El cómputo y el almacenamiento escalables de forma independiente son un pilar de la arquitectura de Snowflake. En este post veremos cómo Snowflake almacena los datos y cómo esto puede acelerar enormemente el rendimiento de las consultas.
Repaso de la arquitectura de Snowflake
En un post anterior vimos cómo la arquitectura de Snowflake se divide en tres capas horizontales. Primero está la capa de servicios en la nube, una categoría muy amplia que abarca todas las funciones de Snowflake fuera de la ejecución de consultas. Los servicios en la nube interactúan con la capa de procesamiento de consultas masivamente paralelo. Los virtual warehouses de esa capa leen y escriben datos en la capa de almacenamiento, que es S3 para la mayoría de los clientes de Snowflake (la mayor parte de las cuentas de Snowflake corren en AWS). Las micro-particiones viven en esta capa de almacenamiento.
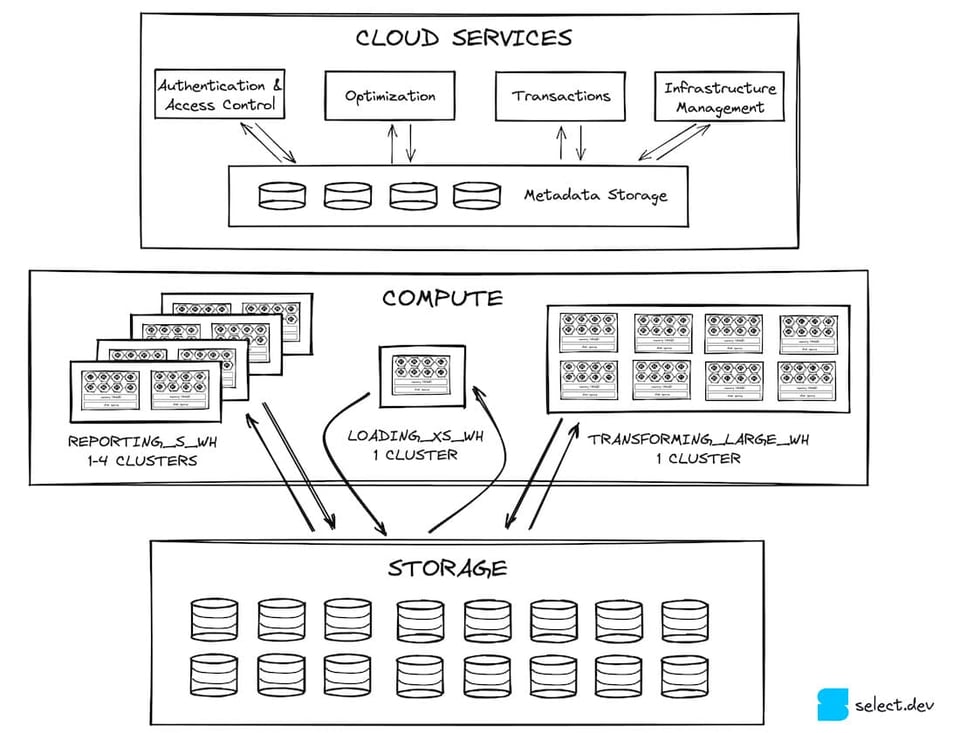
Micro-particiones, particionamiento, clustering: ¿qué significa todo esto?
Para sumar a la confusión, existen varios términos parecidos pero distintos asociados a las micro-particiones. Aquí va un glosario:
- Micro-particiones (el foco de este post): la unidad de almacenamiento en Snowflake. Dicho de forma sencilla, una micro-partición es un tipo especial de archivo. A veces se les llama simplemente particiones.
- Clustering: describe la distribución de los datos entre las micro-particiones de una tabla determinada.
- Clustered: todas las tablas están clustered en el sentido de que sus datos se almacenan en una o más micro-particiones, pero la documentación de Snowflake lo define como "Una tabla con una clustering key definida se considera clustered".
- Well-clustered: describe una tabla que se poda (prunes) bien para las consultas habituales que se ejecutan sobre ella. Ojo: una tabla well-clustered no es necesariamente clustered según la definición anterior.
- Clustering key: se puede definir una clustering key o expresión para una tabla, lo cual activa el servicio de clustering automático de Snowflake. Este servicio es un proceso serverless facturable que reorganiza los datos en las micro-particiones para ajustarlos a la clustering key indicada.
