レンジ結合をはじめとする非等価結合は、多くのデータベースで処理が遅いことで知られています。Snowflakeは大半のクエリにおいて圧倒的な速度を発揮しますが、こうした結合の処理ではパフォーマンスが大きく落ち込みます。本記事では、レンジ結合を含むクエリを最大300倍まで高速化する最適化テクニックを紹介します 1。
本題に入る前に、結合の種類と、Snowflakeでレンジ結合が遅くなる仕組みを簡単におさらいします。すでにご存じの方はこちらから本題へお進みください。
等価結合と非等価結合
等価結合とは、等価条件を用いた結合のことです。通常、ユーザーが書くクエリの多くは、1つ以上の等価結合条件を含んでいます。
select
...
from orders
join customers
on orders.customer_id=customers.id -- 等価結合条件の例
非等価結合とは、不等価条件を用いた結合です。たとえば、同じ商品を購入した顧客の一覧を取得するケースが該当します。
select distinct
o1.customer_id,
o2.customer_id,
o1.product_id
from orders_items as o1
join orders_items as o2
on o1.product_id=o2.product_id -- 等価結合条件
and o1.customer_id<>o2.customer_id -- 非等価結合条件
あるいは、顧客ごとに特定の日付以降の注文をすべて取得するケースも挙げられます。
select
...
from orders
inner join customers
on orders.customer_id=customers.id
and orders.created_at > customers.one_year_anniversary_date
レンジ結合とは?
レンジ結合は、非等価結合の中でも特定のタイプを指します。ある値が特定の範囲内に収まるかを判定する結合(「point in interval join」)と、2つの期間が重なるかどうかを判定する結合(「interval overlap join」)の2つがあります。
point in interval レンジ結合
point in interval レンジ結合の例としては、毎秒実行中のクエリ数を集計するケースが挙げられます。
select
seconds.timestamp,
count(queries.query_id) as num_queries
from seconds
left join queries
on seconds.timestamp between
