CTEはSQLロジックをモジュール化し、再利用するうえで非常に強力なツールです。一方で、想定外の非効率なクエリ実行を引き起こすことがあるため、最適化の議論で頻繁に取り上げられるテーマでもあります。本記事では、CTEがクエリプランに与える影響を掘り下げ、安心して使えるケースと避けた方がよいケースを整理します。
はじめに
ここ数年、CTEがパフォーマンスに与える影響については多くの記事が書かれてきました。
- CTEs are pass-throughs - Tristan Handy - 2018-11-07
- Snowflake query optimizer: unoptimized - Dominik Golebiewski - 2021-10-13
- CTE Considerations - bennieregenold7 - 2022-07-22
- A recent dbt Slack thread - 2023-02-22
それでも議論が絶えないのは、まだ結論が出ていないことの裏返しでもあります。本記事では、CTEを使うべきタイミング、避けた方がよいタイミングについて、根拠に基づいたガイドラインを示すことを目指します。Snowflakeのクエリオプティマイザは継続的に改善されており、上記の記事と同様、ここで観測される挙動も時間とともに変わっていく可能性があります。
本記事ではクエリプロファイルを使って、クエリの書き方が実行にどう影響するかを見ていきます。クエリプロファイルが初めての方や復習したい方は、Snowflakeのクエリプロファイルの使い方もあわせてご覧ください。
まずはCTEとは何か、そしてなぜ広く使われているのかをおさらいしましょう。
CTEとは?
CTE(Common Table Expression/共通テーブル式)とは、名前の付いたサブクエリのことです。with句で宣言し、その名前で参照できます。
with my_cte as (
select 1
)
select * from my_cte
CTEはカンマ区切りで複数定義できます。
with my_cte as (
select 1
),
my_cte_2 as (
select 2
)
select *
from my_cte
left join my_cte_2
