Los datos semiestructurados se han convertido en un pilar de muchos proyectos de datos. Aportan más flexibilidad que los datos estructurados, algo que necesitan muchos workloads, sobre todo los que giran en torno a APIs, sensores IoT o aplicaciones web. JSON se ha convertido en el "estándar" de facto para la comunicación entre APIs. Al no tener la estructura de los datos relacionales tradicionales, aparecen retos a la hora de procesar y trabajar con este tipo de estructuras. En los próximos posts, quiero repasar las capacidades de la plataforma de datos de Snowflake para el procesamiento de datos semiestructurados. Vamos a recorrer todo el ciclo de vida del dato: desde la ingesta, pasando por el procesamiento, hasta la entrega de los datos a los consumidores.
¿Qué son los datos semiestructurados?
Los datos semiestructurados son un tipo de datos que no sigue la estructura tabular de los datos relacionales. Se pueden ver como un híbrido entre los formatos de datos estructurados y los no estructurados. Tienen cierto nivel de organización, pero son más flexibles y dan más libertad a la hora de almacenar y usar la información.
Entre los elementos de los datos semiestructurados se incluyen:
- Pares clave-valor: es la forma más básica de datos semiestructurados y, en esencia, una estructura simple donde cada elemento se compone de una clave y su valor correspondiente.
- Estructuras jerárquicas: los datos semiestructurados se pueden organizar en elementos anidados, lo que da lugar a una jerarquía más compleja.
- Campos multivaluados: los datos semiestructurados pueden incluir campos con varios valores, conocidos comúnmente como arrays.
Ejemplo de datos semiestructurados en JSON
Tomemos un documento JSON como ejemplo, ya que es un formato fácil de leer para las personas. No tiene un formato fijo y el JSON puede adoptar la estructura que mejor se ajuste al caso de uso. Abajo puedes ver un ejemplo de archivo JSON. El JSON contiene un elemento person con varios pares clave-valor y un array.
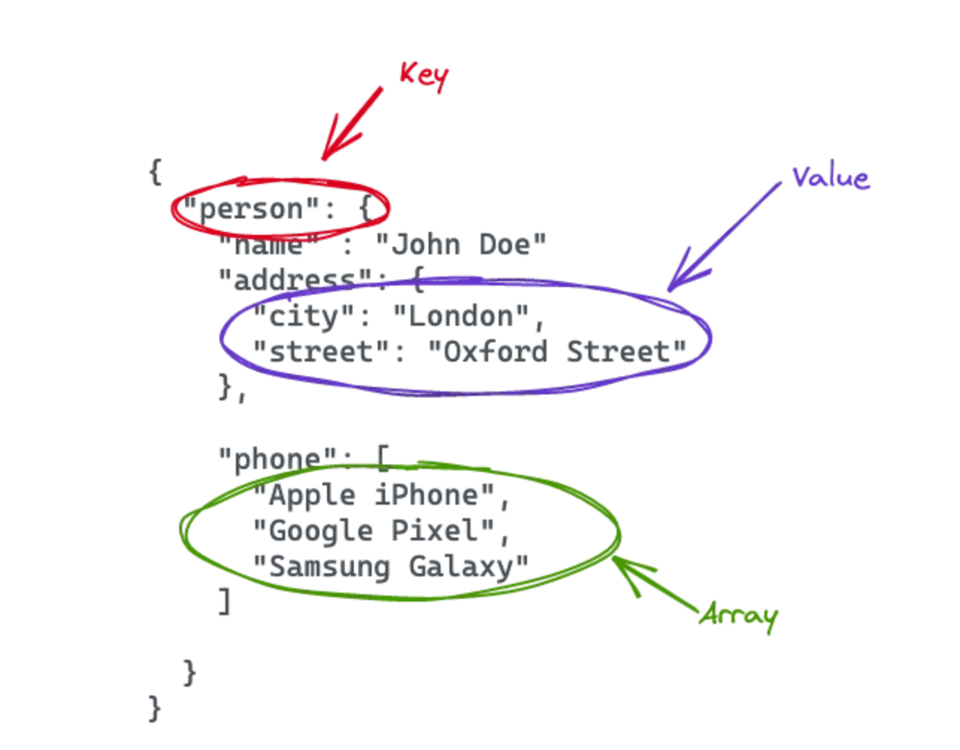
Soporte nativo de Snowflake para formatos de datos semiestructurados
¿Qué tan bien trabaja Snowflake con datos semiestructurados? Bastante bien, diría yo. Snowflake ofrece soporte nativo para este tipo de datos, lo que significa que se pueden importar y exportar de forma nativa en los siguientes formatos:
- JSON
- Avro
- ORC
- Parquet
- XML
Para almacenar datos semiestructurados en Snowflake, existen los siguientes tipos de datos nativos: ARRAY, OBJECT y VARIANT.
