Les CTE sont un outil extrêmement précieux pour modulariser et réutiliser la logique SQL. Elles alimentent aussi de nombreuses discussions d'optimisation, leur usage étant associé à des exécutions de requêtes parfois inattendues, voire inefficaces. Dans cet article, nous analysons leur impact sur les plans d'exécution, identifions quand les utiliser sans risque et quand mieux vaut les éviter.
Introduction
Beaucoup a été écrit ces dernières années sur l'impact des CTE sur les performances :
- CTEs are pass-throughs - Tristan Handy - 07/11/2018
- Snowflake query optimizer: unoptimized - Dominik Golebiewski - 13/10/2021
- CTE Considerations - bennieregenold7 - 22/07/2022
- Un fil récent sur le Slack dbt - 22/02/2023
Le fait que le sujet continue d'alimenter les débats montre qu'aucun consensus n'a encore émergé. Cet article propose un ensemble de recommandations argumentées sur les cas où utiliser des CTE et ceux où mieux vaut s'en passer. L'optimiseur de requêtes de Snowflake évolue en permanence et, comme dans les articles cités, les comportements observés ici changeront au fil du temps.
Nous nous appuyons sur les query profiles pour comprendre l'impact des différentes approches sur l'exécution. Si les query profiles vous sont peu familiers ou si vous souhaitez un rappel, consultez notre article sur comment utiliser le query profile de Snowflake.
Commençons par un rappel de ce que sont les CTE et des raisons de leur popularité.
Qu'est-ce qu'une CTE ?
Une CTE (common table expression) est une sous-requête nommée. On la déclare via une clause with, puis on peut l'interroger via son identifiant :
with my_cte as (
select 1
)
select * from my_cte
Les CTE sont séparées par des virgules, ce qui permet d'en définir plusieurs :
with my_cte as (
select 1
),
my_cte_2 as (
select 2
)
select *
from my_cte
left join my_cte_2
On peut également imbriquer des CTE les unes dans les autres (au prix d'une lisibilité réduite !) :
with my_cte as (
with my_inner_cte as (
select 1
)
select * from my_inner_cte
)
select *
from my_cte
Pourquoi utiliser des CTE ?
Les principales raisons d'utiliser des CTE sont les suivantes :
- Elles permettent de découper la logique SQL en sous-requêtes isolées. Le débogage s'en trouve facilité : il suffit d'exécuter
select * from ctepour tester une CTE isolément. - Elles offrent un style d'écriture procédural, du haut vers le bas, qui facilite la revue de code et la maintenabilité.
- Elles aident à respecter le principe DRY (don't repeat yourself), en centralisant une logique réutilisée à plusieurs reprises en aval.
Comment Snowflake traite-t-il les CTE dans le plan d'exécution ?
Pour saisir l'impact des CTE sur les performances, il faut d'abord comprendre comment Snowflake gère leurs déclarations lors de l'exécution d'une requête.
Les CTE sont-elles des pass-throughs ?
Oui, tant que la CTE n'est référencée qu'une seule fois. Par pass-through, on entend que la requête est traitée de la même manière, que la CTE soit utilisée ou non. Lorsqu'une CTE n'est référencée qu'une fois, c'est toujours un pass-through, et le query profile n'en montre aucune trace. Utiliser une CTE référencée une seule fois n'a donc jamais d'impact sur les performances par rapport à un usage sans CTE.
