As CTEs são uma ferramenta extremamente valiosa para modularizar e reaproveitar lógica SQL. Também aparecem com frequência em discussões sobre otimização, já que seu uso costuma ser associado a execuções de consulta inesperadas e, às vezes, ineficientes. Neste post, vamos analisar o impacto das CTEs nos planos de consulta, entender quando dá para usá-las sem preocupação e quando talvez seja melhor evitá-las.
Introdução
Muita coisa já se escreveu sobre o impacto das CTEs na performance nos últimos anos:
- CTEs are pass-throughs - Tristan Handy - 07/11/2018
- Snowflake query optimizer: unoptimized - Dominik Golebiewski - 13/10/2021
- CTE Considerations - bennieregenold7 - 22/07/2022
- Uma thread recente no Slack do dbt - 22/02/2023
Mas o fato de o assunto ainda render tanta discussão mostra que a gente não chegou a uma conclusão. Este post traz um conjunto de diretrizes fundamentadas sobre quando usar CTEs e quando talvez seja melhor evitá-las. O otimizador de consultas do Snowflake está em constante evolução e, assim como nos posts citados acima, o comportamento descrito aqui vai mudar com o tempo.
Vamos usar query profiles para entender como diferentes estruturas de consulta afetam a execução. Se query profiles são novidade para você ou se quiser uma revisão, confira nosso post sobre como usar o query profile do Snowflake.
Vamos começar relembrando o que são CTEs e por que elas são tão populares.
O que são CTEs?
Uma CTE, ou common table expression, é uma subconsulta com um nome associado. Ela é declarada com uma cláusula with e, depois disso, pode ser consultada pelo identificador de nome:
with my_cte as (
select 1
)
select * from my_cte
As CTEs são separadas por vírgula, ou seja, dá para definir várias usando vírgulas entre elas:
with my_cte as (
select 1
),
my_cte_2 as (
select 2
)
select *
from my_cte
left join my_cte_2
Também é possível colocar CTEs dentro de CTEs, se quiser (embora a leitura fique meio complicada!):
with my_cte as (
with my_inner_cte as (
select 1
)
select * from my_inner_cte
)
select *
from my_cte
Por que usar CTEs?
Os principais motivos para usar CTEs são:
- As CTEs ajudam a dividir a lógica SQL em subconsultas isoladas. Isso facilita o debug, já que basta rodar
select * from ctepara executar uma CTE separadamente. - As CTEs permitem escrever SQL em um estilo procedural, de cima para baixo, o que ajuda na revisão de código e na manutenção.
- As CTEs ajudam a seguir o princípio DRY (don't repeat yourself), oferecendo um único lugar para definir uma lógica que será referenciada várias vezes adiante.
Como o Snowflake trata as CTEs no plano de consulta?
Para entender as implicações de performance das CTEs, primeiro precisamos entender como o Snowflake lida com declarações de CTE na execução de uma consulta.
As CTEs são pass-throughs?
São, desde que a CTE seja referenciada apenas uma vez. Por pass-through, queremos dizer que a consulta é processada da mesma forma, com ou sem a CTE. Quando uma CTE é referenciada uma única vez, ela é sempre um pass-through, e o query profile não mostra sinal nenhum dela. Ou seja, usar uma CTE referenciada uma única vez nunca vai impactar a performance em comparação a não usá-la.