date_trunc('second', queries.start_time) and date_trunc('second', queries.end_time)
group by 1
この結合は派生タイムスタンプを基準にすることもできます。たとえば、ユーザーがホームページを閲覧してから24時間以内に発生した購入イベントをすべて抽出するクエリです。
select
...
from page_views
inner join events
on events.event_type='purchase' -- フィルター条件
and page_views.pathname = '/' -- フィルター条件
and page_views.user_id=events.user_id -- 等価結合条件
and page_views.viewed_at < events.event_at -- レンジ結合条件
and dateadd('hour', 24, page_views.viewed_at) >= events.event_at -- レンジ結合条件
interval overlap レンジ結合
interval overlap レンジ結合は、重なり合う期間どうしをマッチングするクエリで使われます。たとえば、ランディングページ上の各ブラウジングセッションについて、同時刻にアプリケーション側で発生していたセッションをすべて抽出するケースを考えてみましょう。
select
s1.session_id,
array_agg(s2.session_id) as concurrent_sessions
from landing_page_sessions as s1
inner join app_sessions as s2
on s1.end_time > s2.start_time
and s1.start_time < s2.end_time
group by 1
Snowflakeでレンジ結合が遅くなる理由
Snowflakeでレンジ結合が遅くなるのは、ポストフィルター条件付きのデカルト結合として実行されるためです。クロス結合とも呼ばれるデカルト結合では、結合対象となる2つのデータセット間でレコードのデカルト積が返されます。両方のテーブルにそれぞれ1万件のレコードがある場合、デカルト結合の出力はなんと1億件に達します。これを「join explosion(結合の爆発) 💥」と呼ぶエンジニアも少なくありません。これほど巨大な中間データセットを処理しなければならないため、クエリの実行速度が大きく低下するのです。
先ほどの「毎秒実行中のクエリ数」の例を使って、もう少し詳しく見ていきましょう。
select
s1.session_id,