with sample_data as (
select *
from snowflake_sample_data.tpch_sf1.customer
)
select *
from sample_data
where c_nationkey = 14
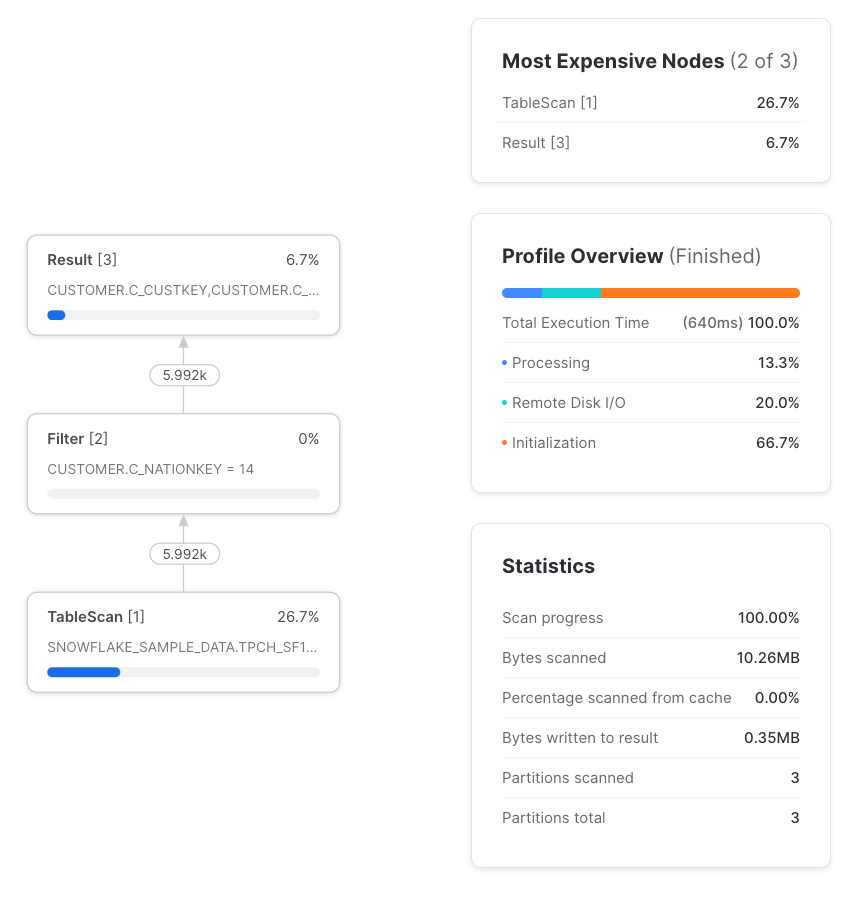
Mais dès que l'on référence cette CTE plusieurs fois, le comportement change : l'exécution diffère alors de celle obtenue en référençant directement la table sans passer par une CTE.
with sample_data as (
select *
from snowflake_sample_data.tpch_sf1.customer
),
nation_14_customers as (
select *
from sample_data
where c_nationkey = 14
),
nation_9_customers as (
select *
from sample_data
where c_nationkey = 9
Expand Code
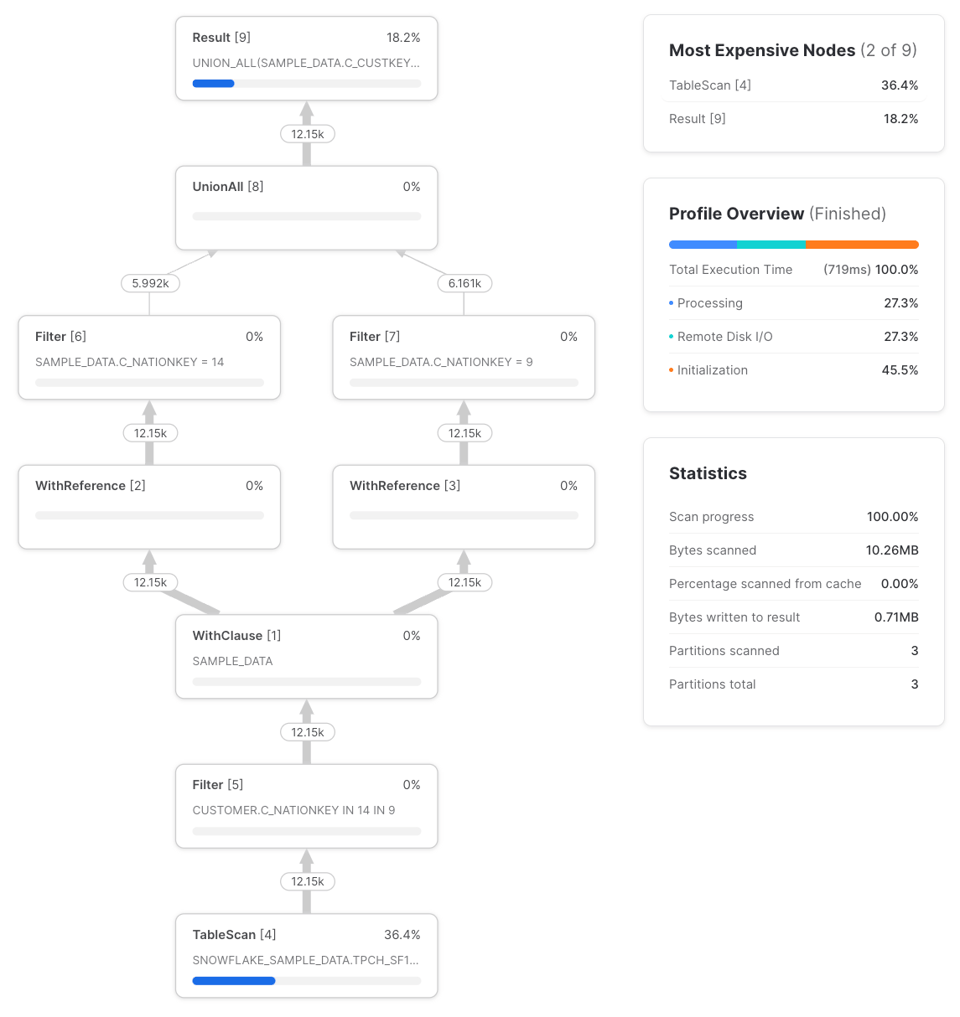
Deux nouveaux types de nœuds apparaissent : WithClause et WithReference. Le WithClause représente un flux de sortie et un buffer issus de la CTE sample_data, ensuite consommés par chaque nœud WithReference. À noter que Snowflake fait intelligemment redescendre (push down) le filtre des CTE nation_14_customers et nation_9_customers jusqu'au TableScan, en amont du WithClause. Auparavant, Snowflake ne le faisait pas, comme le signalait l'article de Dominik. Il reste à vérifier que ce comportement s'applique à des requêtes plus complexes, mais pour celle-ci, le profil est identique à celui qu'on obtiendrait avec :
with sample_data as (
select *
