Range joins e outros tipos de non-equi joins são notoriamente lentos na maioria dos bancos de dados. O Snowflake é extremamente rápido na maior parte das consultas, mas também patina quando precisa processar esse tipo de join. Neste post, vamos mostrar uma técnica de otimização que você pode usar para acelerar consultas com range join em até 300x 1.
Antes de entrar na técnica em si, vale revisar os diferentes tipos de join e o que torna os range joins tão lentos no Snowflake. Se você já manja do assunto, fique à vontade para pular direto para a otimização.
Equi-joins versus non-equi joins
Um equi-join é um join com uma condição de igualdade. A maioria das pessoas escreve consultas com uma ou mais condições de equi-join.
select
...
from orders
join customers
on orders.customer_id=customers.id -- exemplo de condição de equi-join
Já um non-equi join é um join com uma condição de desigualdade. Um exemplo seria encontrar uma lista de clientes que compraram o mesmo produto:
select distinct
o1.customer_id,
o2.customer_id,
o1.product_id
from orders_items as o1
join orders_items as o2
on o1.product_id=o2.product_id -- condição de equi-join
and o1.customer_id<>o2.customer_id -- condição de non-equi join
Ou ainda buscar todos os pedidos depois de uma determinada data para cada cliente:
select
...
from orders
inner join customers
on orders.customer_id=customers.id
and orders.created_at > customers.one_year_anniversary_date
O que são range joins?
Um range join é um tipo específico de non-equi join. Ele aparece quando o join verifica se um valor cai dentro de um intervalo (\"point in interval join\") ou quando procura dois períodos que se sobrepõem (\"interval overlap join\").
Point in interval range join
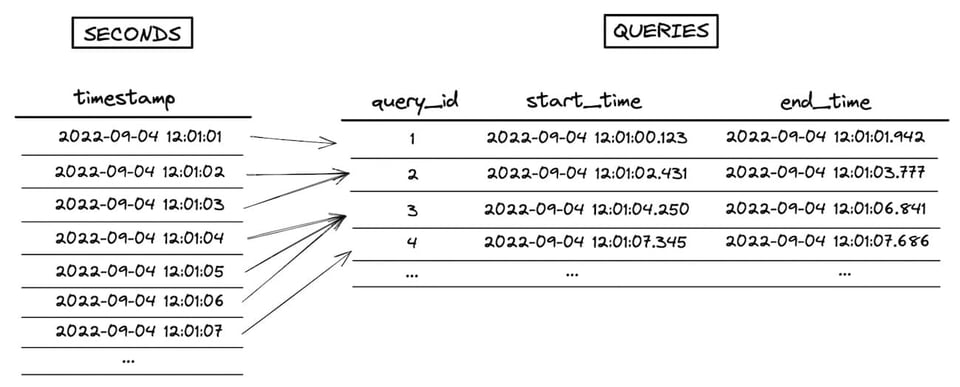
Um exemplo de point in interval range join é calcular quantas queries estão rodando a cada segundo:
select
seconds.timestamp,
count(queries.query_id) as num_queries
from seconds
left join queries
on seconds.timestamp between
date_trunc('second', queries.start_time) and date_trunc('second', queries.end_time)
group by 1
Esse tipo de join também pode usar timestamps derivados. Por exemplo, encontrar todos os eventos de compra que ocorreram em até 24 horas depois de o usuário ver a home page:
select
...
from page_views
inner join events
on events.event_type='purchase' -- condição de filtro
and page_views.pathname = '/' -- condição de filtro
and page_views.user_id=events.user_id -- condição de equi-join
and page_views.viewed_at < events.event_at -- condição de range join
and dateadd('hour', 24, page_views.viewed_at) >= events.event_at -- condição de range join
Interval overlap range join
Os interval overlap range joins acontecem quando uma consulta tenta cruzar períodos que se sobrepõem. Imagine que, para cada sessão de navegação na sua landing page, você precise encontrar todas as outras sessões que rolaram ao mesmo tempo dentro do aplicativo:
select
s1.session_id,
array_agg(s2.session_id) as concurrent_sessions
from landing_page_sessions as s1
inner join app_sessions as s2
on s1.end_time > s2.start_time
and s1.start_time < s2.end_time
group by 1
Por que os range joins são lentos no Snowflake?
