O Snowflake Query Profile é o melhor recurso para entender como o Snowflake está executando sua query e descobrir como melhorá-la. Neste post, abordamos temas importantes como interpretar o Query Profile e o que observar ao diagnosticar problemas de performance de queries.
O que é um query plan no Snowflake?
Antes de falar do Query Profile, é importante entender o que é um "query plan". Para cada query SQL no Snowflake, existe um query plan correspondente, produzido pelo otimizador de queries. Esse plano contém o conjunto de instruções (ou "passos") necessárias para processar qualquer instrução SQL. É como uma receita de dados. Como o Snowflake descobre automaticamente a melhor forma de executar uma query, o query plan pode parecer diferente da ordem lógica da instrução SQL correspondente.
No Snowflake, o query plan é um DAG formado por operadores conectados por links. Os operadores processam um conjunto de linhas. Exemplos de operações: escanear uma tabela, filtrar linhas, fazer joins, agregar, etc. Os links passam dados entre os operadores. Para deixar isso mais concreto, veja a query a seguir:
select
date_trunc('day', event_timestamp) as date,
count(*) as num_events
from events
group by 1
order by 1
O query plan correspondente seria mais ou menos assim:

Neste plano há 4 "operadores" e 3 "links":
TableScan: lê os registros da tabelaeventsno armazenamento remoto. Ele passa 1,3 milhão de registros 1 por um link para o próximo operador.Aggregate: executa as operações de group by date e count e passa 365 registros por um link para o próximo operador.Sort: ordena os dados por data e passa os mesmos 365 registros para o operador final.Result: retorna os resultados da query.
O Query Profile costuma se referir aos operadores como "nós operadores" ou simplesmente "nós". Também é comum chamá-los de "estágios".
O que é o Snowflake Query Profile?
