Le découplage du compute et du stockage constitue un fondement architectural de Snowflake. Dans cet article, nous nous penchons sur la manière dont Snowflake stocke les données et sur l'impact considérable de ce mécanisme sur les performances des requêtes.
Rappel sur l'architecture de Snowflake
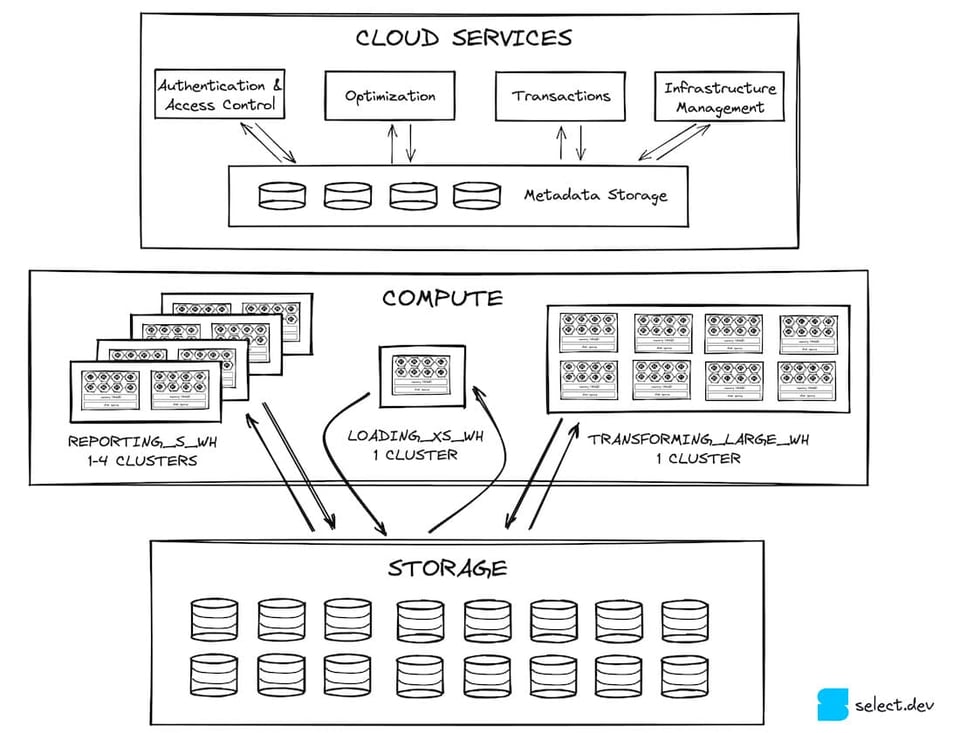
Dans un précédent article, nous avons vu comment l'architecture de Snowflake se décompose en trois couches horizontales. La première est la couche des services cloud, une catégorie très large qui regroupe toutes les fonctionnalités de Snowflake en dehors de l'exécution des requêtes. Ces services cloud interagissent avec la couche de traitement des requêtes, massivement parallèle. Les virtual warehouses de cette couche lisent et écrivent les données depuis la couche de stockage, qui repose sur S3 pour la majorité des clients Snowflake (la plupart des comptes Snowflake tournent sur AWS). C'est dans cette couche de stockage que résident les micro-partitions.
Micro-partitions, partitionnement, clustering : que signifient vraiment ces termes ?
Source de confusion fréquente, plusieurs notions similaires mais distinctes gravitent autour des micro-partitions. Voici un petit glossaire :
- Micro-partitions (le sujet de cet article) — l'unité de stockage dans Snowflake. Une micro-partition, pour faire simple, est un type de fichier sophistiqué. On les désigne parfois simplement par le terme partitions.
- Clustering — décrit la répartition des données entre les micro-partitions d'une table donnée.
- Clustered — toutes les tables sont clustered au sens où leurs données sont stockées dans une ou plusieurs micro-partitions, mais la documentation Snowflake précise : "Une table sur laquelle une clé de clustering est définie est considérée comme clustered."
- Well-clustered — une table well-clustered est une table qui se prête bien au pruning pour les requêtes qui lui sont habituellement adressées. Attention toutefois : une table well-clustered n'est pas nécessairement clustered au sens de la définition ci-dessus.
- Clé de clustering — une clé ou expression de clustering peut être définie sur une table pour activer le service de clustering automatique de Snowflake. Ce service serverless, facturé à l'usage, réorganise les données dans les micro-partitions afin de les aligner sur la clé de clustering spécifiée.
