Los CTEs son una herramienta muy valiosa para modularizar y reutilizar la lógica SQL. También aparecen seguido en las discusiones sobre optimización, ya que su uso se ha asociado con una ejecución de consultas inesperada y, en ocasiones, ineficiente. En este post analizamos cómo impactan los CTEs en los planes de consulta, cuándo conviene usarlos y cuándo es mejor evitarlos.
Introducción
En los últimos años se ha escrito bastante sobre cómo impactan los CTEs en el rendimiento:
- CTEs are pass-throughs - Tristan Handy - 2018-11-07
- Snowflake query optimizer: unoptimized - Dominik Golebiewski - 2021-10-13
- CTE Considerations - bennieregenold7 - 2022-07-22
- Un hilo reciente en el Slack de dbt - 2023-02-22
Pero que la discusión siga viva demuestra que todavía no hay una conclusión clara. Este post busca ofrecer una serie de pautas razonadas sobre cuándo usar CTEs y cuándo evitarlos. El optimizador de consultas de Snowflake mejora de forma continua y, como en los posts enlazados arriba, el comportamiento que se observa acá cambiará con el tiempo.
Nos vamos a apoyar en los query profiles para entender cómo impactan los distintos diseños de consulta en la ejecución. Si los query profiles son nuevos para ti o quieres repasarlos, échale un vistazo a nuestro post sobre cómo usar el query profile de Snowflake.
Empecemos con un repaso de qué son los CTEs y por qué son tan populares.
¿Qué son los CTEs?
Un CTE, o common table expression, es una subconsulta con un nombre asociado. Se declaran con una cláusula with y luego se puede hacer un select usando ese identificador:
with my_cte as (
select 1
)
select * from my_cte
Los CTEs se separan con comas, así que podemos definir varios uno tras otro:
with my_cte as (
select 1
),
my_cte_2 as (
select 2
)
select *
from my_cte
left join my_cte_2
También podemos anidar CTEs dentro de otros CTEs si queremos (¡aunque se vuelven difíciles de leer!):
with my_cte as (
with my_inner_cte as (
select 1
)
select * from my_inner_cte
)
select *
from my_cte
¿Por qué usar CTEs?
Las razones principales para usar CTEs son:
- Los CTEs ayudan a separar la lógica SQL en subconsultas independientes y aisladas. Eso facilita la depuración, ya que basta con hacer
select * from ctepara ejecutar un CTE por separado. - Los CTEs permiten escribir SQL con un estilo casi procedimental, de arriba hacia abajo, lo que facilita la revisión de código y el mantenimiento.
- Los CTEs ayudan a cumplir con el principio DRY (don't repeat yourself), al ofrecer un único lugar donde definir la lógica que se referencia varias veces más adelante.
¿Cómo trata Snowflake los CTEs en el plan de consulta?
Para entender las implicaciones de los CTEs en el rendimiento, primero hay que ver cómo gestiona Snowflake la declaración de un CTE durante la ejecución de la consulta.
¿Son los CTEs pass-throughs?
Sí, siempre y cuando el CTE se referencie una sola vez. Por pass-through entendemos que la consulta se procesa igual se use o no el CTE. Cuando un CTE se referencia una sola vez, siempre es pass-through y el query profile no muestra ni rastro de él. Por lo tanto, usar un CTE que se referencia una sola vez nunca impactará el rendimiento frente a no usarlo.
