コンピュートとストレージを独立してスケールできる点は、Snowflakeアーキテクチャの根幹をなす特徴です。本記事では、Snowflakeがデータをどのように保存しているのか、そしてそれがクエリパフォーマンスをどれほど高速化できるのかに焦点を当てて解説します。
Snowflakeアーキテクチャのおさらい
以前の記事で、Snowflakeのアーキテクチャが3つの水平レイヤーに分かれていることを取り上げました。まず最上位にクラウドサービスレイヤーがあり、これはクエリ実行以外のSnowflake機能をまとめて指す非常に幅広いカテゴリです。クラウドサービスレイヤーは、大規模並列処理を担うクエリ処理レイヤーとやり取りします。クエリ処理レイヤー内の仮想ウェアハウスは、ストレージレイヤーに対してデータの読み書きを行います。ストレージレイヤーは、Snowflakeユーザーの大多数(ほとんどのSnowflakeアカウントはAWS上で稼働)においてS3にあたります。マイクロパーティションはこのストレージレイヤーに格納されます。
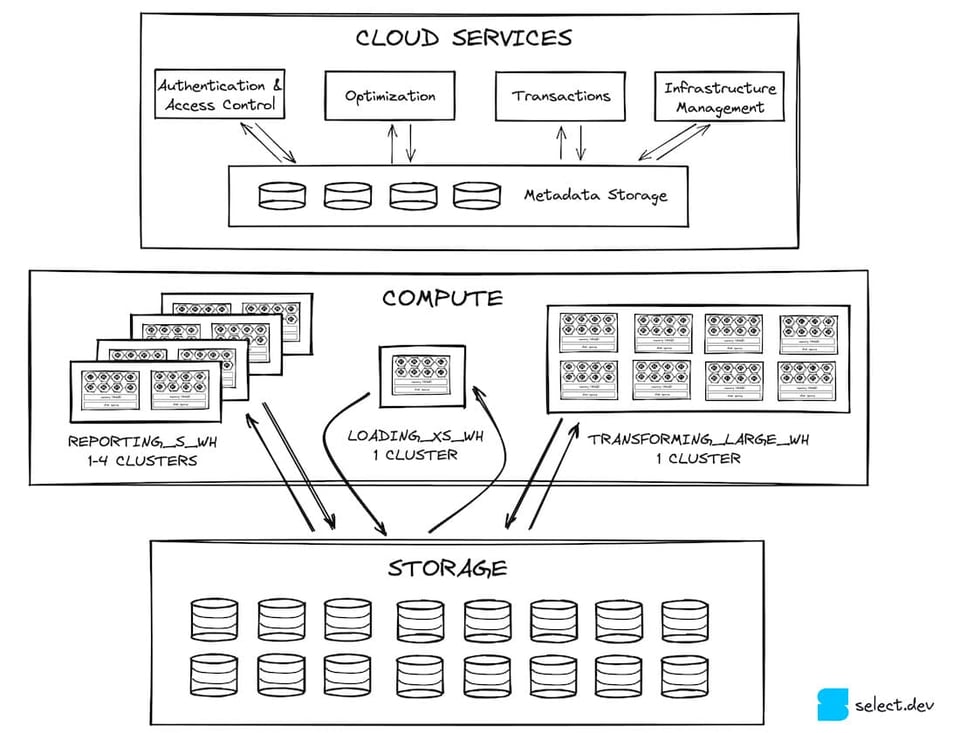
マイクロパーティション、パーティショニング、クラスタリング — 結局それぞれ何を指す?