with sample_data as (
select *
from snowflake_sample_data.tpch_sf1.customer
)
select *
from sample_data
where c_nationkey = 14
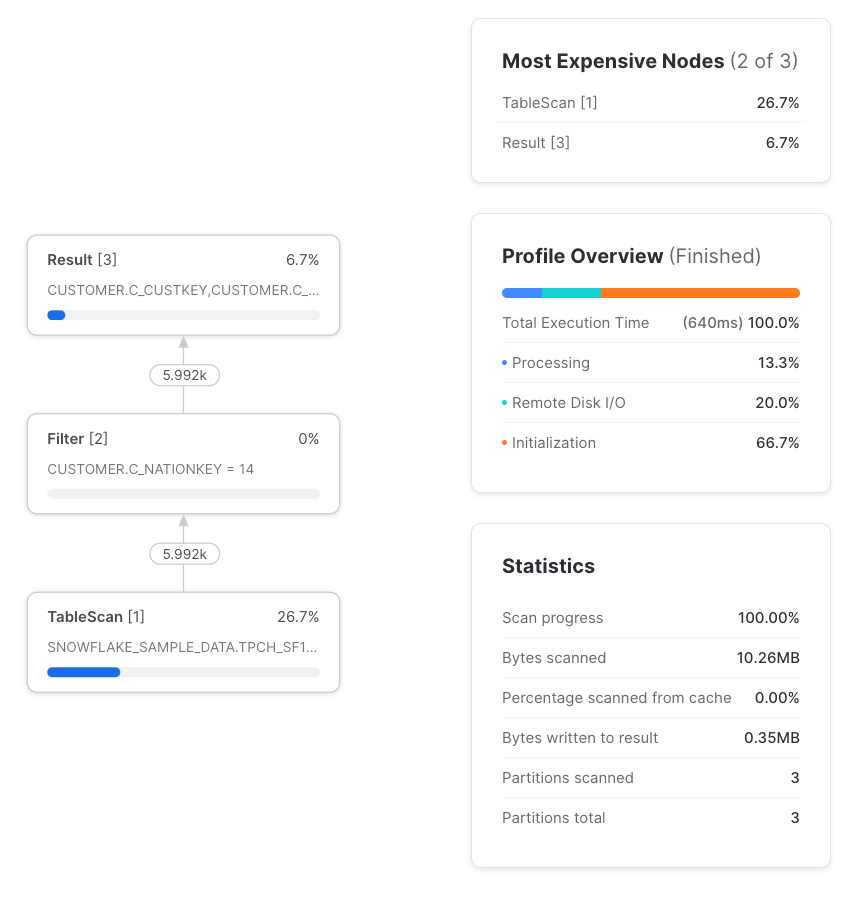
Mas, se referenciarmos essa CTE mais de uma vez, o cenário muda — e a execução da consulta passa a ser diferente do que seria caso a tabela fosse referenciada diretamente, sem CTE.
with sample_data as (
select *
from snowflake_sample_data.tpch_sf1.customer
),
nation_14_customers as (
select *
from sample_data
where c_nationkey = 14
),
nation_9_customers as (
select *
from sample_data
where c_nationkey = 9
Expandir código
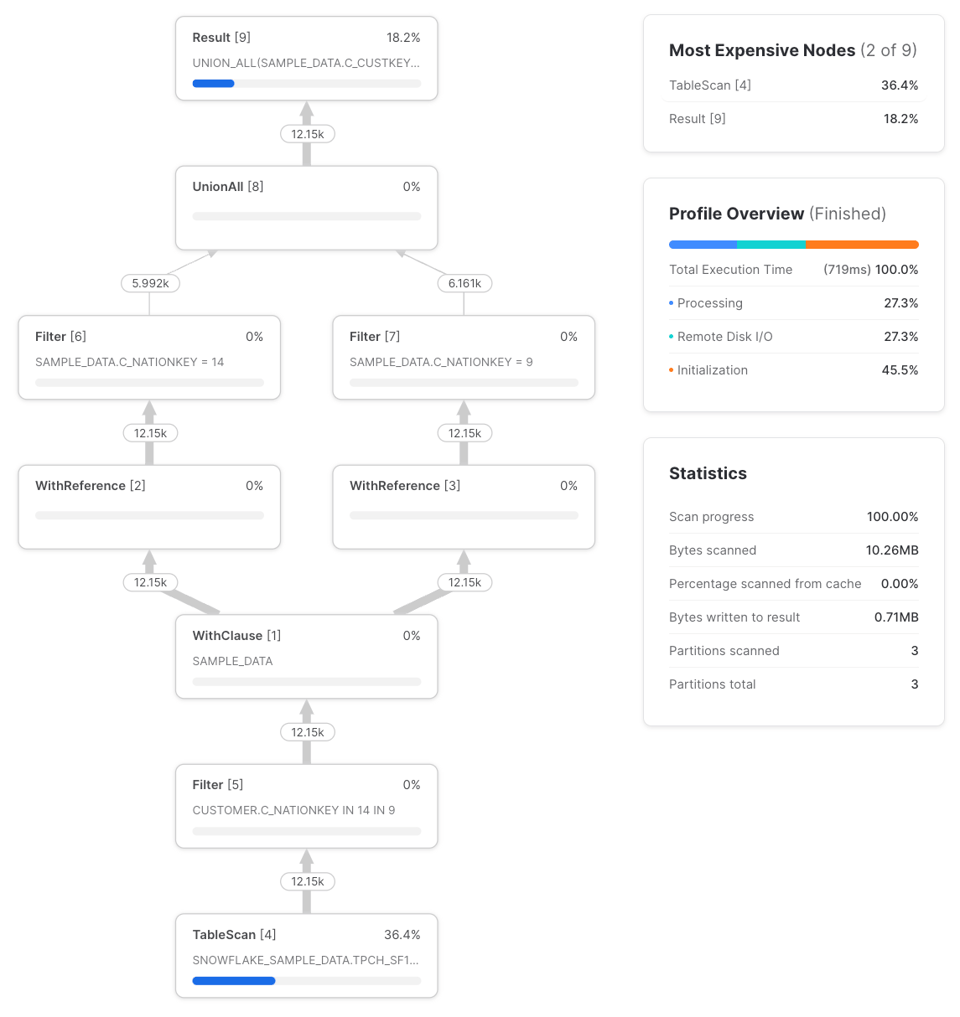
Aparecem dois novos tipos de nó: o WithClause e o WithReference. O WithClause representa um fluxo de saída e buffer da CTE sample_data que definimos, que depois é consumido por cada nó WithReference. Repare que o Snowflake faz, de forma inteligente, o push-down do filtro das CTEs nation_14_customers e nation_9_customers até o TableScan antes do WithClause. Antes, o Snowflake não fazia isso, como relatado no post do Dominik. Vale verificar se esse comportamento se mantém em consultas mais complexas, mas, para esta consulta, o profile é igual ao que teríamos se a escrevêssemos assim:
