Das Snowflake Query Profile ist die beste Quelle, um nachzuvollziehen, wie Snowflake Ihre Query ausführt und wie Sie sie verbessern können. In diesem Beitrag zeigen wir, wie Sie das Query Profile richtig lesen und worauf Sie achten sollten, wenn Sie schwache Query-Performance analysieren.
Was ist ein Snowflake Query Plan?
Bevor wir uns dem Query Profile zuwenden, lohnt sich ein Blick darauf, was ein "Query Plan" eigentlich ist. Zu jeder SQL-Query in Snowflake erstellt der Query Optimizer einen passenden Query Plan. Dieser Plan beschreibt die Abfolge von Anweisungen oder "Schritten", die zur Verarbeitung einer SQL-Anweisung nötig sind – quasi ein Rezept für die Daten. Da Snowflake automatisch den optimalen Ausführungsweg bestimmt, kann der Query Plan von der logischen Reihenfolge der SQL-Anweisung abweichen.
In Snowflake ist der Query Plan ein DAG aus Operatoren, die über Links miteinander verbunden sind. Operatoren verarbeiten eine Menge von Zeilen – typische Operationen sind das Scannen einer Tabelle, das Filtern von Zeilen, Joins, Aggregationen usw. Links geben Daten zwischen Operatoren weiter. Zur Veranschaulichung dient folgende Query:
select
date_trunc('day', event_timestamp) as date,
count(*) as num_events
from events
group by 1
order by 1
Der zugehörige Query Plan sähe in etwa so aus:

Dieser Plan umfasst 4 "Operatoren" und 3 "Links":
TableScan: liest die Datensätze aus der Tabelleeventsim Remote Storage und reicht 1,3 Millionen Datensätze 1 über einen Link an den nächsten Operator weiter.Aggregate: führt die Group-by- und Count-Operationen nach Datum aus und übergibt 365 Datensätze über einen Link an den nächsten Operator.Sort: sortiert die Daten nach Datum und reicht dieselben 365 Datensätze an den letzten Operator weiter.Result: liefert die Query-Ergebnisse zurück.
Im Query Profile werden Operatoren häufig als "Operator Nodes" oder kurz "Nodes" bezeichnet. Ebenso geläufig ist der Begriff "Stages".
Was ist das Snowflake Query Profile?
Das Query Profile ist eine Funktion in der Snowflake-Oberfläche, die Ihnen detaillierte Einblicke in die Ausführung einer Query gibt. Es zeigt den Query Plan visuell mit allen Nodes und Links und liefert für jede Node sowie für die Query insgesamt Ausführungsdetails und Statistiken.
Wann sollte ich es nutzen?
Das Query Profile ist immer dann das richtige Werkzeug, wenn Sie tiefergehende Diagnoseinformationen zu einer Query brauchen. Ein typischer Fall: Sie wollen verstehen, warum eine Query sich auf eine bestimmte Art verhält. Das Query Profile zeigt zum Beispiel, welche Stages deutlich länger dauern als andere. Genauso lässt sich damit herausfinden, warum eine Query noch läuft und wo genau sie hängenbleibt.
Ebenso hilfreich: Sie können nachvollziehen, warum eine Query nicht das erwartete Ergebnis geliefert hat. Wer die Links zwischen den Nodes genau prüft, findet oft die Stellen, an denen Zeilen verloren gehen oder Duplikate entstehen – und damit die Ursache für unerwartete Ergebnisse.
Wie öffnet man ein Snowflake Query Profile?
