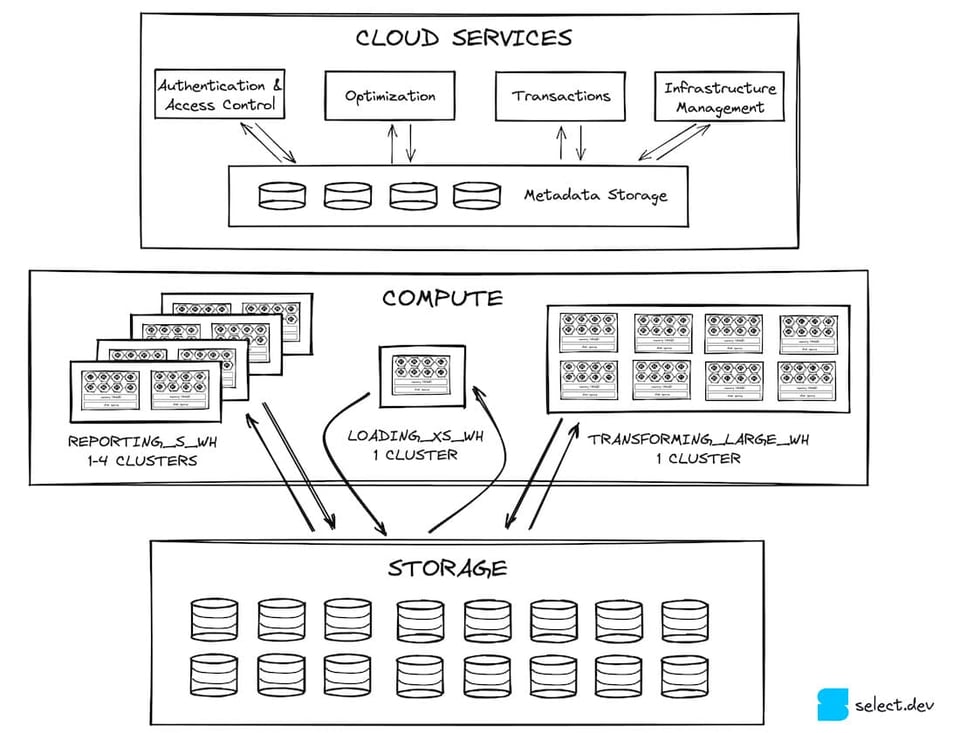
Snowflake a connu une popularité fulgurante ces cinq dernières années et s'est solidement installé au cœur de la stack data de nombreuses entreprises. Snowflake a vu le jour en 2012 avec une architecture singulière, décrite dans son white paper fondateur comme l'entrepôt de données élastique. Plutôt que de coupler compute et stockage sur une même machine comme le faisaient ses concurrents 1, Snowflake a proposé une nouvelle approche tirant parti des ressources quasi infinies offertes par les plateformes de cloud computing telles qu'Amazon Web Services (AWS). Dans cet article, nous allons explorer les trois couches de l'architecture de l'entrepôt de données Snowflake 2 : services cloud, compute et stockage.
Services cloud
La couche des services cloud est le point d'entrée de toutes les interactions d'un utilisateur avec Snowflake. Elle est constituée de services stateless, adossés à une base de données FoundationDB qui stocke l'ensemble des métadonnées nécessaires. L'authentification et le contrôle d'accès (qui peut accéder à Snowflake et ce qu'il peut y faire) sont des exemples de services présents dans cette couche. La compilation et l'optimisation des requêtes font partie des autres rôles essentiels assurés par les services cloud. Snowflake applique des optimisations de performance comme la réduction du nombre de micro-partitions qu'une requête donnée doit parcourir (pruning à la compilation).
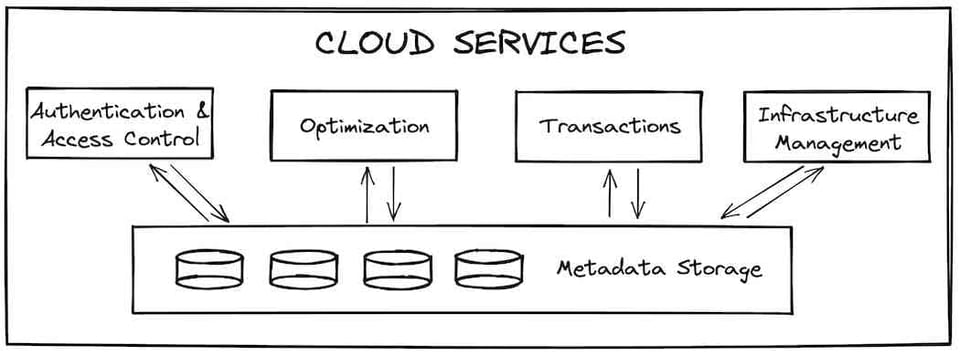
Les services cloud assurent également la gestion de l'infrastructure et des transactions. Lorsque de nouveaux virtual warehouses doivent être provisionnés pour traiter une requête, les services cloud s'assurent de leur mise à disposition. Si une requête tente d'accéder à des données en cours de mise à jour par une autre transaction, la couche des services cloud attend la fin de cette mise à jour avant de retourner les résultats.
