Unabhängig skalierbare Compute- und Speicherressourcen sind ein Grundpfeiler der Snowflake-Architektur. In diesem Beitrag schauen wir uns an, wie Snowflake Daten speichert und wie sich damit die Query-Performance massiv steigern lässt.
Snowflake-Architektur im Schnelldurchlauf
In einem früheren Beitrag haben wir erläutert, dass die Snowflake-Architektur aus drei horizontalen Schichten besteht. Ganz oben liegt die Cloud-Services-Schicht – eine sehr breit gefasste Kategorie, die alle Funktionen außerhalb der eigentlichen Query-Ausführung umfasst. Die Cloud Services greifen auf die massiv parallele Query-Processing-Schicht zu. Die Virtual Warehouses dieser Schicht lesen und schreiben Daten in die Storage-Schicht, die bei den meisten Snowflake-Kunden auf S3 basiert (die meisten Snowflake-Konten laufen auf AWS). Micro-Partitions sind genau in dieser Storage-Schicht angesiedelt.
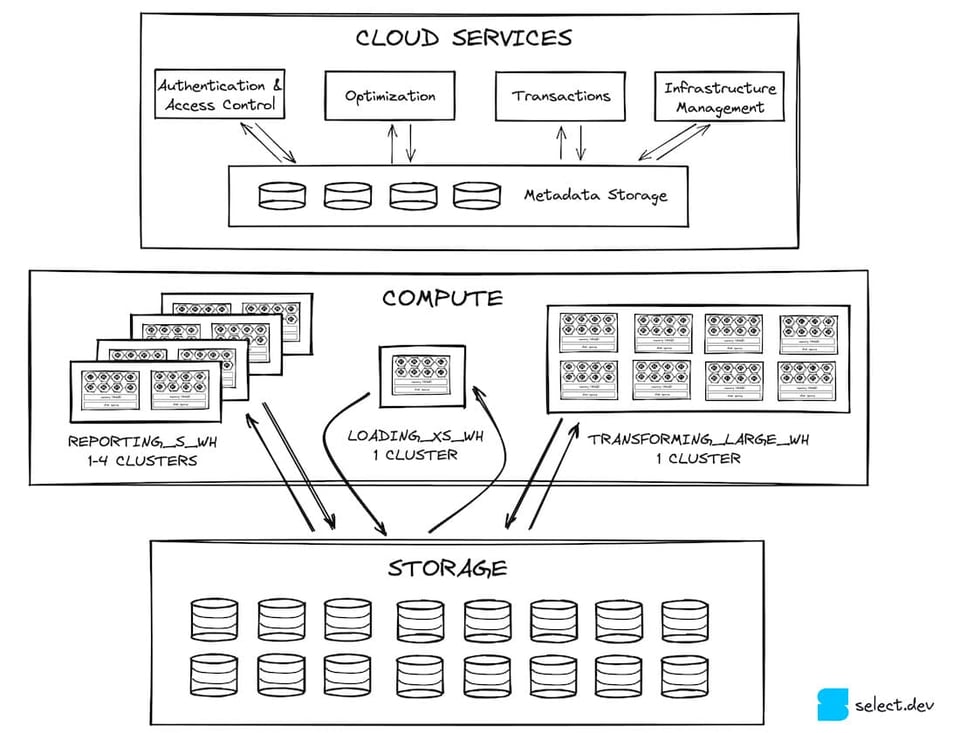
Micro-Partitions, Partitioning, Clustering – was bedeutet das alles?!
Rund um Micro-Partitions kursieren verwirrend viele ähnliche, aber unterschiedliche Begriffe. Hier ein kleines Glossar:
- Micro-Partitions (Thema dieses Beitrags) – die Speichereinheit in Snowflake. Eine Micro-Partition ist im Grunde eine spezielle Art von Datei. Häufig werden sie auch einfach als Partitions bezeichnet.
- Clustering – beschreibt, wie die Daten einer bestimmten Tabelle auf die Micro-Partitions verteilt sind.
- Clustered – Alle Tabellen sind in dem Sinne clustered, dass ihre Daten in einer oder mehreren Micro-Partitions abgelegt sind. Die Snowflake-Dokumentation definiert den Begriff jedoch enger: "A table with a clustering key defined is considered to be clustered."
- Well-clustered – Eine well-clustered Tabelle lässt sich für die typischerweise darauf ausgeführten Queries gut prunen. Achtung: Eine well-clustered Tabelle ist nicht zwangsläufig auch clustered im Sinne der obigen Definition.
- Clustering Key – Für eine Tabelle lässt sich ein Clustering Key oder ein entsprechender Ausdruck definieren, der Snowflakes automatischen Clustering-Service aktiviert. Dieser Service ist ein kostenpflichtiger, serverloser Prozess, der die Daten in den Micro-Partitions so umorganisiert, dass sie zum angegebenen Clustering Key passen.