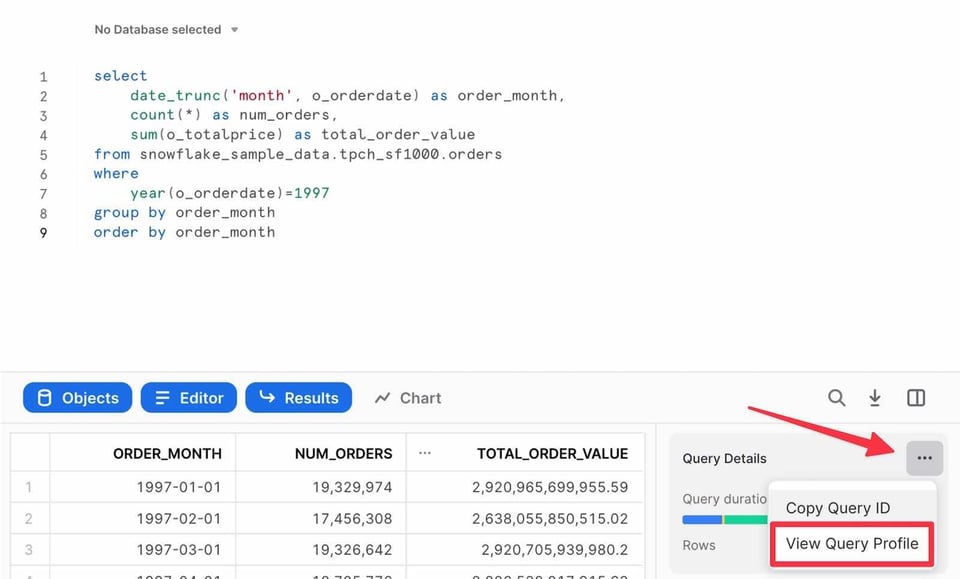
Nach dem Ausführen einer Query im Snowsight Query Editor finden Sie im Ergebnisbereich einen Link zum Query Profile:
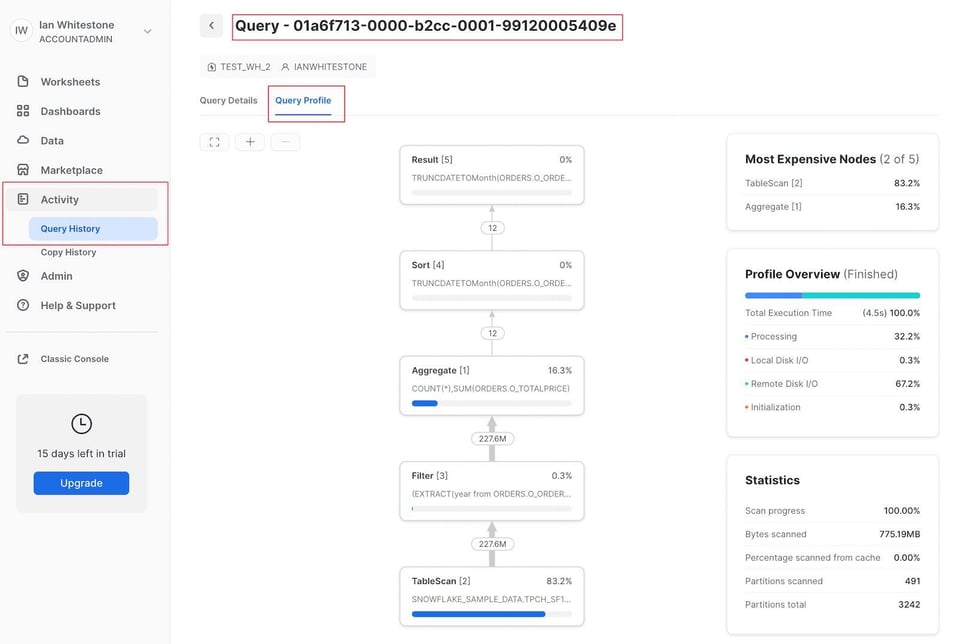
Alternativ wechseln Sie auf die Seite "Query History" unter dem Tab "Activity". Für jede Query, die in den letzten 14 Tagen ausgeführt wurde, lässt sich von dort das Query Profile öffnen.
Wenn Sie die query_id bereits zur Hand haben, können Sie die strukturierten URLs von Snowflake nutzen und folgendes Template ausfüllen:
- Template:
https://app.snowflake.com/<snowflake-region>/<account-locator>/compute/history/queries/<paste-query-id-here>/profile - Beispiel:
https://app.snowflake.com/us-east4.gcp/xq35282/compute/history/queries/01a8c0a5-0000-0b5e-0000-2dd500044a26/profile
Lassen sich die Daten im Snowflake Query Profile programmatisch abfragen?
Noch nicht. Snowflake arbeitet aktiv an einer neuen Funktion, mit der sich die im Query Profile angezeigten Daten direkt abfragen lassen. Bleiben Sie dran.
Wie liest man ein Snowflake Query Profile?