Range joins são lentos no Snowflake porque são executados como cartesian joins com uma condição de filtro aplicada depois. Um cartesian join, também chamado de cross join, retorna o produto cartesiano dos registros entre as duas tabelas envolvidas. Se cada tabela tem 10 mil registros, a saída do cartesian join terá 100 milhões de registros! É o que muita gente chama de explosão de join 💥. A execução da consulta fica bem mais lenta quando o Snowflake precisa processar conjuntos intermediários tão grandes.
Vamos usar o exemplo de \"número de queries em execução por segundo\" para explorar isso em mais detalhes.
select
s1.session_id,
array_agg(s2.session_id) as concurrent_sessions
from landing_page_sessions as s1
inner join app_sessions as s2
on s1.end_time > s2.start_time
and s1.start_time < s2.end_time
group by 1
Nossa tabela seconds tem 1 linha por segundo, e a tabela queries tem 1 linha por query. O objetivo da consulta é identificar quais queries estavam rodando a cada segundo e, depois, agregar e contar.
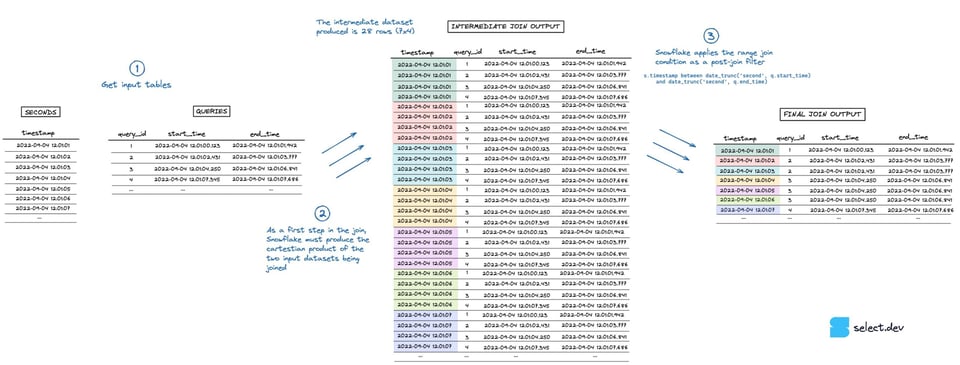
Na hora de executar o join, o Snowflake primeiro monta um conjunto intermediário que é o produto cartesiano das duas tabelas. Neste exemplo, a tabela seconds tem 7 linhas e a tabela queries tem 4, então o conjunto intermediário estoura para 28 linhas. A condição de range join que faz a verificação \"point in interval\" é aplicada depois, como um filtro pós-join. Dá para ver uma visualização desse processo na imagem abaixo (clique aqui para abrir em tela cheia, em alta resolução).
