Les données semi-structurées sont devenues un pilier de nombreux projets data. Elles offrent davantage de flexibilité que les données structurées — une souplesse souvent indispensable à de nombreux workloads, en particulier ceux qui reposent sur des API, des capteurs IoT ou des applications web. JSON s'est imposé comme le standard de fait pour la communication entre API. Le fait de ne pas suivre la structure des données relationnelles traditionnelles soulève toutefois des défis quant au traitement et à l'exploitation de ces structures. Dans les prochains articles, je vous propose de passer en revue les capacités de la plateforme Snowflake pour le traitement des données semi-structurées. Couvrons l'ensemble du cycle de vie des données, depuis l'ingestion jusqu'à la mise à disposition auprès des consommateurs, en passant par le traitement.
Qu'est-ce qu'une donnée semi-structurée ?
Les données semi-structurées ne suivent pas la structure tabulaire des données relationnelles. On peut les voir comme un hybride entre les formats structurés et les données non structurées. Elles présentent un certain niveau d'organisation, tout en laissant une plus grande latitude quant à la manière dont les données sont stockées et exploitées.
Les éléments des données semi-structurées peuvent inclure :
- Paires clé-valeur — La forme la plus élémentaire de données semi-structurées : une structure simple où chaque élément se compose d'une clé et de la valeur correspondante.
- Structures hiérarchiques — Les données semi-structurées peuvent être organisées en éléments imbriqués, offrant une hiérarchie plus complexe.
- Champs à valeurs multiples — Les données semi-structurées peuvent contenir des champs comportant plusieurs valeurs, communément appelés tableaux (arrays).
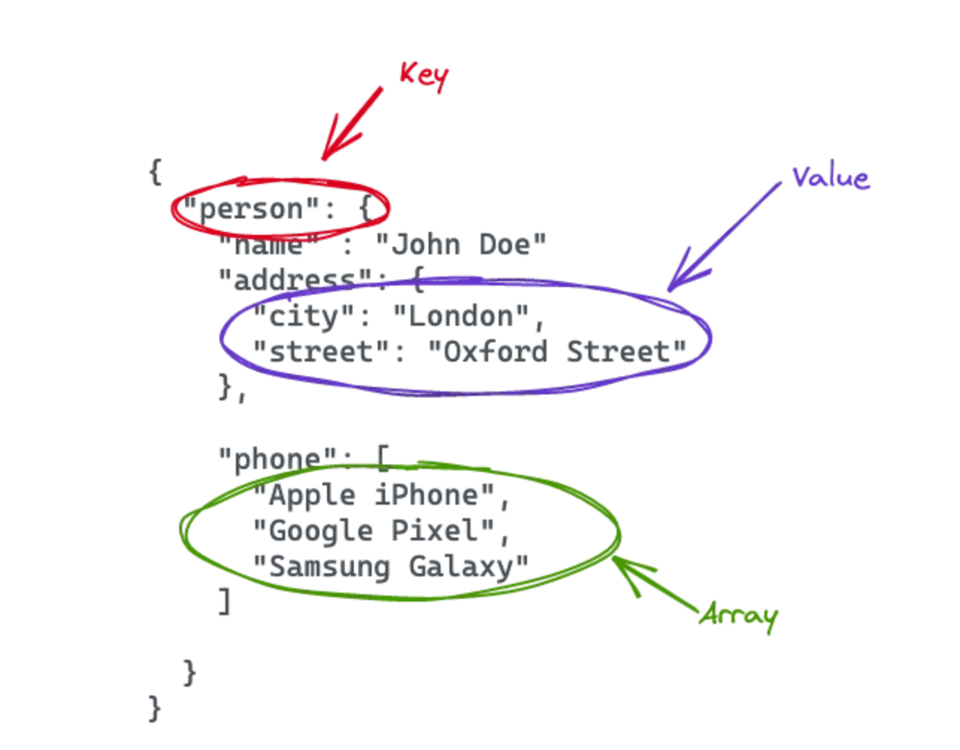
Exemple de données semi-structurées au format JSON
Prenons un document JSON comme exemple, car ce format se lit facilement. Il n'existe aucun format figé : le JSON peut adopter la structure la mieux adaptée au cas d'usage. Vous trouverez un exemple de fichier JSON dans l'image ci-dessous. Le JSON contient un élément person avec plusieurs paires clé-valeur et un tableau.
