Semi-strukturierte Daten sind in vielen Datenprojekten zu einer tragenden Säule geworden. Sie bieten mehr Flexibilität als strukturierte Daten – eine Flexibilität, die viele Workloads brauchen, vor allem solche rund um APIs, IoT-Sensoren oder Web-Apps. JSON hat sich zum De-facto-Standard für die Kommunikation zwischen APIs entwickelt. Weil diese Daten nicht wie klassische relationale Daten strukturiert sind, bringt ihre Verarbeitung eigene Herausforderungen mit sich. In den folgenden Blogbeiträgen möchte ich zeigen, was die Snowflake-Datenplattform bei der Verarbeitung semi-strukturierter Daten leistet. Wir gehen den gesamten Daten-Lifecycle durch – von der Ingestion über die Verarbeitung bis zur Bereitstellung für die Konsumenten.
Was sind semi-strukturierte Daten?
Semi-strukturierte Daten folgen nicht der tabellarischen Struktur relationaler Daten. Man kann sie als Hybrid zwischen strukturierten und unstrukturierten Datenformaten verstehen. Sie weisen zwar ein gewisses Maß an Organisation auf, lassen sich aber deutlich flexibler speichern und nutzen.
Zu den Elementen semi-strukturierter Daten zählen:
- Key-Value-Paare – die einfachste Form semi-strukturierter Daten: eine schlichte Datenstruktur, bei der jedes Element aus einem Schlüssel und einem zugehörigen Wert besteht.
- Hierarchische Strukturen – semi-strukturierte Daten lassen sich in verschachtelten Elementen organisieren und bilden so komplexere Hierarchien ab.
- Felder mit mehreren Werten – semi-strukturierte Daten können Felder mit mehreren Werten enthalten, üblicherweise als Arrays bezeichnet.
Beispiel für semi-strukturierte JSON-Daten
Nehmen wir ein JSON-Dokument als Beispiel, denn das JSON-Format ist für Menschen gut lesbar. Ein festes Format gibt es nicht – die Struktur richtet sich nach den Anforderungen des jeweiligen Use Cases. Eine Beispiel-JSON-Datei sehen Sie in der Abbildung unten. Sie enthält ein Personen-Element mit mehreren Key-Value-Paaren und einem Array.
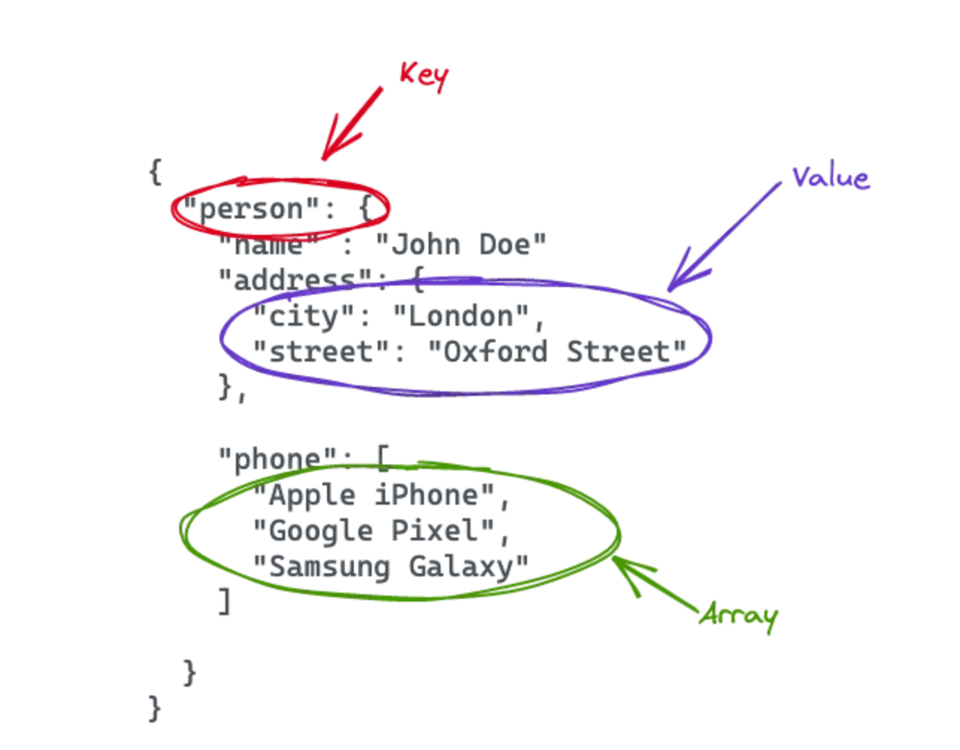
Native Unterstützung für semi-strukturierte Datenformate in Snowflake
Wie geht Snowflake mit semi-strukturierten Daten um? Ziemlich gut, würde ich sagen. Snowflake unterstützt sie nativ. Das heißt, Sie können Daten in den folgenden Formaten direkt importieren und exportieren:
- JSON
- Avro
- ORC
- Parquet
- XML
Für die Speicherung semi-strukturierter Daten in Snowflake stehen die folgenden nativen Datentypen zur Verfügung: ARRAY, OBJECT, VARIANT.