with sample_data as (
select *
from snowflake_sample_data.tpch_sf1.customer
)
select *
from sample_data
where c_nationkey = 14
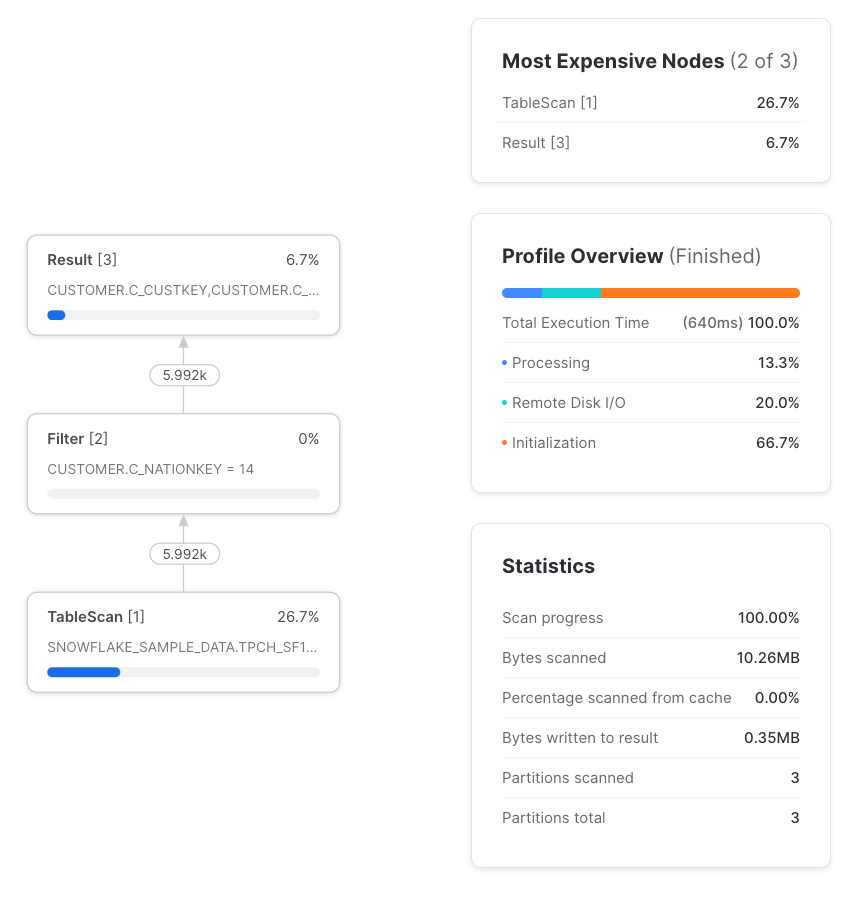
Pero si referenciamos ese CTE más de una vez, la cosa cambia, y la ejecución de la consulta ya no es la misma que si hubiéramos referenciado la tabla directamente en lugar de usar un CTE.
with sample_data as (
select *
from snowflake_sample_data.tpch_sf1.customer
),
nation_14_customers as (
select *
from sample_data
where c_nationkey = 14
),
nation_9_customers as (
select *
from sample_data
where c_nationkey = 9
Expandir código
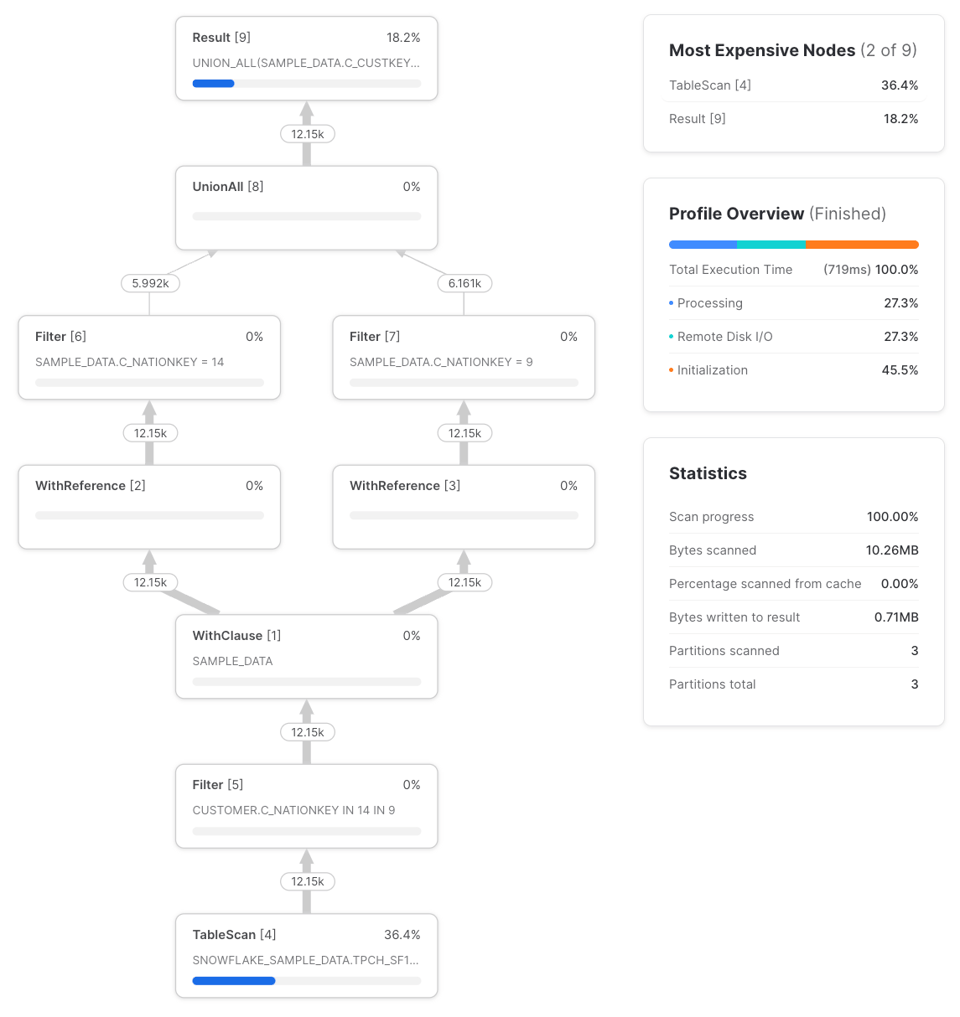
Aparecen dos tipos de nodos nuevos: WithClause y WithReference. El WithClause representa un flujo de salida y un buffer del CTE sample_data que definimos, que luego consume cada nodo WithReference. Fíjate en que Snowflake hace un 'push down' inteligente del filtro de los CTEs nation_14_customers y nation_9_customers hacia el TableScan antes del WithClause. Antes Snowflake no lo hacía, como se reportó en el post de Dominik. Vale la pena comprobar que este comportamiento se aplica a consultas más complejas, pero para esta consulta el profile es el mismo que si hubiéramos escrito la consulta así:
with sample_data as (
select *
from snowflake_sample_data.tpch_sf1.customer
where c_nationkey in (14, 9)
),
nation_14_customers as (
select *
from sample_data
where c_nationkey = 14
),
nation_9_customers as (
select *
from sample_data
Expandir código
Ahora reemplacemos las referencias al CTE sample_data por una referencia directa a la tabla snowflake_sample_data.tpch_sf1.customer y veamos las diferencias en el plan de ejecución:
with nation_14_customers as (
select *
from snowflake_sample_data.tpch_sf1.customer
where c_nationkey = 14
),
nation_9_customers as (
select *
from snowflake_sample_data.tpch_sf1.customer
where c_nationkey = 9
)
select *
from nation_14_customers
union all
Expandir código
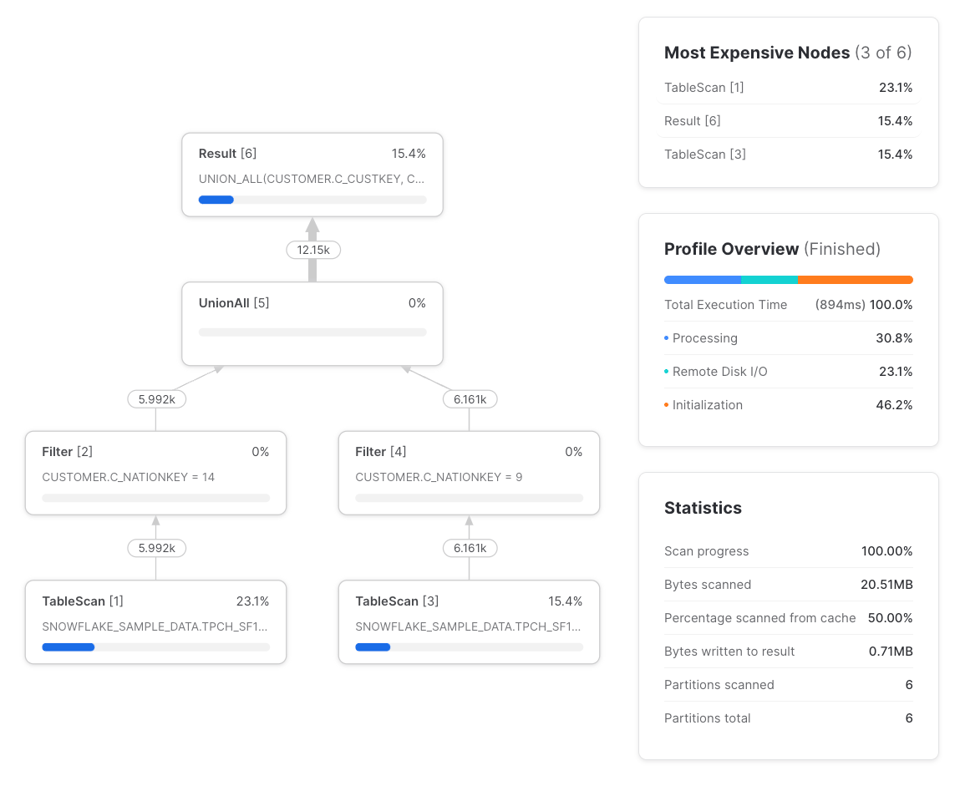
Las diferencias son:
- Dos
TableScanen lugar de uno. ElTableScande la izquierda hace la lectura desde el almacenamiento remoto y el de la derecha aprovecha el resultado en caché local del warehouse del primero. Aunque hay dosTableScan, solo uno hace lectura remota de datos. - Dos
Filteren lugar de tres. Cuando un filtro se aplica después de unTableScan, el propio nodoTableScanse encarga del filtrado, por eso los conteos de filas de entrada y salida del filtro son iguales. - Sin nodos
WithClauseniWithReference.
