Snowflake hat in den letzten fünf Jahren einen rasanten Aufstieg hingelegt und sich fest im Zentrum der Data Stacks vieler Unternehmen etabliert. Snowflake entstand 2012 mit einer einzigartigen Architektur, die im wegweisenden White Paper als "the elastic data warehouse" beschrieben wurde. Statt Compute und Storage wie die damaligen Wettbewerber auf derselben Maschine zu koppeln 1, setzten sie auf ein neues Design, das die nahezu unbegrenzten Ressourcen von Cloud-Plattformen wie Amazon Web Services (AWS) nutzte. In diesem Beitrag sehen wir uns die drei Schichten von Snowflakes Data-Warehouse-Architektur genauer an 2: Cloud Services, Compute und Storage.
Cloud Services
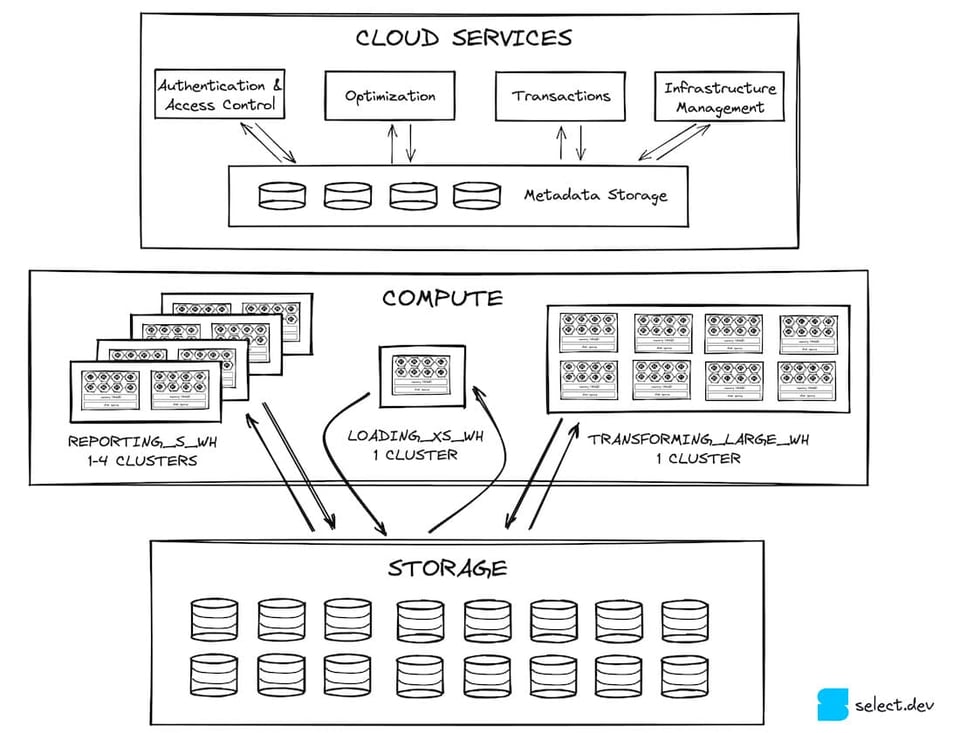
Die Cloud-Services-Schicht ist der Einstiegspunkt für jede Interaktion mit Snowflake. Sie besteht aus zustandslosen Services, gestützt von einer FoundationDB-Datenbank, in der sämtliche benötigten Metadaten liegen. Authentifizierung und Zugriffskontrolle (wer auf Snowflake zugreifen darf und was er dort tun kann) sind typische Beispiele für Services dieser Schicht. Auch Query-Kompilierung und -Optimierung gehören zu den zentralen Aufgaben der Cloud Services. Snowflake führt dabei Performance-Optimierungen durch, etwa die Reduktion der Anzahl an Micro-Partitions, die für eine Query gescannt werden müssen (Compile-Time-Pruning).