array_agg(s2.session_id) as concurrent_sessions
from landing_page_sessions as s1
inner join app_sessions as s2
on s1.end_time > s2.start_time
and s1.start_time < s2.end_time
group by 1
secondsテーブルは1秒あたり1行、queriesテーブルはクエリごとに1行を持つ構成です。このクエリの目的は、各秒に実行中だったクエリを特定し、集計してカウントすることです。
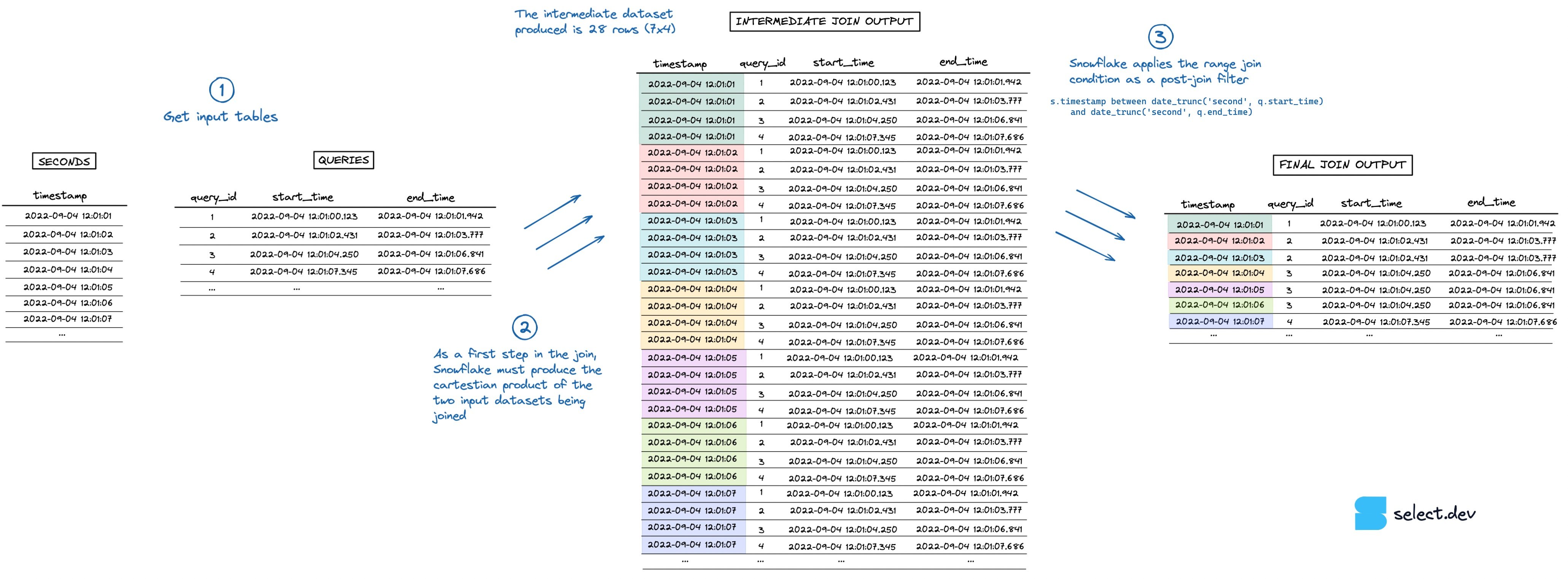
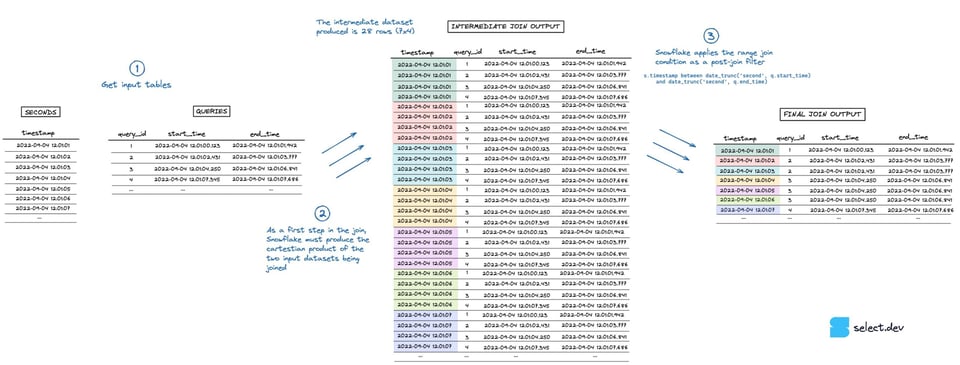
結合を実行する際、Snowflakeはまず2つの入力データセットのデカルト積となる中間データセットを生成します。この例では、secondsテーブルが7行、queriesテーブルが4行のため、中間データセットは28行にまで膨れ上がります。「point in interval」の判定を行うレンジ結合条件は、この中間データセットが作られた後に、ポストジョインフィルターとして適用されます。下の図でこの流れを視覚的に確認できます(フルスクリーンの高解像度版はこちら)。
{kind=link}
267K件のクエリを含む30日分のサンプルデータでこのクエリを実行したところ、12分30秒かかりました。クエリプロファイルを見ると、結合がこのクエリの明らかなボトルネックになっていることがわかります。レンジ結合条件は「Additional Join Condition」として表示されています。

Snowflakeでレンジ結合を最適化する方法
レンジ結合を実行する際、Snowflakeのボトルネックは、レンジ結合条件がポストジョインフィルターとして適用される前に生成される中間データセットの規模にあります。クエリを高速化するには、中間データセットのサイズをいかに小さく抑えるかがポイントになります。これは等価結合条件を追加することで実現でき、Snowflakeはハッシュ結合によって等価結合を非常に高速に処理できます 2。
行の爆発を最小化する
「データセットを小さくする」という原理はシンプルですが、実践は意外と難しいものです。レンジ結合のポストジョインフィルターを適用する前に、どうやって中間データセットを絞り込めばよいのでしょうか。先ほどの「毎秒のクエリ数」の例の続きで考えると、各タイムスタンプのhour(時)などに等価結合条件を追加したくなるところです。
select
seconds.timestamp,
count(queries.query_id) as num_queries
