Les range joins et autres non-equi joins sont réputés pour leur lenteur dans la plupart des bases de données. Snowflake a beau être ultra-rapide sur la majorité des requêtes, il pâtit lui aussi de performances médiocres face à ce type de jointures. Dans cet article, nous présentons une technique d'optimisation permettant d'accélérer jusqu'à 300x les requêtes impliquant un range join 1.
Avant d'aborder la technique elle-même, revenons sur les différents types de jointures et sur ce qui rend les range joins si lents dans Snowflake. Si ces notions vous sont déjà familières, passez directement à la suite.
Equi-joins et non-equi joins
Un equi-join est une jointure reposant sur une condition d'égalité. La plupart des utilisateurs écrivent des requêtes comportant une ou plusieurs conditions d'equi-join.
select
...
from orders
join customers
on orders.customer_id=customers.id -- exemple de condition d'equi-join
Un non-equi join est une jointure reposant sur une condition d'inégalité. On peut par exemple chercher la liste des clients ayant acheté le même produit :
select distinct
o1.customer_id,
o2.customer_id,
o1.product_id
from orders_items as o1
join orders_items as o2
on o1.product_id=o2.product_id -- condition d'equi-join
and o1.customer_id<>o2.customer_id -- condition de non-equi join
Ou encore identifier toutes les commandes passées après une date donnée pour chaque client :
select
...
from orders
inner join customers
on orders.customer_id=customers.id
and orders.created_at > customers.one_year_anniversary_date
Qu'est-ce qu'un range join ?
Un range join est un type particulier de non-equi join. Il intervient lorsqu'une jointure vérifie si une valeur se situe dans un certain intervalle (\"point in interval join\"), ou lorsqu'elle cherche deux périodes qui se chevauchent (\"interval overlap join\").
Point in interval range join
Un exemple de point in interval range join : calculer le nombre de requêtes en cours d'exécution à chaque seconde.
select
seconds.timestamp,
count(queries.query_id) as num_queries
from seconds
left join queries
on seconds.timestamp between
date_trunc('second', queries.start_time) and date_trunc('second', queries.end_time)
group by 1
Cette jointure peut aussi s'appuyer sur des timestamps dérivés. Par exemple, retrouver tous les événements d'achat survenus dans les 24 heures suivant la consultation de la page d'accueil par un utilisateur :
select
...
from page_views
inner join events
on events.event_type='purchase' -- condition de filtrage
and page_views.pathname = '/' -- condition de filtrage
and page_views.user_id=events.user_id -- condition d'equi-join
and page_views.viewed_at < events.event_at -- condition de range join
and dateadd('hour', 24, page_views.viewed_at) >= events.event_at -- condition de range join
Interval overlap range join
Les interval overlap range joins interviennent lorsqu'une requête cherche à faire correspondre des périodes qui se chevauchent. Imaginons que pour chaque session de navigation sur votre site vitrine, vous deviez retrouver toutes les autres sessions ayant eu lieu au même moment dans votre application :
select
s1.session_id,
array_agg(s2.session_id) as concurrent_sessions
from landing_page_sessions as s1
inner join app_sessions as s2
on s1.end_time > s2.start_time
and s1.start_time < s2.end_time
group by 1
Pourquoi les range joins sont-ils lents dans Snowflake ?
Les range joins sont lents dans Snowflake car ils sont exécutés comme des jointures cartésiennes assorties d'un filtre appliqué a posteriori. Une jointure cartésienne, ou cross join, renvoie le produit cartésien des enregistrements entre les deux jeux de données joints. Si chaque table contient 10 000 lignes, le résultat de la jointure cartésienne comptera 100 millions de lignes ! On parle souvent d'explosion de jointure 💥. L'exécution de la requête peut être considérablement ralentie lorsque Snowflake doit traiter ces très grands jeux de données intermédiaires.
Reprenons l'exemple du \"nombre de requêtes exécutées par seconde\" pour creuser le sujet.
select
s1.session_id,
array_agg(s2.session_id) as concurrent_sessions
from landing_page_sessions as s1
inner join app_sessions as s2
on s1.end_time > s2.start_time
and s1.start_time < s2.end_time
group by 1
Notre table seconds contient 1 ligne par seconde, et la table queries contient 1 ligne par requête. L'objectif est d'identifier les requêtes qui s'exécutaient à chaque seconde, puis d'agréger et de compter.
