Negli ultimi 5 anni Snowflake è cresciuto in modo vertiginoso, conquistando una posizione centrale negli stack di dati di moltissime aziende. Snowflake nasce nel 2012 con un'architettura unica nel suo genere, descritta nel white paper di riferimento come "the elastic data warehouse". Invece di tenere compute e storage accoppiati sulla stessa macchina, come facevano i concorrenti dell'epoca 1, ha proposto un design del tutto nuovo, capace di sfruttare le risorse pressoché illimitate offerte dalle piattaforme di cloud computing come Amazon Web Services (AWS). In questo articolo approfondiremo i tre livelli dell'architettura del data warehouse di Snowflake 2: cloud services, compute e storage.
Cloud Services
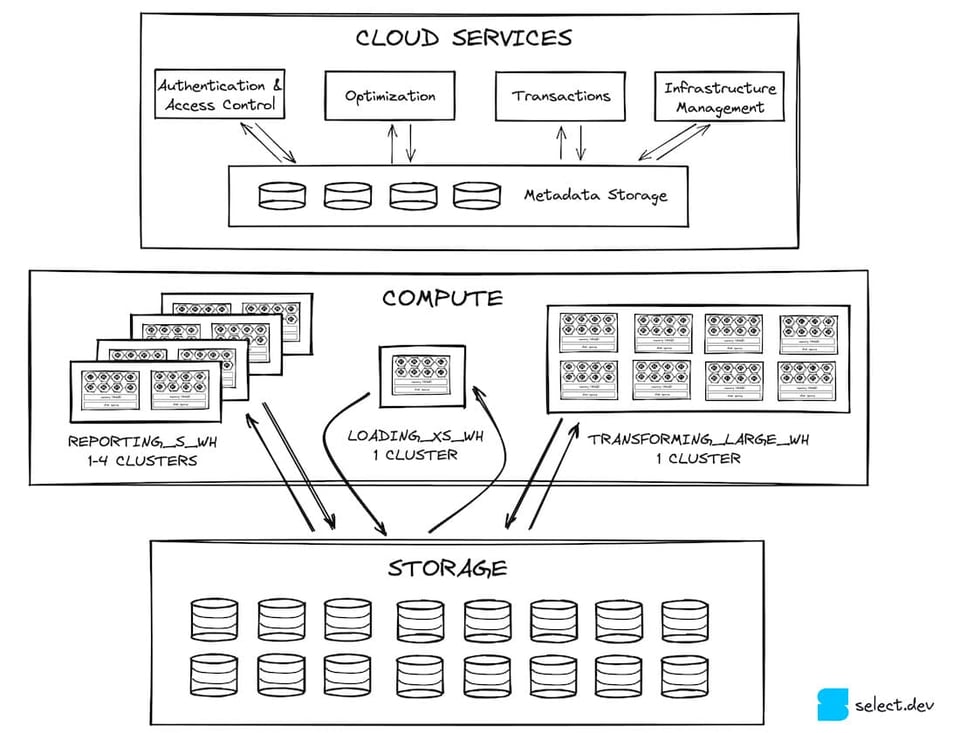
Il livello dei cloud services è il punto di ingresso per qualsiasi interazione dell'utente con Snowflake. È composto da servizi stateless, appoggiati a un database FoundationDB che conserva tutti i metadati necessari. Autenticazione e controllo degli accessi (chi può accedere a Snowflake e cosa può farci) sono due esempi di servizi gestiti da questo livello. Anche la compilazione e l'ottimizzazione delle query sono compiti critici affidati ai cloud services. Snowflake esegue ottimizzazioni delle prestazioni, ad esempio riducendo il numero di micro-partizioni che la query di un utente deve scansionare (compile-time pruning).
I cloud services si occupano anche della gestione dell'infrastruttura e delle transazioni. Quando occorre fornire nuovi virtual warehouse per eseguire una query, sono i cloud services a garantirne la disponibilità. Se una query tenta di accedere a dati in fase di aggiornamento da parte di un'altra transazione, il livello dei cloud services attende il completamento dell'aggiornamento prima di restituire i risultati.
Sul fronte delle prestazioni, uno dei compiti più importanti dei cloud services è memorizzare i risultati delle query nella global result cache, che può restituirli con estrema rapidità se la stessa query viene eseguita di nuovo 3. In questo modo si riduce notevolmente il carico sul livello compute 4, di cui parliamo a breve.