La prise en charge native des formats semi-structurés par Snowflake
Comment Snowflake gère-t-il les données semi-structurées ? Plutôt bien, dirais-je. La prise en charge est native. Vous pouvez ainsi importer et exporter nativement des données dans les formats suivants :
- JSON
- Avro
- ORC
- Parquet
- XML
Pour le stockage des données semi-structurées dans Snowflake, vous disposez des types natifs suivants : ARRAY, OBJECT et VARIANT.
À noter également : vous pouvez exploiter des données semi-structurées via des tables externes, sans les charger dans Snowflake. Vos fichiers JSON ou Parquet peuvent rester dans votre Data Lake externe, tout en restant accessibles depuis Snowflake.
Charger des données semi-structurées dans Snowflake
Pour une piqûre de rappel sur le chargement de données dans Snowflake, consultez notre article précédent, qui passe en revue toutes les options disponibles. Je détaille ci-dessous deux options spécifiques au chargement de données semi-structurées.
Option 1 : charger l'intégralité du fichier dans une seule colonne
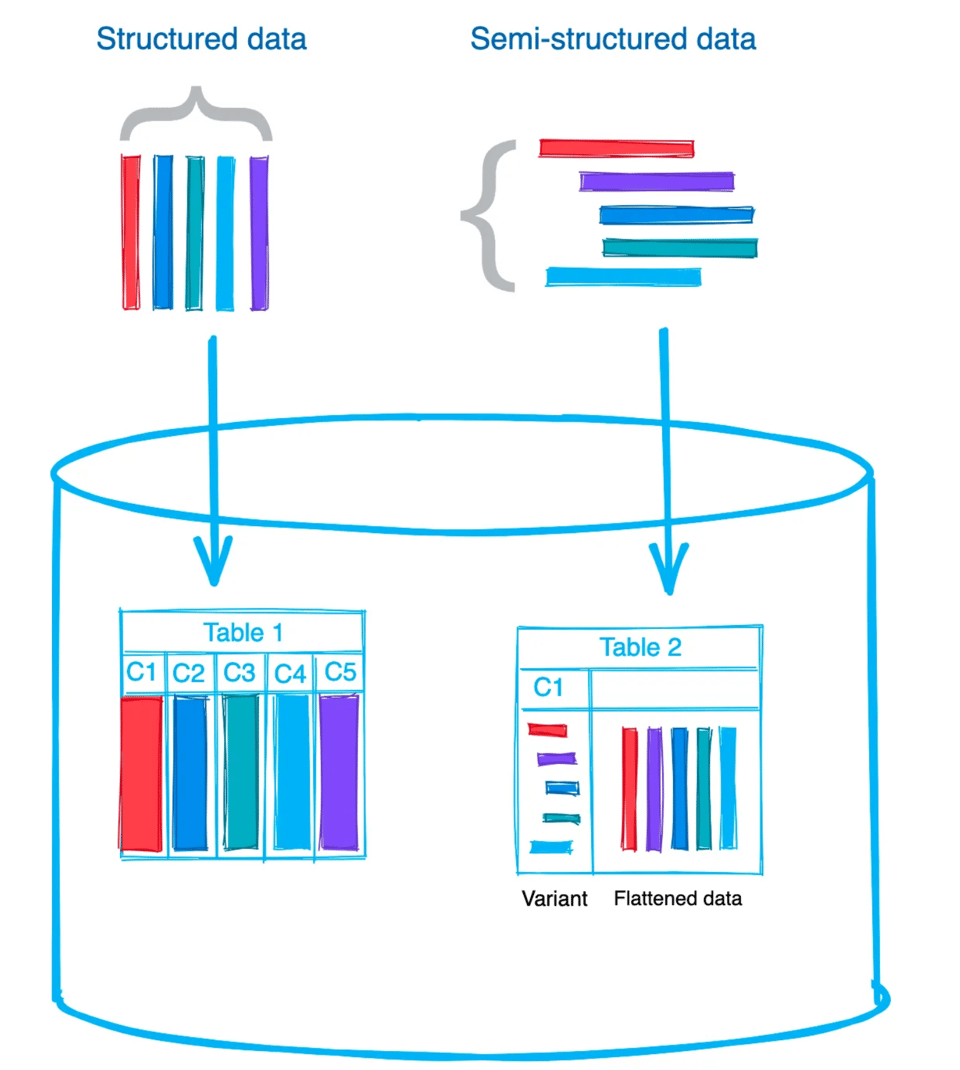
Pour charger des données brutes semi-structurées dans des tables Snowflake, vous avez deux options : stocker l'intégralité du fichier ou du document dans une seule colonne, ou aplatir les données et stocker chaque valeur dans sa propre colonne. Le choix dépend de votre cas d'usage et de la manière dont vous souhaitez exploiter les données par la suite. Personnellement, je charge généralement les données telles quelles, au format brut, dans une colonne VARIANT. Je procède ensuite à l'aplatissement, ce qui simplifie le traitement ultérieur. À garder en tête : une seule valeur VARIANT est limitée à 128 Mo de données compressées. Un fichier JSON de 128 Mo compressé représente déjà un volume conséquent. 🙂
Option 2 : générer un schéma à partir de la structure du fichier
L'approche précédente fonctionne pour les JSON, mais les données semi-structurées peuvent aussi être stockées dans d'autres formats. On rencontre fréquemment des données au format Apache Parquet, en particulier dans les Data Lakes. Contrairement à JSON, qui est un format texte, Parquet est un format binaire optimisé pour le stockage en colonnes. Les données sont stockées par colonnes plutôt que par lignes, ce qui le rend plus efficace pour interroger et analyser de grands jeux de données.
