半構造化データは、いまやデータ関連業務を支える柱の一つです。構造化データに比べて柔軟性が高く、API や IoT センサー、Web アプリを中心に組み立てられる workloads では、その柔軟性が欠かせません。API 間の通信フォーマットとしては、JSON が事実上の「標準」となっています。一方で、従来のリレーショナルデータのような構造を持たないため、処理や取り扱いには独自の難しさがあります。本連載では、Snowflake データプラットフォームが備える半構造化データ処理の機能を紹介していきます。取り込みから処理、そして利用者への提供まで、データライフサイクル全体を順に取り上げていきましょう。
半構造化データとは
半構造化データとは、リレーショナルデータのような表形式の構造に従わないデータの総称です。構造化データと非構造化データの中間に位置するハイブリッドな形式と考えるとわかりやすいでしょう。一定の整理はされているものの、保存方法や利用方法において高い自由度があります。
半構造化データを構成する要素には、次のようなものがあります。
- キーバリューペア — 半構造化データの最も基本的な形式で、各項目がキーと対応する値の組み合わせで構成される、シンプルなデータ構造です。
- 階層構造 — 半構造化データはネストした要素として整理でき、より複雑な階層型のデータ構造を表現できます。
- 多値フィールド — 半構造化データには、複数の値を持つフィールド(一般に配列と呼ばれます)を含められます。
半構造化 JSON データの例
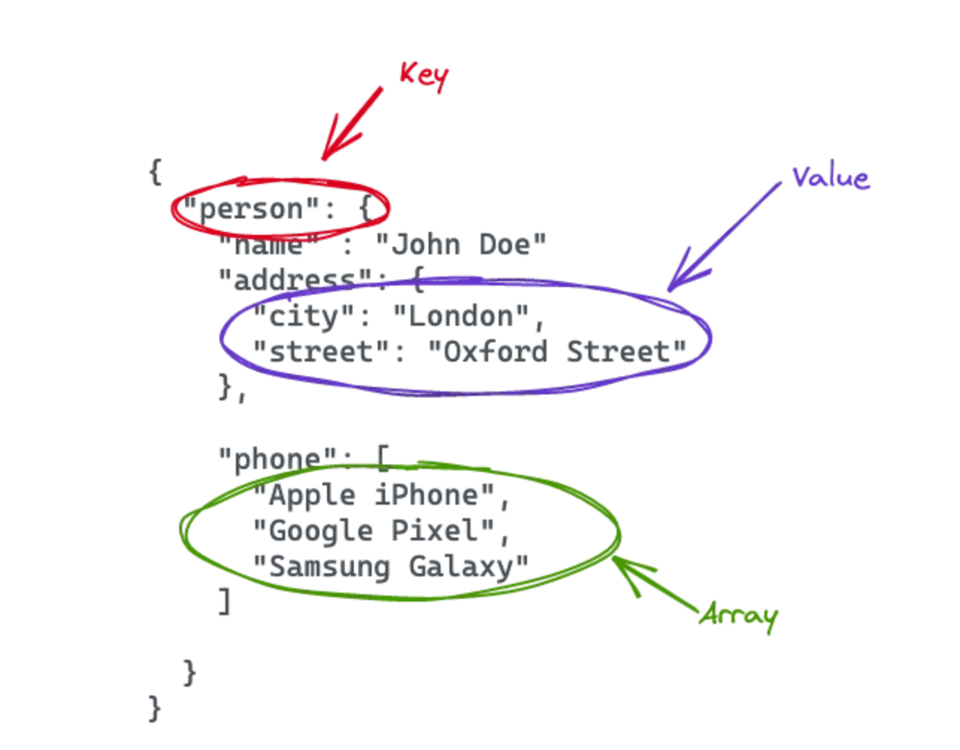
JSON は人間にとっても読みやすい形式なので、半構造化データの例として JSON ドキュメントを取り上げてみましょう。決まったフォーマットはなく、ユースケースに合わせて自由に構造を設計できます。下の画像はサンプルの JSON ファイルです。person 要素の中に、複数のキーバリューペアと 1 つの配列が含まれています。
Snowflake のネイティブな半構造化データサポート
Snowflake は半構造化データをどう扱うのか。結論から言えば、かなり得意です。Snowflake は半構造化データをネイティブにサポートしており、次のデータ形式の読み込みと書き出しを標準で行えます。
- JSON
- Avro
- ORC
- Parquet
- XML
Snowflake で半構造化データを保存するためのネイティブなデータ型としては、ARRAY、OBJECT、VARIANT が用意されています。
さらに、Snowflake に取り込まずに外部テーブル経由で半構造化データを扱える点も見逃せません。JSON や Parquet ファイルを外部のデータレイクに置いたまま、Snowflake からそのデータを利用できます。
半構造化データを Snowflake に取り込む
Snowflake のデータロード全般のおさらいは、選択肢を網羅した前回の記事を参照してください。ここでは、半構造化データに特化した 2 つのアプローチを取り上げます。
選択肢 1:ファイル全体を 1 つのカラムに読み込む
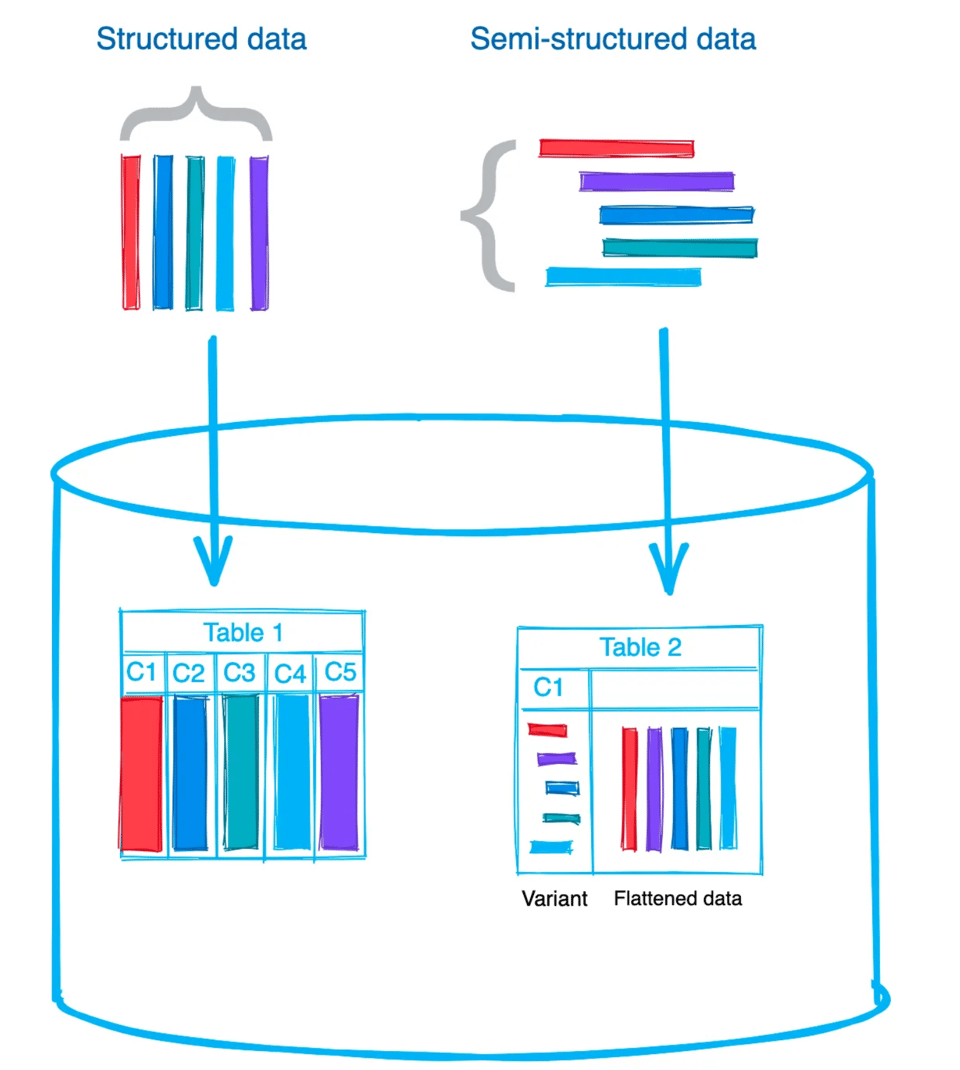
