Dies ist der zweite Teil unserer Reihe zum Data Loading in Snowflake. Im ersten Beitrag haben wir die fünf Optionen für das Data Loading vorgestellt. In diesem Beitrag gehen wir der gängigsten Methode der Datenaufnahme auf den Grund: Batch Data Loading. Wir behandeln:
- Wie Sie Ihre Dateien vor dem Laden partitionieren und dimensionieren
- Wie Sie Ihren Stage aufsetzen
- Wie Sie den Befehl COPY INTO einsetzen
- Worauf Sie bei der Größe des Virtual Warehouse achten sollten
- Wann Serverless statt selbstverwalteter Warehouses sinnvoll ist
Überblick: Dateien vorbereiten
Ob Sie Daten im Batch oder in Echtzeit laden – Sie müssen in jedem Fall einen Satz Dateien zum Laden vorbereiten. Zunächst entscheiden Sie, wie Ihre Dateien im Cloud Storage partitioniert (organisiert) werden. Das hat erheblichen Einfluss darauf, wie viel Zeit Snowflake für das Scannen des Cloud Storage und das Auflisten aller verfügbaren Dateien aufwenden muss. Anschließend sollten Sie überlegen, wie Sie Ihre Dateien zu optimalen Dateigrößen bündeln, damit die zum Laden verwendeten Virtual Warehouses voll ausgelastet werden. Zuletzt wählen Sie ein Dateiformat und konfigurieren Ihr Stage-Objekt.
Datei-Partitionierung
Statt alle Dateien in einem einzigen Verzeichnis abzulegen, sollten Sie sie entlang logischer Pfade oder Dimensionen wie Datum bzw. Uhrzeit strukturieren.
Wenn Sie Dateien beispielsweise in S3 ablegen, könnten Sie sie nach Datum sortieren:
s3://my-data-bucket/2023/12/01/dataFile1.csvs3://my-data-bucket/2023/12/01/dataFile2.csvs3://my-data-bucket/2023/12/02/dataFile3.csvs3://my-data-bucket/2023/12/02/dataFile4.csvs3://my-data-bucket/2023/12/03/dataFile5.csv
Sie können noch einen Schritt weitergehen und zusätzliche Dimensionen zur Gruppierung hinzufügen. Soll etwa die Organisation nach Abteilung berücksichtigt werden, könnten die Dateien so abgelegt sein:
s3://my-data-bucket/finance/2023/12/01/dataFile1.csvs3://my-data-bucket/finance/2023/12/01/dataFile2.csvs3://my-data-bucket/marketing/2023/12/02/dataFile3.csvs3://my-data-bucket/marketing/2023/12/02/dataFile4.csv
Entscheidend ist: Organisieren Sie Ihre Dateien so, wie Sie sie später in Snowflake laden möchten. Ziel ist, die Anzahl der von Snowflake zu scannenden Dateien zu reduzieren. Auch wenn Snowflake automatisch protokolliert, welche Dateien bereits geladen wurden, kann das Auflisten aller Dateien innerhalb eines Stage sehr zeitaufwendig sein.
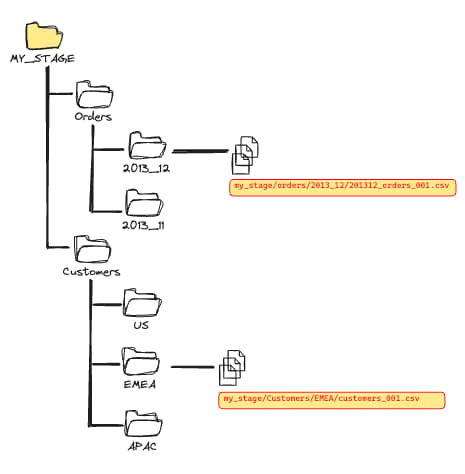
Wenn Sie Dateien in solchen Verzeichnissen organisieren, muss Snowflake nur die Dateien innerhalb dieser Verzeichnisse scannen – nicht den gesamten Stage. Sobald diese Struktur steht, kombinieren Sie Pfadfilter mit dem Schlüsselwort PATTERN.
Sehen Sie sich die beiden folgenden Beispiele an.
