I dati semi-strutturati sono ormai uno dei pilastri di molti progetti data. Offrono maggiore flessibilità rispetto ai dati strutturati, una caratteristica spesso indispensabile per numerosi workloads, in particolare quelli costruiti attorno ad API, sensori IoT o applicazioni web. JSON è di fatto lo "standard" per la comunicazione tra API. Non avendo la struttura dei dati relazionali tradizionali, questi formati pongono nuove sfide in fase di elaborazione e gestione. Nei prossimi articoli vorrei approfondire le funzionalità della piattaforma Snowflake dedicate all'elaborazione dei dati semi-strutturati, coprendo l'intero ciclo di vita del dato: dall'ingestion alla trasformazione, fino alla messa a disposizione dei consumatori.
Cosa sono i dati semi-strutturati?
I dati semi-strutturati sono dati che non seguono la struttura tabellare tipica dei dati relazionali. Si possono considerare un ibrido tra i formati strutturati e quelli non strutturati: hanno un certo grado di organizzazione, ma lasciano molta più libertà nel modo in cui vengono archiviati e utilizzati.
Tra gli elementi dei dati semi-strutturati troviamo:
- Coppie chiave-valore - È la forma più elementare di dato semi-strutturato: una struttura semplice in cui ogni elemento è composto da una chiave e dal valore corrispondente.
- Strutture gerarchiche - I dati semi-strutturati possono essere organizzati in elementi annidati, dando vita a una gerarchia più complessa.
- Campi multi-valore - I dati semi-strutturati possono contenere campi con più valori, comunemente noti come array.
Esempio di dato JSON semi-strutturato
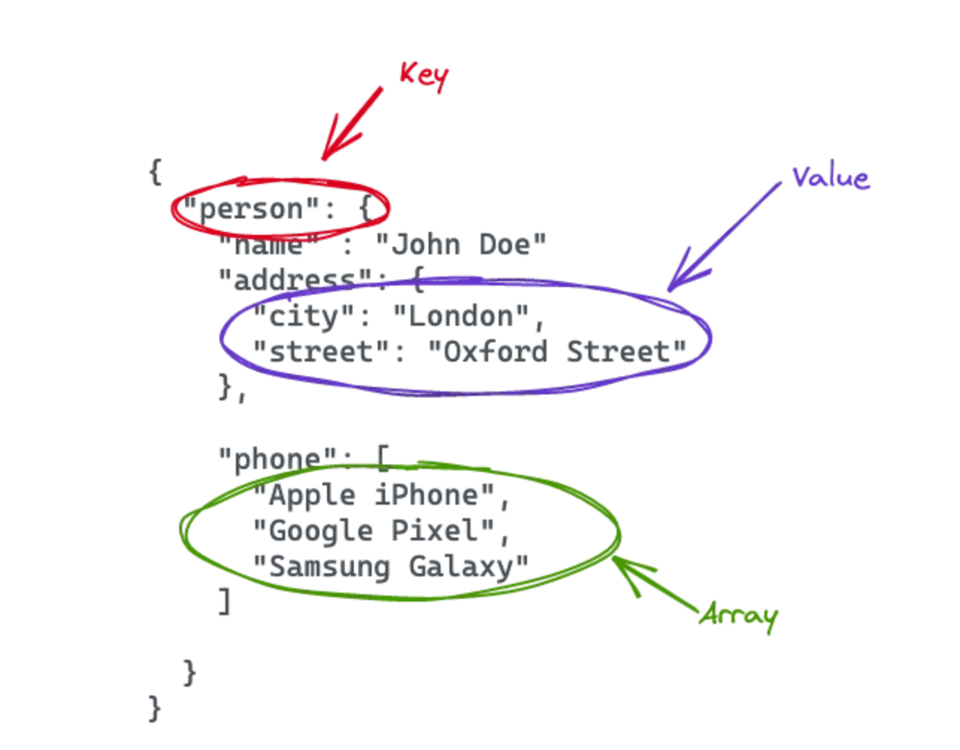
Prendiamo come esempio un documento JSON, dato che il formato JSON è di facile lettura anche per l'occhio umano. Non esiste un formato fisso: il JSON può assumere la struttura più adatta alle esigenze del caso d'uso. Nell'immagine qui sotto è riportato un file JSON di esempio, con un elemento person che contiene diverse coppie chiave-valore e un array.