Ahora que entendemos cómo se traducen los CTEs a un plan de ejecución, veamos las implicaciones de rendimiento.
A veces es más rápido repetir la lógica que reutilizar un CTE
La mayoría de las veces, la estrategia de Snowflake de calcular el resultado de un CTE una sola vez y distribuirlo hacia abajo es la más eficiente. Pero en algunos casos, el costo de almacenar en buffer y distribuir el resultado del CTE a los nodos siguientes supera al de recalcularlo, sobre todo porque los nodos TableScan ya usan resultados en caché.
Acá va un ejemplo construido a propósito, que referencia el CTE lineitems tres veces:
with lineitems as (
select *
from snowflake_sample_data.tpch_sf100.lineitem
where l_receiptdate > '1998-01-01'
),
lineitem_future_sales as (
select
a.l_orderkey,
a.l_linenumber,
sum(b.l_quantity) as future_part_order_total
from lineitems as a
left join lineitems as b
on a.l_partkey = b.l_partkey
and b.l_receiptdate > a.l_receiptdate
Expandir código
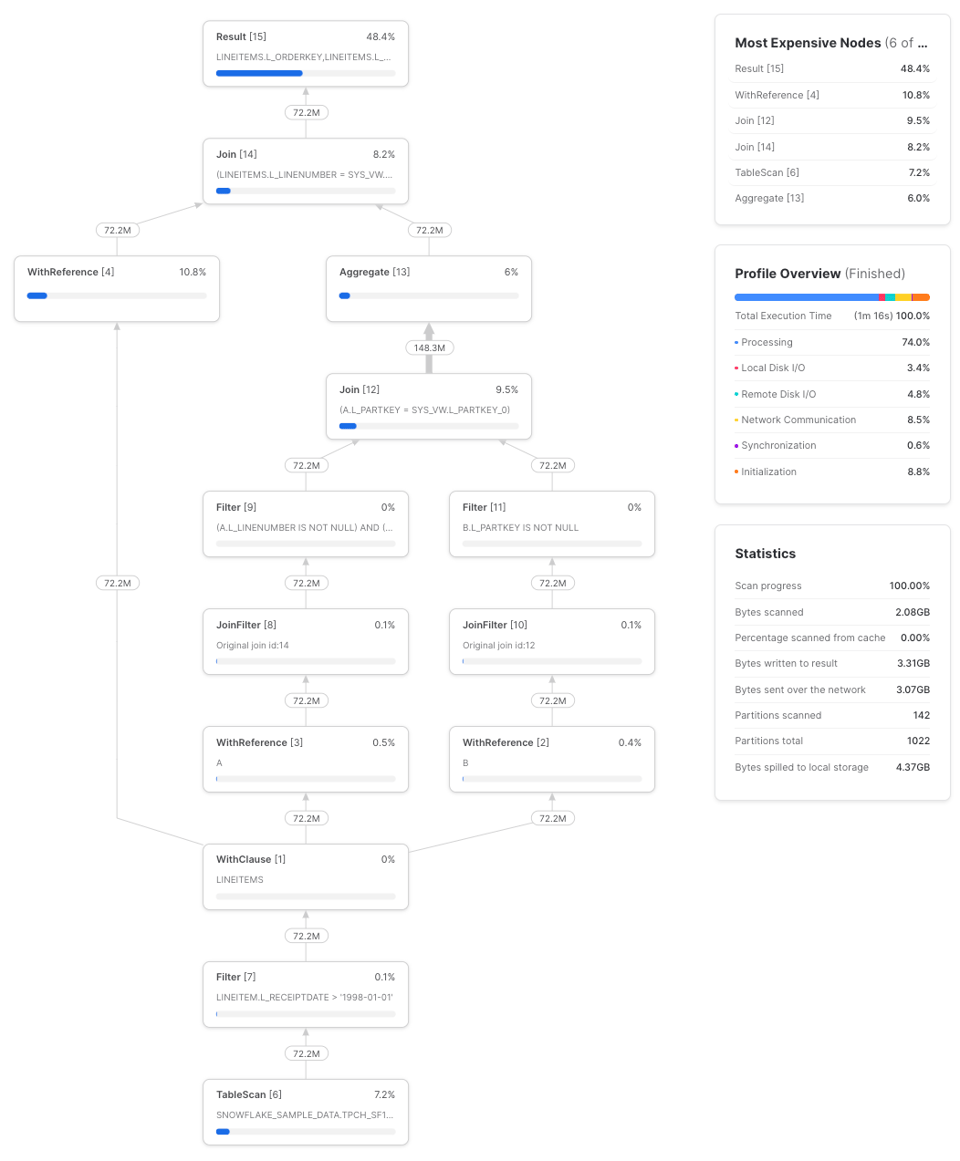
En tres ejecuciones, esta consulta tardó en promedio 1m 17s en completarse en un warehouse small. Este es un profile de ejemplo:
Si en cambio reescribimos la consulta repitiendo el CTE lineitems como subconsulta:
with lineitem_future_sales as (
select
a.l_orderkey,
a.l_linenumber,