Dieses Beispiel scannt alle Dateien im angegebenen Stage, obwohl das Schlüsselwort PATTERN verwendet wird. Der Grund: PATTERN wird erst angewendet, nachdem alle Dateien im Stage gescannt wurden.
COPY INTO raw_table
FROM @my_stage
PATTERN='.*[.]csv'
Damit Snowflake das aufwendige Scannen unnötiger Dateien überspringt, müssen Sie einen Pfadfilter setzen. Dieses zweite Beispiel scannt nur Dateien im Verzeichnis /orders/2023_12 und findet darin alle CSV-Dateien.
COPY INTO raw_table
FROM @my_stage/orders/2013_12
PATTERN='.*[.]csv'
Optimale Dateigrößen für das Laden
Den größten Einfluss auf die Effizienz beim Data Loading haben Anzahl und Größe der zu ladenden Dateien.
Snowflake empfiehlt Dateigrößen zwischen 100 und 250 MB (komprimiert). Haben Sie viele Dateien deutlich über 250 MB, sollten Sie sie vor dem Laden aufteilen. Liegen umgekehrt zu viele kleine Dateien (<10 MB) vor, fassen Sie sie vorher zusammen.
Hintergrund ist die optimale Auslastung Ihres Virtual Warehouse: Durch paralleles Laden lassen sich alle verfügbaren Kerne bzw. CPU-Threads ausschöpfen.
Sehen Sie sich die folgende Abbildung an. Es macht einen enormen Unterschied, ob Sie eine einzelne 200-GB-Datei laden und damit nur 2 % eines XL-Warehouse nutzen (das bis zu 128 Dateien parallel verarbeiten kann) oder ob Sie die Datei in viele kleinere Dateien aufteilen und das Warehouse voll auslasten!
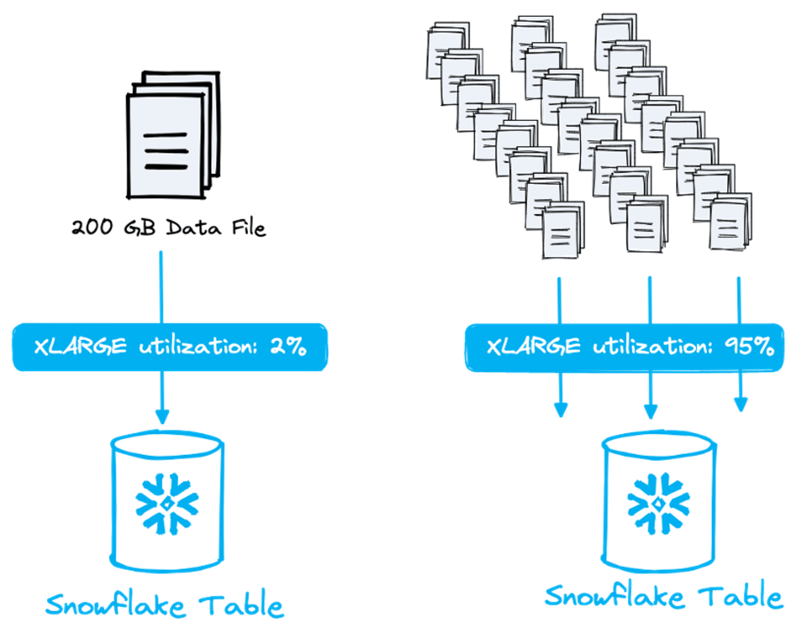
Jede Warehouse-Größe kann eine unterschiedliche Anzahl an Dateien parallel verarbeiten. Mit jeder Vergrößerung verdoppelt sich die Anzahl der Nodes. Jede Node verfügt über 8 Threads, und jeder Thread kann eine Datei verarbeiten. Das kleinste Warehouse (XS) mit einer einzelnen Node und 8 Threads kann also bis zu 8 Dateien parallel verarbeiten!