マイクロパーティション周辺には、似ているようで意味の異なる用語がいくつもあり、混同しがちです。まずは用語を整理しましょう。
- マイクロパーティション(本記事の主題) — Snowflakeにおけるストレージの最小単位です。要するに特殊なファイルの一種で、単に「パーティション」と呼ばれることもあります。
- クラスタリング — 特定のテーブルにおいて、データがマイクロパーティション間でどのように分布しているかを表す概念です。
- クラスタード(Clustered) — すべてのテーブルは、データが1つ以上のマイクロパーティションに保存されているという意味ではクラスタードですが、Snowflakeドキュメントでは「クラスタリングキーが定義されているテーブルがクラスタードとみなされる」と定義されています。
- well-clustered(良くクラスタリングされた状態) — そのテーブルで通常実行されるクエリに対してプルーニングがよく効くテーブルを指します。ただし、well-clusteredなテーブルが上記定義のクラスタードに必ずしも該当するとは限らない点に注意してください。
- クラスタリングキー — テーブルにクラスタリングキーまたは式を定義すると、Snowflakeの自動クラスタリングサービスが有効になります。自動クラスタリングサービスは課金対象のサーバーレスプロセスで、指定したクラスタリングキーに合わせてマイクロパーティション内のデータを再配置します。
- パーティショニング — Snowflakeの文脈では明確な定義はありません。
- ウェアハウスクラスター — マルチクラスターウェアハウスにおけるスケーリングの単位です。
Snowflakeのマイクロパーティションとは
マイクロパーティションは、Snowflakeアカウントが稼働しているクラウドプロバイダーのBlobストレージサービスに保存されるファイルです。
- AWS — S3
- Azure — Azure Blob Storage
- GCP — Google Cloud Storage
マイクロパーティションには、Snowflakeが独自に開発したプロプライエタリかつクローズドソースのファイルフォーマットが採用されています。格納データを記述したメタデータを含むヘッダーがあり、実データは列単位にグループ化されたうえで圧縮形式で保存されます。
1つのマイクロパーティションが保持できる圧縮データは最大16MB(同じVARIANT型の制約もここに由来します)で、非圧縮では通常50〜500MB程度になります。小さなテーブル(非圧縮で500MB未満)はマイクロパーティションが1つだけのこともあります。Snowflakeにはテーブルサイズの上限がないため、必然的に1つのテーブルが持てるマイクロパーティション数にも上限はありません。
マイクロパーティションには、常に行全体のデータが格納されます。マイクロパーティションは列指向ストレージフォーマットでもあるため、この点は混乱を招きやすいかもしれません。しかし、個々の列をマイクロパーティションから取り出すこともできるため、この2つの特性は矛盾しません。マイクロパーティションが「ハイブリッド列指向」と表現されることがあるのは、行(マイクロパーティション単位)と列(各マイクロパーティション内)の両方でデータをグループ化しているためです。