Einfache Query
Starten wir mit einer einfachen Query, die jeder auf dem Snowflake-Beispieldatensatz ausführen kann:
select
date_trunc('month', o_orderdate) as order_month,
count(*) as num_orders,
sum(o_totalprice) as total_order_value
from snowflake_sample_data.tpch_sf1000.orders
where
year(o_orderdate)=1997
group by order_month
order by order_month
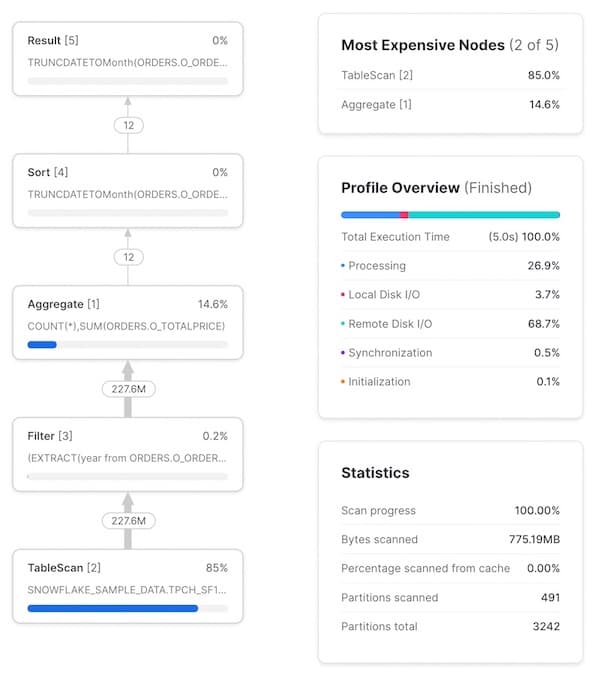
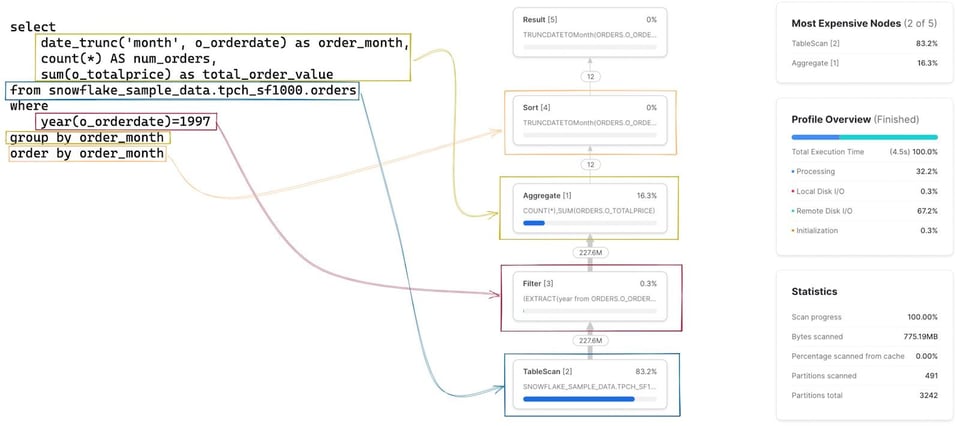
Im ersten Schritt sollten Sie ein Gefühl dafür entwickeln, wie jede Stage bzw. jeder Operator im Query Profile zu Ihrer geschriebenen Query passt. Am Anfang ist das knifflig, mit etwas Übung geht es aber schnell von der Hand. Ein Klick auf eine Node zeigt weitere Details zum Operator – etwa welche Tabelle gescannt wird oder welche Aggregationen laufen – und erleichtert so die Zuordnung zum SQL. In der folgenden Abbildung ist der zu jedem Operator gehörende SQL-Code hervorgehoben:
Das Query Profile liefert zudem einige nützliche Statistiken. Hier die wichtigsten:
- Eine Aufschlüsselung der Ausführungszeit. Sie zeigt, welcher Anteil der Gesamtausführungszeit prozentual auf welche Kategorie entfällt. Die vier Kategorien lauten:
- Processing: Zeit für Query-Operationen wie Joins, Aggregationen, Filter, Sortierungen usw.
- Local Disk I/O: Zeit für das Lesen/Schreiben auf lokalem SSD-Speicher. Dazu zählen etwa Spilling auf die Festplatte oder das Lesen gecachter Daten von lokaler SSD.