| Warehouse-Größe | Anzahl Threads / verarbeitbare Dateien |
|---|---|
| XS | 8 |
| S | 16 |
| M | 32 |
| L | 64 |
| XL | 128 |
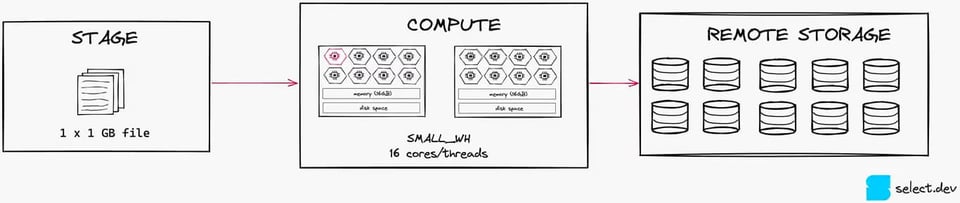
Zur Verdeutlichung dieser Effekte zeigt die folgende Abbildung: Bei einer einzelnen 1-GB-Datei nutzen wir auf einem Small Warehouse nur 1 von 16 Threads.
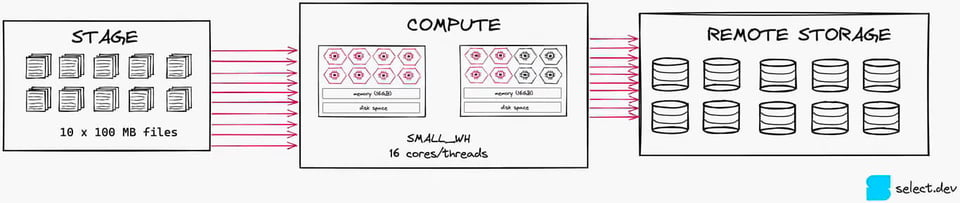
Teilen Sie diese Datei stattdessen in zehn Dateien zu je 100 MB auf, nutzen Sie 10 von 16 Threads. Dieses Maß an Parallelisierung ist deutlich besser, da die vorhandenen Compute-Ressourcen besser ausgelastet werden. Anmerkung: In diesem Fall wäre ein XSMALL die bessere Wahl.
Einen Stage einrichten
Beim Batch Data Loading arbeiten Sie mit drei weiteren Snowflake-Ressourcen:
- Dem Objekt FILE FORMAT, das das Format der Dateien definiert
- Dem Objekt STORAGE INTEGRATION, das die Zugriffsinformationen für Cloud-Storage-Standorte kapselt
- Dem Objekt STAGE, das beschreibt, wo die Dateien liegen und wie Snowflake auf diesen Speicherort zugreift
Sehen wir uns die drei im Detail an.
File Format
In Snowflake gibt es mehrere Möglichkeiten, das File Format zu definieren:
- Als Teil des
COPY-Befehls - Als Teil der
STAGE-Definition - Als eigenständiges Objekt
Als Best Practice empfiehlt es sich, das File Format als eigenständiges Objekt anzulegen – so lässt es sich in Ihren Data-Loading-Vorgängen unkompliziert wiederverwenden. Neben der Wiederverwendung steigt auch die Wartbarkeit deutlich. Müssen Sie etwas am File Format ändern (z. B. Trennzeichen, Header überspringen usw.), passen Sie es zentral am Objekt an. Sie müssen nicht jede einzelne Pipeline anfassen. Ein weiterer Vorteil: Sie steuern den Zugriff auf die Formate über das RBAC-Modell von Snowflake.
Beispiel: File Format anlegen
Nehmen wir eine CSV-Datei wie diese:

Das passende File-Format-Objekt definieren Sie so:
CREATE OR REPLACE FILE FORMAT my_csv
TYPE = csv
FIELD_DELIMITER = ‘,’
SKIP_HEADER = 1
NULL_IF = ''
Weitere Details finden Sie in der Snowflake-Dokumentation.
Snowflake-File-Format-Optionen
Snowflake unterstützt zahlreiche Dateiformate:
- CSV
- JSON
- AVRO
- ORC
- Parquet
- XML
Die Optionen zu jedem Dateiformat finden Sie in der Dokumentation.