説明はこのくらいにして、図で確認してみましょう。本記事では一貫してordersテーブルを例に用います。このテーブルに格納されたマイクロパーティションの1つは次のような構造になっています。
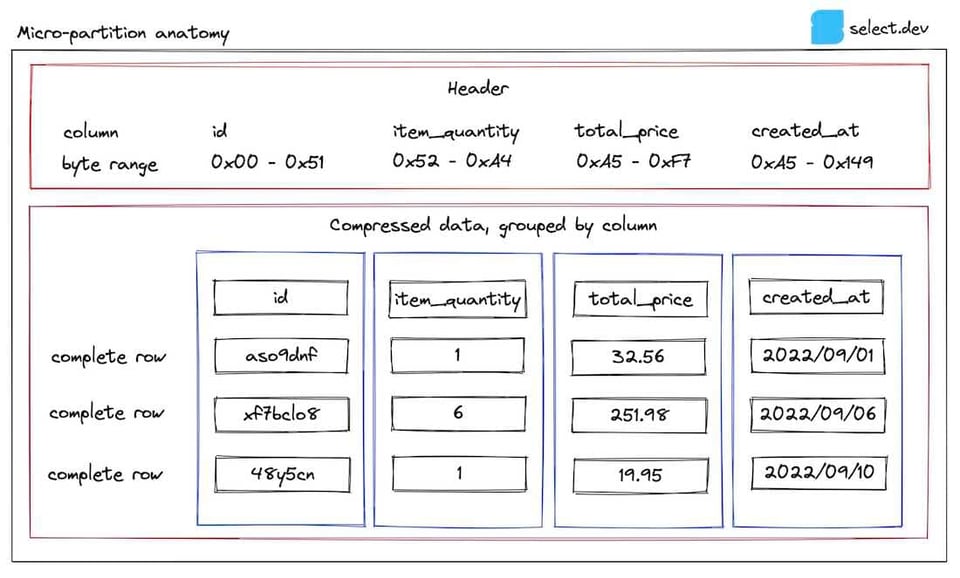
ヘッダーにはマイクロパーティション内の各列のバイトレンジが格納されており、SnowflakeはバイトレンジGETを使ってクエリに必要な列だけを取り出すことができます。SELECTする列数を減らすとクエリが速くなるのは、このためです。
マイクロパーティション内の各列に関するメタデータは、クラウドサービスレイヤーのメタデータキャッシュにSnowflakeが保持しています。このメタデータは、count(*)やmax(column)といった基本的な分析クエリに対して非常に高速に結果を返すために利用されます。図には示していない追加メタデータも保持されており、その一部は非公開で、Snowflakeは「最適化と効率的なクエリ処理の両方に利用される」と説明しています。

そして決定的に重要なのが最小値・最大値で、これによりSnowflakeはプルーニングを行えるようになります。
Snowflakeのクエリプルーニングとは
プルーニングとは、クエリ実行時に読み込むマイクロパーティション数を減らすためにSnowflakeが用いる手法です。マイクロパーティションの読み込みはネットワーク越しにリモートからデータを取得する処理のため、クエリ実行の中でも特にコストの高いステップの1つです。WHERE句、JOIN、サブクエリでフィルターがかけられると、Snowflakeは関連データを含まないと判断できるマイクロパーティションを除外しようとします。これが機能するためには、フィルター対象の列の値がマイクロパーティション内で狭い範囲に収まっている必要があります。
視点を引いて、ordersテーブル全体を見てみましょう。この例ではテーブルが28個のマイクロパーティションで構成されており、それぞれ3行のデータを保持しています(実際には1つのマイクロパーティションに数十万行が格納されるのが一般的です)。

このサンプルテーブルはcreated_at列でソートされているため、同じ列に対してwell-clusteredな状態になっています(各マイクロパーティション内で当該列の値の範囲が狭い)。ユーザーがこのテーブルに対して次のクエリを実行するとします。
1select * from orders where created_at > '2022/08/14'
Snowflakeはクエリプランニングの一環として、どのマイクロパーティションがクエリに関連するデータを含むかを確認します。今回の場合、必要なのは2022/08/14以降に作成されたordersのみです。クエリプランナーはcreated_at列の最小値・最大値メタデータを使い、該当レコードが図中でハイライトされた最初の3つのマイクロパーティションにしか存在しないことを瞬時に特定します。残りのマイクロパーティションは無視(プルーニング)され、結果としてSnowflakeはテーブル全体のごく一部だけを読めば済むようになります。
プルーニングの効き具合を確認する
Snowflakeのクエリプロファイルには、プルーニングのパフォーマンスを含む有用な情報が数多く表示されます。クエリのプルーニング統計は実行前には確認できません。また、テーブルスキャンを必要としないクエリもあり、その場合はプルーニング統計は表示されません。
