本記事は、Snowflakeへのデータロードに関するシリーズの第2回です。第1回ではデータロードの5つの選択肢を取り上げました。今回は、最も一般的な取り込み手法であるバッチデータロードを深掘りし、次のポイントを解説します。
- ロード前のファイルのパーティショニングとサイズ設計
- Stageのセットアップ方法
- COPY INTOコマンドの使い方
- 仮想ウェアハウスサイズの選び方
- 自己管理ウェアハウスではなくServerlessを選ぶべきタイミング
ファイル準備の概要
バッチロードでもリアルタイムロードでも、まずはロード対象のファイル群を準備する必要があります。最初に決めるのは、クラウドストレージ上でのファイルのパーティショニング(整理方法)です。これはSnowflakeが対象ファイルを一覧化するためにストレージをスキャンする時間に大きく影響します。次に、ロードに使う仮想ウェアハウスを使い切れるよう、ファイルを最適なサイズにまとめる方法を検討します。最後に、ファイルフォーマットを選択し、Stageオブジェクトを構成します。
ファイルのパーティショニング
すべてのファイルを単一のディレクトリに置くのではなく、日時などの論理的なパスやディメンションに沿って整理しましょう。
たとえばS3にファイルを保管している場合、日付ごとに整理できます。
s3://my-data-bucket/2023/12/01/dataFile1.csvs3://my-data-bucket/2023/12/01/dataFile2.csvs3://my-data-bucket/2023/12/02/dataFile3.csvs3://my-data-bucket/2023/12/02/dataFile4.csvs3://my-data-bucket/2023/12/03/dataFile5.csv
さらに別のディメンションを加えてグループ化することも可能です。たとえば部門ごとにデータを整理したい場合は、次のように保管できます。
s3://my-data-bucket/finance/2023/12/01/dataFile1.csvs3://my-data-bucket/finance/2023/12/01/dataFile2.csvs3://my-data-bucket/marketing/2023/12/02/dataFile3.csvs3://my-data-bucket/marketing/2023/12/02/dataFile4.csv
ポイントは、Snowflakeへのロード方法を見据えてファイルを整理することです。狙いは、Snowflakeがスキャンするファイル数を減らすこと。Snowflakeはロード済みファイルを自動で追跡しますが、Stage内の全ファイルを一覧化する処理は意外と時間がかかります。
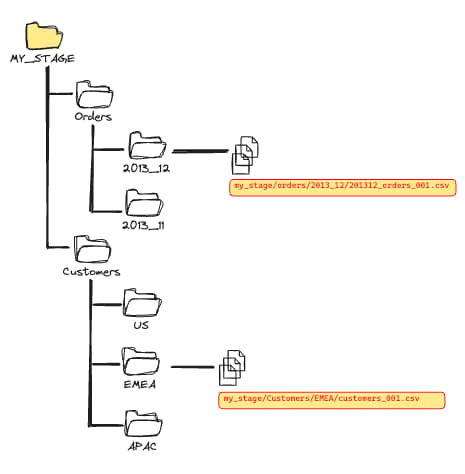
このようにディレクトリを分けておけば、Stage全体ではなく該当ディレクトリ内のファイルだけがスキャン対象になります。この構成を整えたうえで、パスフィルターとPATTERNキーワードを組み合わせて使います。
次の2つの例を比べてみましょう。
こちらの例はPATTERNキーワードを使っているにもかかわらず、Stage内のすべてのファイルがスキャンされてしまいます。これは、PATTERNキーワードがStage内の全ファイルをスキャンした後に適用されるためです。
COPY INTO raw_table
FROM @my_stage
PATTERN='.*[.]csv'
不要なファイルのスキャン(コストがかさみます)をSnowflakeに省略させるには、パスフィルターの指定が必要です。次の例では/orders/2023_12ディレクトリ内のファイルだけがスキャンされ、そのパス配下のCSVがすべて検出されます。
COPY INTO raw_table
FROM @my_stage/orders/2013_12
PATTERN='.*[.]csv'
ロードに最適なファイルサイズ
データロード効率に最も大きく影響するのは、ロードするファイルの数とサイズです。
Snowflakeは、圧縮後のサイズで100〜250 MBに揃えることを推奨しています。250MBを大きく超える大きなファイルが多い場合はロード前に分割し、逆に10MB未満の小さなファイルが多すぎる場合はまとめてからロードしましょう。