sum(b.l_quantity) as future_part_order_total
from (
select *
from snowflake_sample_data.tpch_sf100.lineitem
where l_receiptdate > '1998-01-01'
) as a
left join (select *
from snowflake_sample_data.tpch_sf100.lineitem
where l_receiptdate > '1998-01-01'
) as b
on a.l_partkey = b.l_partkey
Expandir código
La consulta tarda en promedio 1m 7s en tres ejecuciones, una mejora de velocidad cercana al 10%. Query profile:
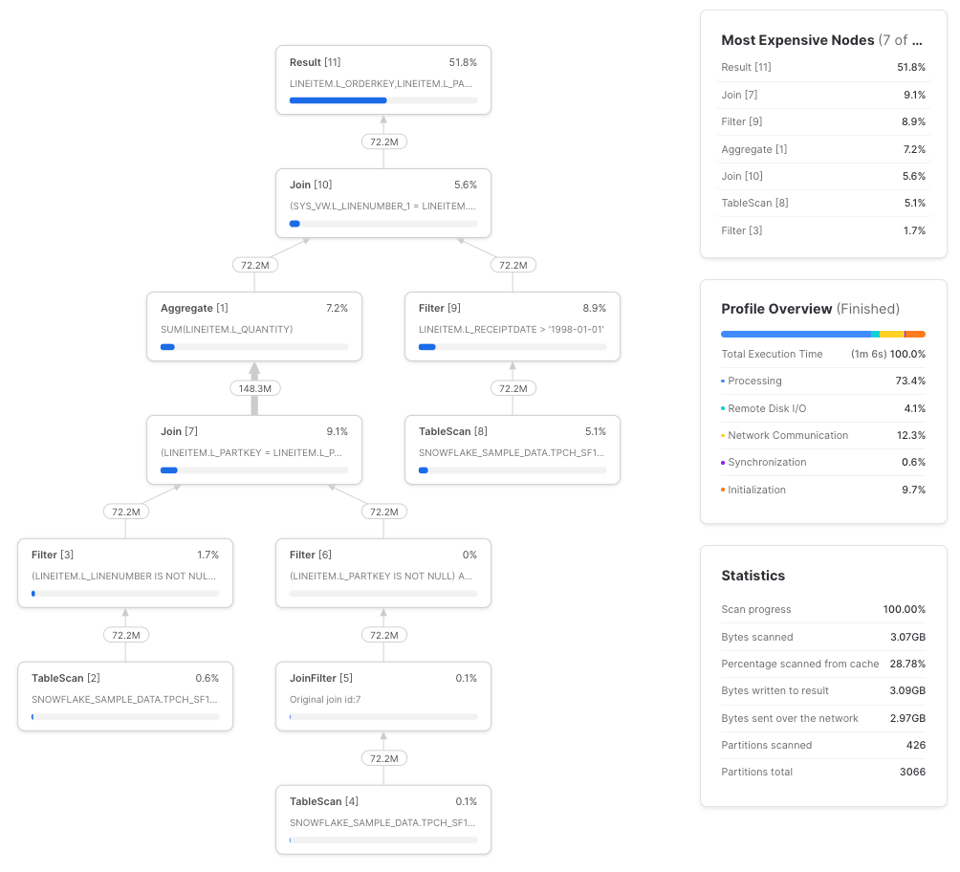
lineitems es un CTE simple. Cuando un CTE alcanza cierto nivel de complejidad, sale más barato calcularlo una sola vez y pasar los resultados a las referencias posteriores que recalcularlo varias veces. Pero este comportamiento no es consistente (como vimos con el ejemplo básico en ¿Son los CTEs pass-throughs?), así que lo mejor es experimentar. Acá va una forma de visualizar la relación:
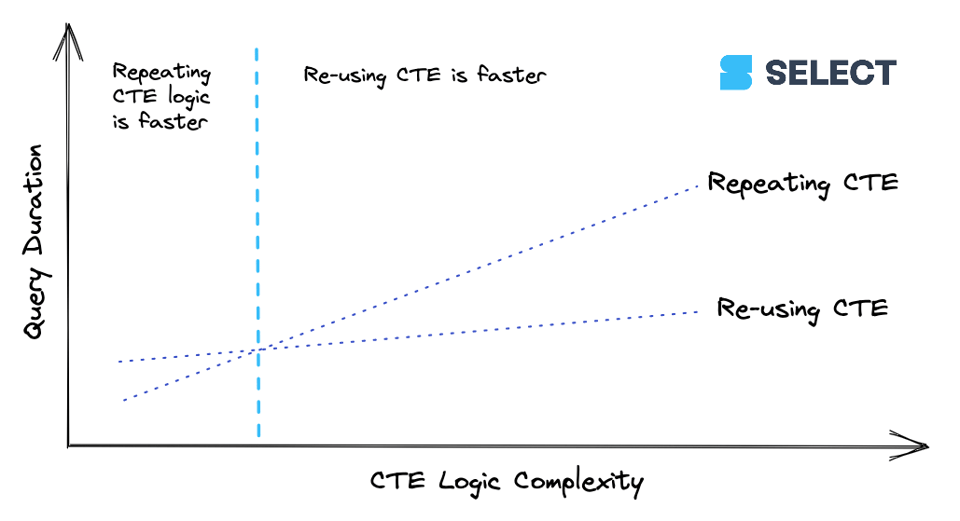
Recomendación
Los CTEs se pueden usar con confianza en Snowflake y un CTE que se referencia una sola vez nunca impactará el rendimiento. Salvo en casos muy específicos como el anterior, calcular el CTE una sola vez y reutilizarlo da el mejor rendimiento, frente a repetir su lógica. En la sección anterior vimos que Snowflake hace push down de los filtros dentro de los CTEs de forma inteligente para evitar escaneos completos innecesarios.