Il supporto nativo di Snowflake per i formati di dati semi-strutturati
Come si comporta Snowflake con i dati semi-strutturati? Direi piuttosto bene. Snowflake offre un supporto nativo per questo tipo di dati, il che significa che puoi importare ed esportare in modo nativo i seguenti formati:
- JSON
- Avro
- ORC
- Parquet
- XML
Per l'archiviazione dei dati semi-strutturati in Snowflake sono disponibili i seguenti tipi di dato nativi: ARRAY, OBJECT, VARIANT.
Vale anche la pena ricordare che puoi lavorare con dati semi-strutturati tramite tabelle esterne, senza doverli caricare in Snowflake. Puoi tenere i tuoi file JSON o Parquet nel tuo Data Lake esterno e continuare a utilizzarli da Snowflake!
Caricare dati semi-strutturati in Snowflake
Per un ripasso sul data loading in Snowflake, ti consigliamo di leggere il nostro articolo precedente, che illustra tutte le opzioni disponibili. Qui di seguito mi concentro su due opzioni specifiche per il caricamento dei dati semi-strutturati.
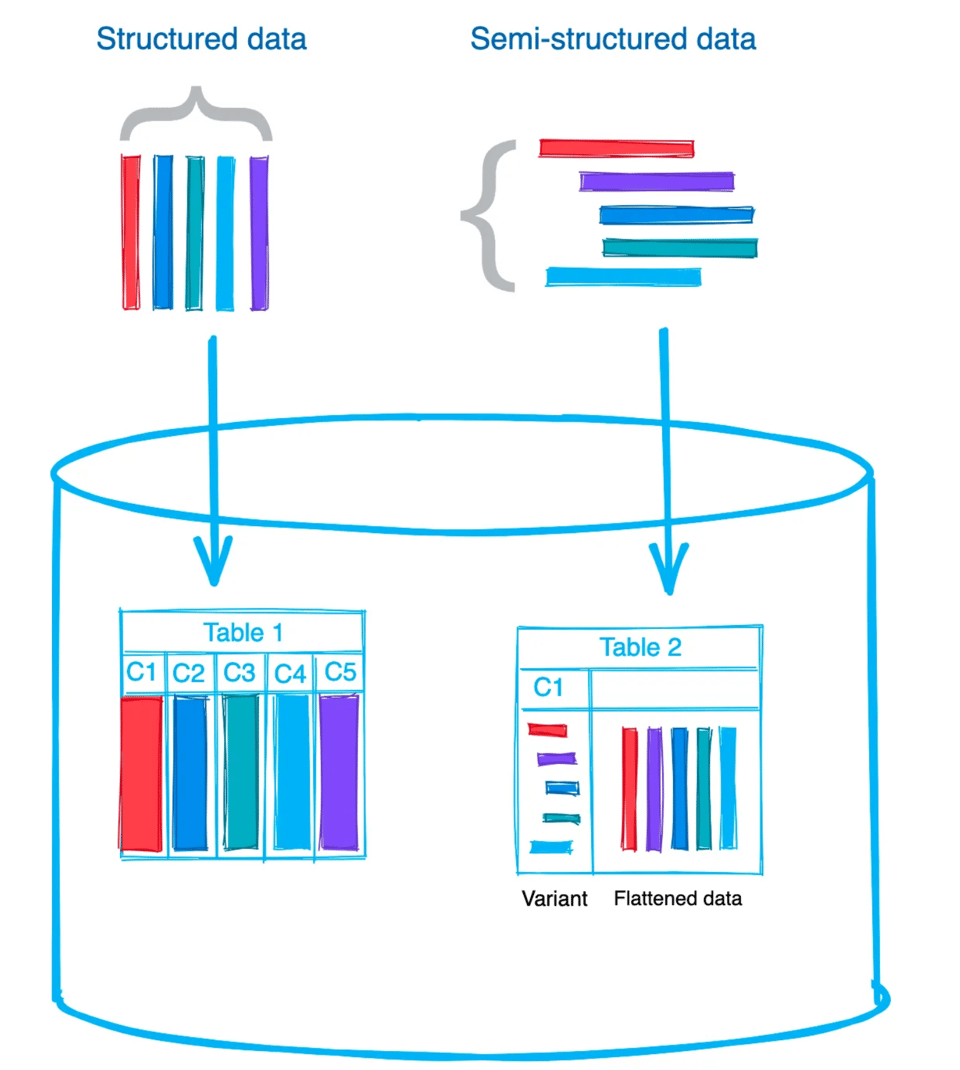
Opzione 1: caricare l'intero file in un'unica colonna
Per caricare i dati semi-strutturati grezzi nelle tabelle Snowflake hai due possibilità: memorizzare l'intero file/documento in un'unica colonna, oppure appiattire i dati e salvare i singoli valori in colonne separate. La scelta dipende dal tuo caso d'uso e da come intendi utilizzare i dati in seguito. Personalmente carico quasi sempre i dati in formato grezzo, così come sono, in una colonna VARIANT, per poi procedere all'appiattimento in un secondo momento: in questo modo le elaborazioni successive risultano più semplici. Attenzione però: un singolo valore VARIANT è limitato a 128 MB di dati compressi. E se pensi a un file JSON di 128 MB compressi, parliamo di un file davvero enorme. 🙂
Opzione 2: generare uno schema in base alla struttura del file
L'approccio precedente funziona bene con i JSON, ma i dati semi-strutturati possono essere archiviati anche in altri formati. Capita spesso di trovare dati salvati in formato Apache Parquet, soprattutto nei Data Lake. A differenza di JSON, che è un formato testuale, Parquet è un formato binario ottimizzato per l'archiviazione colonnare: i dati vengono memorizzati per colonne anziché per righe, risultando molto più efficienti nell'interrogazione e nell'analisi di grandi dataset.