- Remote Disk I/O: Zeit für das Lesen/Schreiben aus dem Remote Storage (z. B. S3 oder Azure Blob Storage). Dazu zählen Spilling auf Remote Disk oder das Lesen Ihrer Datensätze.
- Initialization: Overhead-Kosten für den Start Ihrer Query auf dem Warehouse. Erfahrungsgemäß ist dieser Anteil immer sehr gering und nahezu konstant.
- Query-Statistiken. Hier finden Sie etwa die Anzahl gescannter Partitionen im Verhältnis zur Gesamtzahl der möglichen Partitionen – über alle in der Query verwendeten Tabellen hinweg. Wenige gescannte Partitionen bedeuten, dass die Query gut pruned. Reicht der Speicher des Warehouse nicht aus und kommt es zum Spilling auf die Festplatte, wird das hier ebenfalls angezeigt.
- Anzahl der zwischen den Nodes ausgetauschten Datensätze. Das hilft enorm, das verarbeitete Datenvolumen einzuschätzen und zu sehen, wie jede Node die Datenmenge reduziert (oder vergrößert).
- Prozentualer Anteil der Gesamtausführungszeit pro Node. Oben rechts an jeder Node wird angezeigt, welcher Anteil der Gesamtausführungszeit auf diesen Operator entfällt. In diesem Beispiel entfielen 83,2 % der Gesamtausführungszeit auf den
TableScan-Operator. Aus diesen Werten speist sich die Liste "Most Expensive Nodes" oben rechts im Query Profile, die die Nodes nach prozentualem Anteil an der Gesamtausführungszeit sortiert.
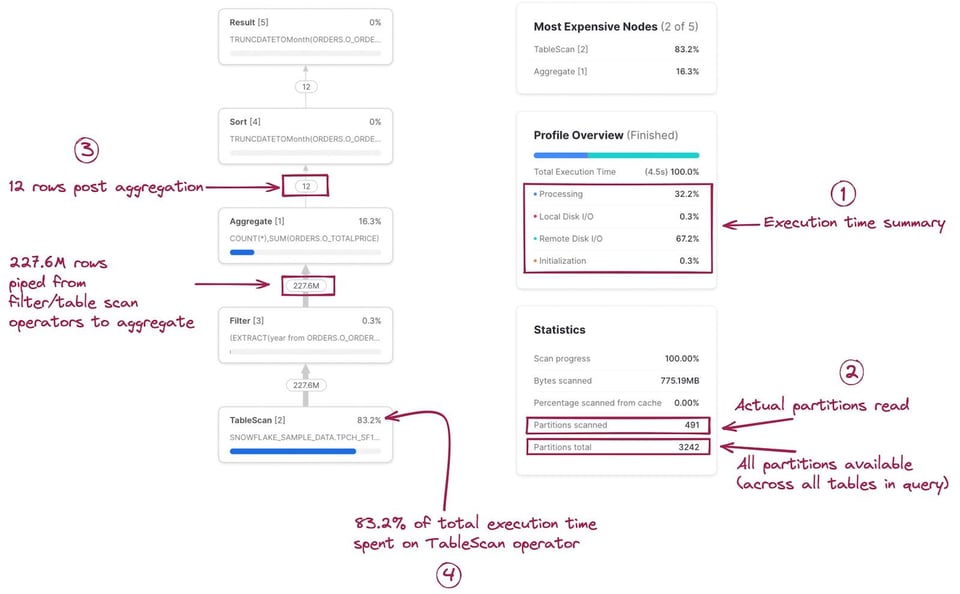
Ihnen ist vielleicht aufgefallen, dass die Anzahl der ein- und ausgehenden Zeilen an der Filter-Node identisch ist – so, als hätte der SQL-Code year(o_orderdate)=1997 nichts bewirkt. Tatsächlich filtert er aber sehr wohl Datensätze heraus, denn die Tabelle enthält 1,5 Milliarden Datensätze. Das ist ein bedauerlicher Schwachpunkt des Query Profile: Die exakte Zahl der von einem bestimmten Filter entfernten Datensätze wird nicht angezeigt.