O Query Profile é um recurso da interface do Snowflake que traz insights detalhados sobre a execução de uma query. Ele inclui uma representação visual do query plan, com todos os nós e links. Detalhes de execução e estatísticas são exibidos tanto para cada nó quanto para a query como um todo.
Quando devo usar?
O Query Profile deve ser usado sempre que você precisar de mais informações de diagnóstico sobre uma query. Um exemplo comum é entender por que uma query está se comportando de determinada forma. O Query Profile ajuda a revelar estágios da query que demoram bem mais do que os outros para serem processados. Da mesma forma, dá para usar o Query Profile para descobrir por que uma query continua rodando e onde ela está travando.
Outra aplicação útil do Query Profile é descobrir por que uma query não retornou o resultado esperado. Analisando com atenção os links entre os nós, você pode identificar partes da query que estão eliminando linhas ou gerando duplicatas, o que pode explicar resultados inesperados.
Como visualizar um Snowflake Query Profile?
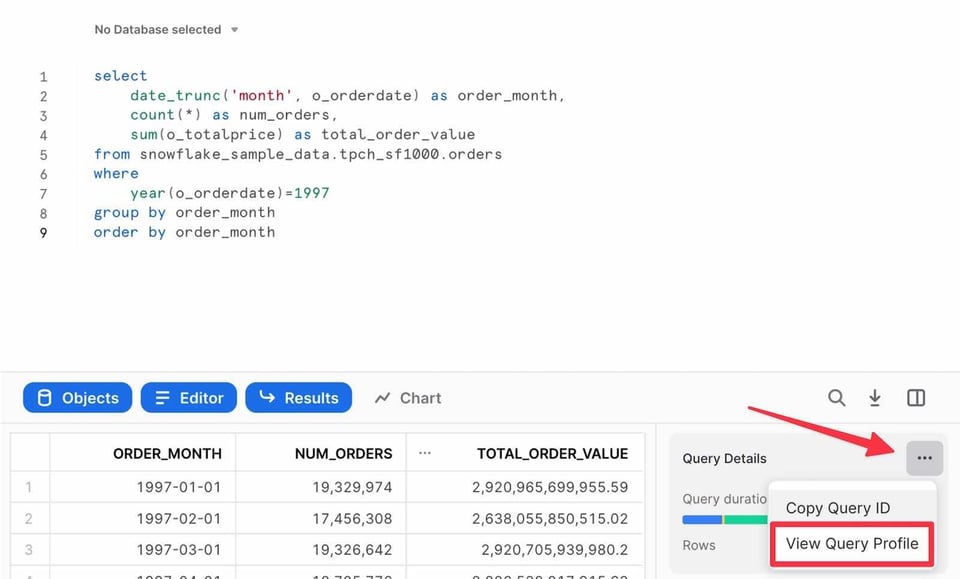
Depois de rodar uma query no editor do Snowsight, o painel de resultados vai mostrar um link para o Query Profile:
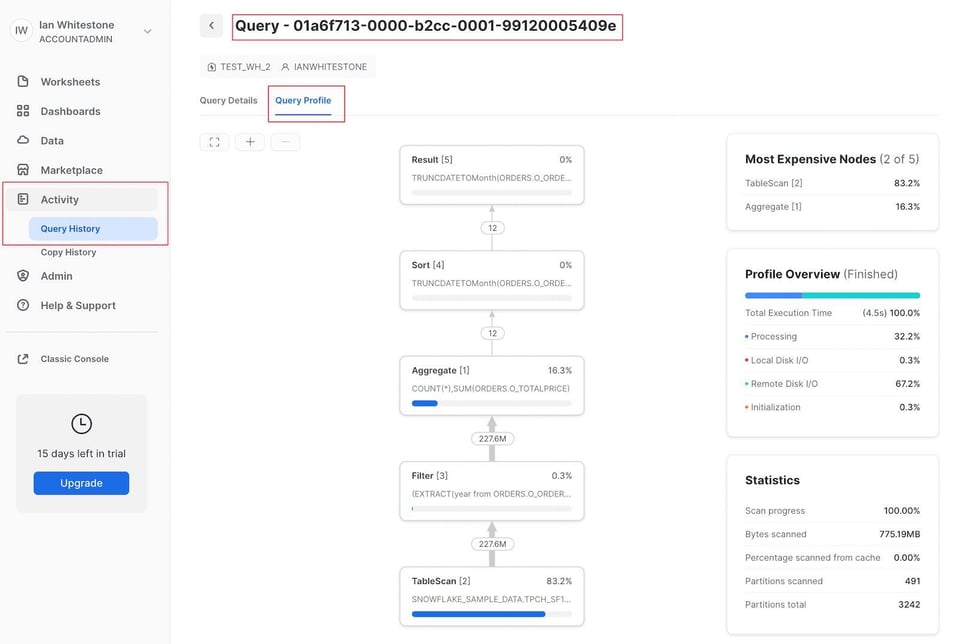
Outra opção é acessar a página "Query History" na aba "Activity". Para qualquer query executada nos últimos 14 dias, basta clicar nela para ver o Query Profile.
Se você já tiver o query_id em mãos, pode aproveitar as URLs estruturadas do Snowflake preenchendo este modelo:
- Modelo:
https://app.snowflake.com/<snowflake-region>/<account-locator>/compute/history/queries/<paste-query-id-here>/profile - Exemplo preenchido:
https://app.snowflake.com/us-east4.gcp/xq35282/compute/history/queries/01a8c0a5-0000-0b5e-0000-2dd500044a26/profile
Dá para acessar os dados do Snowflake Query Profile via código?
Ainda não. O Snowflake está trabalhando em um novo recurso para permitir que os usuários consultem os dados exibidos no Query Profile. Fique de olho.
Como ler um Snowflake Query Profile?