必要であればCTEを入れ子にすることもできます(ただし可読性は下がります)。
with my_cte as (
with my_inner_cte as (
select 1
)
select * from my_inner_cte
)
select *
from my_cte
なぜCTEを使うのか?
CTEを使う主な理由は次のとおりです。
- SQLロジックを独立したサブクエリに切り出せます。
select * from cteでCTE単体を実行できるため、デバッグもしやすくなります。 - 上から下へと流れる手続き型に近いスタイルでSQLを書けるため、コードレビューや保守がしやすくなります。
- DRY(Don't Repeat Yourself)原則を守りやすく、複数箇所から参照されるロジックを一箇所にまとめられます。
Snowflakeはクエリプラン内でCTEをどう扱うのか
CTEがパフォーマンスに与える影響を理解するには、まずSnowflakeがクエリ実行時にCTE宣言をどう扱うかを押さえる必要があります。
CTEはパススルーなのか?
CTEが1回しか参照されない場合は、その通りパススルーです。ここでいうパススルーとは、CTEを使っても使わなくてもクエリの処理が同じになることを指します。1回しか参照されないCTEは常にパススルーとして扱われ、クエリプロファイルにはその痕跡が一切残りません。したがって、1回だけ参照するCTEを使ってもパフォーマンスに影響することはありません。
with sample_data as (
select *
from snowflake_sample_data.tpch_sf1.customer
)
select *
from sample_data
where c_nationkey = 14
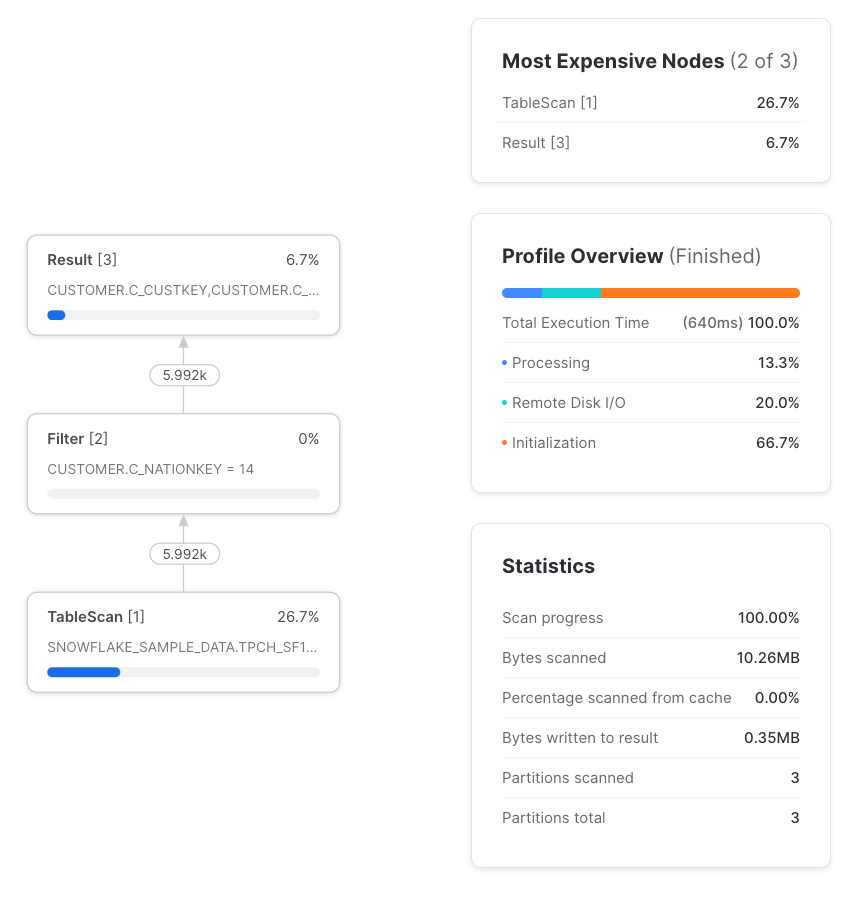
一方、同じCTEを複数回参照すると様子が変わり、テーブルを直接参照した場合とは実行プランが異なってきます。
with sample_data as (
select *
from snowflake_sample_data.tpch_sf1.customer
),
nation_14_customers as (
select *
from sample_data
where c_nationkey = 14
