Snowflake Query Profileは、Snowflakeがクエリをどのように実行しているかを把握し、改善につなげるための最良のリソースです。本記事では、Query Profileの読み解き方や、クエリパフォーマンスの低下を診断する際に注目すべきポイントなど、押さえておきたいトピックを解説します。
Snowflakeのクエリプランとは
Query Profileの話に入る前に、まず「クエリプラン」とは何かを押さえておきましょう。Snowflakeでは、SQLクエリごとにクエリオプティマイザがクエリプランを生成します。このプランには、SQL文を処理するために必要な一連の命令、つまり「ステップ」が含まれています。いわばデータ処理のレシピです。Snowflakeはクエリを実行する最適な方法を自動で判断するため、クエリプランの並びはSQL文の論理的な順序と異なる場合があります。
Snowflakeのクエリプランは、オペレーターをリンクでつないだDAGとして表現されます。オペレーターは行の集合を処理する単位で、たとえばテーブルのスキャン、行のフィルタリング、データの結合、集計などがあります。リンクはオペレーター間でデータを受け渡す役割を担います。具体例として、次のクエリを見てみましょう。
select
date_trunc('day', event_timestamp) as date,
count(*) as num_events
from events
group by 1
order by 1
このクエリに対応するクエリプランは、おおよそ次のような形になります。

このプランには4つの「オペレーター」と3つの「リンク」が含まれます。
TableScan: リモートストレージにあるeventsテーブルからレコードを読み込みます。130万件のレコードをリンク経由で次のオペレーターに渡します。 1Aggregate: 日付ごとのグループ化とカウント処理を行い、365件のレコードをリンク経由で次のオペレーターに渡します。Sort: データを日付順に並べ替え、同じ365件のレコードを最後のオペレーターに渡します。Result: クエリ結果を返します。