with sample_data as (
select *
from snowflake_sample_data.tpch_sf1.customer
where c_nationkey in (14, 9)
),
nation_14_customers as (
select *
from sample_data
where c_nationkey = 14
),
nation_9_customers as (
select *
from sample_data
Expandir código
Agora vamos trocar as referências à CTE sample_data por uma referência direta à tabela snowflake_sample_data.tpch_sf1.customer e ver as diferenças no plano de execução:
with nation_14_customers as (
select *
from snowflake_sample_data.tpch_sf1.customer
where c_nationkey = 14
),
nation_9_customers as (
select *
from snowflake_sample_data.tpch_sf1.customer
where c_nationkey = 9
)
select *
from nation_14_customers
union all
Expandir código
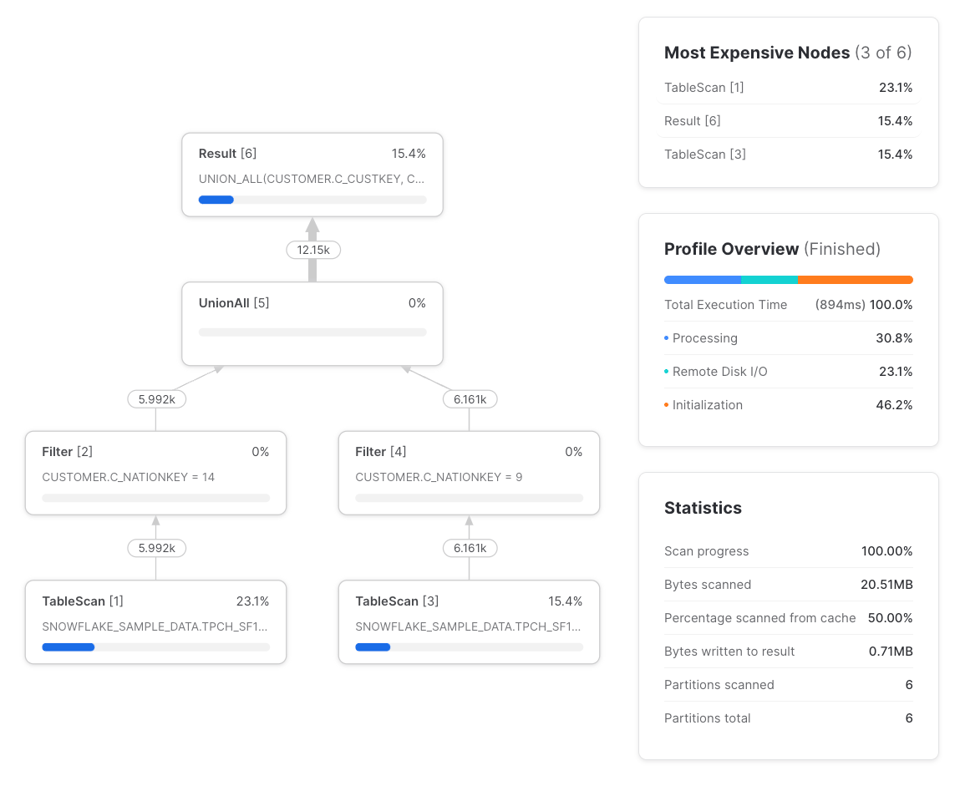
As diferenças são:
- Dois
TableScans em vez de um. OTableScanda esquerda faz a leitura do storage remoto, e o da direita aproveita o resultado em cache do warehouse local gerado pelo primeiro. Apesar de existirem doisTableScans, só um deles faz busca remota de dados. - Dois
Filters em vez de três. Quando um filtro é aplicado logo depois de umTableScan, o próprio nóTableScancuida da filtragem — por isso a contagem de linhas de entrada e saída do filtro é a mesma. - Nenhum nó
WithClauseouWithReference.