from snowflake_sample_data.tpch_sf1.customer
where c_nationkey in (14, 9)
),
nation_14_customers as (
select *
from sample_data
where c_nationkey = 14
),
nation_9_customers as (
select *
from sample_data
Expand Code
Remplaçons maintenant les références à la CTE sample_data par une référence directe à la table snowflake_sample_data.tpch_sf1.customer, et observons les différences dans le plan d'exécution :
with nation_14_customers as (
select *
from snowflake_sample_data.tpch_sf1.customer
where c_nationkey = 14
),
nation_9_customers as (
select *
from snowflake_sample_data.tpch_sf1.customer
where c_nationkey = 9
)
select *
from nation_14_customers
union all
Expand Code
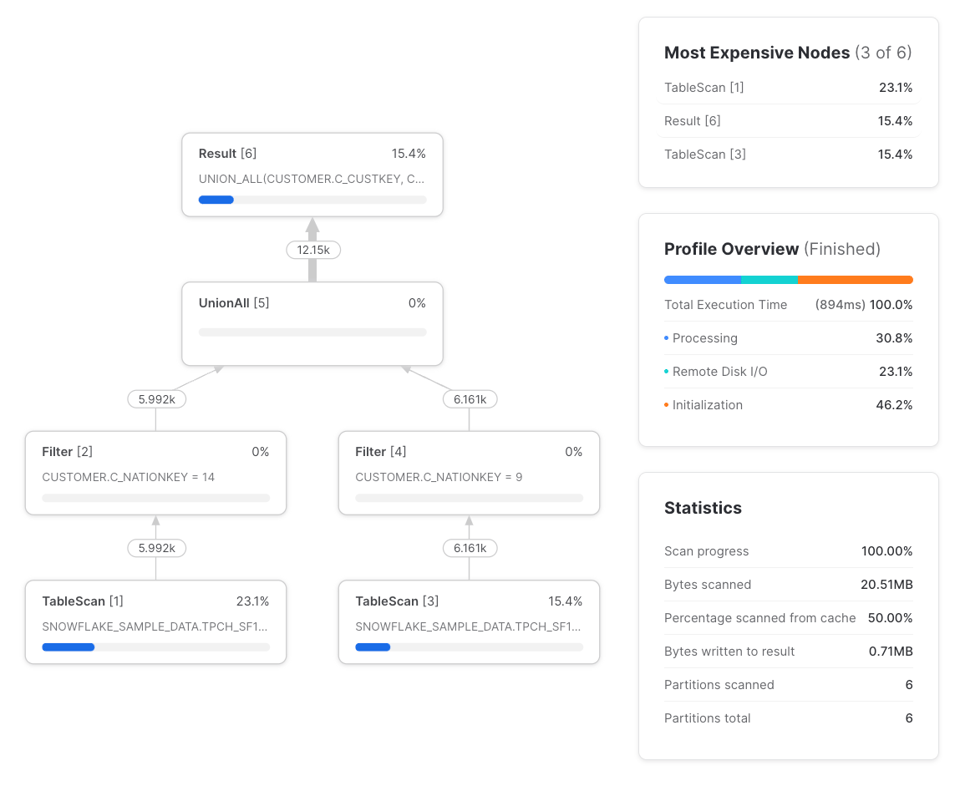
Les différences sont les suivantes :
- Deux
TableScanau lieu d'un. Celui de gauche lit les données depuis le stockage distant, tandis que celui de droite exploite le résultat mis en cache localement par le warehouse. Bien qu'il y ait deuxTableScan, un seul effectue une réelle récupération de données distantes. - Deux
Filterau lieu de trois. Lorsqu'un filtre est appliqué juste après unTableScan, c'est le nœudTableScanlui-même qui prend en charge le filtrage, d'où des comptes de lignes en entrée et en sortie identiques pour le filtre. - Aucun nœud
WithClauseniWithReference.