その狙いは、ファイルを並列にロードして仮想ウェアハウスの利用可能なコア/CPU処理スレッドを飽和させ、稼働率を最大化することです。
下の図をご覧ください。200 GBの単一ファイルをロードしてXLウェアハウス(最大128ファイルを並列処理可能)のわずか2%しか使わないのと、ファイルを小さく分割してフル稼働させるのとでは、効率が大きく変わります。
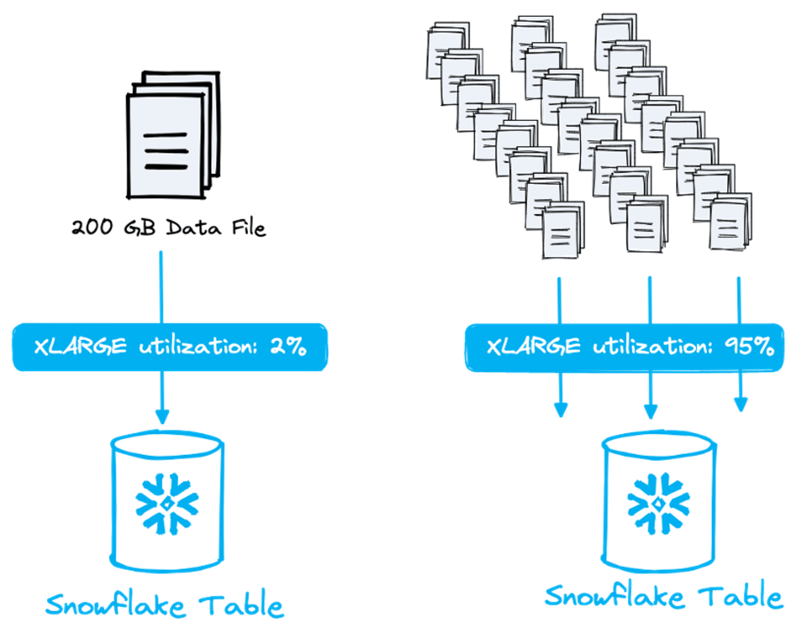
ウェアハウスのサイズごとに並列処理できるファイル数は異なります。サイズを1段階上げるとノード数は2倍になります。各ノードは8スレッドを持ち、1スレッドにつき1ファイルを処理します。つまり、最小サイズのXSウェアハウス(ノード1台・8スレッド)でも最大8ファイルを並列処理できます。
| ウェアハウスサイズ | スレッド数/処理可能ファイル数 |
|---|---|
| XS | 8 |
| S | 16 |
| M | 32 |
| L | 64 |
| XL | 128 |
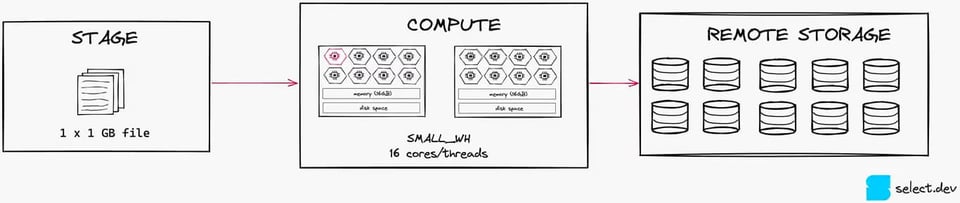
もう少し具体的に見てみましょう。下の図のとおり、1GBのファイルが1つだけだと、Smallウェアハウスでは16スレッドのうち1スレッドしか使えません。
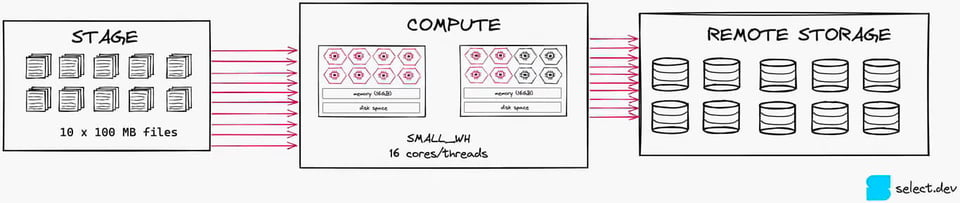
これを100 MB×10ファイルに分割すれば、16スレッドのうち10スレッドを稼働できます。この程度の並列度になれば、コンピュートリソースをはるかに有効活用できます。なお、このケースではXSMALLのほうがより適した選択肢になります。
Stageのセットアップ
バッチデータロードを行う際は、これに加えてSnowflakeの次の3つのリソースを扱う必要があります。
- FILE FORMATオブジェクト:ファイルのフォーマットを定義します
- STORAGE INTEGRATIONオブジェクト:クラウドストレージへのアクセス情報をカプセル化します
- STAGEオブジェクト:ファイルの保存場所と、Snowflakeがそのストレージにどうアクセスするかを定義します
それぞれ詳しく見ていきましょう。
ファイルフォーマット
Snowflakeでは、ファイルフォーマットを次の3通りで定義できます。
COPYコマンドの一部として定義するSTAGE定義の一部として定義する- 独立したオブジェクトとして定義する
ベストプラクティスは、ファイルフォーマットを独立したオブジェクトとして定義することです。こうすればデータロード処理全体で簡単に再利用できますし、保守性も大きく向上します。区切り文字の変更やヘッダーのスキップといった修正も、オブジェクト1か所で集中管理でき、各パイプラインを個別に書き換える必要がありません。さらに、SnowflakeのRBACモデルでフォーマットへのアクセス制御もできます。
ファイルフォーマット作成の例
次のようなCSVファイルを例に考えてみましょう。

対応するFile Formatオブジェクトは次のように定義します。
CREATE OR REPLACE FILE FORMAT my_csv
TYPE = csv
FIELD_DELIMITER = ‘,’
SKIP_HEADER = 1
NULL_IF = ''
詳細はSnowflakeの公式ドキュメントをご覧ください。
Snowflakeが対応するファイルフォーマット
Snowflakeは多様なファイルフォーマットに対応しています。
- CSV
- JSON
- AVRO
- ORC
- Parquet
- XML
各フォーマットのオプションは公式ドキュメントをご参照ください。
Storage Integration
Storage IntegrationオブジェクトはStageのセキュリティレイヤーとして機能します。これを使えば、認証情報をSnowflakeに共有・保存することなくStageを作成できます。再利用も可能で、一度定義すれば複数のStageから使い回せます。Storage Integrationオブジェクトを用意しておけば、開発者はファイルアクセスに必要なロールや認証情報を意識する必要がなく、適切なStorage IntegrationオブジェクトをStageに紐付けるだけで済みます。これは職務分離のベストプラクティスにも合致します。