Uno dei principali vantaggi di Parquet è la capacità di gestire dataset di grandi dimensioni in modo efficiente. Dato che i dati sono memorizzati in colonne, possono essere compressi e archiviati in forma più compatta, riducendo lo spazio occupato e migliorando le prestazioni in lettura.
Un'altra differenza tra JSON e Parquet riguarda la gestione dei tipi di dato. JSON è un formato a tipizzazione debole: non impone tipi rigidi per ciascun campo. Parquet, al contrario, ha uno schema ben definito e supporta diversi tipi di dato, tra cui interi, numeri in virgola mobile, stringhe e timestamp. Questo semplifica il lavoro coerente sui dati e garantisce che vengano archiviati ed elaborati in modo accurato.
Queste differenze richiedono approcci diversi anche in fase di ingestion. Poiché Parquet ha uno schema ben definito, devi specificarlo al momento dell'importazione. Se hai mai provato a caricare dati Parquet in Snowflake, probabilmente ti sei scontrato con il processo lungo e laborioso della definizione dello schema del file. Devi inoltre creare una tabella di destinazione con esattamente lo stesso schema. Se il file ha decine o centinaia di colonne, l'operazione può richiedere ore.
Per chi non sapesse come caricare dati Parquet in Snowflake, ecco il codice di riferimento. Come puoi notare, nel comando COPY è necessario indicare gli attributi del file insieme al rispettivo tipo di dato.
COPY INTO <table_name>
FROM (
SELECT
$1:column1::<target_data_type>,
$1:column2::<target_data_type>,
$1:column3::<target_data_type>
FROM <my_stage>.<my_file.parquet>
);
``
$1 nella query SELECT fa riferimento all'unica colonna in cui sono memorizzati tutti i dati Parquet.
Prima di poter caricare i dati in Snowflake, devi quindi creare una tabella di destinazione con lo schema richiesto e poi scrivere lo statement COPY elencando tutte le colonne, come nell'esempio sopra.
Quando archiviare i dati semi-strutturati in una singola colonna e quando appiattire la struttura annidata
A questo punto ti starai chiedendo: quali criteri usare per scegliere tra le due opzioni?
Se non sai ancora come utilizzerai i dati in futuro, archiviarli in una singola colonna VARIANT è un ottimo punto di partenza. Secondo la documentazione Snowflake, otterrai prestazioni di query analoghe a quelle di una struttura appiattita, a patto che il formato semi-strutturato utilizzi tipi nativi come stringhe e interi. Anche i costi di archiviazione saranno simili.
Se invece lavori con date, timestamp o array, Snowflake dichiara che otterrai un query pruning migliore archiviandoli in colonne separate.
Memorizzare separatamente le colonne o i campi a cui si accede di frequente migliora inoltre l'esperienza degli utenti finali: i dati diventano più immediati da utilizzare e non è più necessario sapere come interpretare i dati JSON.
Rilevamento automatico dello schema e creazione della tabella
Invece di elencare manualmente tutte le colonne necessarie, Snowflake automatizza il processo. Oggi puoi usare alcune funzioni integrate per leggere lo schema dal file e preparare il comando COPY. Esiste anche una funzione per automatizzare la creazione della tabella. Posso confermare che si tratta di un approccio che fa risparmiare ore di lavoro: in passato ho dovuto gestire manualmente file Parquet di grandi dimensioni con oltre 100 colonne. Vediamo come utilizzare queste funzioni per automatizzare l'intero processo.
