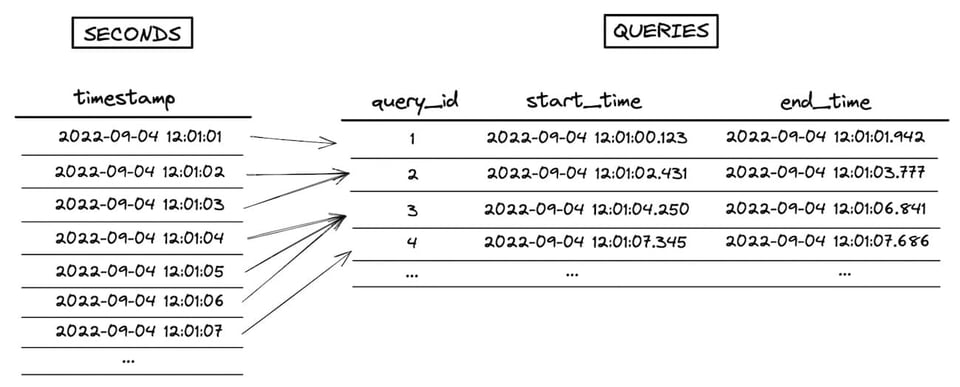
Un ejemplo de point in interval range join sería calcular cuántas consultas se ejecutan en cada segundo:
select
seconds.timestamp,
count(queries.query_id) as num_queries
from seconds
left join queries
on seconds.timestamp between
date_trunc('second', queries.start_time) and date_trunc('second', queries.end_time)
group by 1
Este join también puede basarse en timestamps derivados. Por ejemplo, encontrar todos los eventos de compra ocurridos dentro de las 24 horas siguientes a que los usuarios vieran la página de inicio:
select
...
from page_views
inner join events
on events.event_type='purchase' -- condición de filtro
and page_views.pathname = '/' -- condición de filtro
and page_views.user_id=events.user_id -- condición equi-join
and page_views.viewed_at < events.event_at -- condición range join
and dateadd('hour', 24, page_views.viewed_at) >= events.event_at -- condición range join
Interval overlap range join
Los interval overlap range joins aparecen cuando una consulta intenta emparejar períodos que se traslapan. Imagina que, para cada sesión de navegación en tu landing page, necesitas encontrar todas las demás sesiones que ocurrieron al mismo tiempo en tu aplicación:
select
s1.session_id,
array_agg(s2.session_id) as concurrent_sessions
from landing_page_sessions as s1
inner join app_sessions as s2
on s1.end_time > s2.start_time
and s1.start_time < s2.end_time
group by 1
¿Por qué los range joins son lentos en Snowflake?
Los range joins son lentos en Snowflake porque se ejecutan como cartesian joins con un filtro posterior. Un cartesian join, también conocido como cross join, devuelve el producto cartesiano de los registros entre los dos datasets que se unen. Si ambas tablas tienen 10 mil registros, ¡el resultado del cartesian join será de 100 millones de registros! A esto se le suele llamar una explosión de join 💥. La ejecución de la consulta puede ralentizarse muchísimo cuando Snowflake tiene que procesar datasets intermedios tan grandes.
Tomemos el ejemplo de "cuántas consultas se ejecutan por segundo" para verlo en detalle.
select
s1.session_id,
array_agg(s2.session_id) as concurrent_sessions
from landing_page_sessions as s1
inner join app_sessions as s2
on s1.end_time > s2.start_time
and s1.start_time < s2.end_time
group by 1
Nuestra tabla seconds contiene 1 fila por segundo, y la tabla queries tiene 1 fila por consulta. El objetivo es identificar qué consultas se estaban ejecutando en cada segundo, y luego agregar y contar.