以下はAmazon S3向けにStorage Integrationオブジェクトを作成する例です。
CREATE STORAGE INTEGRATION s3_int
TYPE = EXTERNAL_STAGE
STORAGE_PROVIDER = 'S3'
ENABLED = TRUE
STORAGE_AWS_ROLE_ARN = 'arn:aws:iam::00123456789:role/myrole
STORAGE_ALLOWED_LOCATIONS = ('s3://bucket1', 's3://bucket2')
STORAGE_BLOCKED_LOCATIONS = ('s3://bucket3/sensitive_data/')
いくつか押さえておきたいポイントがあります。
- このオブジェクトにはAWS IAMロールのARNが必要です。すでにアクセス権限を持っていなければ、AWSのクラウド管理者と連携してSnowflake用のアクセスロールを作成する必要があるでしょう。
- 1つのStorage Integrationに複数のバケットや場所を定義できます。同じStorage Integrationを複数のS3バケットやデータパイプラインで使い回せるため非常に便利です。
Storage Integrationの詳細はSnowflakeの公式ドキュメントをご覧ください。
Stage
File FormatとStorage Integrationのオブジェクトを作成したら、いよいよStageを作成します。
Stageはファイルの場所を表す定義で、取り込み対象のデータファイルが保存されている場所を示します。Stageには2種類あります。
- Snowflakeアカウントに含まれるInternal Stage
- クラウドプロバイダーのオブジェクトストレージ(AWS S3バケットなど)を指すExternal Stage
ベストプラクティスとしては、可能な限りExternal Stageの利用をおすすめします。理由は2つあります。
- 多くのSnowflake利用企業はすでにクラウドストレージにデータファイルを保管しているため、そこを指すExternal Stageを定義するのが自然です。
- 生データのコピーをSnowflake外に保持しておけば、他システムからも容易に利用・参照できます。
File FormatとStorage Integrationを独立したオブジェクトとして定義するベストプラクティスに従っていれば、Stageの作成はとてもシンプルです。以下はAWS S3上のロケーションを指すExternal Stageを作成するコマンド例です。
CREATE STAGE my_s3_stage
STORAGE_INTEGRATION =s3_int
URL = 's3://bucket1/path1/'
FILE_FORMAT= my_csv
前述のとおり、File FormatやStorage Integrationを別オブジェクトとして作らず、必要なプロパティをすべてStage内に直接定義することもできます。
COPY INTOコマンドの使い方
必要なFILE FORMAT、STAGE、STORAGE INTEGRATIONを準備したら、クラウドストレージからSnowflakeへのデータロードを実行できます。そのために使うのがCOPYコマンドです。
COPYコマンドはSnowflakeでデータロードとアンロードの両方に使われる機能で、データ移動の方向に応じて異なるパラメータが用意されています。ここではデータ取り込み(インポート)での使い方を見ていきます。
基本的な使い方
最もシンプルな形では、COPYは次のように書けます。
COPY INTO mytable
FROM @my_s3_stage
これだけで済むのは、ファイルフォーマットをStageオブジェクトの一部として定義しているためです。そのため他のパラメータや設定を指定する必要がありません。詳細はCOPYコマンドのドキュメントをご参照ください。
簡単なデータ変換の実行
COPYコマンドはSELECT文を用いた簡単なデータ変換にも対応しています。カラムの省略・並び替え、別データ型へのキャストなどが可能です。さらに、半構造化データをFLATTENで個別カラムに展開したり、監査用カラムとしてCURRENT_TIMESTAMPを追加することもできます。