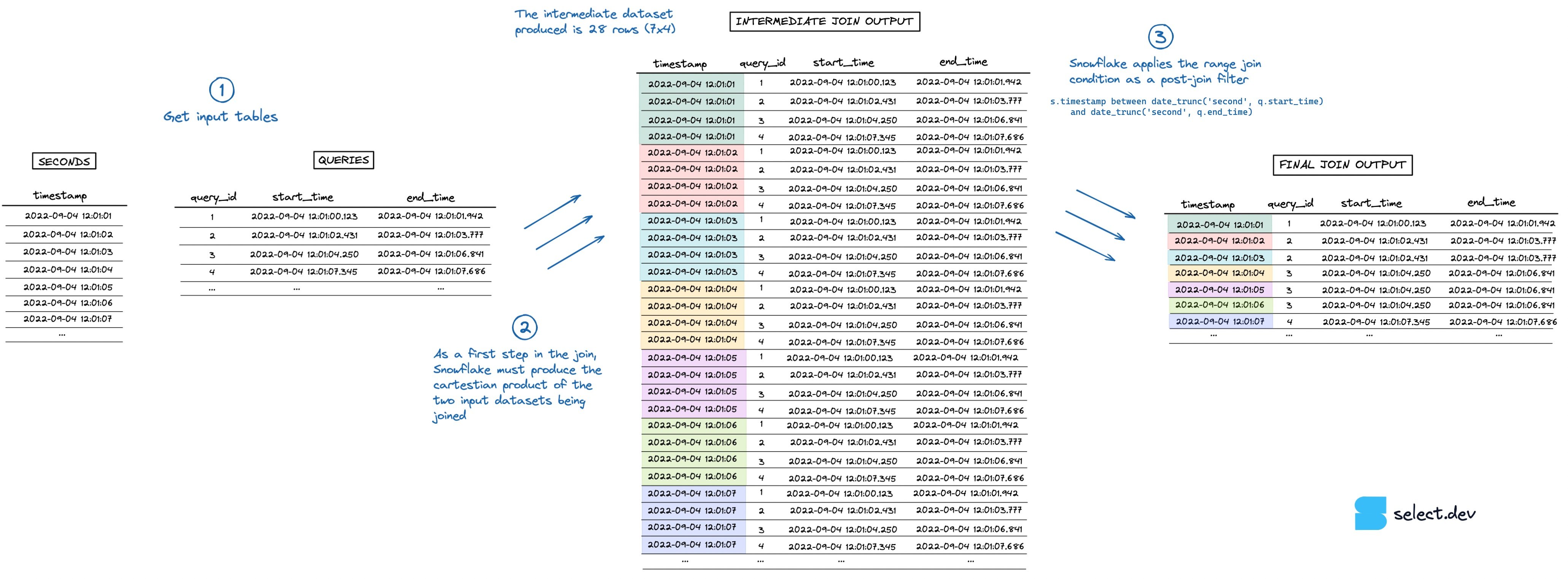{kind=link}
Rodar essa consulta em uma amostra de 30 dias com 267 mil queries levou 12 minutos e 30 segundos. Como mostra o query profile, o join é claramente o gargalo. Você também consegue ver a condição de range join descrita como \"Additional Join Condition\":

Como otimizar range joins no Snowflake
Em um range join, o gargalo para o Snowflake é o volume de dados gerado no conjunto intermediário antes que a condição de range join seja aplicada como filtro pós-join. Para acelerar essas consultas, precisamos reduzir o tamanho desse conjunto intermediário. E uma forma de fazer isso é adicionar uma condição de equi-join, que o Snowflake processa rapidinho via hash join. 2
Reduza a explosão de linhas
A ideia por trás disso é intuitiva — deixar nossos conjuntos de dados menores —, mas a aplicação prática tem suas pegadinhas. Como restringir o conjunto intermediário antes de aplicar o filtro pós-join do range join? Voltando ao exemplo de queries por segundo, é tentador adicionar uma condição de equi-join em algo como a hour de cada timestamp:
select
seconds.timestamp,
count(queries.query_id) as num_queries
from seconds
left join queries
on date_trunc('hour', seconds.timestamp)=date_trunc('hour', queries.start_time) -- NOVO: condição de equi-join
and seconds.timestamp -- condição de range join
between date_trunc('second', queries.start_time) and date_trunc('second', queries.end_time)
group by 1
Parece promissor, mas a abordagem cai por terra quando o intervalo (tempo total de execução da query) ultrapassa 1 hora. Como o equi-join é feito na hora em que a query começou, todos os registros das horas seguintes ficariam de fora da contagem.
Dá para resolver isso criando um conjunto intermediário, query_hours, com 1 linha por query por hora em que a query rodou. Aí passa a ser seguro fazer o join por hour, porque teremos 1 linha para cada hora em que a query esteve ativa. Nenhum registro é descartado sem querer.
