El Query Profile de Snowflake es el mejor recurso con el que cuentas para entender cómo Snowflake ejecuta tu consulta y aprender a optimizarla. En este post abordamos temas importantes como la lectura del Query Profile y qué revisar al diagnosticar un bajo rendimiento en las consultas.
¿Qué es un plan de consulta de Snowflake?
Antes de hablar del Query Profile, conviene entender qué es un "plan de consulta". Para cada consulta SQL en Snowflake existe un plan correspondiente, generado por el optimizador. Ese plan contiene el conjunto de instrucciones o "pasos" necesarios para procesar cualquier sentencia SQL. Es como una receta de datos. Como Snowflake determina automáticamente la forma óptima de ejecutar una consulta, el plan puede verse distinto al orden lógico de la sentencia SQL asociada.
En Snowflake, el plan de consulta es un DAG formado por operadores conectados mediante enlaces. Los operadores procesan un conjunto de filas. Algunos ejemplos: escanear una tabla, filtrar filas, hacer joins, agregar, etc. Los enlaces pasan datos entre operadores. Para aterrizarlo con un ejemplo, considera la siguiente consulta:
select
date_trunc('day', event_timestamp) as date,
count(*) as num_events
from events
group by 1
order by 1
El plan de consulta correspondiente se vería más o menos así:

En este plan hay 4 "operadores" y 3 "enlaces":
TableScan: lee los registros de la tablaeventsdesde el almacenamiento remoto. Pasa 1,3 millones de registros 1 al siguiente operador a través de un enlace.Aggregate: ejecuta el group by por fecha y la operación de conteo, y pasa 365 registros al siguiente operador por un enlace.Sort: ordena los datos por fecha y pasa esos mismos 365 registros al operador final.Result: devuelve los resultados de la consulta.
El Query Profile suele referirse a los operadores como "nodos de operador" o, simplemente, "nodos". También es común llamarlos "etapas".
¿Qué es el Query Profile de Snowflake?
Query Profile es una funcionalidad de la interfaz de Snowflake que te entrega información detallada sobre la ejecución de una consulta. Incluye una representación visual del plan, con todos los nodos y enlaces. Para cada nodo, y para la consulta en general, se muestran detalles y estadísticas de ejecución.
¿Cuándo conviene usarlo?
Conviene usar el Query Profile siempre que necesites más información de diagnóstico sobre una consulta. Un caso típico es entender por qué una consulta se comporta de cierta manera. El Query Profile ayuda a identificar etapas que tardan bastante más que otras en procesarse. De la misma forma, te sirve para descubrir por qué una consulta sigue corriendo y en qué punto se atora.
Otra aplicación útil es entender por qué una consulta no devolvió el resultado esperado. Al estudiar con cuidado los enlaces entre nodos, puedes detectar partes de tu consulta que están descartando filas o generando duplicados, lo que puede explicar resultados inesperados.
¿Cómo se visualiza un Query Profile de Snowflake?
Después de ejecutar una consulta en el editor de Snowsight, el panel de resultados incluye un enlace al Query Profile:
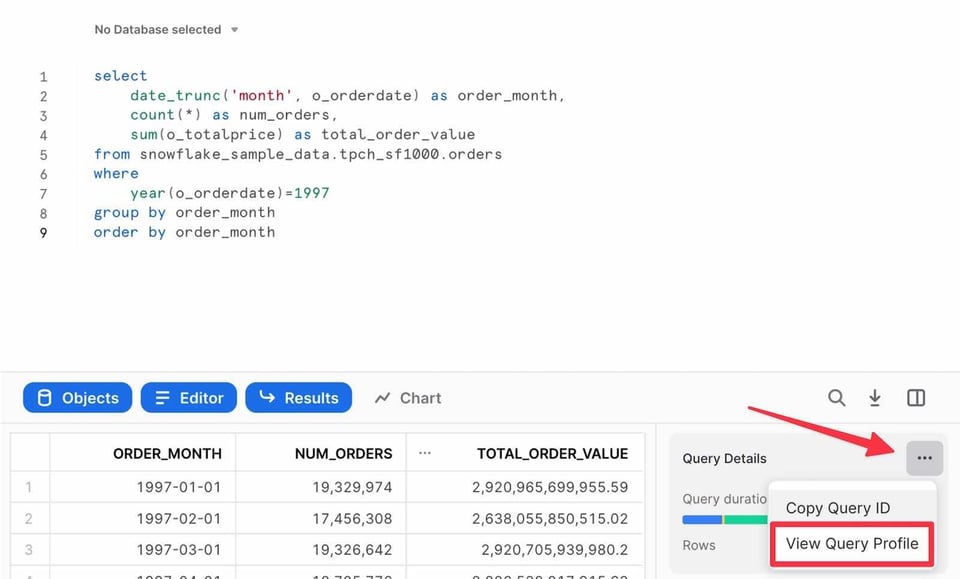
También puedes ir a la página "Query History" dentro de la pestaña "Activity". Para cualquier consulta ejecutada en los últimos 14 días, basta con hacer clic en ella para ver el Query Profile.