Query Profileでは、オペレーターを「オペレーターノード」または略して「ノード」と呼ぶことが多く、「ステージ」と呼ばれることもあります。
Snowflake Query Profileとは
Query Profileは、クエリの実行状況を詳細に把握できるSnowflake UIの機能です。すべてのノードとリンクを含むクエリプランがビジュアルに表示され、各ノードおよびクエリ全体について実行詳細と統計情報を確認できます。
どんなときに使うのか
Query Profileは、クエリについてより詳しい診断情報が必要なときに活用します。代表的なのは、クエリが特定の挙動を示す理由を突き止めたいケースです。Query Profileを見れば、他のステージに比べて処理時間が突出して長いステージを特定できます。同じように、クエリが終わらない原因や、どこで処理が滞っているのかを調べる際にも役立ちます。
もう一つの有効な使い方は、クエリが期待どおりの結果を返さなかった理由を調べることです。ノード間のリンクを丁寧に確認すれば、行が脱落していたり重複が生じていたりする箇所を特定でき、想定外の結果が出た原因の解明につながります。
Snowflake Query Profileの表示方法
Snowsightのクエリエディタでクエリを実行すると、結果ペインにQuery Profileへのリンクが表示されます。
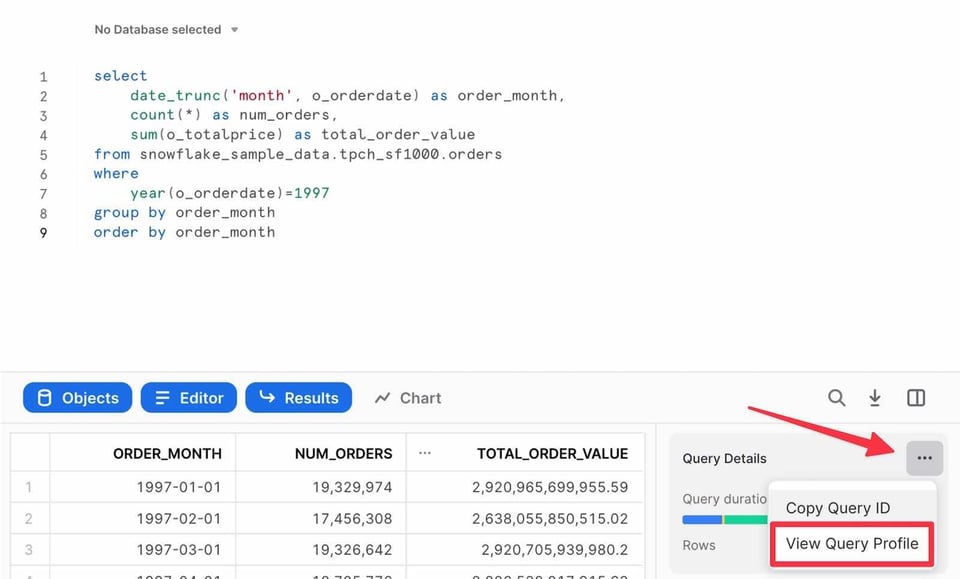
あるいは、「Activity」タブ配下の「Query History」ページに移動する方法もあります。過去14日間に実行されたクエリであれば、クリックしてQuery Profileを開けます。
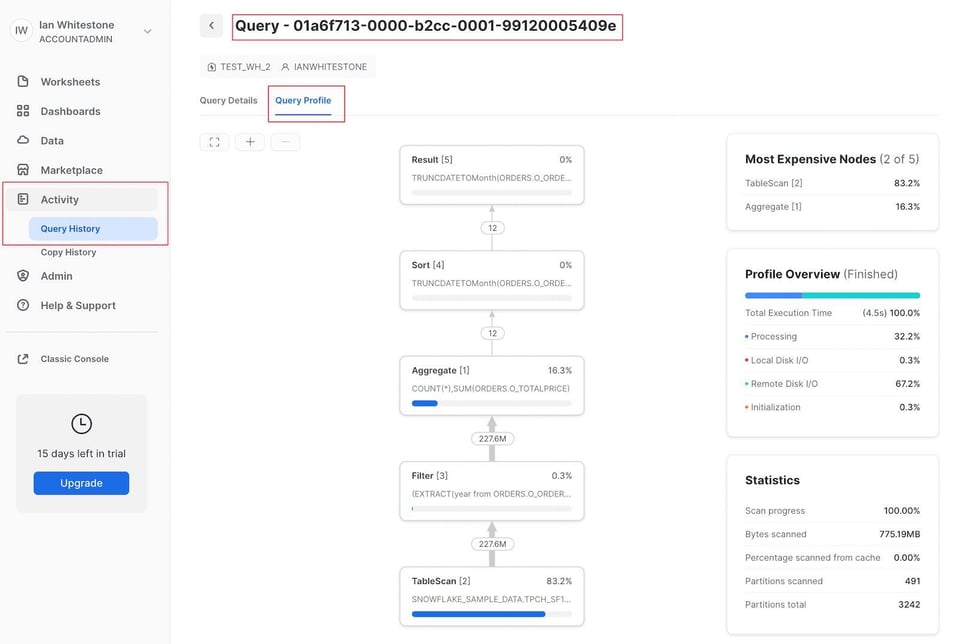
query_idがすでにわかっている場合は、Snowflakeの構造化URLを利用して次のテンプレートに当てはめる方法もあります。
- テンプレート:
https://app.snowflake.com/<snowflake-region>/<account-locator>/compute/history/queries/<paste-query-id-here>/profile - 記入例:
https://app.snowflake.com/us-east4.gcp/xq35282/compute/history/queries/01a8c0a5-0000-0b5e-0000-2dd500044a26/profile
Snowflake Query Profileのデータにプログラムからアクセスできるか
現時点ではまだ対応していません。Snowflakeは、Query Profileに表示されるデータをユーザーがクエリで取得できるようにする新機能を現在開発中です。続報をお待ちください。
Snowflake Query Profileの読み方
基本的なクエリ
まずは、Snowflakeのサンプルデータセットに対して誰でも実行できるシンプルなクエリから始めましょう。
select
date_trunc('month', o_orderdate) as order_month,
count(*) as num_orders,
sum(o_totalprice) as total_order_value
from snowflake_sample_data.tpch_sf1000.orders
where
year(o_orderdate)=1997
group by order_month
order by order_month
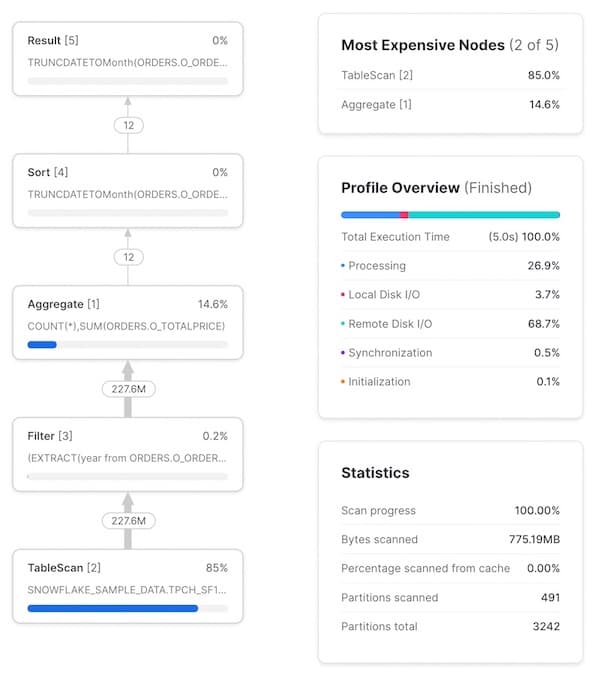
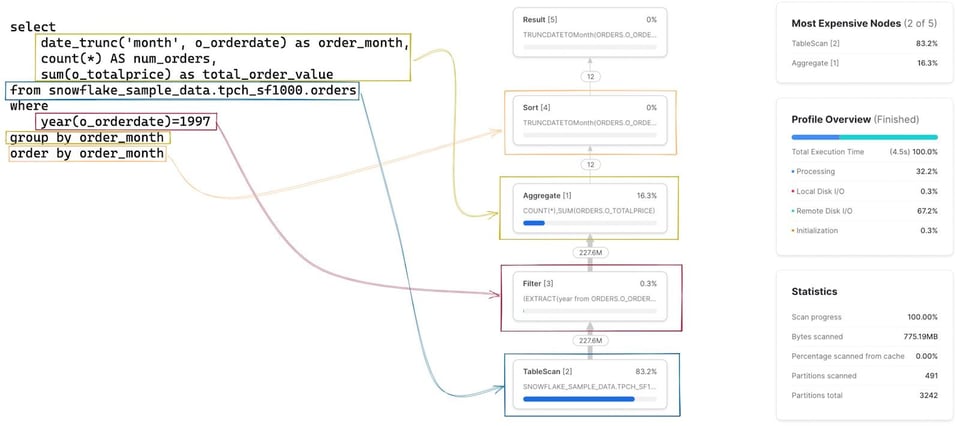
最初のステップは、Query Profile上の各ステージ/オペレーターが自分の書いたクエリのどの部分に対応しているかをイメージできるようになることです。最初は難しく感じますが、慣れればすぐに掴めるようになります。各ノードをクリックすると、スキャン対象のテーブルや実行中の集計など、そのオペレーターの詳細が表示され、対応するSQLを特定する手がかりになります。下図では、各オペレーターに対応するSQLをハイライト表示しています。