Storage Integration
Das Storage-Integration-Objekt fungiert als Sicherheits-Layer für einen Stage. Damit lassen sich Stages erstellen, ohne dass Zugangsdaten geteilt oder in Snowflake gespeichert werden. Sie sind zudem wiederverwendbar: einmal definieren, mit beliebig vielen Stages nutzen. Mit einem Storage-Integration-Objekt müssen Entwickler nicht wissen, welche Rollen oder Zugangsdaten für den Zugriff auf die Dateien nötig sind – sie verweisen ihren Stage einfach auf das passende Storage-Integration-Objekt. Das entspricht der Best Practice der Funktionstrennung.
Hier ein Beispiel zum Anlegen eines Storage-Integration-Objekts für Amazon S3:
CREATE STORAGE INTEGRATION s3_int
TYPE = EXTERNAL_STAGE
STORAGE_PROVIDER = 'S3'
ENABLED = TRUE
STORAGE_AWS_ROLE_ARN = 'arn:aws:iam::00123456789:role/myrole
STORAGE_ALLOWED_LOCATIONS = ('s3://bucket1', 's3://bucket2')
STORAGE_BLOCKED_LOCATIONS = ('s3://bucket3/sensitive_data/')
Dabei fallen mehrere Dinge auf:
- Das Objekt benötigt den AWS ARN der IAM-Rolle. Sie müssen also wahrscheinlich mit Ihren AWS-Cloud-Admins zusammenarbeiten, um eine Zugriffsrolle für Snowflake einzurichten – sofern Sie diese nicht bereits haben.
- Sie können mehrere Buckets oder Standorte für eine einzelne Storage Integration definieren. Das ist praktisch, denn so lässt sich dieselbe Storage Integration für mehrere S3-Buckets oder Datenpipelines wiederverwenden.
Mehr zu Storage Integrations finden Sie in den Snowflake-Docs.
Stage
Nachdem wir die Objekte File Format und Storage Integration angelegt haben, können wir unseren Stage erstellen.
Ein Stage ist eine Beschreibung eines Speicherorts. Er definiert, wo die Datendateien für die Aufnahme liegen. Es gibt zwei Arten von Stages:
- Interne Stages, die Teil Ihres Snowflake-Accounts sind
- Externe Stages, die typischerweise auf Object-Storage-Standorte (etwa einen AWS-S3-Bucket) bei Ihrem Cloud-Anbieter verweisen
Als Best Practice empfehlen wir, wo immer möglich externe Stages zu nutzen – aus zwei Gründen:
- Die meisten Snowflake-Kunden haben ihre Datendateien bereits im Cloud Storage liegen. Daher ist es sinnvoll, einen externen Stage zu definieren, der auf diese Dateien zeigt.
- Wenn Sie eine Kopie Ihrer Rohdaten außerhalb von Snowflake behalten, können Sie diese Dateien problemlos auch mit anderen Systemen nutzen.
Wenn Sie der Best Practice gefolgt sind und separate File Format- und Storage Integration-Objekte definiert haben, ist das Anlegen eines Stage denkbar einfach. Hier ein Beispiel für einen externen Stage, der auf einen Speicherort in AWS S3 zeigt:
CREATE STAGE my_s3_stage
STORAGE_INTEGRATION =s3_int
URL = 's3://bucket1/path1/'
FILE_FORMAT= my_csv
Wie bereits erwähnt, können Sie alternativ auf separate File-Format- und Storage-Integration-Objekte verzichten und alle relevanten Eigenschaften direkt im Stage definieren.
So nutzen Sie den COPY-INTO-Befehl
Sobald Sie die nötigen FILE-FORMAT-, STAGE- und STORAGE-INTEGRATION-Objekte eingerichtet haben, können Sie Daten aus Ihrem Cloud-Storage-Anbieter in Snowflake laden. Dafür nutzen Sie den COPY-Befehl.
Der COPY-Befehl ist eine Snowflake-Funktion, die sowohl für das Laden als auch für das Entladen von Daten verwendet wird – mit jeweils unterschiedlichen Parametern. Sehen wir uns an, wie Sie den COPY-Befehl für Datenimporte einsetzen.
Grundlegende Nutzung
In seiner einfachsten Form sieht der COPY-Befehl etwa so aus:
COPY INTO mytable
FROM @my_s3_stage
Diese Einfachheit ergibt sich daraus, dass wir das File Format bereits im Stage-Objekt definiert haben. Weitere Parameter oder Einstellungen sind daher nicht nötig. Details finden Sie in der COPY-Command-Dokumentation.