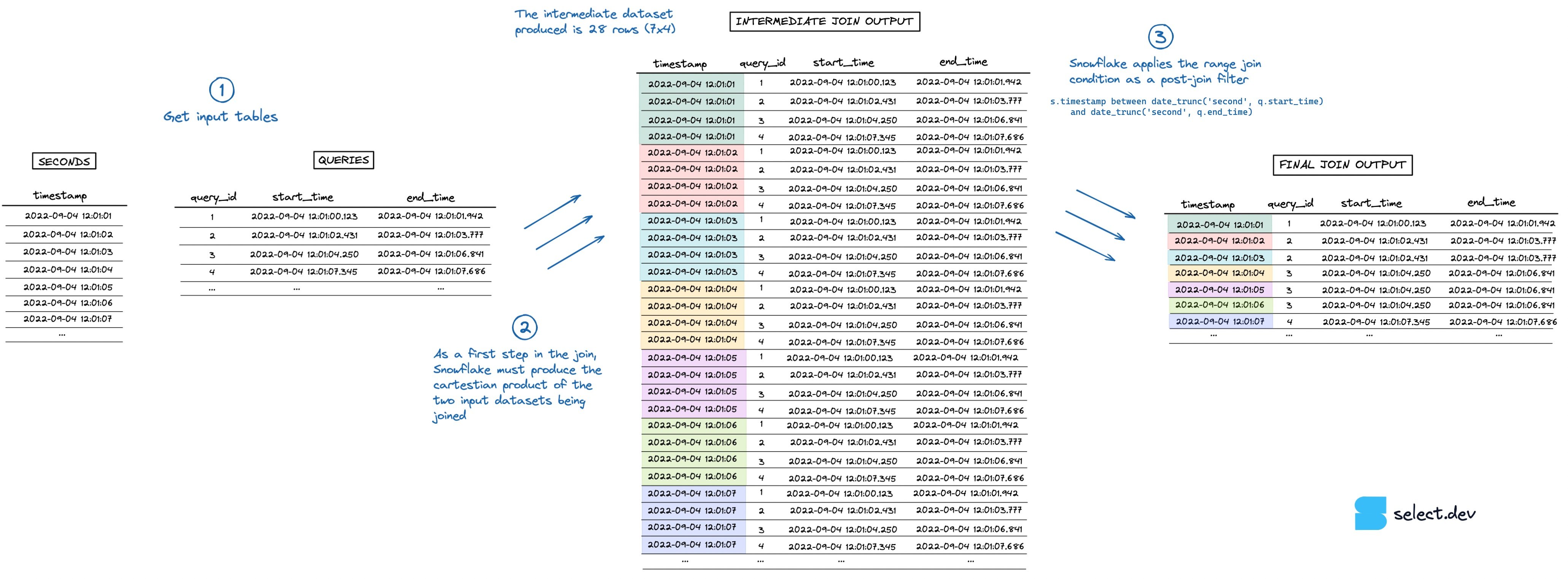
Al ejecutar el join, Snowflake primero crea un dataset intermedio que es el producto cartesiano de los dos datasets de entrada. En este caso, la tabla seconds tiene 7 filas y la tabla queries tiene 4, por lo que el dataset intermedio explota a 28 filas. La condición del range join que hace la verificación "point in interval" se aplica después, como filtro posterior al join. Puedes ver una visualización del proceso en la imagen de abajo (entra aquí para verla en pantalla completa y mayor resolución).
{kind=link}
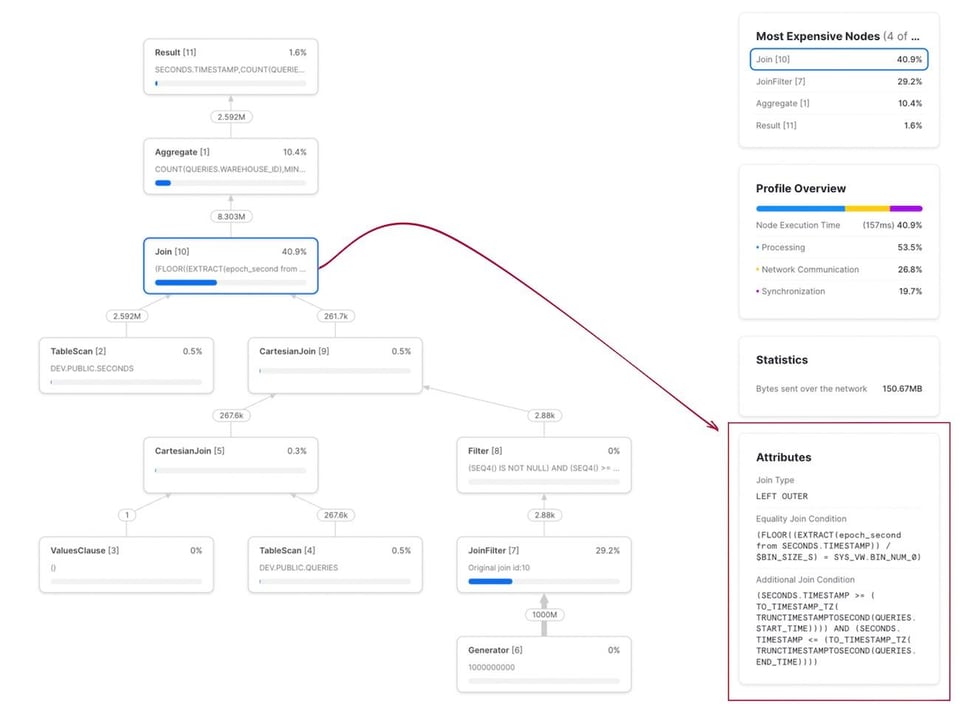
Ejecutar esta consulta sobre una muestra de 30 días con 267K consultas tardó 12 minutos y 30 segundos. Como se ve en el query profile, el join es claramente el cuello de botella. También se observa la condición del range join expresada como "Additional Join Condition":

Cómo optimizar range joins en Snowflake
En los range joins, el cuello de botella en Snowflake es el volumen de datos del dataset intermedio antes de que se aplique la condición del range join como filtro posterior. Para acelerar estas consultas hay que reducir el tamaño de ese dataset intermedio. Esto se logra agregando una condición de equi-join, que Snowflake puede procesar muy rápido con un hash join. 2
Reducir la explosión de filas
El principio es intuitivo —achicar los datasets—, pero llevarlo a la práctica es complicado. ¿Cómo restringir el dataset intermedio antes de aplicar el filtro posterior del range join? Siguiendo con el ejemplo de consultas por segundo, resulta tentador agregar una condición de equi-join sobre algo como la hour de cada timestamp:
select
seconds.timestamp,
count(queries.query_id) as num_queries
from seconds
left join queries
on date_trunc('hour', seconds.timestamp)=date_trunc('hour', queries.start_time) -- NUEVO: condición equi-join
and seconds.timestamp -- condición range join
between date_trunc('second', queries.start_time) and date_trunc('second', queries.end_time)
group by 1