Query Profileには、便利な統計情報も用意されています。主なものをいくつか紹介します。
- 実行時間のサマリー。クエリ全体の実行時間のうち、どの項目に何%が費やされたかを示します。ここに表示される4つの項目は次のとおりです。
- Processing: 結合、集計、フィルタ、ソートなど、クエリ処理に費やされた時間。
- Local Disk I/O: ローカルSSDストレージへの読み書きに費やされた時間。ディスクへのスピルや、ローカルSSDからのキャッシュデータの読み込みなどが含まれます。
- Remote Disk I/O: リモートストレージ(S3やAzure Blob Storageなど)への読み書きに費やされた時間。リモートディスクへのスピルやデータセットの読み込みなどが含まれます。
- Initialization: ウェアハウス上でクエリを起動する際のオーバーヘッドです。経験上、常に極めて小さく、ほぼ一定の値になります。
- クエリ統計。スキャンされたパーティション数と全パーティション数といった情報を確認できます。これはクエリ内の全テーブルを合算した値である点に注意してください。スキャンされたパーティションが少ないほど、プルーニングがうまく効いていることを意味します。ウェアハウスのメモリ不足でディスクにスピルしている場合も、この情報に反映されます。
- 各ノード間で受け渡されたレコード数。処理されているデータ量や、各ノードがそれをどれだけ削減(あるいは増加)させているかを把握するのに非常に役立ちます。
- 各ノードが占める全実行時間の割合。各ノードの右上に表示され、そのオペレーターが全実行時間のうちどれだけを占めたかを示します。この例では、全実行時間の83.2%が
TableScanオペレーターで費やされています。この情報はQuery Profile右上の「Most Expensive Nodes」リストにも使われ、全実行時間の割合が高い順にノードが並びます。