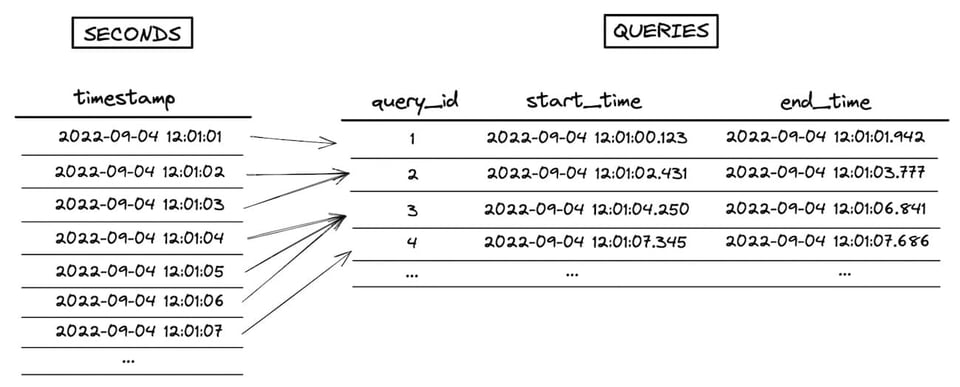
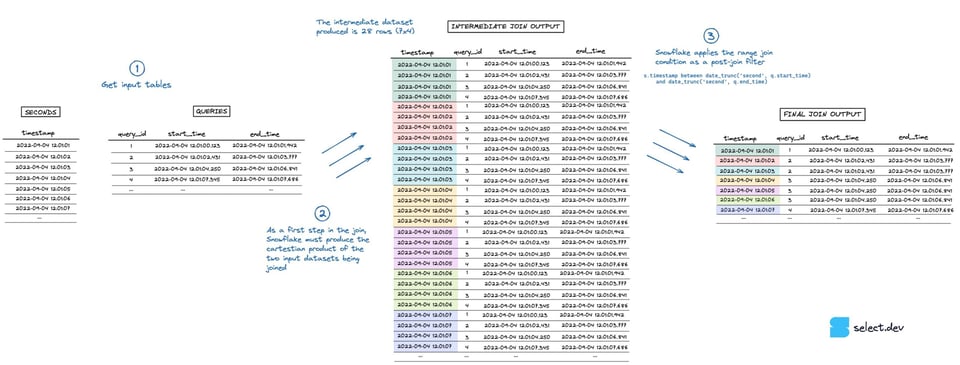
Lors de l'exécution de la jointure, Snowflake crée d'abord un jeu de données intermédiaire correspondant au produit cartésien des deux jeux joints. Ici, la table seconds compte 7 lignes et la table queries 4 lignes : le jeu intermédiaire explose donc à 28 lignes. La condition de range join qui effectue la vérification \"point in interval\" intervient ensuite, en tant que filtre post-jointure. La visualisation ci-dessous illustre ce processus (cliquez ici pour la version plein écran en haute résolution).