生の半構造化データを Snowflake テーブルに読み込む方法は 2 通りあります。ファイル/ドキュメント全体を 1 つのカラムに格納する方法と、データをフラット化して値ごとに別カラムへ格納する方法です。どちらを選ぶかは、ユースケースや後でどのようにデータを扱いたいかによって変わります。私は通常、生のままのデータを VARIANT カラムに読み込み、その後でフラット化するようにしています。こうすると後続の処理がぐっとシンプルになるからです。ただし、1 つの VARIANT 値は圧縮後 128 MB までという制限がある点には注意してください。圧縮後で 128 MB の JSON ファイルとなれば、相当に大きなファイルですが。🙂
選択肢 2:ファイル構造に基づいてスキーマを生成する
前述のアプローチは JSON に向いていますが、半構造化データは JSON 以外の形式でも保存できます。とくにデータレイクでは、Apache Parquet 形式で格納されているケースが多く見られます。テキストベースの JSON とは異なり、Parquet はカラムナストレージに最適化されたバイナリ形式です。データを行ではなく列単位で保持するため、大規模データセットのクエリや分析を効率よく実行できます。
Parquet の大きな利点の 1 つは、超大規模なデータセットを効率よく扱えることです。列単位で保持されるため、よりコンパクトに圧縮でき、必要なストレージ量を抑えながら読み取り性能を引き上げられます。
JSON と Parquet のもう 1 つの違いは、データ型の扱い方です。JSON は緩い型付けの形式で、各フィールドに厳密な型を強制しません。一方の Parquet は明確なスキーマを持ち、整数、浮動小数点、文字列、タイムスタンプなど多様なデータ型をサポートします。これにより、データを一貫した形で扱え、正確に保存・処理できます。
こうした違いから、データ取り込み時のアプローチも変わってきます。Parquet はスキーマが明確に定義されているため、インポート時にもそれを定義しておく必要があります。Parquet データを Snowflake に読み込んだことのある方なら、ファイルスキーマの定義に手を取られた経験があるのではないでしょうか。さらに、同じスキーマを持つターゲットテーブルもあわせて作成する必要があり、カラム数が数十、数百ともなると、この作業だけで何時間も費やしてしまうこともあります。
念のため、Parquet データを Snowflake に読み込む手順をご存じない方のために、以下のコードをご覧ください。COPY コマンドの中で、ファイル内の属性とそのデータ型を指定する必要があることがわかります。
COPY INTO <table_name>
FROM (
SELECT
$1:column1::<target_data_type>,
$1:column2::<target_data_type>,
$1:column3::<target_data_type>
FROM <my_stage>.<my_file.parquet>
);
``
SELECT クエリ内の $1 は、Parquet データがまとめて格納されている単一のカラムを指します。
データを Snowflake に読み込む前に、まず必要なスキーマを持つターゲットテーブルを作成し、上記の例のように全カラムを列挙した COPY 文を書く必要があります。