Einfache Datentransformationen durchführen
Der COPY-Befehl unterstützt auch einfache Datentransformationen über das SELECT-Statement. Möglich sind etwa das Auslassen von Spalten, deren Neusortierung oder ein Cast in einen anderen Datentyp. Sie können semi-strukturierte Daten zudem mit FLATTEN in einzelne Spalten zerlegen oder einen CURRENT_TIMESTAMP als Audit-Spalte hinzufügen.
Einzelne Spalten im SELECT-Statement werden über das Dollarzeichen zusammen mit der Spaltenposition referenziert: $1, $2, $3, etc.
Hier ein Beispiel, in dem wir nur die erste, zweite, sechste und siebte Spalte aus der bereitgestellten Datei auswählen:
COPY INTO home_sales(city, zip, sale_date, price)
FROM (
SELECT t.$1, t.$2, t.$6, t.$7
FROM @mystage/sales.csv.gz t
)
Folgende Operationen werden im COPY-Statement nicht unterstützt:
WHEREORDER BYLIMITFETCHTOPJOINGROUP BY
Metadaten des COPY-Befehls
Der COPY-Befehl erzeugt Metadaten, die sich aus verschiedenen Tabellenfunktionen bzw. Views abrufen lassen:
COPY_HISTORY– eine Tabellenfunktion im Schemasnowflake.information_schemaLOAD_HISTORY– eine Tabellenfunktion im Schemasnowflake.information_schemaLOAD_HISTORY– ein View im Schemasnowflake.account_usage
Diese Metadaten enthalten Informationen zu jeder geladenen Datei, etwa Dateiname, Zeilenanzahl, Fehleranzahl und Zieltabelle. Sie verhindern, dass dieselbe Datei mehrfach in Snowflake geladen wird. Die Load-Metadaten verfallen nach 64 Tagen. Müssen Sie dieselbe Datei dennoch mehrfach laden, lässt sich mit der COPY-Option FORCE = TRUE ein erneutes Laden erzwingen.
Virtual-Warehouse-Größe beim Data Loading – worauf achten?
Der COPY-Befehl benötigt ein aktives Virtual Warehouse, um die Dateien zu verarbeiten und zu laden. Bei Snowflake Virtual Warehouses zahlen Sie für jede Sekunde, in der das Warehouse läuft – mit einer Mindestabrechnungsdauer von 60 Sekunden bei jedem Start.
Bei der Wahl der richtigen Warehouse-Größe – speziell fürs Data Loading – sollten Sie zwei Punkte beachten:
- Wie eingangs besprochen, sollten Sie Ihre Dateien so bündeln, dass sie rund 100 MB bis 250 MB groß (komprimiert) sind. So stehen genügend Dateien zur Verfügung, um alle Verarbeitungs-Threads des Warehouse effektiv zu nutzen (statt einer großen Datei, die nur auf einem einzigen Thread verarbeitet werden kann). Umgekehrt verursachen zu viele kleine Dateien unnötigen Overhead.
- Verwenden Sie immer die kleinstmögliche Warehouse-Größe, mit der Sie Ihre SLAs einhalten. Ein Praxisbeispiel dazu finden Sie in der Fallstudie unten.
Eine größere Warehouse-Größe führt häufig zu ungenutzten Kernen bzw. Threads, weil schlicht nicht genug Dateien vorhanden sind. Zudem werden alle Dateien in wenigen Sekunden abgearbeitet, abgerechnet wird aber dennoch der Mindestzeitraum von 1 Minute. Daher empfehlen wir, mit der kleinstmöglichen Warehouse-Größe zu starten und sie nur dann zu vergrößern, wenn die Daten für Ihre SLAs nicht schnell genug geladen werden.
Hypothetisches Warehouse Sizing fürs Data Loading
Um diese Konzepte zu festigen, schauen wir uns ein hypothetisches Beispiel an.