),
nation_9_customers as (
select *
from sample_data
where c_nationkey = 9
Expand Code
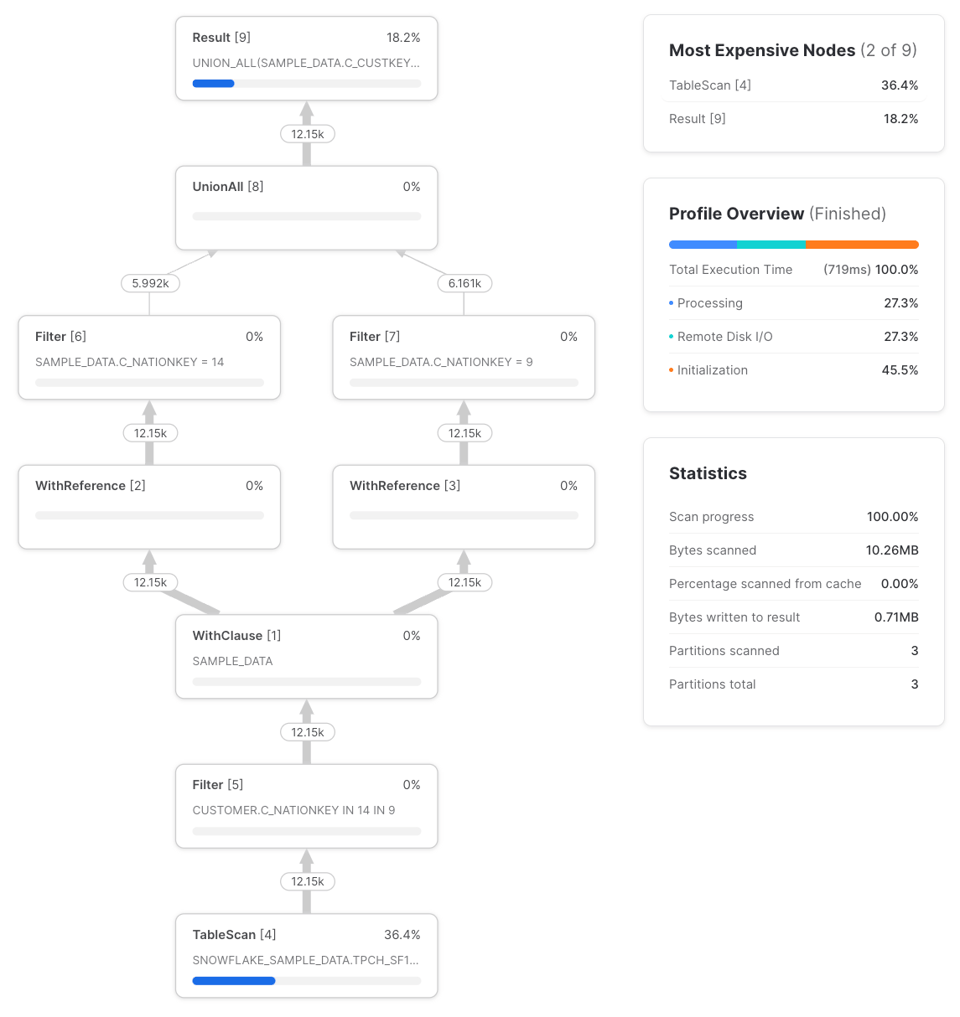
ここではWithClauseとWithReferenceという2種類のノードが新たに登場します。WithClauseは定義したsample_data CTEの出力ストリームとバッファを表し、各WithReferenceノードがその出力を消費します。注目したいのは、Snowflakeがnation_14_customersとnation_9_customersのフィルタを、WithClauseの前段にあるTableScanまで賢くプッシュダウンしている点です。Dominik氏の記事でも触れられていたように、以前のSnowflakeはこの最適化を行っていませんでした。より複雑なクエリでも同じ挙動になるかは別途検証が必要ですが、このクエリでは次のように書いた場合と同じプロファイルになります。
with sample_data as (
select *
from snowflake_sample_data.tpch_sf1.customer
where c_nationkey in (14, 9)
),
nation_14_customers as (
select *
from sample_data
where c_nationkey = 14
),
nation_9_customers as (
select *
from sample_data
Expand Code
続いてsample_data CTEの参照をsnowflake_sample_data.tpch_sf1.customerテーブルへの直接参照に置き換え、実行プランの違いを確認します。
with nation_14_customers as (
select *
from snowflake_sample_data.tpch_sf1.customer
where c_nationkey = 14
),
nation_9_customers as (
select *
from snowflake_sample_data.tpch_sf1.customer
