Le Query Profile de Snowflake est la meilleure ressource dont vous disposez pour comprendre comment Snowflake exécute vos requêtes et apprendre à les améliorer. Dans cet article, nous abordons des sujets essentiels comme l'interprétation du Query Profile et les éléments à surveiller pour diagnostiquer des performances de requête décevantes.
Qu'est-ce qu'un plan de requête Snowflake ?
Avant de parler du Query Profile, il faut comprendre ce qu'est un plan de requête. Pour chaque requête SQL dans Snowflake, l'optimiseur de requêtes produit un plan de requête correspondant. Ce plan contient l'ensemble des instructions, ou étapes, nécessaires au traitement d'une instruction SQL. C'est en quelque sorte une recette de données. Comme Snowflake détermine automatiquement la manière optimale d'exécuter une requête, le plan peut différer de l'ordre logique de l'instruction SQL associée.
Dans Snowflake, le plan de requête est un DAG composé d'opérateurs reliés par des liens. Les opérateurs traitent un ensemble de lignes. Parmi les opérations possibles : scanner une table, filtrer des lignes, joindre des données, agréger, etc. Les liens transmettent les données entre opérateurs. Pour illustrer, prenons la requête suivante :
select
date_trunc('day', event_timestamp) as date,
count(*) as num_events
from events
group by 1
order by 1
Le plan de requête correspondant ressemblerait à ceci :

Ce plan comporte 4 opérateurs et 3 liens :
TableScan: lit les enregistrements de la tableeventsdans le stockage distant. Il transmet 1,3 million d'enregistrements 1 via un lien vers l'opérateur suivant.Aggregate: effectue le group by date et les opérations de comptage, puis transmet 365 enregistrements via un lien vers l'opérateur suivant.Sort: trie les données par date et transmet ces mêmes 365 enregistrements à l'opérateur final.Result: retourne les résultats de la requête.
Le Query Profile désigne souvent les opérateurs sous le nom de nœuds d'opérateur, ou simplement nœuds. On parle aussi couramment d'étapes.
Qu'est-ce que le Query Profile de Snowflake ?
Le Query Profile est une fonctionnalité de l'interface Snowflake qui offre une vue détaillée de l'exécution d'une requête. Il contient une représentation visuelle du plan de requête, avec l'ensemble des nœuds et des liens. Des détails d'exécution et des statistiques sont fournis pour chaque nœud ainsi que pour la requête dans son ensemble.
Quand l'utiliser ?
Le Query Profile s'utilise dès qu'on a besoin d'informations diagnostiques plus poussées sur une requête. Un cas courant consiste à comprendre pourquoi une requête se comporte d'une certaine manière. Le Query Profile met en évidence les étapes dont le temps de traitement est nettement plus long que les autres. Vous pouvez aussi l'utiliser pour identifier pourquoi une requête tourne encore et à quel endroit elle se bloque.
Autre usage utile : comprendre pourquoi une requête n'a pas renvoyé le résultat attendu. En examinant attentivement les liens entre les nœuds, vous pouvez repérer les parties de votre requête qui entraînent une perte de lignes ou la création de doublons, ce qui peut expliquer des résultats inattendus.
Comment consulter un Query Profile Snowflake ?