from seconds
left join queries
on date_trunc('hour', seconds.timestamp)=date_trunc('hour', queries.start_time) -- 新規:等価結合条件
and seconds.timestamp -- レンジ結合条件
between date_trunc('second', queries.start_time) and date_trunc('second', queries.end_time)
group by 1
一見うまくいきそうですが、区間(クエリの総実行時間)が1時間を超えるとこの方法は破綻します。等価結合がクエリ開始時の時間に対して行われるため、それ以降の時間に該当するレコードがカウントから漏れてしまうのです。
これを解決するには、各クエリが実行された時間ごとに1行を持つ中間データセットquery_hoursを作成します。こうすればクエリが実行された各時間ごとに1行ずつデータが存在するため、hourで結合しても安全で、レコードを取りこぼすこともありません。
with
query_hours as (
select
queries.*,
hours_list.timestamp as query_hour
from queries
inner join hours_list -- 1時間ごとに1行を持つデータセット
on hours_list.timestamp between date_trunc('hour', queries.start_time) and date_trunc('hour', queries.end_time)
)
select
seconds.timestamp,
count(queries.query_id) as num_queries
from seconds
left join query_hours as queries
on date_trunc('hour', seconds.timestamp)=queries.query_hour -- 新規:等価結合条件
Expand Code
お気付きの方もいるかもしれませんが、query_hours CTE自体がレンジ結合を含んでいます。これも遅くならないのでしょうか? 適切なクエリに適用すれば、入力データセットの準備にかかる追加時間を補って余りある高速化が全体として得られます
3。もう1つの懸念は、query_hoursがクエリごと時間ごとに1行へ展開されるため、元のqueriesデータセットよりはるかに大きくなるのではないか、という点です。しかし、ほとんどのクエリは1時間以内に完了するため、query_hoursのサイズは元のqueriesとほぼ同等になります。
