Os dados semiestruturados se tornaram um pilar de muitas entregas na área de dados. Eles oferecem mais flexibilidade do que os dados estruturados — algo que vários workloads precisam, principalmente os que giram em torno de APIs, sensores de IoT ou aplicações web. O JSON virou o "padrão" de fato para comunicação entre APIs. Por não terem a estrutura dos dados relacionais tradicionais, esses formatos trazem desafios na hora de processá-los e trabalhar com eles. Nos próximos posts do blog, quero passar pelos recursos da plataforma de dados Snowflake voltados ao processamento de dados semiestruturados. Vamos percorrer todo o ciclo de vida do dado, da ingestão ao processamento, até a entrega para os consumidores.
O que são dados semiestruturados?
Dados semiestruturados são um tipo de dado que não segue a estrutura tabular dos dados relacionais. Dá para pensar neles como um híbrido entre formatos estruturados e não estruturados. Têm algum nível de organização, mas são mais flexíveis e permitem mais liberdade na forma como são armazenados e usados.
Os elementos de dados semiestruturados podem incluir:
- Pares chave-valor - É a forma mais básica de dados semiestruturados e, na prática, uma estrutura simples em que cada item é composto por uma chave e o valor correspondente.
- Estruturas hierárquicas - Os dados semiestruturados podem ser organizados em elementos aninhados, formando uma hierarquia mais complexa.
- Campos com múltiplos valores - Os dados semiestruturados podem conter campos com vários valores, normalmente conhecidos como arrays.
Exemplo de dados JSON semiestruturados
Vamos usar um documento JSON como exemplo de dados semiestruturados, já que o formato JSON é fácil de ler para humanos. Não existe um formato fixo, e o JSON pode ter a estrutura que melhor atender ao caso de uso. Você pode ver um arquivo JSON de exemplo na imagem abaixo. Ele contém um elemento person com vários pares chave-valor e um array.
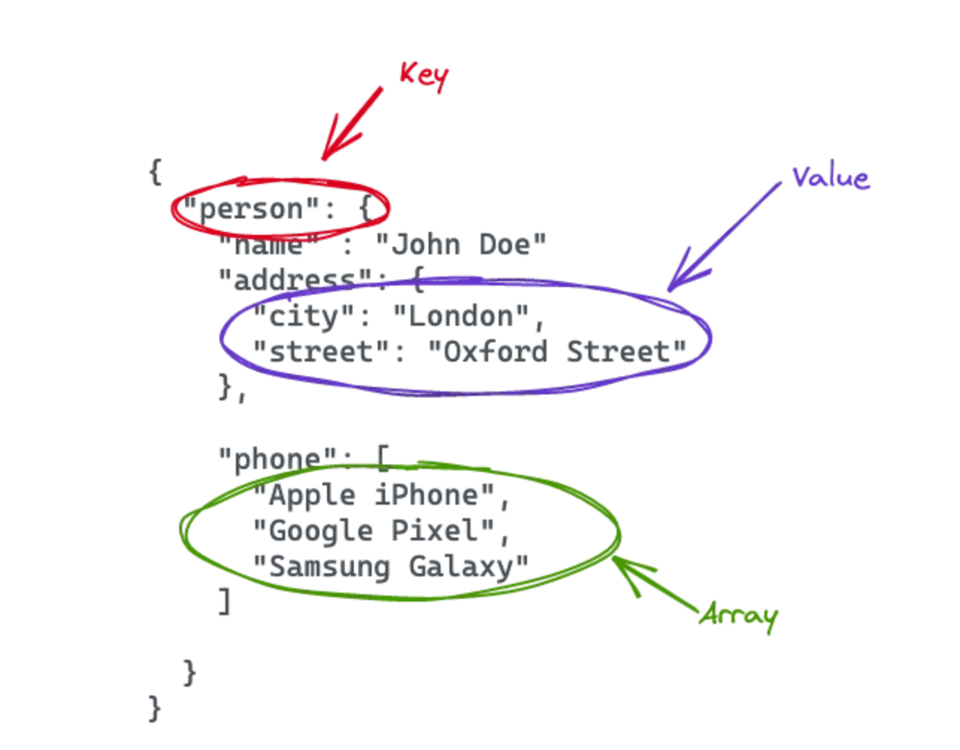
Suporte nativo do Snowflake a formatos de dados semiestruturados
Como o Snowflake lida com dados semiestruturados? Muito bem, eu diria. O suporte é nativo. Isso significa que dá para importar e exportar dados nativamente nos seguintes formatos:
- JSON
- Avro
- ORC
- Parquet
- XML
Para armazenar dados semiestruturados no Snowflake, existem os seguintes tipos nativos — ARRAY, OBJECT, VARIANT.