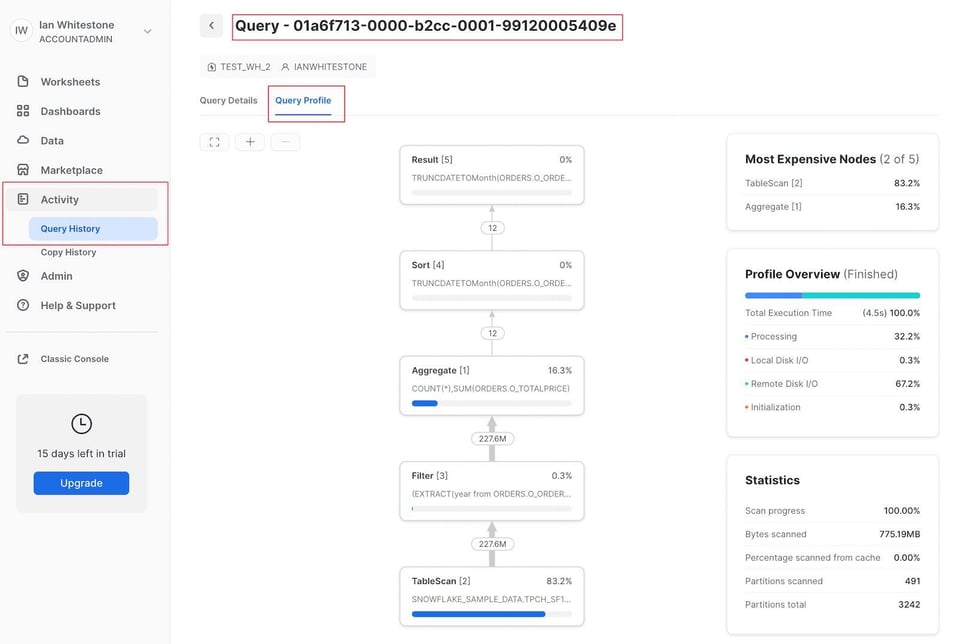
Si ya tienes el query_id a la mano, puedes aprovechar las URL estructuradas de Snowflake completando esta plantilla:
- Plantilla:
https://app.snowflake.com/<snowflake-region>/<account-locator>/compute/history/queries/<paste-query-id-here>/profile - Ejemplo completo:
https://app.snowflake.com/us-east4.gcp/xq35282/compute/history/queries/01a8c0a5-0000-0b5e-0000-2dd500044a26/profile
¿Se puede acceder de forma programática a los datos del Query Profile de Snowflake?
Todavía no. Snowflake está trabajando activamente en una nueva funcionalidad para que los usuarios puedan consultar los datos que se muestran en el Query Profile. Mantente atento.
¿Cómo se lee un Query Profile de Snowflake?