hourに対する新しい等価結合条件を追加することで、中間データセットのサイズが抑えられ、このレンジ結合クエリが高速化されます。ただし、この方法にはいくつか課題もあります。hourが最適な単位とは限らず、別の値を制約に使うべきケースもあるでしょう。また、整数や浮動小数点といった他の数値型を扱うレンジ結合には、このやり方をどう拡張すればよいのでしょうか。
ビン分割によるレンジ結合の最適化
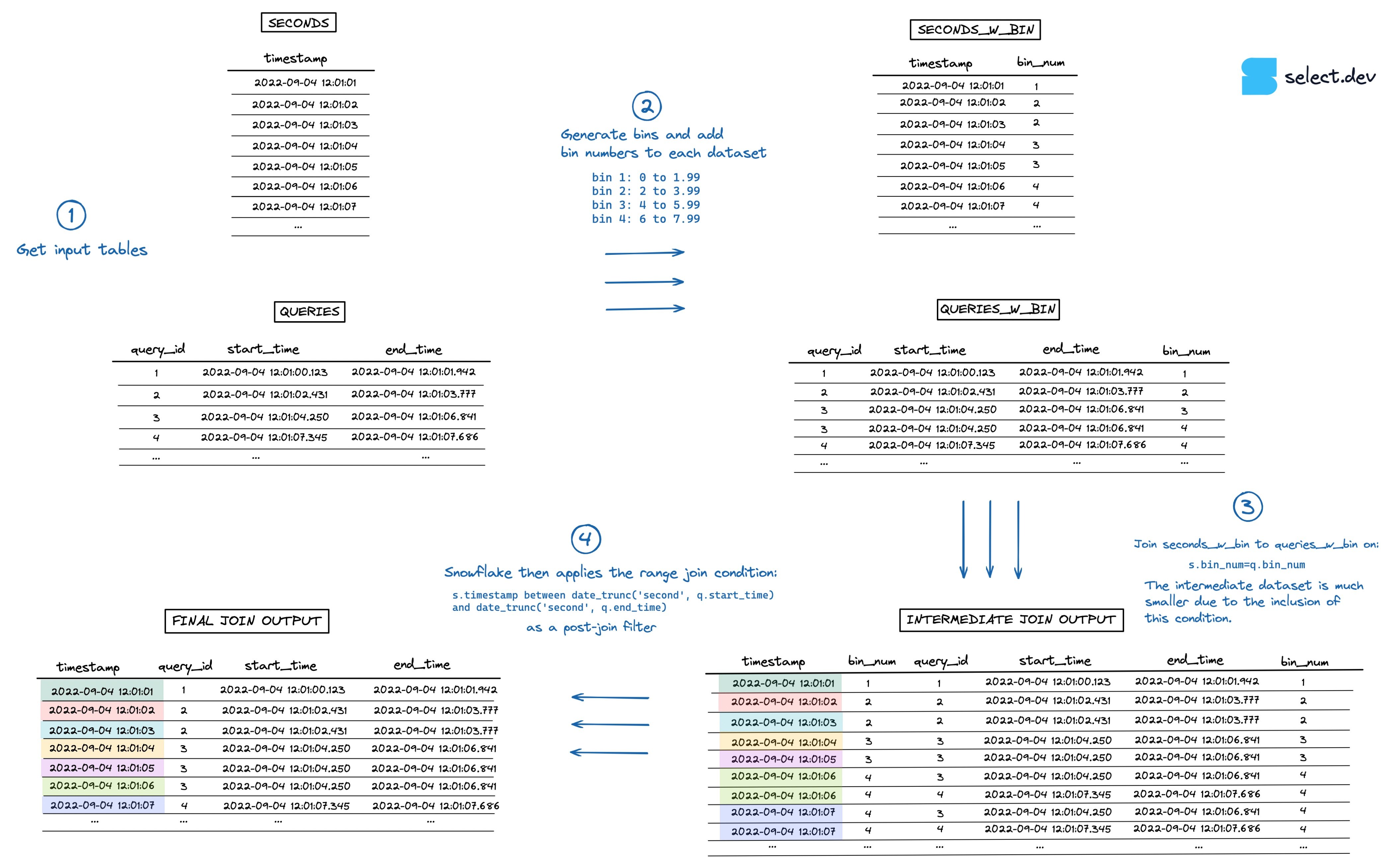
上記の発想を「ビン」という考え方で一般化し、より汎用的なアプローチへと拡張できます 4。
Snowflakeに対し、レンジ結合条件をより小さなデータのサブセットに限定して適用するよう指示することで、結合処理は大幅に高速化します。各タイムスタンプについて、全期間の全クエリではなく、同じ時間に実行されたクエリだけを結合対象とするようになるためです。
「時」「分」「日」といったあらかじめ定められた範囲に縛られず、任意のサイズのビンを使うことができます。たとえば、ほとんどのクエリが2秒以内に終わるなら、2秒単位のビンにクエリを振り分けるとよいでしょう。
アルゴリズムは次のとおりです。
- ビンを生成し、各データセットにビン番号を付与する
- 先ほど
hourで行ったのと同様に、bin_numを使ってレンジ結合に等価結合条件の制約を追加する - 生成される中間データセットがはるかに小さくなる
- 通常どおりSnowflakeがレンジ結合をポストジョインフィルターとして適用するが、今回は格段に高速
下の図でこの流れを視覚的に確認できます(フルスクリーンの高解像度版はこちら)。
{kind=link}
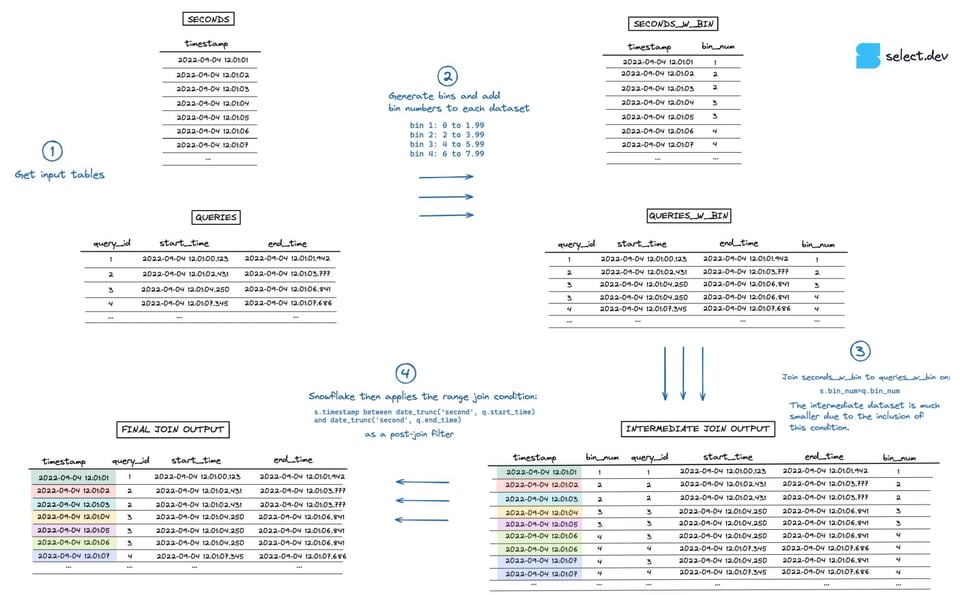
ビン分割レンジ結合クエリの例
ビン番号とは、データの範囲を表す単なる整数です。作り方の1つは、対象の数値を希望するビンサイズで割ることです。タイムスタンプの場合は、まず整数であるUnix時刻に変換してから割ります。
-- 60秒サイズのビンの場合
select
timestamp,
floor(date_part(epoch_second, timestamp) / 60) as bin_num
毎回同じ計算を書かずに済むよう、これをget_bin_number関数として保存しておきます
5。
先ほど述べた手順に沿って、まず対象となるビンのリストを生成します。ジェネレーターで整数のリストを作り、それを目的の開始ビン番号と終了ビン番号に絞り込むことで実現できます 6。
set bin_size_s = 60;
with
metadata as (
select
-- 対象としたい時間範囲に対するクエリを書く
