Le CTE sono uno strumento estremamente prezioso per modularizzare e riutilizzare la logica SQL. Sono anche al centro di frequenti discussioni sull'ottimizzazione, perché il loro utilizzo è spesso associato a esecuzioni di query inattese e talvolta inefficienti. In questo articolo analizziamo l'impatto delle CTE sui piani di esecuzione, capendo quando si possono usare senza timori e quando è meglio evitarle.
Introduzione
Negli ultimi anni si è scritto molto sull'impatto delle CTE sulle performance:
- CTEs are pass-throughs - Tristan Handy - 2018-11-07
- Snowflake query optimizer: unoptimized - Dominik Golebiewski - 2021-10-13
- CTE Considerations - bennieregenold7 - 2022-07-22
- Un recente thread su Slack di dbt - 2023-02-22
Il fatto che se ne parli ancora così tanto, però, dimostra che non si è ancora arrivati a una conclusione definitiva. Questo articolo si propone di offrire una serie ragionata di linee guida su quando usare le CTE e quando invece conviene evitarle. Il query optimizer di Snowflake è in costante evoluzione e, come negli articoli citati sopra, il comportamento osservato in questo post cambierà nel tempo.
Useremo i query profile per capire l'impatto dei diversi design di query sull'esecuzione. Se i query profile sono una novità o se ti serve un ripasso, dai un'occhiata al nostro articolo su come usare il query profile di Snowflake.
Partiamo da un breve ripasso: cosa sono le CTE e perché piacciono così tanto.
Cosa sono le CTE?
Una CTE, o common table expression, è una subquery a cui viene assegnato un nome. Si dichiarano con una clausola with e si richiamano poi tramite il loro identificatore:
with my_cte as (
select 1
)
select * from my_cte
Le CTE si separano con la virgola, quindi è possibile definirne più di una in sequenza:
with my_cte as (
select 1
),
my_cte_2 as (
select 2
)
select *
from my_cte
left join my_cte_2
Volendo, si possono anche annidare CTE dentro altre CTE (anche se la leggibilità ne risente parecchio!):
with my_cte as (
with my_inner_cte as (
select 1
)
select * from my_inner_cte
)
select *
from my_cte
Perché usare le CTE?
I motivi principali per usare le CTE sono:
- Le CTE aiutano a suddividere la logica SQL in subquery distinte e isolate. Questo semplifica il debug, perché basta eseguire
select * from cteper testare una CTE in isolamento. - Le CTE permettono di scrivere SQL in uno stile quasi procedurale, dall'alto verso il basso, facilitando code review e manutenibilità.
- Le CTE aiutano a rispettare il principio DRY (don't repeat yourself), offrendo un unico punto in cui definire una logica richiamata più volte a valle.
Come gestisce Snowflake le CTE nel piano di esecuzione?
Per capire le implicazioni delle CTE sulle performance, bisogna prima vedere come Snowflake gestisce le dichiarazioni di CTE durante l'esecuzione di una query.
Le CTE sono pass-through?
Sì, a patto che la CTE sia referenziata una sola volta. Per pass-through intendiamo che la query viene elaborata allo stesso modo, a prescindere dal fatto che si usi o meno la CTE. Quando una CTE è referenziata una sola volta è sempre un pass-through e nel query profile non se ne trova traccia. Di conseguenza, usare una CTE referenziata una sola volta non avrà mai impatto sulle performance rispetto al non utilizzarla.