Erwähnenswert ist außerdem, dass Sie semi-strukturierte Daten über External Tables nutzen können, ohne sie in Snowflake zu laden. Ihre JSON- oder Parquet-Dateien bleiben in Ihrem externen Data Lake liegen – und Sie arbeiten in Snowflake trotzdem mit den Daten!
Semi-strukturierte Daten in Snowflake laden
Eine Auffrischung zum Thema Datenladen in Snowflake finden Sie in unserem vorherigen Beitrag, der alle Optionen vorstellt. Im Folgenden gehe ich gezielt auf zwei Optionen für das Laden semi-strukturierter Daten ein.
Option 1: Die gesamte Datei in eine einzelne Spalte laden
Beim Laden semi-strukturierter Rohdaten in Snowflake-Tabellen haben Sie zwei Möglichkeiten: Entweder Sie speichern die gesamte Datei bzw. das Dokument in einer einzelnen Spalte, oder Sie flachen die Daten ab und legen die einzelnen Werte in separaten Spalten ab. Das hängt vom Use Case ab und davon, wie Sie später mit den Daten arbeiten möchten. Ich lade die Daten meistens im Rohformat und speichere sie in einer VARIANT-Spalte. Das Abflachen erledige ich danach, weil das die spätere Verarbeitung vereinfacht. Beachten Sie: Ein einzelner VARIANT-Wert ist auf 128 MB komprimierte Daten begrenzt. Eine JSON-Datei mit 128 MB komprimierten Daten – das ist schon eine ordentlich große Datei. 🙂
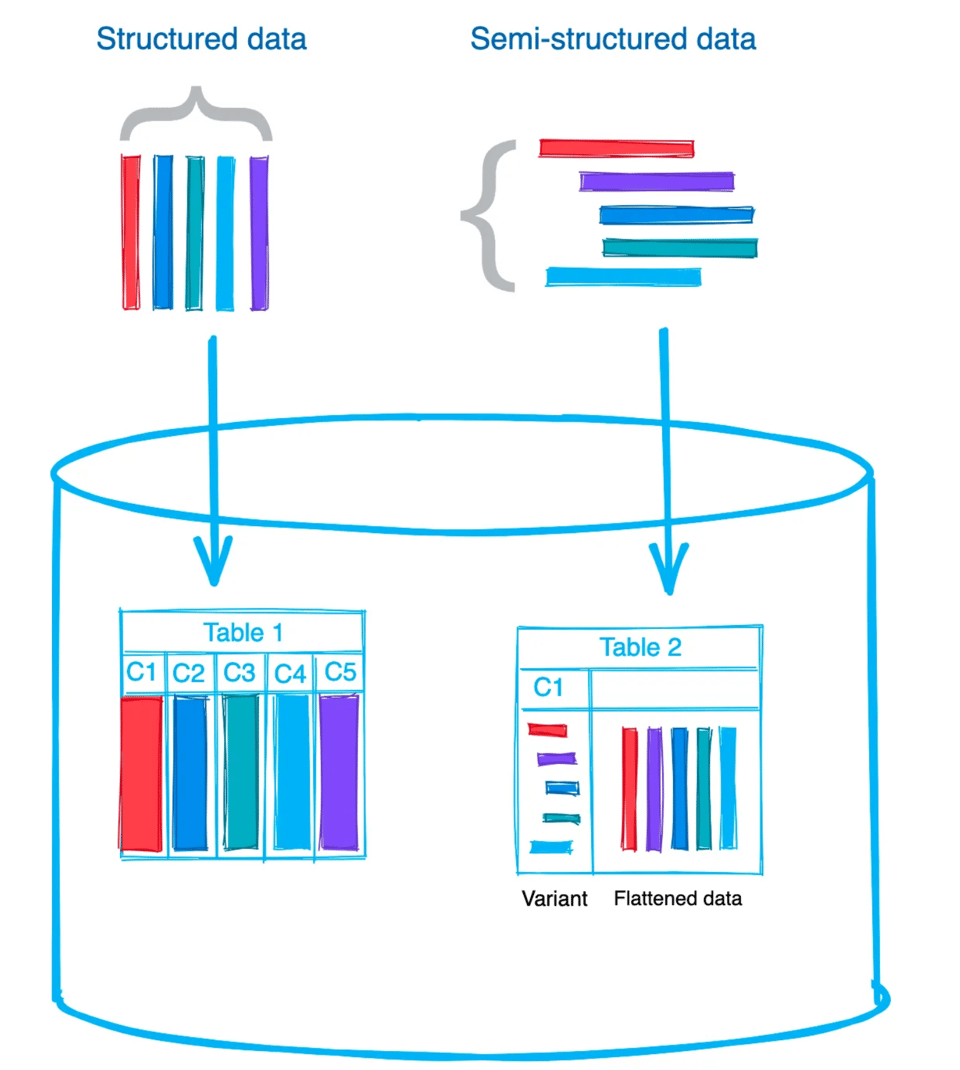
Option 2: Ein Schema aus der Dateistruktur ableiten
Der erste Ansatz funktioniert für JSON-Dateien, aber semi-strukturierte Daten lassen sich auch in anderen Formaten ablegen. Häufig findet man Daten im Apache-Parquet-Format, vor allem in Data Lakes. Anders als JSON, das ein textbasiertes Format ist, ist Parquet ein binäres, für spaltenorientierte Speicherung optimiertes Format. Die Daten werden also in Spalten statt in Zeilen abgelegt – das macht Abfragen und Analysen großer Datensätze deutlich effizienter.
