Il Query Profile di Snowflake è la risorsa migliore a disposizione per capire come Snowflake esegue una query e per imparare a ottimizzarla. In questo articolo affrontiamo temi chiave come l'interpretazione del Query Profile e gli aspetti da analizzare per diagnosticare problemi di performance delle query.
Che cos'è un query plan di Snowflake?
Prima di parlare del Query Profile è importante capire che cos'è un "query plan". Per ogni query SQL in Snowflake esiste un query plan corrispondente, generato dall'ottimizzatore. Il piano contiene l'insieme di istruzioni, o "passaggi", necessari per elaborare una qualsiasi istruzione SQL: una sorta di ricetta per i dati. Poiché Snowflake individua automaticamente il modo ottimale per eseguire una query, il query plan può differire dall'ordine logico dell'istruzione SQL associata.
In Snowflake, il query plan è un DAG formato da operatori collegati da link. Gli operatori elaborano un insieme di righe: esempi tipici sono la scansione di una tabella, il filtraggio delle righe, il join dei dati, l'aggregazione e così via. I link trasferiscono i dati tra un operatore e l'altro. Per rendere il concetto più concreto, consideri questa query:
select
date_trunc('day', event_timestamp) as date,
count(*) as num_events
from events
group by 1
order by 1
Il query plan corrispondente sarà più o meno così:

In questo piano ci sono 4 "operatori" e 3 "link":
TableScan: legge i record dalla tabellaeventsnello storage remoto e ne passa 1,3 milioni 1 tramite un link all'operatore successivo.Aggregate: esegue il group by per data e il count, passando 365 record tramite un link all'operatore successivo.Sort: ordina i dati per data e passa gli stessi 365 record all'operatore finale.Result: restituisce i risultati della query.
Nel Query Profile gli operatori vengono spesso chiamati "operator node" o, in breve, "node". È altrettanto frequente trovarli indicati come "stage".
Che cos'è il Query Profile di Snowflake?
Il Query Profile è una funzionalità della UI di Snowflake che offre informazioni dettagliate sull'esecuzione di una query. Mostra una rappresentazione visiva del query plan, con tutti i nodi e i link, e fornisce dettagli e statistiche di esecuzione sia per ogni singolo nodo sia per la query nel complesso.
Quando conviene usarlo?
Il Query Profile è utile ogni volta che servono informazioni diagnostiche più approfondite su una query. Un caso tipico è capire perché una query si comporta in un determinato modo: il Query Profile aiuta a individuare le fasi che richiedono molto più tempo delle altre. Allo stesso modo, lo si può usare per capire perché una query è ancora in esecuzione e dove si è impuntata.
Un'altra applicazione preziosa è capire perché una query non ha restituito il risultato atteso. Analizzando con attenzione i link tra i nodi è possibile individuare i punti della query in cui si generano righe perse o duplicate, spesso all'origine di risultati inattesi.
Come si visualizza un Query Profile di Snowflake?
Dopo aver eseguito una query nell'editor Snowsight, il pannello dei risultati mostra un link al Query Profile:
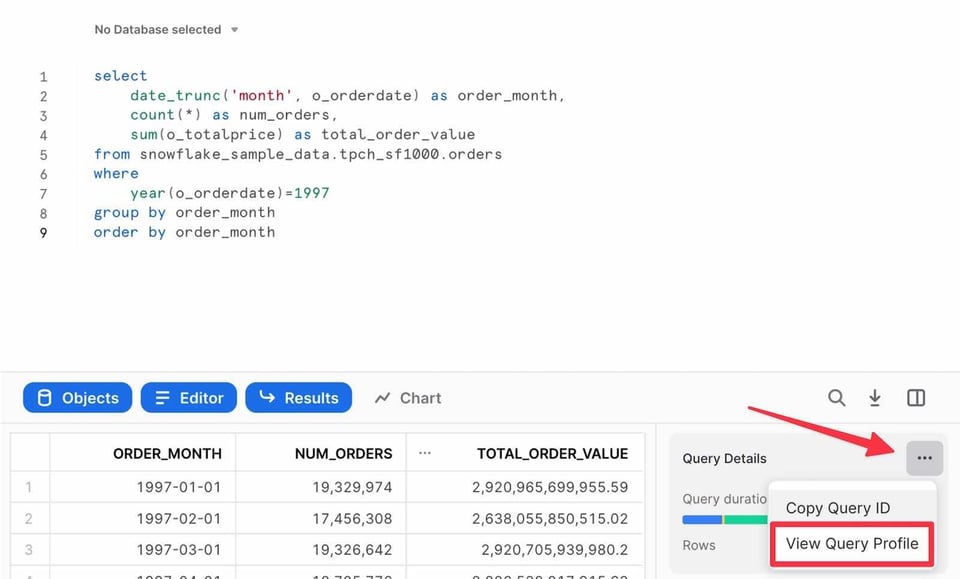
In alternativa, può accedere alla pagina "Query History" nella scheda "Activity". Per qualsiasi query eseguita negli ultimi 14 giorni basta selezionarla per visualizzarne il Query Profile.