where c_nationkey = 9
)
select *
from nation_14_customers
union all
Expand Code
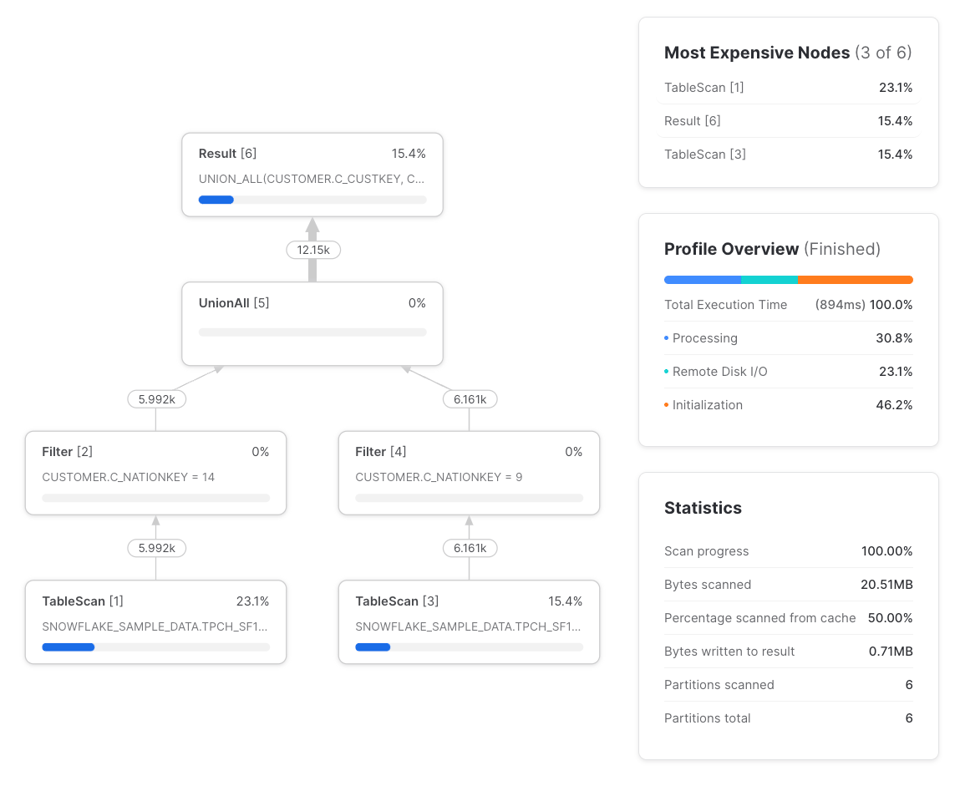
違いは次のとおりです。
TableScanが1つではなく2つになっています。左側のTableScanはリモートストレージから読み取り、右側のTableScanは左側のローカルウェアハウスにキャッシュされた結果を利用します。TableScanは2つありますが、リモートからデータを取得しているのは片方だけです。Filterは3つではなく2つです。なおTableScan直後のフィルタはTableScanノード自身が処理するため、フィルタの入力行数と出力行数が一致しています。WithClauseやWithReferenceノードは存在しません。
CTEがどのように実行プランへ変換されるかが分かったところで、次はパフォーマンスへの影響を見ていきましょう。
ロジックを繰り返した方がCTEの再利用より速い場合もある
多くの場合、CTEの結果を一度だけ計算して下流に配布するSnowflakeの戦略が最もパフォーマンスに優れています。ただし状況によっては、CTEの結果をバッファリングして下流ノードに配布するコストが、再計算するコストを上回ることがあります。TableScanノードはどのみちキャッシュ済みの結果を使うため、なおさらです。
以下はlineitems CTEを3回参照する、やや作為的な例です。
with lineitems as (
select *
from snowflake_sample_data.tpch_sf100.lineitem
where l_receiptdate > '1998-01-01'
),
lineitem_future_sales as (
select
a.l_orderkey,
a.l_linenumber,
sum(b.l_quantity) as future_part_order_total
from lineitems as a
left join lineitems as b
on a.l_partkey = b.l_partkey
and b.l_receiptdate > a.l_receiptdate
Expand Code