- Partitioning – Partitioning hat im Snowflake-Kontext keine eigenständige Bedeutung.
- Warehouse Cluster – die Skalierungseinheit innerhalb eines Multi-Cluster-Warehouse.
Was ist eine Snowflake Micro-Partition?
Eine Micro-Partition ist eine Datei, die im Blob-Storage-Dienst desjenigen Cloud-Anbieters abgelegt wird, auf dem das Snowflake-Konto läuft:
- AWS – S3
- Azure – Azure Blob Storage
- GCP – Google Cloud Storage
Micro-Partitions nutzen ein proprietäres, geschlossenes Dateiformat von Snowflake. Sie bestehen aus einem Header mit Metadaten zu den gespeicherten Daten; die eigentlichen Daten liegen spaltenweise gruppiert und komprimiert vor.
Eine einzelne Micro-Partition fasst bis zu 16 MB komprimierte Daten (daher rührt auch die bekannte Variant-Einschränkung); unkomprimiert sind das in der Regel zwischen 50 und 500 MB. Kleine Tabellen (<500 MB unkomprimiert) bestehen unter Umständen aus nur einer einzigen Micro-Partition. Da Snowflake die Tabellengröße nicht begrenzt, gibt es entsprechend auch keine Obergrenze für die Anzahl der Micro-Partitions pro Tabelle.
Eine Micro-Partition enthält immer vollständige Datenzeilen. Das mag zunächst verwirren, denn Micro-Partitions sind zugleich ein spaltenorientiertes Speicherformat. Beide Eigenschaften widersprechen sich aber nicht, da sich einzelne Spalten gezielt aus einer Micro-Partition abrufen lassen. Deshalb werden Micro-Partitions manchmal auch als "hybrid columnar" bezeichnet: Die Daten sind sowohl nach Zeilen (eine Micro-Partition) als auch nach Spalten (innerhalb jeder Micro-Partition) gruppiert.
Genug der Theorie – Zeit für ein Diagramm. Im weiteren Verlauf des Beitrags arbeiten wir mit einer Orders-Tabelle als Beispiel. So sieht eine der dazugehörigen Micro-Partitions aus:
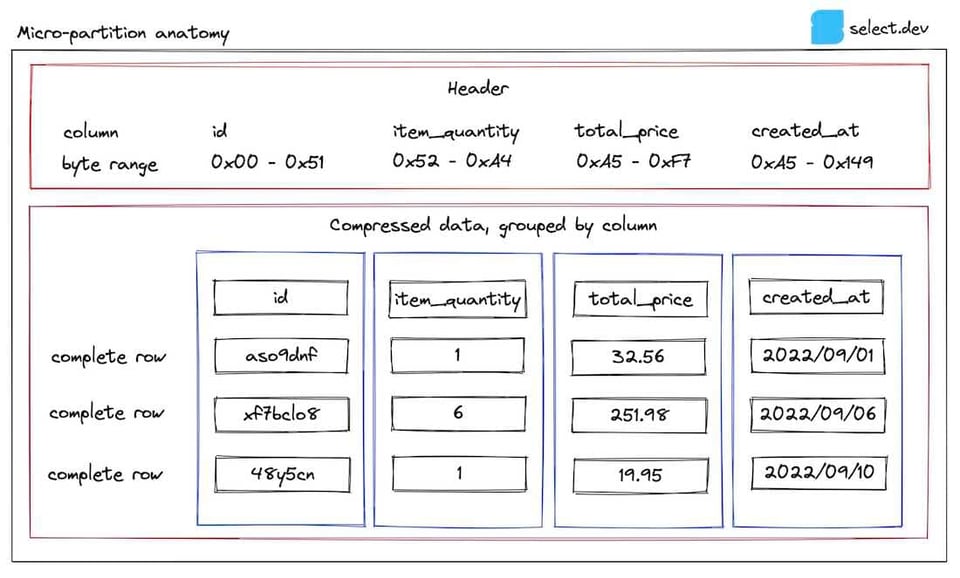
Im Header sind die Byte-Bereiche jeder Spalte innerhalb der Micro-Partition hinterlegt. So kann Snowflake per Byte Range Get ausschließlich die für eine Query relevanten Spalten laden. Genau deshalb laufen Queries schneller, wenn Sie weniger Spalten auswählen.
Die Metadaten zu jeder Spalte einer Micro-Partition hält Snowflake im Metadata Cache der Cloud-Services-Schicht vor. Dank dieser Metadaten liefern einfache analytische Queries wie count(*) oder max(column) extrem schnell Ergebnisse. Daneben werden weitere Metadaten gespeichert, die hier nicht abgebildet sind – einige davon undokumentiert und von Snowflake lediglich beschrieben als 'used for both optimization and efficient query processing'.