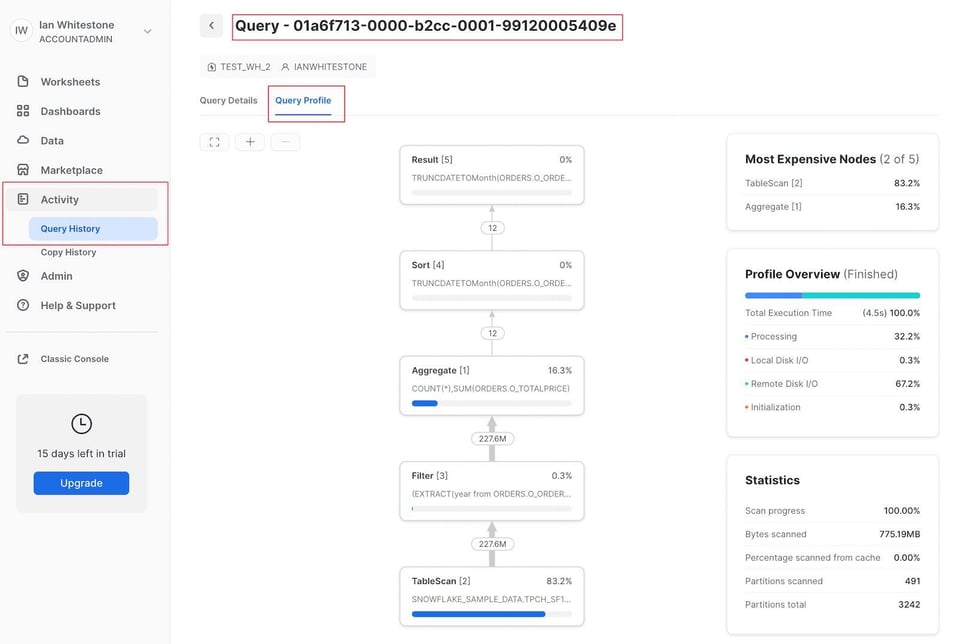
Se ha già a portata di mano il query_id, può sfruttare gli URL strutturati di Snowflake compilando questo template:
- Template:
https://app.snowflake.com/<snowflake-region>/<account-locator>/compute/history/queries/<paste-query-id-here>/profile - Esempio compilato:
https://app.snowflake.com/us-east4.gcp/xq35282/compute/history/queries/01a8c0a5-0000-0b5e-0000-2dd500044a26/profile
È possibile accedere ai dati del Query Profile di Snowflake in modo programmatico?
Non ancora. Snowflake sta lavorando attivamente a una nuova funzionalità che consentirà agli utenti di interrogare i dati mostrati nel Query Profile. Restate sintonizzati.
Come si legge un Query Profile di Snowflake?