También vale la pena mencionar que puedes trabajar con datos semiestructurados desde tablas externas sin necesidad de cargarlos en Snowflake. ¡Puedes dejar tus archivos JSON o Parquet en tu Data Lake externo y usarlos igualmente en Snowflake!
Cargar datos semiestructurados en Snowflake
Para repasar el tema de la carga de datos en Snowflake, no te pierdas nuestro post anterior, donde cubrimos todas las opciones disponibles. A continuación, repaso dos opciones específicas para la carga de datos semiestructurados.
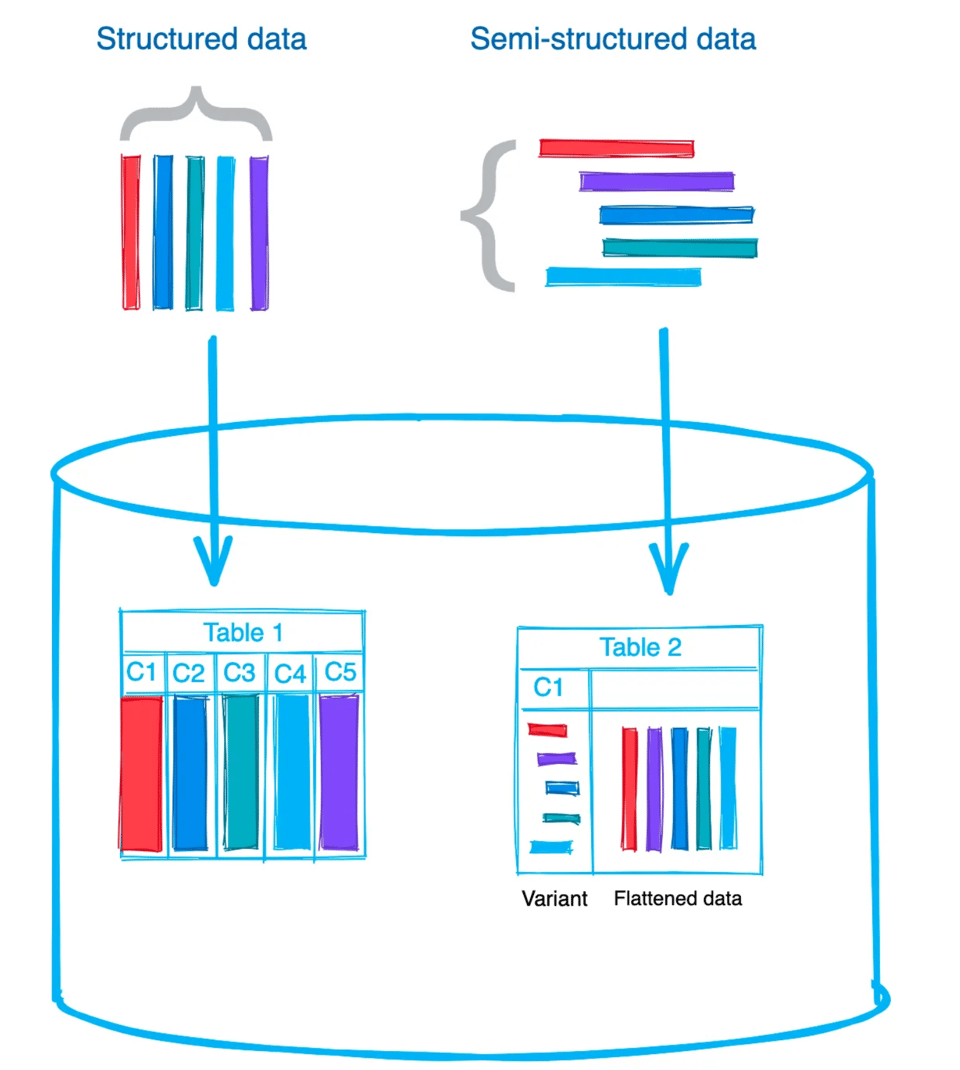
Opción 1: Cargar el archivo completo en una sola columna
A la hora de cargar datos semiestructurados en bruto en tablas de Snowflake, tienes dos opciones: guardar el archivo o documento completo en una sola columna, o aplanar los datos y guardar los valores individuales en columnas separadas. Depende del caso de uso y de cómo quieras trabajar con los datos después. Yo suelo cargarlos en formato crudo tal cual están y los guardo en una columna VARIANT. Luego los aplano, porque simplifica el procesamiento posterior. Eso sí, ten en cuenta que un único valor VARIANT está limitado a 128 MB de datos comprimidos. Si te imaginas un archivo JSON con 128 MB de datos comprimidos, es un archivo bastante grande. 🙂
Opción 2: Generar un esquema a partir de la estructura del archivo
El enfoque anterior funciona con JSON, pero los datos semiestructurados también se pueden almacenar en otros formatos. Muchas veces los datos se guardan en formato Apache Parquet, sobre todo en Data Lakes. A diferencia de JSON, que es un formato basado en texto, Parquet es un formato binario optimizado para almacenamiento columnar. Es decir, los datos se almacenan en columnas en lugar de filas, lo que resulta más eficiente para consultar y analizar grandes volúmenes de datos.