Maintenant que nous comprenons comment les CTE sont traduites en plan d'exécution, examinons leurs implications en matière de performances.
Parfois, répéter la logique est plus rapide que réutiliser une CTE
La plupart du temps, la stratégie de Snowflake consistant à calculer le résultat d'une CTE une seule fois puis à le distribuer en aval est la plus performante. Mais dans certains cas, le coût de mise en buffer et de distribution du résultat dépasse celui de son recalcul, d'autant que les nœuds TableScan exploitent de toute façon les résultats en cache.
Voici un exemple volontairement construit, qui référence la CTE lineitems trois fois :
with lineitems as (
select *
from snowflake_sample_data.tpch_sf100.lineitem
where l_receiptdate > '1998-01-01'
),
lineitem_future_sales as (
select
a.l_orderkey,
a.l_linenumber,
sum(b.l_quantity) as future_part_order_total
from lineitems as a
left join lineitems as b
on a.l_partkey = b.l_partkey
and b.l_receiptdate > a.l_receiptdate
Expand Code
Sur trois exécutions, cette requête a mis en moyenne 1 min 17 s sur un small warehouse. Voici un exemple de profil :
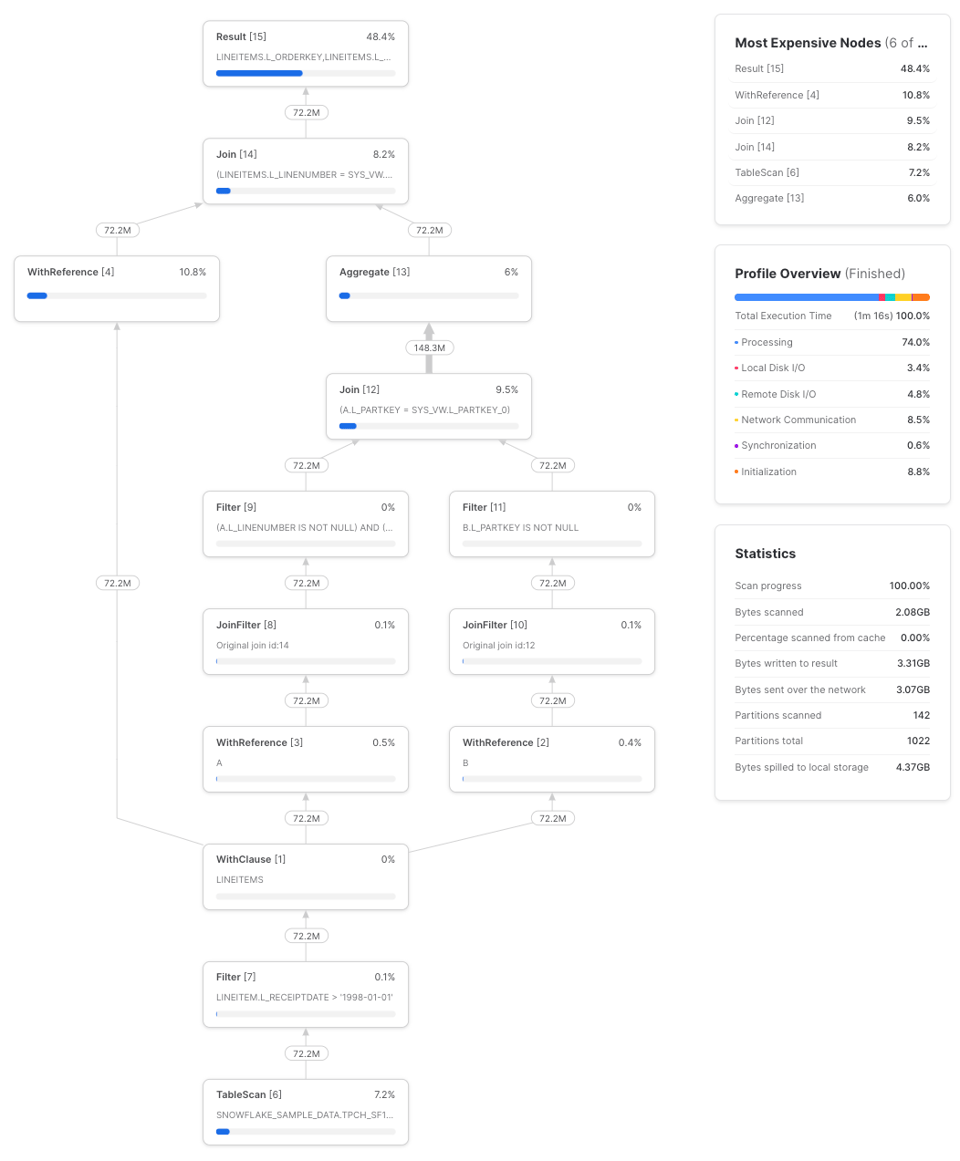
Réécrivons la requête en remplaçant la CTE lineitems par une sous-requête répétée :
with lineitem_future_sales as (
select
a.l_orderkey,
a.l_linenumber,
sum(b.l_quantity) as future_part_order_total
