O Snowflake disparou em popularidade nos últimos 5 anos e se firmou no centro do data stack de muitas empresas. O Snowflake surgiu em 2012 com uma arquitetura única, descrita em seu white paper seminal como "o data warehouse elástico". Em vez de manter compute e storage acoplados na mesma máquina, como faziam os concorrentes da época 1, eles propuseram um novo design que tirava proveito dos recursos praticamente infinitos disponíveis em plataformas de cloud computing como a Amazon Web Services (AWS). Neste post, vamos mergulhar nas três camadas da arquitetura de data warehouse do Snowflake 2: cloud services, compute e storage.
Cloud Services
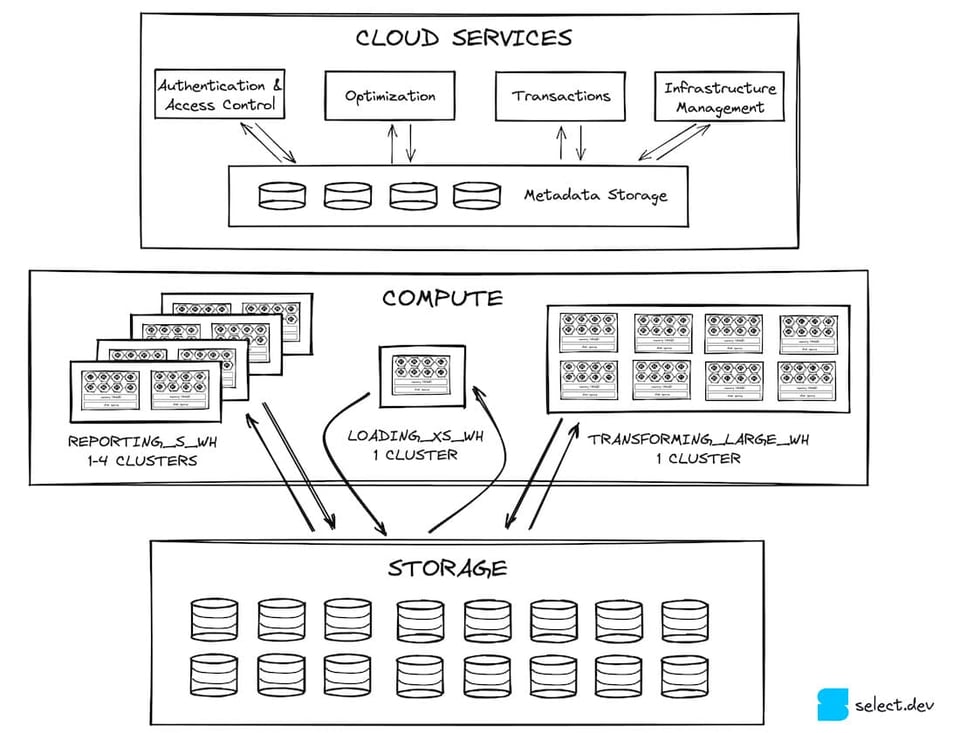
A camada de cloud services é o ponto de entrada para todas as interações de um usuário com o Snowflake. Ela é composta por serviços stateless, apoiados por um banco de dados FoundationDB que armazena todos os metadados necessários. Autenticação e controle de acesso (quem pode acessar o Snowflake e o que pode fazer dentro dele) são exemplos de serviços dessa camada. A compilação e a otimização de queries também são funções críticas dos cloud services. O Snowflake aplica otimizações de performance como a redução do número de micro-partitions que a query de um usuário precisa escanear (compile-time pruning).
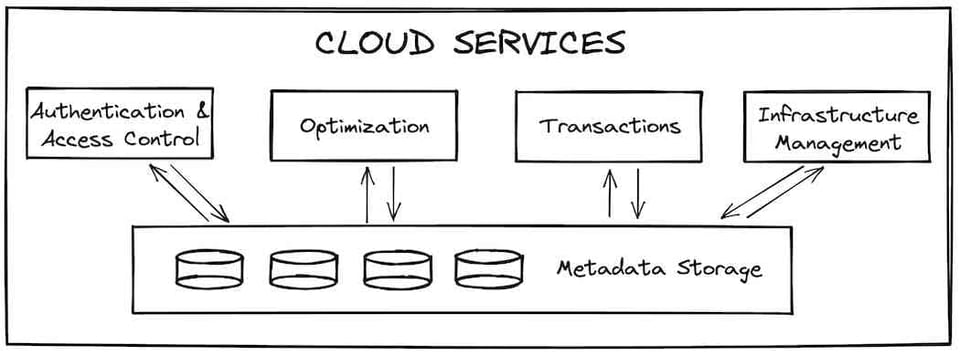
Os cloud services também cuidam da gestão de infraestrutura e de transações. Quando novos virtual warehouses precisam ser provisionados para atender uma query, os cloud services garantem que fiquem disponíveis. Se uma query tenta acessar dados que estão sendo atualizados por outra transação, a camada de cloud services aguarda a conclusão da atualização antes de retornar os resultados.