Après l'exécution d'une requête dans l'éditeur Snowsight, le volet des résultats affiche un lien vers le Query Profile :
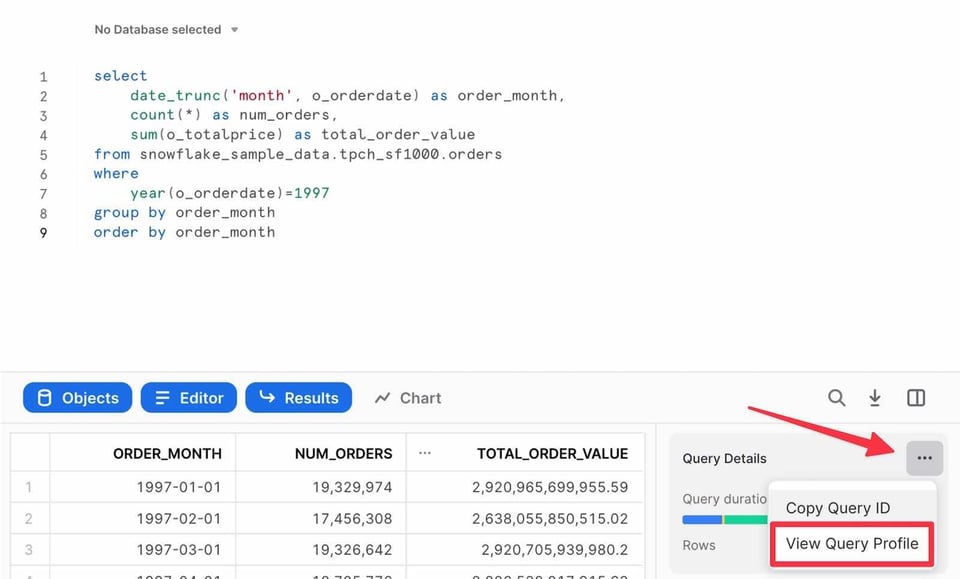
Vous pouvez également vous rendre sur la page Query History dans l'onglet Activity. Pour toute requête exécutée au cours des 14 derniers jours, il suffit de cliquer dessus pour consulter son Query Profile.
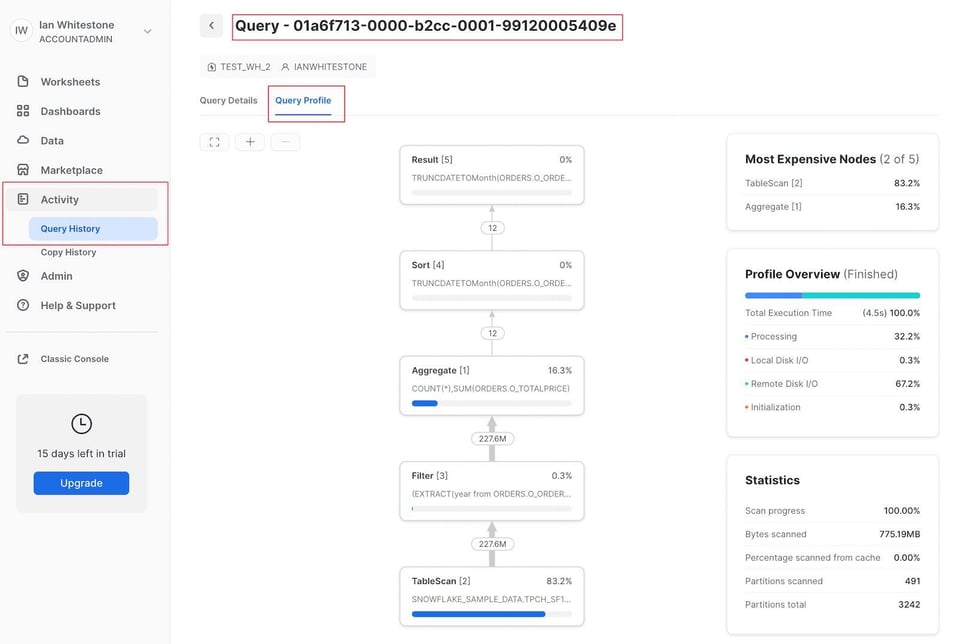
Si vous disposez déjà du query_id, vous pouvez tirer parti des URL structurées de Snowflake en complétant ce modèle :
- Modèle :
https://app.snowflake.com/<snowflake-region>/<account-locator>/compute/history/queries/<paste-query-id-here>/profile - Exemple complété :
https://app.snowflake.com/us-east4.gcp/xq35282/compute/history/queries/01a8c0a5-0000-0b5e-0000-2dd500044a26/profile
Peut-on accéder aux données du Query Profile Snowflake par programmation ?
Pas encore. Snowflake travaille activement sur une nouvelle fonctionnalité qui permettra d'interroger les données affichées dans le Query Profile. À suivre.
Comment lire un Query Profile Snowflake ?