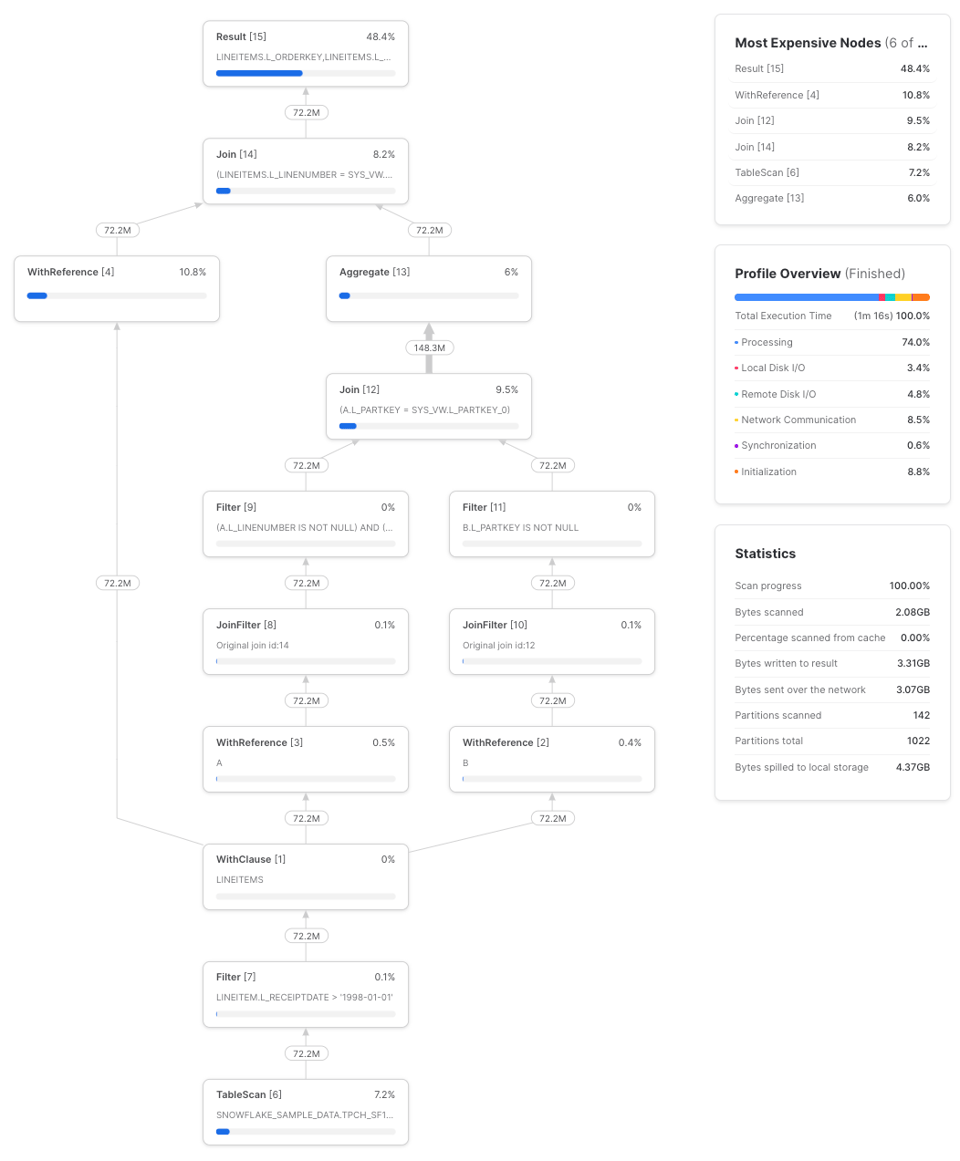
このクエリをsmallウェアハウスで3回実行した平均は1分17秒でした。プロファイルの例は次のとおりです。
これを、lineitems CTEをサブクエリとして繰り返す形に書き換えてみます。
with lineitem_future_sales as (
select
a.l_orderkey,
a.l_linenumber,
sum(b.l_quantity) as future_part_order_total
from (
select *
from snowflake_sample_data.tpch_sf100.lineitem
where l_receiptdate > '1998-01-01'
) as a
left join (select *
from snowflake_sample_data.tpch_sf100.lineitem
where l_receiptdate > '1998-01-01'
) as b
on a.l_partkey = b.l_partkey
Expand Code
この場合は3回実行の平均が1分7秒となり、約10%高速化しました。クエリプロファイルは次のとおりです。
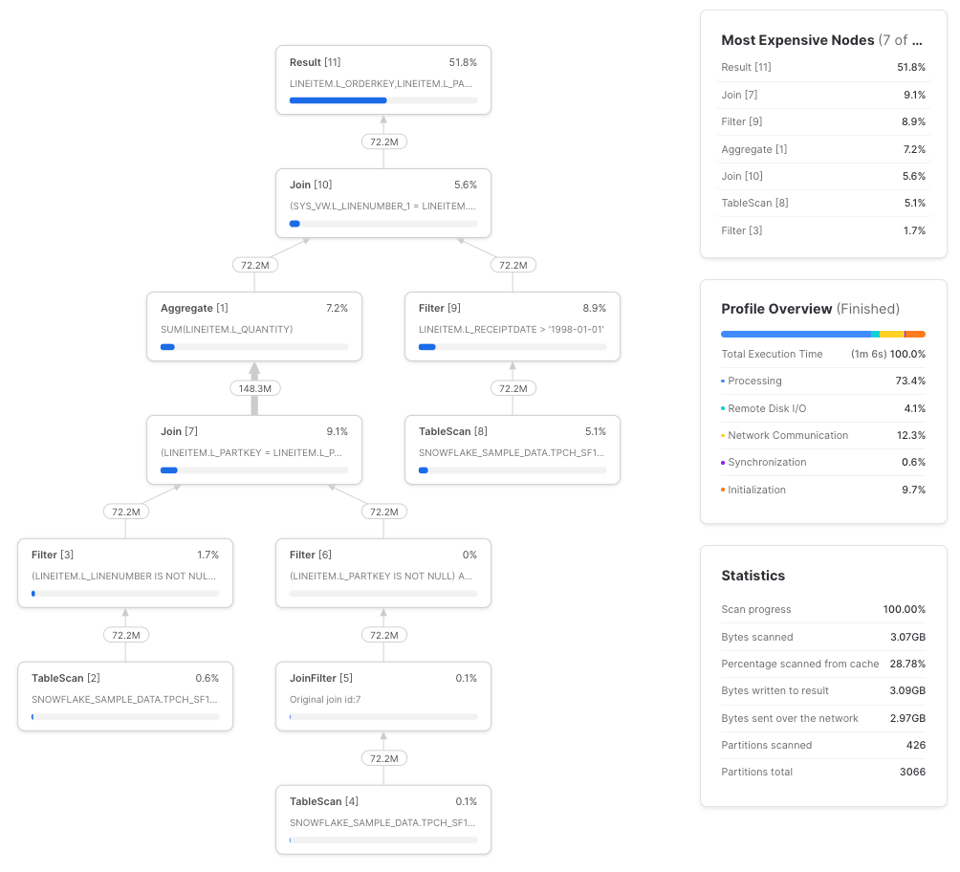
lineitemsはシンプルなCTEです。CTEが一定以上の複雑さに達すると、何度も再計算するよりも、一度計算して下流の参照に結果を渡す方がコスト面で有利になります。ただし、この挙動は一貫しているわけではなく(CTEはパススルーかの節で見た基本例のとおりです)、実際に試して比較するのが最善です。両者の関係を図にすると次のようになります。
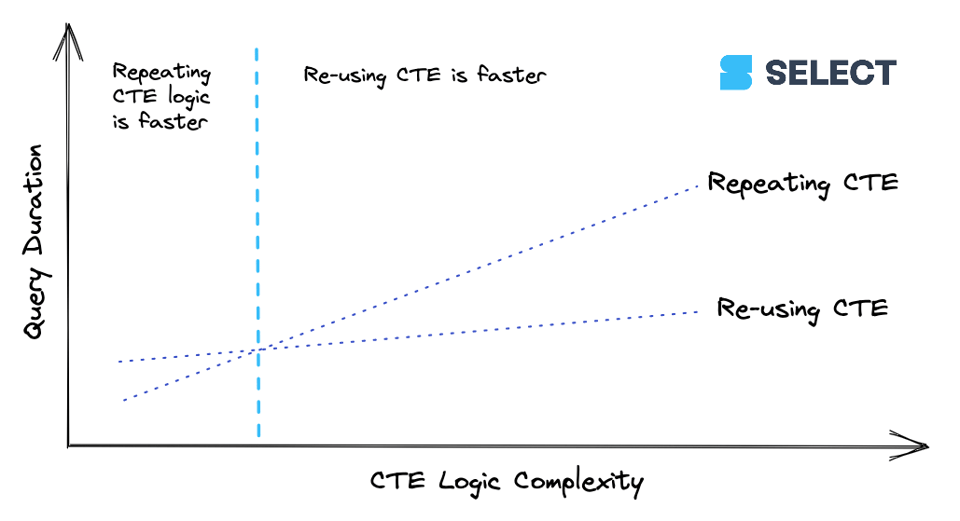
推奨事項
SnowflakeではCTEを安心して使えます。1回しか参照されないCTEはパフォーマンスにまったく影響しません。前述のようなごく特定のケースを除けば、CTEを一度計算して再利用する方が、ロジックを繰り返すよりも良いパフォーマンスを発揮します。前節で見たとおり、Snowflakeは不要なフルテーブルスキャンを避けるため、フィルタをCTE内へ賢くプッシュダウンしてくれます。