Ahora bien, si estás optimizando una consulta concreta en la que el rendimiento y la eficiencia de costo son críticos y vale la pena invertir tiempo, prueba a repetir la lógica del CTE. Esa lógica puede repetirse en varias subconsultas o se puede definir en una vista y referenciarla varias veces, igual que se hacía con el CTE.
En algunos escenarios, los CTEs impiden el column pruning
En posts anteriores cubrimos el diseño único de las micro-particiones de Snowflake y cómo permiten una potente optimización llamada pruning de micro-particiones. Gracias a su formato de almacenamiento columnar, también permiten el column pruning. Esto es importante porque significa que solo se recuperan por la red las columnas seleccionadas en la consulta.
El column pruning siempre funciona cuando un CTE se referencia una sola vez (cuando los CTEs se referencian una sola vez, se tratan como si no existieran). En un caso simple:
with sample_data as (
select *
from snowflake_sample_data.tpch_sf1.customer
)
select c_name, c_address
from sample_data
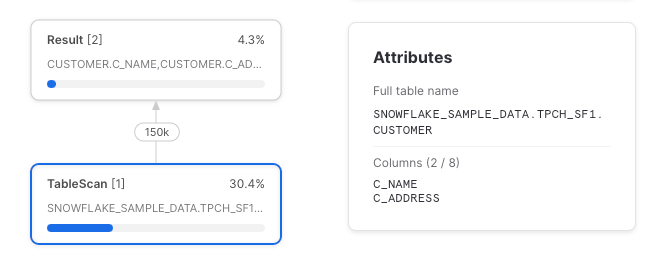
Podemos ver que solo se leyeron de la tabla subyacente las dos columnas seleccionadas. Pero como ya sabemos, un CTE que se referencia una sola vez es pass-through y se compila en un plan de consulta que ignora su existencia.
