この5年でSnowflakeは爆発的に普及し、多くの企業のデータスタックの中核を担う存在となりました。Snowflakeは2012年に誕生し、画期的なホワイトペーパーのなかで「エラスティックデータウェアハウス」と称される独自のアーキテクチャを打ち出しました。当時の競合のようにコンピュートとストレージを同一マシン上で密結合させるのではなく 1、Amazon Web Services(AWS)をはじめとするクラウド基盤の事実上無尽蔵なリソースを活かす新しい設計を提案したのです。本記事では、Snowflakeデータウェアハウスを構成する3つのレイヤー、すなわちクラウドサービス、コンピュート、ストレージを順に掘り下げていきます 2。
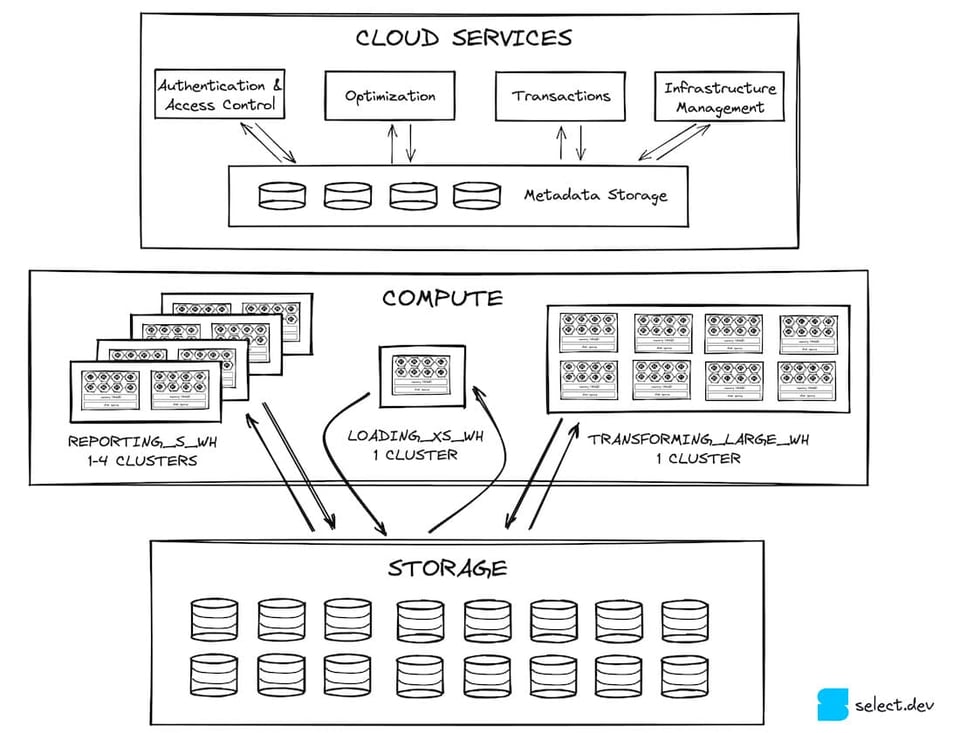
クラウドサービス
クラウドサービス層は、ユーザーがSnowflakeに対して行うあらゆる操作の入口となるレイヤーです。必要なメタデータをすべて保持するFoundationDBに支えられたステートレスなサービス群で構成されています。認証とアクセス制御(誰がSnowflakeにアクセスでき、その中で何ができるか)は、この層が担うサービスの一例です。クエリのコンパイルと最適化も、クラウドサービスが担う重要な役割の一つです。Snowflakeは、対象クエリがスキャンすべきマイクロパーティションの数を減らす(コンパイル時プルーニング)など、さまざまなパフォーマンス最適化を実施します。
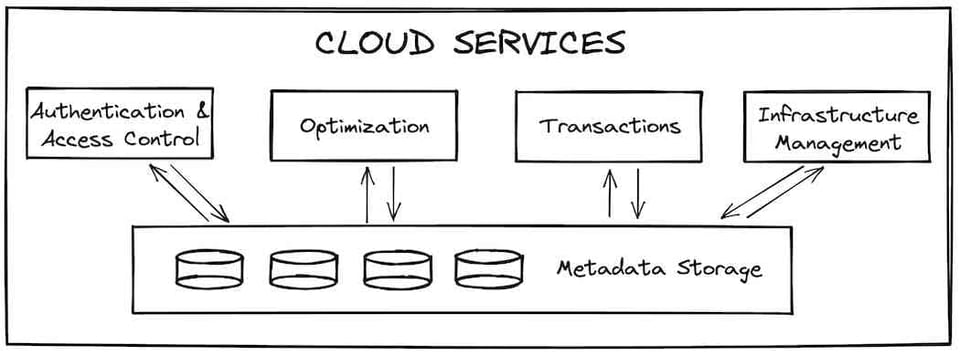
クラウドサービスは、インフラとトランザクションの管理も担います。クエリ実行のために新しい仮想ウェアハウスをプロビジョニングする必要が生じれば、クラウドサービスが確実に立ち上げます。別のトランザクションによって更新中のデータにクエリがアクセスしようとした場合は、その更新が完了するまで待ってから結果を返します。
パフォーマンス面で特に重要なのが、クエリ結果をグローバル結果キャッシュに蓄える役割です。同じクエリが再実行されたときに、極めて高速に結果を返せます 3。これにより、次に紹介するコンピュート層の負荷を大幅に軽減できます 4。
コンピュート
クラウドサービスを通過したクエリは、実行のためコンピュート層へと送られます。コンピュート層は、顧客が作成したすべての仮想ウェアハウスから構成されます。仮想ウェアハウスは、1つ以上のコンピュートインスタンス(「ノード」)を抽象化したものです。AWS上で稼働するSnowflakeアカウントであれば、ノードは1つのEC2インスタンスに相当します。Snowflakeでは、ウェアハウスのノード数をTシャツサイズで指定します。多くの場合、顧客はworkloadごとに別々のウェアハウスを用意します。下の図は、3つの仮想ウェアハウスを構えた一例です。ビジネスインテリジェンス用のsmallウェアハウス 5、Snowflakeへのデータ取り込み用のextra-smallウェアハウス、データ変換用のlargeウェアハウスという構成です。