- Partitionnement — le partitionnement n'a pas de définition propre dans le contexte de Snowflake.
- Warehouse cluster — l'unité de scaling au sein d'un warehouse multi-cluster.
Qu'est-ce qu'une micro-partition Snowflake ?
Une micro-partition est un fichier, stocké dans le service de blob storage du fournisseur cloud sur lequel tourne le compte Snowflake :
- AWS — S3
- Azure — Azure Blob Storage
- GCP — Google Cloud Storage
Les micro-partitions utilisent un format de fichier propriétaire et fermé conçu par Snowflake. Elles comportent un en-tête contenant des métadonnées qui décrivent les données stockées, les données elles-mêmes étant regroupées par colonne et conservées sous forme compressée.
Une seule micro-partition peut contenir jusqu'à 16 Mo de données compressées (d'où la même contrainte appliquée aux variants), ce qui représente en règle générale entre 50 et 500 Mo non compressés. Les petites tables (moins de 500 Mo non compressés) peuvent ne contenir qu'une seule micro-partition et, comme Snowflake n'impose aucune limite de taille de table, il n'existe par extension aucune limite au nombre de micro-partitions d'une même table.
Une micro-partition contient toujours des lignes de données complètes. Cela peut prêter à confusion, car les micro-partitions reposent également sur un format de stockage en colonnes. Ces deux propriétés ne sont pas contradictoires : il est tout à fait possible d'extraire des colonnes individuelles d'une micro-partition. Vous entendrez parfois parler de format hybrid columnar pour décrire ce double regroupement, à la fois par lignes (la micro-partition) et par colonnes (au sein de chaque micro-partition).
Assez de théorie, passons à un schéma. Tout au long de cet article, nous prendrons l'exemple d'une table de commandes (orders). Voici à quoi ressemble l'une des micro-partitions stockées pour cette table :
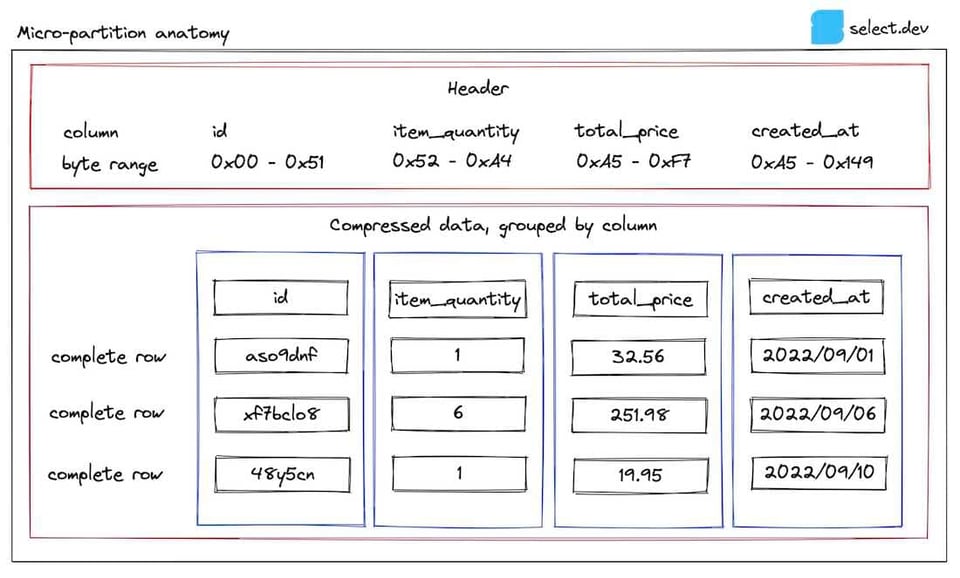
Les plages d'octets de chaque colonne au sein de la micro-partition sont consignées dans l'en-tête, ce qui permet à Snowflake de ne récupérer que les colonnes utiles à une requête grâce à un byte range get. C'est la raison pour laquelle les requêtes s'exécutent plus rapidement lorsque l'on réduit le nombre de colonnes sélectionnées.
Snowflake conserve les métadonnées de chaque colonne d'une micro-partition dans son cache de métadonnées, situé dans la couche des services cloud. Ces métadonnées permettent d'obtenir des résultats extrêmement rapides sur des requêtes analytiques basiques comme count(*) ou max(column). D'autres métadonnées sont également stockées sans figurer ici, dont certaines ne sont pas documentées et que Snowflake décrit comme "utilisées à la fois pour l'optimisation et le traitement efficace des requêtes".