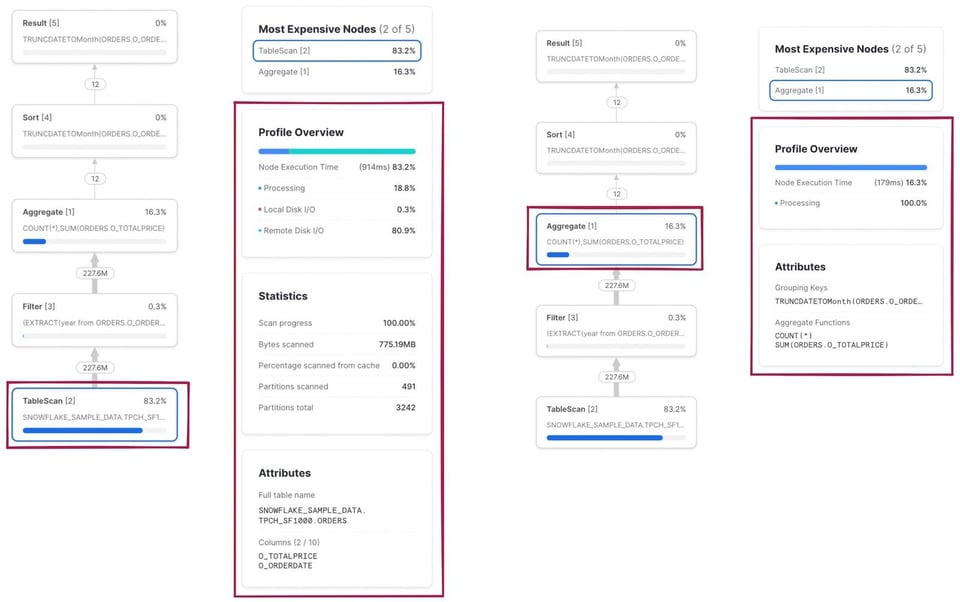
Wie eingangs erwähnt, können Sie auf jede Node klicken, um weitere Ausführungsdetails und Statistiken einzublenden. Links sehen Sie das Ergebnis eines Klicks auf den TableScan-Operator, rechts die Details zum Aggregate-Operator.
Mehrstufige Query
Wird der Filter in der obigen Query durch eine Subquery ersetzt, entsteht eine mehrstufige Query.
select
date_trunc('month', o_orderdate) as order_month,
count(*) as num_orders,
sum(o_totalprice) as total_order_value
from snowflake_sample_data.tpch_sf1000.orders
where
o_totalprice > (select avg(o_totalprice) from snowflake_sample_data.tpch_sf1000.orders)
group by order_month
order by order_month
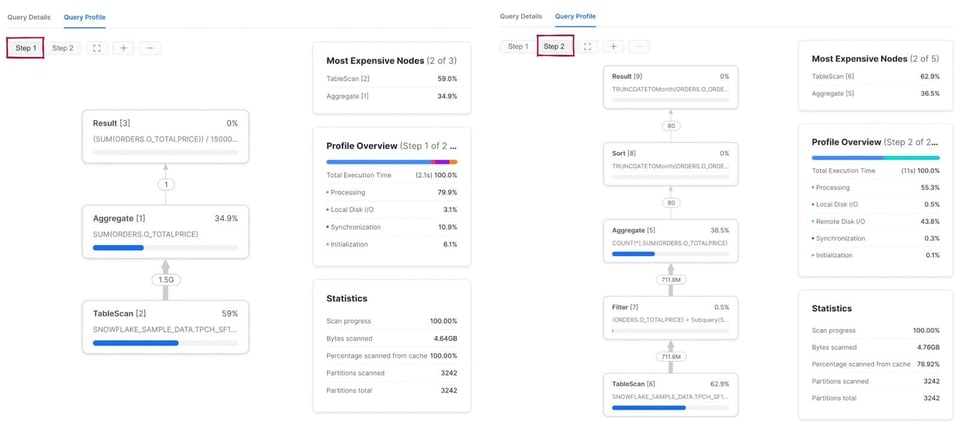
Anders als zuvor besteht der Query Plan jetzt aus zwei Schritten. Zunächst führt Snowflake die Subquery aus und berechnet den Durchschnitt von o_totalprice. Das Ergebnis wird gespeichert und im zweiten Schritt der Query verwendet, der dieselben fünf Operatoren enthält wie unsere Query oben.