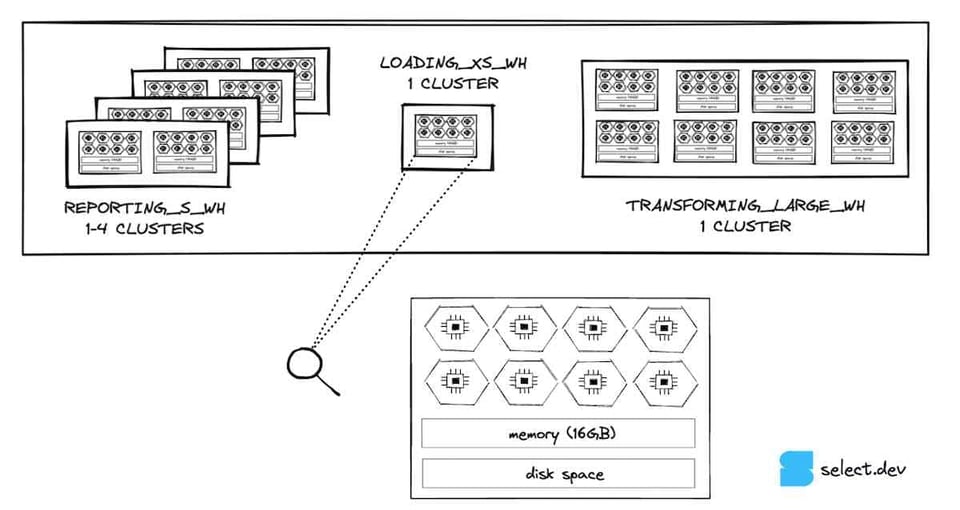
Snowflakeで最小サイズのextra-smallウェアハウスを拡大して見ると、1つのノードで構成されていることがわかります。各ノードは8コア/スレッド、16GBのメモリ(RAM)、SSDキャッシュを備えます(ただし5XLと6XLは異なるノード仕様で動作します) 6。ウェアハウスのサイズが1段階上がるごとにノード数は倍になり、スレッド数、メモリ、ディスク容量も同じく倍増します。smallウェアハウスはextra-smallの2倍のメモリ(32GB)、2倍のコア(16)、2倍のディスク容量を備え、largeウェアハウスはextra-smallの8倍のリソースを持つことになります。
Snowflakeの設計上重要なのは、稼働中の各ウェアハウスのノードが他の用途に使い回されないという点です。これにより、同一アカウント内の他のウェアハウスで実行中のクエリから影響を受けないという強力なパフォーマンス保証が得られ、Snowflakeユーザーは高性能かつ予測可能なデータworkloadを実行できます。この点は、アカウント間で共有されタイミングが必ずしも一定ではないクラウドサービス層とは対照的ですが、実用上はほとんど問題になりません。
ストレージ
Snowflakeはテーブルを、スケーラブルなクラウドストレージサービス(AWSならS3、AzureならAzure Blobなど)に格納します。すべてのテーブル 7は、不変のマイクロパーティションに分割されます。マイクロパーティションには、Snowflakeが開発した独自のクローズドソースファイル形式が使われています。Snowflakeは各マイクロパーティションを強力に圧縮したうえで、16MB前後に保つように調整しています 8。その結果、1つのテーブルに数百万ものマイクロパーティションが存在することもあります。
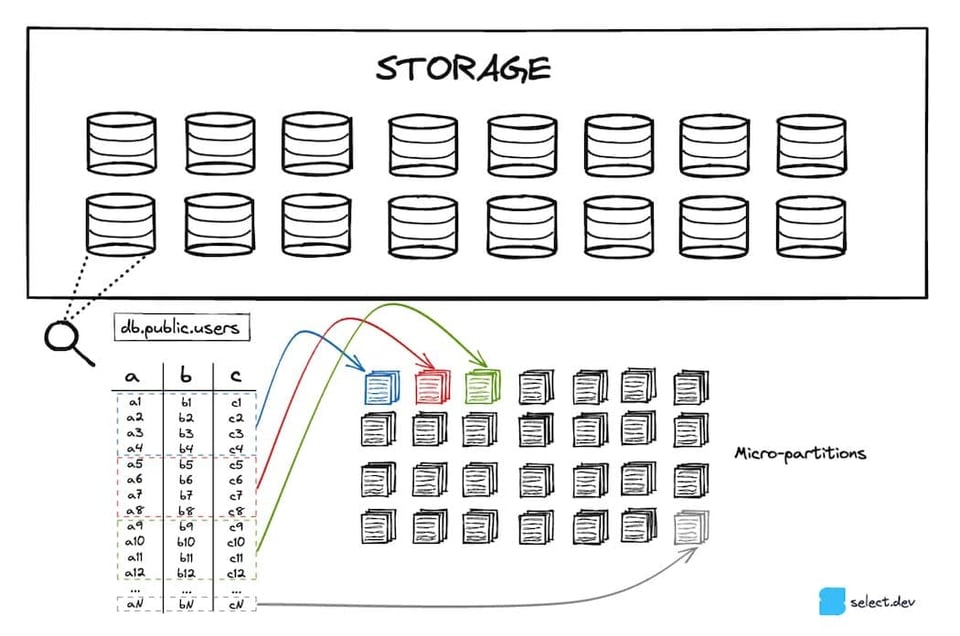
マイクロパーティションは、Postgres、SQLite、MySQL、SQLServerなどのOLTPデータベースで一般的な行ベースのレイアウトではなく、列指向のストレージ形式を採用しています。分析クエリは通常、広範囲の行から少数の列を取り出すため、列指向の方がはるかに高いパフォーマンスを発揮します。