Do ponto de vista de performance, uma das funções mais importantes dos cloud services é fazer cache dos resultados de query no global result cache, de onde podem ser retornados de forma extremamente rápida se a mesma query for executada de novo 3. Isso reduz bastante a carga sobre a camada de compute 4, que veremos a seguir.
Compute
Depois de passar pelos cloud services, a query é enviada para a camada de compute para ser executada. A camada de compute é formada por todos os virtual warehouses criados pelo cliente. Os virtual warehouses são uma abstração sobre uma ou mais instâncias de compute, ou "nodes". Em contas do Snowflake rodando na Amazon Web Services, um node equivale a uma única instância EC2. O Snowflake usa tamanhos de camiseta (t-shirt sizing) para configurar quantos nodes cada warehouse terá. Em geral, os clientes criam warehouses separados para diferentes workloads. Na imagem abaixo, vemos uma configuração hipotética com 3 virtual warehouses: um small usado para business intelligence 5, um extra-small usado para carregar dados no Snowflake e um large usado para transformações de dados.
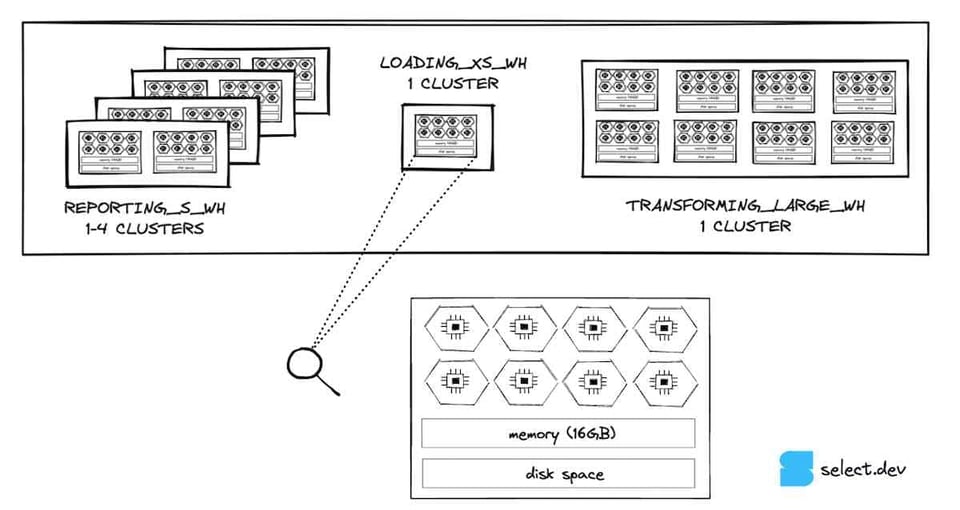
Olhando de perto o warehouse extra-small, o menor tamanho oferecido pelo Snowflake, vemos que ele é composto por um único node. Cada node tem 8 cores/threads, 16 GB de memória (RAM) e um cache SSD 6, com exceção dos 5XL e 6XL, que rodam em especificações diferentes. A cada aumento de tamanho do warehouse, o número de nodes dobra. Isso significa que o número de threads, a memória e o espaço em disco também dobram. Um warehouse size small tem o dobro de memória (32 GB), o dobro de cores (16) e o dobro de espaço em disco em relação a um extra-small. Por extensão, um warehouse large tem 8 vezes os recursos de um extra-small.
Um aspecto importante do design do Snowflake é que os nodes de cada warehouse em execução não são usados em nenhum outro lugar. Isso dá aos usuários uma forte garantia de performance: suas queries não sofrem impacto de queries rodando em outros warehouses da mesma conta, permitindo que os clientes do Snowflake executem workloads de dados com alta performance e previsibilidade. Já a camada de cloud services é compartilhada entre contas, com tempos menos consistentes — embora, na prática, isso seja irrelevante.