with sample_data as (
select *
from snowflake_sample_data.tpch_sf1.customer
)
select *
from sample_data
where c_nationkey = 14
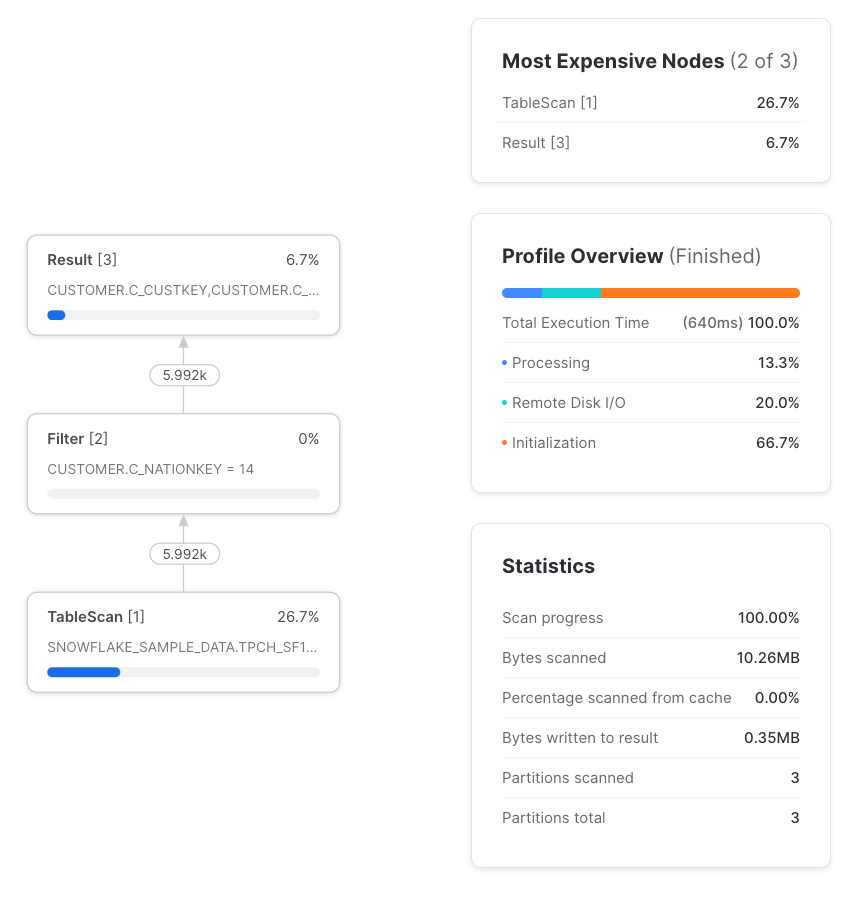
Se invece referenziamo quella CTE più di una volta cambia tutto, e l'esecuzione della query risulta diversa rispetto a quanto otterremmo referenziando direttamente la tabella senza usare una CTE.
with sample_data as (
select *
from snowflake_sample_data.tpch_sf1.customer
),
nation_14_customers as (
select *
from sample_data
where c_nationkey = 14
),
nation_9_customers as (
select *
from sample_data
where c_nationkey = 9
Espandi codice
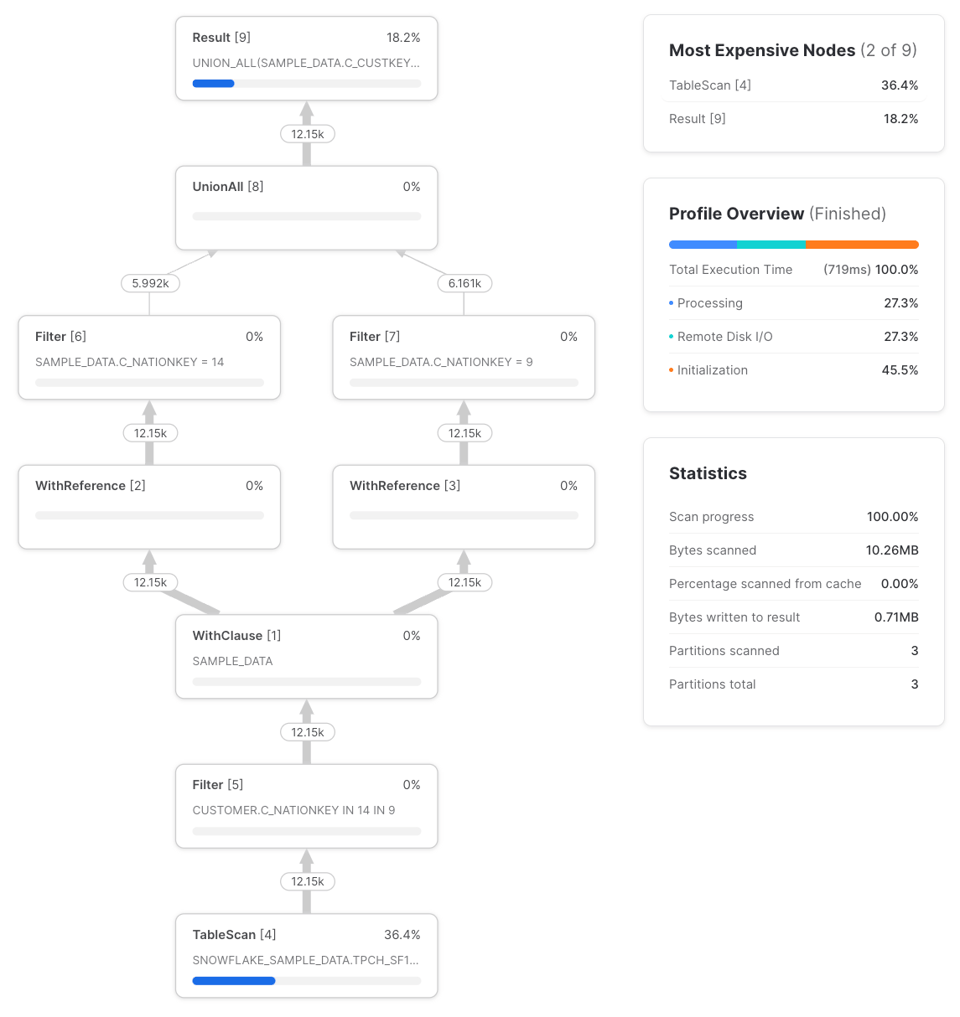
Compaiono due nuovi tipi di nodi: WithClause e WithReference. Il WithClause rappresenta uno stream di output e un buffer della CTE sample_data che abbiamo definito, consumato poi da ciascun nodo WithReference. Da notare come Snowflake esegua in modo intelligente il push-down del filtro presente nelle CTE nation_14_customers e nation_9_customers fino al TableScan, prima del WithClause. In passato Snowflake non lo faceva, come segnalato nell'articolo di Dominik. Vale la pena verificare che questo comportamento si applichi anche a query più complesse, ma in questo caso il profile è identico a quello di una query scritta così:
with sample_data as (
select *
from snowflake_sample_data.tpch_sf1.customer
where c_nationkey in (14, 9)
),
nation_14_customers as (
select *
from sample_data
where c_nationkey = 14
),
nation_9_customers as (
select *
from sample_data
Espandi codice
Ora sostituiamo i riferimenti alla CTE sample_data con un riferimento diretto alla tabella snowflake_sample_data.tpch_sf1.customer e osserviamo le differenze nel piano di esecuzione:
with nation_14_customers as (
select *
from snowflake_sample_data.tpch_sf1.customer
where c_nationkey = 14
),
nation_9_customers as (
select *
from snowflake_sample_data.tpch_sf1.customer
where c_nationkey = 9
)
select *
from nation_14_customers
union all
Espandi codice
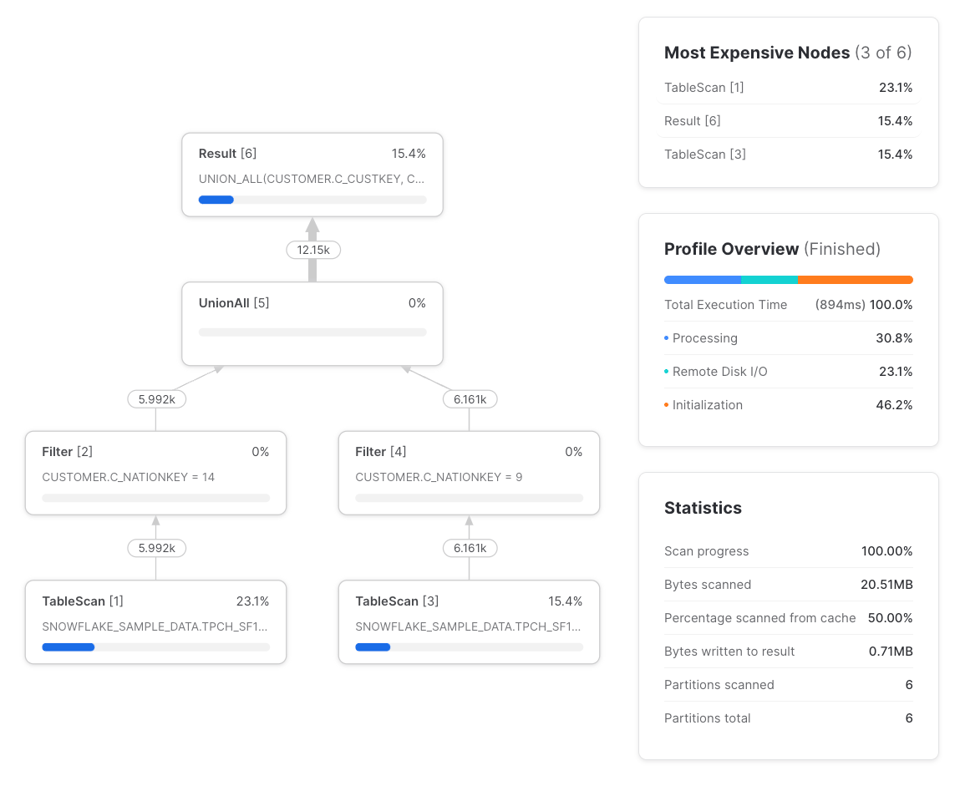
Le differenze sono:
- Due
TableScaninvece di uno. Quello a sinistra legge dallo storage remoto, mentre quello a destra utilizza il risultato già in cache locale sul warehouse del primo. Pur essendoci dueTableScan, solo uno effettua il recupero dei dati da remoto. - Due
Filterinvece di tre, anche se quando un filtro viene applicato dopo unTableScanè il nodoTableScanstesso a occuparsi del filtraggio: per questo il numero di righe in input e in output del filtro coincide. - Nessun nodo
WithClauseoWithReference.