Compute
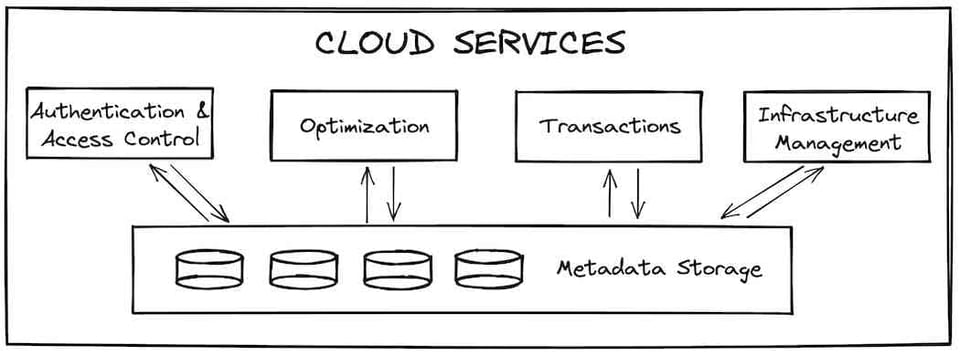
Una volta superato il livello dei cloud services, la query viene inviata al livello compute per l'esecuzione. Il livello compute è formato da tutti i virtual warehouse che il cliente ha creato. I virtual warehouse sono un'astrazione su una o più istanze di calcolo, o "nodi". Per gli account Snowflake che girano su Amazon Web Services, un nodo corrisponde a una singola istanza EC2. Per configurare il numero di nodi dei propri warehouse, Snowflake adotta il t-shirt sizing. In genere i clienti creano warehouse separati per workloads diversi. Nell'immagine qui sotto vediamo una configurazione ipotetica con 3 virtual warehouse: uno small dedicato alla business intelligence 5, uno extra-small per il caricamento dei dati in Snowflake e uno large per le trasformazioni dei dati.
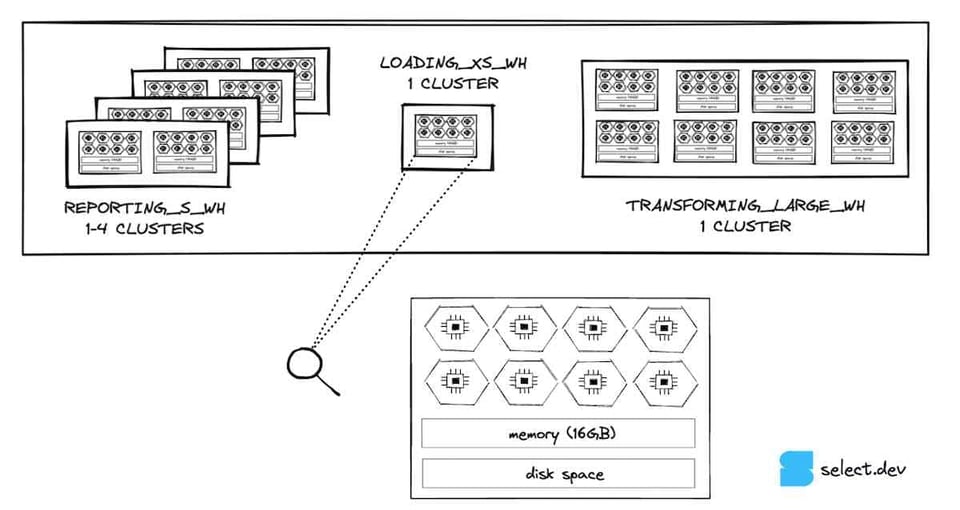
Soffermandoci sul warehouse extra-small, la taglia minima offerta da Snowflake, notiamo che è composto da un singolo nodo. Ogni nodo dispone di 8 core/thread, 16 GB di memoria (RAM) e una cache SSD 6, fatta eccezione per le taglie 5XL e 6XL, che girano su specifiche di nodo diverse. A ogni passaggio di taglia, il numero di nodi del warehouse raddoppia. Di conseguenza raddoppiano anche thread, memoria e spazio su disco. Un warehouse small dispone del doppio della memoria (32 GB), del doppio dei core (16) e del doppio dello spazio su disco rispetto a un extra-small. Allo stesso modo, un warehouse large ha 8 volte le risorse di un extra-small.
Un aspetto importante del design di Snowflake è che i nodi di ciascun warehouse attivo non vengono condivisi con altri. Gli utenti hanno così una solida garanzia di prestazioni: le loro query non risentono di quelle in esecuzione su altri warehouse dello stesso account, e i clienti Snowflake possono eseguire workloads di dati altamente performanti e prevedibili. Diverso è il discorso per il livello dei cloud services, condiviso tra gli account e con tempi meno costanti, anche se nella pratica la differenza è trascurabile.