Stellen Sie sich vor, Sie müssen täglich 1 GB Daten laden. Da das Laden einer einzigen großen Datei ineffektiv ist, werden die Dateien in 100-MB-Blöcken (10 Dateien) erzeugt. Wir gehen von einem Snowflake-Credit-Preis von 3 $/Credit aus.
| Warehouse-Größe | Anzahl Kerne | Auslastung | Laufzeit | Abgerechnete Zeit | Kosten/Tag | Kosten/Jahr |
|---|---|---|---|---|---|---|
| XS | 32 | ~30 % | 10 s | 60 s | 0,20 $ | 73 $ |
| M | 8 | ~100 % | 50 s | 60 s | 0,05 $ | 18,25 $ |
Mit dem Medium-Warehouse erreichen wir bestenfalls ~30 % Auslastung, da nur 10 Dateien zu verarbeiten sind, aber 32 Kerne zur Verfügung stehen. Die 8 Kerne des X-Small-Warehouse hingegen lassen sich vollständig auslasten. Zwar verarbeitet das Medium-Warehouse die Dateien fünfmal schneller als das X-Small-Warehouse, kostet am Ende aber das Vierfache – wegen der 50 Sekunden Leerlaufzeit, die ebenfalls bezahlt werden müssen.
Praxisbeispiel: Warehouse Sizing fürs Data Loading
Wie sich das in der Praxis auswirkt, zeigen die Ergebnisse aus einem realen Snowflake-Account.
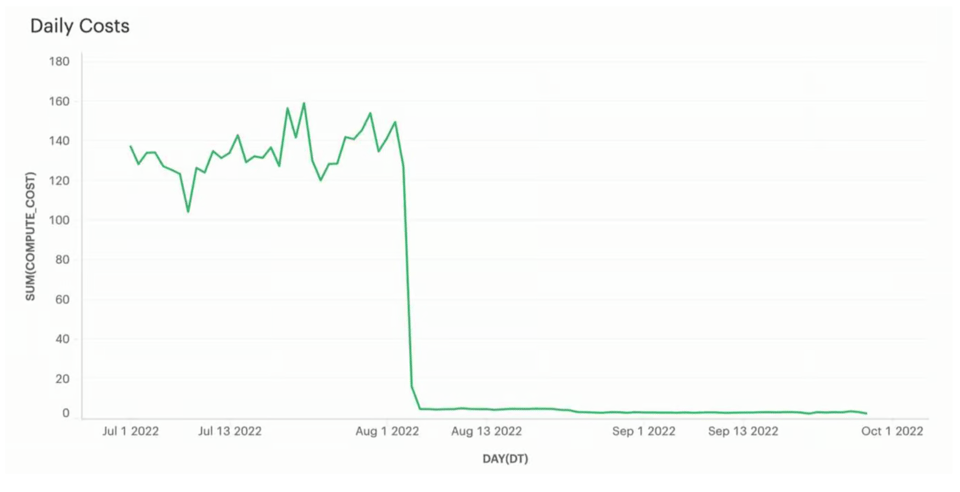
Ursprünglich nutzte diese Data-Loading-Pipeline ein Large Warehouse. Es lud alle Dateien in etwa 5 Sekunden und stand dann weitere 55 Sekunden im Leerlauf. Nach dem Wechsel auf X-Small stieg die Ladezeit im Schnitt auf ~20 Sekunden.
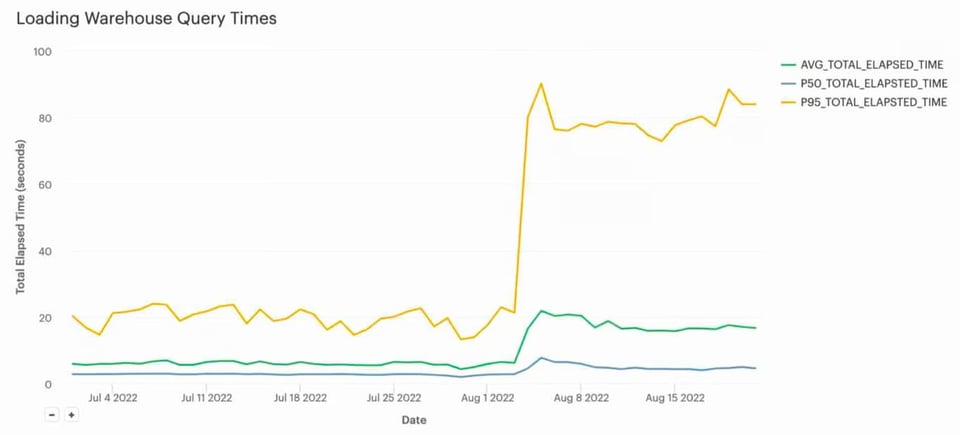
Viel wichtiger: Die Kosten sind regelrecht eingebrochen – von ~130 $/Tag auf weniger als 5 $/Tag, was Einsparungen von rund 45.000 $/Jahr entspricht. Für diesen Kunden war es absolut akzeptabel, dass die Daten in ~20 s statt ~5 s geladen wurden, sodass sich der Tausch klar gelohnt hat.