Komplexe Query
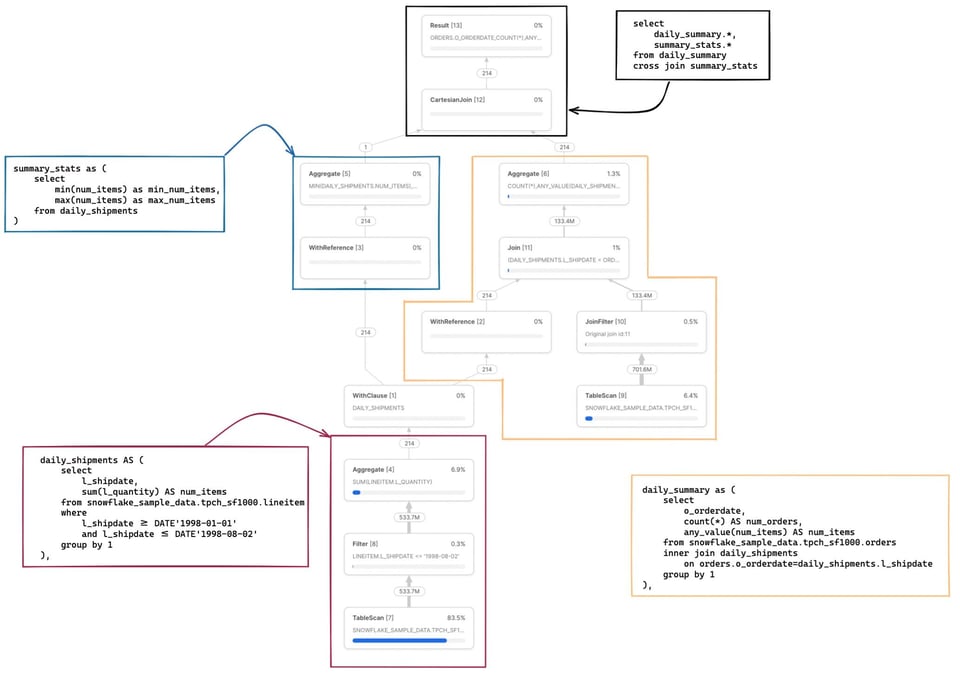
Hier ein etwas komplexeres Beispiel 2 mit mehreren CTEs, von denen eines an zwei weiteren Stellen referenziert wird.
with
daily_shipments AS (
select
l_shipdate,
sum(l_quantity) AS num_items
from snowflake_sample_data.tpch_sf1000.lineitem
where
l_shipdate >= DATE'1998-01-01'
and l_shipdate <= DATE'1998-08-02'
group by 1
),
daily_summary as (
select
o_orderdate,
count(*) AS num_orders,
Code erweitern
In diesem Beispiel sind ein paar Dinge bemerkenswert. Erstens: Das CTE daily_shipments wird nur einmal berechnet. Jedes nachgelagerte SQL, das auf dieses CTE zugreift, nutzt den Operator WithReference, um auf die Ergebnisse zuzugreifen, statt sie jedes Mal neu zu berechnen.
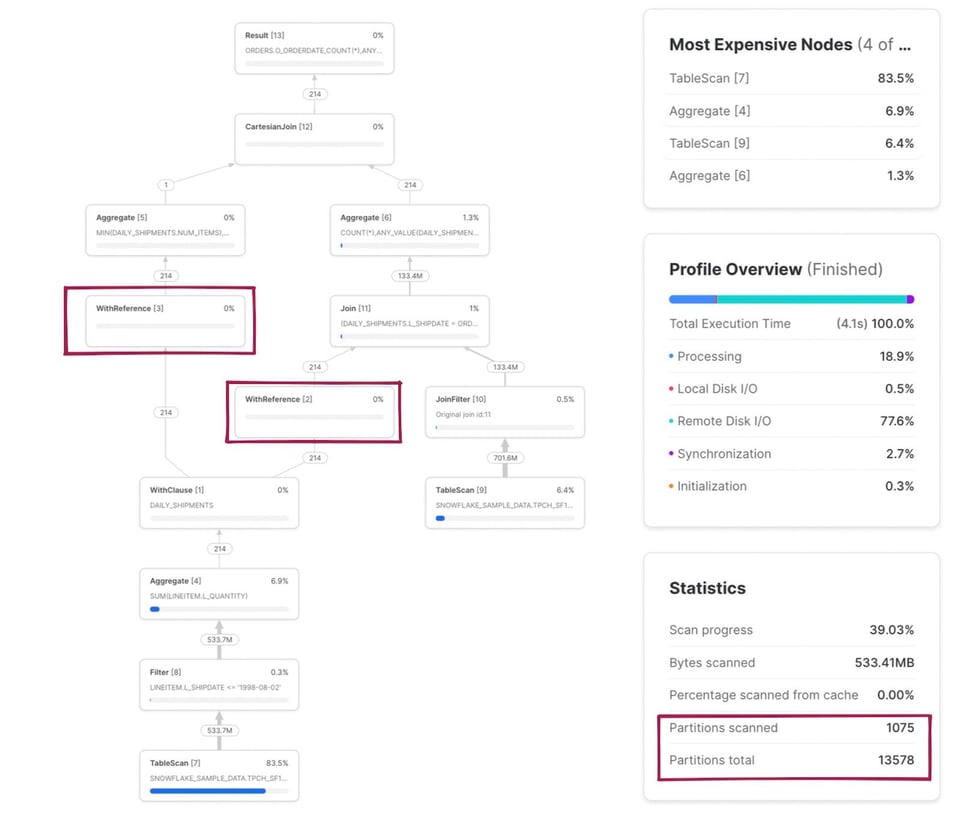
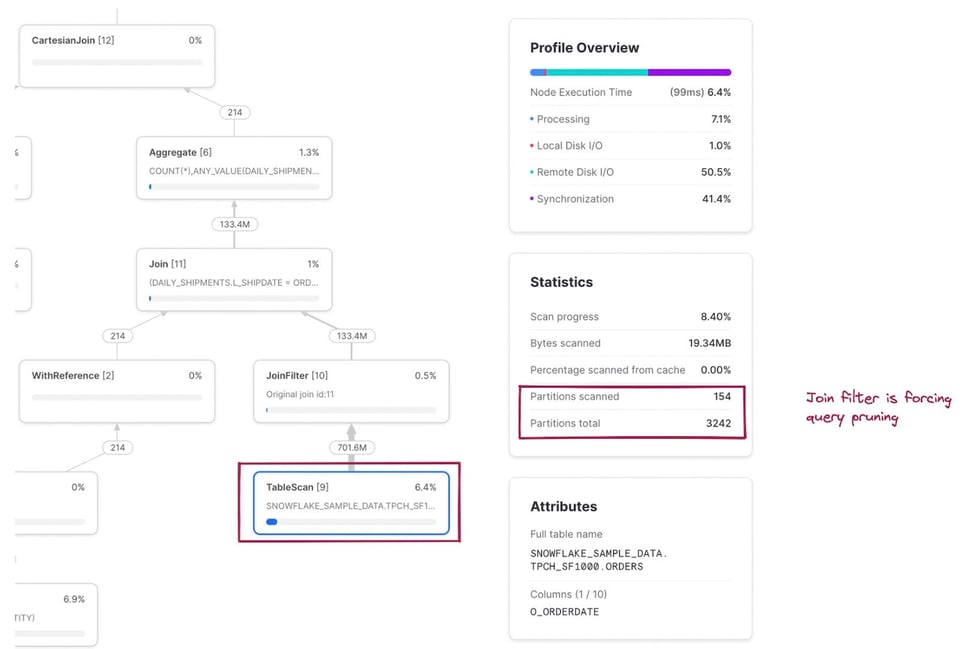
Die Metrik "gescannte/Gesamt-Partitionen" ist jetzt eine Kombination beider in der Query gelesenen Tabellen. Klicken wir auf die TableScan-Node für die Tabelle snowflake_sample_data.tpch_sf1000.orders, sehen wir, dass diese Tabelle sehr gut pruned wird – nur 154 von 3242 Partitionen werden gescannt. Wie funktioniert dieses Pruning, obwohl im SQL gar kein expliziter where-Filter steht? Hier kommt der Operator JoinFilter ins Spiel. Snowflake nutzt automatisch diese clevere Optimierung: Während der Query-Ausführung ermittelt Snowflake den Datumsbereich aus dem CTE daily_shipments und wendet diesen als Filter auf die Tabelle orders an – möglich wird das, weil die Query einen inner join verwendet.
Eine vollständige Zuordnung des SQL-Codes zu den jeweiligen Operator Nodes finden Sie in den Anmerkungen weiter unten 3.
Worauf sollten Sie im Snowflake Query Profile achten?