Query di base
Partiamo da una query semplice, che chiunque può eseguire sul dataset di esempio di Snowflake:
select
date_trunc('month', o_orderdate) as order_month,
count(*) as num_orders,
sum(o_totalprice) as total_order_value
from snowflake_sample_data.tpch_sf1000.orders
where
year(o_orderdate)=1997
group by order_month
order by order_month
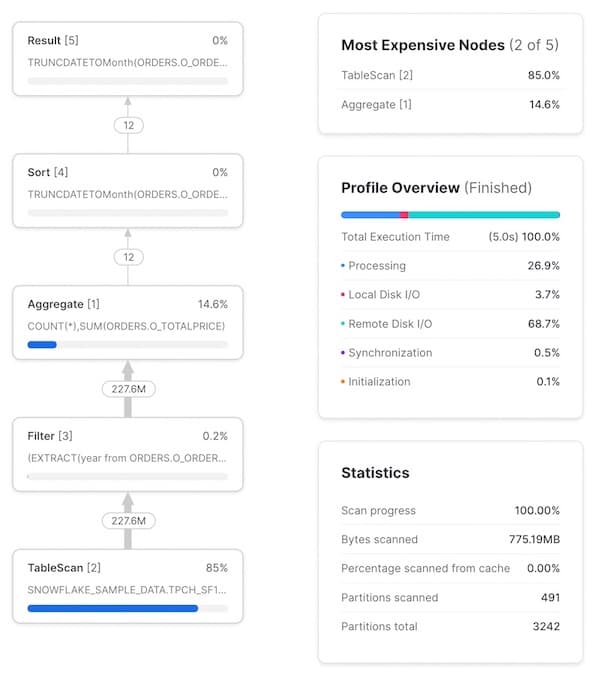
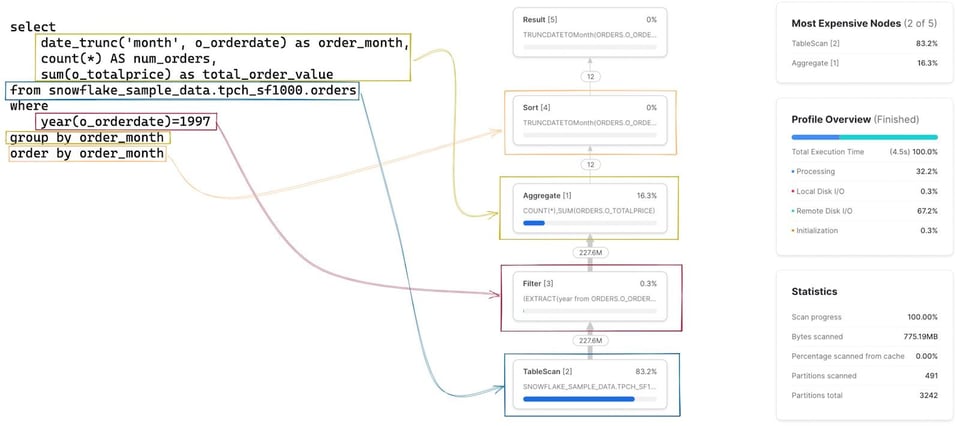
Il primo passo è costruirsi un modello mentale di come ogni stage/operatore del Query Profile corrisponda alla query scritta. All'inizio non è immediato, ma con un po' di pratica diventa rapidissimo. Cliccando su un nodo si ottengono ulteriori dettagli sull'operatore — ad esempio la tabella scansionata o le aggregazioni eseguite — utili a individuare il codice SQL corrispondente. Nell'immagine seguente il codice SQL associato a ciascun operatore è evidenziato:
Il Query Profile include anche diverse statistiche utili. Le principali:
- Un riepilogo del tempo di esecuzione, che mostra la percentuale del tempo totale dedicata a ciascuna categoria. Le 4 voci elencate sono:
- Processing: tempo dedicato alle operazioni di elaborazione della query come join, aggregazioni, filtri, ordinamenti, ecc.
- Local Disk I/O: tempo dedicato alla lettura/scrittura di dati da/verso lo storage SSD locale. Include attività come lo spilling su disco o la lettura di dati nella cache dell'SSD locale.