Ein zentraler Vorteil von Parquet ist die effiziente Verarbeitung sehr großer Datensätze. Weil die Daten spaltenweise gespeichert werden, lassen sie sich kompakt komprimieren – das reduziert den Speicherbedarf und beschleunigt Lesezugriffe.
Ein weiterer Unterschied zwischen JSON und Parquet liegt im Umgang mit Datentypen. JSON ist lose typisiert und erzwingt keine festen Datentypen pro Feld. Parquet hingegen hat ein klar definiertes Schema und unterstützt verschiedene Datentypen wie Integer, Fließkommazahlen, Strings und Timestamps. Das erleichtert konsistentes Arbeiten und sorgt für eine präzise Speicherung und Verarbeitung.
Diese Unterschiede erfordern auch unterschiedliche Vorgehensweisen bei der Datenaufnahme. Da Parquet ein klar definiertes Schema hat, müssen Sie es beim Import angeben. Wer schon einmal Parquet-Daten in Snowflake geladen hat, kennt vermutlich den zeitraubenden Prozess der Schemadefinition. Außerdem müssen Sie eine Zieltabelle mit exakt demselben Schema anlegen. Bei Dateien mit dutzenden oder hunderten Spalten kann das schnell Stunden dauern.
Zur Erinnerung – für alle, die noch nicht wissen, wie man Parquet-Daten in Snowflake lädt, hier der entsprechende Code. Sie sehen: Im COPY-Befehl müssen die Attribute aus der Datei zusammen mit ihrem Datentyp angegeben werden.
COPY INTO <table_name>
FROM (
SELECT
$1:column1::<target_data_type>,
$1:column2::<target_data_type>,
$1:column3::<target_data_type>
FROM <my_stage>.<my_file.parquet>
);
``
$1 in der SELECT-Abfrage verweist auf die einzelne Spalte, in der alle Parquet-Daten liegen.
Bevor Sie die Daten in Snowflake laden können, legen Sie zunächst eine Zieltabelle mit dem passenden Schema an und schreiben dann das COPY-Statement mit allen Spalten – so wie im Beispiel oben.
Überlegungen: Speicherung in einer einzelnen Spalte vs. Abflachen der verschachtelten Struktur
Sie fragen sich jetzt vielleicht: Wann eignet sich welche Option?
Wenn Sie noch nicht wissen, wie die Daten später verwendet werden, ist die Speicherung in einer einzelnen VARIANT-Spalte ein guter Ausgangspunkt. Laut Snowflake-Dokumentation erreichen Sie eine vergleichbare Query-Performance wie bei einer abgeflachten Struktur, sofern das semi-strukturierte Format native Typen wie Strings und Integer verwendet. Auch die Speicherkosten bewegen sich auf ähnlichem Niveau.
Bei Datumswerten, Timestamps oder Arrays erzielen Sie laut Snowflake besseres Query Pruning, wenn Sie diese als separate Spalten ablegen.
Häufig genutzte Spalten bzw. Felder separat zu speichern verbessert zudem die Endnutzer-Experience: Der Umgang mit den Daten wird einfacher, und die Nutzer müssen nicht wissen, wie man JSON-Daten parst.
Automatische Schemaerkennung und Tabellenerstellung
Statt alle benötigten Spalten von Hand aufzulisten, hat Snowflake diesen Prozess automatisiert. Es stehen mehrere eingebaute Funktionen bereit, mit denen Sie das Schema aus der Datei auslesen und den COPY-Befehl vorbereiten können. Auch für die Tabellenerstellung gibt es eine eigene Funktion. Aus eigener Erfahrung kann ich sagen: Das spart leicht Stunden – ich habe mit sehr großen Parquet-Dateien (100+ Spalten) gearbeitet, bei denen ich alles manuell erledigen musste. Schauen wir uns an, wie Sie diese Funktionen einsetzen und den gesamten Prozess automatisieren.