Côté performance, l'un des rôles les plus importants des services cloud consiste à mettre en cache les résultats des requêtes dans leur global result cache, qui peut renvoyer ces résultats extrêmement rapidement si la même requête est exécutée à nouveau 3. Cela réduit considérablement la charge sur la couche compute 4, que nous aborderons ensuite.
Compute
Une fois passée par les services cloud, la requête est transmise à la couche compute pour exécution. La couche compute regroupe l'ensemble des virtual warehouses créés par un client. Les virtual warehouses constituent une abstraction au-dessus d'une ou plusieurs instances de compute, ou nœuds. Pour les comptes Snowflake hébergés sur Amazon Web Services, un nœud correspond à une instance EC2. Snowflake recourt à un dimensionnement en tailles de t-shirt pour ses warehouses afin de configurer leur nombre de nœuds. Les clients créent généralement des warehouses distincts selon les workloads. Dans l'image ci-dessous, on observe une configuration hypothétique avec 3 virtual warehouses : un small dédié à la business intelligence 5, un extra-small utilisé pour le chargement des données dans Snowflake, et un large pour les transformations de données.
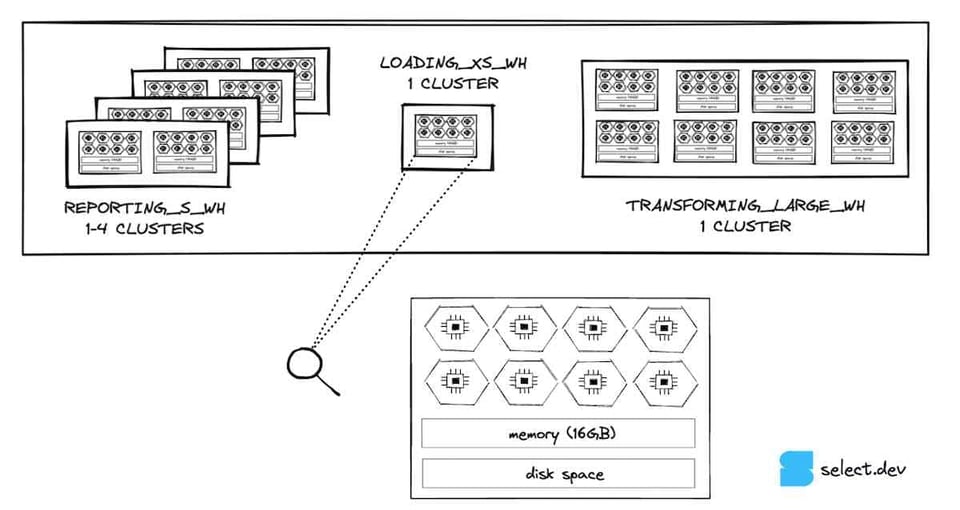
Si l'on zoome sur le warehouse extra-small, la plus petite taille proposée par Snowflake, on constate qu'il se compose d'un seul nœud. Chaque nœud dispose de 8 cœurs/threads, 16 Go de mémoire (RAM) et d'un cache SSD 6, à l'exception des tailles 5XL et 6XL qui reposent sur des spécifications de nœud différentes. À chaque augmentation de taille, le nombre de nœuds du warehouse double. Le nombre de threads, la mémoire et l'espace disque doublent donc également. Un warehouse small disposera de deux fois plus de mémoire (32 Go), de deux fois plus de cœurs (16) et du double d'espace disque par rapport à un extra-small. Par extension, un warehouse large disposera de 8 fois les ressources d'un extra-small.
Un aspect important de la conception de Snowflake : les nœuds de chaque warehouse en cours d'exécution ne sont utilisés nulle part ailleurs. Cela offre aux utilisateurs une solide garantie de performance : leurs requêtes ne seront pas impactées par celles qui s'exécutent sur d'autres warehouses du même compte, ce qui permet aux clients Snowflake d'exécuter des workloads data hautement performants et prévisibles. À l'inverse, la couche des services cloud est partagée entre les comptes, avec des temps de réponse moins constants — bien qu'en pratique cela soit sans conséquence.