Storage
Snowflake archivia le tabelle in un servizio di cloud storage scalabile (S3 su AWS, Azure Blob su Azure e così via). Ogni tabella 7 viene suddivisa in un certo numero di micro-partizioni immutabili. Le micro-partizioni utilizzano un formato file proprietario e closed-source sviluppato da Snowflake. L'obiettivo è mantenerle intorno ai 16 MB, con un livello di compressione elevato 8. Di conseguenza, una singola tabella può arrivare a contare milioni di micro-partizioni.
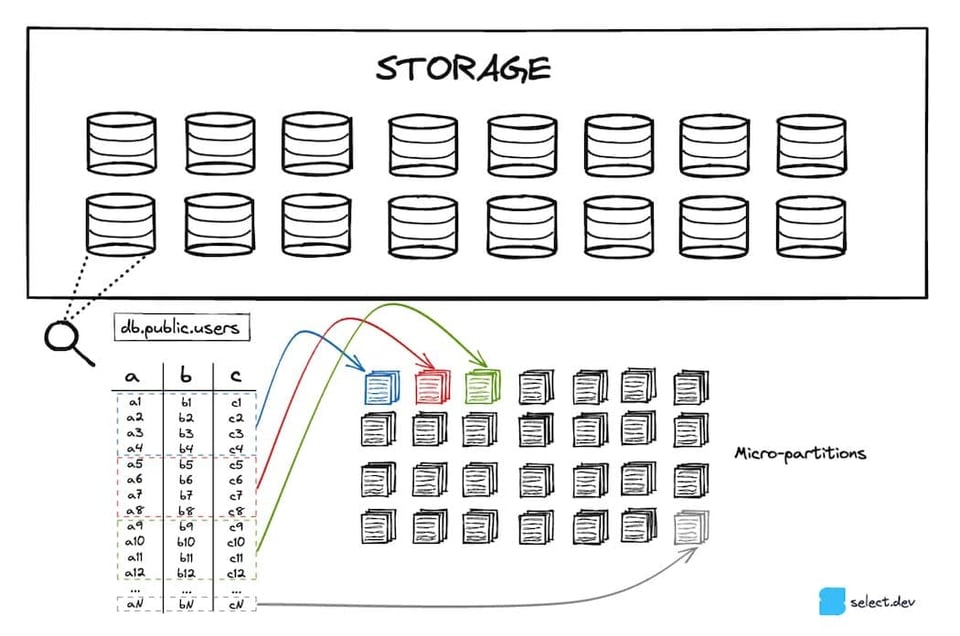
Le micro-partizioni sfruttano un formato di storage colonnare anziché il layout a righe tipicamente usato dai database OLTP come Postgres, SQLite, MySql, SQLServer e così via. Dato che le query analitiche selezionano in genere poche colonne su un ampio insieme di righe, i formati colonnari offrono prestazioni nettamente superiori.
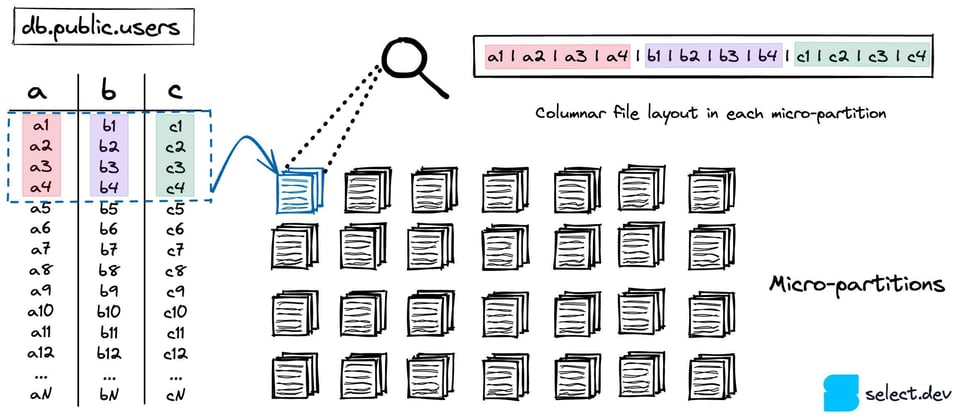
Ogni volta che viene creata una micro-partizione vengono calcolati i metadati a livello di colonna. Valore min/max, conteggio, numero di valori distinti e numero di null sono solo alcuni esempi dei metadati calcolati e memorizzati nei cloud services. Come abbiamo visto, Snowflake può sfruttare questi metadati in fase di ottimizzazione e pianificazione delle query per individuare con precisione le micro-partizioni da scansionare per una determinata query: una tecnica fondamentale nota come "pruning". Il risultato è una netta accelerazione delle query, ottenuta eliminando letture di dati superflue e lente.
