CTEs sind ein äußerst wertvolles Werkzeug, um SQL-Logik zu modularisieren und wiederzuverwenden. Gleichzeitig stehen sie häufig im Fokus von Optimierungsdiskussionen, da ihre Nutzung mit unerwarteter und mitunter ineffizienter Query-Ausführung in Verbindung gebracht wird. In diesem Beitrag schauen wir uns an, wie sich CTEs auf Query-Pläne auswirken, wann ihr Einsatz unproblematisch ist und wann man besser darauf verzichtet.
Einleitung
In den letzten Jahren ist viel über die Performance-Auswirkungen von CTEs geschrieben worden:
- CTEs are pass-throughs – Tristan Handy – 07.11.2018
- Snowflake query optimizer: unoptimized – Dominik Golebiewski – 13.10.2021
- CTE Considerations – bennieregenold7 – 22.07.2022
- Ein aktueller Thread im dbt Slack – 22.02.2023
Dass die Diskussion bis heute anhält, zeigt allerdings: Eine abschließende Antwort gibt es noch nicht. Dieser Beitrag liefert eine fundierte Orientierung, wann Sie CTEs einsetzen sollten und wann eher nicht. Der Query-Optimizer von Snowflake wird laufend weiterentwickelt – wie schon in den oben verlinkten Beiträgen kann sich das hier beobachtete Verhalten daher mit der Zeit ändern.
Wir nutzen Query-Profile, um nachzuvollziehen, wie sich unterschiedliche Query-Designs auf die Ausführung auswirken. Falls Query-Profile für Sie Neuland sind oder Sie eine Auffrischung brauchen, werfen Sie einen Blick in unseren Beitrag dazu, wie Sie das Query Profile von Snowflake nutzen.
Starten wir mit einer kurzen Wiederholung: Was sind CTEs überhaupt, und warum sind sie so beliebt?
Was sind CTEs?
Ein CTE (Common Table Expression) ist eine benannte Subquery. CTEs werden mit einer with-Klausel deklariert und lassen sich anschließend über ihren Namen ansprechen:
with my_cte as (
select 1
)
select * from my_cte
CTEs werden durch Kommas getrennt – so lassen sich mehrere hintereinander definieren:
with my_cte as (
select 1
),
my_cte_2 as (
select 2
)
select *
from my_cte
left join my_cte_2
Bei Bedarf lassen sich CTEs auch verschachteln (auch wenn die Lesbarkeit darunter leidet):
with my_cte as (
with my_inner_cte as (
select 1
)
select * from my_inner_cte
)
select *
from my_cte
Warum CTEs einsetzen?
Die wichtigsten Gründe für den Einsatz von CTEs:
- CTEs helfen dabei, SQL-Logik in voneinander isolierte Subqueries aufzuteilen. Das vereinfacht das Debugging, da Sie einen CTE einfach per
select * from cteisoliert ausführen können. - CTEs ermöglichen einen prozedural anmutenden, von oben nach unten lesbaren SQL-Stil – ein Pluspunkt für Code Review und Wartbarkeit.
- CTEs unterstützen das DRY-Prinzip (don't repeat yourself), indem sie eine zentrale Stelle bieten, an der mehrfach referenzierte Logik definiert wird.
Wie behandelt Snowflake CTEs im Query-Plan?
Um die Performance-Auswirkungen von CTEs einzuordnen, müssen wir zunächst klären, wie Snowflake CTE-Deklarationen bei der Query-Ausführung verarbeitet.
Sind CTEs Pass-throughs?
Ja – solange der CTE nur einmal referenziert wird. Pass-through heißt: Die Query wird identisch verarbeitet, egal ob ein CTE verwendet wird oder nicht. Wird ein CTE nur einmal referenziert, ist er immer ein Pass-through und taucht im Query-Profil überhaupt nicht auf. Ein einmal referenzierter CTE hat also nie negative Auswirkungen auf die Performance gegenüber dem Verzicht auf den CTE.