- Remote Disk I/O: tempo dedicato alla lettura/scrittura di dati da/verso lo storage remoto (ad esempio S3 o Azure Blob storage). Include attività come lo spilling su disco remoto o la lettura dei dataset.
- Initialization: l'overhead necessario per avviare la query sul warehouse. Nella nostra esperienza è sempre estremamente contenuto e relativamente costante.
- Statistiche della query. Qui si trovano informazioni come il numero di partizioni scansionate sul totale disponibile. Il dato si riferisce a tutte le tabelle coinvolte nella query: meno partizioni scansionate significa che il pruning della query funziona bene. Se il warehouse non ha memoria sufficiente per elaborare la query e ricorre allo spilling su disco, anche questa informazione compare qui.
- Numero di record scambiati tra un nodo e l'altro. Un'informazione molto utile per capire il volume di dati elaborato e come ciascun nodo lo riduce (o lo amplifica).
- Percentuale del tempo totale di esecuzione dedicata a ciascun nodo. Visibile in alto a destra di ogni nodo, indica quanta parte del tempo complessivo è stata spesa su quell'operatore. In questo esempio, l'83,2% del tempo totale di esecuzione è stato impiegato dall'operatore
TableScan. Questa informazione alimenta la lista "Most Expensive Nodes" in alto a destra del Query Profile, che ordina i nodi in base alla percentuale di tempo totale di esecuzione.
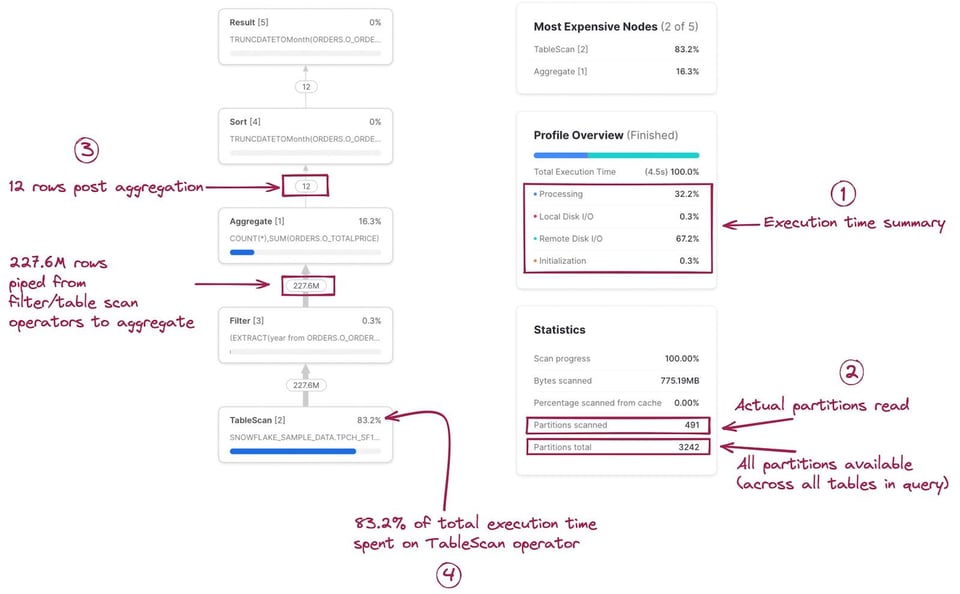
Potrebbe notare che il numero di righe in ingresso e in uscita dal nodo Filter è identico, come se la condizione SQL year(o_orderdate)=1997 non avesse avuto alcun effetto. In realtà il filtro sta eliminando dei record: la tabella ne contiene 1,5 miliardi. Si tratta di un limite spiacevole del Query Profile, che non mostra il numero esatto di record rimossi da un singolo filtro.