from (
select *
from snowflake_sample_data.tpch_sf100.lineitem
where l_receiptdate > '1998-01-01'
) as a
left join (select *
from snowflake_sample_data.tpch_sf100.lineitem
where l_receiptdate > '1998-01-01'
) as b
on a.l_partkey = b.l_partkey
Expand Code
La requête prend en moyenne 1 min 7 s sur trois exécutions, soit un gain d'environ 10 %. Query profile :
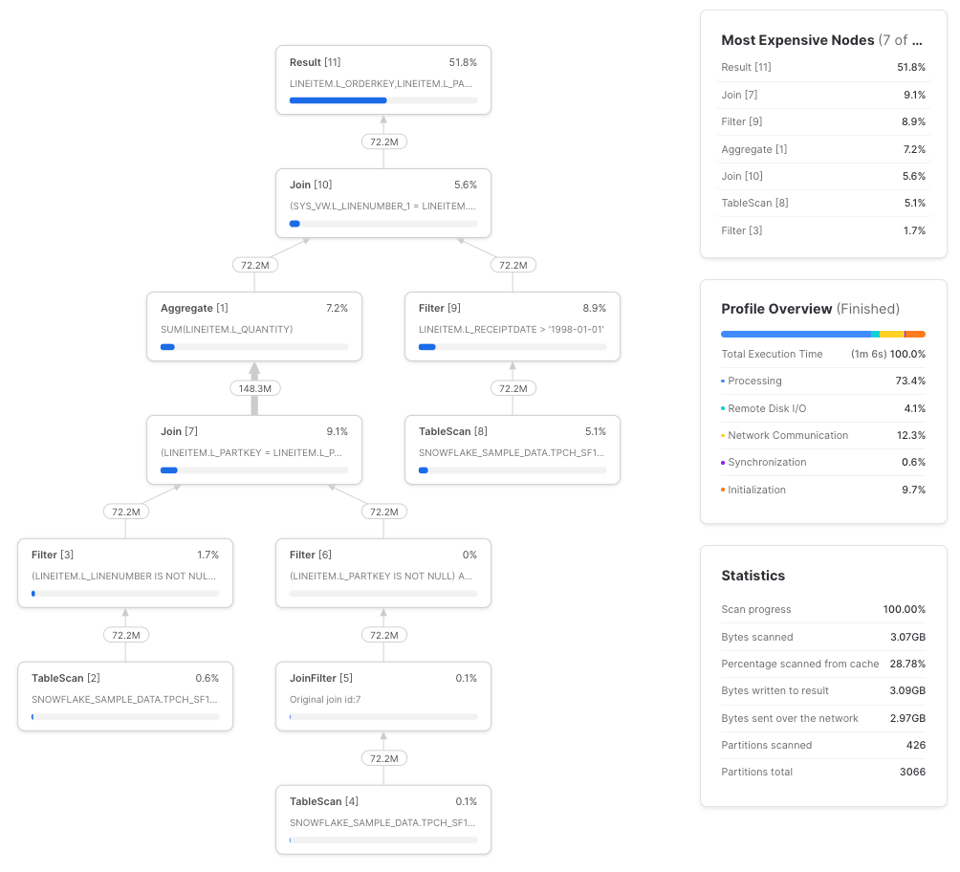
lineitems est une CTE simple. Au-delà d'un certain niveau de complexité, il devient plus économique de calculer la CTE une seule fois et de transmettre ses résultats aux références en aval plutôt que de la recalculer. Ce comportement n'est toutefois pas constant (comme on l'a vu avec l'exemple basique dans Les CTE sont-elles des pass-throughs) ; mieux vaut donc expérimenter. Voici une façon de visualiser la relation :
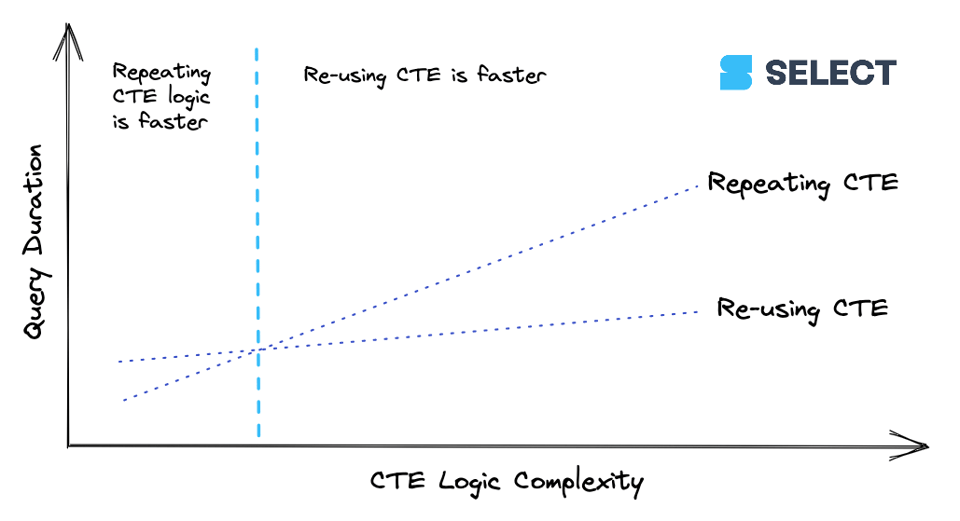
Recommandation
Les CTE peuvent s'utiliser en toute confiance dans Snowflake : une CTE référencée une seule fois n'aura jamais d'impact sur les performances. À l'exception de quelques cas très spécifiques comme celui ci-dessus, calculer la CTE une fois et la réutiliser offre les meilleures performances, par rapport à la répétition de sa logique. Dans la section précédente, nous avons vu que Snowflake fait intelligemment redescendre les filtres dans les CTE pour éviter des scans complets inutiles.