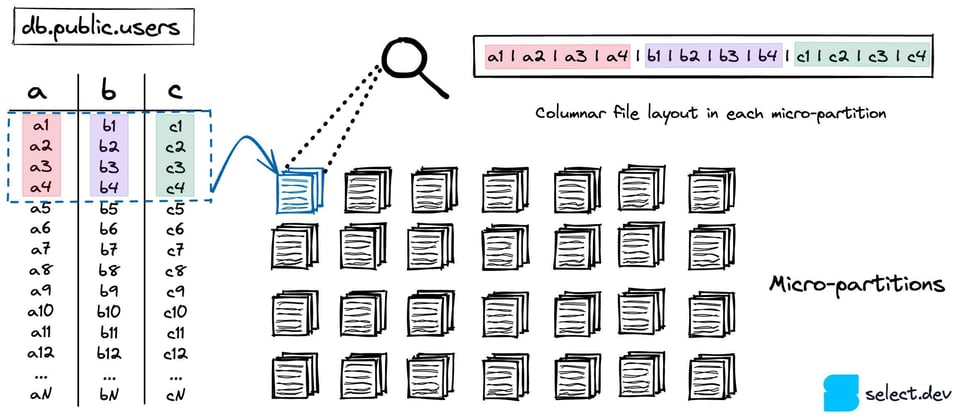
マイクロパーティションが作成されるたびに、列レベルのメタデータが計算されます。最小値・最大値、件数、ユニーク値の数、NULLの数などが、計算されてクラウドサービスに保存されるメタデータの代表例です。前述のとおり、Snowflakeはクエリの最適化や実行計画立案の段階でこのメタデータを活用し、特定のクエリで実際にスキャンすべきマイクロパーティションを正確に絞り込みます。これが「プルーニング」と呼ばれる重要な手法です。不要で時間のかかるデータ読み取りを排除することで、クエリを大幅に高速化できます。
マイクロパーティションは不変であるため、DML操作(更新、追加、削除)では対象ファイルごと追加・削除し、関連メタデータも再計算する必要があります。Snowflakeは、書き換えられるマイクロパーティションの数を抑えるためにDML操作をまとめて実行することを推奨しており、これにより総実行時間とコストの両方を削減できます。
Snowflakeのテーブルオブジェクトは、実体としてはマイクロパーティション群を参照するクラウドサービス上のエントリにすぎません。だからこそSnowflakeは、ゼロコピークローンやタイムトラベルといった革新的なストレージ機能を提供できるのです。既存テーブルのクローンとして新規テーブルを作成すると、Snowflakeは同じマイクロパーティション群を指す新しいメタデータエントリを作成します。タイムトラベルでは、テーブルがどのマイクロパーティションで構成されていたかを時系列で追跡しているため、ユーザーは特定の時点のテーブルそのものにアクセスできます。
注釈
当時のSnowflakeの主な競合は、Amazon Redshiftや、OracleやTeradataといった従来型のオンプレミス製品でした。これらの既存ソリューションはいずれもストレージとコンピュートを同一マシンに密結合させており、スケールさせるのは困難でコストもかさみました。今日のSnowflakeの主要な競合はBigQueryやDatabricksです。BigQueryはGoogle Cloud Platformの他サービスとシームレスに統合されている強みから、Snowflakeと同等かそれ以上の市場シェアを持っている可能性があります。Databricksは、両社が「データクラウド」へとポジショニングを再定義し始めたことで、新たな競合として浮上してきました。
本格的な「データクラウド」への進化に伴い、SnowflakeはSnowpark、Unistore、外部テーブル、Streamlit、ネイティブApp Storeなど、アーキテクチャを拡張する新機能を急ピッチで投入しています。本稿のアーキテクチャレビューではこれらの新機能には踏み込まず、現時点で大多数の顧客が利用しているデータウェアハウス領域に焦点を当てます。