Requête de base
Commençons par une requête simple, exécutable par tous sur le jeu de données d'exemple Snowflake :
select
date_trunc('month', o_orderdate) as order_month,
count(*) as num_orders,
sum(o_totalprice) as total_order_value
from snowflake_sample_data.tpch_sf1000.orders
where
year(o_orderdate)=1997
group by order_month
order by order_month
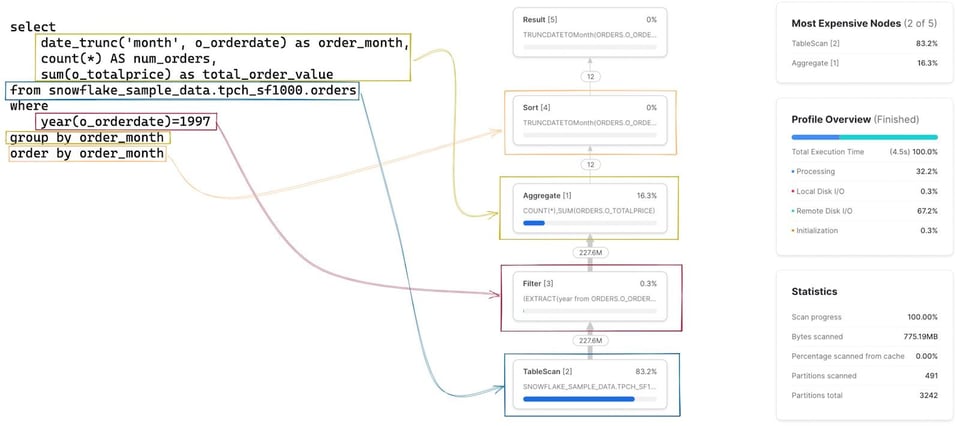
Dans un premier temps, il est essentiel de se construire un modèle mental reliant chaque étape ou opérateur du Query Profile à la requête écrite. L'exercice est délicat au début, mais devient vite naturel. Cliquer sur un nœud affiche davantage de détails sur l'opérateur — la table scannée, les agrégations effectuées, etc. — ce qui aide à retrouver le SQL associé. Le SQL correspondant à chaque opérateur est mis en évidence dans l'image ci-dessous :
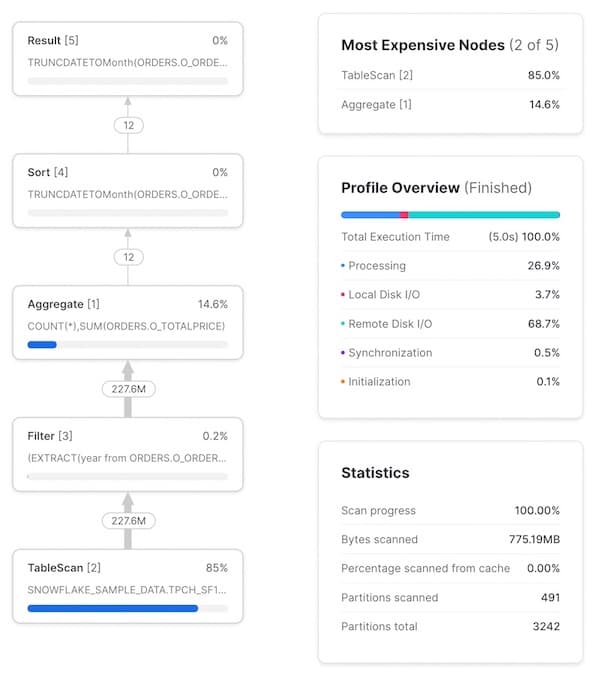
Le Query Profile contient également des statistiques utiles. En voici quelques-unes :
- Un récapitulatif du temps d'exécution. Il indique le pourcentage du temps total d'exécution consacré à différentes catégories. Les 4 options listées sont :
- Processing : temps consacré aux opérations de traitement comme les jointures, agrégations, filtres, tris, etc.
- Local Disk I/O : temps consacré à la lecture/écriture de données depuis/vers le stockage SSD local. Cela inclut par exemple le spilling sur disque ou la lecture de données mises en cache sur le SSD local.