Query básica
Vamos começar com uma query simples que qualquer pessoa pode executar no dataset de exemplo do Snowflake:
select
date_trunc('month', o_orderdate) as order_month,
count(*) as num_orders,
sum(o_totalprice) as total_order_value
from snowflake_sample_data.tpch_sf1000.orders
where
year(o_orderdate)=1997
group by order_month
order by order_month
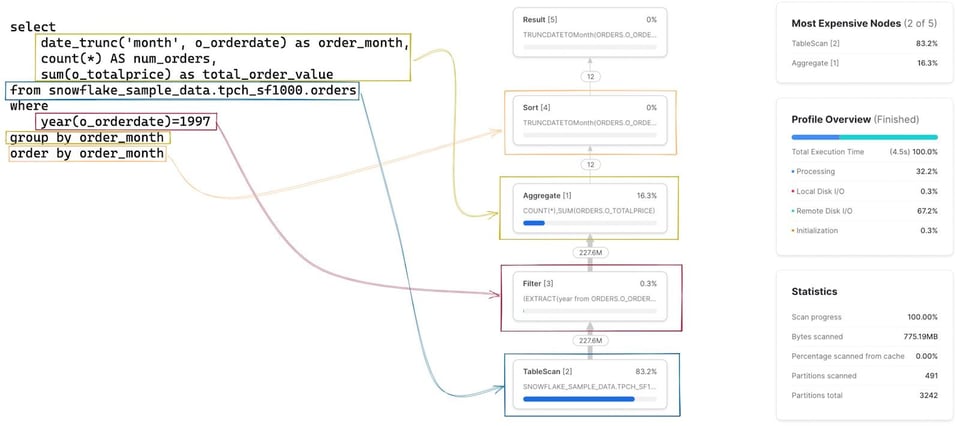
O primeiro passo é montar um modelo mental de como cada estágio/operador do Query Profile se relaciona com a query que você escreveu. No começo dá trabalho, mas fica rápido depois que você pega o jeito. Clicar em cada nó mostra mais detalhes sobre o operador, como a tabela que está sendo escaneada ou as agregações executadas, o que ajuda a identificar o SQL correspondente. O SQL relacionado a cada operador está destacado na imagem abaixo:
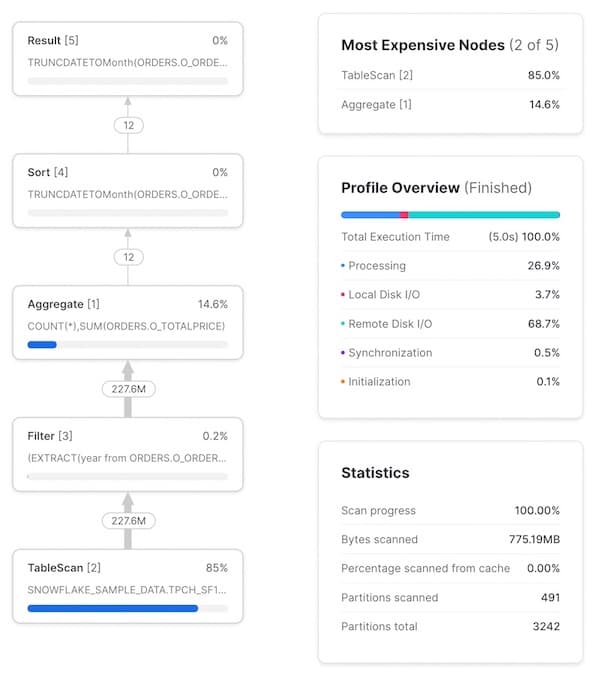
O Query Profile também traz estatísticas úteis. Algumas que vale destacar:
- Um resumo do tempo de execução. Mostra qual % do tempo total de execução da query foi gasto em cada categoria. As 4 opções listadas aqui são:
- Processing: tempo gasto em operações de processamento da query, como joins, agregações, filtros, ordenações, etc.
- Local Disk I/O: tempo gasto lendo/escrevendo dados no armazenamento SSD local. Inclui coisas como spilling para o disco ou leitura de dados em cache no SSD local.
- Remote Disk I/O: tempo gasto lendo/escrevendo dados no armazenamento remoto (ou seja, S3 ou Azure Blob storage). Inclui coisas como spilling para o disco remoto ou leitura dos seus datasets.