Stockage
Snowflake stocke vos tables dans un service de stockage cloud évolutif (S3 sur AWS, Azure Blob sur Azure, etc.). Chaque table 7 est partitionnée en un certain nombre de micro-partitions immuables. Les micro-partitions utilisent un format de fichier propriétaire et fermé conçu par Snowflake. Snowflake cherche à maintenir leur taille autour de 16 Mo, fortement compressées 8. Une même table peut ainsi compter des millions de micro-partitions.
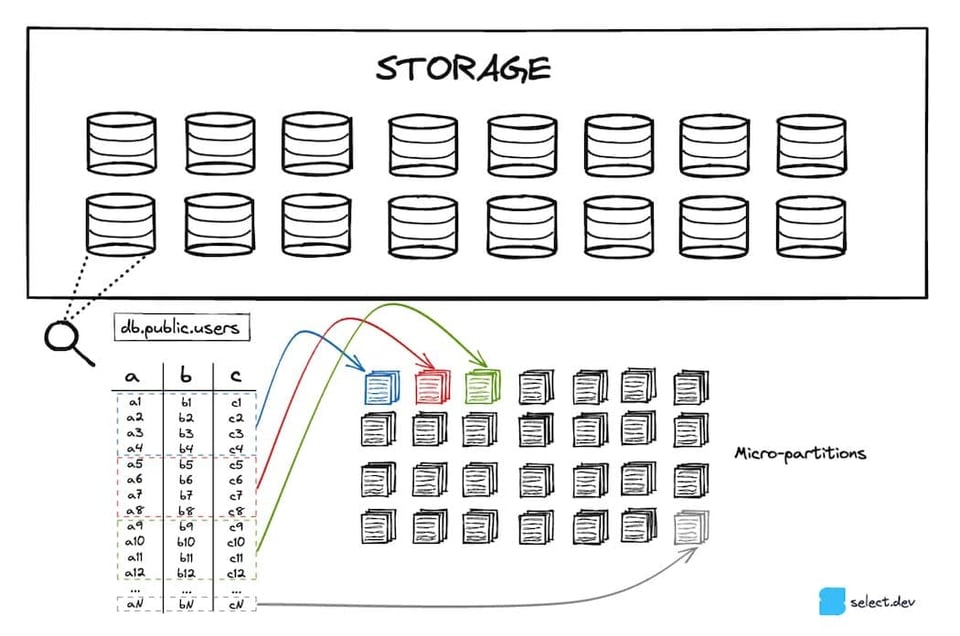
Les micro-partitions s'appuient sur un format de stockage colonnaire plutôt que sur l'organisation par lignes habituellement utilisée par les bases OLTP comme Postgres, SQLite, MySQL, SQLServer, etc. Comme les requêtes analytiques ne sélectionnent généralement que quelques colonnes sur un large ensemble de lignes, les formats colonnaires offrent des performances nettement supérieures.
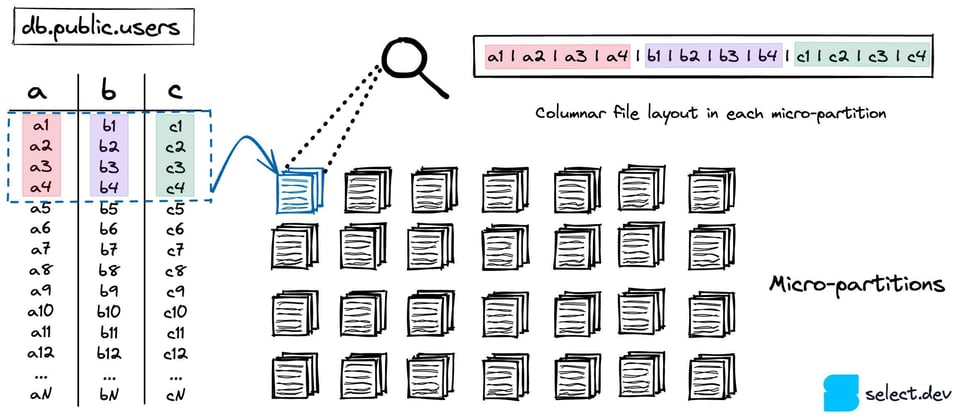
Des métadonnées au niveau des colonnes sont calculées à chaque création d'une micro-partition. La valeur min/max, le nombre de lignes, le nombre de valeurs distinctes et le nombre de valeurs nulles en sont quelques exemples ; elles sont calculées et stockées dans les services cloud. Comme vu plus haut, Snowflake peut exploiter ces métadonnées lors de l'optimisation et de la planification des requêtes pour identifier précisément les micro-partitions à scanner pour une requête donnée, une technique essentielle dite du pruning. Cela accélère considérablement les requêtes en évitant des lectures de données inutiles et coûteuses en temps.