Agora que entendemos como as CTEs viram um plano de execução, vamos explorar as implicações para a performance.
Às vezes, repetir a lógica é mais rápido do que reaproveitar uma CTE
Na maioria das vezes, a estratégia do Snowflake de calcular o resultado de uma CTE uma vez e distribuir os resultados adiante é a mais performática. Mas, em alguns casos, o custo de fazer o buffer e distribuir o resultado da CTE para os nós seguintes acaba sendo maior do que o de recalculá-la, ainda mais porque os nós TableScan já usam resultados em cache.
Veja um exemplo hipotético, que referencia a CTE lineitems três vezes:
with lineitems as (
select *
from snowflake_sample_data.tpch_sf100.lineitem
where l_receiptdate > '1998-01-01'
),
lineitem_future_sales as (
select
a.l_orderkey,
a.l_linenumber,
sum(b.l_quantity) as future_part_order_total
from lineitems as a
left join lineitems as b
on a.l_partkey = b.l_partkey
and b.l_receiptdate > a.l_receiptdate
Expandir código
Em três execuções, essa consulta levou em média 1m 17s para terminar em um warehouse small. Veja um exemplo de profile:
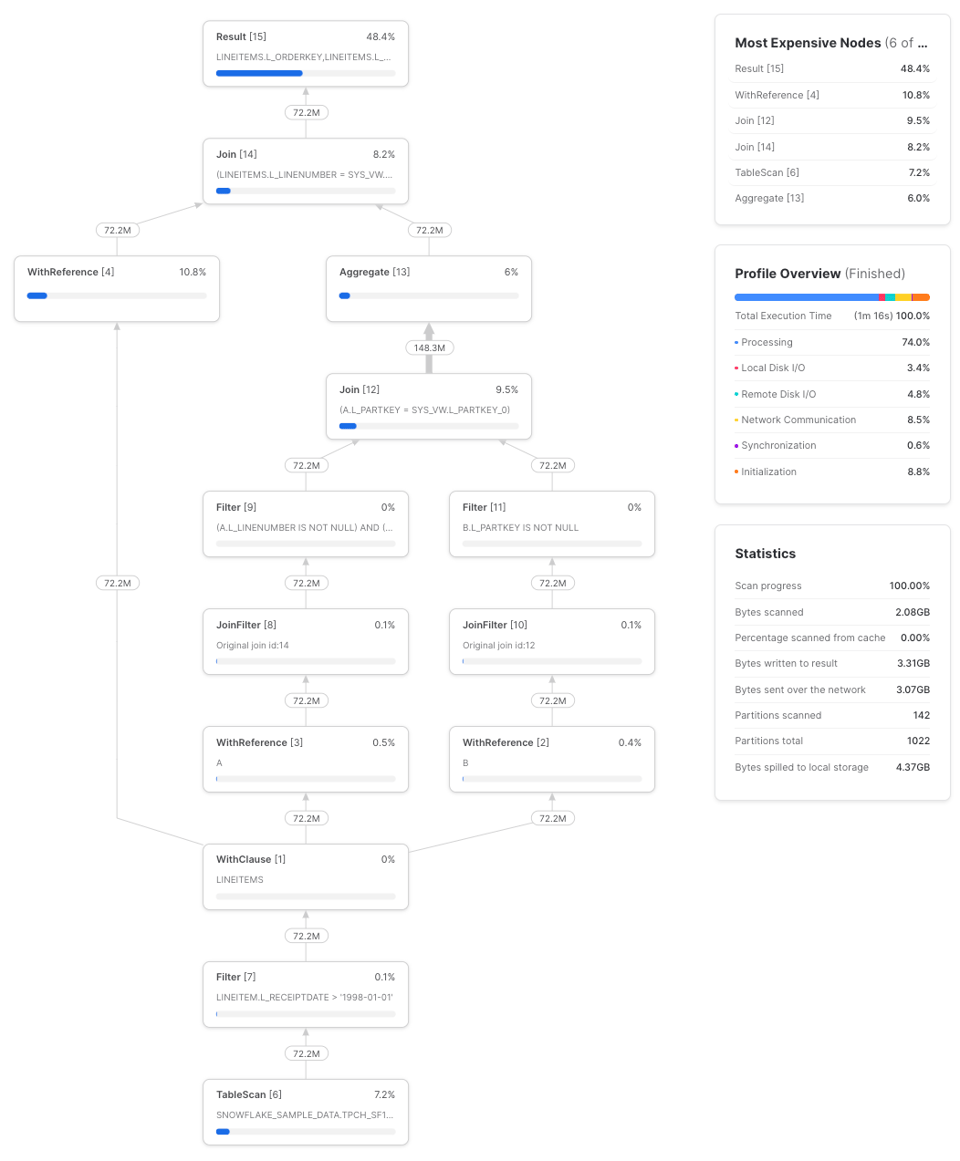
Se reescrevermos a consulta repetindo a CTE lineitems como subconsulta:
with lineitem_future_sales as (
select
a.l_orderkey,
a.l_linenumber,