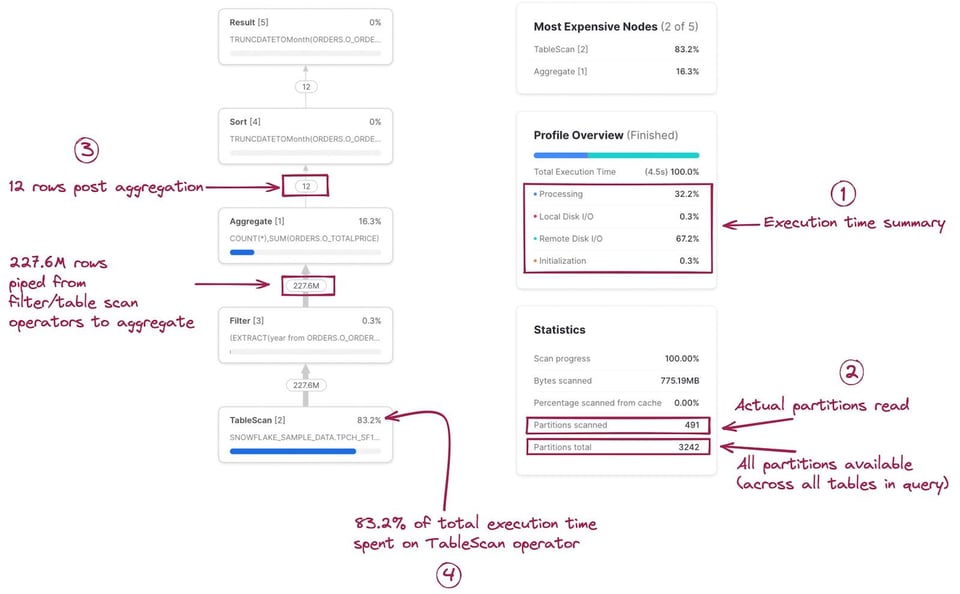
Filterノードの入出力レコード数が同じ点に気づいた方もいるかもしれません。一見するとyear(o_orderdate)=1997というSQLが効いていないように見えますが、実際にはこのテーブルには15億件のレコードがあり、フィルタはしっかりレコードを除外しています。これはQuery Profileの惜しい点で、特定のフィルタによって除外された正確なレコード数は表示されないのです。
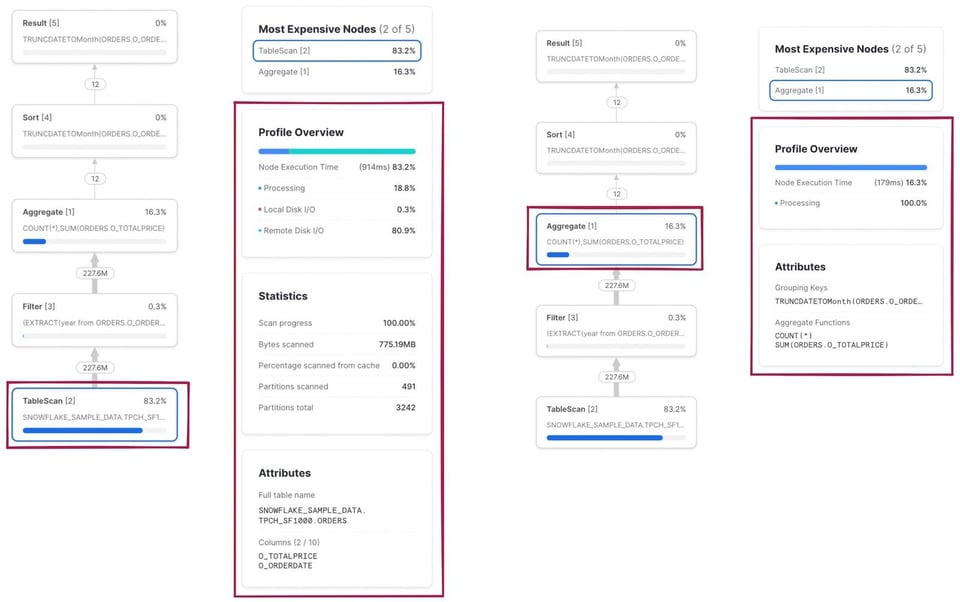
前述のとおり、各ノードをクリックすると追加の実行詳細と統計情報が表示されます。左側はTableScanオペレーターをクリックした結果、右側はAggregateオペレーターの結果です。
マルチステップクエリ
先ほどのクエリのフィルタをサブクエリ付きに書き換えると、マルチステップのクエリになります。
select
date_trunc('month', o_orderdate) as order_month,
count(*) as num_orders,
sum(o_totalprice) as total_order_value
from snowflake_sample_data.tpch_sf1000.orders
where
o_totalprice > (select avg(o_totalprice) from snowflake_sample_data.tpch_sf1000.orders)
group by order_month
order by order_month
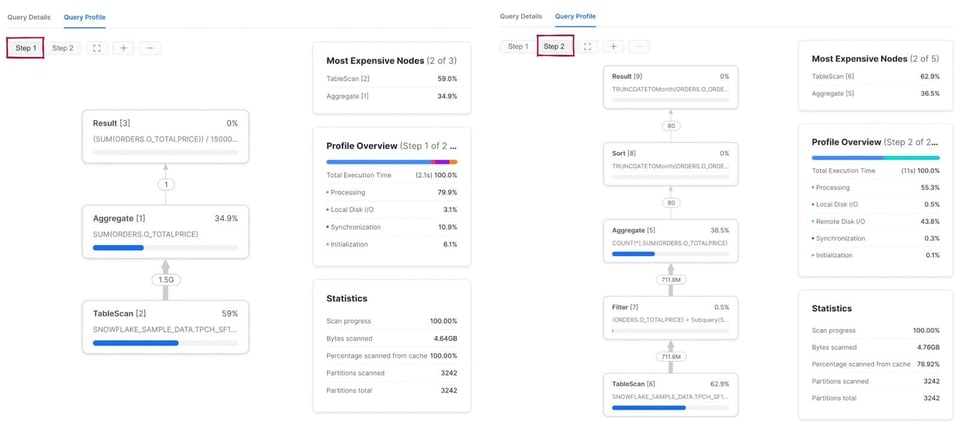
先ほどと違い、クエリプランは2つのステップに分かれます。まずSnowflakeはサブクエリを実行してo_totalpriceの平均を算出します。その結果が保持され、先ほどのクエリと同じ5つのオペレーターを持つ第2ステップで利用されます。
複雑なクエリ