with
query_hours as (
select
queries.*,
hours_list.timestamp as query_hour
from queries
inner join hours_list -- conjunto contendo 1 linha por hora
on hours_list.timestamp between date_trunc('hour', queries.start_time) and date_trunc('hour', queries.end_time)
)
select
seconds.timestamp,
count(queries.query_id) as num_queries
from seconds
left join query_hours as queries
on date_trunc('hour', seconds.timestamp)=queries.query_hour -- NOVO: condição de equi-join
Expand Code
Você pode ter notado que a CTE query_hours envolve um range join — isso não vai ser lento também? Quando aplicado nas consultas certas, o tempo extra gasto preparando o conjunto de entrada compensa, e a consulta como um todo fica bem mais rápida
3. Outra preocupação possível: o conjunto query_hours não ficaria muito maior que o queries original, já que ele se expande para 1 linha por query por hora? Como a maioria das queries termina em bem menos de 1 hora, o query_hours acaba tendo um tamanho parecido com o do queries original.
Adicionar a nova condição de equi-join em hours ajuda a acelerar essa consulta de range join, porque limita o tamanho do conjunto intermediário. Mas a abordagem não é ideal por alguns motivos. Talvez hour não seja a melhor escolha, e outra granularidade funcionaria melhor como restrição. Além disso, como estender essa ideia para range joins envolvendo outros tipos numéricos, como inteiros e floats?
Otimização de range join com binning
Dá para estender as ideias acima para uma abordagem mais genérica usando \"bins\" 4.