Wann sich Serverless Compute fürs Data Loading lohnt
In unserem vorherigen Beitrag zu den 5 Data-Loading-Optionen in Snowflake haben wir Tipps gegeben, wann Serverless Tasks gegenüber einem selbstverwalteten Warehouse zu bevorzugen sind.
Lesen Sie diesen Beitrag gerne für mehr Details. Kurz gesagt: Serverless Tasks lohnen sich, wenn Ihre Data-Loading-Jobs für die gewählte Warehouse-Größe weniger als 40 Sekunden dauern. Warum 40 s? Weil Compute für Serverless Tasks zum 1,5-fachen Tarif gegenüber selbstverwalteten Warehouses abgerechnet wird. Die folgende Beispieltabelle veranschaulicht das (Annahme: 3 $/Credit):
| Warehouse-Größe | Compute-Typ | Laufzeit | Kosten |
|---|---|---|---|
| XS | Serverless | 10 s | 0,0125 $ |
| XS | Selbstverwaltetes Warehouse | 10 s | 0,05 $ |
| XS | Serverless | 35 s | 0,0375 $ |
| XS | Selbstverwaltetes Warehouse | 35 s | 0,05 $ |
| XS | Serverless | 40 s | 0,05 $ |
| XS | Selbstverwaltetes Warehouse | 40 s | 0,05 $ |
| XS | Serverless | 50 s | 0,0625 $ |
| XS | Selbstverwaltetes Warehouse | 50 s | 0,05 $ |
Falls Sie sich für die Kostenberechnung interessieren – so kommt der Wert in der ersten Zeile zustande:
- Ein X-Small-Warehouse verbraucht 1 Credit pro Stunde
- Für Serverless Tasks multiplizieren wir das mit 1,5
- Serverless Tasks werden sekundengenau abgerechnet, die Kosten betragen also 0,00125 $/Sekunde (
1 Credit/Stunde * 1,5 * 3 $/Credit / 3600 Sekunden/Stunde)
Und für die zweite Zeile:
- Ein X-Small-Warehouse wird mindestens 60 Sekunden abgerechnet
- Die Kosten für alles unter 60 Sekunden betragen: 0,05 $ (
1 Credit/Stunde * 3 $/Credit / 60 Minuten/Stunde)
Tomáš Sobotík · Senior Data Engineer & Snowflake SME bei Norlys
Tomas ist langjähriger Snowflake Data SuperHero und ausgewiesener Snowflake-Experte. Seine umfangreiche Erfahrung in der Datenwelt umfasst mehr als ein Jahrzehnt, in dem er als Snowflake Data Engineer, Architect und Admin in unterschiedlichsten Projekten, Branchen und Technologien tätig war. Tomas ist ein zentrales Community-Mitglied, das sein Wissen aktiv teilt und andere inspiriert. Er ist außerdem O'Reilly-Instructor und leitet Live-Online-Trainings.
Ian Whitestone · Co-Founder & CEO von SELECT
Ian ist Co-Founder & CEO von SELECT, einer SaaS-Plattform für Snowflake-Kostenmanagement und -Optimierung. Vor SELECT verantwortete Ian 6 Jahre lang Full-Stack Data Science- und Engineering-Teams bei Shopify und Capital One. Bei Shopify leitete er die Initiativen zur Optimierung des Data Warehouse und zum Ausbau der Kostentransparenz.