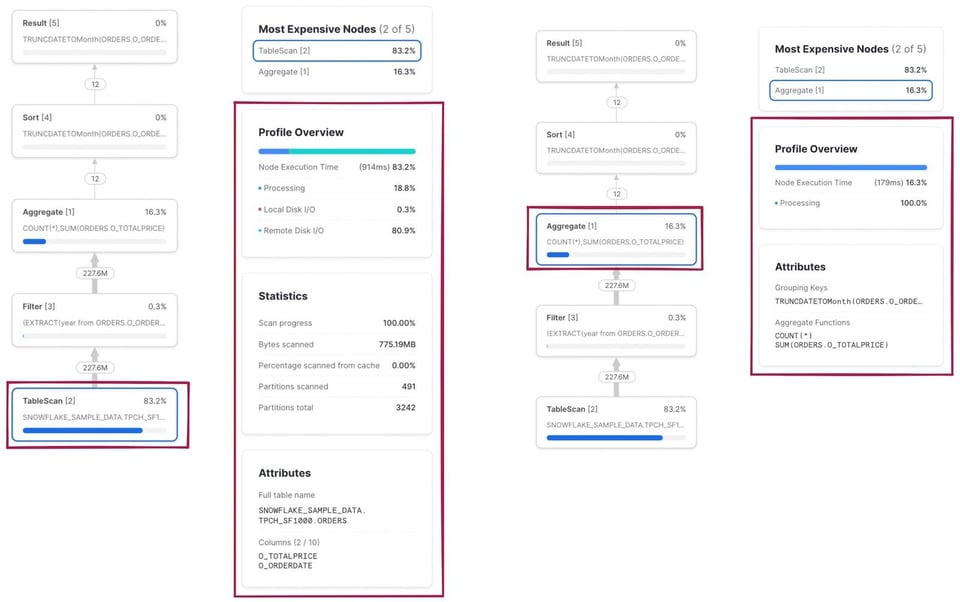
Come detto, cliccando su ciascun nodo si ottengono ulteriori dettagli e statistiche di esecuzione. A sinistra trova i risultati del click sull'operatore TableScan; a destra quelli dell'operatore Aggregate.
Query a più step
Modificando il filtro della query precedente con una subquery otteniamo una query a più step.
select
date_trunc('month', o_orderdate) as order_month,
count(*) as num_orders,
sum(o_totalprice) as total_order_value
from snowflake_sample_data.tpch_sf1000.orders
where
o_totalprice > (select avg(o_totalprice) from snowflake_sample_data.tpch_sf1000.orders)
group by order_month
order by order_month
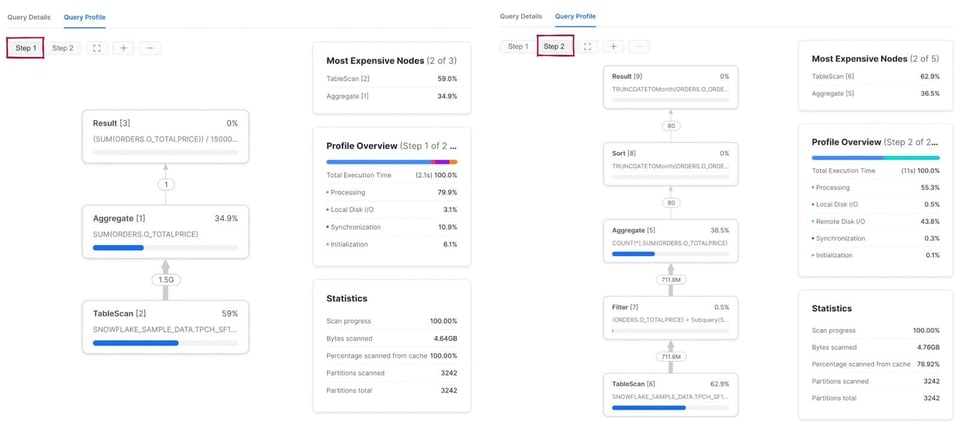
A differenza di prima, il query plan ora si compone di due step. Nel primo Snowflake esegue la subquery e calcola la media di o_totalprice. Il risultato viene memorizzato e riutilizzato nel secondo step, che presenta gli stessi 5 operatori della query vista in precedenza.