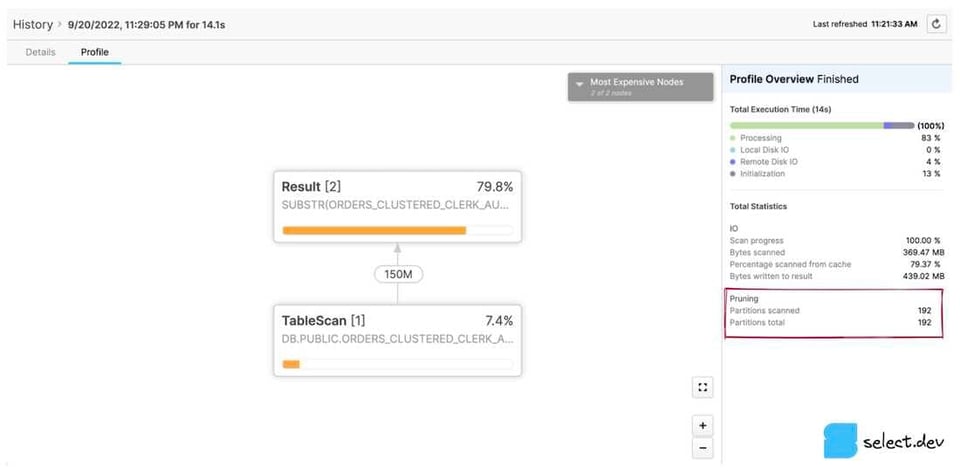
クラシックWebインターフェース
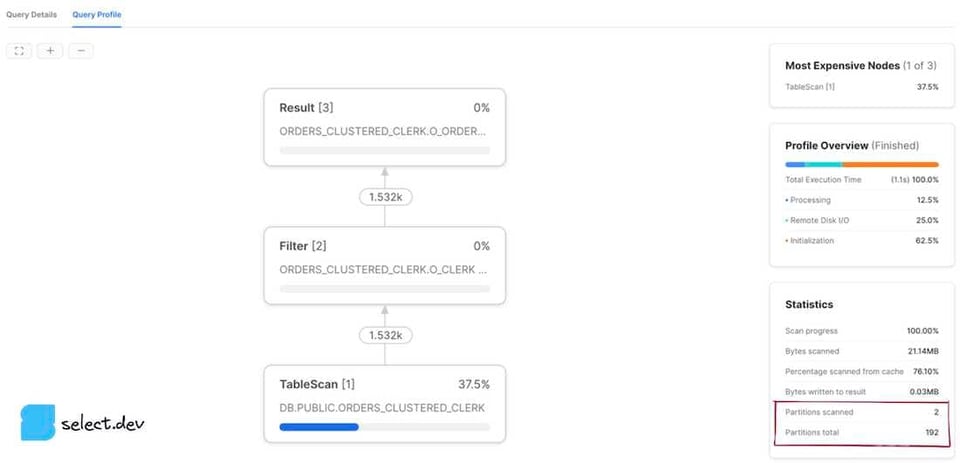
HistoryまたはWorksheetsページでクエリIDをクリックすると、そのクエリのDetailsページに移動します。次にProfileタブをクリックし、表示されていれば最終ステップ番号をクリックして、クエリのすべての統計を表示します。右側のペインにあるTotal Statisticsセクション内のPruning見出しに、partitions scannedとpartitions totalの2つの値が表示されます。
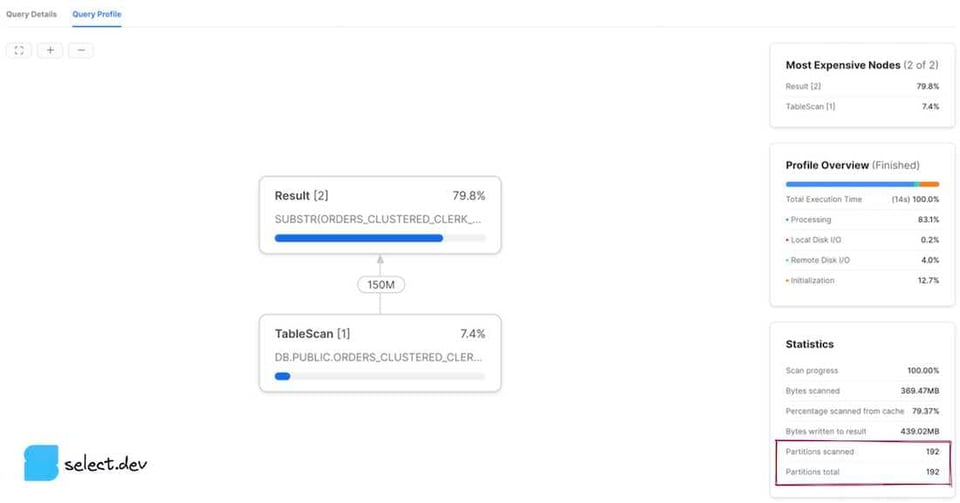
Snowsight Webインターフェース
クエリを実行すると、クエリ結果セクションの右側にQuery Detailsペインが表示されます。三点リーダーをクリックし、View Query Profileを選択します。過去に実行したクエリのプロファイルを開きたい場合は、左ナビゲーションバーのActivityボタンをクリックし、続いてQuery Historyを選択します。対象のクエリをクリックしてQuery Profileタブを開くと、partitions scannedとpartitions totalの値が表示されます。
結果の読み解き方
partitions scannedはクエリが実際に読み込んだパーティションの数を、partitions totalはそのクエリでSELECT対象となったテーブルに存在するマイクロパーティションの総数を表します。プルーニングがうまく効いているクエリでは、partitions totalに対してpartitions scannedが小さくなります。上記のプロファイルはpartitions scannedとpartitions totalが等しく、プルーニングがまったく効いていないクエリの例です。一方、Snowflakeがマイクロパーティションのメタデータを活かしてプルーニングできるフィルターをクエリに加えると、結果は大きく改善されます。
まとめ
本記事では、マイクロパーティションとは何か、Snowflakeがプルーニングを通じてそれをどのようにクエリ最適化に活用しているか、そしてプルーニングのパフォーマンスを測定するさまざまな方法を見てきました。
次回の記事では、より良いプルーニング性能を引き出すために、テーブルのクラスタリングをどのようにコントロールできるかを掘り下げていきます。
Niall Woodward・Co-founder & CTO of SELECT
Niallは、Snowflakeのコスト管理・最適化SaaSプラットフォームであるSELECTのCo-Founder兼CTOです。SELECT創業以前は、Brooklyn Data Companyや複数のスタートアップでデータエンジニアを務めていました。オープンソースにも熱心に取り組んでおり、SQLFluffのメンテナーであるほか、3つのdbtパッケージ dbt_artifacts、dbt_snowflake_monitoring、dbt_query_tags の作者でもあります。