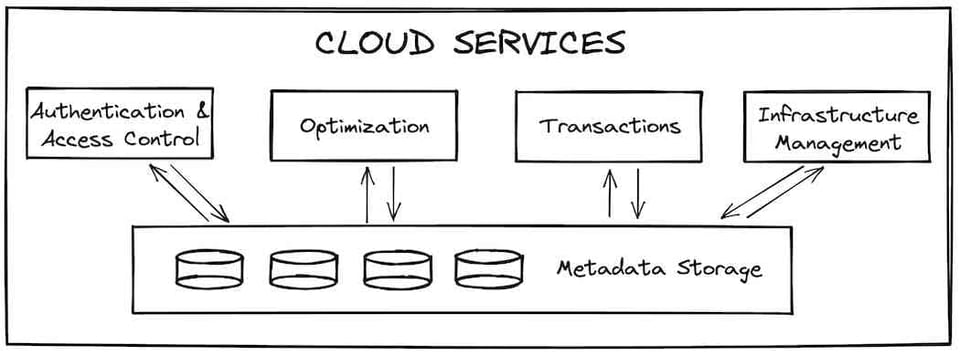
Die Cloud Services sind außerdem für Infrastruktur- und Transaktionsmanagement zuständig. Müssen für eine Query neue Virtual Warehouses bereitgestellt werden, sorgen die Cloud Services dafür, dass diese verfügbar sind. Greift eine Query auf Daten zu, die gerade von einer anderen Transaktion aktualisiert werden, wartet die Cloud-Services-Schicht, bis das Update abgeschlossen ist, bevor sie Ergebnisse zurückgibt.
Eine der aus Performance-Sicht wichtigsten Aufgaben der Cloud Services ist das Caching von Query-Ergebnissen im Global Result Cache. Wird dieselbe Query erneut ausgeführt, lassen sich die Ergebnisse extrem schnell zurückgeben 3. Das entlastet die Compute-Schicht spürbar 4 – darauf gehen wir im nächsten Abschnitt ein.
Compute
Hat eine Query die Cloud Services durchlaufen, wird sie zur Ausführung an die Compute-Schicht weitergereicht. Die Compute-Schicht umfasst alle Virtual Warehouses, die ein Kunde angelegt hat. Virtual Warehouses sind eine Abstraktion über eine oder mehrere Compute-Instanzen, sogenannte "Nodes". Bei Snowflake-Accounts auf Amazon Web Services entspricht ein Node einer einzelnen EC2-Instanz. Snowflake nutzt ein T-Shirt-Sizing, um festzulegen, wie viele Nodes ein Warehouse umfasst. In der Regel legen Kunden für unterschiedliche Workloads getrennte Warehouses an. Die Abbildung unten zeigt ein hypothetisches Setup mit drei Virtual Warehouses: ein Small-Warehouse für Business Intelligence 5, ein Extra-Small-Warehouse zum Laden von Daten in Snowflake und ein Large-Warehouse für Datentransformationen.