- Remote Disk I/O : temps consacré à la lecture/écriture de données depuis/vers le stockage distant (c.-à-d. S3 ou Azure Blob storage). Cela inclut par exemple le spilling vers le disque distant ou la lecture de vos jeux de données.
- Initialization : coût d'overhead lié au démarrage de la requête sur le warehouse. D'après notre expérience, il est toujours extrêmement faible et relativement constant.
- Statistiques de requête. On y trouve par exemple le nombre de partitions scannées sur le total de partitions possibles. Notez que cela couvre l'ensemble des tables de la requête. Moins il y a de partitions scannées, plus le pruning de la requête est efficace. Si votre warehouse manque de mémoire pour traiter la requête et effectue du spilling sur disque, l'information apparaît également ici.
- Nombre d'enregistrements échangés entre chaque nœud. Cette information est très utile pour comprendre le volume de données traitées et la façon dont chaque nœud réduit (ou augmente) ce volume.
- Pourcentage du temps total d'exécution passé sur chaque nœud. Affiché en haut à droite de chaque nœud, il indique la part du temps total d'exécution consacrée à cet opérateur. Dans cet exemple, 83,2 % du temps total d'exécution est passé sur l'opérateur
TableScan. Cette information alimente la liste Most Expensive Nodes en haut à droite du Query Profile, qui se contente de trier les nœuds selon ce pourcentage.
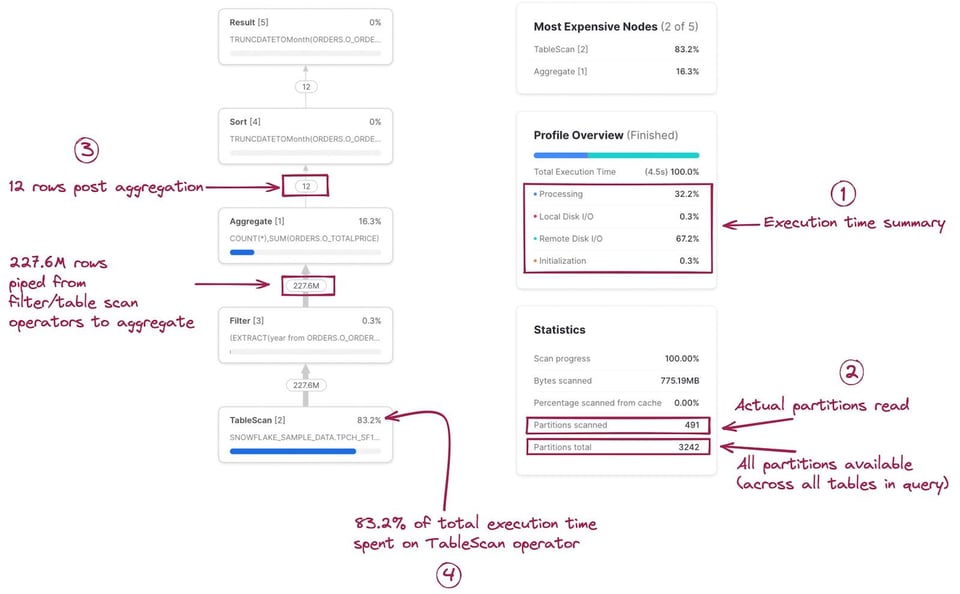
Vous remarquerez peut-être que le nombre de lignes entrant et sortant du nœud Filter est identique, ce qui pourrait laisser penser que le code SQL year(o_orderdate)=1997 n'a servi à rien. Le filtre élimine pourtant bien des enregistrements, puisque cette table en contient 1,5 milliard. C'est un écueil regrettable du Query Profile : il n'indique pas le nombre exact d'enregistrements supprimés par un filtre donné.
Comme évoqué plus haut, cliquer sur un nœud révèle des détails et statistiques d'exécution supplémentaires. À gauche, le résultat d'un clic sur l'opérateur TableScan. À droite, celui de l'opérateur Aggregate.