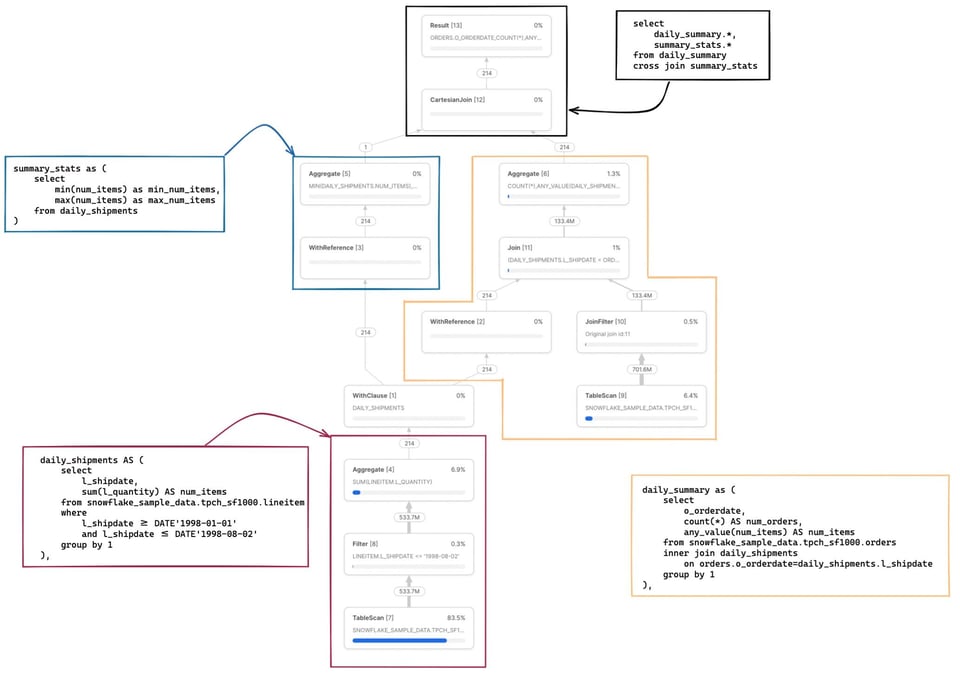
次は、複数のCTEを持ち、そのうち1つが他の2箇所から参照されている、もう少し複雑なクエリです。 2
with
daily_shipments AS (
select
l_shipdate,
sum(l_quantity) AS num_items
from snowflake_sample_data.tpch_sf1000.lineitem
where
l_shipdate >= DATE'1998-01-01'
and l_shipdate <= DATE'1998-08-02'
group by 1
),
daily_summary as (
select
o_orderdate,
count(*) AS num_orders,
Expand Code
この例には注目すべき点がいくつかあります。まず、daily_shipments CTEは一度しか計算されません。このCTEを参照する下流のSQLは、毎回再計算するのではなく、WithReferenceオペレーターを呼び出してCTEの結果にアクセスします。
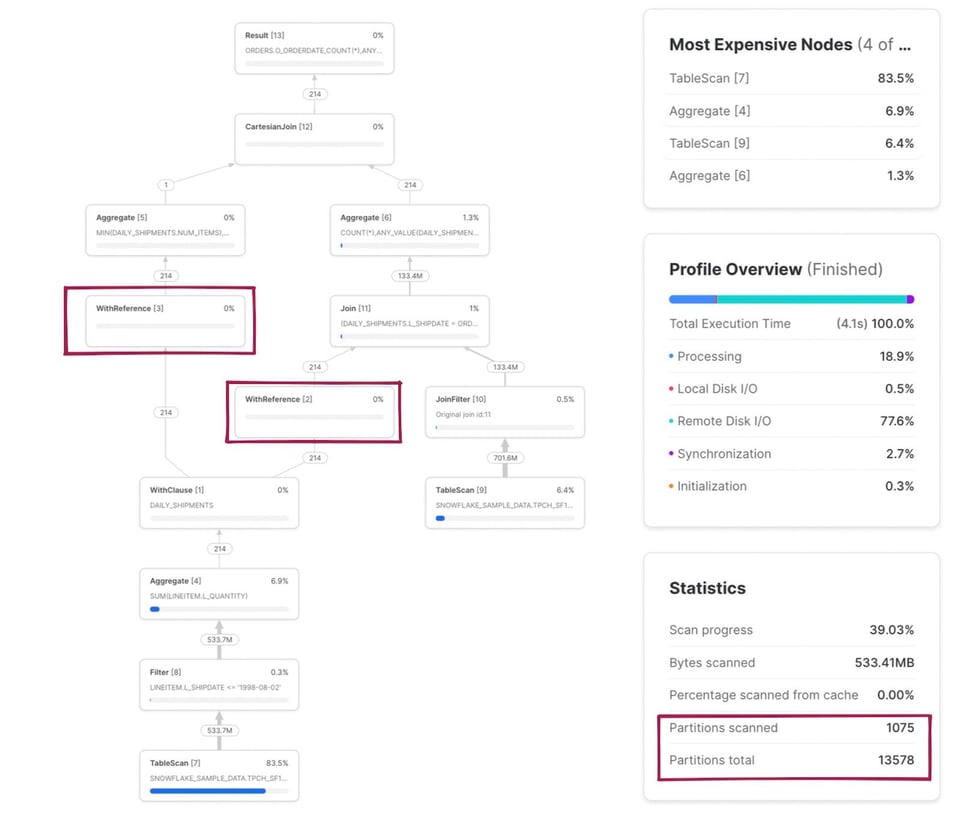
スキャンされたパーティション数/総パーティション数のメトリクスは、クエリで読み込まれる両テーブルを合算した値になります。snowflake_sample_data.tpch_sf1000.ordersテーブルのTableScanノードをクリックしてみると、3242パーティションのうちわずか154しかスキャンされておらず、プルーニングがしっかり効いていることがわかります。SQLには明示的なwhereフィルタが書かれていないのに、なぜプルーニングが効いているのでしょうか。これはJoinFilterオペレーターの働きによるものです。クエリがinner joinを使用しているため、Snowflakeはクエリ実行中にdaily_shipments CTEから日付の範囲を判定し、それをフィルタとしてordersテーブルに自動適用するという、巧妙な最適化を行っているのです。