1 カラムにまとめるか、ネスト構造をフラット化するか — 判断のポイント
どちらを選ぶべきか、判断材料が気になっている方もいるでしょう。
データの今後の用途がはっきりしていない場合は、VARIANT カラム 1 つにまとめて格納するのが手堅い出発点です。Snowflake のドキュメントによれば、半構造化データが文字列や整数といったネイティブ型で構成されている場合、フラット化した構造と同等のクエリパフォーマンスが得られます。ストレージコストもほぼ同等です。
一方、日付やタイムスタンプ、配列を扱う場合は、それらを個別のカラムに格納したほうがクエリプルーニングが効きやすいと Snowflake は説明しています。
また、よく参照されるカラムやフィールドを個別に切り出しておけば、データが扱いやすくなり、利用者が JSON データのパース方法を知らなくてもよくなるため、エンドユーザー体験も向上します。
スキーマの自動検出とテーブルの自動作成
必要なカラムを 1 つずつ書き並べる代わりに、Snowflake にはこれを自動化する仕組みが用意されています。組み込み関数を組み合わせれば、ファイルからスキーマを読み取って COPY コマンドを組み立てられます。テーブル作成を自動化する関数もあります。100 列を超える巨大な Parquet ファイルをすべて手作業で扱った経験から言わせてもらえば、これは何時間もの作業を確実に節約してくれます。それでは、これらの関数を使ってプロセス全体を自動化する方法を見ていきましょう。
INFER_SCHEMA の使い方
INFER_SCHEMA 関数は、半構造化データを含むステージ上のファイルからメタデータスキーマを自動的に検出し、カラム定義を返します。現時点では、Apache Parquet、Apache Avro、ORC ファイルに対応しています。
テーブル関数なので、TABLE() キーワードで囲んで使用します。
SELECT *
FROM TABLE(
INFER_SCHEMA(
LOCATION=>'@mystage',
FILE_FORMAT=>'my_parquet_format'
)
);
出力は次のようになります。
| COLUMN_NAME | TYPE | NULLABLE | EXPRESSION | FILENAMES | ORDER_ID |
|---|---|---|---|---|---|
| id | TEXT | True | $1:id::TEXT | customer/initial.parquet | 0 |
| first_name | TEXT | True | $1:first_name::TEXT | customer/initial.parquet | 1 |
| LAST_NAME | TEXT | True | $1:LAST_NAME::TEXT | customer/initial.parquet | 2 |
注意点として、デフォルトではステージファイルから検出されるカラム名は大文字・小文字を区別して扱われます。これは IGNORE_CASE => TRUE パラメータで制御できます。
これでステージ上のファイル構造はわかりましたが、そのスキーマからテーブルを作成するにはどうすればよいのでしょうか。そのための関数も用意されています。
GENERATE_COLUMN_DESCRIPTION の使い方
