Compute e storage scalabili in modo indipendente sono un pilastro dell'architettura di Snowflake. In questo articolo vedremo come Snowflake archivia i dati e come questo possa accelerare in modo significativo le performance delle query.
Un ripasso dell'architettura di Snowflake
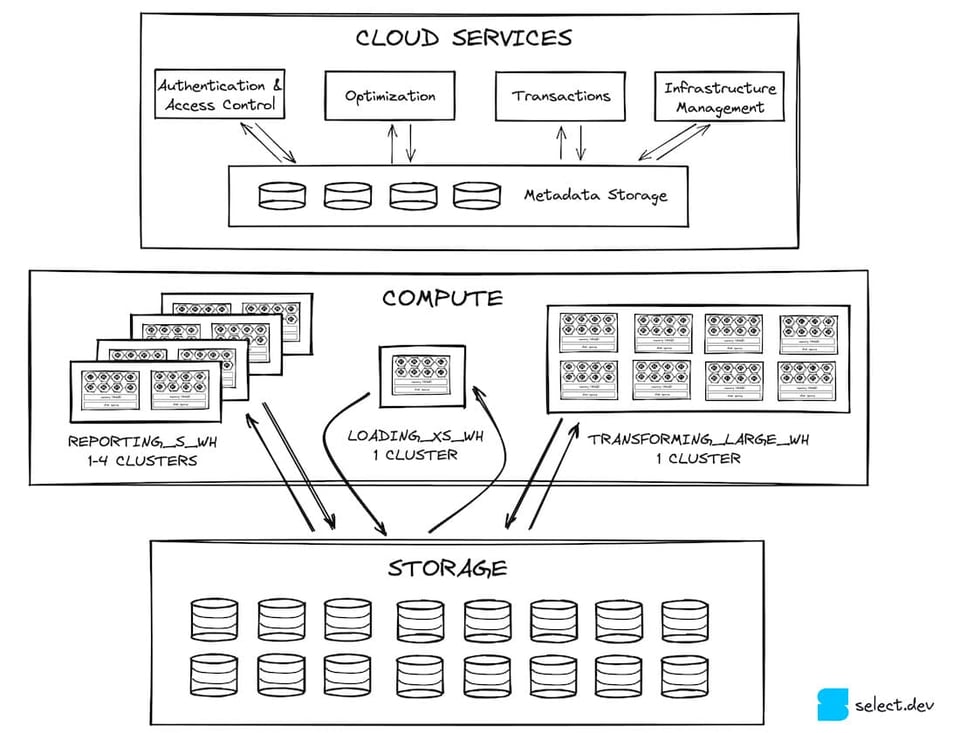
In un articolo precedente abbiamo visto come l'architettura di Snowflake sia suddivisa in tre livelli orizzontali. Il primo è il cloud services layer, una categoria molto ampia che racchiude tutte le funzionalità di Snowflake al di fuori dell'esecuzione delle query. I cloud services dialogano con il livello di query processing massivamente parallelo. I virtual warehouse di questo livello leggono e scrivono dati dal livello di storage, che per la maggior parte dei clienti Snowflake è S3 (gran parte degli account Snowflake gira su AWS). È proprio in questo livello di storage che si trovano le micro-partizioni.
Micro-partizioni, partitioning, clustering: facciamo chiarezza
Attorno alle micro-partizioni ruotano diversi termini simili ma distinti, che possono generare confusione. Ecco un glossario:
- Micro-partizioni (l'argomento di questo articolo): l'unità di storage in Snowflake. Una micro-partizione, in parole semplici, è un tipo particolare di file. A volte vengono chiamate semplicemente partizioni.
- Clustering: descrive la distribuzione dei dati tra le micro-partizioni di una determinata tabella.
- Clustered: tutte le tabelle sono clustered nel senso che i dati sono archiviati in una o più micro-partizioni, ma la documentazione di Snowflake precisa che "Una tabella con una clustering key definita è considerata clustered."
- Well-clustered: descrive una tabella su cui il pruning funziona bene per le query tipicamente eseguite. Attenzione però: una tabella well-clustered non è necessariamente clustered secondo la definizione precedente.
- Clustering key: è possibile definire per una tabella una clustering key o un'espressione che attivi il servizio di automatic clustering di Snowflake. Si tratta di un processo serverless a pagamento che riorganizza i dati nelle micro-partizioni in base alla clustering key specificata.