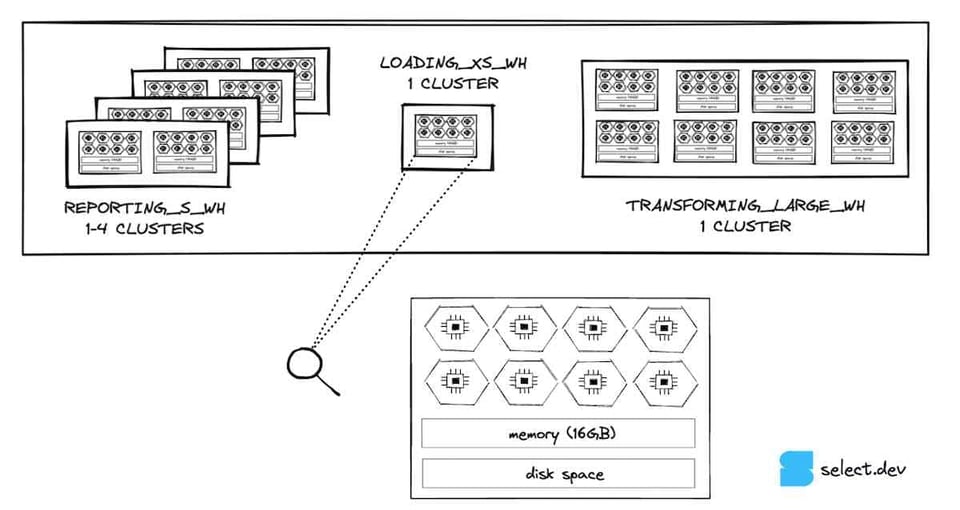
Zoomen wir in das Extra-Small-Warehouse hinein – die kleinste von Snowflake angebotene Größe –, sehen wir, dass es aus einem einzigen Node besteht. Jeder Node verfügt über 8 Cores/Threads, 16 GB Arbeitsspeicher (RAM) und einen SSD-Cache 6 – ausgenommen 5XL und 6XL, die auf abweichenden Node-Spezifikationen laufen. Mit jeder Erhöhung der Warehouse-Größe verdoppelt sich die Anzahl der Nodes – und damit auch Threads, Arbeitsspeicher und Festplattenkapazität. Ein Small-Warehouse hat doppelt so viel Speicher (32 GB), doppelt so viele Cores (16) und doppelt so viel Festplattenplatz wie ein Extra-Small-Warehouse. Ein Large-Warehouse verfügt entsprechend über die achtfachen Ressourcen eines Extra-Small-Warehouses.
Ein wichtiger Aspekt im Design von Snowflake: Die Nodes eines laufenden Warehouses werden nirgendwo sonst genutzt. Damit haben Nutzer die Garantie, dass ihre Queries nicht von Queries anderer Warehouses innerhalb desselben Accounts beeinträchtigt werden – Snowflake-Kunden können so hochperformante und vorhersehbare Daten-Workloads fahren. Anders verhält es sich bei der Cloud-Services-Schicht, die accountübergreifend geteilt wird und weniger konsistente Laufzeiten zeigt – in der Praxis ist das aber zu vernachlässigen.
Storage
Snowflake speichert Ihre Tabellen in einem skalierbaren Cloud-Storage-Dienst (S3 bei AWS, Azure Blob bei Azure usw.). Jede Tabelle 7 wird in eine Vielzahl unveränderlicher Micro-Partitions aufgeteilt. Diese nutzen ein proprietäres, nicht offenes Dateiformat, das Snowflake selbst entwickelt hat. Snowflake hält sie stark komprimiert bei rund 16 MB 8. Entsprechend können bei einer einzigen Tabelle Millionen von Micro-Partitions zusammenkommen.
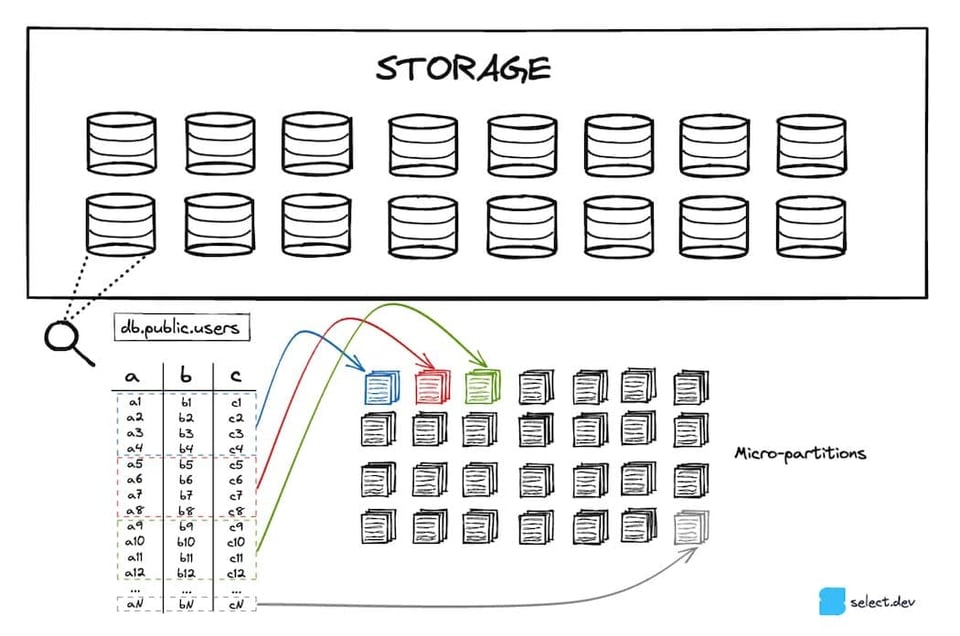
Micro-Partitions setzen auf ein spaltenorientiertes Speicherformat statt auf das zeilenbasierte Layout, das OLTP-Datenbanken wie Postgres, SQLite, MySQL oder SQL Server typischerweise verwenden. Da analytische Queries meist nur wenige Spalten über sehr viele Zeilen hinweg auswählen, liefert ein spaltenorientiertes Format deutlich bessere Performance.