グローバル結果キャッシュから結果が返されるには、クエリが完全に同一である必要があります。またSnowflakeには、パフォーマンス向上に寄与する2種類のキャッシュ、すなわちグローバル結果キャッシュと各ウェアハウス内のローカルキャッシュが存在します。両者の詳細は今後の記事で改めて取り上げます。
グローバル結果キャッシュから過去のクエリ結果を返すだけでなく、Snowflakeは
count(*)やmax(column)といった特定のクエリを、メタデータストレージだけで完結して処理することもできます。詳細はマイクロパーティションに関する記事をご覧ください。このウェアハウスは実際にはマルチクラスターウェアハウスであり、クエリ需要が単一のsmallウェアハウスの処理能力を超えた際にSnowflakeが追加のコンピュートリソースを割り当てます。マルチクラスターウェアハウスについては今後の記事で詳述します。
ここで示した数値はAWSの場合のもので、他のクラウドプロバイダーでは若干異なります。Snowflakeはこれらを公表しておらず、基盤となるサーバーやウェアハウス構成もいつでも変更され得るため、正確性は保証されません。本記事の数値は、2022年8月に2つの独立した情報源で最後に検証したものです。2019年に観測された情報とも整合しているようです。各ノードで利用可能なディスク容量は検証できていませんが、今後数か月のうちに実験的に確認する予定です。
例外として、データの保存に外部テーブルを使用している場合は当てはまりません。
この圧縮はSnowflakeが内部で自動的に行います。非圧縮の状態では、これらのファイルが500MBを超えることもあります!
Ian Whitestone·Co-founder & CEO of SELECT
Ianは、SaaS型のSnowflakeコスト管理・最適化プラットフォームであるSELECTのCo-founder兼CEOです。SELECTを立ち上げる前は、ShopifyとCapital Oneで6年間にわたりフルスタックのデータサイエンスおよびエンジニアリングチームを率いてきました。Shopifyでは、データウェアハウスの最適化とコストの可視化を主導しています。
独自かつスケーラブルなアーキテクチャを武器に、Snowflakeは今日のデータウェアハウス市場で圧倒的な存在感を獲得しました。今後の記事では、Snowflakeアーキテクチャの各レイヤーをさらに深掘りし、その機能を活かしてクエリパフォーマンスを最大化し、コストを抑える方法を解説していきます。