Entscheidend sind die Min- und Max-Werte: Sie sind die Grundlage für das Pruning in Snowflake.
Was ist Query Pruning in Snowflake?
Pruning ist eine Technik, mit der Snowflake die Anzahl der bei einer Query gelesenen Micro-Partitions reduziert. Das Lesen von Micro-Partitions gehört zu den teuersten Schritten einer Query, da die Daten über das Netzwerk geladen werden. Sobald ein Filter in einer WHERE-Klausel, einem JOIN oder einer Subquery greift, versucht Snowflake, alle Micro-Partitions auszuschließen, von denen es weiß, dass sie keine relevanten Daten enthalten. Damit das funktioniert, müssen die Micro-Partitions jeweils einen engen Wertebereich für die gefilterte Spalte abdecken.
Zoomen wir auf die gesamte Orders-Tabelle heraus. In diesem Beispiel umfasst die Tabelle 28 Micro-Partitions mit jeweils drei Datenzeilen (in der Praxis sind es typischerweise Hunderttausende Zeilen pro Micro-Partition).

Diese Beispieltabelle ist nach der Spalte created_at sortiert und damit well-clustered (jede Micro-Partition deckt einen engen Wertebereich dieser Spalte ab). Ein Nutzer führt nun folgende Query aus:
1select * from orders where created_at > '2022/08/14'
Bereits in der Query-Planung prüft Snowflake, welche Micro-Partitions für die Query relevante Daten enthalten. In diesem Fall werden nur Bestellungen benötigt, die nach dem 2022/08/14 angelegt wurden. Anhand der Min- und Max-Metadaten der Spalte created_at erkennt der Query Planner sofort, dass diese Datensätze nur in den ersten drei im Diagramm hervorgehobenen Micro-Partitions liegen. Die übrigen Micro-Partitions werden ignoriert (geprunt), und Snowflake muss nur noch einen kleinen Bruchteil der Tabelle einlesen.
Pruning-Performance erkennen
Das Query Profile von Snowflake liefert jede Menge nützlicher Informationen – auch zur Pruning-Performance. Vor der Ausführung einer Query lassen sich die Pruning-Statistiken nicht ermitteln. Beachten Sie außerdem: Manche Queries benötigen gar keinen Table Scan; in diesem Fall werden auch keine Pruning-Statistiken angezeigt.
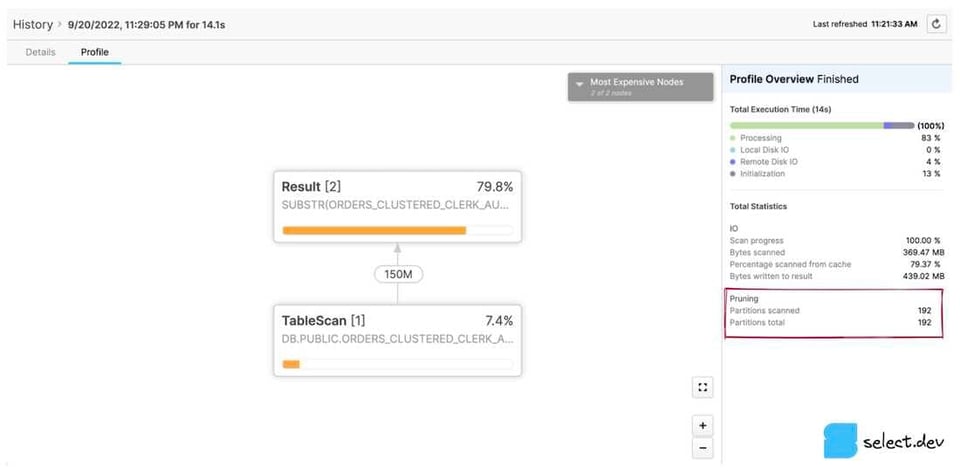
Klassisches Web-Interface
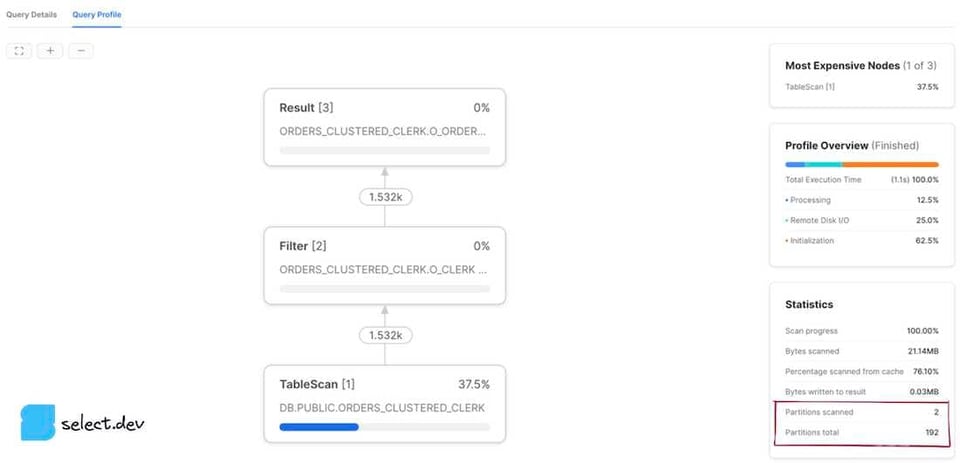
Klicken Sie auf der Seite History oder Worksheets auf eine Query-ID. Sie gelangen auf die Details-Seite der Query. Öffnen Sie dort den Tab Profile und – falls vorhanden – die letzte Schrittnummer, um sämtliche Statistiken einzusehen. Im rechten Bereich finden Sie unter Total Statistics einen Abschnitt Pruning mit zwei Werten: partitions scanned und partitions total.