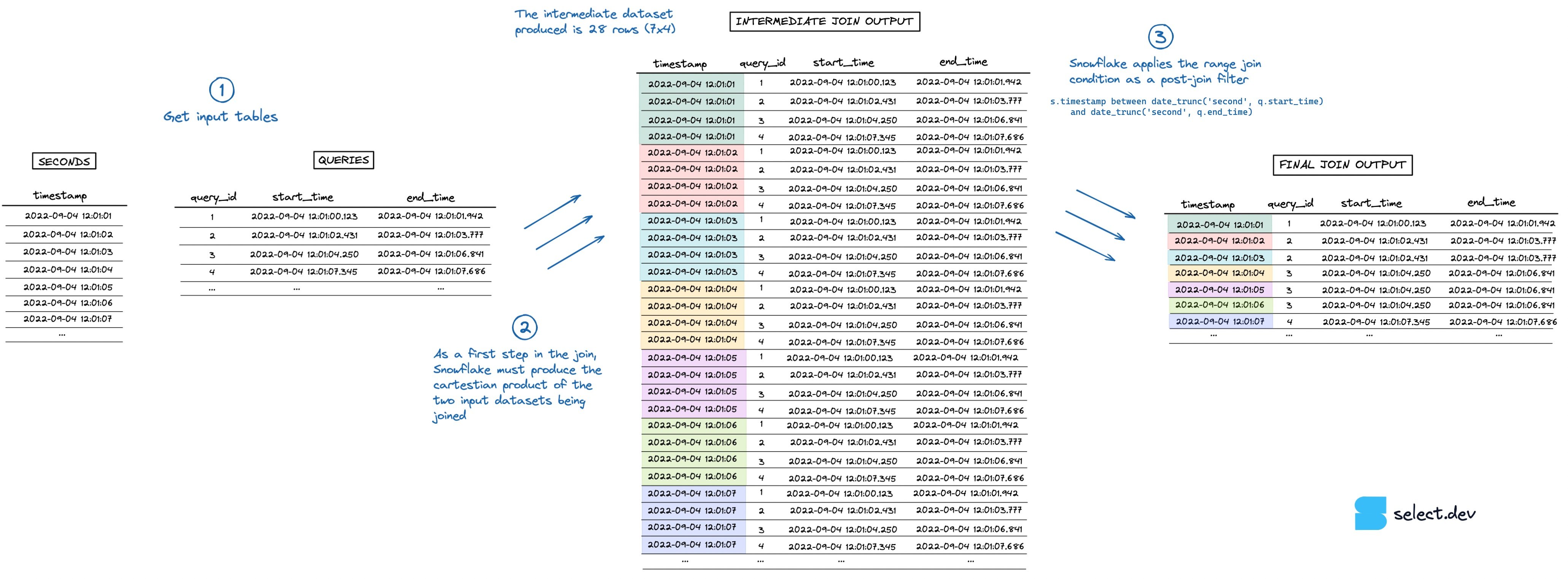{kind=link}
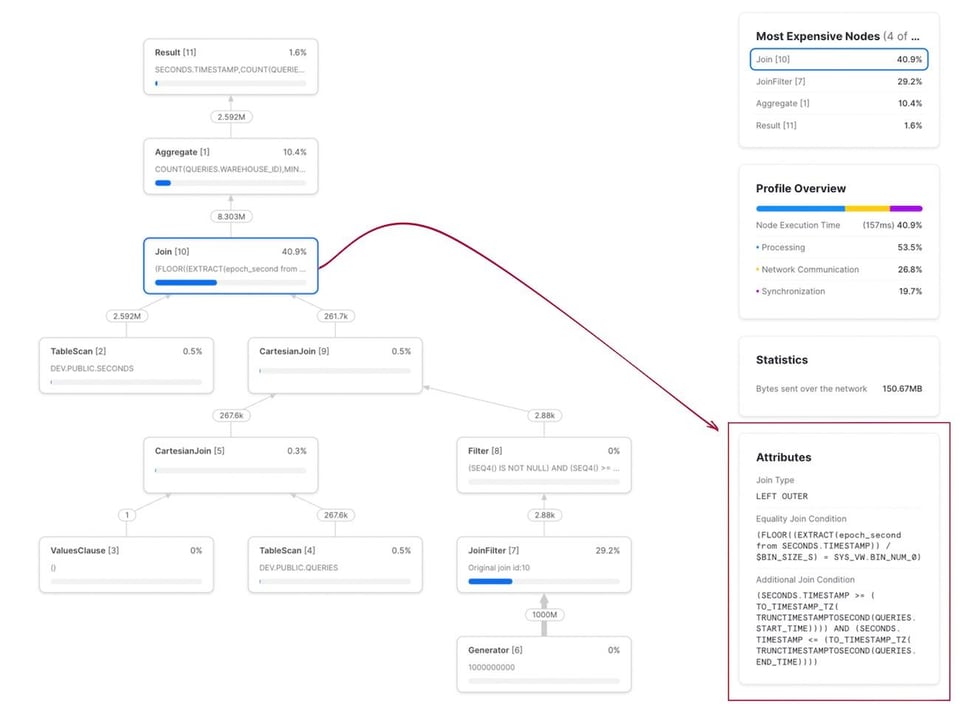
Exécutée sur un échantillon de 30 jours de données comportant 267 000 requêtes, cette requête a mis 12 minutes et 30 secondes. Comme le montre le query profile, la jointure est clairement le goulot d'étranglement. La condition de range join y apparaît sous l'intitulé \"Additional Join Condition\" :

Comment optimiser les range joins dans Snowflake
Lors de l'exécution d'un range join, le goulot d'étranglement pour Snowflake réside dans le volume de données du jeu intermédiaire, généré avant que la condition de range join ne soit appliquée en filtre post-jointure. Pour accélérer ces requêtes, il faut donc trouver un moyen de réduire la taille de ce jeu intermédiaire. On y parvient en ajoutant une condition d'equi-join, que Snowflake traite très rapidement via une hash join. 2
Limiter l'explosion du nombre de lignes
Le principe est intuitif — réduire la taille des jeux de données — mais sa mise en pratique reste délicate. Comment limiter le jeu intermédiaire avant l'application du filtre post-jointure du range join ? En reprenant l'exemple du nombre de requêtes par seconde, on serait tenté d'ajouter une condition d'equi-join sur l'hour de chaque timestamp :
select
seconds.timestamp,
count(queries.query_id) as num_queries
from seconds
left join queries
on date_trunc('hour', seconds.timestamp)=date_trunc('hour', queries.start_time) -- NOUVEAU : condition d'equi-join
and seconds.timestamp -- condition de range join
between date_trunc('second', queries.start_time) and date_trunc('second', queries.end_time)
group by 1
L'approche est séduisante, mais elle s'effondre dès que l'intervalle (durée totale d'exécution de la requête) dépasse 1 heure. Comme l'equi-join porte sur l'heure de démarrage de la requête, aucun enregistrement des heures suivantes ne serait comptabilisé.
Pour résoudre ce problème, on peut créer un jeu de données intermédiaire, query_hours, contenant 1 ligne par requête et par heure d'exécution. Il devient alors possible de joindre sur hour en toute sécurité, puisqu'on a 1 ligne pour chaque heure d'exécution. Aucun enregistrement n'est laissé de côté par inadvertance.
with
query_hours as (