Ora che abbiamo capito come le CTE vengono tradotte in un piano di esecuzione, vediamo le implicazioni sulle performance.
A volte ripetere la logica è più veloce che riutilizzare una CTE
Nella maggior parte dei casi, la strategia di Snowflake di calcolare una sola volta il risultato di una CTE e distribuirlo ai nodi a valle è la più performante. In alcune circostanze, però, il costo di bufferizzare e distribuire il risultato della CTE ai nodi a valle supera quello di ricalcolarlo, soprattutto perché i nodi TableScan usano comunque i risultati in cache.
Ecco un esempio costruito ad hoc, che referenzia tre volte la CTE lineitems:
with lineitems as (
select *
from snowflake_sample_data.tpch_sf100.lineitem
where l_receiptdate > '1998-01-01'
),
lineitem_future_sales as (
select
a.l_orderkey,
a.l_linenumber,
sum(b.l_quantity) as future_part_order_total
from lineitems as a
left join lineitems as b
on a.l_partkey = b.l_partkey
and b.l_receiptdate > a.l_receiptdate
Espandi codice
Su tre esecuzioni, questa query ha impiegato in media 1 minuto e 17 secondi a completarsi su un warehouse small. Ecco un profile di esempio:
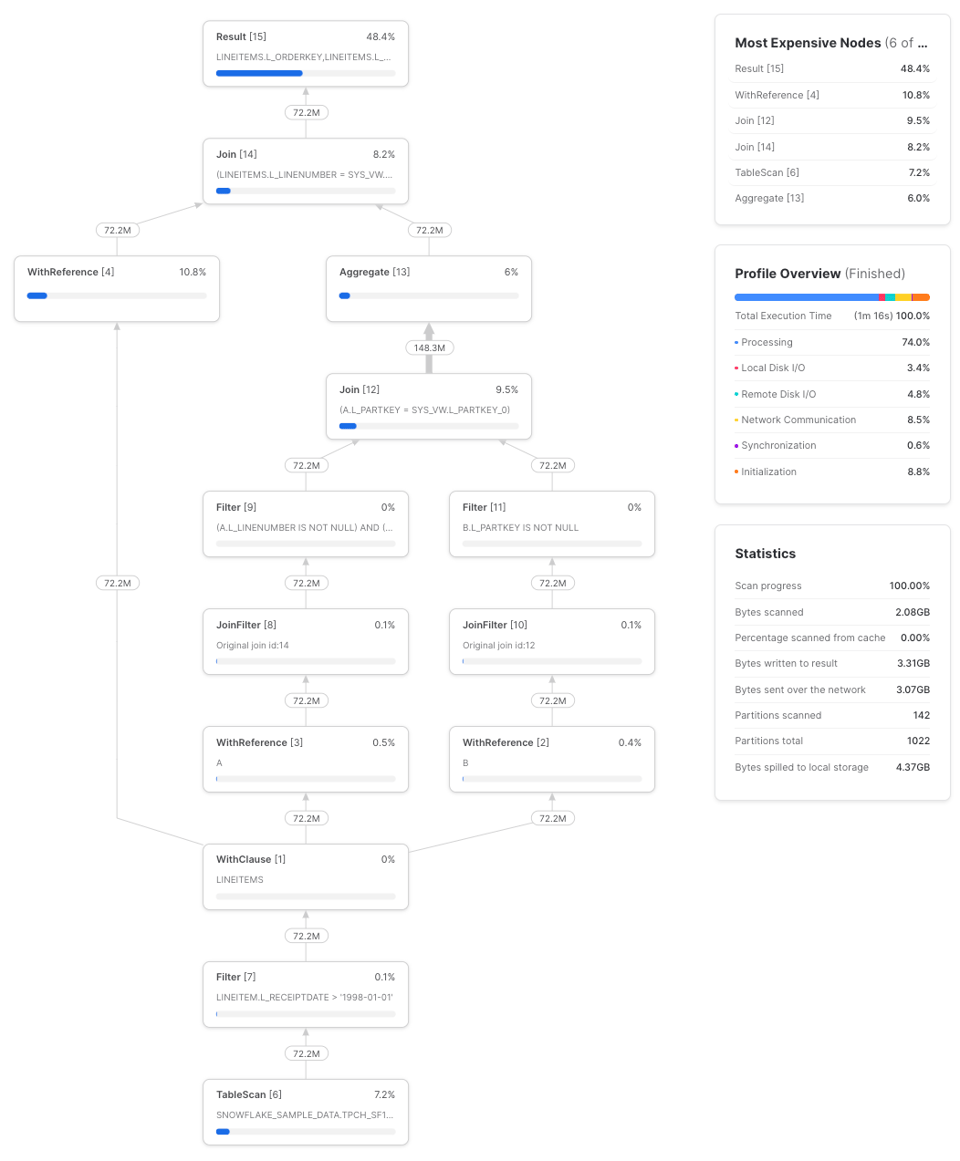
Se invece riscriviamo la query ripetendo la CTE lineitems come subquery:
with lineitem_future_sales as (
select
a.l_orderkey,
a.l_linenumber,
sum(b.l_quantity) as future_part_order_total