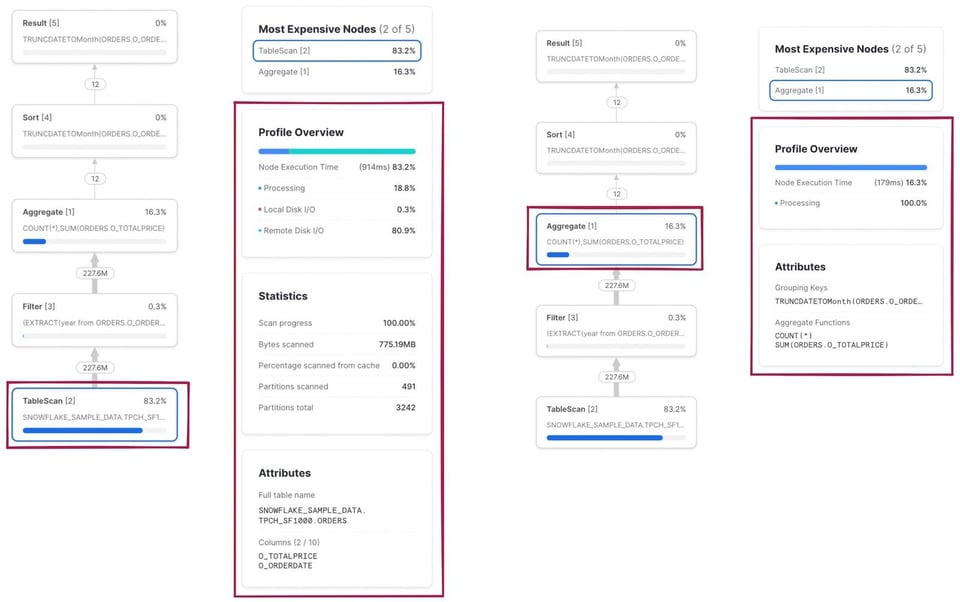
Requête multi-étapes
En modifiant le filtre de la requête précédente pour y inclure une sous-requête, on obtient une requête multi-étapes.
select
date_trunc('month', o_orderdate) as order_month,
count(*) as num_orders,
sum(o_totalprice) as total_order_value
from snowflake_sample_data.tpch_sf1000.orders
where
o_totalprice > (select avg(o_totalprice) from snowflake_sample_data.tpch_sf1000.orders)
group by order_month
order by order_month
Contrairement à l'exemple précédent, le plan de requête comporte désormais deux étapes. D'abord, Snowflake exécute la sous-requête et calcule la moyenne de o_totalprice. Le résultat est stocké, puis réutilisé dans la seconde étape, qui mobilise les mêmes 5 opérateurs que la requête précédente.
