Snowflake ha crecido de forma vertiginosa en los últimos 5 años y se afianzó en el centro del stack de datos de muchísimas empresas. Snowflake nació en 2012 con una arquitectura única, descrita en su white paper fundacional como "el data warehouse elástico". En lugar de acoplar compute y storage en la misma máquina, como hacían sus competidores 1, propuso un nuevo diseño que aprovecha los recursos casi infinitos de plataformas de cloud computing como Amazon Web Services (AWS). En este post vamos a recorrer las tres capas de la arquitectura del data warehouse de Snowflake 2: cloud services, compute y storage.
Cloud Services
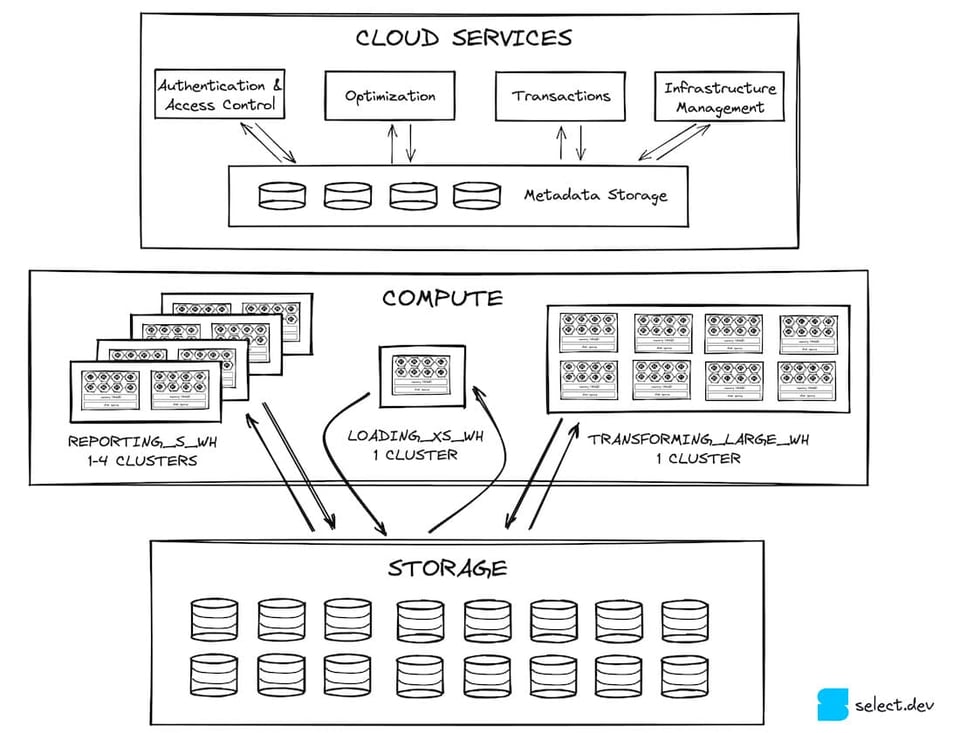
La capa de cloud services es el punto de entrada para todas las interacciones que un usuario tiene con Snowflake. Está compuesta por servicios sin estado, respaldados por una base de datos FoundationDB que guarda todos los metadatos necesarios. La autenticación y el control de acceso (quién puede entrar a Snowflake y qué puede hacer dentro) son ejemplos de servicios de esta capa. La compilación y la optimización de consultas son otras funciones críticas que recaen en los cloud services. Snowflake aplica optimizaciones de rendimiento, como reducir la cantidad de micro-partitions que una consulta debe escanear (pruning en tiempo de compilación).
Los cloud services también se encargan de la gestión de infraestructura y de transacciones. Cuando hay que aprovisionar nuevos virtual warehouses para atender una consulta, los cloud services se ocupan de que estén disponibles. Si una consulta intenta acceder a datos que otra transacción está actualizando, la capa de cloud services espera a que termine esa actualización antes de devolver resultados.
Desde el punto de vista del rendimiento, una de las funciones más importantes de los cloud services es cachear los resultados de las consultas en su global result cache, lo que permite devolverlos a gran velocidad cuando se ejecuta la misma consulta de nuevo 3. Así se reduce significativamente la carga sobre la capa de compute 4, que veremos a continuación.