select
queries.*,
hours_list.timestamp as query_hour
from queries
inner join hours_list -- jeu de données contenant 1 ligne par heure
on hours_list.timestamp between date_trunc('hour', queries.start_time) and date_trunc('hour', queries.end_time)
)
select
seconds.timestamp,
count(queries.query_id) as num_queries
from seconds
left join query_hours as queries
on date_trunc('hour', seconds.timestamp)=queries.query_hour -- NOUVEAU : condition d'equi-join
Développer le code
Vous aurez sans doute remarqué que la CTE query_hours implique elle-même un range join — ne va-t-il pas être lent ? Appliqué aux bonnes requêtes, le temps supplémentaire consacré à la préparation du jeu d'entrée se traduit par une requête globalement bien plus rapide
3. Autre interrogation possible : le jeu query_hours ne risque-t-il pas de devenir nettement plus volumineux que le queries initial, puisqu'il se déploie à 1 ligne par requête et par heure ? La plupart des requêtes s'achevant largement en moins d'une heure, le jeu query_hours aura en réalité une taille similaire à celle du jeu queries d'origine.
Ajouter cette nouvelle condition d'equi-join sur hour permet d'accélérer la requête de range join en limitant la taille du jeu intermédiaire. Cette approche n'est toutefois pas idéale pour plusieurs raisons. hour n'est peut-être pas le meilleur choix, et une autre contrainte pourrait s'avérer plus pertinente. Par ailleurs, comment l'étendre à des range joins portant sur d'autres types numériques, comme des entiers ou des flottants ?
Optimisation des range joins par binning
On peut généraliser les idées précédentes grâce à l'utilisation de bins 4.
En indiquant à Snowflake de n'appliquer la condition de range join que sur de plus petits sous-ensembles de données, l'opération de jointure devient bien plus rapide. Pour chaque timestamp, Snowflake ne joint désormais que les requêtes ayant tourné durant la même heure, au lieu de la totalité des requêtes.
Plutôt que de se limiter à des plages prédéfinies comme \"hour\", \"minute\" ou \"day\", on peut utiliser des bins de taille arbitraire. Par exemple, si la plupart des requêtes s'exécutent en moins de 2 secondes, on peut les regrouper dans des bins couvrant 2 secondes chacun.