Query complessa
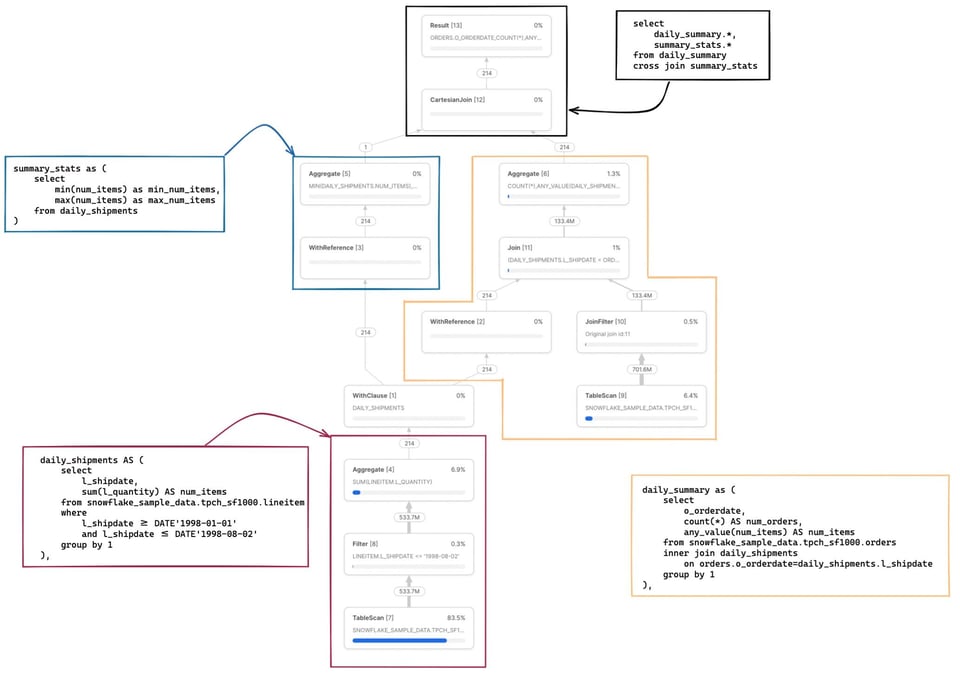
Vediamo ora una query leggermente più complessa 2 con più CTE, una delle quali viene richiamata in due punti diversi.
with
daily_shipments AS (
select
l_shipdate,
sum(l_quantity) AS num_items
from snowflake_sample_data.tpch_sf1000.lineitem
where
l_shipdate >= DATE'1998-01-01'
and l_shipdate <= DATE'1998-08-02'
group by 1
),
daily_summary as (
select
o_orderdate,
count(*) AS num_orders,
Espandi il codice
In questo esempio ci sono alcuni aspetti interessanti. Innanzitutto la CTE daily_shipments viene calcolata una sola volta: qualsiasi SQL a valle che la referenzia richiama l'operatore WithReference per accedere ai risultati, invece di ricalcolarli ogni volta.