Si toutefois vous optimisez une requête spécifique où la performance et la maîtrise des coûts sont critiques et méritent qu'on y consacre du temps, essayez de répéter la logique de la CTE. Cette logique peut être répétée dans plusieurs sous-requêtes, ou bien définie dans une vue et référencée plusieurs fois, comme l'était la CTE.
Dans certains cas, les CTE empêchent le column pruning
Dans de précédents articles, nous avons abordé la conception singulière des micro-partitions de Snowflake et la puissante optimisation qu'elles permettent : le micro-partition pruning. Leur format de stockage en colonnes autorise également le column pruning. C'est important : seules les colonnes sélectionnées dans une requête sont récupérées via le réseau.
Le column pruning fonctionne toujours lorsqu'une CTE est référencée une seule fois (elle est alors traitée comme si elle n'existait pas). Dans un cas simple :
with sample_data as (
select *
from snowflake_sample_data.tpch_sf1.customer
)
select c_name, c_address
from sample_data
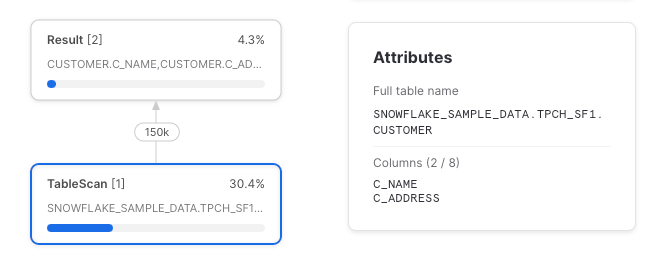
On constate que seules les deux colonnes sélectionnées ont été lues depuis la table sous-jacente. Mais, comme vu précédemment, une CTE référencée une seule fois est un pass-through, et le plan d'exécution est compilé indépendamment de son existence.