Ao dizer ao Snowflake para aplicar a condição de range join só em subconjuntos menores dos dados, a operação de join fica muito mais rápida. Para cada timestamp, o Snowflake passa a unir apenas as queries que rodaram na mesma hora, em vez de todas as queries de todo o histórico.
Em vez de ficar preso a intervalos predefinidos como \"hora\", \"minuto\" ou \"dia\", dá para usar bins de tamanho arbitrário. Por exemplo, se a maioria das queries roda em menos de 2 segundos, podemos agrupá-las em bins de 2 segundos cada.
O algoritmo seria mais ou menos assim:
- Gerar os bins e atribuir um número de bin a cada conjunto de dados
- Adicionar a condição de equi-join ao range join usando
bin_num, como fizemos acima comhour. - O conjunto intermediário criado agora fica bem menor.
- Como sempre, o Snowflake aplica o range join como filtro pós-join. Só que, desta vez, muito mais rápido.
Você pode ver uma visualização desse processo na imagem abaixo (clique aqui para abrir em tela cheia, em alta resolução).
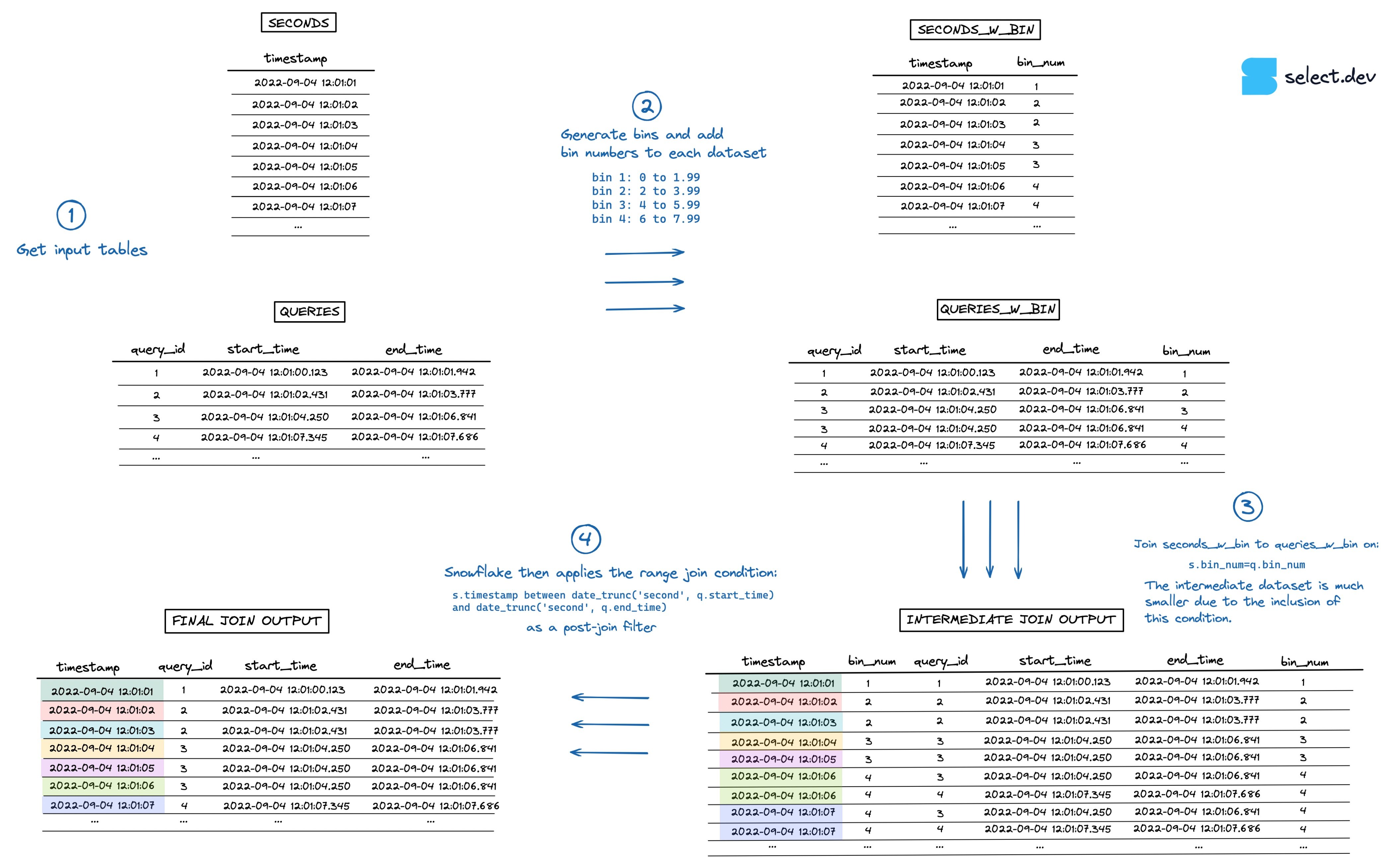{kind=link}
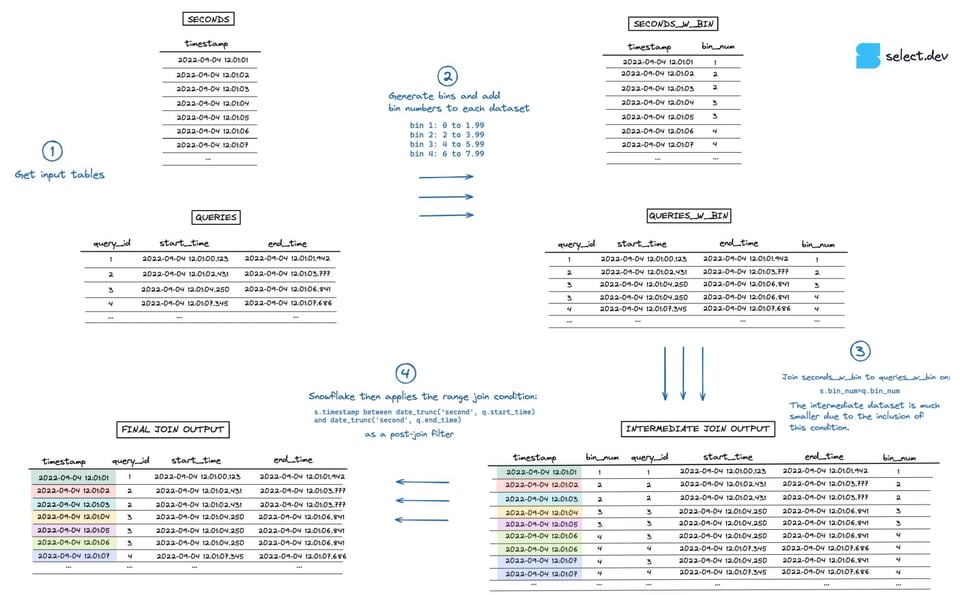
Exemplo de consulta com binned range join
Números de bin são apenas inteiros que representam um intervalo de dados. Uma forma de criá-los é dividir o número pelo tamanho desejado do bin. Com timestamps, dá para primeiro converter o timestamp para unix time, que é um inteiro, e só então dividir:
-- para bins de 60 segundos
select
timestamp,
floor(date_part(epoch_second, timestamp) / 60) as bin_num
Vamos salvar isso em uma função, get_bin_number
5, para não ter que repetir o cálculo o tempo todo.