Consulta básica
Vamos a empezar con una consulta sencilla que cualquiera puede ejecutar sobre el dataset de muestra de Snowflake:
select
date_trunc('month', o_orderdate) as order_month,
count(*) as num_orders,
sum(o_totalprice) as total_order_value
from snowflake_sample_data.tpch_sf1000.orders
where
year(o_orderdate)=1997
group by order_month
order by order_month
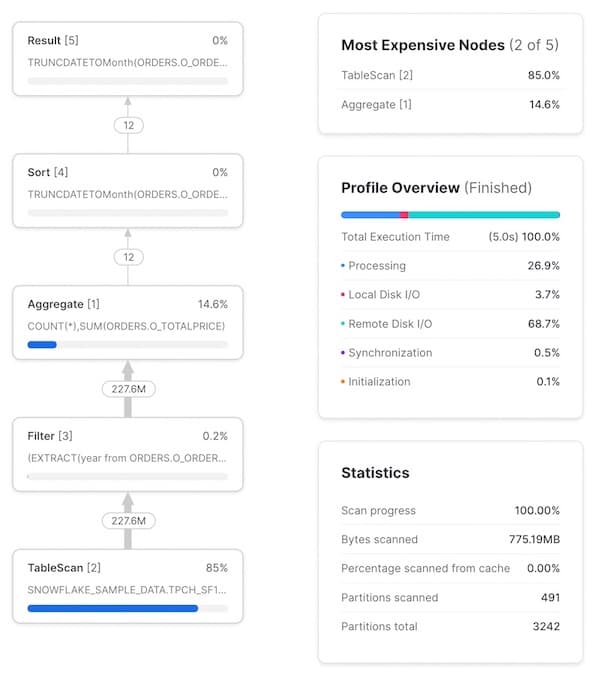
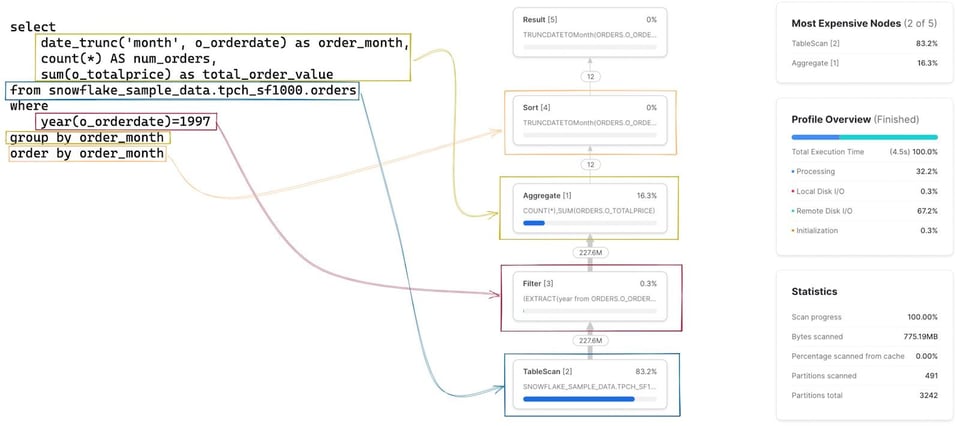
Como primer paso, conviene armar un modelo mental de cómo cada etapa/operador del Query Profile se relaciona con la consulta que escribiste. Al principio cuesta, pero con la práctica se vuelve muy ágil. Al hacer clic en cada nodo aparecen más detalles del operador, como la tabla que está escaneando o las agregaciones que ejecuta, lo que ayuda a identificar el SQL correspondiente. El SQL relevante para cada operador aparece resaltado en la siguiente imagen:
El Query Profile también incluye estadísticas útiles. Destacamos algunas:
- Un resumen del tiempo de ejecución. Muestra el % del tiempo total que se invirtió en distintas categorías. Las 4 opciones que aparecen son:
- Processing: tiempo dedicado a operaciones como joins, agregaciones, filtros, ordenamientos, etc.
- Local Disk I/O: tiempo dedicado a leer/escribir datos desde/hacia el SSD local. Incluye cosas como spilling a disco o la lectura de datos en caché desde el SSD local.