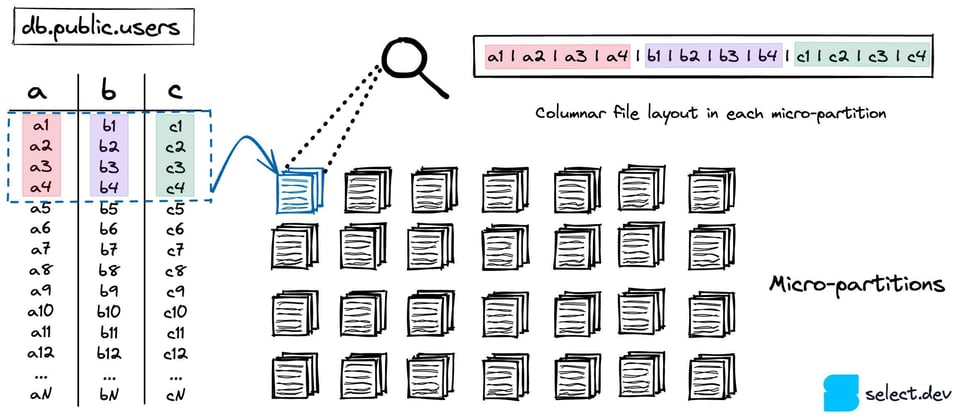
Sobald eine Micro-Partition erstellt wird, berechnet Snowflake Metadaten auf Spaltenebene. Min-/Max-Werte, Count, Anzahl distinkter Werte oder Anzahl NULLs sind Beispiele für Metadaten, die berechnet und in den Cloud Services abgelegt werden. Wie bereits erwähnt, nutzt Snowflake diese Metadaten bei der Query-Optimierung und -Planung, um genau die Micro-Partitions zu identifizieren, die für eine konkrete Query gescannt werden müssen – eine zentrale Technik, bekannt als "Pruning". Das beschleunigt Queries erheblich, weil unnötige, langsame Datenlesevorgänge wegfallen.
Da Micro-Partitions unveränderlich sind, müssen DML-Operationen (Updates, Inserts, Deletes) ganze Dateien hinzufügen oder entfernen und die zugehörigen Metadaten neu berechnen. Snowflake empfiehlt deshalb, DML-Operationen in Batches durchzuführen, um die Zahl der neu geschriebenen Micro-Partitions zu reduzieren – das senkt sowohl Laufzeit als auch Kosten der Operationen.
Da ein Tabellenobjekt in Snowflake im Grunde ein Cloud-Services-Eintrag ist, der auf eine Sammlung von Micro-Partitions verweist, kann Snowflake innovative Storage-Funktionen wie Zero-Copy Cloning und Time Travel anbieten. Legen Sie eine neue Tabelle als Klon einer bestehenden Tabelle an, erzeugt Snowflake einen neuen Metadaten-Eintrag, der auf dieselben Micro-Partitions zeigt. Bei Time Travel verfolgt Snowflake, aus welchen Micro-Partitions eine Tabelle im Zeitverlauf bestand, und ermöglicht so den Zugriff auf den exakten Zustand einer Tabelle zu einem bestimmten Zeitpunkt.