Seguindo os passos descritos acima, primeiro precisamos gerar a lista de bins aplicáveis. Isso é feito com um generator para criar uma lista de inteiros e, depois, filtrá-la até os números de bin de início e fim desejados 6.
set bin_size_s = 60;
with
metadata as (
select
-- esta seria uma consulta no seu intervalo de tempo desejado
min(timestamp) as start_time,
max(timestamp) as end_time,
get_bin_number(start_time, $bin_size_s) as bin_num_start,
get_bin_number(end_time, $bin_size_s) as bin_num_end
from seconds
),
-- precisa de uma CTE com 1 linha entre bin_num_start e bin_num_end
-- é preciso primeiro gerar uma lista enorme e depois filtrar, porque não dá para passar valores calculados
-- quando bins_base é 1 trilhão leva 5 segundos para filtrar. 106 ms para 1 milhão
Expand Code
Agora dá para adicionar o número de bin a cada conjunto de dados. Para o queries, vamos gerar um conjunto com 1 linha por query por bin em que a query rodou. Para o seconds, cada timestamp será mapeado para um único bin.
queries_w_bin_number as (
select
start_time,
end_time,
warehouse_id,
cluster_number,
bins.bin_num
from queries
inner join bins
on bins.bin_num between
get_bin_number(queries.start_time, $bin_size_s) and get_bin_number(queries.end_time, $bin_size_s)
),
seconds_w_bin_number as (
select
timestamp,
Expand Code
E aplicamos a condição de join final, com a condição extra de equi-join em bin_num:
select
s.timestamp,
count(q.warehouse_id) as num_queries
from seconds_w_bin_number as s
left join queries_w_bin_number as q
on s.bin_num=q.bin_num
and s.timestamp between date_trunc('second', q.start_time) and date_trunc('second', q.end_time)
group by 1
Usando o mesmo conjunto de dados, essa consulta{% superscript id=7 /%} rodou em 2,2 segundos, enquanto a versão não otimizada levou 750 segundos. É uma melhoria de mais de 300x. O query profile aparece abaixo. Repare que a condição de join agora aparece em duas seções: uma para o equi-join em bin_num e outra para a condição de range join.
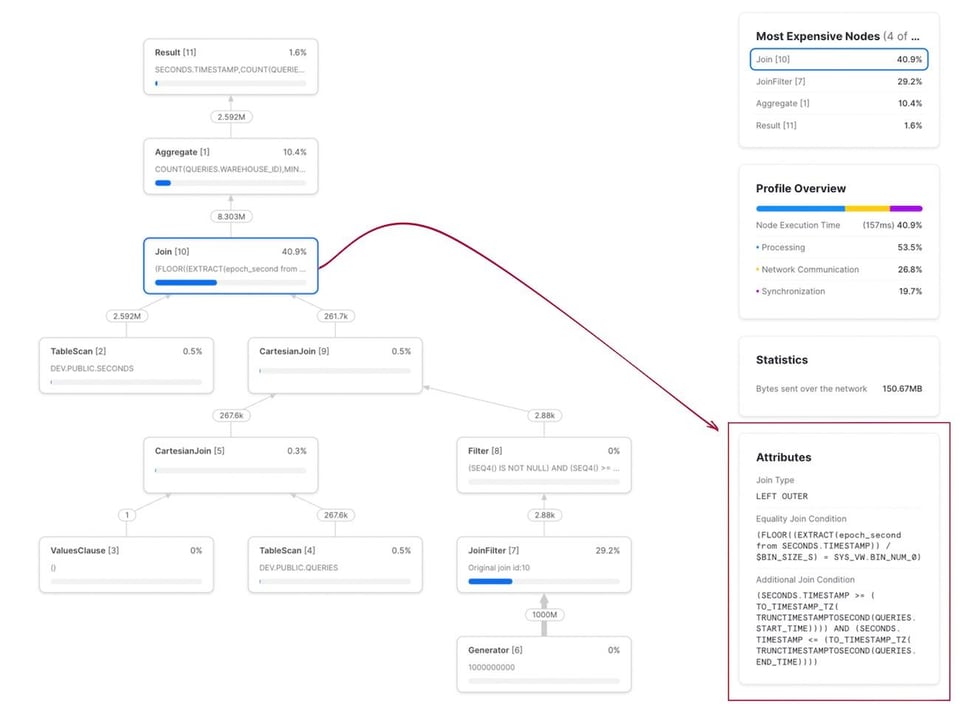
Escolhendo o tamanho certo de bin
Uma parte essencial dessa estratégia é escolher o tamanho certo de bin. Cada bin precisa cobrir um intervalo pequeno de valores, para minimizar a explosão de linhas no conjunto intermediário antes do filtro de range join. Por outro lado, se o bin for pequeno demais, a sua \"tabela à direita\" (queries) cresce muito ao se expandir para 1 linha por bin.