sum(b.l_quantity) as future_part_order_total
from (
select *
from snowflake_sample_data.tpch_sf100.lineitem
where l_receiptdate > '1998-01-01'
) as a
left join (select *
from snowflake_sample_data.tpch_sf100.lineitem
where l_receiptdate > '1998-01-01'
) as b
on a.l_partkey = b.l_partkey
Expandir código
A consulta leva em média 1m 7s em três execuções, um ganho de velocidade de cerca de 10%. Query profile:
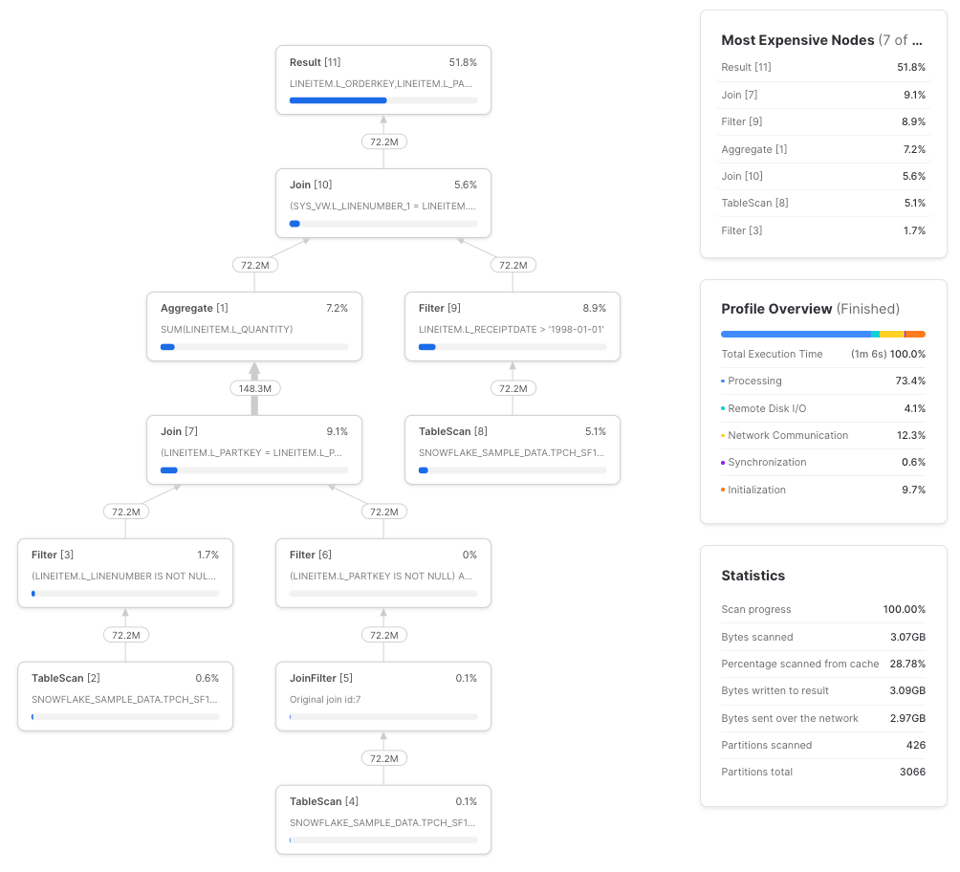
lineitems é uma CTE simples. Quando uma CTE atinge certo nível de complexidade, fica mais barato calculá-la uma vez e repassar os resultados para as referências seguintes do que recalculá-la várias vezes. Mas esse comportamento não é consistente (como vimos no exemplo básico em As CTEs são pass-throughs?), então o melhor é testar. Veja uma forma de visualizar essa relação:
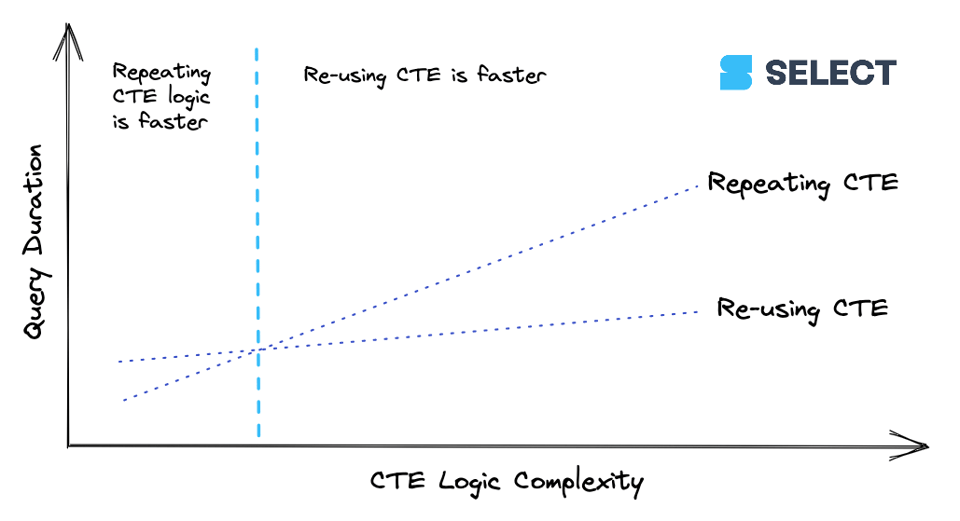
Recomendação
Dá para usar CTEs com tranquilidade no Snowflake, e uma CTE referenciada uma única vez nunca vai impactar a performance. Salvo em alguns exemplos bem específicos como o acima, calcular a CTE uma vez e reaproveitá-la rende a melhor performance, comparado a repetir a lógica. Na seção anterior, vimos que o Snowflake faz o push-down de filtros para dentro das CTEs de forma inteligente, evitando varreduras completas desnecessárias da tabela.