with sample_data as (
select *
from snowflake_sample_data.tpch_sf1.customer
)
select *
from sample_data
where c_nationkey = 14
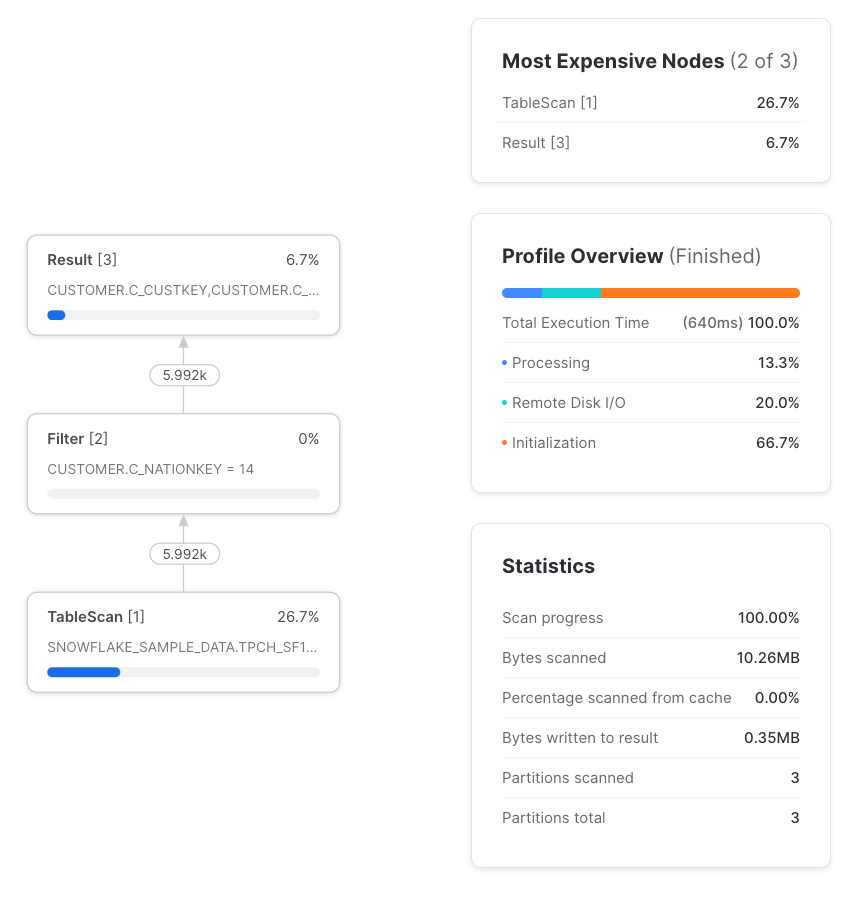
Referenzieren wir denselben CTE mehrfach, sieht das Bild jedoch anders aus: Die Ausführung unterscheidet sich nun deutlich von einer direkten Tabellenreferenz ohne CTE.
with sample_data as (
select *
from snowflake_sample_data.tpch_sf1.customer
),
nation_14_customers as (
select *
from sample_data
where c_nationkey = 14
),
nation_9_customers as (
select *
from sample_data
where c_nationkey = 9
Code ausklappen
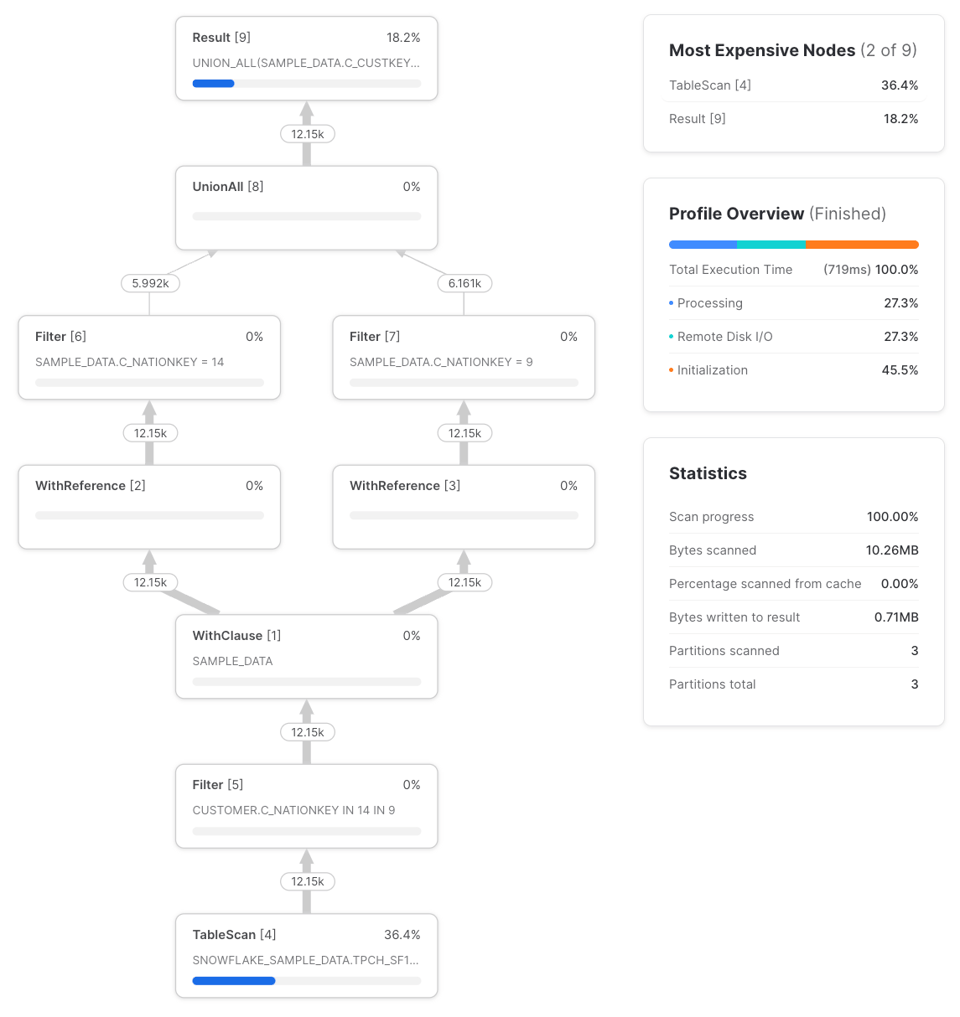
Es tauchen zwei neue Node-Typen auf: WithClause und WithReference. Die WithClause steht für einen Ausgabestream samt Buffer aus dem definierten sample_data-CTE, der dann von jedem WithReference-Node konsumiert wird. Beachten Sie, dass Snowflake die Filter aus den CTEs nation_14_customers und nation_9_customers intelligent bis in den TableScan vor der WithClause hineinzieht (Predicate Pushdown). Früher war das nicht der Fall, wie in Dominiks Beitrag beschrieben. Ob dieses Verhalten auch bei komplexeren Queries greift, sollte man im Einzelfall prüfen – in diesem Beispiel ist das Profil jedenfalls identisch mit dieser Variante:
with sample_data as (
select *
from snowflake_sample_data.tpch_sf1.customer
where c_nationkey in (14, 9)
),
nation_14_customers as (
select *
from sample_data
where c_nationkey = 14
),
nation_9_customers as (
select *
from sample_data
Code ausklappen
Ersetzen wir nun die sample_data-CTE-Referenzen durch eine direkte Tabellenreferenz auf snowflake_sample_data.tpch_sf1.customer, ergeben sich folgende Unterschiede im Ausführungsplan:
with nation_14_customers as (
select *
from snowflake_sample_data.tpch_sf1.customer
where c_nationkey = 14
),
nation_9_customers as (
select *
from snowflake_sample_data.tpch_sf1.customer
where c_nationkey = 9
)
select *
from nation_14_customers
union all
Code ausklappen
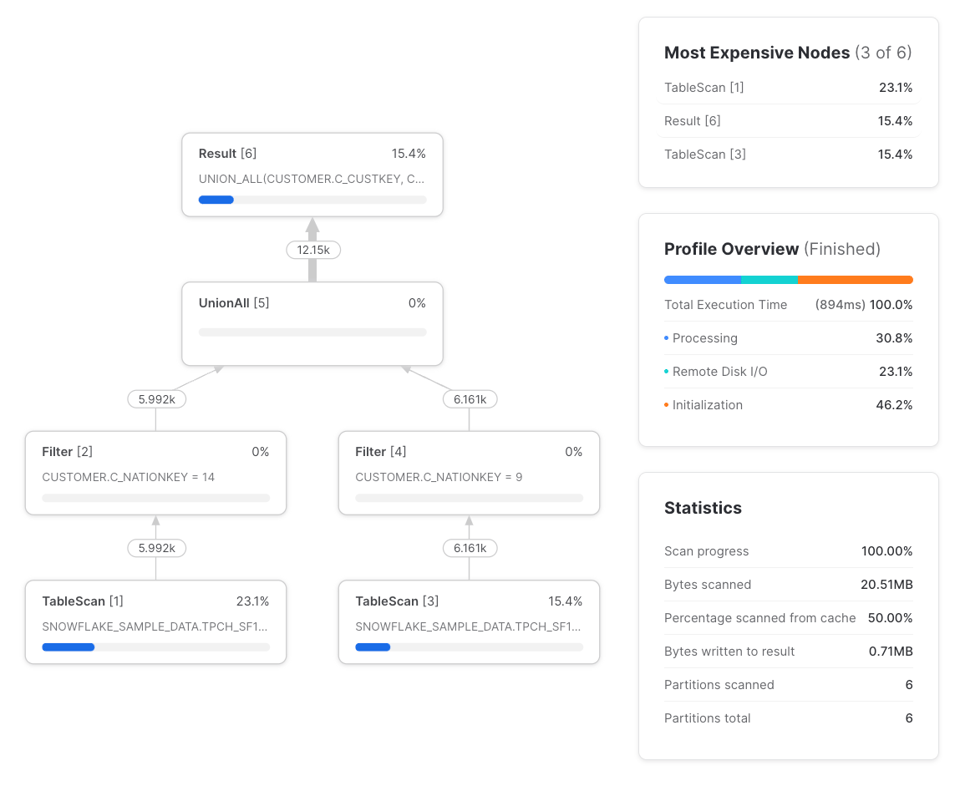
Die Unterschiede:
- Zwei
TableScans statt einem. Der linkeTableScanliest aus dem Remote Storage, der rechte greift auf das lokale, im Warehouse gecachte Ergebnis des linken zurück. Trotz zweierTableScans erfolgt nur bei einem davon ein Remote-Datenabruf. - Zwei
Filterstatt drei. Wird ein Filter direkt nach einemTableScanangewendet, übernimmt derTableScan-Node das Filtern selbst – deshalb sind Input- und Output-Zeilenzahlen des Filters identisch. - Keine
WithClause- oderWithReference-Nodes.