- Initialization: é o custo de overhead para iniciar a query no warehouse. Na nossa experiência, esse valor é sempre bem pequeno e relativamente constante.
- Estatísticas da query. Aqui você encontra informações como o número de partições escaneadas em relação ao total de partições possíveis. Vale lembrar que esse número considera todas as tabelas da query. Quanto menos partições escaneadas, melhor está o pruning da query. Se o warehouse não tiver memória suficiente para processar a query e estiver fazendo spilling para o disco, isso também vai aparecer aqui.
- Número de registros trocados entre os nós. Essa informação ajuda bastante a entender o volume de dados sendo processado e como cada nó reduz (ou amplia) esse número.
- Porcentagem do tempo total de execução gasto em cada nó. Exibida no canto superior direito de cada nó, indica o percentual do tempo total de execução consumido por aquele operador. Neste exemplo, 83,2% do tempo total de execução foi gasto no operador
TableScan. Essa informação alimenta a lista "Most Expensive Nodes" no canto superior direito do Query Profile, que ordena os nós pelo percentual do tempo total de execução.
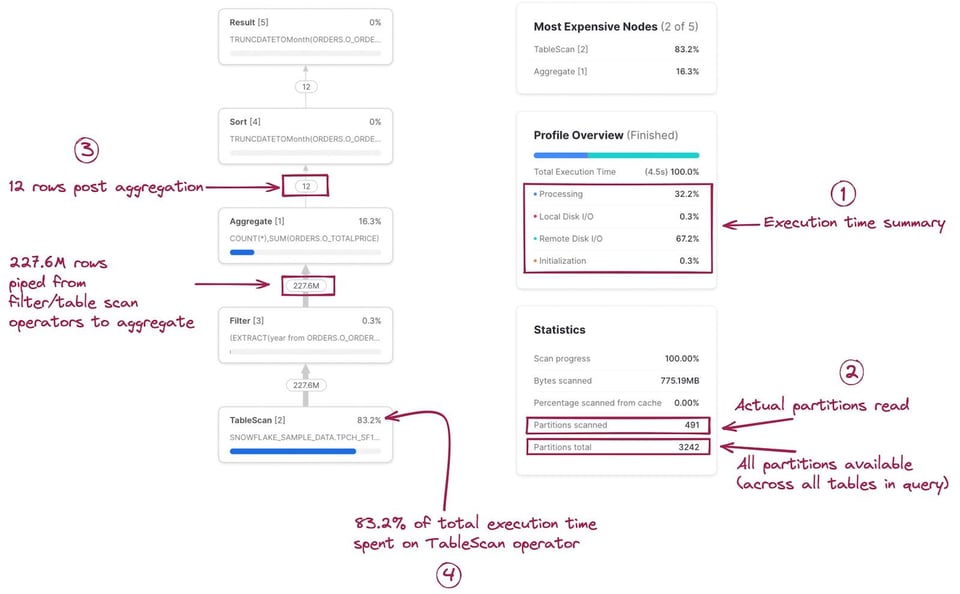
Você pode reparar que o número de linhas que entram e saem do nó Filter é o mesmo, dando a impressão de que o SQL year(o_orderdate)=1997 não fez nada. Mas o filtro está, sim, eliminando registros, já que essa tabela tem 1,5 bilhão de registros. Essa é uma limitação chata do Query Profile: ele não mostra o número exato de registros removidos por um determinado filtro.