L'un des principaux atouts de Parquet est sa capacité à gérer efficacement de très grands volumes de données. Comme les données sont stockées en colonnes, elles peuvent être compressées sous une forme plus compacte, ce qui réduit le volume de stockage requis et améliore les performances en lecture.
Autre différence entre JSON et Parquet : la gestion des types de données. JSON est un format faiblement typé, qui n'impose pas de types stricts à chaque champ. Parquet, lui, dispose d'un schéma bien défini et prend en charge divers types : entiers, nombres à virgule flottante, chaînes de caractères, horodatages, etc. Cela facilite l'exploitation cohérente des données et garantit qu'elles sont stockées et traitées avec précision.
Ces différences imposent des approches distinctes pour l'ingestion. Comme Parquet possède un schéma bien défini, il faut le déclarer lors de l'import. Si vous avez déjà tenté de charger des données Parquet dans Snowflake, vous avez peut-être été confronté au processus chronophage de définition du schéma. Vous devez également créer une table cible avec exactement le même schéma. Si le fichier comporte des dizaines, voire des centaines de colonnes, vous risquez d'y passer des heures.
Pour rappel, à l'intention de celles et ceux qui ne sauraient pas comment charger des données Parquet dans Snowflake, voici le code à utiliser. Vous constaterez que, dans la commande COPY, vous devez lister les attributs du fichier avec leur type de données.
COPY INTO <table_name>
FROM (
SELECT
$1:column1::<target_data_type>,
$1:column2::<target_data_type>,
$1:column3::<target_data_type>
FROM <my_stage>.<my_file.parquet>
);
``
Dans la requête SELECT, $1 fait référence à la colonne unique où sont stockées toutes les données Parquet.
Avant de charger les données dans Snowflake, vous devez d'abord créer une table cible avec le schéma requis, puis rédiger l'instruction COPY en listant toutes les colonnes, comme dans l'exemple ci-dessus.
Stocker les données semi-structurées dans une seule colonne ou aplatir la structure imbriquée : quels critères de choix ?
Vous vous demandez sans doute quels critères retenir pour choisir l'une ou l'autre option.
Si vous n'êtes pas certain de l'usage futur des données, les stocker dans une seule colonne VARIANT est un bon point de départ. Selon la documentation Snowflake, vous obtiendrez des performances de requête comparables à celles d'une structure aplatie si le format semi-structuré s'appuie sur des types natifs tels que chaînes de caractères et entiers. Les coûts de stockage seront eux aussi similaires.
Si vous travaillez avec des dates, des horodatages ou des tableaux, Snowflake indique que vous obtiendrez un meilleur query pruning en les stockant dans des colonnes séparées.
Stocker séparément les colonnes ou les champs fréquemment consultés améliore l'expérience de l'utilisateur final : les données deviennent plus simples à manipuler, et il n'est plus nécessaire de savoir parser du JSON.
Détection automatique du schéma et création de table
Plutôt que d'énumérer explicitement toutes les colonnes requises, Snowflake a automatisé ce processus. Vous pouvez désormais utiliser plusieurs fonctions intégrées pour lire le schéma à partir du fichier et préparer la commande COPY. Une autre fonction permet d'automatiser la création de la table. Je peux confirmer que cela peut vous faire gagner des heures de travail : j'ai manipulé de très gros fichiers Parquet (plus de 100 colonnes) où tout devait être fait manuellement. Voyons comment utiliser ces fonctions et automatiser l'ensemble du processus.