El column pruning deja de funcionar cuando un CTE se referencia más de una vez
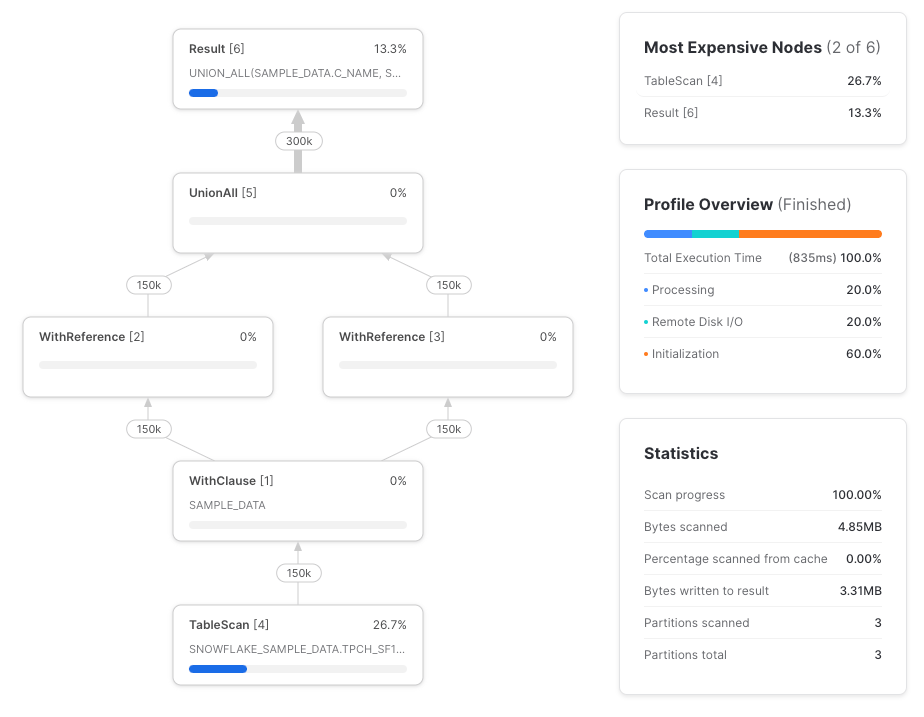
Esta vez, referenciemos el CTE dos veces, seleccionando una sola columna en cada referencia.
with sample_data as (
select *
from snowflake_sample_data.tpch_sf1.customer
),
customer_names as (
select c_name
from sample_data
),
customer_addresses as (
select c_address
from sample_data
)
Expandir código
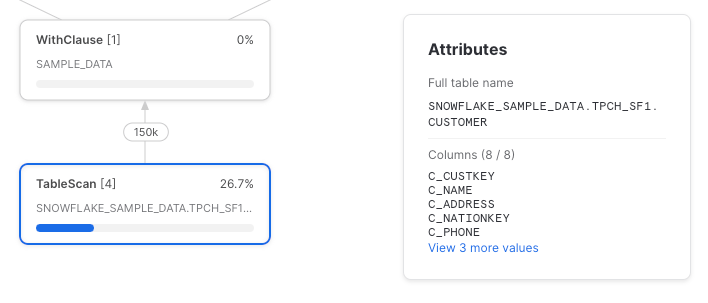
Lamentablemente, Snowflake no hizo push down de las referencias a las columnas hasta el table scan subyacente. Este es el query profile completo:
Probemos de nuevo, esta vez con referencias directas a la tabla.
with customer_names as (
select c_name
from snowflake_sample_data.tpch_sf1.customer
),
customer_addresses as (
select c_address
from snowflake_sample_data.tpch_sf1.customer
)
select c_name
from customer_names
union all
select c_address
from customer_addresses
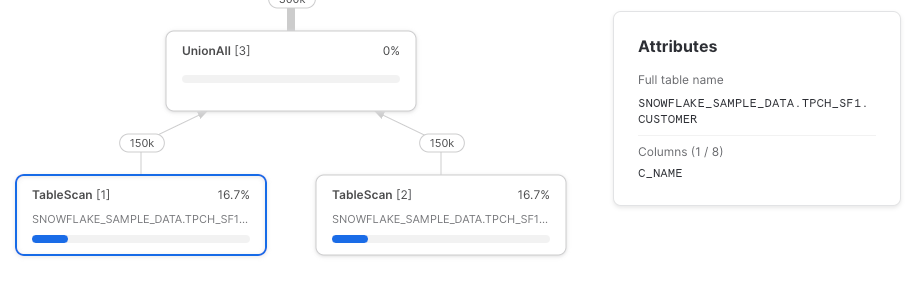
Como era de esperar, tenemos dos nodos TableScan y cada uno recupera solo las columnas referenciadas.