Les micro-partitions étant immuables, les opérations DML (mises à jour, ajouts, suppressions) doivent ajouter ou supprimer des fichiers entiers et recalculer les métadonnées associées. Snowflake recommande d'effectuer les opérations DML par lots afin de réduire le nombre de micro-partitions réécrites, ce qui diminue le temps d'exécution total et le coût des opérations.
Puisqu'un objet table dans Snowflake est essentiellement une entrée des services cloud qui référence une collection de micro-partitions, Snowflake peut proposer des fonctionnalités de stockage innovantes comme le zero-copy cloning et le time travel. Lorsque vous créez une table comme clone d'une table existante, Snowflake se contente de créer une nouvelle entrée de métadonnées qui pointe vers le même ensemble de micro-partitions. Avec le time travel, Snowflake suit dans le temps les micro-partitions qui composaient une table, permettant ainsi aux utilisateurs d'accéder à la version exacte d'une table à un instant donné.
Notes
À l'époque, les principaux concurrents de Snowflake étaient Amazon Redshift et les offres traditionnelles on-premise comme Oracle et Teradata. Ces solutions couplaient toutes le stockage et le compute sur les mêmes machines, ce qui les rendait difficiles et coûteuses à faire évoluer. Aujourd'hui, les plus grands concurrents de Snowflake sont des acteurs comme BigQuery et Databricks. BigQuery détient probablement une part de marché comparable, voire supérieure, grâce à son intégration fluide avec le reste de Google Cloud Platform. Databricks est devenu un nouveau concurrent à mesure que les deux entreprises se repositionnent comme des data clouds.
Avec son virage vers un véritable data cloud, Snowflake ajoute rapidement de nouvelles fonctionnalités comme Snowpark, Unistore, External Tables, Streamlit et un App store natif — autant d'éléments qui étendent l'architecture de Snowflake. Nous laisserons de côté ces nouvelles capacités dans cette revue d'architecture pour nous concentrer sur les aspects data warehousing utilisés par la majorité des clients aujourd'hui.
Les requêtes doivent être strictement identiques pour être servies depuis le global result cache. Par ailleurs, Snowflake dispose en réalité de deux caches distincts qui peuvent améliorer les performances : un global result cache et un cache local dans chaque warehouse. Nous les détaillerons dans un prochain article.
En plus de servir les requêtes précédemment exécutées depuis le global result cache, Snowflake peut également traiter certaines requêtes comme
count(*)oumax(column)entièrement à partir du stockage des métadonnées. Pour en savoir plus, consultez notre article sur les micro-partitions.Ce warehouse est en réalité un multi-cluster warehouse, ce qui signifie que Snowflake allouera des ressources de compute supplémentaires si la demande dépasse ce qu'un seul warehouse small peut traiter. Nous reviendrons en détail sur les multi-cluster warehouses dans un prochain article.
Ces chiffres concernent AWS et peuvent légèrement différer chez d'autres cloud providers. Ils ne sont pas garantis exacts puisque Snowflake ne les publie pas et peut modifier à tout moment les serveurs sous-jacents et les configurations des warehouses. Ces chiffres ont été validés pour la dernière fois en août 2022 via deux sources distinctes. Ils semblent cohérents avec ce qui avait été observé en 2019. Je n'ai pas pu vérifier l'espace disque disponible sur chaque nœud, mais je prévois de le déterminer expérimentalement dans les mois à venir.
L'exception à cette règle concerne l'utilisation d'external tables pour stocker vos données.
Cette compression est effectuée automatiquement par Snowflake en arrière-plan. Non compressés, ces fichiers peuvent dépasser 500 Mo !
Ian Whitestone·Co-founder & CEO of SELECT
Ian est Co-founder & CEO de SELECT, une plateforme SaaS de gestion et d'optimisation des coûts Snowflake. Avant de fonder SELECT, Ian a passé 6 ans à diriger des équipes full stack data science & engineering chez Shopify et Capital One. Chez Shopify, Ian a piloté les travaux d'optimisation de leur entrepôt de données et l'amélioration de l'observabilité des coûts.
Grâce à son architecture unique et évolutive, Snowflake s'est rapidement imposé comme l'entrepôt de données de référence aujourd'hui. Dans de prochains articles, nous explorerons en détail chaque couche de l'architecture Snowflake et verrons comment tirer parti de ses fonctionnalités pour maximiser les performances des requêtes et réduire les coûts.