Prometedor, pero el enfoque se desmorona cuando el intervalo (tiempo total de ejecución de la consulta) supera 1 hora. Como el equi-join es sobre la hora en que comenzó la consulta, los registros de horas posteriores no se contarían.
Esto se resuelve creando un dataset intermedio, query_hours, con 1 fila por consulta por cada hora en que la consulta se ejecutó. Así es seguro hacer el join sobre hour, porque tendremos 1 fila por cada hora en que la consulta corrió. No se pierden registros sin querer.
with
query_hours as (
select
queries.*,
hours_list.timestamp as query_hour
from queries
inner join hours_list -- dataset con 1 fila por hora
on hours_list.timestamp between date_trunc('hour', queries.start_time) and date_trunc('hour', queries.end_time)
)
select
seconds.timestamp,
count(queries.query_id) as num_queries
from seconds
left join query_hours as queries
on date_trunc('hour', seconds.timestamp)=queries.query_hour -- NUEVO: condición equi-join
Expandir código
Quizá notaste que el CTE query_hours también implica un range join, ¿no será lento? Cuando se aplica a las consultas adecuadas, el tiempo extra en preparar el dataset de entrada se traduce en una consulta general mucho más rápida
3. Otra preocupación puede ser que el dataset query_hours se vuelva mucho más grande que el original queries, al expandirse a 1 fila por consulta por hora. Como la mayoría de las consultas termina muy por debajo de 1 hora, el dataset query_hours termina siendo de tamaño similar al original queries.
Agregar la nueva condición de equi-join sobre hours ayuda a acelerar la consulta al limitar el tamaño del dataset intermedio. Sin embargo, el enfoque no es ideal por varias razones. Tal vez hour no sea la mejor elección y convenga usar otra restricción. Además, ¿cómo extenderlo para soportar range joins con otros tipos de datos numéricos, como enteros y flotantes?
Optimización de range join con bins
Podemos llevar las ideas anteriores a un enfoque más genérico usando 'bins' 4.