この関数は INFER_SCHEMA 関数の出力を入力として受け取り、カラムのリストを生成します。その出力は CREATE TABLE 文にそのまま流用できます。関数には 2 つのパラメータがあり、2 つ目で出力フォーマット — テーブル用、ビュー用、外部テーブル用のいずれにするか — を指定します。INFER_SCHEMA と組み合わせた例は以下のとおりです。
SELECT GENERATE_COLUMN_DESCRIPTION(
ARRAY_AGG(OBJECT_CONSTRUCT(*)), 'table') AS COLUMNS
FROM TABLE (
INFER_SCHEMA(
LOCATION=>'@mystage',
FILE_FORMAT=>'my_parquet_format'
)
);
出力例:
+--------------------+
| COLUMN_DESCRIPTION |
|--------------------|
| "id" TEXT, |
| "first_name", TEXT |
| "LAST_NAME" TEXT |
+--------------------+
あとは、生成されたカラムリストを CREATE TABLE 文に組み込むだけです。
検出したスキーマからテーブルを自動作成する
GENERATE_COLUMN_DESCRIPTION でも十分便利ですが、もう一歩進めて、検出したスキーマからテーブルそのものを自動生成したい場合は、CREATE TABLE 文の USING TEMPLATE キーワードが使えます。このキーワードは INFER_SCHEMA 関数の出力を入力として受け取ります。
CREATE TABLE mytable
USING TEMPLATE (
SELECT ARRAY_AGG(OBJECT_CONSTRUCT(*))
FROM TABLE(
INFER_SCHEMA(
LOCATION=>'@mystage',
FILE_FORMAT=>'my_parquet_format'
)
));
なかなか便利ですよね。いくつかの関数を組み合わせるだけで、半構造化データ取り込みの初期工程を自動化できました。さらに踏み込みたい場合は、ファイル形式・ステージ・ターゲットなどをパラメータとして受け取る Python ストアドプロシージャに、このロジックをまとめておくこともできます。
次のステップ
Snowflake アカウントに半構造化データを取り込めたら、次はそれを実際に活用していきましょう。続編の JSON データの扱い方もぜひあわせてご覧ください。
Tomáš Sobotík・Norlys シニアデータエンジニア兼 Snowflake SME
Tomas は長年にわたり活躍する Snowflake Data SuperHero であり、Snowflake 全般のエキスパートです。データ業界での経験は 10 年以上に及び、多岐にわたる業界・技術領域のプロジェクトで Snowflake のデータエンジニア、アーキテクト、管理者を務めてきました。コミュニティの中核メンバーとして自身の知見を積極的に共有し、多くの人々にインスピレーションを与えています。さらに O'Reilly のインストラクターとして、ライブのオンライントレーニングも担当しています。