Comment utiliser INFER_SCHEMA
La fonction INFER_SCHEMA détecte automatiquement le schéma des métadonnées dans les fichiers en stage qui contiennent des données semi-structurées, et renvoie les définitions de colonnes. Pour l'heure, elle prend en charge les fichiers Apache Parquet, Apache Avro et ORC.
Il s'agit d'une fonction de table : elle doit donc être encapsulée par le mot-clé TABLE() :
SELECT *
FROM TABLE(
INFER_SCHEMA(
LOCATION=>'@mystage',
FILE_FORMAT=>'my_parquet_format'
)
);
Le résultat ressemble alors à ceci :
| COLUMN_NAME | TYPE | NULLABLE | EXPRESSION | FILENAMES | ORDER_ID |
|---|---|---|---|---|---|
| id | TEXT | True | $1:id::TEXT | customer/initial.parquet | 0 |
| first_name | TEXT | True | $1:first_name::TEXT | customer/initial.parquet | 1 |
| LAST_NAME | TEXT | True | $1:LAST_NAME::TEXT | customer/initial.parquet | 2 |
Attention : par défaut, les noms de colonnes détectés dans les fichiers en stage sont sensibles à la casse. Le paramètre IGNORE_CASE => TRUE permet de modifier ce comportement.
Nous connaissons à présent la structure des fichiers en stage. Reste à créer une table à partir de ce schéma : une autre fonction est prévue à cet effet.
Comment utiliser GENERATE_COLUMN_DESCRIPTION
Cette fonction prend en entrée la sortie de INFER_SCHEMA et génère une liste de colonnes. Le résultat peut ensuite être utilisé dans une instruction CREATE TABLE. La fonction comporte deux paramètres, le second servant à définir le formatage souhaité en sortie selon que l'on crée une table, une vue ou une table externe. Voici un exemple combiné avec INFER_SCHEMA :
SELECT GENERATE_COLUMN_DESCRIPTION(
ARRAY_AGG(OBJECT_CONSTRUCT(*)), 'table') AS COLUMNS
FROM TABLE (
INFER_SCHEMA(
LOCATION=>'@mystage',
FILE_FORMAT=>'my_parquet_format'
)
);
Et le résultat obtenu :
+--------------------+
| COLUMN_DESCRIPTION |
|--------------------|
| "id" TEXT, |
| "first_name", TEXT |
| "LAST_NAME" TEXT |
+--------------------+
Vous pouvez alors reprendre la liste de colonnes générée dans votre instruction CREATE TABLE.
Créer automatiquement la table à partir du schéma détecté
GENERATE_COLUMN_DESCRIPTION fonctionne très bien, mais pour pousser l'automatisation plus loin et créer la table directement à partir du schéma détecté, vous pouvez recourir au mot-clé USING TEMPLATE dans l'instruction CREATE TABLE. Ce mot-clé accepte en entrée la sortie de INFER_SCHEMA.
CREATE TABLE mytable
USING TEMPLATE (
SELECT ARRAY_AGG(OBJECT_CONSTRUCT(*))
FROM TABLE(
INFER_SCHEMA(
LOCATION=>'@mystage',
FILE_FORMAT=>'my_parquet_format'
)
));
Plutôt élégant, non ? En combinant plusieurs fonctions, nous automatisons la phase initiale d'ingestion des données semi-structurées. Pour aller plus loin, vous pouvez même encapsuler cette logique dans une procédure stockée Python prenant en paramètres le format de fichier, le stage et la cible.
Et maintenant ?
Vos données semi-structurées sont chargées dans votre compte Snowflake : il s'agit maintenant de les exploiter. Ne manquez pas notre prochain article consacré à l'exploitation des données JSON.
Tomáš Sobotík · Senior Data Engineer & Snowflake SME chez Norlys
Tomas est un Snowflake Data SuperHero de longue date et un expert reconnu de Snowflake. Son expérience approfondie du monde de la data couvre plus d'une décennie, durant laquelle il a occupé les rôles de data engineer, d'architecte et d'administrateur Snowflake sur divers projets, dans des secteurs et avec des technologies variés. Tomas est un membre actif de la communauté : il partage son expertise et inspire les autres. Il est également formateur O'Reilly et anime des sessions de formation en direct en ligne.