min(timestamp) as start_time,
max(timestamp) as end_time,
get_bin_number(start_time, $bin_size_s) as bin_num_start,
get_bin_number(end_time, $bin_size_s) as bin_num_end
from seconds
),
-- bin_num_startからbin_num_endまで1行ずつ持つCTEが必要
-- ジェネレーターには計算値を渡せないため、まず大きなリストを作ってから絞り込む2段階方式
-- bins_baseが1兆の場合は絞り込みに5秒、100万の場合は106ms
Expand Code
続いて、各データセットにビン番号を付与します。queries側は、クエリが実行されていた各ビンごとに1行を持つデータセットとして出力します。seconds側は、各timestampを1つのビンにマッピングします。
queries_w_bin_number as (
select
start_time,
end_time,
warehouse_id,
cluster_number,
bins.bin_num
from queries
inner join bins
on bins.bin_num between
get_bin_number(queries.start_time, $bin_size_s) and get_bin_number(queries.end_time, $bin_size_s)
),
seconds_w_bin_number as (
select
timestamp,
Expand Code
最後に、bin_numに対する等価結合条件を加えて、最終的な結合条件を適用します。
select
s.timestamp,
count(q.warehouse_id) as num_queries
from seconds_w_bin_number as s
left join queries_w_bin_number as q
on s.bin_num=q.bin_num
and s.timestamp between date_trunc('second', q.start_time) and date_trunc('second', q.end_time)
group by 1
先ほどと同じデータセットを使ったこのクエリ{% superscript id=7 /%}は2.2秒で実行され、先の最適化前のバージョンの750秒と比べて300倍以上の改善となりました。クエリプロファイルは下の図のとおりです。結合条件が2つのセクションに分かれている点に注目してください。1つはbin_numに対する等価結合条件、もう1つはレンジ結合条件です。