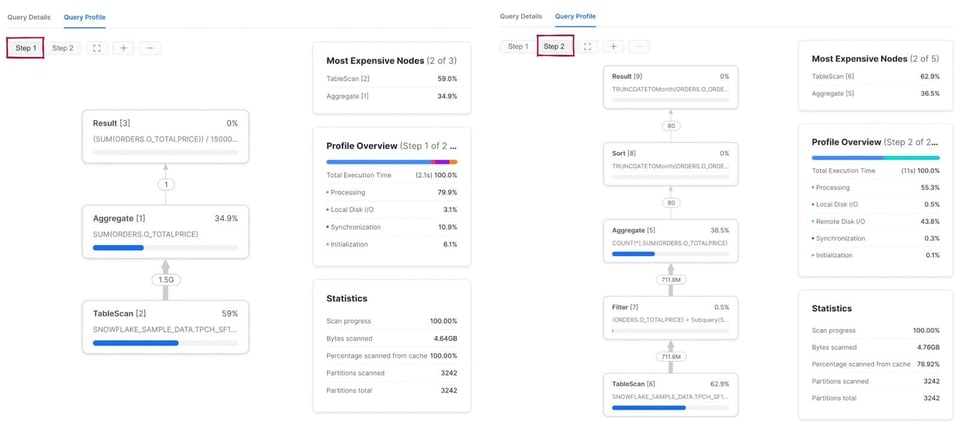
Requête complexe
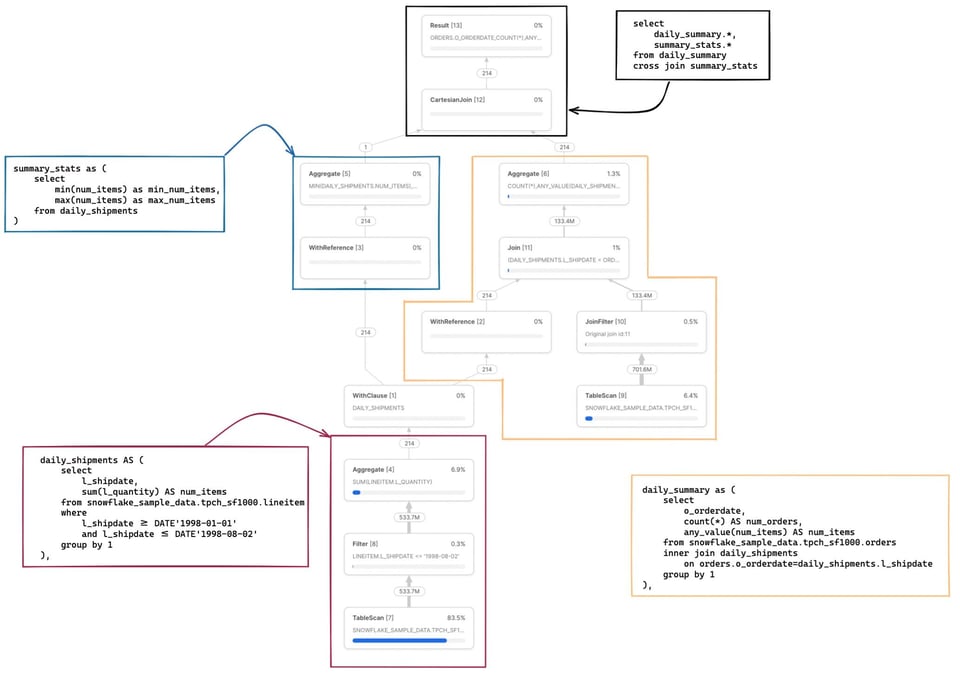
Voici une requête légèrement plus complexe 2, avec plusieurs CTE, dont l'une est référencée à deux endroits différents.
with
daily_shipments AS (
select
l_shipdate,
sum(l_quantity) AS num_items
from snowflake_sample_data.tpch_sf1000.lineitem
where
l_shipdate >= DATE'1998-01-01'
and l_shipdate <= DATE'1998-08-02'
group by 1
),
daily_summary as (
select
o_orderdate,
count(*) AS num_orders,
Développer le code
Plusieurs points méritent d'être soulignés dans cet exemple. Tout d'abord, le CTE daily_shipments n'est calculé qu'une seule fois. Tout SQL en aval qui référence ce CTE fait appel à l'opérateur WithReference pour accéder à ses résultats plutôt que de le recalculer à chaque fois.