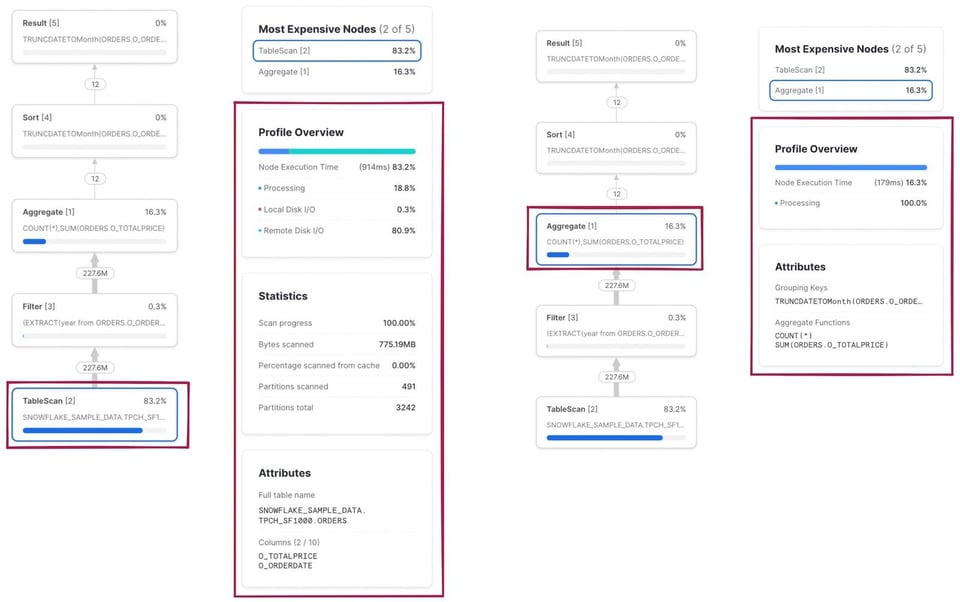
Como já mencionamos, dá para clicar em cada nó para ver detalhes adicionais de execução e estatísticas. À esquerda, você vê o resultado de clicar no operador TableScan. À direita, aparecem os resultados do operador Aggregate.
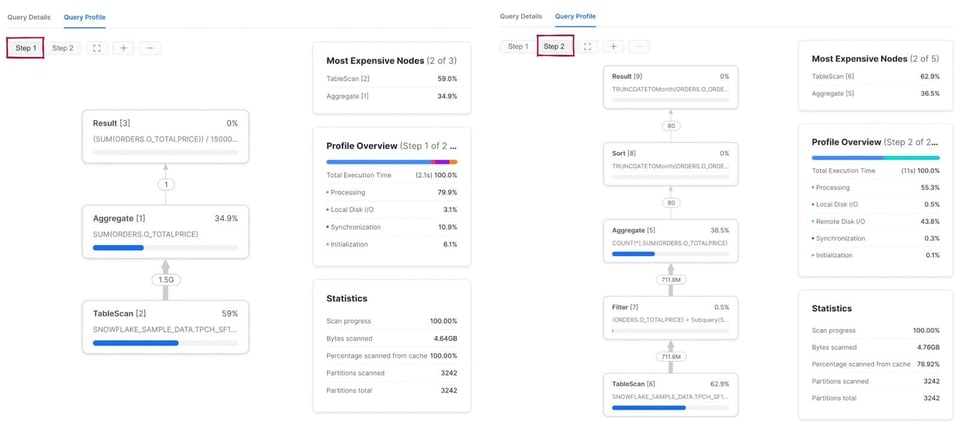
Query com vários passos
Se modificarmos o filtro da query acima para incluir uma subquery, chegamos a uma query com vários passos.
select
date_trunc('month', o_orderdate) as order_month,
count(*) as num_orders,
sum(o_totalprice) as total_order_value
from snowflake_sample_data.tpch_sf1000.orders
where
o_totalprice > (select avg(o_totalprice) from snowflake_sample_data.tpch_sf1000.orders)
group by order_month
order by order_month
Diferente do caso anterior, o query plan agora tem dois passos. Primeiro, o Snowflake executa a subquery e calcula a média de o_totalprice. O resultado fica armazenado e é usado no segundo passo da query, que tem os mesmos 5 operadores da query anterior.