Jetzt, da wir wissen, wie CTEs in einen Ausführungsplan übersetzt werden, sehen wir uns die Performance-Auswirkungen genauer an.
Manchmal ist es schneller, Logik zu wiederholen, statt einen CTE wiederzuverwenden
In den meisten Fällen ist Snowflakes Ansatz, das Ergebnis eines CTE einmal zu berechnen und an nachgelagerte Knoten zu verteilen, die performanteste Variante. In manchen Situationen übersteigen die Kosten für Buffering und Verteilung des CTE-Ergebnisses jedoch den Aufwand einer Neuberechnung – zumal die TableScan-Nodes ohnehin gecachte Ergebnisse nutzen.
Hier ein konstruiertes Beispiel, das den CTE lineitems dreimal referenziert:
with lineitems as (
select *
from snowflake_sample_data.tpch_sf100.lineitem
where l_receiptdate > '1998-01-01'
),
lineitem_future_sales as (
select
a.l_orderkey,
a.l_linenumber,
sum(b.l_quantity) as future_part_order_total
from lineitems as a
left join lineitems as b
on a.l_partkey = b.l_partkey
and b.l_receiptdate > a.l_receiptdate
Code ausklappen
Über drei Durchläufe hinweg brauchte diese Query auf einem Small Warehouse im Schnitt 1 Min. 17 Sek. Hier ein Beispielprofil:
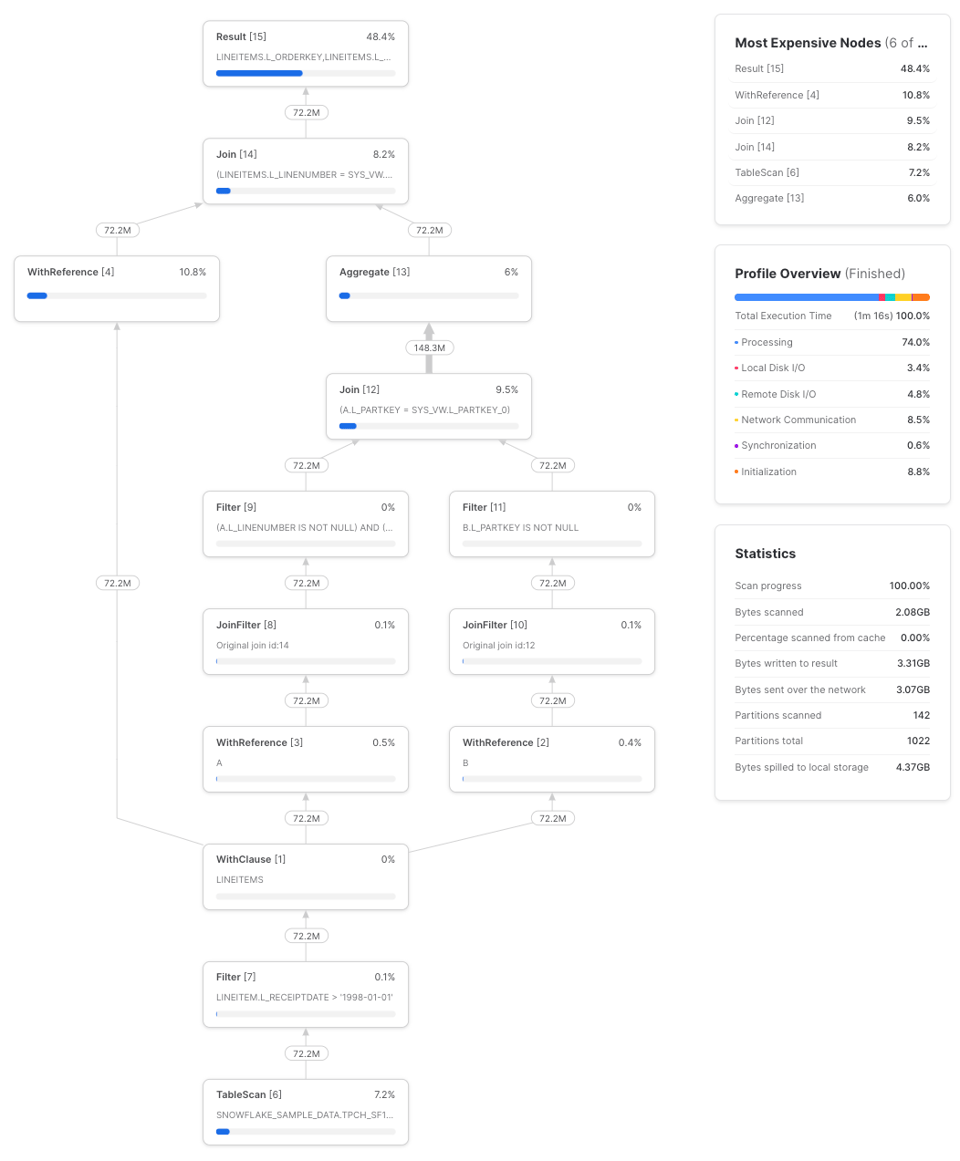
Schreiben wir die Query stattdessen so um, dass der lineitems-CTE als Subquery wiederholt wird:
with lineitem_future_sales as (
select
a.l_orderkey,
a.l_linenumber,