- Remote Disk I/O: tiempo dedicado a leer/escribir datos desde/hacia el almacenamiento remoto (por ejemplo, S3 o Azure Blob storage). Incluye spilling a disco remoto o la lectura de tus datasets.
- Initialization: es el costo de overhead para arrancar tu consulta en el warehouse. Según nuestra experiencia, siempre es muy pequeño y bastante constante.
- Estadísticas de la consulta. Aquí encontrarás información como la cantidad de particiones escaneadas sobre el total disponible. Ten en cuenta que es a lo largo de todas las tablas de la consulta. Menos particiones escaneadas significa que la consulta está haciendo buen pruning. Si tu warehouse no tiene memoria suficiente para procesar la consulta y hace spilling a disco, esa información también se refleja aquí.
- Cantidad de registros que se intercambian entre cada nodo. Esta información es muy útil para entender el volumen de datos que se está procesando y cómo cada nodo reduce (o aumenta) ese número.
- Porcentaje del tiempo total de ejecución dedicado a cada nodo. Aparece arriba a la derecha de cada nodo e indica el porcentaje del tiempo total que se gastó en ese operador. En este ejemplo, el 83,2% del tiempo total se dedicó al operador
TableScan. Esta información alimenta la lista "Most Expensive Nodes" en la esquina superior derecha del Query Profile, que simplemente ordena los nodos por su porcentaje del tiempo total.
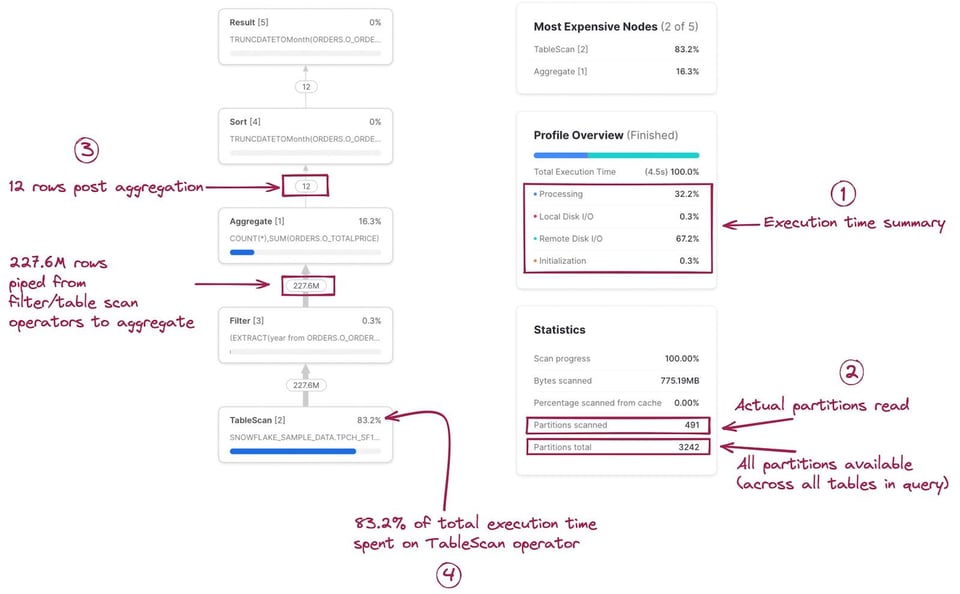
Quizás notes que la cantidad de filas que entran y salen del nodo Filter es la misma, lo que daría a entender que el código SQL year(o_orderdate)=1997 no hizo nada. Pero el filtro sí está eliminando registros: esta tabla contiene 1500 millones de filas. Esta es una limitación lamentable del Query Profile: no muestra el número exacto de registros que un filtro descarta.
Como mencionamos antes, puedes hacer clic en cada nodo para ver detalles y estadísticas adicionales. A la izquierda se ve el resultado de hacer clic en el operador TableScan. A la derecha, los resultados del operador Aggregate.