L'algorithme se présente comme suit :
- Générer les bins et ajouter les numéros de bin à chaque jeu de données.
- Ajouter la contrainte d'equi-join au range join via
bin_num, à l'image de ce qui a été fait plus haut avechour. - Le jeu de données intermédiaire est désormais bien plus petit.
- Comme à l'accoutumée, Snowflake applique le range join en filtre post-jointure. Cette fois, beaucoup plus rapidement.
La visualisation ci-dessous illustre ce processus (cliquez ici pour la version plein écran en haute résolution).
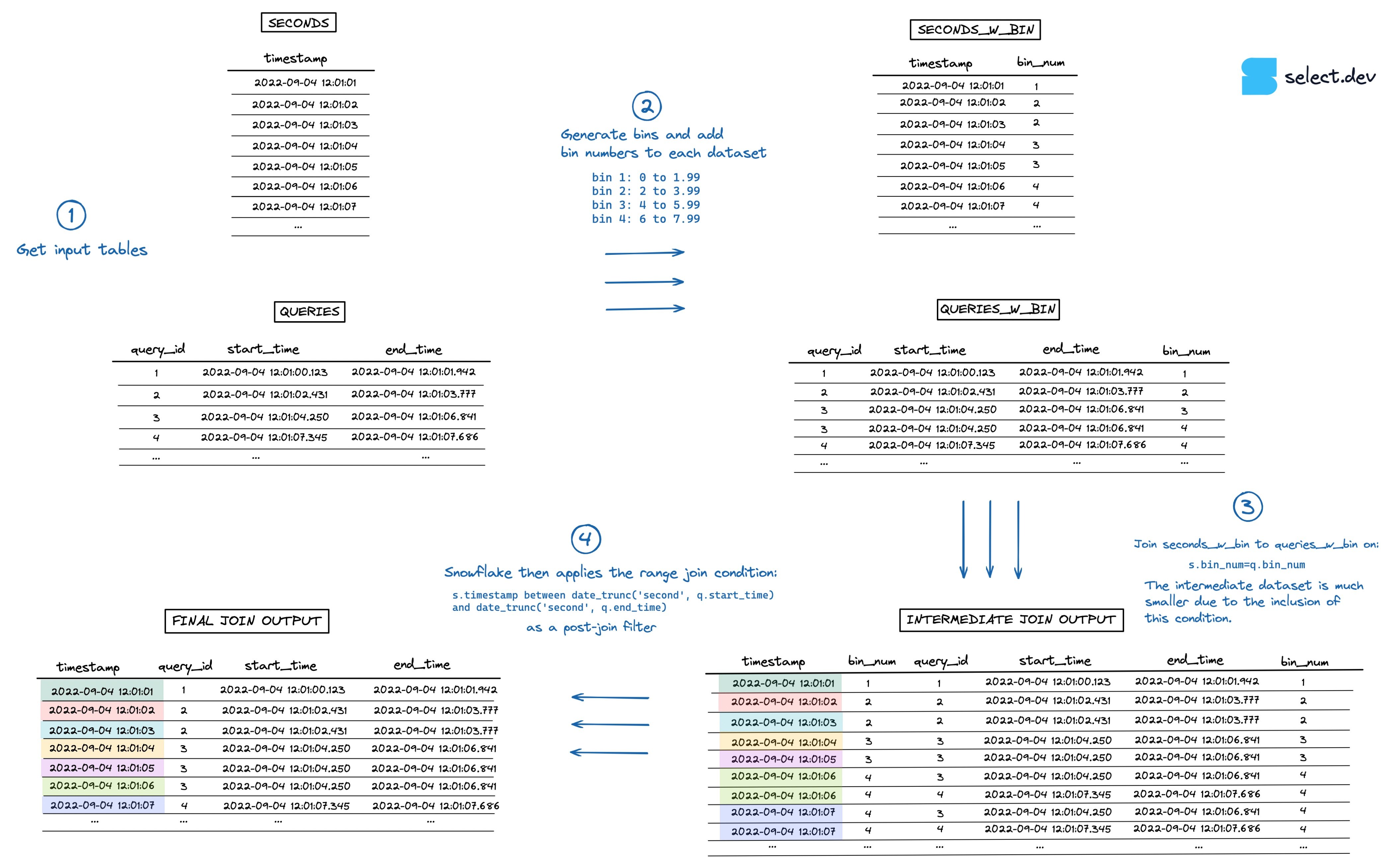{kind=link}
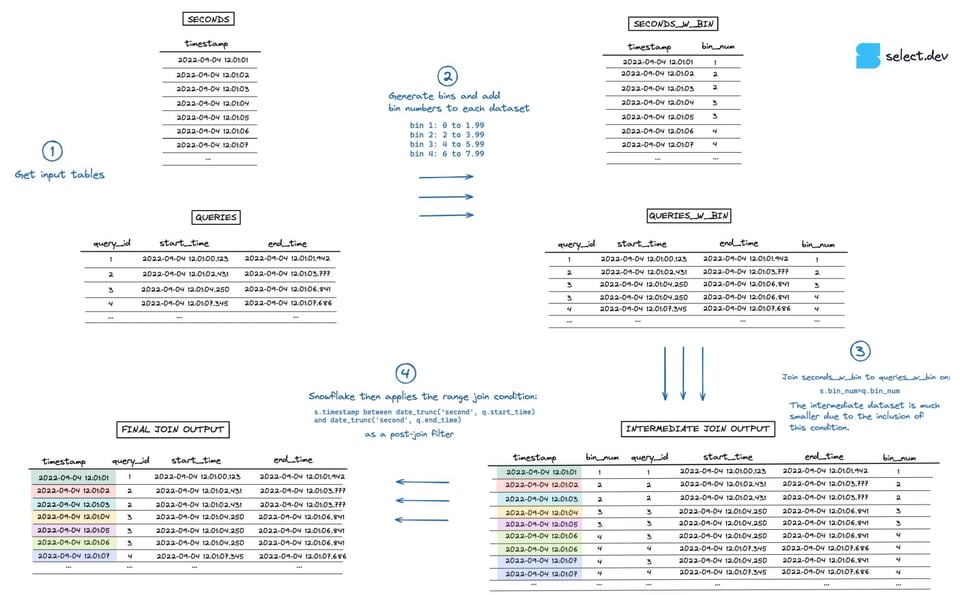
Exemple de requête de range join avec binning
Les numéros de bin ne sont que des entiers représentant une plage de données. Une façon de les créer consiste à diviser le nombre par la taille de bin souhaitée. Pour les timestamps, on peut d'abord convertir le timestamp en temps unix, qui est un entier, avant d'effectuer la division :
-- pour des bins de 60 secondes
select
timestamp,
floor(date_part(epoch_second, timestamp) / 60) as bin_num
Encapsulons cela dans une fonction, get_bin_number
5, pour éviter de la répéter à chaque fois.
En suivant les étapes décrites plus haut, il faut d'abord générer la liste des bins applicables. On utilise pour cela un générateur qui produit une liste d'entiers, puis on la filtre pour ne conserver que les numéros de bin de début et de fin souhaités 6.
set bin_size_s = 60;
with
metadata as (
select
-- ceci serait une requête sur la plage de temps souhaitée
min(timestamp) as start_time,
max(timestamp) as end_time,
get_bin_number(start_time, $bin_size_s) as bin_num_start,
get_bin_number(end_time, $bin_size_s) as bin_num_end
from seconds
),
-- il faut une CTE avec 1 ligne entre bin_num_start et bin_num_end
-- il faut d'abord générer une liste massive, puis filtrer, car on ne peut pas passer de valeurs calculées
-- avec bins_base à 1 000 milliards, le filtrage prend 5 secondes. 106 ms pour 1 million
Développer le code
On peut maintenant ajouter le numéro de bin à chaque jeu de données. Pour le jeu queries, on produit un jeu contenant 1 ligne par requête et par bin durant lequel la requête s'est exécutée. Pour le jeu seconds, chaque timestamp sera associé à un unique bin.