sum(b.l_quantity) as future_part_order_total
from (
select *
from snowflake_sample_data.tpch_sf100.lineitem
where l_receiptdate > '1998-01-01'
) as a
left join (select *
from snowflake_sample_data.tpch_sf100.lineitem
where l_receiptdate > '1998-01-01'
) as b
on a.l_partkey = b.l_partkey
Code ausklappen
Die Query benötigt nun im Schnitt 1 Min. 7 Sek. über drei Durchläufe – rund 10 % schneller. Query-Profil:
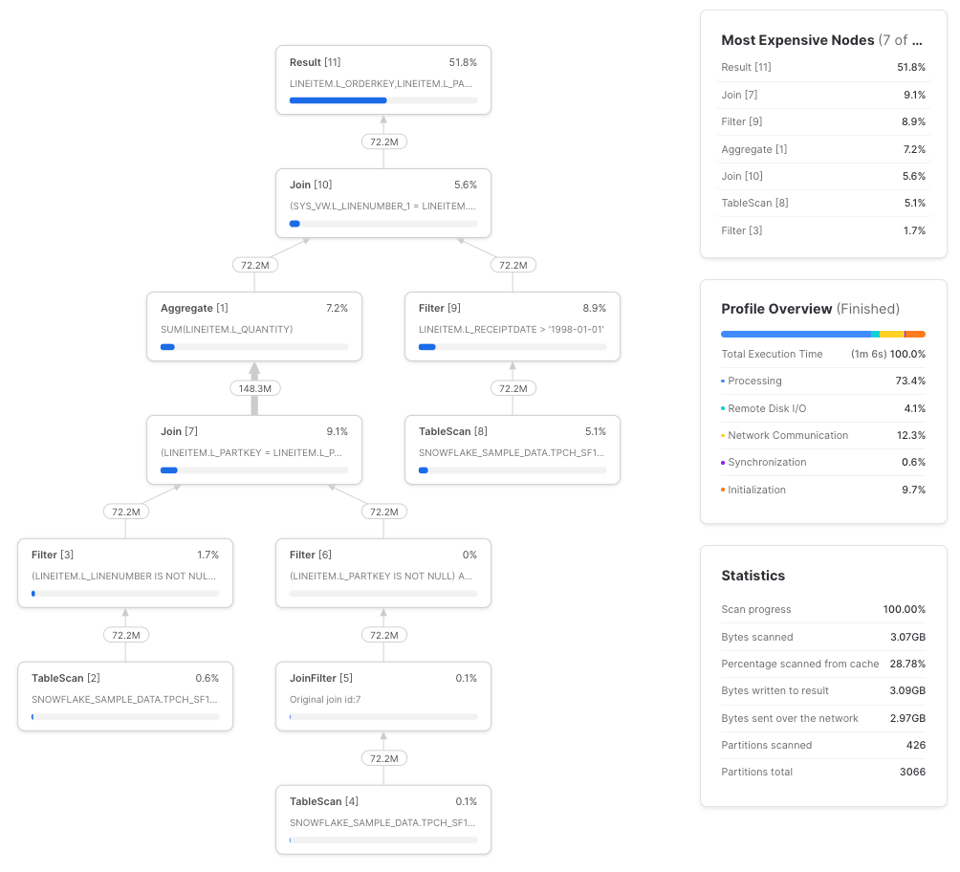
lineitems ist ein einfacher CTE. Ab einem bestimmten Komplexitätsgrad wird es günstiger, den CTE einmal zu berechnen und sein Ergebnis an nachgelagerte Referenzen weiterzureichen, statt ihn mehrfach neu zu berechnen. Konsistent ist dieses Verhalten allerdings nicht (wie wir am einfachen Beispiel unter Sind CTEs Pass-throughs? gesehen haben), daher hilft nur Ausprobieren. So lässt sich der Zusammenhang visualisieren:
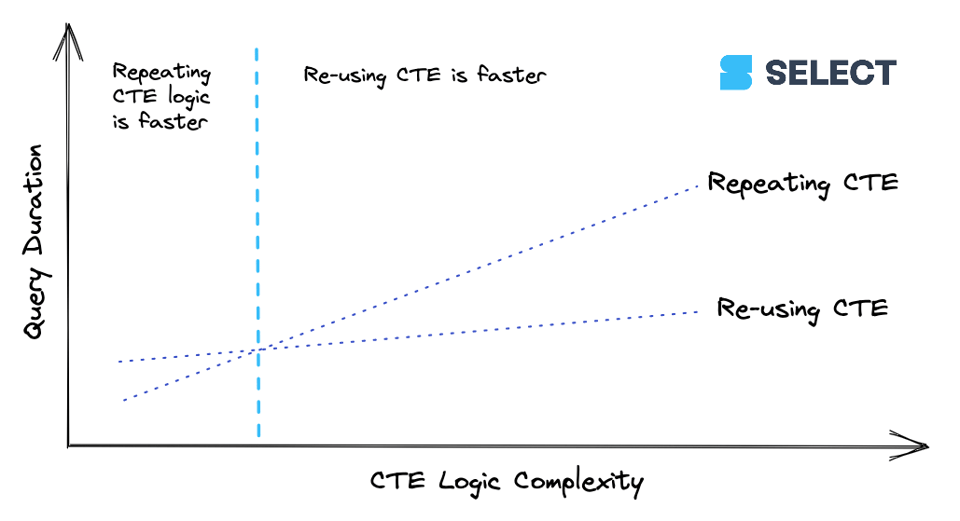
Empfehlung
CTEs lassen sich in Snowflake bedenkenlos einsetzen, und ein nur einmal referenzierter CTE wirkt sich nie auf die Performance aus. Abgesehen von sehr speziellen Fällen wie dem obigen erzielen Sie die beste Performance, indem Sie den CTE einmal berechnen und wiederverwenden, statt seine Logik zu wiederholen. Wie im vorherigen Abschnitt gezeigt, zieht Snowflake Filter intelligent in CTEs hinein und vermeidet so unnötige Full Table Scans.