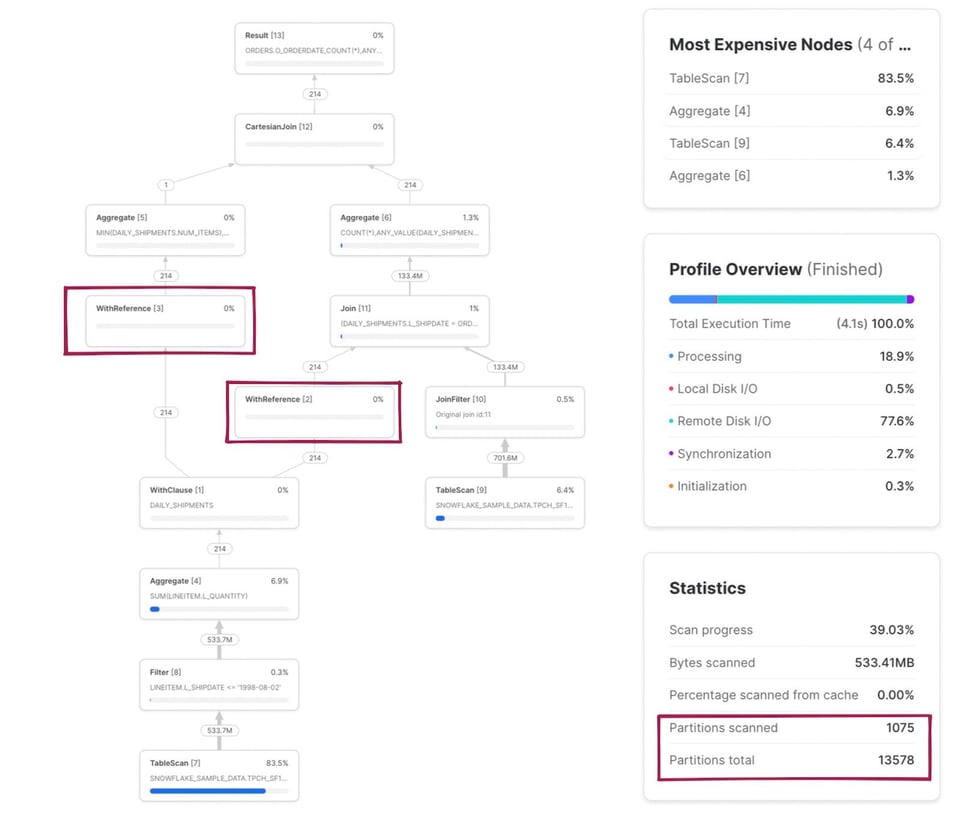
La métrique partitions scannées/totales combine désormais les deux tables lues dans la requête. Si l'on clique sur le nœud TableScan de la table snowflake_sample_data.tpch_sf1000.orders, on constate que la table est bien prunée : seules 154 partitions sur 3242 sont scannées. Comment ce pruning peut-il s'opérer alors qu'aucun filtre where explicite n'est écrit dans le SQL ? C'est l'opérateur JoinFilter à l'œuvre. Snowflake applique automatiquement cette optimisation astucieuse : il détermine durant l'exécution la plage de dates issue du CTE daily_shipments, puis l'applique comme filtre sur la table orders, puisque la requête utilise un inner join !
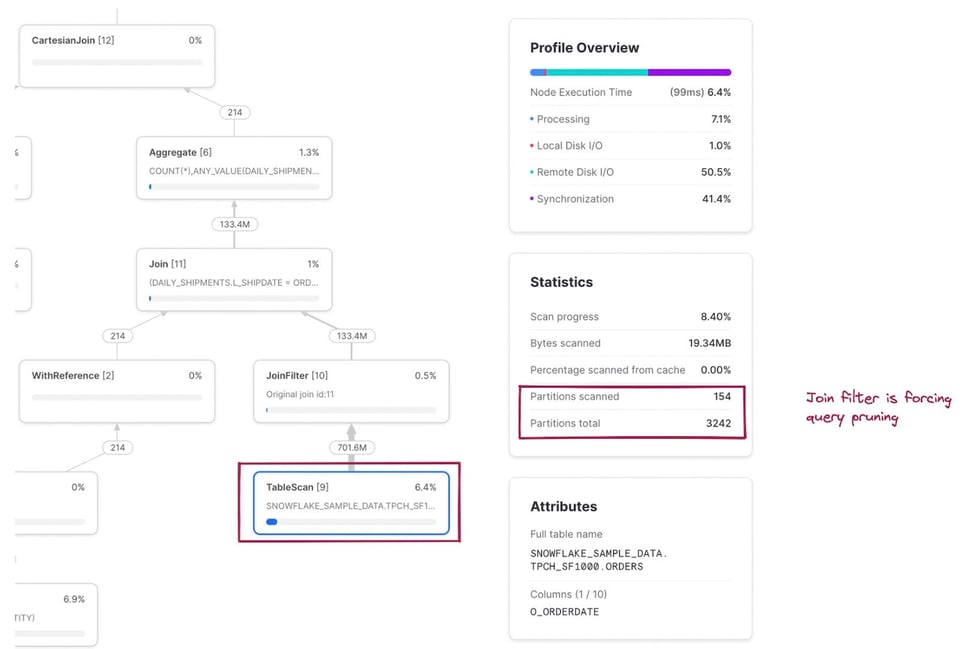
La correspondance complète entre le code SQL et les nœuds d'opérateurs concernés figure dans les notes ci-dessous 3.