Query complexa
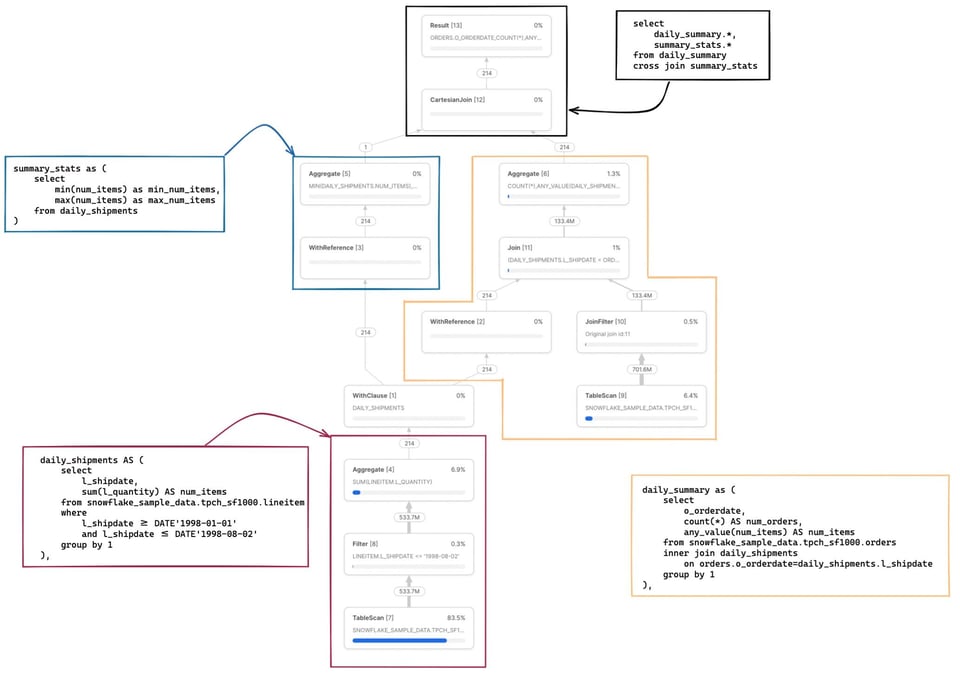
Veja uma query um pouco mais complexa 2 com várias CTEs, sendo uma delas referenciada em outros dois lugares.
with
daily_shipments AS (
select
l_shipdate,
sum(l_quantity) AS num_items
from snowflake_sample_data.tpch_sf1000.lineitem
where
l_shipdate >= DATE'1998-01-01'
and l_shipdate <= DATE'1998-08-02'
group by 1
),
daily_summary as (
select
o_orderdate,
count(*) AS num_orders,
Expandir código
Há alguns pontos que vale destacar neste exemplo. Primeiro, a CTE daily_shipments é calculada apenas uma vez. Qualquer SQL downstream que referencie essa CTE chama o operador WithReference para acessar os resultados, em vez de recalculá-los a cada referência.