from (
select *
from snowflake_sample_data.tpch_sf100.lineitem
where l_receiptdate > '1998-01-01'
) as a
left join (select *
from snowflake_sample_data.tpch_sf100.lineitem
where l_receiptdate > '1998-01-01'
) as b
on a.l_partkey = b.l_partkey
Espandi codice
La query impiega in media 1 minuto e 7 secondi su tre esecuzioni, con un guadagno di circa il 10% sui tempi. Query profile:
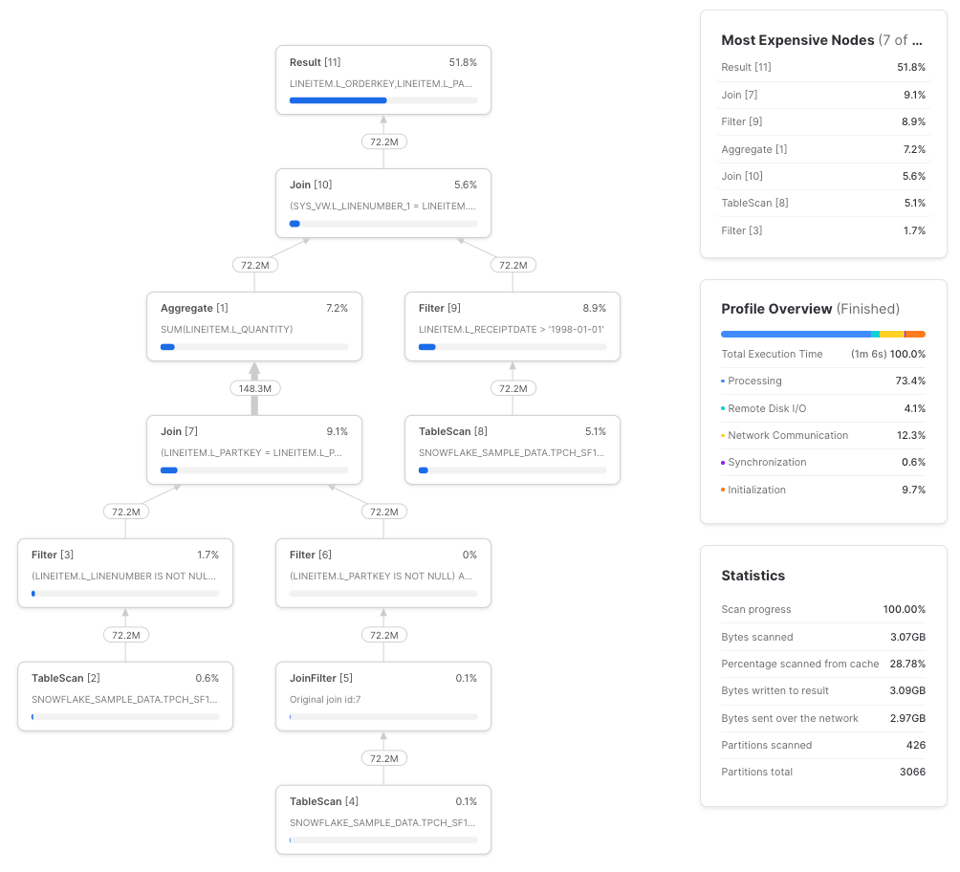
lineitems è una CTE semplice. Quando una CTE raggiunge un certo livello di complessità, conviene calcolarla una sola volta e passarne i risultati ai riferimenti a valle anziché ricalcolarla più volte. Questo comportamento, però, non è sempre coerente (come abbiamo visto nell'esempio di base in Le CTE sono pass-through), quindi conviene sperimentare. Ecco un modo per visualizzare la relazione:
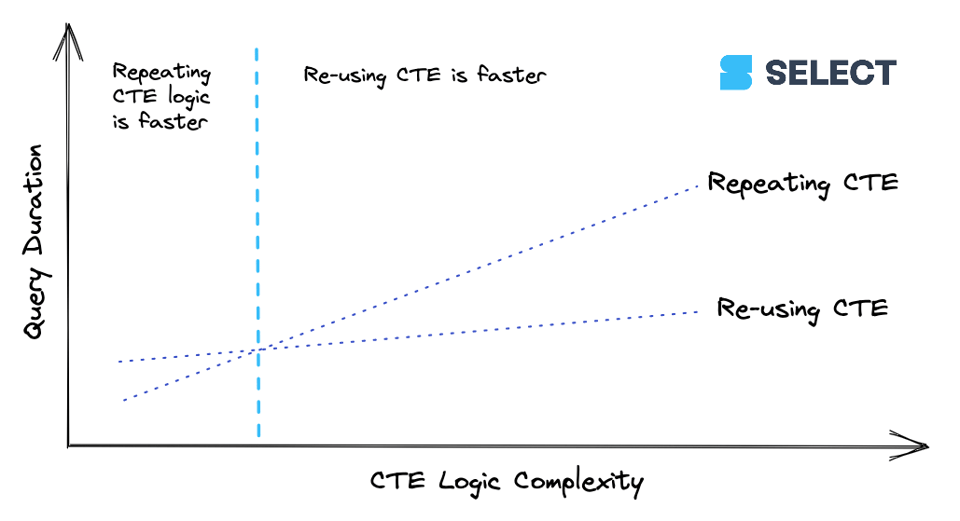
Consiglio
Le CTE si possono usare con tranquillità in Snowflake, e una CTE referenziata una sola volta non avrà mai impatto sulle performance. A parte qualche caso molto specifico come quello visto sopra, calcolare la CTE una sola volta e riutilizzarla offre le performance migliori rispetto a ripeterne la logica. Nella sezione precedente abbiamo visto che Snowflake esegue in modo intelligente il push-down dei filtri all'interno delle CTE, evitando full table scan inutili.