ただし、パフォーマンスとコスト効率を最優先する特定のクエリの最適化に取り組んでいて、そこに時間をかける価値がある場合は、CTEのロジックを繰り返す形を試してみてください。ロジックは複数のサブクエリに分けて繰り返す方法もあれば、ビューとして定義してCTEと同じように複数回参照する方法もあります。
CTEがカラムプルーニングを妨げるケース
過去の記事では、Snowflakeのマイクロパーティションの独自設計と、それを支えにした強力な最適化であるマイクロパーティションプルーニングについて解説しました。マイクロパーティションは列指向のストレージ形式を採用しているため、カラムプルーニングも実現できます。これにより、クエリで選択された列だけをネットワーク経由で取得すればよくなるという大きな利点があります。
CTEが1回だけ参照される場合、カラムプルーニングは常に機能します(1回しか参照されないCTEは存在しないかのように扱われるためです)。シンプルな例で確認してみましょう。
with sample_data as (
select *
from snowflake_sample_data.tpch_sf1.customer
)
select c_name, c_address
from sample_data
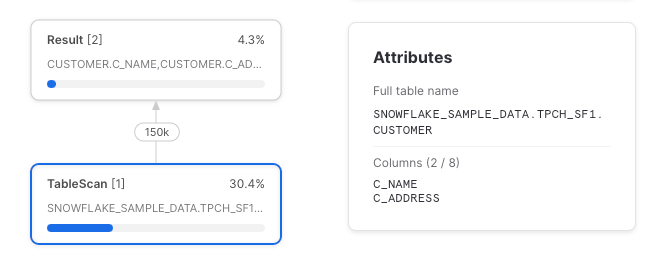
選択した2列だけが元のテーブルから読み込まれているのが分かります。前述のとおり、1回しか参照されないCTEはパススルー扱いとなり、その存在を意識しないクエリプランにコンパイルされるからです。
CTEを複数回参照するとカラムプルーニングが効かなくなる
今度は同じCTEを2回参照し、それぞれの参照で1列ずつ選択してみます。
with sample_data as (
select *
from snowflake_sample_data.tpch_sf1.customer
),
customer_names as (
select c_name
from sample_data
),
customer_addresses as (
select c_address
from sample_data
)
Expand Code
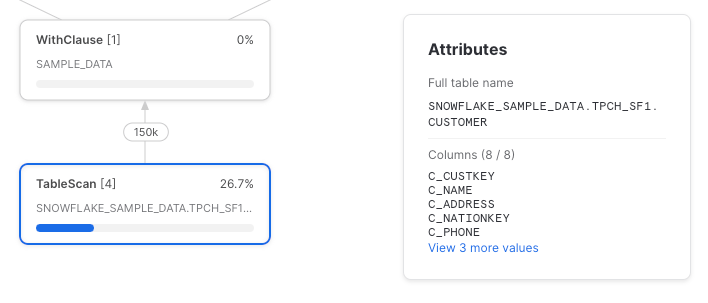