Una de las principales ventajas de Parquet es su capacidad para manejar conjuntos de datos muy grandes de forma eficiente. Al almacenarse en columnas, los datos se pueden comprimir y guardar de forma más compacta, reduciendo el almacenamiento necesario y mejorando el rendimiento de las operaciones de lectura.
Otra diferencia entre JSON y Parquet está en cómo manejan los tipos de datos. JSON es un formato débilmente tipado, es decir, no impone tipos de datos estrictos en cada campo. Parquet, en cambio, tiene un esquema bien definido y admite varios tipos de datos, como enteros, números de punto flotante, cadenas y timestamps. Esto facilita trabajar con los datos de forma consistente y garantiza que se almacenen y procesen con precisión.
Estas diferencias requieren enfoques distintos al momento de ingestar los datos. Como Parquet tiene un esquema bien definido, hay que definirlo durante la importación. Si alguna vez intentaste cargar datos Parquet en Snowflake, quizás te tocó pasar por un proceso lento para definir el esquema del archivo. Además, hay que crear una tabla destino con exactamente el mismo esquema. Si el archivo tiene decenas o cientos de columnas, esta tarea te puede llevar horas.
A modo de recordatorio, para quienes no sepan cómo cargar datos Parquet en Snowflake, revisen el siguiente código. Como se ve, dentro del comando copy hay que indicar los atributos del archivo junto con su tipo de dato.
COPY INTO <table_name>
FROM (
SELECT
$1:column1::<target_data_type>,
$1:column2::<target_data_type>,
$1:column3::<target_data_type>
FROM <my_stage>.<my_file.parquet>
);
``
$1 en la consulta SELECT hace referencia a la única columna donde se almacenan todos los datos de Parquet.
Antes de cargar los datos en Snowflake, primero hay que crear la tabla destino con el esquema requerido y después escribir la sentencia COPY listando todas las columnas, tal como en el ejemplo anterior.
Consideraciones para almacenar datos semiestructurados en una sola columna vs. aplanar la estructura anidada
Quizás ahora te preguntes: ¿qué hay que tener en cuenta para elegir una u otra opción?
Si no tienes claro qué uso se les va a dar a los datos en el futuro, guardarlos en una sola columna VARIANT es un buen punto de partida. Según la documentación de Snowflake, obtendrás un rendimiento de consulta parecido al de una estructura aplanada si el formato semiestructurado usa tipos nativos como cadenas y enteros. Los costos de almacenamiento también serán similares.
Si trabajas con fechas, timestamps o arrays, Snowflake señala que obtendrás un mejor pruning de consultas si los almacenas en columnas separadas.
Guardar por separado las columnas o campos a los que se accede con frecuencia mejora la experiencia del usuario final, ya que los datos son más fáciles de usar y se elimina la necesidad de saber cómo parsear datos JSON.
Detección automática del esquema y creación de tablas
En lugar de listar de forma explícita todas las columnas necesarias, Snowflake automatiza este proceso. Ahora puedes usar un par de funciones integradas que te ayudan a leer el esquema del archivo y preparar el comando COPY. También hay una función para automatizar la creación de la tabla. Te puedo asegurar que esto te ahorra horas de trabajo, porque yo he trabajado con archivos Parquet enormes (más de 100 columnas) donde había que hacer todo a mano. Veamos cómo usar estas funciones y automatizar todo el proceso.