Se però stai ottimizzando una query specifica in cui performance ed efficienza dei costi sono prioritarie, e quindi vale la pena dedicarci tempo, prova a ripetere la logica della CTE. La logica può essere ripetuta in più subquery, oppure definita in una view e referenziata più volte come si farebbe con la CTE.
In alcuni scenari le CTE impediscono il column pruning
Negli articoli precedenti abbiamo parlato del design unico delle micro-partizioni di Snowflake e di come abilitino una potente ottimizzazione chiamata micro-partition pruning. Grazie al loro formato di storage colonnare, abilitano anche il column pruning. È un aspetto importante perché significa che dalla rete vengono recuperate solo le colonne effettivamente selezionate nella query.
Il column pruning funziona sempre quando una CTE è referenziata una sola volta (in quel caso le CTE vengono trattate come se non esistessero). In uno scenario semplice:
with sample_data as (
select *
from snowflake_sample_data.tpch_sf1.customer
)
select c_name, c_address
from sample_data
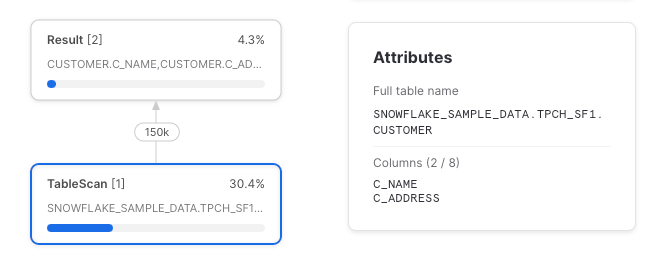
Si vede che dalla tabella sottostante sono state lette solo le due colonne selezionate. Ma, come sappiamo, una CTE referenziata una sola volta è un pass-through e viene compilata in un piano di query del tutto indipendente dalla sua esistenza.