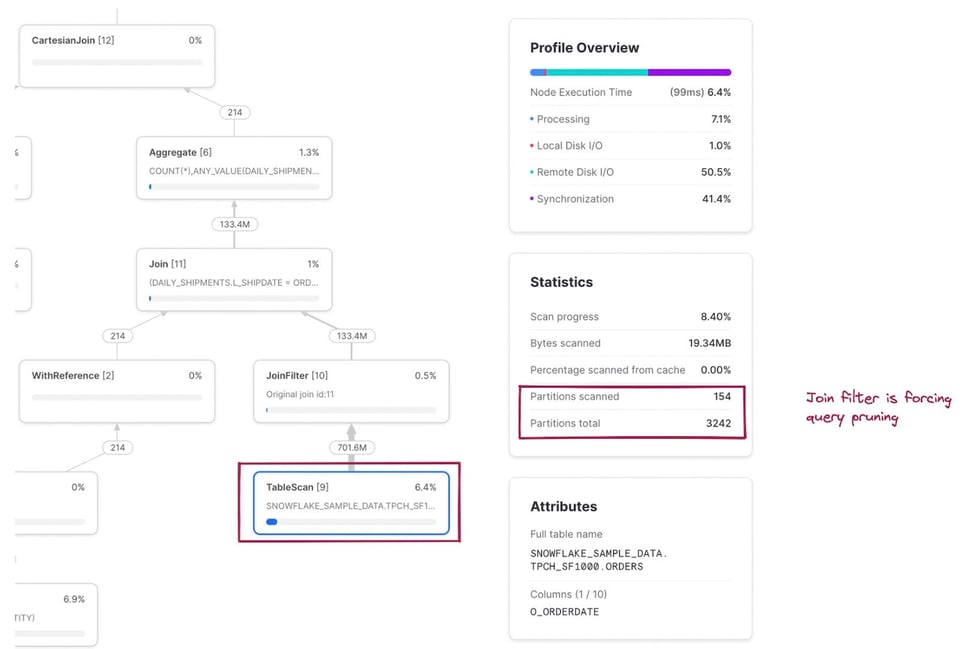
SQLコードと対応するオペレーターノードの完全な対応関係は、末尾の注釈にまとめています。 3
Snowflake Query Profileで見るべきポイント
Query Profileの最も一般的な活用シーンは、特定のクエリのパフォーマンスが芳しくない原因を突き止めることです。基本を押さえたところで、クエリパフォーマンス低下の要因となりうる兆候として、Query Profileで確認すべきポイントを紹介します。
- リモートディスクへの大量のスピル。データのスピルが発生している時点で、ウェアハウスのメモリがデータ処理に足りておらず、一時的に別の場所へ退避させざるを得ない状態であることを意味します。リモートディスクへのスピルは極めて遅く、クエリパフォーマンスを大きく低下させます。
- スキャンされたパーティション数が多い。リモートディスクへのスピルと同様に、リモートディスクからのデータ読み込みも非常に時間がかかります。スキャンされたパーティション数が多いということは、それだけ多くのリモートデータを読み込む必要があるということです。
- 結合による行数の爆発(Exploding joins)。結合から出てくる行数が増えている場合、結合キーの指定が誤っている可能性があります。爆発する結合は処理に時間がかかり、ディスクへのスピルなど別の問題も招きます。
- デカルト結合(Cartesian joins)。デカルト結合はクロス結合のことで、1つ目のテーブルの行数と2つ目のテーブルの行数を掛け合わせた結果セットを生成します。レンジ結合のような非等価結合を使った際に、意図せず発生することがあります。生成されるデータ量が膨大なため、処理が遅く、メモリ不足を引き起こしやすいのが特徴です。
- 単一のCTEによる下流オペレーターのブロック。前述のとおり、SnowflakeはCTEを一度だけ計算します。そのCTEに依存するオペレーターは、計算が完了するまで待たなければなりません。場合によっては、CTEをサブクエリとして繰り返し記述し、並列処理させた方が有利なこともあります。