queries_w_bin_number as (
select
start_time,
end_time,
warehouse_id,
cluster_number,
bins.bin_num
from queries
inner join bins
on bins.bin_num between
get_bin_number(queries.start_time, $bin_size_s) and get_bin_number(queries.end_time, $bin_size_s)
),
seconds_w_bin_number as (
select
timestamp,
Développer le code
Il ne reste plus qu'à appliquer la condition de jointure finale, avec la condition d'equi-join supplémentaire sur bin_num :
select
s.timestamp,
count(q.warehouse_id) as num_queries
from seconds_w_bin_number as s
left join queries_w_bin_number as q
on s.bin_num=q.bin_num
and s.timestamp between date_trunc('second', q.start_time) and date_trunc('second', q.end_time)
group by 1
Sur le même jeu de données qu'auparavant, cette requête{% superscript id=7 /%} s'est exécutée en 2,2 secondes, contre 750 secondes pour la version non optimisée. Soit une amélioration de plus de 300x. Le query profile correspondant est présenté ci-dessous. Remarquez que la condition de jointure affiche désormais deux sections : l'une pour la condition d'equi-join sur bin_num, l'autre pour la condition de range join.
Choisir la bonne taille de bin
Le choix de la taille de bin est un élément clé pour faire fonctionner cette stratégie. Chaque bin doit couvrir une petite plage de valeurs afin de limiter l'explosion du nombre de lignes dans le jeu intermédiaire avant l'application du filtre du range join. En revanche, si la taille choisie est trop petite, votre \"table de droite\" (queries) gonflera fortement une fois déployée à 1 ligne par bin.
Selon Databricks, une bonne règle empirique consiste à retenir le 90e percentile de la durée des intervalles. On peut le calculer avec la fonction approx_percentile combinée à DATEDIFF. Voici les valeurs obtenues sur l'échantillon queries utilisé tout au long de cet article.
select
approx_percentile(datediff('second', start_time, end_time), 0.5) as p50, -- 2s
approx_percentile(datediff('second', start_time, end_time), 0.90) as p90, -- 30s
approx_percentile(datediff('second', start_time, end_time), 0.95) as p95, -- 120s
approx_percentile(datediff('second', start_time, end_time), 0.99) as p99, -- 600s
approx_percentile(datediff('second', start_time, end_time), 0.999) as p999, -- 900s
count(*) -- 267K
from queries
Les règles empiriques ne sont pas parfaites. Si possible, testez votre requête avec plusieurs tailles de bin pour identifier celle qui offre les meilleures performances. Voici la courbe de performance de la requête ci-dessus, pour différentes tailles de bin. Dans ce cas, retenir le 99,9e percentile plutôt que le 90e n'a pas changé grand-chose. Comme on pouvait s'y attendre, les temps de requête se sont dégradés dès que la taille de bin est devenue trop petite.
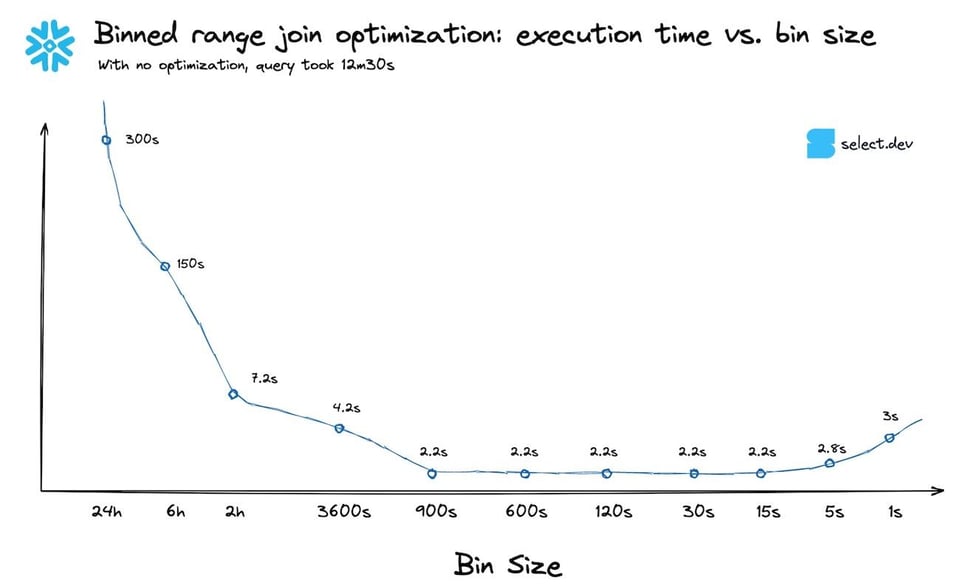
Comment étendre cette technique à une jointure avec intervalle fixe ?