Vale citar também que você pode trabalhar com dados semiestruturados em tabelas externas, sem precisar carregá-los para dentro do Snowflake. Dá para manter seus arquivos JSON ou Parquet no seu Data Lake externo e ainda assim consumi-los no Snowflake!
Carregando dados semiestruturados no Snowflake
Para relembrar o carregamento de dados no Snowflake, vale a pena conferir nosso post anterior, que cobre todas as opções disponíveis. Aqui embaixo, vou tratar de duas opções específicas para o carregamento de dados semiestruturados.
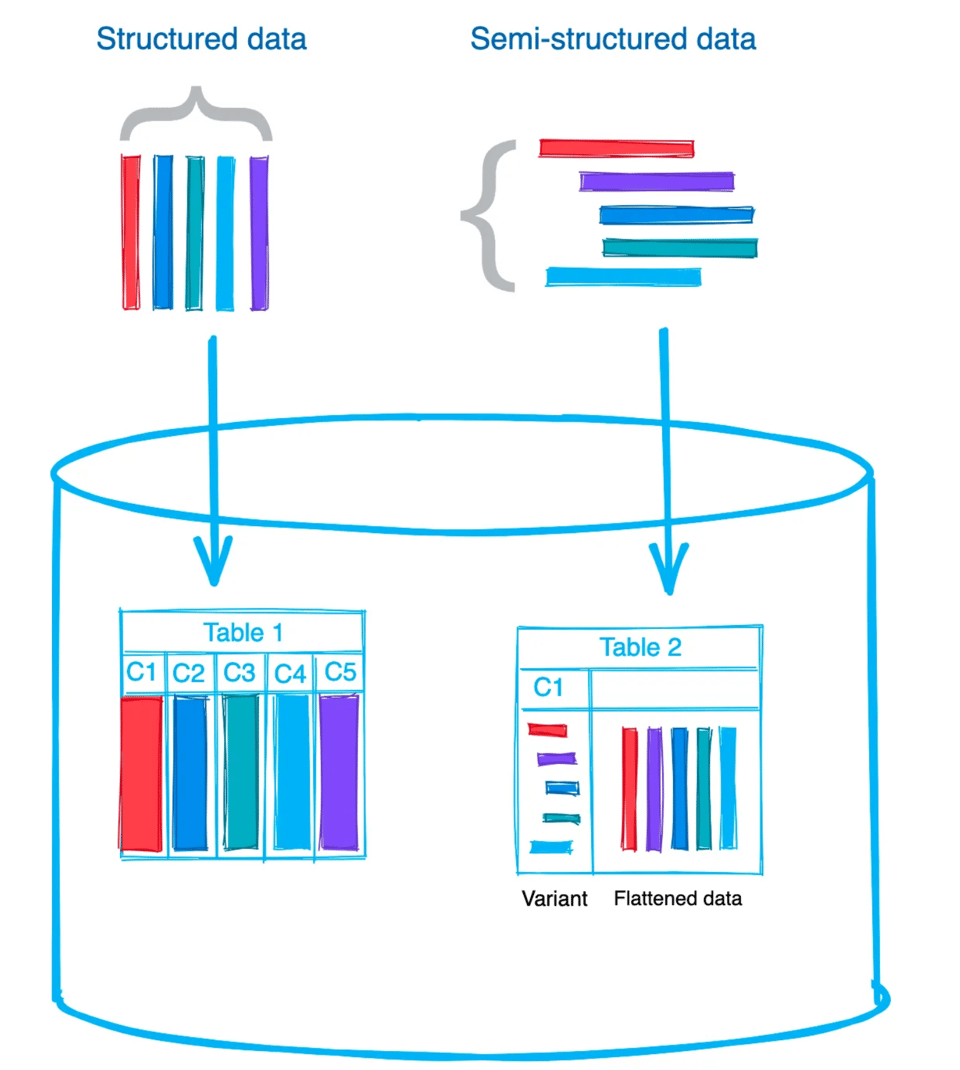
Opção 1: carregar o arquivo inteiro em uma única coluna
Na hora de carregar dados semiestruturados brutos em tabelas do Snowflake, você tem duas opções: armazenar o arquivo/documento inteiro em uma única coluna ou achatar (flatten) os dados e guardar cada valor em uma coluna. Depende do seu caso de uso e de como você pretende trabalhar com os dados depois. Eu costumo carregar os dados no formato bruto, como estão, e armazená-los em uma coluna VARIANT. Em seguida, faço o flattening, porque isso simplifica o processamento posterior. Só fique de olho: um único valor VARIANT é limitado a 128 MB de dados compactados. E se você imaginar um JSON com 128 MB compactados — é um arquivo bem grande. 🙂
Opção 2: gerar um schema com base na estrutura do arquivo
A abordagem anterior funciona para JSONs, mas dados semiestruturados também podem ser armazenados em outros formatos. Em muitos casos, os dados ficam no formato Apache Parquet, principalmente em Data Lakes. Diferente do JSON, que é um formato baseado em texto, o Parquet é binário e otimizado para armazenamento colunar. Ou seja, os dados ficam guardados em colunas, não em linhas, o que torna mais eficiente consultar e analisar grandes volumes.