Compute
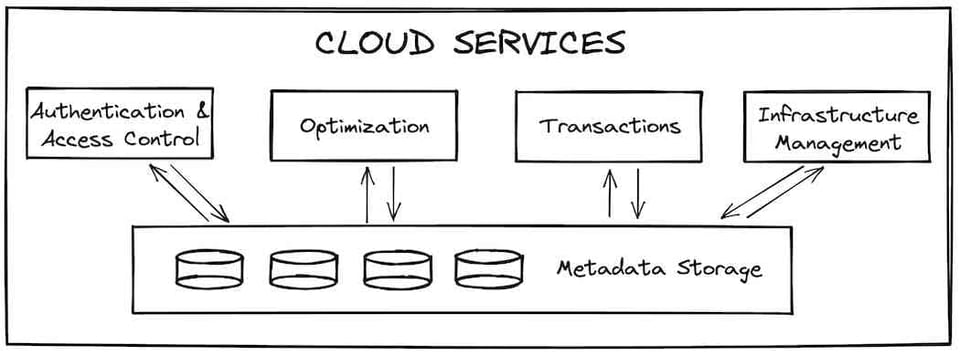
Una vez que la consulta pasó por los cloud services, se envía a la capa de compute para ejecutarse. Esa capa está formada por todos los virtual warehouses que el cliente haya creado. Los virtual warehouses son una abstracción sobre una o más instancias de cómputo, o "nodos". En las cuentas de Snowflake que corren sobre Amazon Web Services, un nodo equivale a una sola instancia EC2. Snowflake utiliza un esquema de tallas tipo camiseta para definir cuántos nodos tendrá cada warehouse. Lo habitual es que los clientes creen warehouses separados para cada tipo de workload. En la imagen de abajo se ve una configuración hipotética con 3 virtual warehouses: uno small para business intelligence 5, uno extra-small para cargar datos en Snowflake y uno large para transformaciones de datos.
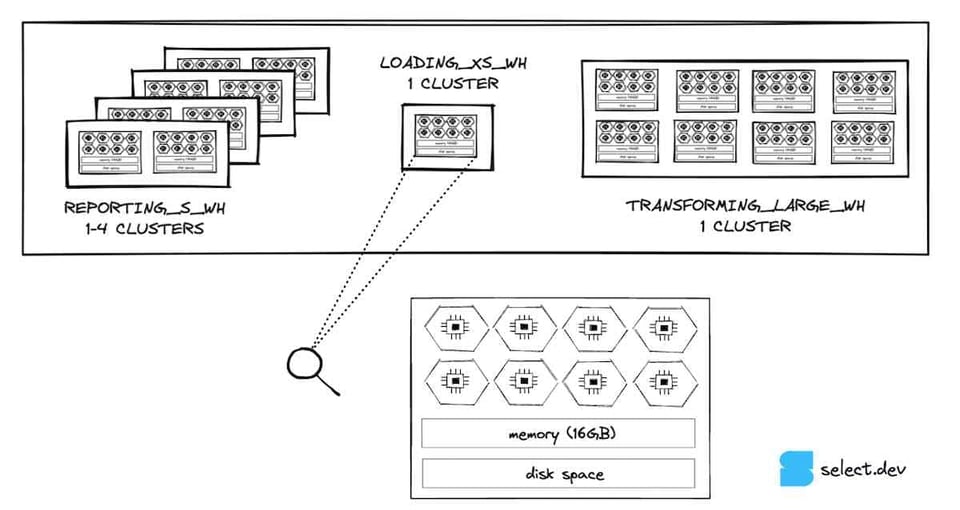
Si nos acercamos al warehouse extra-small, el tamaño más chico que ofrece Snowflake, vemos que se compone de un solo nodo. Cada nodo cuenta con 8 cores/threads, 16GB de memoria (RAM) y una caché SSD 6, salvo los 5XL y 6XL, que corren sobre especificaciones de nodo distintas. Con cada salto de tamaño del warehouse, la cantidad de nodos se duplica. Eso quiere decir que también se duplican los threads, la memoria y el espacio en disco. Un warehouse small tiene el doble de memoria (32GB), el doble de cores (16) y el doble de espacio en disco que uno extra-small. Por extensión, un warehouse large tiene 8 veces los recursos de uno extra-small.
Un aspecto clave del diseño de Snowflake es que los nodos de cada warehouse en ejecución no se reutilizan en ningún otro lado. Esto le da al usuario una sólida garantía de rendimiento: sus consultas no se ven afectadas por las que corren en otros warehouses de la misma cuenta, lo que les permite a los clientes de Snowflake ejecutar workloads de datos altamente performantes y predecibles. A diferencia de la capa de cloud services, que sí se comparte entre cuentas y tiene tiempos menos consistentes, aunque en la práctica esto resulta irrelevante.