Segundo o Databricks, uma boa regra prática é usar o percentil 90 da duração dos seus intervalos. Você calcula isso com a função approx_percentile junto com DATEDIFF. Abaixo estão os valores para o conjunto queries que venho usando ao longo do post.
select
approx_percentile(datediff('second', start_time, end_time), 0.5) as p50, -- 2s
approx_percentile(datediff('second', start_time, end_time), 0.90) as p90, -- 30s
approx_percentile(datediff('second', start_time, end_time), 0.95) as p95, -- 120s
approx_percentile(datediff('second', start_time, end_time), 0.99) as p99, -- 600s
approx_percentile(datediff('second', start_time, end_time), 0.999) as p999, -- 900s
count(*) -- 267K
from queries
Regras práticas não são infalíveis. Se der, teste sua consulta com alguns tamanhos diferentes de bin e veja o que entrega o melhor desempenho. Abaixo está a curva de desempenho para a consulta acima, com diferentes tamanhos de bin. Neste caso, escolher o percentil 99,9 em vez do percentil 90 fez pouca diferença. Como esperado, os tempos de consulta pioram quando o bin fica pequeno demais.
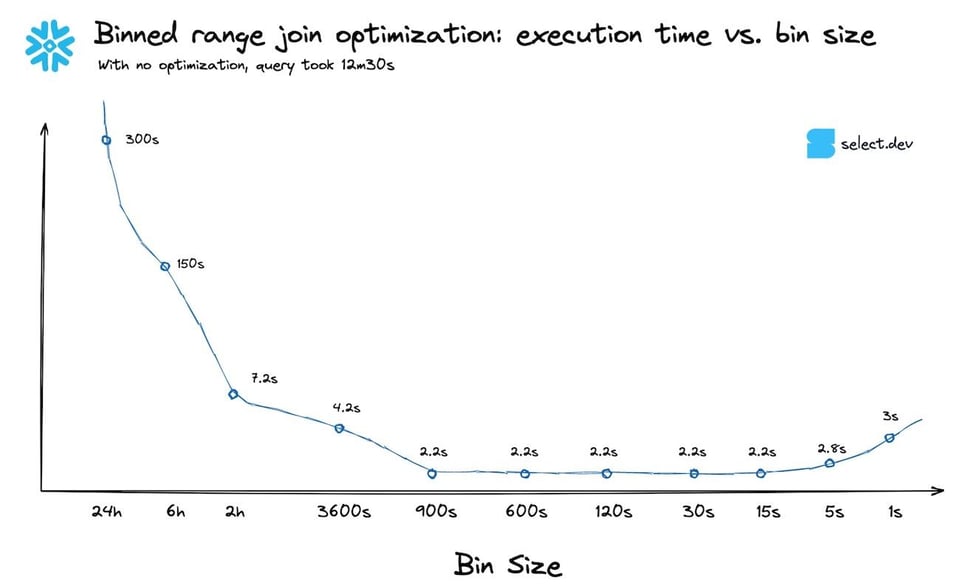
Como estender para um join com intervalo fixo?