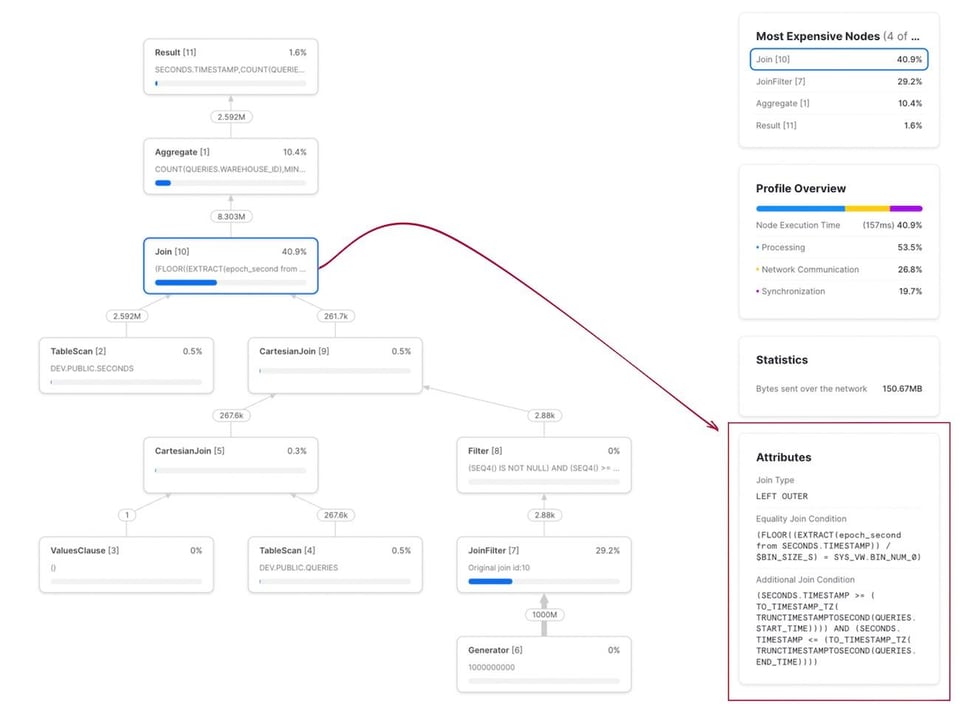
最適なビンサイズの選び方
この手法を成功させるカギは、適切なビンサイズの選択にあります。レンジ結合フィルターが適用される前の中間データセットでの行の爆発を抑えるには、各ビンが含む値の範囲をできるだけ狭くしたいところです。一方で、ビンサイズを小さくしすぎると、「右側のテーブル」(queries)を1ビンあたり1行に展開した際にサイズが大幅に膨らんでしまいます。
Databricksによると、目安は区間長の90パーセンタイルを選ぶことだとされています。この値はapprox_percentile関数とDATEDIFFを組み合わせて算出できます。本記事で使用しているqueriesサンプルデータセットでの値を以下に示します。
select
approx_percentile(datediff('second', start_time, end_time), 0.5) as p50, -- 2s
approx_percentile(datediff('second', start_time, end_time), 0.90) as p90, -- 30s
approx_percentile(datediff('second', start_time, end_time), 0.95) as p95, -- 120s
approx_percentile(datediff('second', start_time, end_time), 0.99) as p99, -- 600s
approx_percentile(datediff('second', start_time, end_time), 0.999) as p999, -- 900s
count(*) -- 267K
from queries
もちろん目安はあくまで目安です。可能であれば複数のビンサイズでクエリをテストし、最もパフォーマンスが良いものを採用してください。下のグラフは、上記クエリにおけるビンサイズ別のパフォーマンス推移です。今回のケースでは、99.9パーセンタイルと90パーセンタイルの間に大きな差は見られませんでした。予想どおり、ビンサイズが極端に小さくなるとクエリ時間は悪化し始めます。
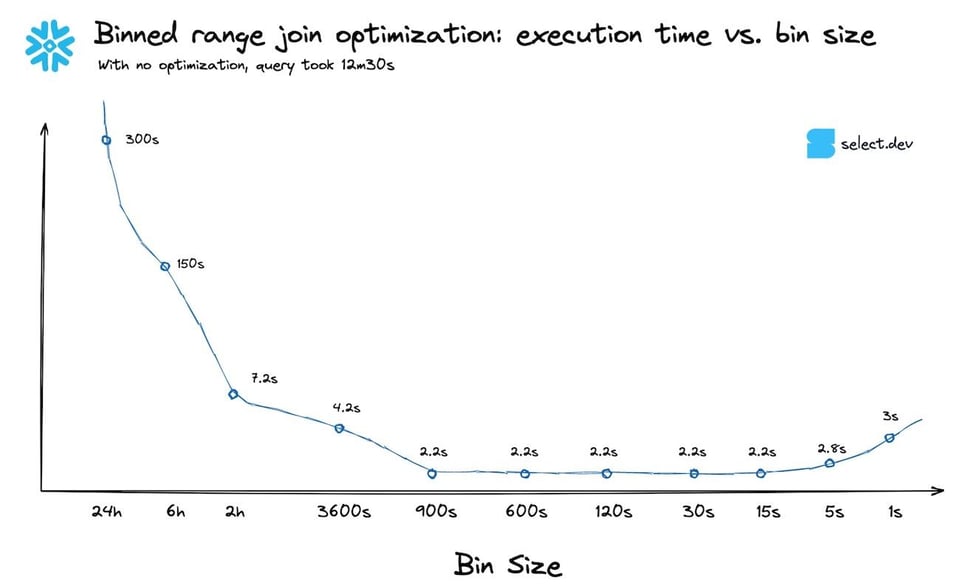
固定区間の結合への応用方法
- 固定区間の point in interval 結合への拡張方法を解説
- ビンサイズは固定区間のサイズに合わせる
先ほど挙げたような、固定区間サイズの point in interval レンジ結合の場合:
select
...