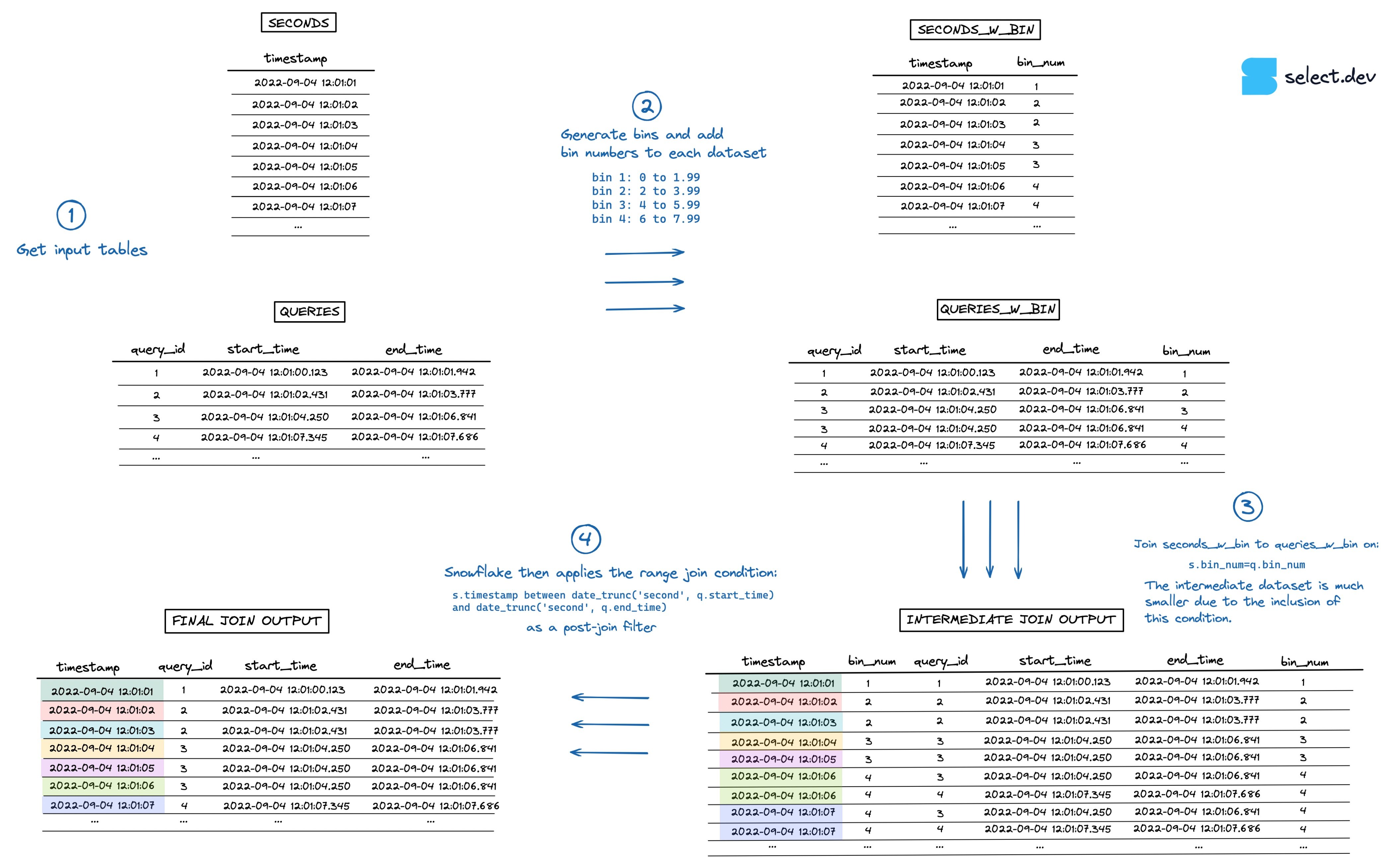
Al indicarle a Snowflake que aplique la condición del range join solo sobre subconjuntos más pequeños de datos, la operación de join se vuelve mucho más rápida. Para cada timestamp, Snowflake ahora une únicamente las consultas que se ejecutaron en la misma hora, en lugar de todas las consultas de todo el tiempo.