Il column pruning smette di funzionare quando una CTE è referenziata più volte
Questa volta referenziamo la CTE due volte, selezionando una singola colonna in ciascun riferimento.
with sample_data as (
select *
from snowflake_sample_data.tpch_sf1.customer
),
customer_names as (
select c_name
from sample_data
),
customer_addresses as (
select c_address
from sample_data
)
Espandi codice
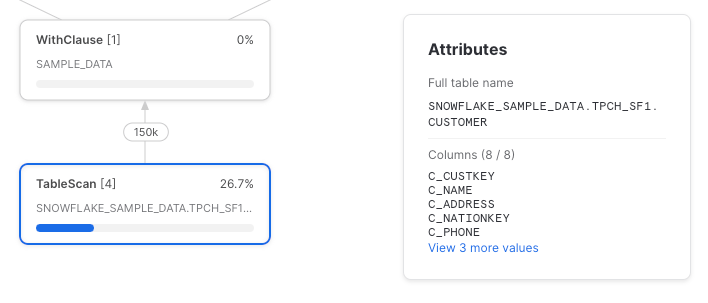
Purtroppo, Snowflake non ha effettuato il push-down dei riferimenti alle colonne fino al table scan sottostante. Ecco il query profile completo:
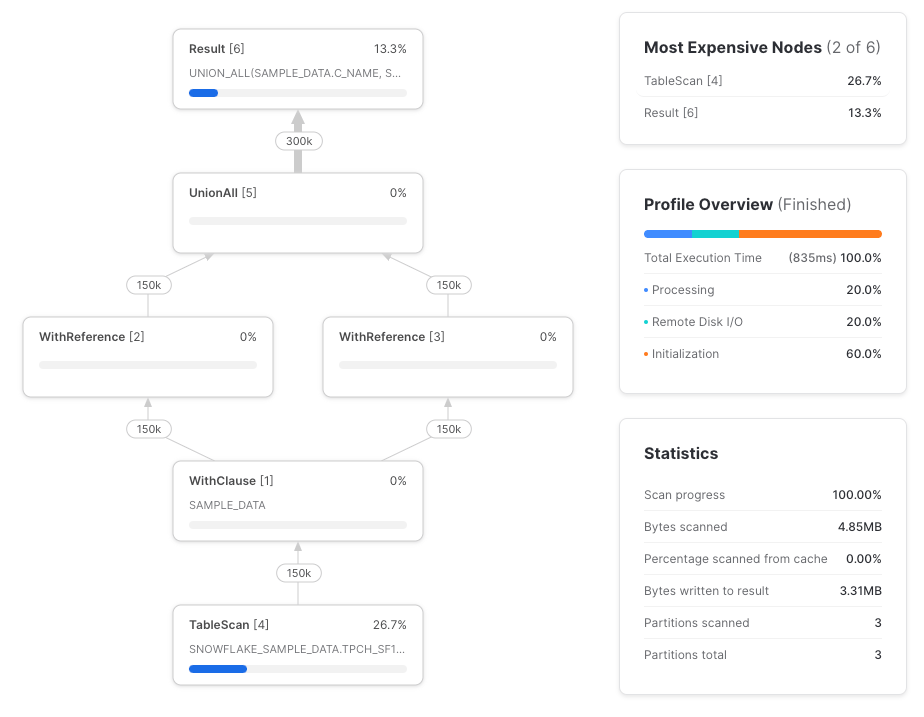
Riproviamo, questa volta usando riferimenti diretti alla tabella.
with customer_names as (
select c_name
from snowflake_sample_data.tpch_sf1.customer
),
customer_addresses as (
select c_address
from snowflake_sample_data.tpch_sf1.customer
)
select c_name
from customer_names
union all
select c_address
from customer_addresses
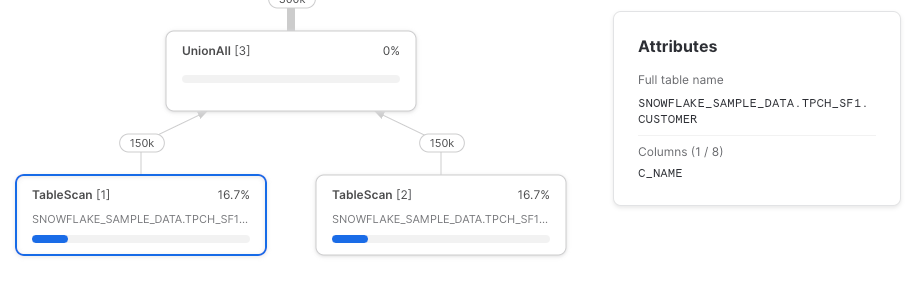
Come previsto, abbiamo due nodi TableScan e ciascuno recupera solo le colonne referenziate.