- Partitioning: el particionamiento no tiene una definición específica dentro del contexto de Snowflake.
- Warehouse cluster: la unidad de escalado en un warehouse multi-cluster.
¿Qué es una micro-partición de Snowflake?
Una micro-partición es un archivo, almacenado en el servicio de blob storage del proveedor de nube en el que corre la cuenta de Snowflake:
- AWS: S3
- Azure: Azure Blob Storage
- GCP: Google Cloud Storage
Las micro-particiones usan un formato de archivo propietario y de código cerrado creado por Snowflake. Llevan un encabezado con metadatos que describen los datos almacenados, mientras que los datos en sí se agrupan por columna y se guardan comprimidos.
Una sola micro-partición puede contener hasta 16MB de datos comprimidos (de ahí viene la misma restricción de variant), que sin comprimir suelen ocupar entre 50 y 500MB. Las tablas pequeñas (<500MB sin comprimir) pueden tener una sola micro-partición y, como Snowflake no impone un límite al tamaño de las tablas, tampoco existe un límite para la cantidad de micro-particiones que puede tener una misma tabla.
Una micro-partición siempre contiene filas completas de datos. Esto puede resultar confuso, ya que las micro-particiones también son un formato de almacenamiento columnar. Ambos atributos no se contradicen, pues se pueden recuperar columnas individuales desde una micro-partición. A veces oirás que las micro-particiones se describen como 'columnar híbrido', porque los datos se agrupan tanto por filas (una micro-partición) como por columnas (dentro de cada micro-partición).
Bueno, basta de palabras: vamos con un diagrama. A lo largo del post usaremos como ejemplo una tabla de orders. Así se ve una de las micro-particiones almacenadas para esa tabla:
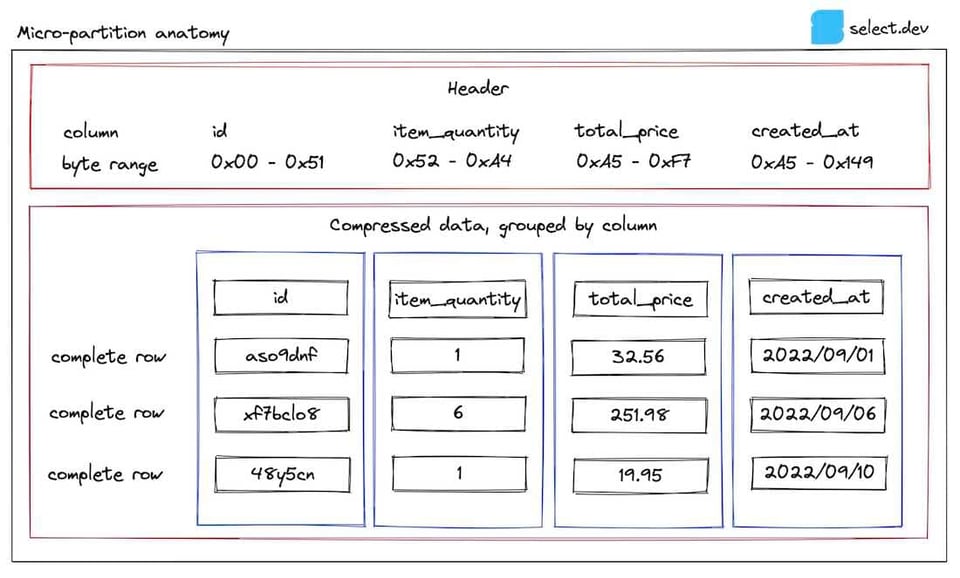
En el encabezado se almacenan los rangos de bytes de cada columna dentro de la micro-partición, lo que le permite a Snowflake recuperar solo las columnas relevantes para una consulta mediante un byte range get. Por eso las consultas corren más rápido cuando reduces el número de columnas seleccionadas.
Snowflake guarda los metadatos de cada columna de la micro-partición en su caché de metadatos, dentro de la capa de servicios en la nube. Estos metadatos sirven para entregar resultados extremadamente rápidos en consultas analíticas básicas como count(*) y max(column). También se almacenan metadatos adicionales que no aparecen aquí, algunos sin documentar, que Snowflake describe como 'utilizados tanto para la optimización como para el procesamiento eficiente de consultas'.