En vez de limitarnos a rangos predefinidos como "hour", "minute" o "day", podemos usar bins de tamaño arbitrario. Por ejemplo, si la mayoría de las consultas se ejecutan en menos de 2 segundos, podríamos agrupar las consultas en bins de 2 segundos cada uno.
El algoritmo sería más o menos así:
- Generar los bins y agregar números de bin a cada dataset.
- Agregar la restricción de equi-join al range join usando
bin_num, similar a lo que hicimos arriba conhour. - El dataset intermedio que se crea ahora es mucho más pequeño.
- Como siempre, Snowflake aplica el range join como filtro posterior al join. Esta vez, mucho más rápido.
Puedes ver una visualización del proceso en la imagen de abajo (entra aquí para verla en pantalla completa y mayor resolución).
{kind=link}
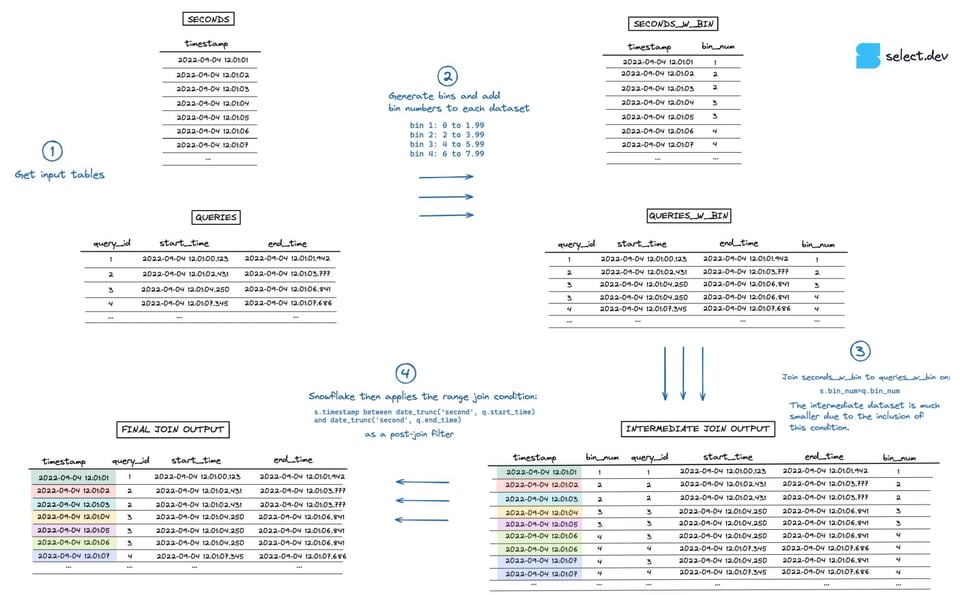
Ejemplo de consulta de range join con bins
Los números de bin son simplemente enteros que representan un rango de datos. Una forma de crearlos es dividir el número por el tamaño de bin deseado. Con timestamps, primero podemos convertir el timestamp a unix time, que es un entero, antes de dividir:
-- para bins de 60 segundos
select
timestamp,
floor(date_part(epoch_second, timestamp) / 60) as bin_num
Guardaremos esto en una función, get_bin_number
5, para no repetirlo cada vez.
Siguiendo los pasos descritos arriba, primero hay que generar la lista de bins aplicables. Esto se hace con un generador que crea una lista de enteros, que luego se filtra hasta los números de bin de inicio y fin deseados 6.
set bin_size_s = 60;
with
metadata as (
select
-- esto sería una consulta sobre el rango de tiempo deseado
min(timestamp) as start_time,
max(timestamp) as end_time,
get_bin_number(start_time, $bin_size_s) as bin_num_start,
get_bin_number(end_time, $bin_size_s) as bin_num_end
from seconds
),
-- se necesita un CTE con 1 fila entre bin_num_start y bin_num_end
-- primero hay que generar una lista enorme y luego filtrarla, ya que no se pueden pasar valores calculados
-- cuando bins_base es 1 billón toma 5 segundos filtrar. 106 ms para 1 millón
Expandir código
Ahora podemos agregar el número de bin a cada dataset. Para el dataset queries, generaremos un dataset con 1 fila por consulta por cada bin en el que la consulta se ejecutó. Para el dataset seconds, cada timestamp se mapeará a un único bin.