Storage
O Snowflake armazena suas tabelas em um serviço de cloud storage escalável (S3 se você estiver na AWS, Azure Blob no Azure, etc.). Toda tabela 7 é particionada em diversas micro-partitions imutáveis. As micro-partitions usam um formato de arquivo proprietário e fechado criado pelo Snowflake. O Snowflake busca mantê-las em torno de 16 MB, com forte compressão 8. Como resultado, pode haver milhões de micro-partitions em uma única tabela.
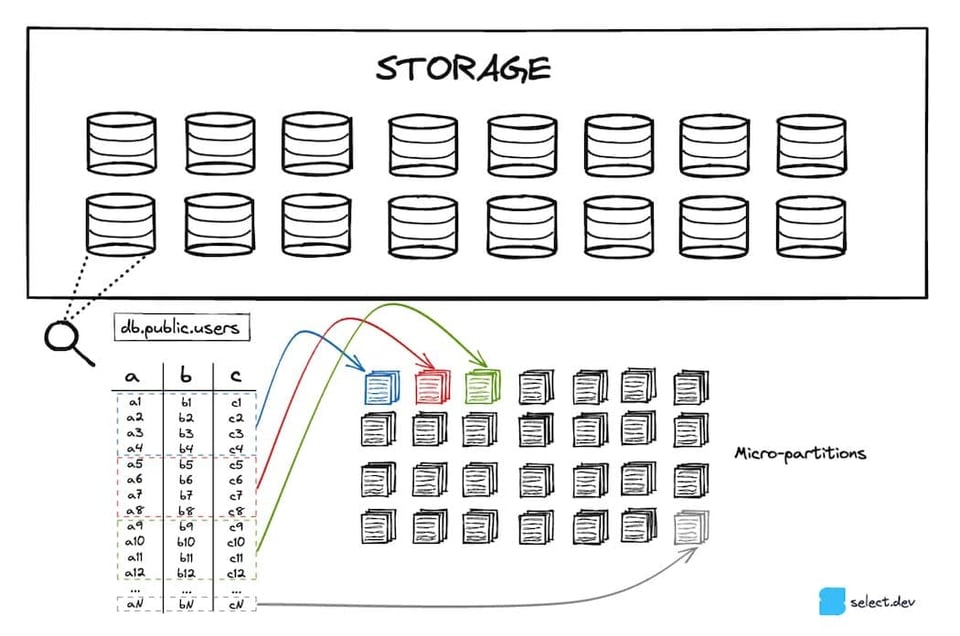
As micro-partitions usam um formato de armazenamento colunar em vez do layout baseado em linhas tipicamente adotado por bancos de dados OLTP como Postgres, SQLite, MySql, SQLServer, etc. Como queries analíticas costumam selecionar poucas colunas em um grande volume de linhas, formatos colunares entregam performance significativamente melhor.
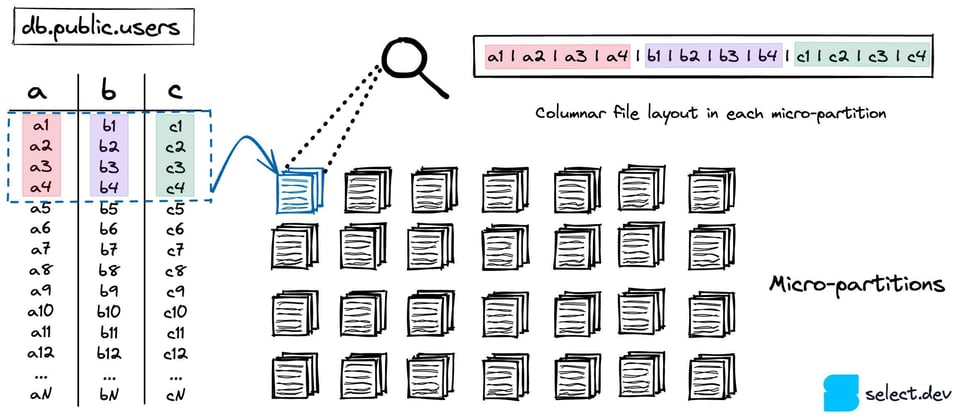
Metadados em nível de coluna são calculados sempre que uma micro-partition é criada. Valor mínimo/máximo, contagem, número de valores distintos e número de nulos são alguns exemplos dos metadados calculados e armazenados nos cloud services. Como já comentamos, o Snowflake aproveita esses metadados durante a otimização e o planejamento de queries para identificar exatamente quais micro-partitions precisam ser escaneadas em uma determinada query — uma técnica importante conhecida como "pruning". Isso acelera bastante as queries ao eliminar leituras de dados desnecessárias e lentas.