Wenn Sie jedoch eine konkrete Query optimieren, bei der Performance und Kosteneffizienz entscheidend sind und sich der Aufwand lohnt, experimentieren Sie damit, die CTE-Logik zu wiederholen. Diese kann entweder in mehreren Subqueries dupliziert oder in einer View definiert und mehrfach referenziert werden, so wie es zuvor der CTE war.
In manchen Szenarien verhindern CTEs das Column Pruning
In früheren Beiträgen haben wir das besondere Design der Micro-Partitionen von Snowflake beschrieben und wie sie eine leistungsstarke Optimierung namens Micro-Partition-Pruning ermöglichen. Dank des spaltenbasierten Speicherformats erlauben sie zudem Column Pruning. Das ist wichtig, denn so müssen nur die in der Query selektierten Spalten tatsächlich über das Netzwerk geladen werden.
Column Pruning funktioniert immer, wenn ein CTE nur einmal referenziert wird (dann wird er behandelt, als existiere er gar nicht). Ein einfacher Fall:
with sample_data as (
select *
from snowflake_sample_data.tpch_sf1.customer
)
select c_name, c_address
from sample_data
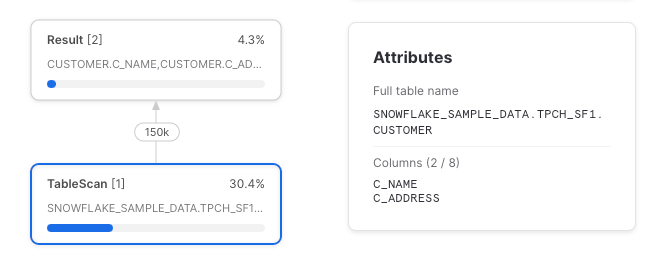
Wie zu sehen, werden nur die beiden ausgewählten Spalten aus der zugrunde liegenden Tabelle gelesen. Aber wie wir wissen: Ein nur einmal referenzierter CTE ist ein Pass-through und wird unabhängig von seiner Existenz in den Query-Plan kompiliert.