Storage
Snowflake guarda tus tablas en un servicio de almacenamiento en la nube escalable (S3 si estás en AWS, Azure Blob para Azure, etc.). Cada tabla 7 se particiona en un conjunto de micro-partitions inmutables. Las micro-partitions usan un formato de archivo propietario y de código cerrado creado por Snowflake. Snowflake apunta a mantenerlas en torno a los 16MB, con una compresión fuerte 8. Como resultado, una sola tabla puede llegar a tener millones de micro-partitions.
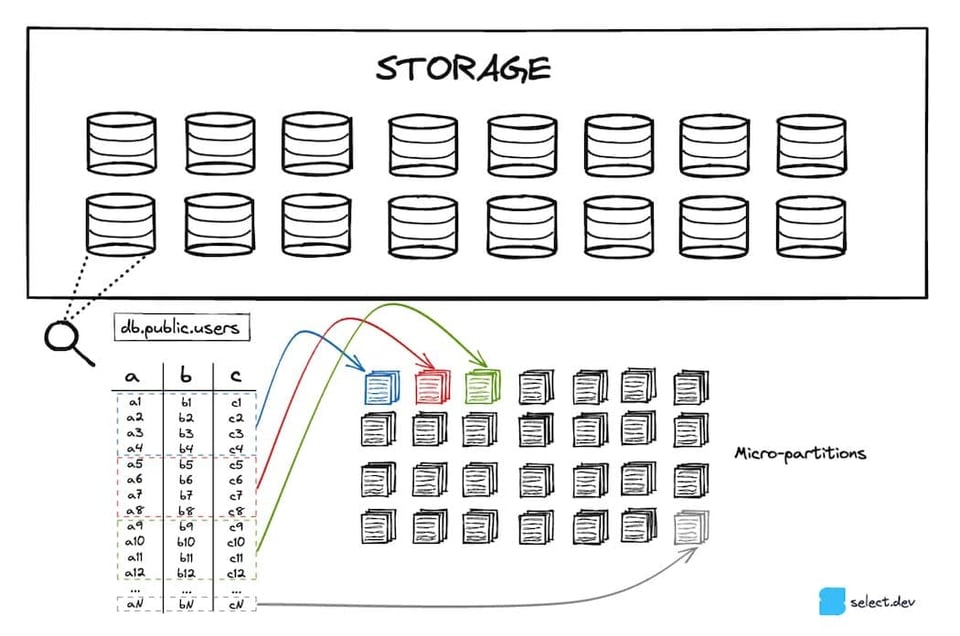
Las micro-partitions usan un formato de almacenamiento columnar en vez del formato basado en filas que suelen usar las bases de datos OLTP como Postgres, SQLite, MySQL, SQLServer, etc. Como las consultas analíticas suelen seleccionar pocas columnas a lo largo de muchas filas, los formatos columnares logran un rendimiento muy superior.
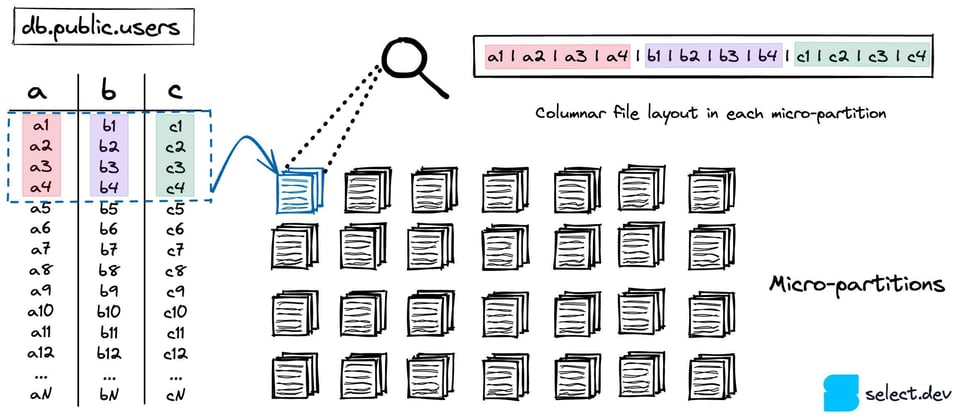
Los metadatos a nivel de columna se calculan cada vez que se crea una micro-partition. El valor min/max, el conteo, el número de valores distintos y la cantidad de nulls son algunos ejemplos de los metadatos que se calculan y se guardan en los cloud services. Como ya vimos, Snowflake puede aprovechar esos metadatos durante la optimización y planificación de consultas para identificar las micro-partitions exactas que hay que escanear, una técnica clave conocida como "pruning". Esto acelera muchísimo las consultas al evitar lecturas innecesarias y lentas.