Mas, se você está otimizando uma consulta específica em que performance e eficiência de custo são fundamentais e vale a pena investir tempo, experimente repetir a lógica da CTE. Essa lógica pode ser repetida em várias subconsultas ou pode ser definida em uma view e referenciada várias vezes, como acontecia com a CTE.
Em alguns cenários, as CTEs impedem o column pruning
Em posts anteriores, falamos sobre o design único das micro-partitions do Snowflake e como elas viabilizam uma otimização poderosa chamada micro-partition pruning. Por causa do formato colunar de storage, elas também viabilizam o column pruning. Isso é importante porque significa que só as colunas selecionadas em uma consulta precisam trafegar pela rede.
O column pruning sempre funciona quando uma CTE é referenciada uma única vez (nesse caso, ela é tratada como se não existisse). Em um exemplo simples:
with sample_data as (
select *
from snowflake_sample_data.tpch_sf1.customer
)
select c_name, c_address
from sample_data
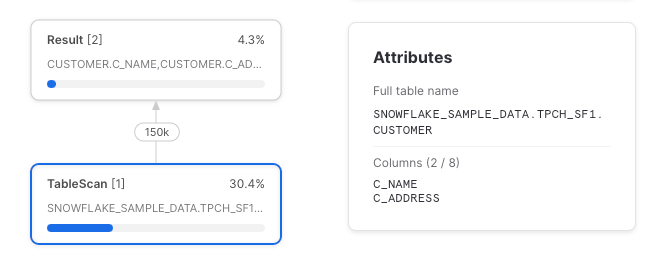
Dá para ver que só as duas colunas selecionadas foram lidas da tabela subjacente. Mas, como já sabemos, uma CTE referenciada uma única vez é um pass-through e é compilada em um plano de consulta que ignora a existência dela.