- Partitioning: nel contesto di Snowflake il partitioning non ha una definizione specifica.
- Warehouse cluster: l'unità di scaling di un multi-cluster warehouse.
Cos'è una micro-partizione di Snowflake?
Una micro-partizione è un file archiviato nel servizio di blob storage del cloud provider su cui gira l'account Snowflake:
- AWS - S3
- Azure - Azure Blob Storage
- GCP - Google Cloud Storage
Le micro-partizioni usano un formato file proprietario e closed-source creato da Snowflake. Contengono un header con i metadati che descrivono i dati archiviati; i dati veri e propri sono raggruppati per colonna e salvati in formato compresso.
Una singola micro-partizione può contenere fino a 16MB di dati compressi (da qui deriva l'analogo vincolo del tipo variant) che, non compressi, si attestano tipicamente tra i 50 e i 500MB. Le tabelle piccole (<500MB non compressi) possono avere una sola micro-partizione e, dato che Snowflake non pone limiti alla dimensione delle tabelle, di conseguenza non esiste alcun limite al numero di micro-partizioni che una singola tabella può contenere.
Una micro-partizione contiene sempre righe complete di dati. Può sembrare un controsenso, dato che le micro-partizioni sono anche un formato di archiviazione colonnare, ma le due caratteristiche non sono in contrasto: le singole colonne restano recuperabili da una micro-partizione. A volte le micro-partizioni vengono infatti descritte come 'ibride colonnari', proprio perché i dati sono raggruppati sia per righe (la micro-partizione) sia per colonne (all'interno di ogni micro-partizione).
Ok, basta parole: è il momento di un diagramma. Nel corso dell'articolo useremo come esempio una tabella degli ordini. Ecco come si presenta una delle micro-partizioni archiviate per questa tabella:
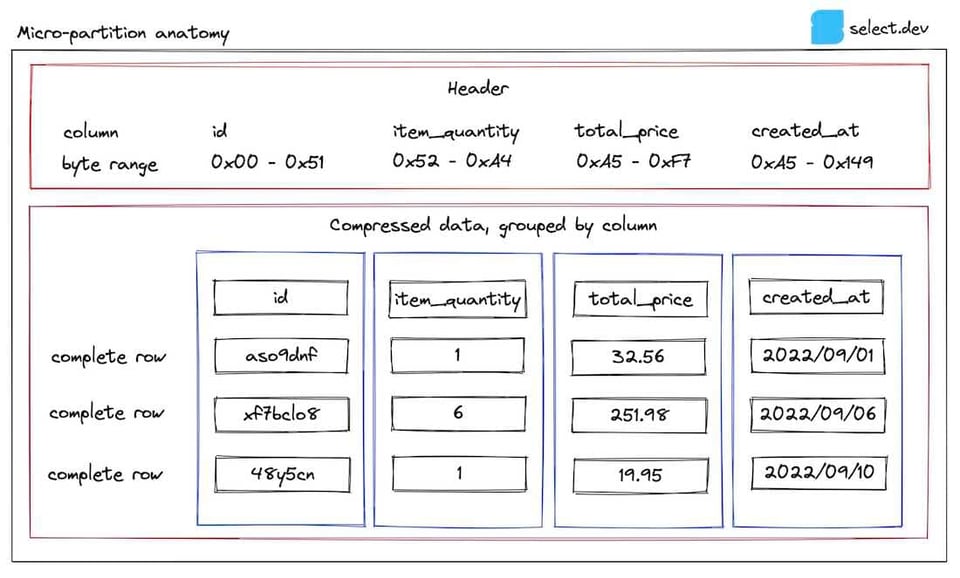
Nell'header sono memorizzati i byte range di ciascuna colonna all'interno della micro-partizione: in questo modo Snowflake può recuperare solo le colonne pertinenti a una query tramite una byte range get. Ecco perché le query risultano più veloci se si riduce il numero di colonne selezionate.
I metadati di ciascuna colonna della micro-partizione vengono archiviati da Snowflake nella metadata cache del cloud services layer. Questi metadati permettono di ottenere risultati rapidissimi per query analitiche di base come count(*) e max(column). Vengono memorizzati anche altri metadati non mostrati qui, alcuni dei quali non documentati e descritti da Snowflake come 'utilizzati sia per l'ottimizzazione sia per un'elaborazione efficiente delle query'.

I valori min e max sono cruciali, perché sono ciò che consente a Snowflake di eseguire il pruning.
