Computação e armazenamento escaláveis de forma independente são um dos pilares da arquitetura do Snowflake. Neste post, vamos mostrar como o Snowflake armazena dados e como isso pode acelerar bastante o desempenho das consultas.
Uma revisão rápida da arquitetura do Snowflake
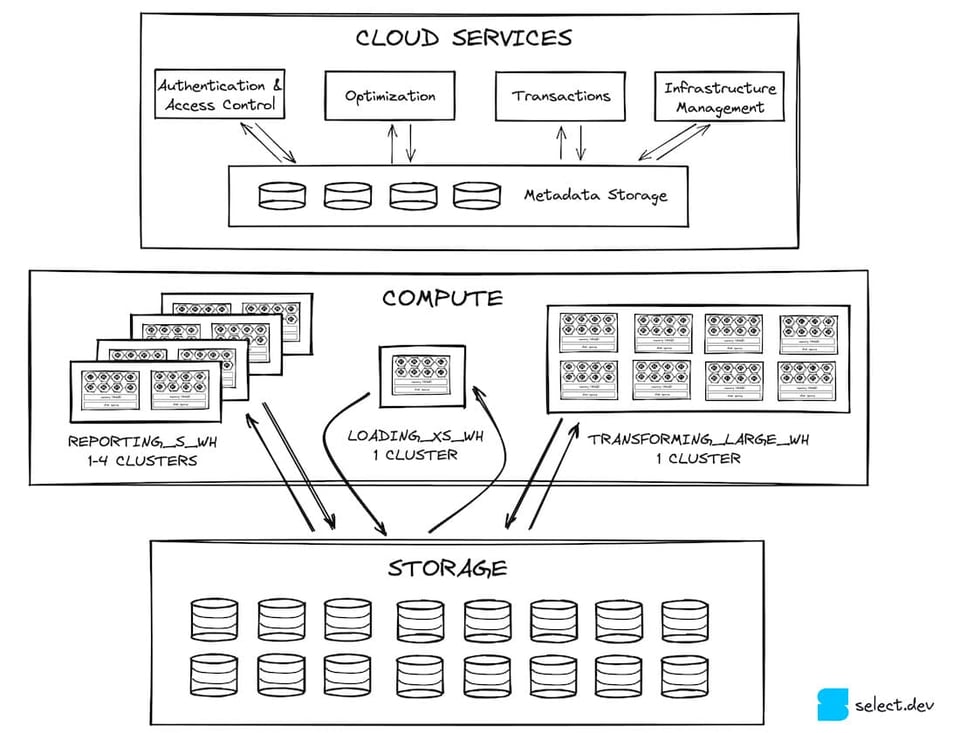
Em um post anterior, falamos sobre como a arquitetura do Snowflake é dividida em três camadas horizontais. Primeiro, existe a camada de cloud services, uma categoria bem ampla que reúne todos os recursos do Snowflake fora da execução de consultas. A camada de cloud services interage com a camada de processamento de consultas massivamente paralelo. Os virtual warehouses dessa camada leem e gravam dados na camada de armazenamento, que é o S3 para a maior parte dos clientes Snowflake (a maioria das contas Snowflake roda na AWS). É nessa camada de armazenamento que ficam as micro-partitions.
Micro-partitions, partitioning, clustering — afinal, o que significa cada um?
Para complicar, existem vários termos parecidos, mas com significados diferentes, ligados às micro-partitions. Veja um glossário:
- Micro-partitions (o foco deste post) — a unidade de armazenamento do Snowflake. Em termos simples, uma micro-partition é um tipo específico de arquivo. Às vezes são chamadas apenas de partitions.
- Clustering — descreve a distribuição dos dados entre as micro-partitions de uma determinada tabela.
- Clustered — todas as tabelas são clustered no sentido de que os dados ficam armazenados em uma ou mais micro-partitions, mas a documentação do Snowflake define o termo assim: "Uma tabela com uma clustering key definida é considerada clustered."
- Well-clustered — descreve uma tabela que faz um bom pruning para as consultas típicas executadas sobre ela. Mas atenção: uma tabela well-clustered não é necessariamente clustered segundo a definição acima.
- Clustering key — uma clustering key (ou expressão) pode ser definida para uma tabela, ativando o serviço de clustering automático do Snowflake. Esse serviço é um processo serverless cobrado à parte, que reorganiza os dados nas micro-partitions conforme a clustering key especificada.