- Explicar como aplicar a técnica a um point in interval join com intervalo fixo
- O tamanho do bin seria definido como o tamanho do intervalo fixo
Se você tem um point in interval range join com intervalo fixo, como a consulta que vimos antes:
select
...
from page_views
inner join events
on events.event_type='purchase' -- condição de filtro
and page_views.pathname = '/' -- condição de filtro
and page_views.user_id=events.user_id -- condição de equi-join
and page_views.viewed_at < events.event_at -- condição de range join
and dateadd('hour', 24, page_views.viewed_at) >= events.event_at -- condição de range join
Basta definir o tamanho do bin igual ao tamanho do intervalo: 24 horas.
Como estender para um interval overlap range join?
Se você está lidando com um interval overlap range join, como o exemplo abaixo:
select
s1.session_id,
array_agg(s2.session_id) as concurrent_sessions
from landing_page_sessions as s1
inner join app_sessions as s2
on s1.end_time > s2.start_time
and s1.start_time < s2.end_time
group by 1
É só aplicar a mesma técnica de binned range join depois de expandir tanto landing_page_sessions quanto app_sessions para que cada uma contenha 1 linha por sessão por bin em que a sessão se encaixa (como fizemos com queries acima).
Quando vale a pena usar essa otimização?
Como primeiro passo, confirme que o range join é mesmo um gargalo usando o query profile do Snowflake para verificar se ele está entre os nós mais custosos da execução. Adicionar a otimização de binned range join deixa as consultas mais difíceis de entender e manter.
A técnica só funciona para point in interval e interval overlap range joins envolvendo tipos numéricos. Ela não vai funcionar para outros tipos de non-equi joins, mas você pode aplicar o mesmo princípio de tentar adicionar uma restrição de equi-join sempre que possível para reduzir a explosão de linhas.
Se o conjunto à \"direita\", com os tempos start e end, tiver uma distribuição relativamente uniforme de tamanhos de intervalo, a técnica não será tão eficaz.
Notas
Esse número vem de uma única consulta, então olhe com um certo ceticismo. O seu resultado vai variar conforme uma série de fatores.
Essa abordagem foi inspirada no post do Simeon Pilgrim de 2016 (na época em que o Snowflake ainda era snowflake.net!). Usei essa técnica com bastante sucesso até implementar a abordagem mais genérica com binning.
O range join com a tabela
hoursé muito mais rápido do que com a tabelaseconds, porque a tabela intermediária fica cerca de 3600 vezes menor.Essa abordagem foi inspirada no Databricks. Eles não detalham como o algoritmo é implementado, mas imagino que funcione de forma parecida.
Se quiser, crie uma função
get_bin_numberpara não ter que repetir o mesmo cálculo ao longo da consulta:
create or replace function get_bin_number(timestamp timestamp_tz, bin_size_s integer)
returns integer
as
$$
floor(date_part(epoch_second, timestamp) / bin_size_s)
$$
O Snowflake não permite passar valores calculados para o generator, então foi preciso fazer isso em duas etapas. Em breve, vamos liberar alguns macros dbt em open source para abstrair esse processo.
A consulta completa com o exemplo de otimização de binned range join:
create or replace function get_bin_number(timestamp timestamp_tz, bin_size_s integer)
returns integer
as
$$
floor(date_part(epoch_second, timestamp) / bin_size_s)
$$
;
set bin_size_s = 60;
with
metadata as (
select
-- Obtenha o intervalo de tempo que sua consulta vai abranger
min(timestamp) as start_time,
Expand Code
Ian Whitestone·Co-founder & CEO da SELECT
Ian é Co-founder & CEO da SELECT, uma plataforma SaaS de gerenciamento e otimização de custos do Snowflake. Antes de fundar a SELECT, Ian passou 6 anos liderando times full stack de data science & engineering na Shopify e na Capital One. Na Shopify, Ian liderou os esforços para otimizar o data warehouse e aumentar a observabilidade de custos.