Como as micro-partitions são imutáveis, operações DML (updates, inserts, deletes) precisam adicionar ou remover arquivos inteiros e recalcular os metadados. O Snowflake recomenda executar operações DML em lotes para reduzir o número de micro-partitions reescritas, o que diminui o tempo total de execução e o custo dessas operações.
Como um objeto de tabela no Snowflake é, na essência, uma entrada nos cloud services que referencia um conjunto de micro-partitions, o Snowflake consegue oferecer recursos inovadores de storage como zero-copy cloning e time travel. Quando você cria uma nova tabela como clone de uma existente, o Snowflake cria uma nova entrada de metadados que aponta para o mesmo conjunto de micro-partitions. No time travel, o Snowflake registra quais micro-partitions compuseram a tabela ao longo do tempo, permitindo que os usuários acessem a versão exata da tabela em um determinado ponto no tempo.
Notas
Na época, os principais concorrentes do Snowflake eram o Amazon Redshift e soluções tradicionais on-premise como Oracle e Teradata. Todas elas acoplavam storage e compute nas mesmas máquinas, o que tornava o scaling difícil e caro. Hoje, os maiores concorrentes do Snowflake são nomes como BigQuery e Databricks. O BigQuery provavelmente tem participação de mercado parecida, se não maior, graças à integração nativa com o restante do Google Cloud Platform. O Databricks se tornou um novo concorrente à medida que as duas empresas passaram a se reposicionar como "data clouds".
Com sua transformação em um "data cloud" completo, o Snowflake vem adicionando rapidamente novas funcionalidades como Snowpark, Unistore, External Tables, Streamlit e uma App store nativa — todas estendendo a arquitetura do Snowflake. Vamos deixar essas novas capacidades de fora desta análise de arquitetura e focar nos aspectos de data warehousing que a maioria dos clientes usa hoje.
As queries precisam ser idênticas para serem atendidas pelo global result cache. Além disso, o Snowflake na verdade tem dois caches diferentes que podem ajudar a performance: o global result cache e um cache local em cada warehouse. Vamos detalhar os dois em um post futuro.
Além de atender queries já executadas a partir do global result cache, o Snowflake também consegue processar algumas queries como
count(*)oumax(column)inteiramente a partir do armazenamento de metadados. Saiba mais em nosso post sobre micro-partitions.Esse warehouse, na verdade, é um multi-cluster warehouse, ou seja, o Snowflake aloca recursos adicionais de compute caso a demanda de queries ultrapasse o que um único warehouse small consegue atender. Vamos abordar multi-cluster warehouses com mais profundidade em um post futuro.
Esses números são da AWS e podem variar um pouco em outros provedores de nuvem. Não há garantia de que sejam precisos, já que o Snowflake não os publica e pode alterar os servidores e configurações de warehouse subjacentes a qualquer momento. Os valores que apresentei foram validados pela última vez em agosto de 2022 por meio de duas fontes distintas. Eles parecem consistentes com o que foi observado em 2019. Não consegui validar o espaço em disco disponível em cada node, mas pretendo descobrir isso experimentalmente nos próximos meses.
A exceção é se você estiver usando external tables para armazenar seus dados.
Essa compressão é feita automaticamente pelo Snowflake nos bastidores. Sem compressão, esses arquivos podem passar de 500 MB!
Ian Whitestone · Cofundador e CEO da SELECT
Ian é Cofundador e CEO da SELECT, uma plataforma SaaS de gestão e otimização de custos do Snowflake. Antes de fundar a SELECT, Ian passou 6 anos liderando times full stack de data science e engenharia na Shopify e na Capital One. Na Shopify, Ian conduziu os esforços para otimizar o data warehouse e ampliar a observabilidade de custos.
A arquitetura única e escalável do Snowflake fez com que ele se tornasse rapidamente o data warehouse dominante da atualidade. Em posts futuros, vamos mergulhar mais fundo em cada camada da arquitetura do Snowflake e mostrar como aproveitar seus recursos para maximizar a performance de queries e reduzir custos.