Ce sont surtout les valeurs min et max qui donnent à Snowflake la capacité d'effectuer du pruning.
Qu'est-ce que le pruning de requêtes dans Snowflake ?
Le pruning est une technique utilisée par Snowflake pour réduire le nombre de micro-partitions lues lors de l'exécution d'une requête. La lecture des micro-partitions est l'une des étapes les plus coûteuses d'une requête, car elle suppose de lire des données à distance via le réseau. Lorsqu'un filtre est appliqué dans une clause where, une jointure ou une sous-requête, Snowflake cherche à écarter toutes les micro-partitions dont il sait qu'elles ne contiennent pas de données pertinentes. Pour que ce mécanisme fonctionne, les micro-partitions doivent présenter une plage de valeurs étroite sur la colonne servant de filtre.
Prenons un peu de recul et regardons l'ensemble de la table orders. Dans cet exemple, la table contient 28 micro-partitions, chacune comportant trois lignes de données (en pratique, une micro-partition contient généralement plusieurs centaines de milliers de lignes).

Cette table d'exemple est triée, et donc well-clustered sur la colonne created_at (chaque micro-partition contient une plage de valeurs étroite pour cette colonne). Un utilisateur exécute la requête suivante :
1select * from orders where created_at > '2022/08/14'
Pendant la phase de planification, Snowflake vérifie quelles micro-partitions contiennent des données pertinentes pour la requête. Ici, seules les commandes créées après le 2022/08/14 sont nécessaires. Le planificateur identifie rapidement ces enregistrements comme présents uniquement dans les trois premières micro-partitions mises en évidence sur le schéma, en s'appuyant sur les métadonnées min et max de la colonne created_at. Les autres micro-partitions sont ignorées (pruned), et Snowflake n'a plus qu'à lire un petit sous-ensemble de la table.
Mesurer l'efficacité du pruning
Le query profile de Snowflake regorge d'informations précieuses, dont les performances de pruning. Il n'est pas possible de connaître les statistiques de pruning d'une requête avant son exécution. À noter par ailleurs que certaines requêtes ne nécessitent pas de scan de table : aucune statistique de pruning n'est alors affichée.
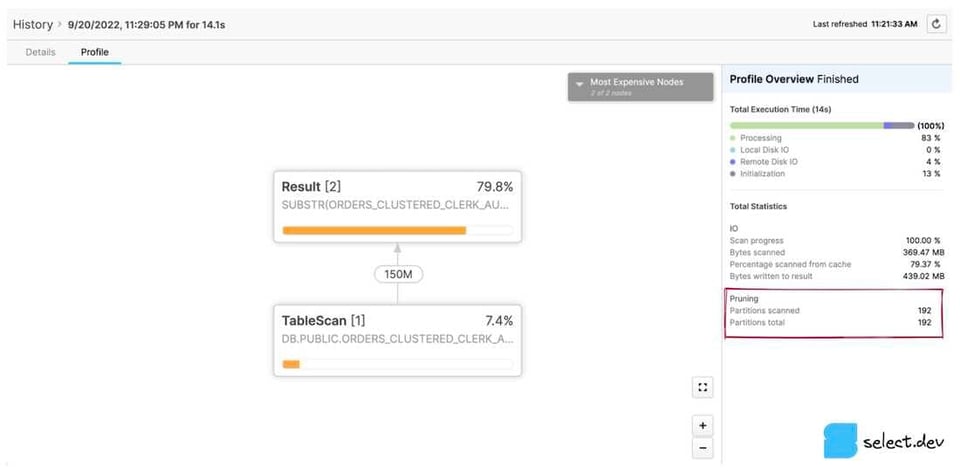
Interface web classique
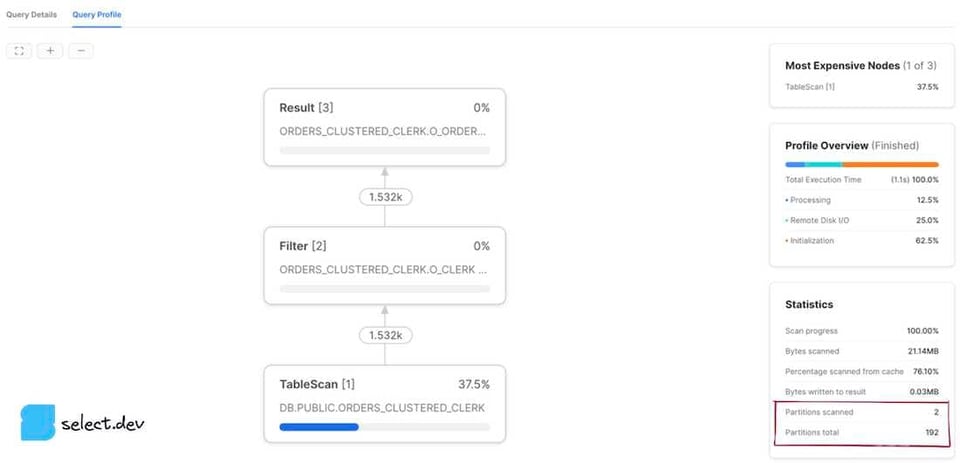
Dans la page History ou Worksheets, cliquez sur un ID de requête pour accéder à sa page Details. Cliquez ensuite sur l'onglet Profile, puis, s'il s'affiche, sur le numéro de la dernière étape pour visualiser toutes les statistiques. Dans le volet de droite, une section Total Statistics contient une rubrique Pruning, qui affiche deux valeurs : partitions scanned et partitions total.