Los valores mínimo y máximo son clave porque le dan a Snowflake la capacidad de hacer pruning.
¿Qué es el query pruning en Snowflake?
El pruning es una técnica que usa Snowflake para reducir la cantidad de micro-particiones que se leen al ejecutar una consulta. Leer micro-particiones es uno de los pasos más costosos de una consulta, ya que implica leer datos de forma remota a través de la red. Si se aplica un filtro en una cláusula where, un join o una subconsulta, Snowflake intentará descartar cualquier micro-partición que sepa que no contiene datos relevantes. Para que esto funcione, las micro-particiones deben contener un rango acotado de valores en la columna por la que estás filtrando.
Veamos toda la tabla de orders en perspectiva. En este ejemplo, la tabla tiene 28 micro-particiones, cada una con tres filas de datos (en la práctica, una micro-partición suele contener cientos de miles de filas).

Esta tabla de ejemplo está ordenada y, por lo tanto, well-clustered por la columna created_at (cada micro-partición tiene un rango acotado de valores para esa columna). Un usuario ejecuta la siguiente consulta sobre la tabla:
1select * from orders where created_at > '2022/08/14'
Como parte del proceso de planificación de la consulta, Snowflake revisa qué micro-particiones contienen datos relevantes. En este caso, solo se necesitan las orders creadas después del 2022/08/14. El query planner identifica rápidamente que esos registros solo están en las primeras tres micro-particiones resaltadas en el diagrama, usando los metadatos de min y max de la columna created_at. El resto de las micro-particiones se ignora (se poda) y Snowflake reduce la cantidad de datos que necesita leer a solo un pequeño subconjunto de la tabla.
Cómo medir el rendimiento del pruning
El query profile de Snowflake muestra mucha información valiosa, incluido el rendimiento del pruning. No se pueden conocer las estadísticas de pruning de una consulta antes de ejecutarla. Ten en cuenta que algunas consultas no requieren un table scan, en cuyo caso no se mostrarán estadísticas de pruning.
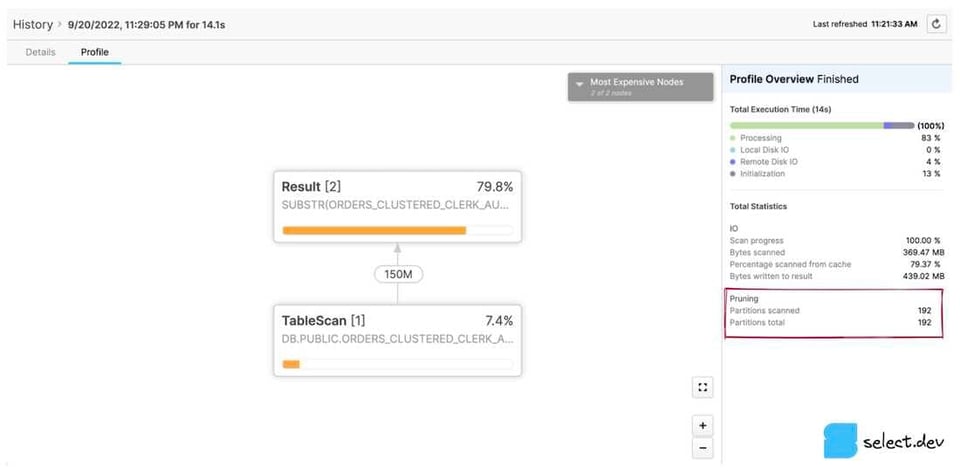
Interfaz web clásica
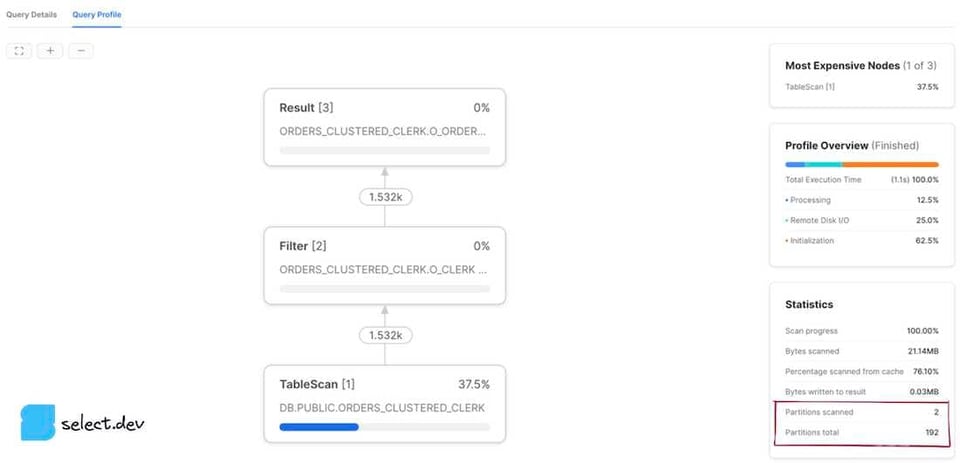
En la página History o Worksheets, haz clic en un ID de consulta. Te llevará a la página Details de esa consulta. Luego haz clic en la pestaña Profile y, si aparece, en el número del último paso para ver todas las estadísticas de la consulta. En el panel derecho, la sección Total Statistics tiene un subtítulo Pruning. Se muestran dos valores: partitions scanned y partitions total.