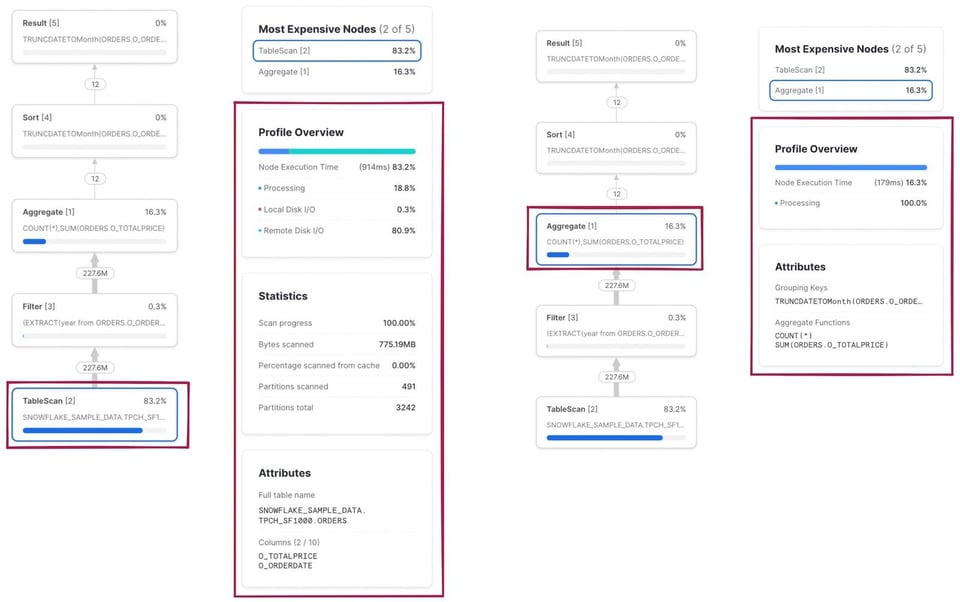
Consulta de varios pasos
Si modificamos el filtro de la consulta anterior para que incluya una subconsulta, obtenemos una consulta de varios pasos.
select
date_trunc('month', o_orderdate) as order_month,
count(*) as num_orders,
sum(o_totalprice) as total_order_value
from snowflake_sample_data.tpch_sf1000.orders
where
o_totalprice > (select avg(o_totalprice) from snowflake_sample_data.tpch_sf1000.orders)
group by order_month
order by order_month
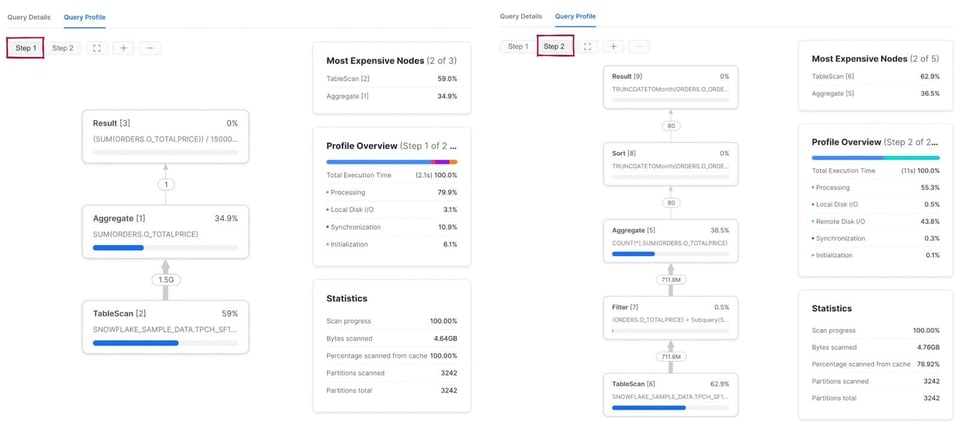
A diferencia del caso anterior, el plan de consulta ahora tiene dos pasos. Primero, Snowflake ejecuta la subconsulta y calcula el promedio de o_totalprice. El resultado se almacena y se usa en el segundo paso, que tiene los mismos 5 operadores que la consulta anterior.