Come usare INFER_SCHEMA
La funzione INFER_SCHEMA rileva automaticamente lo schema dei metadati dei file in stage che contengono dati semi-strutturati e restituisce le definizioni delle colonne. Attualmente è compatibile con file Apache Parquet, Apache Avro e ORC.
Si tratta di una table function, quindi va racchiusa nella parola chiave TABLE():
SELECT *
FROM TABLE(
INFER_SCHEMA(
LOCATION=>'@mystage',
FILE_FORMAT=>'my_parquet_format'
)
);
L'output sarà simile a questo:
| COLUMN_NAME | TYPE | NULLABLE | EXPRESSION | FILENAMES | ORDER_ID |
|---|---|---|---|---|---|
| id | TEXT | True | $1:id::TEXT | customer/initial.parquet | 0 |
| first_name | TEXT | True | $1:first_name::TEXT | customer/initial.parquet | 1 |
| LAST_NAME | TEXT | True | $1:LAST_NAME::TEXT | customer/initial.parquet | 2 |
Tieni presente che, per impostazione predefinita, i nomi delle colonne rilevati dai file in stage vengono trattati come case-sensitive. Puoi modificare questo comportamento tramite il parametro IGNORE_CASE => TRUE.
Ora conosciamo la struttura dei file in stage, ma come procedere per creare una tabella basata su quello schema? Anche in questo caso ci viene in aiuto una funzione dedicata.
Come usare GENERATE_COLUMN_DESCRIPTION
Questa funzione accetta come input l'output di INFER_SCHEMA e genera un elenco di colonne, che possiamo riutilizzare in uno statement CREATE TABLE. La funzione prevede due parametri: il secondo definisce il tipo di formattazione dell'output, ovvero se stiamo creando una tabella, una view o una tabella esterna. Ecco un esempio combinato con INFER_SCHEMA:
SELECT GENERATE_COLUMN_DESCRIPTION(
ARRAY_AGG(OBJECT_CONSTRUCT(*)), 'table') AS COLUMNS
FROM TABLE (
INFER_SCHEMA(
LOCATION=>'@mystage',
FILE_FORMAT=>'my_parquet_format'
)
);
E il relativo output:
+--------------------+
| COLUMN_DESCRIPTION |
|--------------------|
| "id" TEXT, |
| "first_name", TEXT |
| "LAST_NAME" TEXT |
+--------------------+
A questo punto puoi inserire l'elenco di colonne generato all'interno del tuo statement CREATE TABLE.
Come creare automaticamente la tabella in base allo schema rilevato
Usare GENERATE_COLUMN_DESCRIPTION funziona benissimo, ma se vuoi spingere l'automazione ancora oltre e creare la tabella in modo automatico a partire dallo schema rilevato, puoi farlo grazie alla parola chiave USING TEMPLATE nello statement CREATE TABLE. Questa parola chiave accetta come input l'output della funzione INFER_SCHEMA.
CREATE TABLE mytable
USING TEMPLATE (
SELECT ARRAY_AGG(OBJECT_CONSTRUCT(*))
FROM TABLE(
INFER_SCHEMA(
LOCATION=>'@mystage',
FILE_FORMAT=>'my_parquet_format'
)
));
Niente male, vero? Combinando queste funzioni riusciamo ad automatizzare la fase iniziale dell'ingestion dei dati semi-strutturati. Se vuoi spingerti ancora oltre, puoi incapsulare questa logica in una stored procedure Python che riceva come parametri il formato del file, lo stage e la destinazione.
Prossimi passi
Ora che hai caricato i tuoi dati semi-strutturati nel tuo account Snowflake, vorrai iniziare a lavorarci. Non perderti il nostro prossimo articolo su come lavorare con i dati JSON.
Tomáš Sobotík·Senior Data Engineer & Snowflake SME presso Norlys
Tomas è da tempo un Snowflake Data SuperHero e un punto di riferimento sulla piattaforma Snowflake. La sua esperienza nel mondo dei dati abbraccia oltre un decennio, durante il quale ha ricoperto i ruoli di Snowflake data engineer, architect e admin in progetti che spaziano tra settori e tecnologie diversi. Tomas è un membro attivo della community, condivide costantemente la propria expertise e ama ispirare gli altri. È inoltre istruttore O'Reilly e tiene sessioni di formazione live online.