- Expliquer comment étendre cette approche à un point in interval join à intervalle fixe
- La taille de bin serait fixée à la taille de l'intervalle
Si vous avez un point in interval range join avec une taille d'intervalle fixe, comme la requête présentée plus haut :
select
...
from page_views
inner join events
on events.event_type='purchase' -- condition de filtrage
and page_views.pathname = '/' -- condition de filtrage
and page_views.user_id=events.user_id -- condition d'equi-join
and page_views.viewed_at < events.event_at -- condition de range join
and dateadd('hour', 24, page_views.viewed_at) >= events.event_at -- condition de range join
Calez alors la taille de bin sur celle de l'intervalle : 24 heures.
Comment étendre la technique à un interval overlap range join ?
Si vous avez affaire à un interval overlap range join, comme celui ci-dessous :
select
s1.session_id,
array_agg(s2.session_id) as concurrent_sessions
from landing_page_sessions as s1
inner join app_sessions as s2
on s1.end_time > s2.start_time
and s1.start_time < s2.end_time
group by 1
Vous pouvez appliquer la même technique de range join avec binning, après avoir déployé landing_page_sessions et app_sessions de manière à ce qu'elles contiennent 1 ligne par session et par bin couvert par la session (comme nous l'avons fait plus haut avec queries).
Quand utiliser cette optimisation ?
Première étape : vérifiez que le range join constitue bien un goulot d'étranglement, en utilisant le query profile de Snowflake pour confirmer qu'il s'agit de l'un des nœuds les plus coûteux de l'exécution. L'optimisation par binning rend en effet les requêtes plus difficiles à lire et à maintenir.
Cette technique ne fonctionne que pour les point in interval et interval overlap range joins portant sur des types numériques. Elle ne s'applique pas aux autres non-equi joins, même si le principe — ajouter une contrainte d'equi-join chaque fois que possible pour limiter l'explosion du nombre de lignes — reste pertinent.
Si le jeu de données \"de droite\", contenant les start et end times, présente une distribution relativement uniforme des durées d'intervalle, cette technique perdra en efficacité.
Notes
Ce chiffre provient d'une seule requête : à prendre avec des pincettes. Les résultats varient selon de nombreux facteurs.
Cette approche s'inspire de l'article de Simeon Pilgrim publié en 2016 (à l'époque où Snowflake s'appelait encore snowflake.net !). Je l'ai utilisée avec succès pendant un certain temps avant d'adopter l'approche par binning, plus générique.
Le range join vers la table
hourssera bien plus rapide que celui vers la tableseconds, la table intermédiaire étant environ 3 600 fois plus petite.Cette approche s'inspire de Databricks. Ils n'entrent pas dans les détails d'implémentation de leur algorithme, mais je suppose qu'il fonctionne de manière similaire.
Créez éventuellement une fonction
get_bin_numberpour éviter de recopier le même calcul à plusieurs endroits :
create or replace function get_bin_number(timestamp timestamp_tz, bin_size_s integer)
returns integer
as
$$
floor(date_part(epoch_second, timestamp) / bin_size_s)
$$
Snowflake ne permet pas de passer de valeurs calculées au générateur ; il a donc fallu procéder en deux étapes. Nous publierons très prochainement en open source des macros dbt pour masquer cette mécanique.
Exemple complet de requête de range join optimisée par binning :
create or replace function get_bin_number(timestamp timestamp_tz, bin_size_s integer)
returns integer
as
$$
floor(date_part(epoch_second, timestamp) / bin_size_s)
$$
;
set bin_size_s = 60;
with
metadata as (
select
-- Récupère la plage de temps couverte par la requête
min(timestamp) as start_time,
Développer le code
Ian Whitestone·Co-founder & CEO of SELECT
Ian est Co-founder & CEO de SELECT, une plateforme SaaS de gestion et d'optimisation des coûts Snowflake. Avant de fonder SELECT, Ian a passé 6 ans à la tête d'équipes full stack data science et engineering chez Shopify et Capital One. Chez Shopify, il a piloté les chantiers d'optimisation du data warehouse et de visibilité sur les coûts.