Consulta compleja
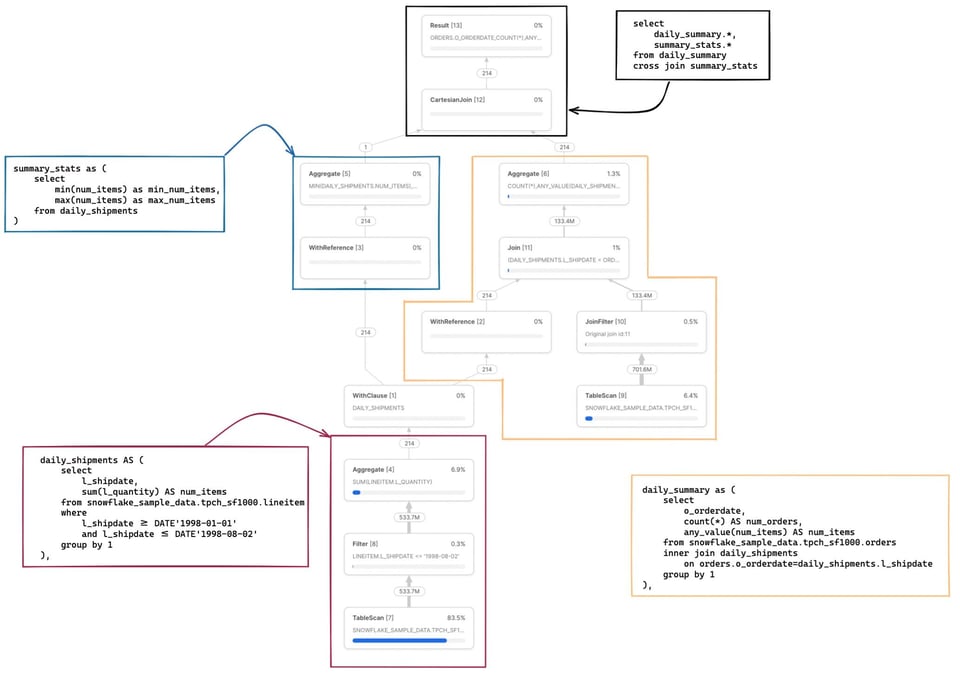
Aquí va una consulta un poco más compleja 2 con varios CTEs, uno de los cuales se referencia en otros dos lugares.
with
daily_shipments AS (
select
l_shipdate,
sum(l_quantity) AS num_items
from snowflake_sample_data.tpch_sf1000.lineitem
where
l_shipdate >= DATE'1998-01-01'
and l_shipdate <= DATE'1998-08-02'
group by 1
),
daily_summary as (
select
o_orderdate,
count(*) AS num_orders,
Expandir código
Hay un par de cosas que vale la pena destacar en este ejemplo. Primero, el CTE daily_shipments se calcula una sola vez. Cualquier SQL posterior que haga referencia a este CTE llama al operador WithReference para acceder a sus resultados, en lugar de recalcularlos.