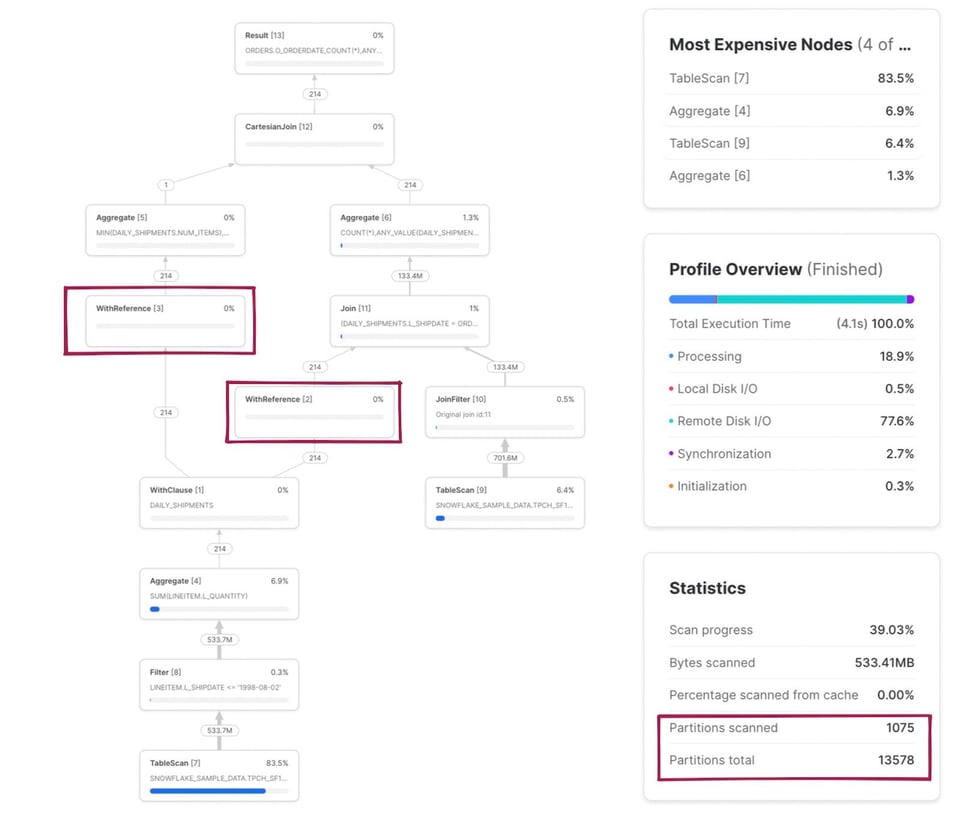
La metrica delle partizioni scansionate/totali è ora una combinazione delle due tabelle lette nella query. Cliccando sul nodo TableScan della tabella snowflake_sample_data.tpch_sf1000.orders vediamo che la tabella viene sottoposta a pruning in modo efficace: solo 154 partizioni scansionate su 3242. Come è possibile, se nel codice SQL non è stato scritto alcun filtro where esplicito? È l'operatore JoinFilter all'opera. Snowflake applica automaticamente questa elegante ottimizzazione: durante l'esecuzione determina l'intervallo di date a partire dalla CTE daily_shipments e lo usa come filtro sulla tabella orders, dato che la query impiega un inner join.
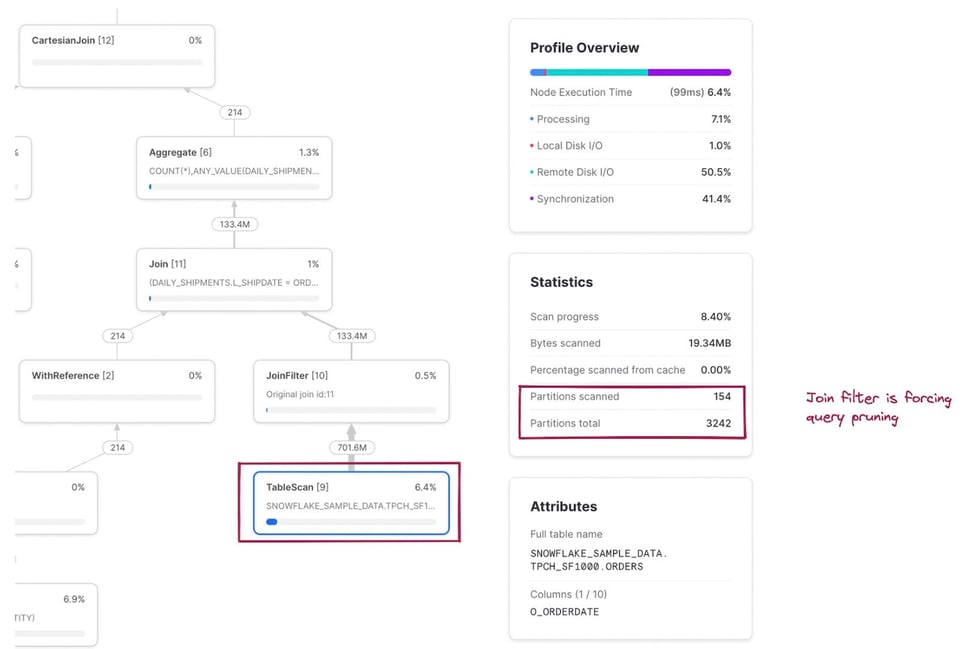
La mappatura completa del codice SQL ai relativi nodi operatori è riportata nelle note in fondo 3.