残念ながら、Snowflakeは列参照を元のテーブルスキャンまでプッシュダウンしてくれません。完全なクエリプロファイルは次のとおりです。
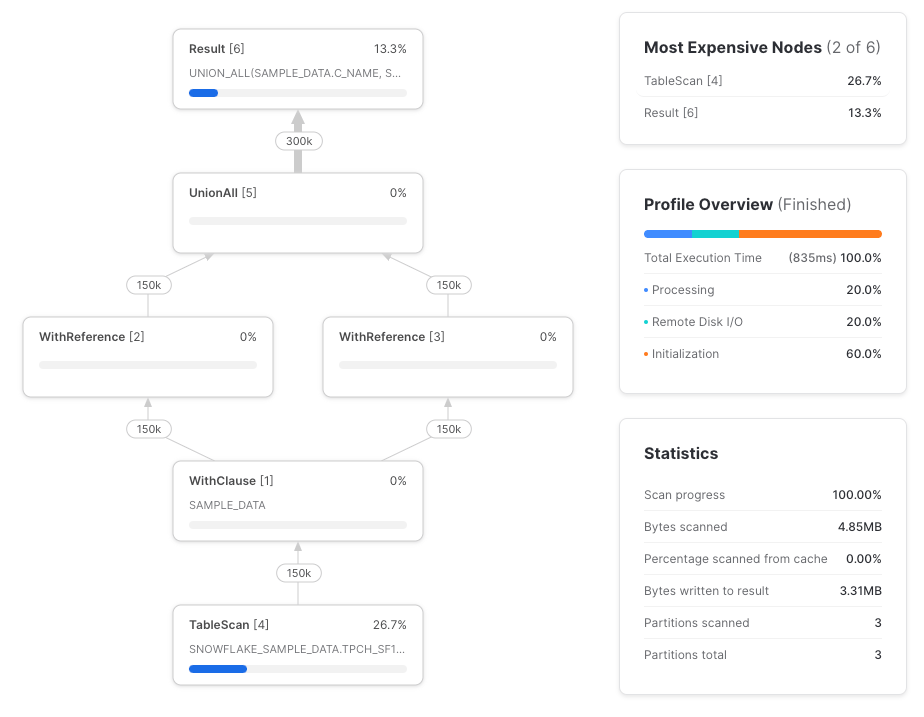
同じクエリを、今度はテーブルを直接参照する形で書いてみます。
with customer_names as (
select c_name
from snowflake_sample_data.tpch_sf1.customer
),
customer_addresses as (
select c_address
from snowflake_sample_data.tpch_sf1.customer
)
select c_name
from customer_names
union all
select c_address
from customer_addresses
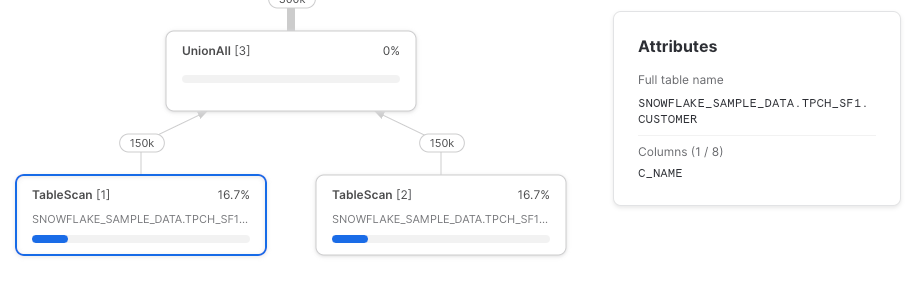
想定どおり、TableScanノードが2つあり、それぞれ参照された列だけを取得しています。
ワイルドカードとJOINでもカラムプルーニングが崩れる
Snowflakeがカラムプルーニングのプッシュダウンを行ってくれないもう一つのケースがJOINです(この点を指摘してくれたPaul Vernon氏に感謝)。nationテーブルのTableScanは本来n_nationkeyとn_nameだけを取得すべきですが、実際には全列を取得しています。
with nations as (
select *
from snowflake_sample_data.tpch_sf1.nation
),
joined as (
select *
from snowflake_sample_data.tpch_sf1.customer
left join nations
on customer.c_nationkey = nations.n_nationkey
)
select c_address, n_name from joined
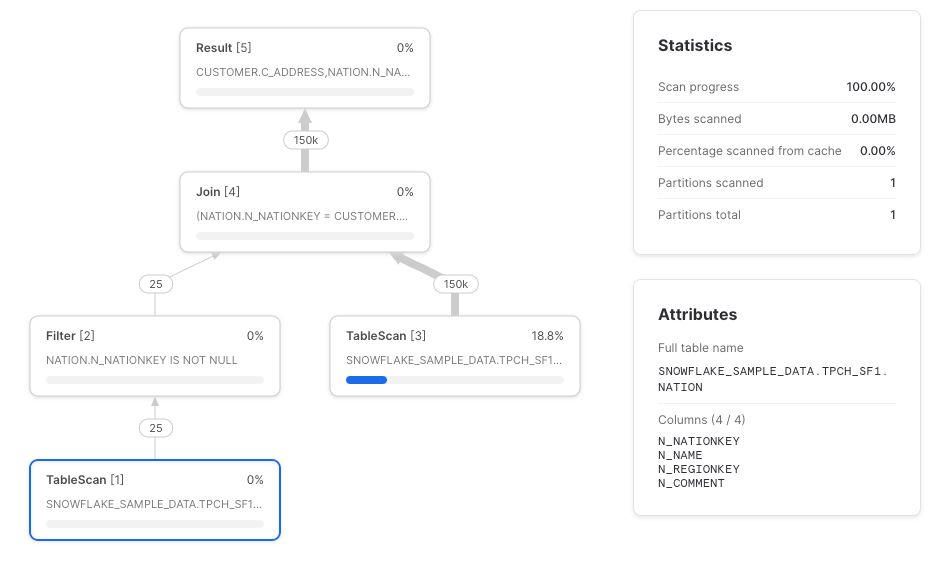
推奨事項
CTEを使うときは、列参照を明示的に列挙し、TableScanが必要な列だけを取得するようにすることをおすすめします。ただし、クエリが十分速く動いているなら、列を明示的に書き出す保守コストに見合わない場合もあります。