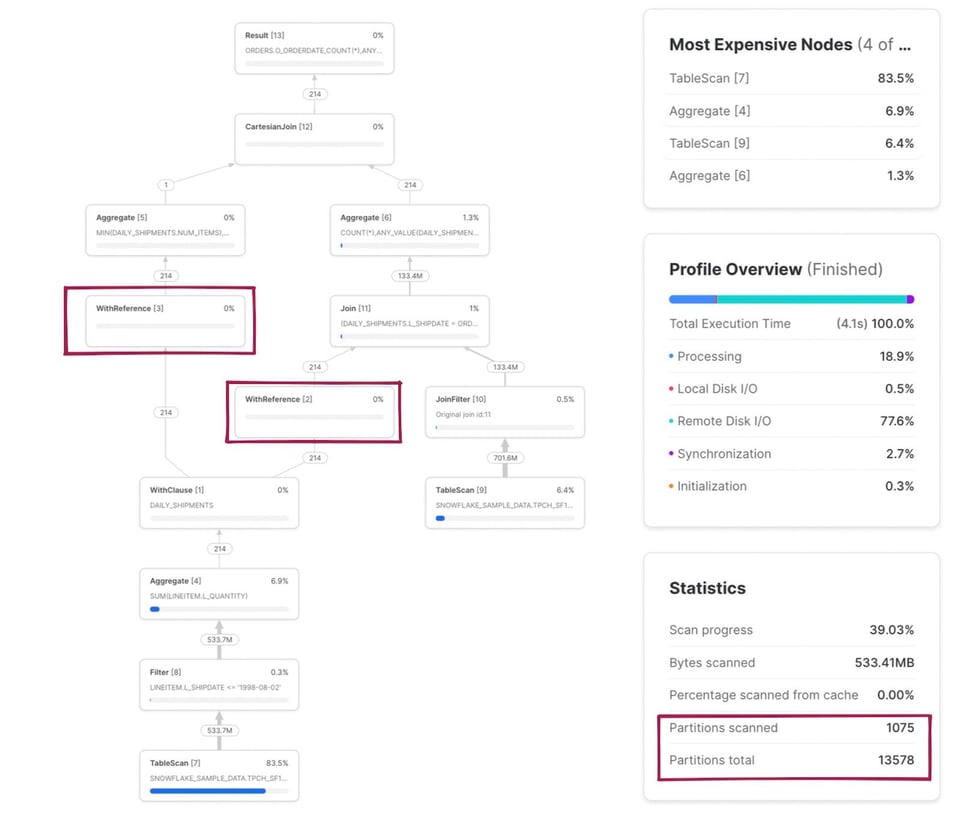
La métrica de particiones escaneadas/totales ahora combina ambas tablas que se leen en la consulta. Si entramos al nodo TableScan de la tabla snowflake_sample_data.tpch_sf1000.orders, vemos que el pruning está funcionando muy bien: solo se escanean 154 de 3242 particiones. ¿Cómo se produce este pruning si no hay un filtro where explícito en el SQL? Es el operador JoinFilter en acción. Snowflake aplica automáticamente esta optimización elegante: determina el rango de fechas del CTE daily_shipments durante la ejecución y luego lo aplica como filtro sobre la tabla orders, ¡ya que la consulta usa un inner join!
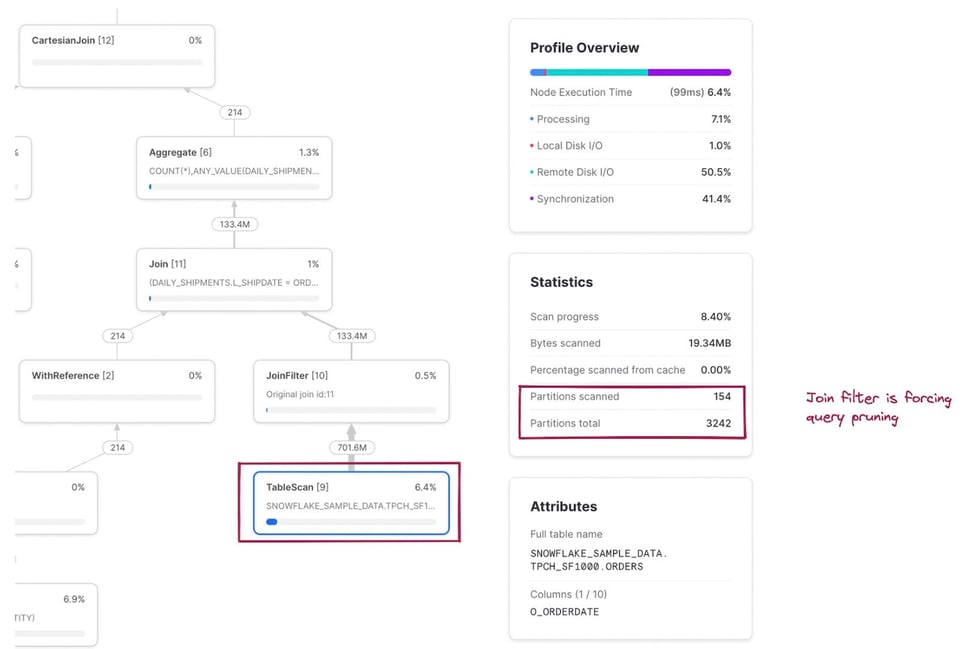
En las notas de abajo encontrarás el mapeo completo del código SQL a los nodos de operador correspondientes 3.