Le column pruning cesse de fonctionner lorsqu'une CTE est référencée plusieurs fois
Cette fois, référençons la CTE deux fois, en sélectionnant une seule colonne à chaque référence.
with sample_data as (
select *
from snowflake_sample_data.tpch_sf1.customer
),
customer_names as (
select c_name
from sample_data
),
customer_addresses as (
select c_address
from sample_data
)
Expand Code
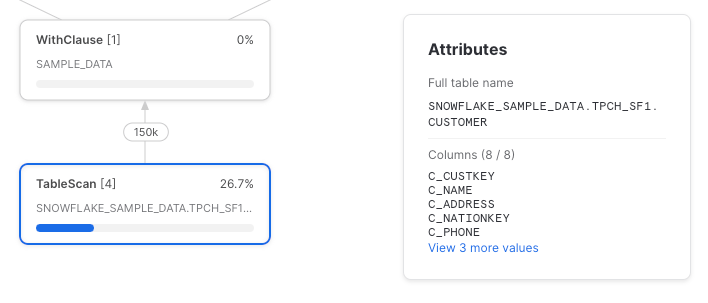
Malheureusement, Snowflake n'a pas fait redescendre les références de colonnes jusqu'au scan de la table sous-jacente. Voici le query profile complet :
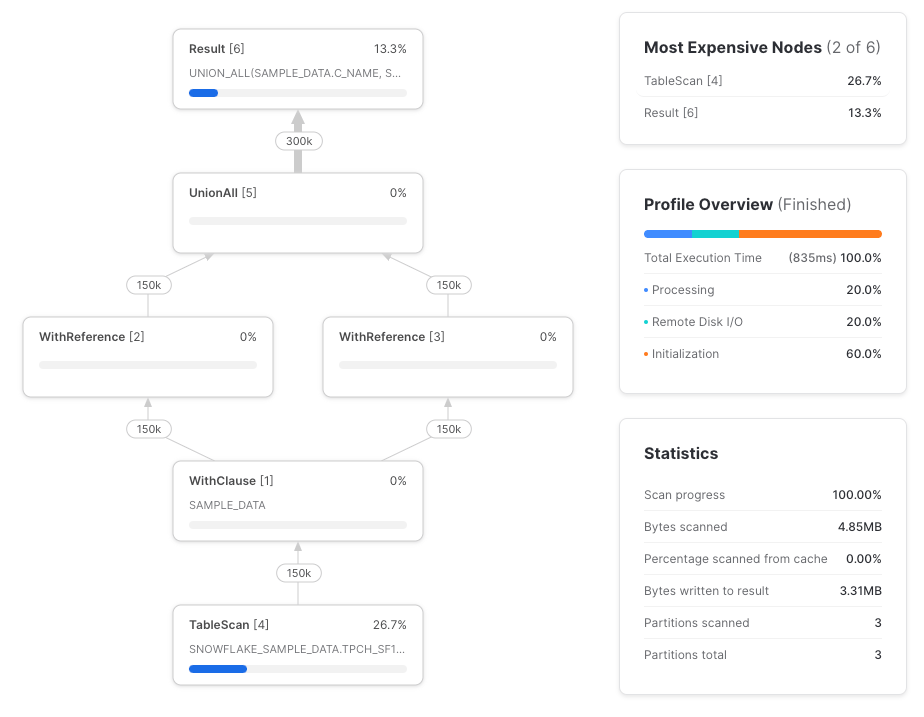
Réessayons, cette fois avec des références directes à la table.
with customer_names as (
select c_name
from snowflake_sample_data.tpch_sf1.customer
),
customer_addresses as (
select c_address
from snowflake_sample_data.tpch_sf1.customer
)
select c_name
from customer_names
union all
select c_address
from customer_addresses
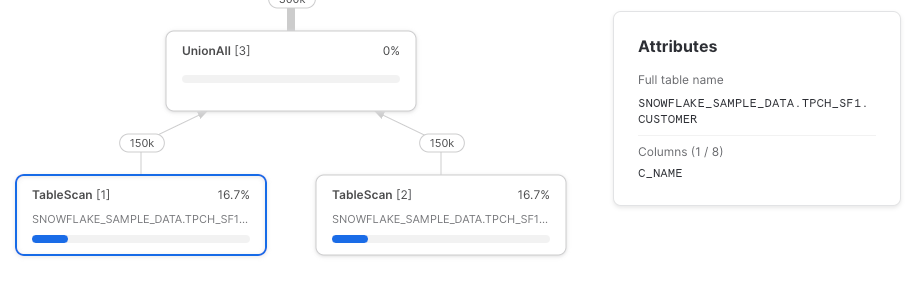
Comme attendu, nous obtenons deux nœuds TableScan, chacun ne récupérant que les colonnes référencées.