So nutzen Sie INFER_SCHEMA
Die Funktion INFER_SCHEMA erkennt automatisch das Metadaten-Schema in Staged Files mit semi-strukturierten Daten und gibt die Spaltendefinitionen zurück. Aktuell funktioniert sie für Apache-Parquet-, Apache-Avro- und ORC-Dateien.
Es handelt sich um eine Table Function – sie muss daher mit dem Keyword TABLE() umschlossen werden:
SELECT *
FROM TABLE(
INFER_SCHEMA(
LOCATION=>'@mystage',
FILE_FORMAT=>'my_parquet_format'
)
);
Die Ausgabe sieht dann so aus:
| COLUMN_NAME | TYPE | NULLABLE | EXPRESSION | FILENAMES | ORDER_ID |
|---|---|---|---|---|---|
| id | TEXT | True | $1:id::TEXT | customer/initial.parquet | 0 |
| first_name | TEXT | True | $1:first_name::TEXT | customer/initial.parquet | 1 |
| LAST_NAME | TEXT | True | $1:LAST_NAME::TEXT | customer/initial.parquet | 2 |
Beachten Sie: Aus Stage-Dateien erkannte Spaltennamen werden standardmäßig case-sensitiv behandelt. Mit dem Parameter IGNORE_CASE => TRUE umgehen Sie das.
Jetzt kennen wir die Struktur der Staged Files – aber wie erstellen wir daraus eine Tabelle? Dafür gibt es eine weitere Funktion.
So nutzen Sie GENERATE_COLUMN_DESCRIPTION
Diese Funktion nimmt die Ausgabe von INFER_SCHEMA als Input und erzeugt daraus eine Spaltenliste. Das Ergebnis lässt sich direkt in einem CREATE TABLE-Statement verwenden. Die Funktion hat zwei Parameter; der zweite legt die gewünschte Formatierung der Ausgabe fest – je nachdem, ob eine Tabelle, eine View oder eine External Table erstellt werden soll. Hier ein kombiniertes Beispiel mit INFER_SCHEMA:
SELECT GENERATE_COLUMN_DESCRIPTION(
ARRAY_AGG(OBJECT_CONSTRUCT(*)), 'table') AS COLUMNS
FROM TABLE (
INFER_SCHEMA(
LOCATION=>'@mystage',
FILE_FORMAT=>'my_parquet_format'
)
);
Und die zugehörige Ausgabe:
+--------------------+
| COLUMN_DESCRIPTION |
|--------------------|
| "id" TEXT, |
| "first_name", TEXT |
| "LAST_NAME" TEXT |
+--------------------+
Diese generierte Spaltenliste übernehmen Sie nun in Ihr CREATE TABLE-Statement.
So erstellen Sie die Tabelle automatisch anhand des erkannten Schemas
GENERATE_COLUMN_DESCRIPTION funktioniert ausgezeichnet. Wenn Sie noch einen Schritt weiter gehen und die Tabelle direkt anhand des erkannten Schemas anlegen möchten, gelingt das mit dem Keyword USING TEMPLATE im CREATE TABLE-Statement. Es nimmt die Ausgabe der Funktion INFER_SCHEMA als Input.
CREATE TABLE mytable
USING TEMPLATE (
SELECT ARRAY_AGG(OBJECT_CONSTRUCT(*))
FROM TABLE(
INFER_SCHEMA(
LOCATION=>'@mystage',
FILE_FORMAT=>'my_parquet_format'
)
));
Ziemlich elegant, oder? Durch das Zusammenspiel mehrerer Funktionen lässt sich die initiale Phase der Ingestion semi-strukturierter Daten automatisieren. Wer noch weiter gehen möchte, kapselt diese Logik in eine Python Stored Procedure, die Parameter wie Dateiformat, Stage und Ziel entgegennimmt.
Nächste Schritte
Nachdem Ihre semi-strukturierten Daten nun in Ihrem Snowflake-Account liegen, wollen Sie auch damit arbeiten. Schauen Sie sich dazu unseren nächsten Beitrag zum Arbeiten mit JSON-Daten an.
Tomáš Sobotík · Senior Data Engineer & Snowflake SME bei Norlys
Tomas ist ein langjähriger Snowflake Data SuperHero und ausgewiesener Snowflake-Experte. Seine Erfahrung in der Datenwelt reicht über mehr als ein Jahrzehnt – als Snowflake Data Engineer, Architect und Admin war er in Projekten unterschiedlichster Branchen und Technologien tätig. Tomas ist ein zentrales Community-Mitglied, das sein Wissen aktiv teilt und andere inspiriert. Außerdem ist er O'Reilly-Instructor und leitet Live-Online-Trainings.