Poiché le micro-partizioni sono immutabili, le operazioni DML (update, addition, delete) devono aggiungere o rimuovere interi file e ricalcolare i metadati necessari. Snowflake consiglia di eseguire le operazioni DML in batch, così da ridurre il numero di micro-partizioni riscritte e abbattere tempi di esecuzione e costi complessivi.
Dato che in Snowflake un oggetto tabella è essenzialmente una voce nei cloud services che fa riferimento a un insieme di micro-partizioni, è possibile offrire funzionalità di storage innovative come lo zero-copy cloning e il time travel. Quando si crea una nuova tabella come clone di una esistente, Snowflake crea una nuova voce di metadati che punta allo stesso insieme di micro-partizioni. Con il time travel, invece, Snowflake tiene traccia delle micro-partizioni che hanno composto una tabella nel tempo, consentendo agli utenti di accedere alla versione esatta della tabella in un determinato momento.
Note
All'epoca, i principali concorrenti di Snowflake erano Amazon Redshift e le tradizionali soluzioni on-premise come Oracle e Teradata. Tutte queste soluzioni accoppiavano storage e compute sulle stesse macchine, rendendole difficili e costose da scalare. Oggi i concorrenti di maggior peso sono nomi come BigQuery e Databricks. BigQuery ha probabilmente una quota di mercato analoga, se non superiore, grazie all'integrazione perfetta con il resto della Google Cloud Platform. Databricks è invece un concorrente più recente, dato che entrambe le aziende stanno iniziando a riposizionarsi come "data cloud".
Con la sua evoluzione verso un vero e proprio "data cloud", Snowflake sta aggiungendo rapidamente nuove funzionalità come Snowpark, Unistore, External Tables, Streamlit e un App store nativo, tutte componenti che estendono la sua architettura. In questa analisi tralasceremo queste novità per concentrarci sugli aspetti di data warehousing che oggi rappresentano l'utilizzo principale per la maggior parte dei clienti.
Perché una query venga servita dalla global result cache deve essere identica alla precedente. In più, Snowflake dispone in realtà di due cache diverse che possono incidere sulle prestazioni: una global result cache e una cache locale in ciascun warehouse. Approfondiremo entrambe in un prossimo articolo.
Oltre a servire le query già eseguite tramite la global result cache, Snowflake può elaborare alcune query come
count(*)omax(column)interamente sfruttando lo storage dei metadati. Per saperne di più, leggi il nostro articolo sulle micro-partizioni.Questo warehouse è in realtà un multi-cluster warehouse: Snowflake alloca risorse di calcolo aggiuntive quando la domanda di query supera la capacità di un singolo warehouse small. Approfondiremo i multi-cluster warehouse in un prossimo articolo.
Le cifre indicate si riferiscono ad AWS e possono differire leggermente per altri cloud provider. Non se ne garantisce l'accuratezza, dato che Snowflake non le pubblica e può modificare in qualsiasi momento i server sottostanti e le configurazioni dei warehouse. Quelle che ho riportato sono state verificate l'ultima volta nell'agosto 2022 attraverso due fonti distinte e sembrano coerenti con quanto osservato nel 2019. Non sono riuscito a verificare lo spazio su disco disponibile su ciascun nodo, ma conto di scoprirlo per via sperimentale nei prossimi mesi.
L'eccezione si ha quando si usano le external tables per archiviare i dati.
La compressione viene eseguita automaticamente da Snowflake dietro le quinte. Non compressi, questi file possono superare i 500 MB!
Ian Whitestone·Co-founder & CEO di SELECT
Ian è Co-founder e CEO di SELECT, una piattaforma SaaS per la gestione e l'ottimizzazione dei costi di Snowflake. Prima di fondare SELECT, Ian ha trascorso 6 anni alla guida di team full stack di data science ed engineering in Shopify e Capital One. In Shopify ha guidato il lavoro di ottimizzazione del data warehouse e l'aumento della visibilità sui costi.
L'architettura unica e scalabile di Snowflake gli ha permesso di affermarsi rapidamente come il data warehouse dominante di oggi. Nei prossimi articoli approfondiremo ogni singolo livello della sua architettura e vedremo come sfruttarne le funzionalità per massimizzare le prestazioni delle query e ridurre i costi.