- Partitioning — partitioning não tem uma definição própria dentro do contexto do Snowflake.
- Warehouse cluster — a unidade de escala em um warehouse multi-clustered.
O que é uma micro-partition do Snowflake?
Uma micro-partition é um arquivo armazenado no serviço de blob storage do provedor de nuvem em que a conta Snowflake roda:
- AWS — S3
- Azure — Azure Blob Storage
- GCP — Google Cloud Storage
As micro-partitions usam um formato de arquivo proprietário e fechado criado pelo Snowflake. Elas têm um cabeçalho com metadados que descrevem os dados armazenados, e os dados em si ficam agrupados por coluna e guardados em formato comprimido.
Uma única micro-partition pode conter até 16MB de dados comprimidos (é daí que vem a mesma restrição do tipo variant), o que, sem compressão, costuma ficar entre 50 e 500MB. Tabelas pequenas (<500MB sem compressão) podem ter apenas uma micro-partition e, como o Snowflake não impõe limite de tamanho para tabelas, também não há limite para o número de micro-partitions que uma tabela pode ter.
Uma micro-partition sempre contém linhas completas de dados. Isso pode causar confusão, já que as micro-partitions também são um formato colunar de armazenamento. Mas esses dois atributos não se contradizem: é possível recuperar colunas individuais de uma micro-partition. Você vai ver as micro-partitions sendo descritas como 'colunar híbrido', justamente porque agrupam os dados tanto por linhas (a micro-partition) quanto por colunas (dentro de cada micro-partition).
Ok, chega de teoria, hora de um diagrama. Ao longo do post, vamos usar como exemplo uma tabela de pedidos (orders). Veja como é uma das micro-partitions armazenadas para essa tabela:
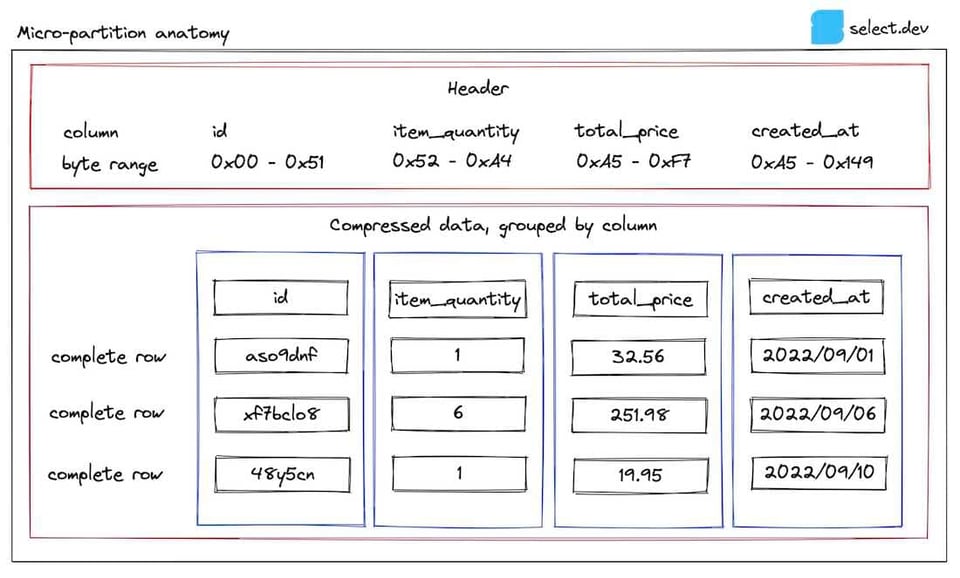
No cabeçalho ficam guardados os intervalos de bytes de cada coluna dentro da micro-partition, o que permite ao Snowflake recuperar apenas as colunas relevantes para uma consulta usando um byte range get. É por isso que as consultas ficam mais rápidas quando você reduz o número de colunas selecionadas.
Os metadados de cada coluna da micro-partition são armazenados pelo Snowflake em seu metadata cache na camada de cloud services. Esses metadados são usados para entregar resultados extremamente rápidos em consultas analíticas básicas, como count(*) e max(column). Há também metadados adicionais que não aparecem aqui, alguns deles não documentados, descritos pelo Snowflake como 'usados tanto para otimização quanto para processamento eficiente de consultas'.

Os valores mínimo e máximo são fundamentais, porque dão ao Snowflake a capacidade de fazer pruning.