Column Pruning greift nicht mehr, wenn ein CTE mehrfach referenziert wird
Referenzieren wir den CTE dieses Mal zweimal und selektieren in jeder Referenz nur eine einzelne Spalte:
with sample_data as (
select *
from snowflake_sample_data.tpch_sf1.customer
),
customer_names as (
select c_name
from sample_data
),
customer_addresses as (
select c_address
from sample_data
)
Code ausklappen
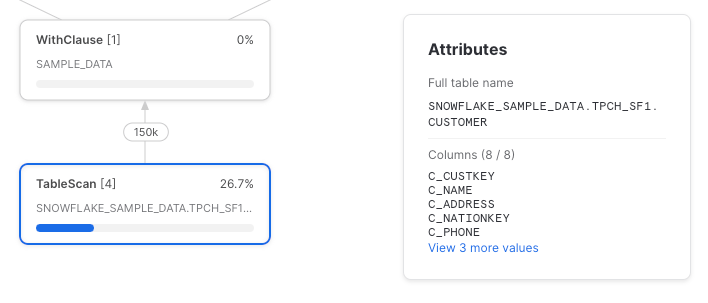
Snowflake hat die Spaltenreferenzen leider nicht in den darunterliegenden Table Scan hinuntergezogen. Hier das vollständige Query-Profil:
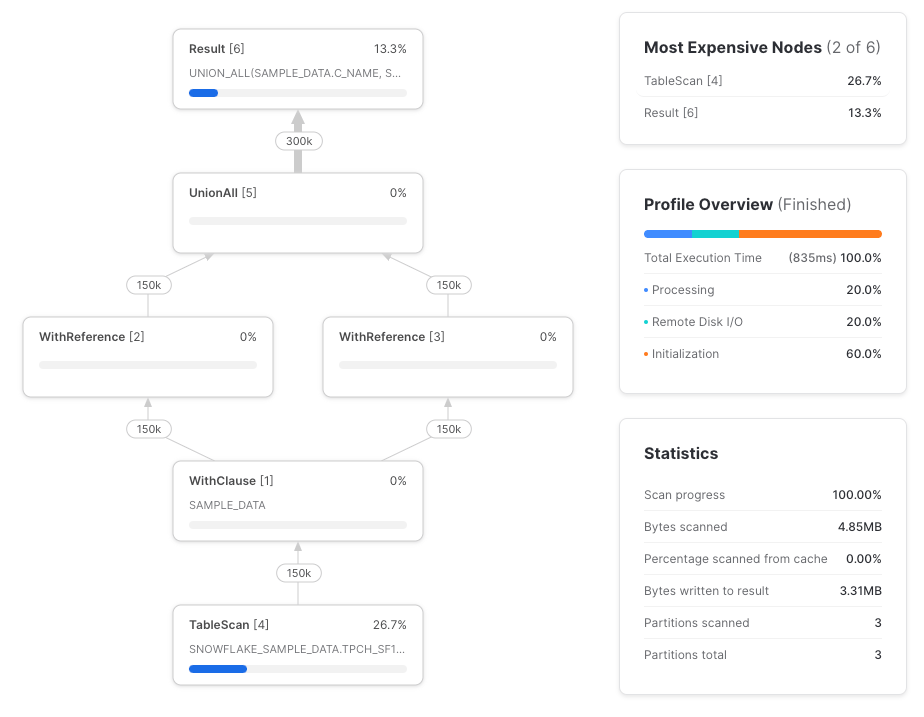
Versuchen wir es erneut, diesmal mit direkten Tabellenreferenzen:
with customer_names as (
select c_name
from snowflake_sample_data.tpch_sf1.customer
),
customer_addresses as (
select c_address
from snowflake_sample_data.tpch_sf1.customer
)
select c_name
from customer_names
union all
select c_address
from customer_addresses
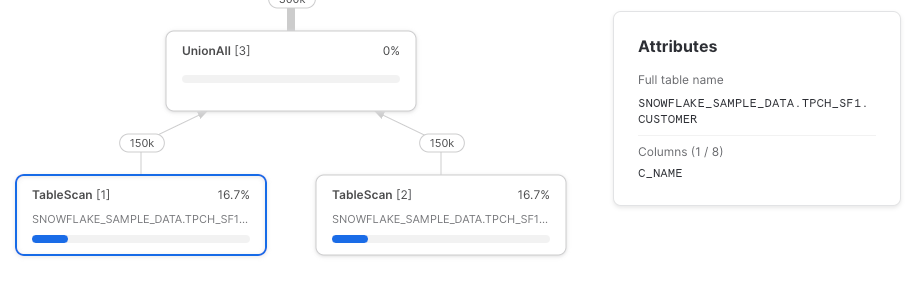
Wie erwartet erhalten wir zwei TableScan-Nodes, die jeweils nur die referenzierten Spalten laden.