queries_w_bin_number as (
select
start_time,
end_time,
warehouse_id,
cluster_number,
bins.bin_num
from queries
inner join bins
on bins.bin_num between
get_bin_number(queries.start_time, $bin_size_s) and get_bin_number(queries.end_time, $bin_size_s)
),
seconds_w_bin_number as (
select
timestamp,
Expandir código
Y aplicar la condición de join final, con la condición de equi-join agregada sobre bin_num:
select
s.timestamp,
count(q.warehouse_id) as num_queries
from seconds_w_bin_number as s
left join queries_w_bin_number as q
on s.bin_num=q.bin_num
and s.timestamp between date_trunc('second', q.start_time) and date_trunc('second', q.end_time)
group by 1
Con el mismo dataset de arriba, esta consulta{% superscript id=7 /%} se ejecutó en 2.2 segundos, mientras que la versión sin optimizar tardaba 750 segundos. Eso es una mejora de más de 300x. El query profile se muestra abajo. Fíjate que la condición del join ahora tiene dos secciones: una para la condición de equi-join sobre bin_num, y otra para la condición del range join.
Cómo elegir el tamaño de bin correcto
Una pieza clave para que esta estrategia funcione es elegir bien el tamaño de bin. Quieres que cada bin contenga un rango pequeño de valores, para minimizar la explosión de filas en el dataset intermedio antes de aplicar el filtro del range join. Pero si el tamaño de bin es demasiado pequeño, la "tabla derecha" (queries) crecerá muchísimo al expandirla a 1 fila por bin.
Según Databricks, una buena regla general es usar el percentil 90 de la duración de tus intervalos. Puedes calcularlo con la función approx_percentile junto con DATEDIFF. Estos son los valores para el dataset de muestra queries que vengo usando a lo largo del post.
select
approx_percentile(datediff('second', start_time, end_time), 0.5) as p50, -- 2s
approx_percentile(datediff('second', start_time, end_time), 0.90) as p90, -- 30s
approx_percentile(datediff('second', start_time, end_time), 0.95) as p95, -- 120s
approx_percentile(datediff('second', start_time, end_time), 0.99) as p99, -- 600s
approx_percentile(datediff('second', start_time, end_time), 0.999) as p999, -- 900s
count(*) -- 267K
from queries
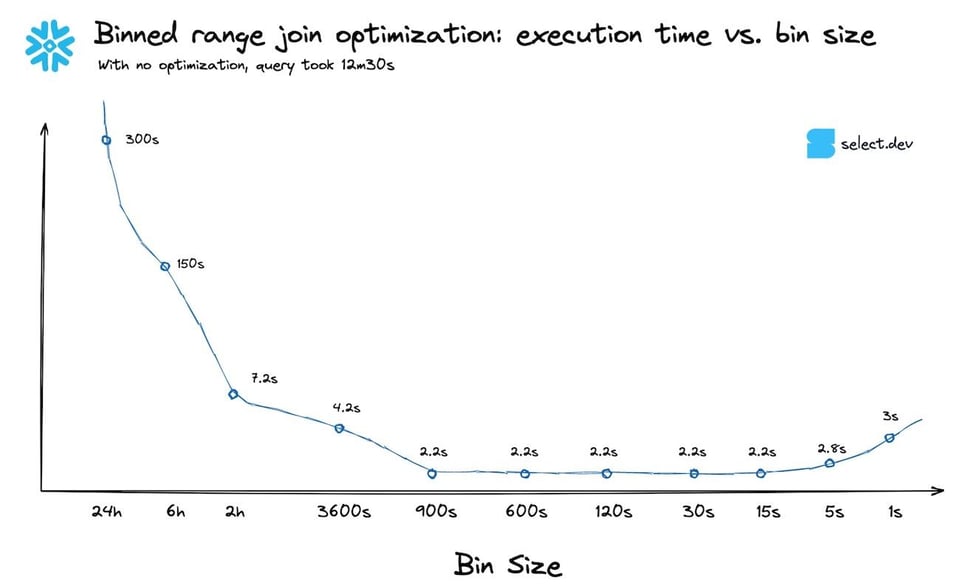
Las reglas generales no son perfectas. Si puedes, prueba tu consulta con varios tamaños de bin y mira cuál rinde mejor. Aquí está la curva de rendimiento para la consulta anterior, con distintos tamaños de bin. En este caso, elegir el percentil 99.9 frente al 90 casi no hizo diferencia. Como era de esperar, los tiempos empezaron a empeorar cuando el tamaño de bin se volvió demasiado pequeño.