Anmerkungen
Damals waren Snowflakes Hauptkonkurrenten Amazon Redshift sowie klassische On-Premise-Lösungen wie Oracle und Teradata. All diese Systeme koppelten Storage und Compute auf denselben Maschinen, was sie schwer und teuer skalierbar machte. Heute sind Snowflakes größere Wettbewerber Anbieter wie BigQuery und Databricks. BigQuery dürfte dank der nahtlosen Integration in die Google Cloud Platform einen ähnlichen, wenn nicht sogar größeren Marktanteil halten. Databricks ist zu einem neuen Wettbewerber geworden, da sich beide Unternehmen zunehmend als "Data Clouds" positionieren.
Mit ihrer Entwicklung hin zu einer vollwertigen "Data Cloud" baut Snowflake rasant neue Funktionen aus – etwa Snowpark, Unistore, External Tables, Streamlit und einen nativen App Store –, die alle die Snowflake-Architektur erweitern. In diesem Architektur-Überblick lassen wir diese neuen Möglichkeiten außen vor und konzentrieren uns auf die Data-Warehousing-Aspekte, die die meisten Kunden heute nutzen.
Die Queries müssen identisch sein, damit sie aus dem Global Result Cache bedient werden können. Außerdem hat Snowflake tatsächlich zwei verschiedene Caches, die der Performance zugutekommen: den Global Result Cache und einen lokalen Cache in jedem Warehouse. Beide behandeln wir in einem späteren Beitrag ausführlicher.
Neben der Auslieferung früherer Queries aus dem Global Result Cache kann Snowflake bestimmte Queries wie
count(*)odermax(column)komplett über den Metadaten-Storage beantworten. Mehr dazu in unserem Beitrag zu Micro-Partitions.Dieses Warehouse ist tatsächlich ein Multi-Cluster-Warehouse: Snowflake stellt zusätzliche Compute-Ressourcen bereit, wenn die Query-Last das übersteigt, was ein einzelnes Small-Warehouse bewältigen kann. Multi-Cluster-Warehouses behandeln wir in einem späteren Beitrag im Detail.
Diese Werte gelten für AWS und können bei anderen Cloud-Anbietern leicht abweichen. Sie sind nicht garantiert exakt, da Snowflake sie nicht veröffentlicht und die zugrunde liegenden Server sowie Warehouse-Konfigurationen jederzeit ändern kann. Die hier genannten Werte wurden zuletzt im August 2022 über zwei unabhängige Quellen bestätigt. Sie scheinen mit dem übereinzustimmen, was 2019 beobachtet wurde. Den verfügbaren Festplattenplatz pro Node konnte ich noch nicht verifizieren, plane aber, das in den kommenden Monaten experimentell herauszufinden.
Eine Ausnahme bilden Daten, die über External Tables gespeichert werden.
Die Komprimierung übernimmt Snowflake automatisch im Hintergrund. Unkomprimiert können diese Dateien über 500 MB groß sein!
Ian Whitestone · Co-Founder & CEO von SELECT
Ian ist Co-Founder & CEO von SELECT, einer SaaS-Plattform für Snowflake-Kostenmanagement und -Optimierung. Vor SELECT leitete Ian sechs Jahre lang Full-Stack-Data-Science- und Engineering-Teams bei Shopify und Capital One. Bei Shopify verantwortete er die Optimierung des Data Warehouse und den Ausbau der Kostentransparenz.
Dank seiner einzigartigen, skalierbaren Architektur hat sich Snowflake schnell zum dominierenden Data Warehouse von heute entwickelt. In künftigen Beiträgen tauchen wir tiefer in die einzelnen Schichten der Snowflake-Architektur ein und zeigen, wie Sie deren Funktionen nutzen, um die Query-Performance zu maximieren und Kosten zu senken.