Cómo usar INFER_SCHEMA
La función INFER_SCHEMA detecta automáticamente el esquema de metadatos en archivos en stage que contienen datos semiestructurados y devuelve las definiciones de columnas. Hoy por hoy, esta función funciona con archivos Apache Parquet, Apache Avro y ORC.
Es una función de tabla, así que hay que envolverla con la palabra clave TABLE():
SELECT *
FROM TABLE(
INFER_SCHEMA(
LOCATION=>'@mystage',
FILE_FORMAT=>'my_parquet_format'
)
);
La salida se ve así:
| COLUMN_NAME | TYPE | NULLABLE | EXPRESSION | FILENAMES | ORDER_ID |
|---|---|---|---|---|---|
| id | TEXT | True | $1:id::TEXT | customer/initial.parquet | 0 |
| first_name | TEXT | True | $1:first_name::TEXT | customer/initial.parquet | 1 |
| LAST_NAME | TEXT | True | $1:LAST_NAME::TEXT | customer/initial.parquet | 2 |
Ten en cuenta que, por defecto, los nombres de columna detectados desde los archivos en stage distinguen entre mayúsculas y minúsculas. Esto se puede ajustar con el parámetro IGNORE_CASE => TRUE.
Ya conocemos la estructura de los archivos en stage, pero ¿cómo damos el siguiente paso y creamos una tabla a partir de ese esquema? Para eso existe otra función.
Cómo usar GENERATE_COLUMN_DESCRIPTION
Esta función recibe como entrada la salida de la función INFER_SCHEMA y genera una lista de columnas. Podemos usar ese resultado en una sentencia CREATE TABLE. La función tiene dos parámetros; el segundo sirve para definir qué tipo de formato queremos en la salida, según si vamos a crear una tabla, una vista o una tabla externa. Aquí va un ejemplo combinado con INFER_SCHEMA:
SELECT GENERATE_COLUMN_DESCRIPTION(
ARRAY_AGG(OBJECT_CONSTRUCT(*)), 'table') AS COLUMNS
FROM TABLE (
INFER_SCHEMA(
LOCATION=>'@mystage',
FILE_FORMAT=>'my_parquet_format'
)
);
Y la salida obtenida:
+--------------------+
| COLUMN_DESCRIPTION |
|--------------------|
| "id" TEXT, |
| "first_name", TEXT |
| "LAST_NAME" TEXT |
+--------------------+
Ya puedes tomar la lista de columnas generada y usarla en tu sentencia CREATE TABLE.
Cómo crear la tabla automáticamente a partir del esquema detectado
Usar GENERATE_COLUMN_DESCRIPTION funciona muy bien, pero si quieres automatizar todavía más y crear la tabla automáticamente a partir del esquema detectado, puedes hacerlo gracias a la palabra clave USING TEMPLATE dentro de la sentencia CREATE TABLE. Esta palabra clave recibe como entrada la salida de la función INFER_SCHEMA.
CREATE TABLE mytable
USING TEMPLATE (
SELECT ARRAY_AGG(OBJECT_CONSTRUCT(*))
FROM TABLE(
INFER_SCHEMA(
LOCATION=>'@mystage',
FILE_FORMAT=>'my_parquet_format'
)
));
Bastante práctico, ¿no? Combinando varias funciones logramos automatizar la fase inicial de la ingesta de datos semiestructurados. Y si quieres ir un paso más allá, incluso puedes encapsular esta lógica en un procedimiento almacenado en Python que reciba parámetros como el formato del archivo, el stage y el destino.
Próximos pasos
Ahora que ya tienes tus datos semiestructurados cargados en tu cuenta de Snowflake, seguro vas a querer trabajar con ellos. No te pierdas nuestro próximo post sobre cómo trabajar con datos JSON.
Tomáš Sobotík·Senior Data Engineer y Snowflake SME en Norlys
Tomas es un Snowflake Data SuperHero de larga trayectoria y un referente en la materia. Su experiencia en el mundo de los datos supera la década, durante la cual se ha desempeñado como Snowflake data engineer, arquitecto y administrador en proyectos de distintas industrias y tecnologías. Tomas es un miembro central de la comunidad: comparte activamente sus conocimientos e inspira a otros. También es instructor en O'Reilly, donde imparte sesiones de formación en vivo online.