from page_views
inner join events
on events.event_type='purchase' -- フィルター条件
and page_views.pathname = '/' -- フィルター条件
and page_views.user_id=events.user_id -- 等価結合条件
and page_views.viewed_at < events.event_at -- レンジ結合条件
and dateadd('hour', 24, page_views.viewed_at) >= events.event_at -- レンジ結合条件
この場合は、ビンサイズを区間サイズと同じ24時間に設定します。
interval overlap レンジ結合への応用方法
以下のような interval overlap レンジ結合を扱う場合:
select
s1.session_id,
array_agg(s2.session_id) as concurrent_sessions
from landing_page_sessions as s1
inner join app_sessions as s2
on s1.end_time > s2.start_time
and s1.start_time < s2.end_time
group by 1
先ほどqueriesで行ったのと同じ要領で、landing_page_sessionsとapp_sessionsの両方をセッションが含まれる各ビンごとに1行ずつへ展開しておけば、同じビン分割レンジ結合の手法を適用できます。
この最適化を使うべき場面
まず最初に、Snowflakeのクエリプロファイルを使って、レンジ結合が実際にボトルネックになっていること、つまりクエリ実行全体の中で最もコストの高いノードの1つになっていることを確認してください。ビン分割レンジ結合の最適化を加えると、クエリの可読性とメンテナンス性は下がります。
このビン分割レンジ結合の手法が有効なのは、数値型を扱う point in interval 結合と interval overlap 結合に限られます。それ以外の非等価結合には適用できませんが、「可能な限り等価結合の制約を追加して行の爆発を抑える」という考え方自体は応用可能です。
startとend時刻を持つ「右側」のデータセットの区間サイズが比較的均一に分布している場合は、この手法の効果は薄れます。
注釈
この数値は単一のクエリでの結果なので、参考程度に捉えてください。条件次第で結果は大きく変わります。
このアプローチは、2016年に書かれたSimeon Pilgrim氏の記事(当時はまだSnowflakeがsnowflake.netだった頃!)から着想を得たものです。より汎用的なビン分割アプローチを実装するまで、この方法を非常に有効に活用していました。
hoursテーブルへのレンジ結合はsecondsテーブルへのレンジ結合よりはるかに高速です。中間テーブルのサイズが約3600分の1になるためです。このアプローチはDatabricksから着想を得ています。アルゴリズムの実装の詳細までは公開されていませんが、おおむね同様の仕組みで動作していると思われます。
クエリ全体で同じ計算を繰り返さないよう、必要に応じて
get_bin_number関数を作成します。
create or replace function get_bin_number(timestamp timestamp_tz, bin_size_s integer)
returns integer
as
$$
floor(date_part(epoch_second, timestamp) / bin_size_s)
$$
Snowflakeではジェネレーターに計算値を渡せないため、2段階で処理する必要がありました。近いうちに、この処理を抽象化するdbtマクロをオープンソースとして公開する予定です。
ビン分割レンジ結合の最適化クエリの全体例:
create or replace function get_bin_number(timestamp timestamp_tz, bin_size_s integer)
returns integer
as
$$
floor(date_part(epoch_second, timestamp) / bin_size_s)
$$
;
set bin_size_s = 60;
with
metadata as (
select
-- クエリが対象とする時間範囲を取得
min(timestamp) as start_time,
Expand Code
Ian Whitestone・Co-founder & CEO of SELECT
Ianは、SaaS型のSnowflakeコスト管理・最適化プラットフォームであるSELECTのCo-founder兼CEOです。SELECT創業以前は、ShopifyとCapital Oneで6年間にわたりフルスタックのデータサイエンス・エンジニアリングチームを率いてきました。Shopifyでは、データウェアハウスの最適化とコスト可視化の取り組みを牽引しました。