O column pruning para de funcionar quando uma CTE é referenciada mais de uma vez
Desta vez, vamos referenciar a CTE duas vezes, selecionando uma única coluna em cada referência.
with sample_data as (
select *
from snowflake_sample_data.tpch_sf1.customer
),
customer_names as (
select c_name
from sample_data
),
customer_addresses as (
select c_address
from sample_data
)
Expandir código
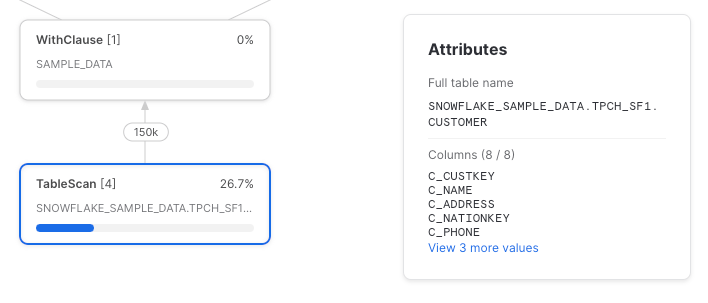
Infelizmente, o Snowflake não fez o push-down das referências de coluna até o table scan subjacente. Veja o query profile completo:
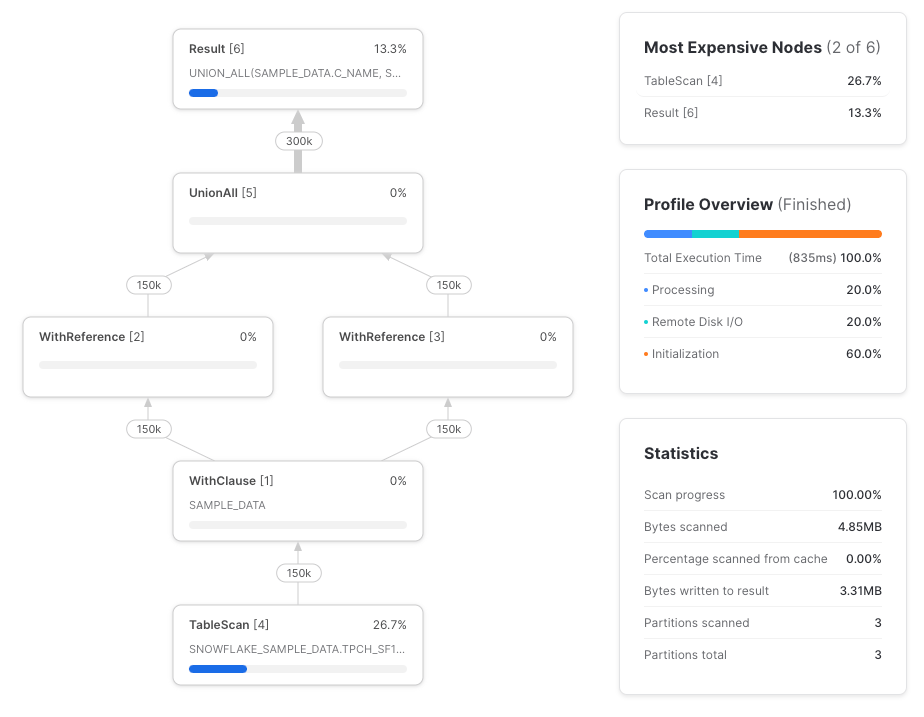
Vamos tentar de novo, agora com referências diretas à tabela.
with customer_names as (
select c_name
from snowflake_sample_data.tpch_sf1.customer
),
customer_addresses as (
select c_address
from snowflake_sample_data.tpch_sf1.customer
)
select c_name
from customer_names
union all
select c_address
from customer_addresses
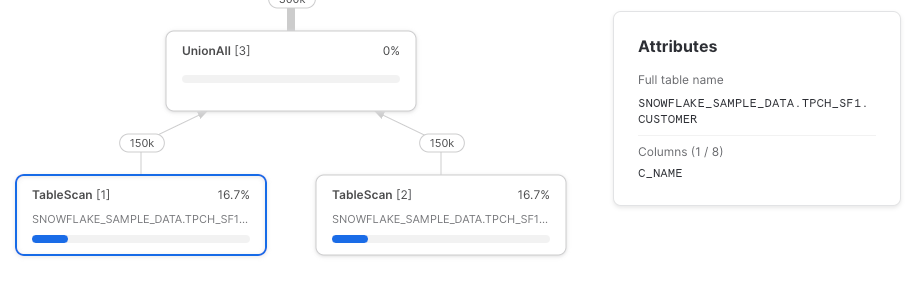
Como esperado, temos dois nós TableScan, e cada um recupera apenas as colunas referenciadas.