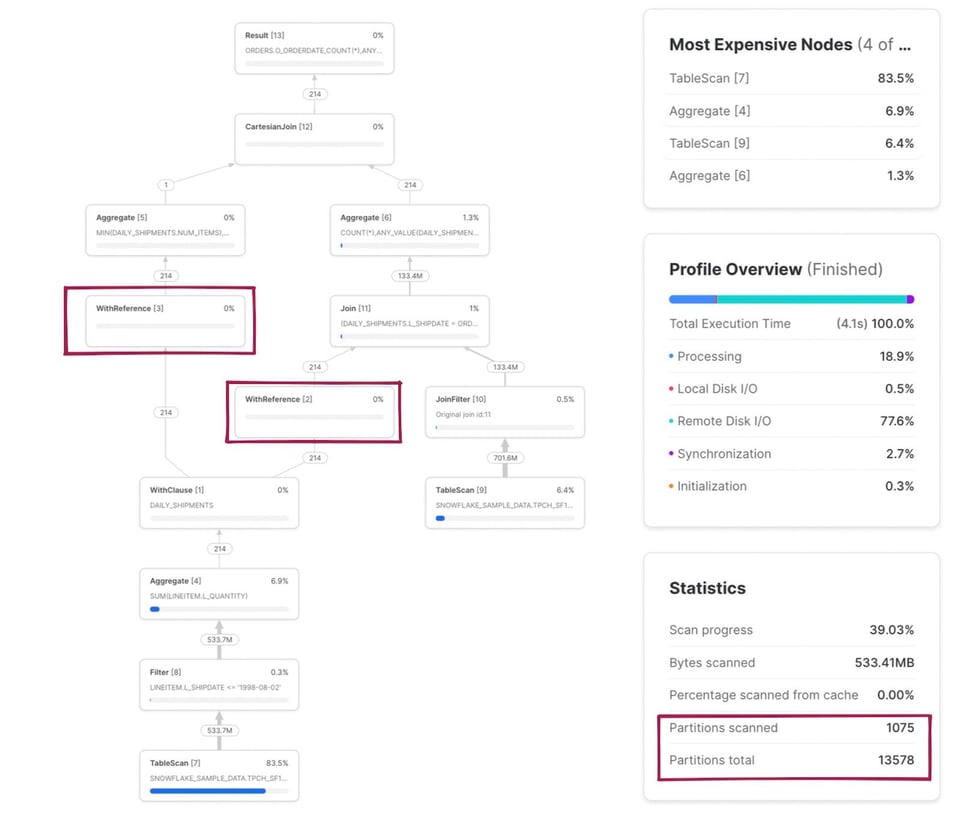
A métrica de partições escaneadas/total agora é uma combinação das duas tabelas lidas na query. Se clicarmos no nó TableScan da tabela snowflake_sample_data.tpch_sf1000.orders, dá para ver que a tabela está sendo bem podada, com apenas 154 de 3242 partições escaneadas. Como esse pruning acontece se não há um filtro where explícito no SQL? É o operador JoinFilter em ação. O Snowflake aplica automaticamente essa otimização inteligente: durante a execução da query, ele identifica o intervalo de datas da CTE daily_shipments e aplica esse intervalo como filtro na tabela orders, já que a query usa um inner join!
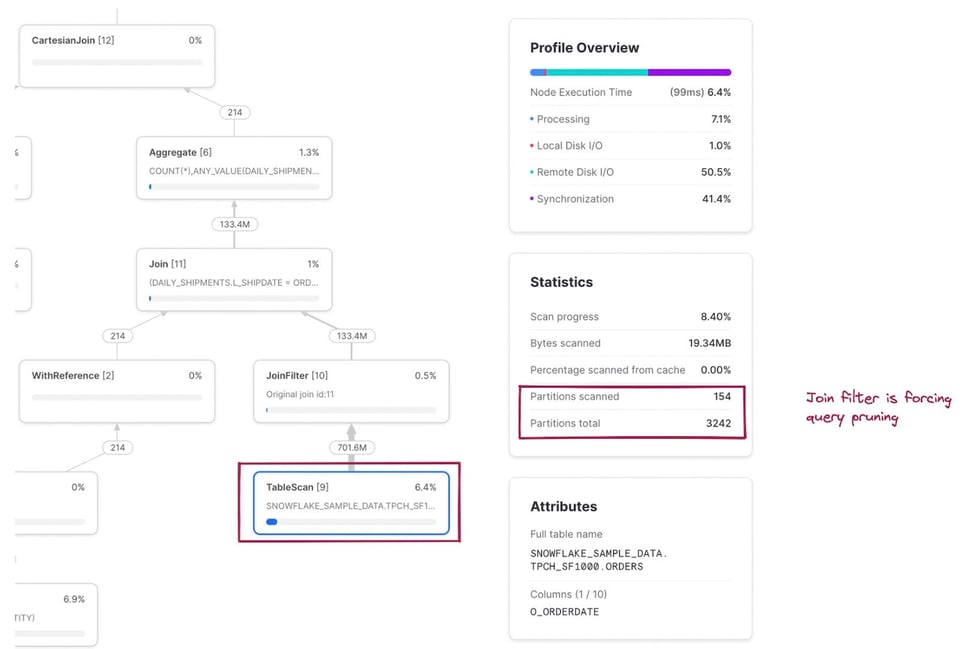
O mapeamento completo do código SQL para os nós operadores correspondentes está nas notas abaixo 3.