A cosa prestare attenzione nel Query Profile di Snowflake?
Il caso d'uso più frequente del Query Profile è capire perché una determinata query non rende come dovrebbe. Ora che abbiamo visto le basi, ecco alcuni segnali da ricercare nel Query Profile come possibili responsabili di performance scadenti:
- Spilling elevato su disco remoto. Quando si verifica un qualsiasi spillage di dati, significa che il warehouse non ha memoria sufficiente per elaborarli e deve depositarli temporaneamente altrove. Lo spilling su disco remoto è estremamente lento e penalizza in modo significativo le performance della query.
- Elevato numero di partizioni scansionate. Analogamente allo spilling su disco remoto, anche la lettura dei dati da disco remoto è molto lenta. Un numero elevato di partizioni scansionate significa che la query deve fare molto lavoro per leggere dati remoti.
- Exploding join. Se nota che il numero di righe in uscita da un join aumenta, è possibile che la join key sia stata specificata in modo errato. Gli exploding join richiedono in genere tempi di elaborazione più lunghi e possono provocare altri problemi, come lo spilling su disco.
- Cartesian join. I cartesian join sono cross-join che producono un result set pari al numero di righe della prima tabella moltiplicato per quello della seconda. Possono comparire involontariamente quando si usa un non equi-join, come ad esempio un range join. Per via del volume di dati prodotto sono lenti e finiscono spesso in problemi di memoria esaurita.
- Operatori a valle bloccati da una singola CTE. Come accennato, Snowflake calcola ogni CTE una sola volta. Se un operatore dipende da quella CTE, deve attendere che l'elaborazione sia completata. In alcuni casi può convenire ripetere la CTE come subquery per consentire un'elaborazione parallela.
- Ordinamenti precoci e inutili. Capita spesso che gli utenti aggiungano un sort superfluo nelle prime fasi della query. Gli ordinamenti sono costosi e andrebbero evitati quando non strettamente necessari.
- Ricalcolo ripetuto della stessa view. Ogni volta che una view viene richiamata in una query deve essere ricalcolata. Se contiene join, aggregazioni o filtri onerosi, talvolta è più efficiente materializzarla in anticipo.
- Query Profile molto esteso, con tantissimi nodi. Alcune query fanno semplicemente troppe cose e possono migliorare moltissimo se semplificate. Suddividere una query in più query, ciascuna più semplice, è una tecnica efficace.
Nei prossimi articoli analizzeremo ciascuno di questi segnali nel dettaglio e condivideremo strategie per risolverli.
Note
Non tutti gli 1,3 milioni di record vengono inviati in un'unica soluzione. Snowflake dispone di un motore di esecuzione vettorizzato: i dati vengono elaborati in pipeline, in batch di poche migliaia di righe in formato colonnare alla volta. È ciò che permette a un warehouse XSMALL con 16GB di RAM di elaborare dataset molto più grandi di 16GB.
Non darei troppo peso a ciò che la query calcola o al modo in cui è scritta: è stata creata unicamente per generare un esempio di query profile interessante.
Per chi vuole migliorare la propria capacità di leggere i Query Profile di Snowflake, può usare la query di esempio qui sopra per vedere come ciascuna CTE si mappa sulle diverse sezioni del Query Profile.
Ian Whitestone·Co-founder & CEO di SELECT
Ian è Co-founder e CEO di SELECT, una piattaforma SaaS per la gestione e l'ottimizzazione dei costi di Snowflake. Prima di fondare SELECT, ha trascorso 6 anni alla guida di team full stack di data science ed engineering in Shopify e Capital One. In Shopify ha guidato le attività di ottimizzazione del data warehouse e di miglioramento dell'osservabilità dei costi.