Column Pruning versagt bei Wildcards und Joins
Ein weiterer Fall, in dem Snowflake möglicherweise keinen Column-Pruning-Pushdown durchführt, sind Joins (danke an Paul Vernon für den Hinweis). Der TableScan der Tabelle nation sollte idealerweise nur die Spalten n_nationkey und n_name laden, holt aber stattdessen alle.
with nations as (
select *
from snowflake_sample_data.tpch_sf1.nation
),
joined as (
select *
from snowflake_sample_data.tpch_sf1.customer
left join nations
on customer.c_nationkey = nations.n_nationkey
)
select c_address, n_name from joined
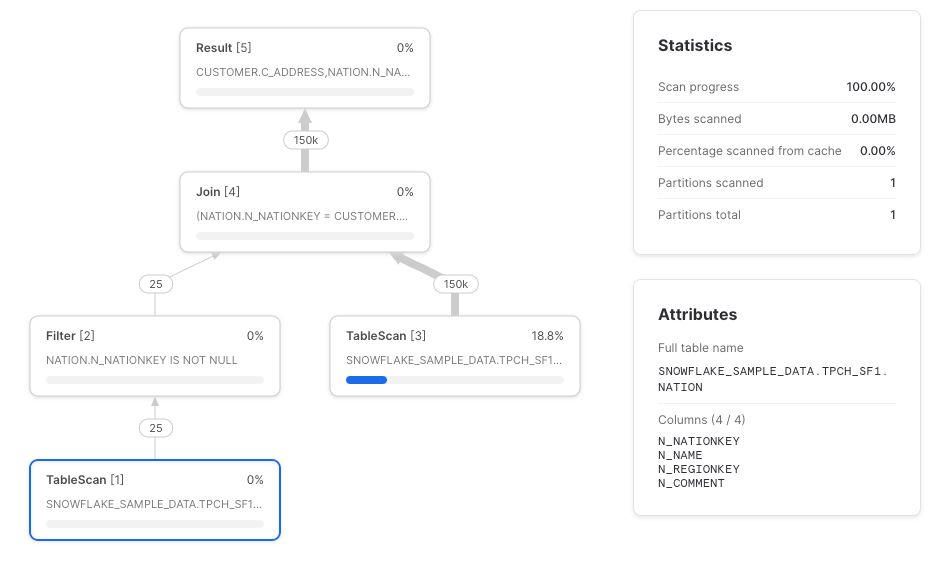
Empfehlung
Wir empfehlen, Spaltenreferenzen beim Einsatz von CTEs explizit aufzuführen, damit TableScans nur die tatsächlich benötigten Spalten laden. Läuft eine Query allerdings ohnehin schnell genug, kann der Wartungsaufwand durch die explizite Auflistung den Nutzen übersteigen.
Entsprechend raten wir von select * from table-CTEs ab, wie sie im Style Guide von dbt empfohlen werden. Referenzieren Sie stattdessen die benötigte Tabelle direkt, um Column Pruning sicherzustellen.
Also: Sollten Sie CTEs in Snowflake einsetzen?
In nahezu allen Fällen lautet die Antwort: Ja. Wenn Ihre Query schnell genug läuft und es keine Kostenbedenken gibt, spricht nichts dagegen. Wichtig ist, nicht unnötig zu optimieren – der Zeit- und Opportunitätsaufwand kann den Nutzen schnell übersteigen.
Wenn Sie jedoch eine konkrete Query mit CTEs optimieren, prüfen Sie Folgendes:
- Wird ein einfacher CTE mehrfach referenziert? Wenn ein CTE wenig Arbeit verrichtet, kann der Overhead der
WithClause- undWithReference-Nodes höher ausfallen, als die CTE-Berechnung schlicht über Subqueries oder eine View zu wiederholen. - Werden Spaltenreferenzen wie erwartet in die
TableScan-Nodes hinuntergezogen und gepruned? Falls nicht, listen Sie die benötigten Spalten möglichst früh in der Query explizit auf. Bei breiten Tabellen kann das die Geschwindigkeit desTableScan-Nodes erheblich verbessern.
Optimierungspotenziale zu erkennen und umzusetzen ist zeitaufwendig. SELECT macht es einfach und legt Optimierungen wie die in diesem Beitrag automatisch offen. Profitieren Sie ab Tag 1 von automatisierten Einsparungen, identifizieren Sie Kostentreiber schnell und optimieren Sie Ihre Snowflake-workloads. Sichern Sie sich heute Ihren Zugang oder buchen Sie über die Links unten eine Demo.
Niall Woodward · Co-Founder & CTO von SELECT
Niall ist Co-Founder & CTO von SELECT, einer SaaS-Plattform für Snowflake-Kostenmanagement und -Optimierung. Vor SELECT war Niall Data Engineer bei Brooklyn Data Company und mehreren Startups. Als Open-Source-Enthusiast ist er außerdem Maintainer von SQLFluff sowie Schöpfer dreier dbt-Pakete: dbt_artifacts, dbt_snowflake_monitoring und dbt_query_tags.