O que observar no Snowflake Query Profile?
O caso de uso mais comum do Query Profile é entender por que uma determinada query não está performando bem. Agora que cobrimos os fundamentos, veja alguns indicadores que você pode buscar no Query Profile como possíveis culpados por uma performance ruim:
- Muito spillage para o disco remoto. Assim que aparece qualquer spillage de dados, significa que seu warehouse não tem memória suficiente para processá-los e precisa armazená-los temporariamente em outro lugar. Fazer spilling de dados para o disco remoto é extremamente lento e degrada bastante a performance da query.
- Grande número de partições escaneadas. Assim como o spilling para o disco remoto, ler dados do disco remoto também é muito lento. Um grande número de partições escaneadas significa que a query precisa fazer muito trabalho lendo dados remotos.
- Joins explosivos. Se você vê o número de linhas saindo de um join aumentar, isso pode indicar que a chave de join foi especificada incorretamente. Joins explosivos costumam demorar mais para processar e levam a outros problemas, como spilling para o disco.
- Cartesian joins. Um cartesian join é um cross-join, que gera um conjunto de resultados igual ao número de linhas da primeira tabela multiplicado pelo número de linhas da segunda. Cartesian joins podem ser introduzidos sem querer ao usar um non equi-join, como um range join. Por causa do volume de dados gerado, eles são lentos e frequentemente causam problemas de out-of-memory.
- Operadores downstream bloqueados por uma única CTE. Como mencionamos, o Snowflake calcula cada CTE uma vez. Se um operador depende dessa CTE, ele precisa esperar o processamento terminar. Em certos casos, pode ser mais vantajoso repetir a CTE como uma subquery para permitir processamento paralelo.
- Ordenação antecipada e desnecessária. É comum os usuários adicionarem um sort desnecessário logo no início da query. Sorts são caros e devem ser evitados, a não ser que sejam absolutamente necessários.
- Cálculo repetido da mesma view. Toda vez que uma view é referenciada em uma query, ela precisa ser calculada. Se a view tem joins, agregações ou filtros caros, às vezes é mais eficiente materializá-la antes.
- Um Query Profile gigante, com muitos nós. Algumas queries simplesmente têm coisa demais acontecendo e podem melhorar muito se forem simplificadas. Quebrar uma query em várias queries menores e mais simples é uma técnica eficaz.
Em posts futuros, vamos aprofundar cada um desses sinais e compartilhar estratégias para resolvê-los.
Notas
Nem todos os 1,3 milhão de registros são enviados de uma vez. O Snowflake tem um motor de execução vetorizado. Os dados são processados em pipeline, em lotes de alguns milhares de linhas em formato colunar por vez. É isso que permite que um warehouse XSMALL com 16GB de RAM processe datasets muito maiores que 16GB.
Não daria muita atenção ao que essa query está calculando ou à forma como ela foi escrita. Ela foi criada apenas para gerar um exemplo interessante de query profile.
Para quem quer melhorar a habilidade de ler Snowflake Query Profiles, dá para usar a query de exemplo acima para ver como cada CTE se mapeia para as diferentes seções do Query Profile.
Ian Whitestone·Co-founder & CEO da SELECT
Ian é Co-founder & CEO da SELECT, uma plataforma SaaS de gestão e otimização de custos do Snowflake. Antes de fundar a SELECT, Ian passou 6 anos liderando times de full stack data science & engineering na Shopify e na Capital One. Na Shopify, Ian liderou os esforços para otimizar o data warehouse e aumentar a observabilidade de custos.