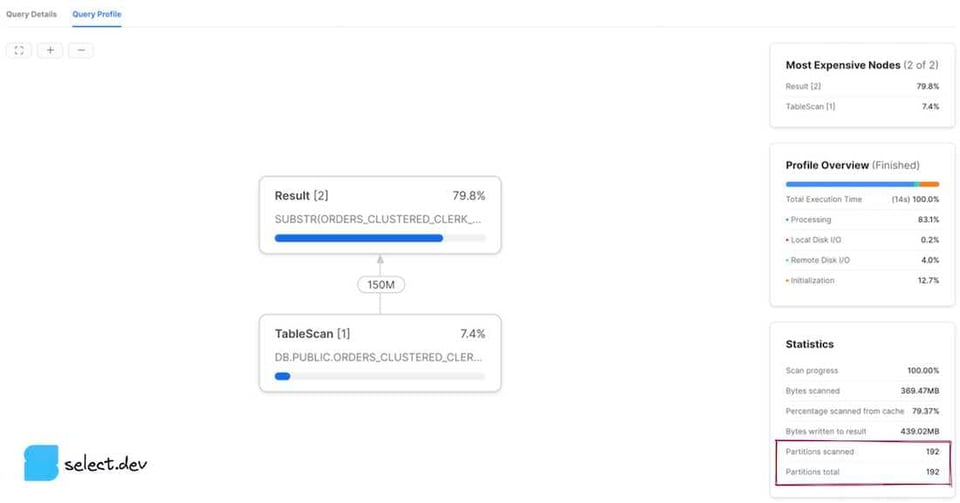
Interface web Snowsight
Après l'exécution d'une requête, un volet Query Details apparaît à droite de la zone des résultats. Cliquez sur les trois points, puis sur View Query Profile. Pour consulter le profile d'une requête exécutée précédemment, cliquez sur le bouton Activity dans la barre de navigation de gauche, puis sur Query History. Sélectionnez ensuite la requête voulue, puis cliquez sur l'onglet Query Profile. Les valeurs partitions scanned et partitions total s'affichent alors.
Interpréter les résultats
La valeur partitions scanned correspond au nombre de partitions lues par la requête. La valeur partitions total correspond au nombre total de micro-partitions existantes pour les tables interrogées. Une requête qui prune efficacement présente un petit nombre de partitions scanned par rapport au total. Les profiles ci-dessus illustrent une requête sans aucun pruning, puisque le nombre de partitions scannées est égal au total. Si l'on ajoute en revanche un filtre que Snowflake peut exploiter via les métadonnées des micro-partitions pour pruner efficacement, les résultats s'améliorent nettement.
En résumé
Nous avons vu ce que sont les micro-partitions, comment Snowflake les exploite pour optimiser les requêtes via le pruning, ainsi que les différentes façons d'en mesurer l'efficacité.
Dans notre prochain article, nous verrons comment agir sur le clustering d'une table afin d'améliorer ses performances de pruning.
Niall Woodward · Co-fondateur et CTO de SELECT
Niall est co-fondateur et CTO de SELECT, une plateforme SaaS de gestion et d'optimisation des coûts Snowflake. Avant de lancer SELECT, Niall était data engineer chez Brooklyn Data Company et dans plusieurs startups. Passionné d'open source, il est également mainteneur de SQLFluff et créateur de trois packages dbt : dbt_artifacts, dbt_snowflake_monitoring et dbt_query_tags.