Cos'è il query pruning in Snowflake?
Il pruning è la tecnica con cui Snowflake riduce il numero di micro-partizioni lette durante l'esecuzione di una query. Leggere le micro-partizioni è uno dei passaggi più costosi di una query, perché comporta il recupero di dati da remoto attraverso la rete. Quando in una clausola where, in una join o in una subquery è presente un filtro, Snowflake cerca di escludere tutte le micro-partizioni che sa non contenere dati pertinenti. Perché tutto questo funzioni, le micro-partizioni devono contenere un intervallo ristretto di valori per la colonna su cui si sta filtrando.
Allarghiamo lo sguardo all'intera tabella degli ordini. In questo esempio la tabella contiene 28 micro-partizioni, ciascuna con tre righe di dati (nella realtà, una micro-partizione contiene tipicamente centinaia di migliaia di righe).

La tabella di esempio è ordinata e quindi well-clustered sulla colonna created_at (ogni micro-partizione presenta un intervallo ristretto di valori per quella colonna). Un utente esegue sulla tabella questa query:
1select * from orders where created_at > '2022/08/14'
Durante la fase di pianificazione della query, Snowflake verifica quali micro-partizioni contengono dati rilevanti. In questo caso servono solo gli ordini creati dopo il 2022/08/14. Il query planner individua rapidamente questi record nelle sole prime tre micro-partizioni evidenziate nel diagramma, sfruttando i metadati min e max della colonna created_at. Le restanti micro-partizioni vengono ignorate (pruned) e Snowflake riduce così la quantità di dati da leggere a un piccolo sottoinsieme della tabella.
Come valutare le performance del query pruning
Il query profile di Snowflake offre molte informazioni utili, comprese le performance del pruning. Non è possibile conoscere le statistiche di pruning di una query prima della sua esecuzione. Va inoltre tenuto presente che alcune query non richiedono una scansione della tabella e, in quei casi, non viene mostrata alcuna statistica di pruning.
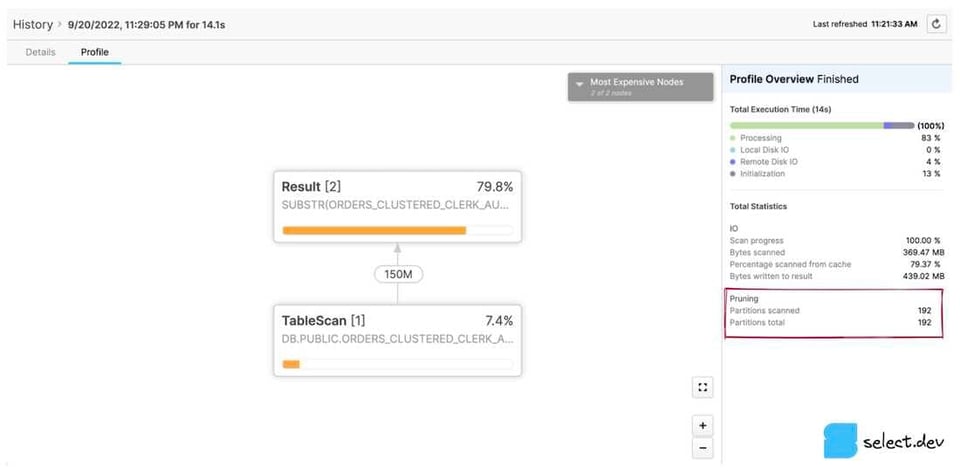
Interfaccia web classica
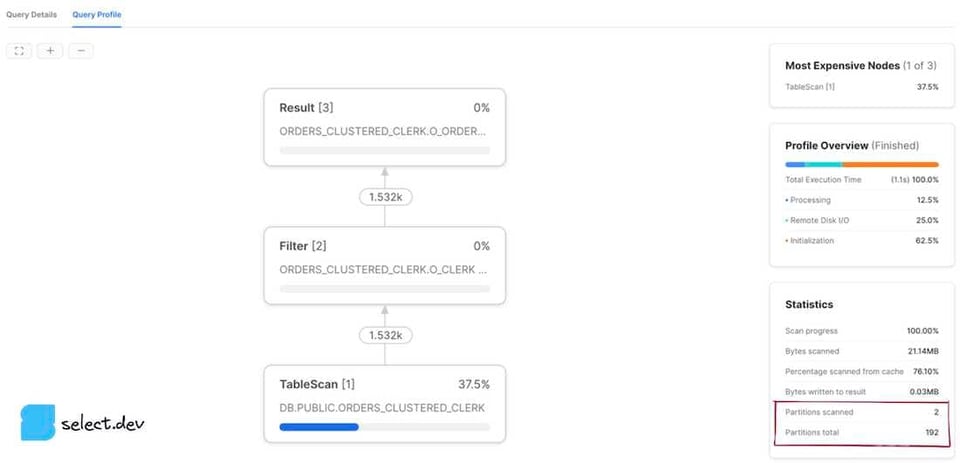
Nella pagina History o Worksheets, fare clic sull'ID di una query. Si aprirà la pagina Details relativa a quella query. A quel punto basta cliccare sul tab Profile e, se visibile, sull'ultimo numero di passo per visualizzare tutte le statistiche della query. Nel pannello a destra, la sezione Total Statistics contiene un sottotitolo Pruning con due valori: partitions scanned e partitions total.