Snowsight Web-Interface
Nach der Ausführung einer Query erscheint rechts neben den Ergebnissen der Bereich Query Details. Klicken Sie auf die drei Punkte und dann auf View Query Profile. Für eine bereits ausgeführte Query öffnen Sie das Profil über Activity in der linken Navigationsleiste und anschließend Query History. Wählen Sie die gewünschte Query aus und öffnen Sie den Tab Query Profile. Daraufhin werden die Werte partitions scanned und partitions total angezeigt.
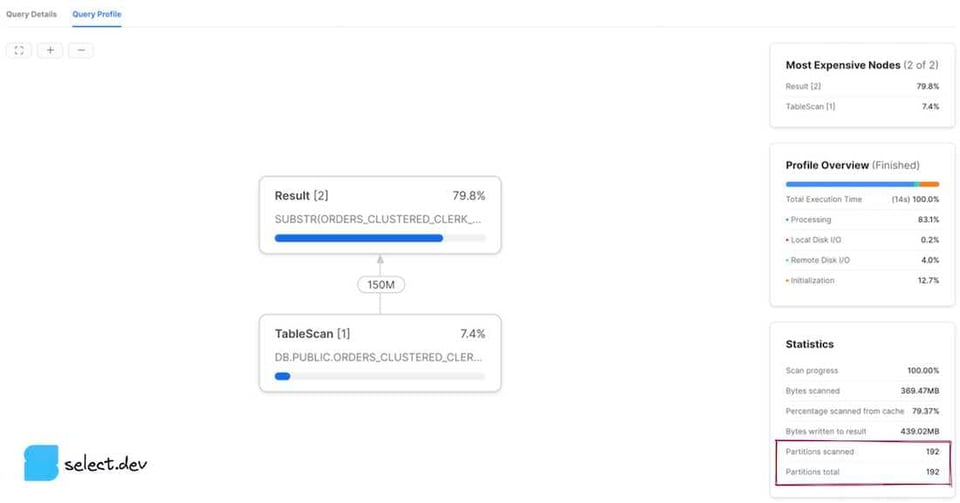
Die Ergebnisse interpretieren
Der Wert partitions scanned zeigt, wie viele Partitions die Query tatsächlich gelesen hat. Der Wert partitions total entspricht der Gesamtzahl aller Micro-Partitions in den abgefragten Tabellen. Eine Query mit gutem Pruning weist eine geringe Zahl gescannter Partitions im Verhältnis zur Gesamtzahl auf. Die oben gezeigten Profile entsprechen einer Query ganz ohne Pruning – die Anzahl der gescannten Partitions ist hier identisch mit der Gesamtzahl. Ergänzen wir die Query dagegen um einen Filter, auf den Snowflake die Micro-Partition-Metadaten effektiv anwenden kann, fällt das Ergebnis deutlich besser aus.
Fazit
Sie wissen jetzt, was Micro-Partitions sind, wie Snowflake sie über Pruning für die Query-Optimierung nutzt und auf welche Weise sich die Pruning-Performance messen lässt.
Im nächsten Beitrag zeigen wir, wie Sie das Clustering einer Tabelle gezielt beeinflussen, um die Pruning-Performance weiter zu verbessern.
Niall Woodward·Co-Founder & CTO von SELECT
Niall ist Co-Founder & CTO von SELECT, einer SaaS-Plattform für Snowflake-Kostenmanagement und -Optimierung. Vor SELECT war er als Data Engineer bei der Brooklyn Data Company sowie bei mehreren Start-ups tätig. Als Open-Source-Enthusiast ist er außerdem Maintainer von SQLFluff und Schöpfer dreier dbt-Packages: dbt_artifacts, dbt_snowflake_monitoring und dbt_query_tags.