O column pruning falha com wildcards e joins
Outro caso em que o Snowflake pode não fazer o push-down do column pruning é com joins (obrigado ao Paul Vernon por apontar esse). O TableScan da tabela nation deveria, idealmente, recuperar só as colunas n_nationkey e n_name, mas acaba trazendo todas.
with nations as (
select *
from snowflake_sample_data.tpch_sf1.nation
),
joined as (
select *
from snowflake_sample_data.tpch_sf1.customer
left join nations
on customer.c_nationkey = nations.n_nationkey
)
select c_address, n_name from joined
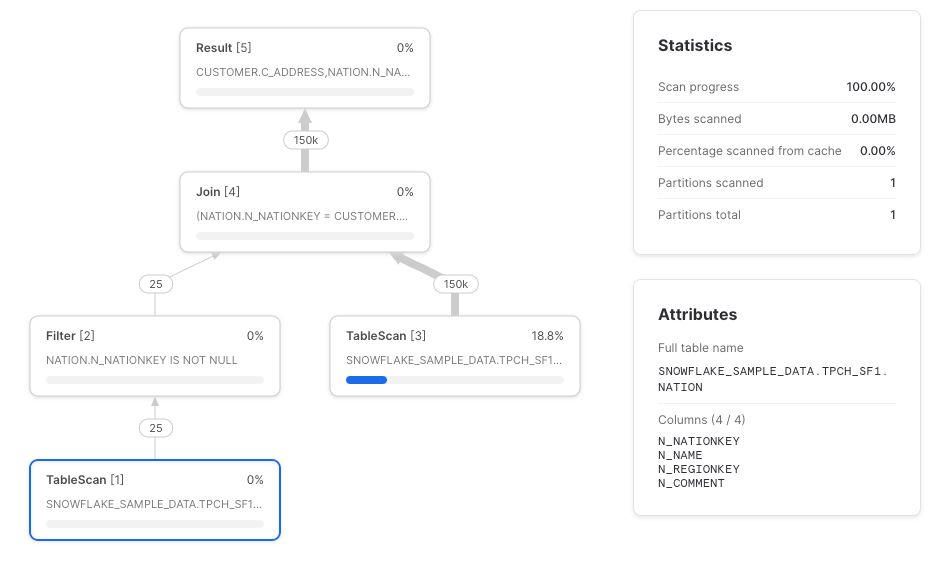
Recomendação
Recomendamos listar as colunas explicitamente quando você usa CTEs, para garantir que os TableScans recuperem só as colunas necessárias. Mas, se a consulta já roda rápido o suficiente, o custo de manutenção de listar tudo pode não compensar.
Na mesma linha, desaconselhamos o uso de CTEs com select * from table, como sugerido no guia de estilo do dbt. Em vez disso, referencie a tabela diretamente para garantir o column pruning.
Então, vale a pena usar CTEs no Snowflake?
Em quase todos os casos, sim. Se sua consulta roda rápido o suficiente e custo não é um problema, pode usar sem medo. É importante não otimizar sem necessidade, já que o tempo e o custo de oportunidade envolvidos podem superar os ganhos.
Mas, se você está otimizando uma consulta específica que usa CTEs, verifique o seguinte:
- Uma CTE simples está sendo referenciada mais de uma vez? Se a CTE faz pouco trabalho, o overhead dos nós
WithClauseeWithReferencepode acabar sendo maior do que simplesmente repetir o cálculo dela, seja por subconsultas ou por uma view. - As referências de coluna estão sofrendo push-down e pruning como esperado nos nós
TableScan? Se não, tente listar as colunas necessárias o quanto antes na consulta. Isso pode acelerar bastante o nóTableScanem tabelas largas.
Identificar e tratar oportunidades de otimização dá trabalho. O SELECT facilita esse processo, trazendo automaticamente à tona otimizações como as deste post. Tenha economia automatizada desde o primeiro dia, identifique rapidamente os centros de custo e otimize seus workloads no Snowflake. Garanta seu acesso hoje ou agende uma demo pelos links abaixo.
Niall Woodward·Co-founder & CTO do SELECT
Niall é Co-Founder e CTO do SELECT, uma plataforma SaaS de gestão e otimização de custos para o Snowflake. Antes de fundar o SELECT, Niall foi data engineer na Brooklyn Data Company e em várias startups. Entusiasta de open source, também é mantenedor do SQLFluff e criador de três pacotes dbt: dbt_artifacts, dbt_snowflake_monitoring e dbt_query_tags.