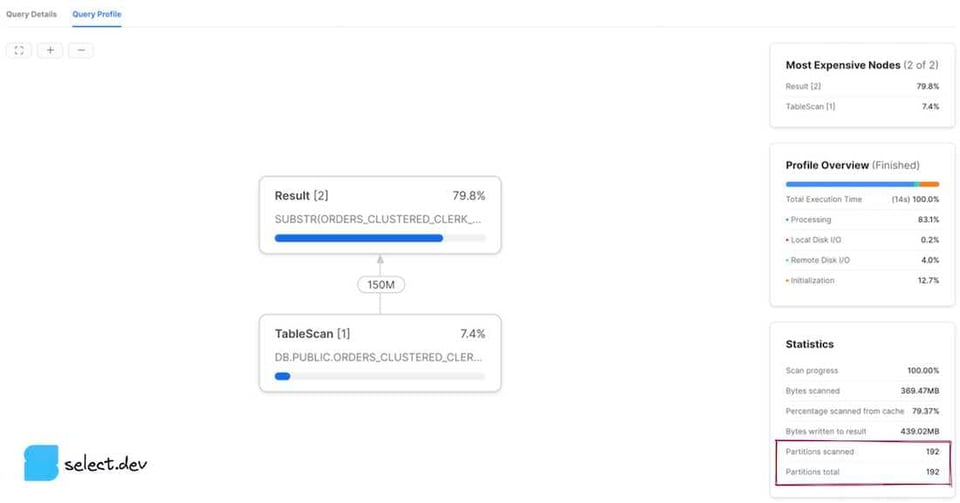
Interfaccia web Snowsight
Dopo aver eseguito una query, a destra della sezione dei risultati compare il pannello Query Details. Cliccare sui tre puntini e poi su View Query Profile. Per visualizzare il profilo di una query eseguita in precedenza, cliccare il pulsante Activity nella barra di navigazione a sinistra, poi Query History. Selezionare quindi la query di interesse e infine il tab Query Profile. Verranno mostrati i valori partitions scanned e partitions total.
Come interpretare i risultati
Il valore partitions scanned indica il numero di partizioni lette dalla query. Il valore partitions total indica il numero totale di micro-partizioni esistenti per le tabelle interrogate. Una query con un buon pruning presenta un numero ridotto di partitions scanned rispetto a partitions total. I profili mostrati sopra evidenziano una query del tutto priva di pruning, dato che il numero di partizioni scansionate coincide con quello totale. Se invece aggiungiamo alla query un filtro su cui Snowflake può sfruttare i metadati delle micro-partizioni per un pruning efficace, i risultati migliorano nettamente.
In sintesi
Abbiamo visto cosa sono le micro-partizioni, come Snowflake le sfrutta per ottimizzare le query tramite il pruning e in quali modi misurare le performance del pruning stesso.
Nel prossimo articolo vedremo come intervenire sul clustering di una tabella per ottenere migliori performance di pruning.
Niall Woodward·Co-founder & CTO di SELECT
Niall è Co-Founder & CTO di SELECT, piattaforma SaaS per il cost management e l'ottimizzazione di Snowflake. Prima di fondare SELECT, ha lavorato come data engineer in Brooklyn Data Company e in diverse startup. Appassionato di open source, è anche maintainer di SQLFluff e creatore di tre pacchetti dbt: dbt_artifacts, dbt_snowflake_monitoring e dbt_query_tags.