¿Cómo extenderlo a un join con intervalo fijo?
- Explicar cómo se extendería a un point in interval join con intervalo fijo
- El tamaño del bin se ajusta al tamaño del intervalo fijo
Si tienes un point in interval range join con un intervalo de tamaño fijo, como la consulta compartida antes:
select
...
from page_views
inner join events
on events.event_type='purchase' -- condición de filtro
and page_views.pathname = '/' -- condición de filtro
and page_views.user_id=events.user_id -- condición equi-join
and page_views.viewed_at < events.event_at -- condición range join
and dateadd('hour', 24, page_views.viewed_at) >= events.event_at -- condición range join
Entonces ajusta el tamaño del bin al del intervalo: 24 horas.
¿Cómo extenderlo a un interval overlap range join?
Si trabajas con un interval overlap range join como el que se muestra abajo:
select
s1.session_id,
array_agg(s2.session_id) as concurrent_sessions
from landing_page_sessions as s1
inner join app_sessions as s2
on s1.end_time > s2.start_time
and s1.start_time < s2.end_time
group by 1
Puedes aplicar la misma técnica de range join con bins después de expandir tanto landing_page_sessions como app_sessions para que contengan 1 fila por sesión por cada bin dentro del cual cae la sesión (igual que se hizo con queries arriba).
¿Cuándo conviene usar esta optimización?
Como primer paso, confirma que el range join realmente es un cuello de botella usando el query profile de Snowflake y verifica que sea uno de los nodos más costosos en la ejecución. Agregar la optimización de range join con bins vuelve las consultas más difíciles de entender y mantener.
La técnica de optimización de range join con bins solo funciona para point in interval e interval overlap range joins con tipos numéricos. No funciona para otros tipos de non-equi joins, aunque puedes aplicar el mismo principio: tratar de agregar una restricción de equi-join siempre que se pueda para reducir la explosión de filas.
Si el dataset de la "derecha", con los tiempos start y end, tiene una distribución relativamente pareja de tamaños de intervalo, entonces esta técnica no será tan efectiva.
Notas
Esta cifra viene de una sola consulta, así que tómala con pinzas. Tus resultados van a variar según muchos factores.
Este enfoque se inspiró en el post de Simeon Pilgrim de 2016 (¡cuando Snowflake todavía era snowflake.net!). Lo usé con bastante éxito hasta que implementé el enfoque más genérico con bins.
El range join contra la tabla
hoursserá mucho más rápido que el range join contra la tablaseconds, ya que la tabla intermedia será ~3600 veces más pequeña.Este enfoque se inspiró en Databricks. No entran en detalles sobre cómo está implementado su algoritmo, pero asumo que funciona de manera similar.
Opcionalmente, crea una función
get_bin_numberpara no copiar el mismo cálculo a lo largo de la consulta:
create or replace function get_bin_number(timestamp timestamp_tz, bin_size_s integer)
returns integer
as
$$
floor(date_part(epoch_second, timestamp) / bin_size_s)
$$
Snowflake no permite pasar valores calculados al generador, así que esto hay que hacerlo en dos pasos. Próximamente vamos a liberar como open source algunos macros de dbt para abstraer este proceso.
La consulta completa de ejemplo con la optimización de range join con bins:
create or replace function get_bin_number(timestamp timestamp_tz, bin_size_s integer)
returns integer
as
$$
floor(date_part(epoch_second, timestamp) / bin_size_s)
$$
;
set bin_size_s = 60;
with
metadata as (
select
-- Obtén el rango de tiempo que abarcará tu consulta
min(timestamp) as start_time,
Expandir código
Ian Whitestone·Co-founder & CEO of SELECT
Ian es Co-founder y CEO de SELECT, una plataforma SaaS de gestión y optimización de costos de Snowflake. Antes de fundar SELECT, pasó 6 años liderando equipos full stack de data science e ingeniería en Shopify y Capital One. En Shopify, lideró los esfuerzos para optimizar su data warehouse y aumentar la observabilidad de costos.