同じ理由から、dbtのスタイルガイドに登場するselect * from table形式のCTEはおすすめしません。必要なテーブルを直接参照して、カラムプルーニングが確実に効くようにしましょう。
結局、SnowflakeでCTEは使うべきか?
ほぼすべてのケースで答えはイエスです。クエリが十分速く動き、コスト面でも問題がなければ、そのまま使って構いません。最適化は必要なときだけ行うのが鉄則で、そこにかける時間や機会コストがメリットを上回ってしまうこともあります。
とはいえ、CTEを使う特定のクエリを最適化したい場合は、次の点を確認してみてください。
- シンプルなCTEを複数回参照していないか? CTEの処理内容が軽い場合、
WithClauseとWithReferenceノードのオーバーヘッドの方が、サブクエリやビューで同じ計算を繰り返すコストを上回ることがあります。 TableScanノードで、列参照が想定どおりにプッシュダウン・プルーニングされているか? 効いていない場合は、必要な列をクエリのできるだけ早い段階で明示的に書き出してみてください。列数の多いテーブルでは、TableScanノードの速度が大きく改善することがあります。
最適化の余地を見つけて実際に手を打つのは、手間のかかる作業です。SELECTを使えば、本記事で紹介したような最適化ポイントを自動で洗い出してくれます。初日からコスト削減を自動化し、コストセンターを素早く特定して、Snowflakeのworkloadsを最適化しましょう。下のリンクから今すぐご利用いただくか、デモをご予約ください。
Niall Woodward・Co-founder & CTO of SELECT
NiallはSaaS型のSnowflakeコスト管理・最適化プラットフォームSELECTの共同創業者兼CTOです。SELECTを立ち上げる以前は、Brooklyn Data Companyや複数のスタートアップでデータエンジニアとして活躍。オープンソースにも情熱を注いでおり、SQLFluffのメンテナーを務めるほか、3つのdbtパッケージ(dbt_artifacts、dbt_snowflake_monitoring、dbt_query_tags)の作者でもあります。