- 早すぎる不要なソート。クエリの早い段階で不要なソートを入れてしまうのはよくあるミスです。ソートはコストが高いため、本当に必要なとき以外は避けるべきです。
- 同じビューの繰り返し計算。ビューはクエリ内で参照されるたびに計算されます。ビューに高コストな結合、集計、フィルタが含まれている場合は、先にビューをマテリアライズした方が効率的なケースもあります。
- ノード数が非常に多い巨大なQuery Profile。中には処理が複雑すぎるクエリもあり、シンプルに書き直すだけで大幅に改善できることがあります。クエリを複数のシンプルなクエリに分割するのは効果的な手段です。
今後の記事では、これらのシグナルそれぞれをさらに掘り下げ、解決のための具体的な戦略を紹介していきます。
注釈
130万件のレコードが一度に送られるわけではありません。Snowflakeはベクトル化された実行エンジンを備えており、データは列指向フォーマットで数千行ずつのバッチとしてパイプライン処理されます。これにより、RAMが16GBのXSMALLウェアハウスでも、16GBをはるかに超えるデータセットを処理できるのです。
このクエリが何を計算しているか、また書き方そのものについてはあまり気にしないでください。興味深いQuery Profileの例を示すためだけに作成したものです。
Snowflake Query Profileの読解力を高めたい方は、上記の例のクエリを使って、各CTEがQuery Profileのどの部分に対応するかを確認してみてください。
Ian Whitestone・Co-founder & CEO, SELECT
Ianは、Snowflakeのコスト管理・最適化SaaSプラットフォームであるSELECTの共同創業者兼CEOです。SELECTを立ち上げる前は、ShopifyとCapital Oneでフルスタックのデータサイエンス&エンジニアリングチームを6年間率いていました。Shopifyでは、データウェアハウスの最適化とコスト可視化の強化を主導しました。