Uma das principais vantagens do Parquet é conseguir lidar com conjuntos de dados muito grandes de forma eficiente. Como ficam em colunas, os dados podem ser compactados e armazenados de maneira mais enxuta, o que reduz o espaço necessário e melhora o desempenho das leituras.
Outra diferença entre JSON e Parquet está na forma como tratam os tipos de dados. O JSON é fracamente tipado, ou seja, não impõe tipos rígidos a cada campo. Já o Parquet tem um schema bem definido e suporta diversos tipos, como inteiros, números de ponto flutuante, strings e timestamps. Isso facilita trabalhar com os dados de forma consistente e garante que sejam armazenados e processados com precisão.
Essas diferenças exigem abordagens distintas na hora da ingestão. Como o Parquet tem um schema bem definido, você precisa especificá-lo durante a importação. Se já tentou carregar dados Parquet no Snowflake, talvez tenha enfrentado o processo demorado de definir o schema do arquivo. Você também precisa criar uma tabela de destino com exatamente o mesmo schema. Se o arquivo tem dezenas ou centenas de colunas, dá para passar horas nessa tarefa.
Só relembrando, para quem ainda não sabe como carregar dados Parquet no Snowflake, dá uma olhada no código a seguir. Repare que, como parte do comando copy, você precisa informar os atributos do arquivo junto com seus tipos de dados.
COPY INTO <table_name>
FROM (
SELECT
$1:column1::<target_data_type>,
$1:column2::<target_data_type>,
$1:column3::<target_data_type>
FROM <my_stage>.<my_file.parquet>
);
``
O $1 na consulta SELECT se refere à única coluna onde todos os dados do Parquet ficam armazenados.
Antes de carregar os dados no Snowflake, é preciso primeiro criar uma tabela de destino com o schema exigido e, em seguida, escrever a instrução COPY listando todas as colunas, como no exemplo acima.
Considerações sobre armazenar dados semiestruturados em uma única coluna vs. achatar a estrutura aninhada
Você deve estar se perguntando: quando usar cada opção?
Se não tem certeza de como os dados serão usados no futuro, armazená-los em uma única coluna VARIANT é um bom ponto de partida. De acordo com a documentação do Snowflake, você terá um desempenho de consulta parecido com o de uma estrutura achatada, desde que o formato semiestruturado use tipos nativos como strings e inteiros. Os custos de armazenamento também ficam parecidos.
Se estiver trabalhando com datas, timestamps ou arrays, o Snowflake afirma que você terá um melhor query pruning ao armazená-los em colunas separadas.
Guardar separadamente os campos/colunas acessados com frequência melhora a experiência do usuário final, já que os dados ficam mais simples de manipular e eliminam a necessidade de o usuário saber fazer o parsing de dados JSON.
Detecção automática de schema e criação de tabela
Em vez de listar explicitamente todas as colunas necessárias, o Snowflake automatizou esse processo. Agora você pode usar algumas funções nativas para ler o schema do arquivo e montar o comando COPY. Também existe uma função para automatizar a criação da tabela. Posso confirmar que isso economiza horas de trabalho, porque já mexi com arquivos Parquet bem grandes (mais de 100 colunas) em que precisei fazer tudo na mão. Vamos ver como usar essas funções e automatizar o processo inteiro.