Il column pruning non funziona con wildcard e join
Un altro caso in cui Snowflake potrebbe non eseguire il push-down del column pruning sono i join (grazie a Paul Vernon per la segnalazione). Idealmente, il TableScan della tabella nation dovrebbe recuperare solo le colonne n_nationkey e n_name, ma le recupera tutte.
with nations as (
select *
from snowflake_sample_data.tpch_sf1.nation
),
joined as (
select *
from snowflake_sample_data.tpch_sf1.customer
left join nations
on customer.c_nationkey = nations.n_nationkey
)
select c_address, n_name from joined
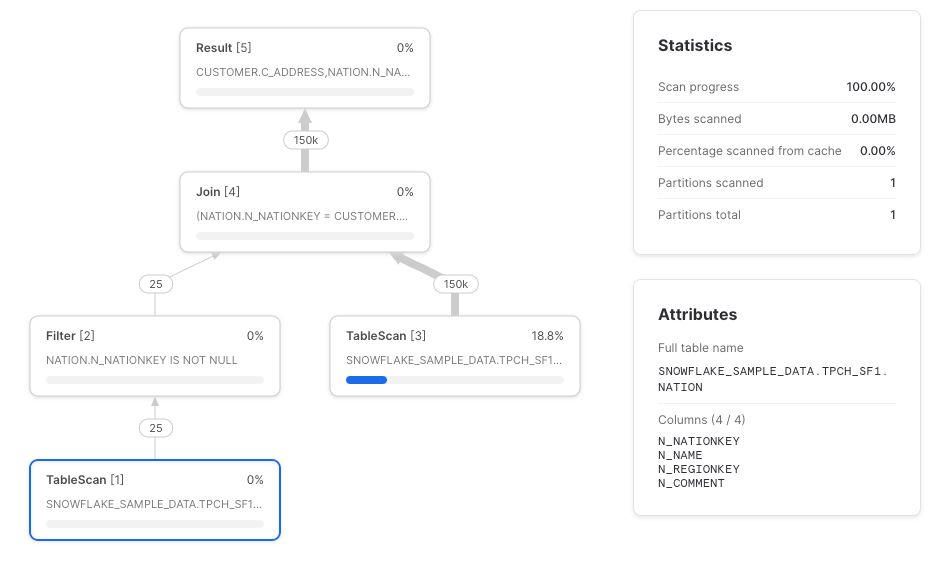
Consiglio
Consigliamo di elencare esplicitamente i riferimenti alle colonne quando si usano le CTE, così da garantire che i TableScan recuperino solo quelle necessarie. Se però una query è già abbastanza veloce, il costo di manutenzione legato all'elencazione esplicita delle colonne potrebbe non valere la candela.
Di conseguenza, sconsigliamo le CTE select * from table proposte nella style guide di dbt. Meglio referenziare direttamente la tabella necessaria, in modo da preservare il column pruning.
Quindi, conviene usare le CTE in Snowflake?
Nella quasi totalità dei casi, sì. Se la query è abbastanza veloce e non ci sono criticità sui costi, vai pure tranquillo. È importante non ottimizzare per il gusto di farlo: il tempo e il costo opportunità impiegati potrebbero superare i benefici.
Se invece stai ottimizzando una query specifica che usa CTE, verifica due cose:
- C'è una CTE semplice referenziata più di una volta? Se la CTE non svolge molto lavoro, l'overhead dei nodi
WithClauseeWithReferencepotrebbe superare il costo di ripeterne il calcolo tramite subquery o view. - I riferimenti alle colonne vengono effettivamente spinti in basso e potati nei nodi
TableScan? In caso contrario, prova a elencare le colonne necessarie il più a monte possibile nella query. Per tabelle molto larghe, questo può migliorare nettamente la velocità del nodoTableScan.
Individuare e mettere in pratica opportunità di ottimizzazione richiede tempo. SELECT lo rende semplice, facendo emergere automaticamente ottimizzazioni come quelle descritte in questo articolo. Ottieni risparmi automatici fin dal primo giorno, individua rapidamente i centri di costo e ottimizza i tuoi workloads Snowflake. Richiedi l'accesso oggi stesso o prenota una demo tramite i link qui sotto.
Niall Woodward·Co-founder & CTO di SELECT
Niall è Co-Founder & CTO di SELECT, una piattaforma SaaS per la gestione e l'ottimizzazione dei costi di Snowflake. Prima di fondare SELECT, ha lavorato come data engineer presso Brooklyn Data Company e in diverse startup. Appassionato di open source, è anche maintainer di SQLFluff e creatore di tre pacchetti dbt: dbt_artifacts, dbt_snowflake_monitoring e dbt_query_tags.