Como las micro-partitions son inmutables, las operaciones DML (actualizaciones, inserciones, borrados) tienen que agregar o quitar archivos completos y recalcular los metadatos correspondientes. Snowflake recomienda ejecutar las operaciones DML por lotes para reducir la cantidad de micro-partitions que se reescriben, lo que disminuye el tiempo total y el costo de las operaciones.
Como un objeto tabla en Snowflake es esencialmente una entrada en cloud services que referencia un conjunto de micro-partitions, Snowflake puede ofrecer funciones de almacenamiento innovadoras como zero-copy cloning y time travel. Cuando creas una tabla nueva como clon de una existente, Snowflake genera una nueva entrada de metadatos que apunta al mismo conjunto de micro-partitions. En el caso de time travel, Snowflake hace un seguimiento de qué micro-partitions componían una tabla a lo largo del tiempo, lo que te permite acceder a la versión exacta de esa tabla en un punto puntual del tiempo.
Notas
En aquel entonces, los principales competidores de Snowflake eran Amazon Redshift y las ofertas on-premise tradicionales como Oracle y Teradata. Todas esas soluciones acoplaban el almacenamiento y el compute en las mismas máquinas, lo que las volvía difíciles y costosas de escalar. Hoy, los grandes competidores de Snowflake son BigQuery y Databricks. BigQuery probablemente tenga una cuota de mercado similar, o incluso mayor, gracias a su integración natural con el resto de Google Cloud Platform. Databricks se sumó como nuevo competidor a medida que ambas compañías se reposicionan como "data clouds".
Con su transición hacia un "data cloud" completo, Snowflake está sumando rápidamente nuevas funciones como Snowpark, Unistore, External Tables, Streamlit y un App store nativo, todas las cuales extienden su arquitectura. En esta revisión de arquitectura vamos a dejar de lado esas nuevas capacidades y enfocarnos en los aspectos de data warehousing que la mayoría de los clientes usa hoy.
Las consultas tienen que ser idénticas para que se atiendan desde el global result cache. Además, Snowflake en realidad tiene dos cachés diferentes que pueden ayudar al rendimiento: el global result cache y una caché local en cada warehouse. Vamos a cubrir ambas con más detalle en un próximo post.
Además de atender consultas ya ejecutadas desde el global result cache, Snowflake también puede procesar ciertas consultas como
count(*)omax(column)íntegramente apoyándose en el almacenamiento de metadatos. Te contamos más en nuestro post sobre micro-partitions.Este warehouse en realidad es un multi-cluster warehouse, lo que significa que Snowflake asigna recursos de compute adicionales cuando la demanda de consultas supera lo que un solo warehouse small puede manejar. Vamos a profundizar en los multi-cluster warehouses en un próximo post.
Estas cifras son para AWS y varían un poco con otros proveedores de nube. No están garantizadas, ya que Snowflake no las publica y puede cambiar los servidores subyacentes y las configuraciones de los warehouses en cualquier momento. Las cifras que compartí se validaron por última vez en agosto de 2022 a través de dos fuentes distintas. Parecen ser consistentes con lo que se observó en 2019. No he podido validar el espacio en disco disponible en cada nodo, pero planeo averiguarlo de forma experimental en los próximos meses.
La excepción a esto es si usas external tables para guardar tus datos.
Esta compresión la hace Snowflake de forma automática, por detrás. ¡Sin comprimir, estos archivos pueden superar los 500MB!
Ian Whitestone·Co-founder & CEO de SELECT
Ian es Co-founder y CEO de SELECT, una plataforma SaaS de gestión y optimización de costos para Snowflake. Antes de fundar SELECT, Ian pasó 6 años liderando equipos full stack de data science e ingeniería en Shopify y Capital One. En Shopify, lideró el trabajo para optimizar su data warehouse y mejorar la observabilidad de costos.
La arquitectura única y escalable de Snowflake le permitió convertirse rápidamente en el data warehouse dominante de hoy. En próximos posts vamos a profundizar en cada capa de la arquitectura de Snowflake y a ver cómo sacarles partido a sus funciones para maximizar el rendimiento de las consultas y reducir costos.