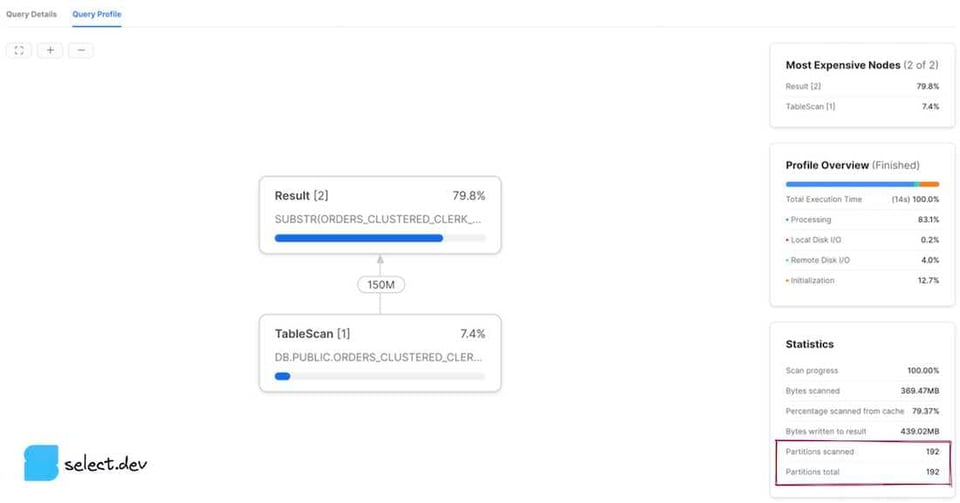
Interfaz web Snowsight
Después de ejecutar una consulta, aparece un panel Query Details a la derecha de la sección de resultados. Haz clic en los tres puntos y luego en View Query Profile. Para ver el profile de una consulta ejecutada antes, haz clic en el botón Activity de la barra de navegación izquierda y luego en Query History. Después, haz clic en la consulta que te interesa y luego en la pestaña Query Profile. Se mostrarán los valores de partitions scanned y partitions total.
Cómo interpretar los resultados
El valor partitions scanned representa la cantidad de particiones que leyó la consulta. El valor partitions total representa el total de micro-particiones existentes para las tablas seleccionadas en la consulta. Una consulta con buen pruning muestra un número bajo de partitions scanned en comparación con partitions total. Los profiles que mostramos arriba corresponden a una consulta sin ningún pruning, ya que partitions scanned es igual al total de particiones. Sin embargo, si añadimos a la consulta un filtro sobre el que Snowflake pueda apoyarse en los metadatos de la micro-partición para podar de forma efectiva, los resultados mejoran notablemente.
En resumen
Vimos qué son las micro-particiones, cómo Snowflake las aprovecha para optimizar consultas mediante el pruning y las distintas formas de medir su rendimiento.
En el próximo post exploramos cómo puedes influir en el clustering de una tabla para lograr un mejor pruning.
Niall Woodward·Co-founder & CTO de SELECT
Niall es Co-Founder & CTO de SELECT, una plataforma SaaS de gestión y optimización de costos de Snowflake. Antes de fundar SELECT, Niall fue data engineer en Brooklyn Data Company y en varias startups. Como entusiasta del open source, también es mantenedor de SQLFluff y creador de tres paquetes de dbt: dbt_artifacts, dbt_snowflake_monitoring y dbt_query_tags.