El column pruning falla con wildcards y joins
Otro escenario donde Snowflake puede no hacer push down del column pruning es con los joins (gracias a Paul Vernon por detectarlo). El TableScan de la tabla nation idealmente solo debería recuperar las columnas n_nationkey y n_name, pero las recupera todas.
with nations as (
select *
from snowflake_sample_data.tpch_sf1.nation
),
joined as (
select *
from snowflake_sample_data.tpch_sf1.customer
left join nations
on customer.c_nationkey = nations.n_nationkey
)
select c_address, n_name from joined
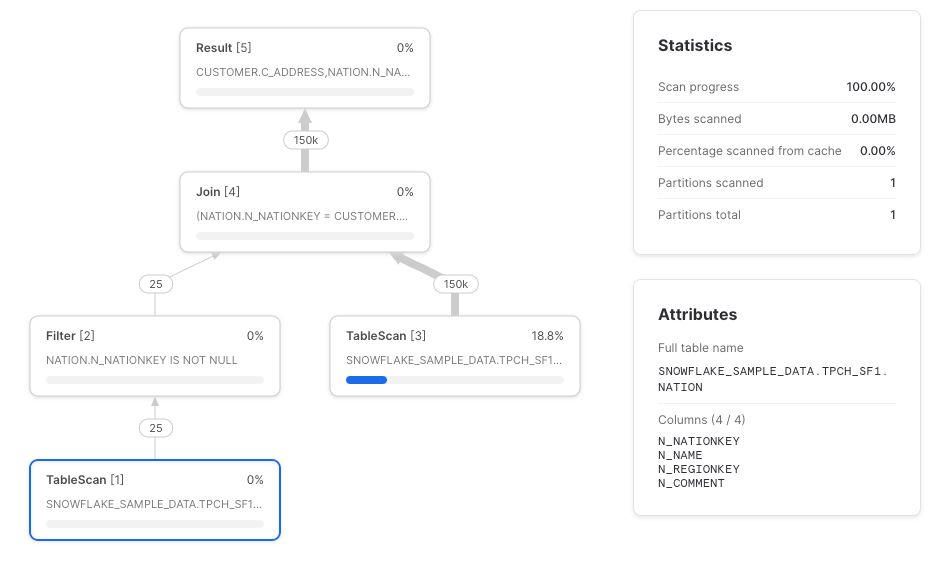
Recomendación
Recomendamos listar de forma explícita las referencias a columnas cuando se usan CTEs, para asegurar que los TableScan recuperen solo las columnas necesarias. Eso sí, si una consulta se ejecuta lo bastante rápido, puede que el costo de mantenimiento de listar las columnas explícitamente no compense.
Por la misma razón, desaconsejamos los CTEs del tipo select * from table que se usan en la guía de estilo de dbt. En su lugar, referencia la tabla directamente para garantizar el column pruning.
Entonces, ¿deberías usar CTEs en Snowflake?
En casi todos los casos, sí. Si tu consulta se ejecuta lo bastante rápido y no hay preocupaciones de costo, adelante. Es importante no optimizar de más, porque el tiempo y el costo de oportunidad de hacerlo pueden superar los beneficios.
Si estás optimizando una consulta concreta que usa CTEs, revisa lo siguiente:
- ¿Hay un CTE simple que se referencia más de una vez? Si un CTE no hace gran cosa, el overhead de los nodos
WithClauseyWithReferencepuede superar el costo de repetir el cálculo del CTE con subconsultas o una vista. - ¿Las referencias a columnas se están pasando hacia abajo y podando como se espera en los nodos
TableScan? Si no, intenta listar las columnas necesarias lo antes posible en la consulta. Esto puede mejorar bastante la velocidad del nodoTableScanen tablas anchas.
Identificar y aplicar oportunidades de optimización lleva tiempo. SELECT lo hace fácil y muestra automáticamente optimizaciones como las de este post. Obtén ahorros automáticos desde el día 1, identifica rápidamente los focos de costo y optimiza tus workloads en Snowflake. Accede hoy o agenda una demo con los enlaces de abajo.
Niall Woodward·Co-founder y CTO de SELECT
Niall es Co-Founder y CTO de SELECT, una plataforma SaaS de gestión y optimización de costos para Snowflake. Antes de fundar SELECT, Niall fue data engineer en Brooklyn Data Company y en varias startups. Como entusiasta del open source, también es mantenedor de SQLFluff y creador de tres paquetes de dbt: dbt_artifacts, dbt_snowflake_monitoring y dbt_query_tags.