¿Qué hay que buscar en el Query Profile de Snowflake?
El caso de uso más común del Query Profile es entender por qué una consulta específica no está rindiendo bien. Ahora que vimos los fundamentos, aquí van algunos indicadores que puedes buscar en el Query Profile como posibles causantes de un mal rendimiento:
- Mucho spilling a disco remoto. En cuanto hay spilling de datos, significa que tu warehouse no tiene memoria suficiente para procesarlos y debe almacenarlos temporalmente en otro lugar. Hacer spilling a disco remoto es extremadamente lento y degradará significativamente el rendimiento de la consulta.
- Gran cantidad de particiones escaneadas. Al igual que con el spilling a disco remoto, leer datos desde disco remoto también es muy lento. Un número alto de particiones escaneadas significa que tu consulta tiene que hacer mucho trabajo leyendo datos remotos.
- Joins que explotan. Si ves que la cantidad de filas que salen de un join aumenta, puede indicar que especificaste mal la clave del join. Los joins que explotan suelen tardar más en procesarse y derivan en otros problemas, como spilling a disco.
- Joins cartesianos. Un join cartesiano es un cross-join, que produce un conjunto de resultados igual a la cantidad de filas de la primera tabla multiplicada por la de la segunda. Los joins cartesianos pueden colarse sin querer al usar un non equi-join, como un range join. Por el volumen de datos que producen, son lentos y suelen derivar en problemas de memoria.
- Operadores aguas abajo bloqueados por un solo CTE. Como vimos antes, Snowflake calcula cada CTE una sola vez. Si un operador depende de ese CTE, tiene que esperar a que termine de procesarse. En ciertos casos, puede convenir repetir el CTE como subconsulta para habilitar procesamiento en paralelo.
- Ordenamientos tempranos e innecesarios. Es común que los usuarios agreguen un sort innecesario al inicio de su consulta. Los sorts son costosos y conviene evitarlos a menos que sean absolutamente necesarios.
- Cálculo repetido de la misma vista. Cada vez que se referencia una vista en una consulta, esta se recalcula. Si la vista contiene joins, agregaciones o filtros costosos, a veces es más eficiente materializarla primero.
- Un Query Profile muy grande con muchos nodos. Algunas consultas tienen demasiado pasando al mismo tiempo y mejoran muchísimo con solo simplificarlas. Dividir una consulta en varias más simples es una técnica efectiva.
En próximos posts profundizaremos en cada una de estas señales y compartiremos estrategias para resolverlas.
Notas
Los 1,3 millones de registros no se envían todos de una sola vez. Snowflake tiene un motor de ejecución vectorizado. Los datos se procesan en forma de pipeline, en lotes de unos pocos miles de filas en formato columnar a la vez. Esto es lo que permite que un warehouse XSMALL con 16GB de RAM procese datasets mucho mayores a 16GB.
No le prestaría demasiada atención a lo que esta consulta calcula ni a cómo está escrita. Se creó únicamente con el fin de generar un ejemplo interesante de Query Profile.
Si te interesa mejorar tu capacidad de leer Query Profiles de Snowflake, puedes usar la consulta de ejemplo de arriba para ver cómo cada CTE se mapea a las distintas secciones del Query Profile.
Ian Whitestone·Co-founder & CEO of SELECT
Ian es Co-founder & CEO de SELECT, una plataforma SaaS de gestión y optimización de costos de Snowflake. Antes de fundar SELECT, Ian pasó 6 años liderando equipos full stack de data science y engineering en Shopify y Capital One. En Shopify, lideró los esfuerzos para optimizar su data warehouse y aumentar la observabilidad de costos.