Quels éléments rechercher dans le Query Profile Snowflake ?
L'usage le plus courant du Query Profile consiste à comprendre pourquoi une requête particulière manque de performance. Maintenant que les bases sont posées, voici quelques indicateurs à surveiller dans le Query Profile comme coupables potentiels de mauvaises performances :
- Spilling important vers le disque distant. Dès qu'il y a du data spilling, c'est que votre warehouse manque de mémoire pour traiter les données et doit les stocker temporairement ailleurs. Le spilling vers le disque distant est extrêmement lent et dégrade significativement les performances de la requête.
- Nombre élevé de partitions scannées. Comme pour le spilling vers le disque distant, lire des données depuis le disque distant est très lent. Un grand nombre de partitions scannées signifie que votre requête doit fournir beaucoup de travail pour lire des données distantes.
- Jointures qui explosent. Si le nombre de lignes en sortie d'une jointure augmente, c'est souvent le signe que la clé de jointure a été mal spécifiée. Les jointures qui explosent prennent généralement plus de temps à traiter et entraînent d'autres problèmes, comme le spilling sur disque.
- Jointures cartésiennes. Une jointure cartésienne est un cross-join qui produit un résultat dont le nombre de lignes est égal au nombre de lignes de la première table multiplié par celui de la seconde. Les jointures cartésiennes peuvent être introduites involontairement avec une non equi-join, comme une range join. En raison du volume de données produit, elles sont à la fois lentes et entraînent souvent des problèmes d'out-of-memory.
- Opérateurs en aval bloqués par un seul CTE. Comme indiqué plus haut, Snowflake ne calcule chaque CTE qu'une seule fois. Si un opérateur dépend de ce CTE, il doit attendre la fin de son traitement. Dans certains cas, il peut être plus avantageux de répéter le CTE sous forme de sous-requête pour autoriser un traitement parallèle.
- Tris inutiles en début de requête. Il arrive fréquemment qu'un tri superflu soit ajouté tôt dans la requête. Les tris sont coûteux et doivent être évités sauf nécessité absolue.
- Calcul répété d'une même vue. Chaque fois qu'une vue est référencée dans une requête, elle doit être calculée. Si elle contient des jointures, agrégations ou filtres coûteux, il peut être plus efficace de la matérialiser au préalable.
- Un Query Profile très volumineux, avec un grand nombre de nœuds. Certaines requêtes en font tout simplement trop et peuvent être nettement améliorées par une simplification. Décomposer une requête en plusieurs requêtes plus simples est une technique efficace.
Dans de prochains articles, nous explorerons chacun de ces signaux plus en détail et partagerons des stratégies pour les résoudre.
Notes
Les 1,3 million d'enregistrements ne sont pas transmis d'un seul coup. Snowflake dispose d'un moteur d'exécution vectorisé. Les données sont traitées en pipeline, par lots de quelques milliers de lignes au format columnar. C'est ce qui permet à un warehouse XSMALL doté de 16 Go de RAM de traiter des jeux de données bien plus volumineux que 16 Go.
Ne prêtez pas trop attention à ce que cette requête calcule ni à la façon dont elle est écrite. Elle a été conçue uniquement pour produire un exemple de query profile intéressant.
Pour les lecteurs qui souhaitent progresser dans la lecture des Query Profiles Snowflake, l'exemple de requête ci-dessus permet de voir comment chaque CTE correspond aux différentes sections du Query Profile.
Ian Whitestone·Co-fondateur et CEO de SELECT
Ian est co-fondateur et CEO de SELECT, une plateforme SaaS de gestion et d'optimisation des coûts Snowflake. Avant de lancer SELECT, Ian a passé 6 ans à diriger des équipes full stack de data science et d'engineering chez Shopify et Capital One. Chez Shopify, il a piloté l'optimisation du data warehouse et l'amélioration de l'observabilité des coûts.