Der häufigste Anwendungsfall des Query Profile ist die Frage, warum eine bestimmte Query schlecht performt. Nach diesen Grundlagen folgen hier einige Indikatoren, die im Query Profile auf mögliche Ursachen schwacher Query-Performance hindeuten:
- Starkes Spilling auf Remote Disk. Sobald es zu Datenspilling kommt, reicht der Speicher Ihres Warehouse nicht aus, um die Daten zu verarbeiten, und sie müssen zwischengelagert werden. Spilling auf Remote Disk ist extrem langsam und verschlechtert die Query-Performance erheblich.
- Viele gescannte Partitionen. Wie beim Spilling auf Remote Disk ist auch das Lesen von Remote Disk sehr langsam. Eine hohe Zahl gescannter Partitionen bedeutet, dass Ihre Query viel Arbeit beim Lesen entfernter Daten zu leisten hat.
- Explodierende Joins. Wenn die Zahl der Zeilen, die aus einem Join herauskommen, steigt, kann das auf einen falsch gewählten Join Key hindeuten. Explodierende Joins dauern meist länger und ziehen Folgeprobleme wie Spilling auf Disk nach sich.
- Kartesische Joins. Ein kartesischer Join ist ein Cross Join, dessen Ergebnis aus der Anzahl der Zeilen der ersten Tabelle multipliziert mit der Anzahl der Zeilen der zweiten Tabelle besteht. Kartesische Joins entstehen oft unbeabsichtigt, etwa bei einem Non-Equi-Join wie einem Range Join. Wegen der hohen Datenmengen sind sie langsam und führen häufig zu Out-of-Memory-Problemen.
- Nachgelagerte Operatoren werden durch ein einzelnes CTE blockiert. Wie oben beschrieben, berechnet Snowflake jedes CTE genau einmal. Hängt ein Operator von einem CTE ab, muss er warten, bis dessen Verarbeitung abgeschlossen ist. In manchen Fällen lohnt es sich, das CTE als Subquery zu wiederholen, um Parallelverarbeitung zu ermöglichen.
- Frühes, unnötiges Sortieren. Häufig fügen Nutzer früh in ihrer Query eine überflüssige Sortierung ein. Sortierungen sind aufwendig und sollten nur dann eingesetzt werden, wenn sie wirklich nötig sind.
- Mehrfache Berechnung derselben View. Jedes Mal, wenn eine View in einer Query referenziert wird, muss sie neu berechnet werden. Enthält sie aufwendige Joins, Aggregationen oder Filter, ist es oft effizienter, die View zunächst zu materialisieren.
- Sehr großes Query Profile mit vielen Nodes. Manche Queries leisten schlicht zu viel auf einmal und lassen sich durch Vereinfachung deutlich verbessern. Eine Query in mehrere kleinere, einfachere Queries aufzuteilen, ist eine wirksame Methode.
In künftigen Beiträgen gehen wir auf jedes dieser Signale detaillierter ein und stellen Lösungsstrategien vor.
Anmerkungen
Nicht alle 1,3 Millionen Datensätze werden auf einmal übergeben. Snowflake verfügt über eine vektorisierte Ausführungs-Engine. Die Daten werden in einer Pipeline verarbeitet – jeweils in Batches von einigen tausend Zeilen im Spaltenformat. So kann ein XSMALL Warehouse mit 16 GB RAM auch Datasets verarbeiten, die deutlich größer als 16 GB sind.
Es lohnt sich nicht, zu viel Energie darauf zu verwenden, was diese Query genau berechnet oder wie sie geschrieben ist. Sie wurde ausschließlich erstellt, um ein interessantes Beispiel für ein Query Profile zu liefern.
Wer das Lesen von Snowflake Query Profiles üben möchte: Nutzen Sie die obige Beispiel-Query, um nachzuvollziehen, wie jedes CTE den verschiedenen Bereichen des Query Profile zugeordnet ist.
Ian Whitestone·Co-Founder & CEO von SELECT
Ian ist Co-Founder & CEO von SELECT, einer SaaS-Plattform für Snowflake-Kostenmanagement und -optimierung. Vor SELECT leitete Ian sechs Jahre lang Full-Stack-Data-Science- und Engineering-Teams bei Shopify und Capital One. Bei Shopify verantwortete er die Optimierung des Data Warehouse und den Ausbau der Kostentransparenz.