Le column pruning ne tient pas face aux wildcards et aux jointures
Autre cas où Snowflake peut ne pas effectuer le push-down du column pruning : les jointures (merci à Paul Vernon de l'avoir signalé). Le TableScan de la table nation devrait idéalement ne récupérer que les colonnes n_nationkey et n_name, mais il les récupère toutes.
with nations as (
select *
from snowflake_sample_data.tpch_sf1.nation
),
joined as (
select *
from snowflake_sample_data.tpch_sf1.customer
left join nations
on customer.c_nationkey = nations.n_nationkey
)
select c_address, n_name from joined
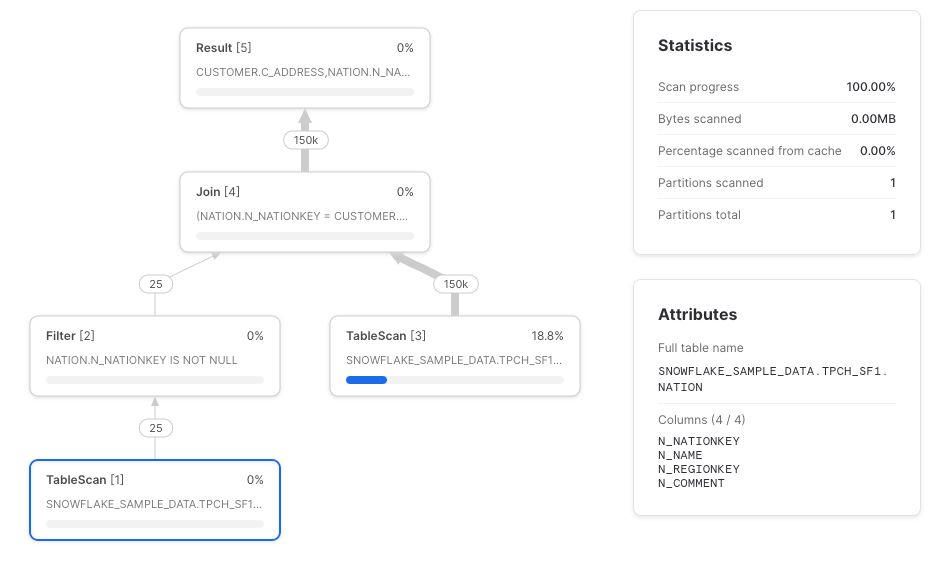
Recommandation
Nous recommandons de lister explicitement les références de colonnes lorsque des CTE sont utilisées, afin de garantir que les TableScan ne récupèrent que les colonnes nécessaires. Cela dit, si une requête s'exécute suffisamment vite, le coût de maintenance lié à l'énumération explicite des colonnes ne vaut pas toujours la peine.
En conséquence, nous déconseillons les CTE de type select * from table préconisées dans le style guide de dbt. Référencez plutôt directement la table concernée pour préserver le column pruning.
Alors, faut-il utiliser des CTE dans Snowflake ?
Dans la quasi-totalité des cas, oui. Si votre requête s'exécute suffisamment vite et qu'il n'y a pas d'enjeu de coût, allez-y. Inutile d'optimiser sans raison : le temps et le coût d'opportunité associés peuvent dépasser les bénéfices.
Si vous optimisez une requête particulière qui utilise des CTE, vérifiez les points suivants :
- Une CTE simple est-elle référencée plusieurs fois ? Si la CTE n'effectue pas beaucoup de travail, le surcoût des nœuds
WithClauseetWithReferencepeut dépasser celui d'une simple répétition du calcul via des sous-requêtes ou une vue. - Les références de colonnes sont-elles bien poussées vers le bas et élaguées comme attendu dans les nœuds
TableScan? Sinon, essayez de lister les colonnes requises le plus tôt possible dans la requête. Cela peut considérablement accélérer le nœudTableScansur des tables larges.
Identifier et concrétiser les opportunités d'optimisation prend du temps. SELECT simplifie tout cela en faisant remonter automatiquement des optimisations comme celles présentées dans cet article. Bénéficiez d'économies automatisées dès le premier jour, identifiez rapidement les postes de coûts et optimisez vos workloads Snowflake. Obtenez un accès dès aujourd'hui ou réservez une démo via les liens ci-dessous.
Niall Woodward·Co-founder & CTO of SELECT
Niall est cofondateur et CTO de SELECT, une plateforme SaaS de gestion et d'optimisation des coûts Snowflake. Avant de lancer SELECT, Niall était data engineer chez Brooklyn Data Company et dans plusieurs startups. Passionné d'open source, il est également mainteneur de SQLFluff et créateur de trois packages dbt : dbt_artifacts, dbt_snowflake_monitoring et dbt_query_tags.