Como usar INFER_SCHEMA
A função INFER_SCHEMA detecta automaticamente o schema dos metadados em arquivos no stage que contêm dados semiestruturados e retorna as definições das colunas. Hoje, essa função funciona com arquivos Apache Parquet, Apache Avro e ORC.
É uma função de tabela, então precisa ser envolvida pela palavra-chave TABLE():
SELECT *
FROM TABLE(
INFER_SCHEMA(
LOCATION=>'@mystage',
FILE_FORMAT=>'my_parquet_format'
)
);
A saída fica assim:
| COLUMN_NAME | TYPE | NULLABLE | EXPRESSION | FILENAMES | ORDER_ID |
|---|---|---|---|---|---|
| id | TEXT | True | $1:id::TEXT | customer/initial.parquet | 0 |
| first_name | TEXT | True | $1:first_name::TEXT | customer/initial.parquet | 1 |
| LAST_NAME | TEXT | True | $1:LAST_NAME::TEXT | customer/initial.parquet | 2 |
Atenção: por padrão, os nomes de colunas detectados nos arquivos em stage são tratados como case-sensitive. Dá para contornar isso com o parâmetro IGNORE_CASE => TRUE.
Agora já conhecemos a estrutura dos arquivos em stage, mas como seguir em frente e criar uma tabela com base nesse schema? Temos outra função para isso.
Como usar GENERATE_COLUMN_DESCRIPTION
Essa função recebe como entrada a saída da função INFER_SCHEMA e gera uma lista de colunas. Dá para usar esse resultado em uma instrução CREATE TABLE. A função tem dois parâmetros — o segundo define o tipo de formatação que queremos na saída: se vamos criar uma tabela, uma view ou uma tabela externa. Aqui está um exemplo combinado com o INFER_SCHEMA:
SELECT GENERATE_COLUMN_DESCRIPTION(
ARRAY_AGG(OBJECT_CONSTRUCT(*)), 'table') AS COLUMNS
FROM TABLE (
INFER_SCHEMA(
LOCATION=>'@mystage',
FILE_FORMAT=>'my_parquet_format'
)
);
E a saída gerada:
+--------------------+
| COLUMN_DESCRIPTION |
|--------------------|
| "id" TEXT, |
| "first_name", TEXT |
| "LAST_NAME" TEXT |
+--------------------+
Agora é só pegar a lista de colunas gerada e usar na sua instrução CREATE TABLE.
Como criar a tabela automaticamente com base no schema detectado
Usar o GENERATE_COLUMN_DESCRIPTION funciona muito bem, mas, se você quiser automatizar ainda mais e criar a tabela na hora com base no schema detectado, dá para fazer isso com a palavra-chave USING TEMPLATE na instrução CREATE TABLE. Essa palavra-chave recebe como entrada a saída da função INFER_SCHEMA.
CREATE TABLE mytable
USING TEMPLATE (
SELECT ARRAY_AGG(OBJECT_CONSTRUCT(*))
FROM TABLE(
INFER_SCHEMA(
LOCATION=>'@mystage',
FILE_FORMAT=>'my_parquet_format'
)
));
Bem bacana, né? Combinando algumas funções, conseguimos automatizar a fase inicial da ingestão de dados semiestruturados. Se quiser ir além, dá até para encapsular essa lógica em uma stored procedure em Python que receba parâmetros como formato do arquivo, stage e destino.
Próximos passos
Agora que você já tem seus dados semiestruturados carregados na sua conta Snowflake, é hora de começar a trabalhar com eles. Não deixe de conferir nosso próximo post sobre como trabalhar com dados JSON.
Tomáš Sobotík·Senior Data Engineer & Snowflake SME na Norlys
Tomas é um veterano Snowflake Data SuperHero e especialista geral em Snowflake. Sua ampla experiência no mundo dos dados já passa de uma década, período em que atuou como engenheiro de dados, arquiteto e administrador Snowflake em diversos projetos, setores e tecnologias. Tomas é um membro ativo da comunidade, compartilha sua expertise com frequência e inspira outras pessoas. Também é instrutor da O'Reilly, conduzindo treinamentos ao vivo online.