SELECT文の中で個別カラムを参照する際は、ドル記号にカラム位置を組み合わせます($1, $2, $3 など)。
以下はステージ上のファイルから1列目・2列目・6列目・7列目だけを抜き出す例です。
COPY INTO home_sales(city, zip, sale_date, price)
FROM (
SELECT t.$1, t.$2, t.$6, t.$7
FROM @mystage/sales.csv.gz t
)
なお、COPY文では次の操作はサポートされていません。
WHEREORDER BYLIMITFETCHTOPJOINGROUP BY
COPYコマンドのメタデータ
COPYコマンドはメタデータを生成し、複数のテーブル関数やビューから取得できます。
COPY_HISTORY-snowflake.information_schemaスキーマのテーブル関数LOAD_HISTORY-snowflake.information_schemaスキーマのテーブル関数LOAD_HISTORY-snowflake.account_usageスキーマのビュー
このメタデータにはロードした各ファイルの情報(ファイル名、行数、エラー件数、対象テーブルなど)が含まれ、これによって同じファイルを2回以上Snowflakeにロードしてしまうのを防げます。ロードメタデータは64日後に有効期限が切れます。同じファイルを何度もリロードする必要がある場合は、COPYコマンドのFORCE = TRUEオプションを使えば再ロードできます。
データロードにおける仮想ウェアハウスサイズの考え方
COPYコマンドの実行とファイル取り込みには、アクティブな仮想ウェアハウスが必要です。Snowflakeの仮想ウェアハウスは稼働秒数で課金され、再開のたびに最低60秒の課金期間が発生します。
データロード用途で適切なウェアハウスサイズを選ぶ際は、次の2点を意識しましょう。
- 先述のとおり、ファイルは圧縮後で100MB〜250MB程度になるようまとめます。これは、ウェアハウスで利用可能な処理スレッドを十分に使い切れるだけのファイル数を確保するために重要です(1つの大きなファイルだけだと、1スレッドでしか処理できません)。一方で、小さなファイルが多すぎると不要なオーバーヘッドコストが発生します。
- SLAを満たせる範囲で、常に最小のウェアハウスサイズを使いましょう。実際の事例については後述のケーススタディをご覧ください。
大きなウェアハウスを使うと、ファイル数が足りずにコアやスレッドが余ってしまうことが多くなります。さらに、全ファイルが数秒で処理し終わっても、最低1分の課金期間分は請求されます。そのため、まずはできる限り小さなウェアハウスサイズから始め、SLAを満たすほどの速度が出ない場合に限ってサイズを上げていくことをおすすめします。
仮想ウェアハウスサイジングの想定例
これらの考え方を整理するため、仮想的な例を見てみましょう。
毎日1 GBのデータを取り込む必要があるとします。1つの大きなファイルをロードしても効率的でないことはすでにわかっているため、ファイルは100 MBずつ(計10ファイル)に分けて生成されています。ここではSnowflakeのクレジット単価を$3/クレジットと仮定します。
| ウェアハウスサイズ | コア数 | 稼働率 | 実行時間 | 課金時間 | 日次コスト | 年間コスト |
|---|---|---|---|---|---|---|
| XS | 32 | 約30% | 10秒 | 60秒 | $0.2 | $73 |
| M | 8 | 約100% | 50秒 | 60秒 | $0.05 | $18.25 |
Mediumウェアハウスでは、処理対象のファイルが10個しかない一方で利用可能なコアが32個あるため、稼働率はせいぜい30%程度にとどまります。一方、X-Smallウェアハウスなら8コアをフルに稼働させられます。Mediumウェアハウスの処理速度はX-Smallの5倍ですが、50秒のアイドル時間にも課金されるため、最終的なコストは4倍になります。
実例:データロードにおけるウェアハウスサイジング
実際のSnowflakeアカウントで、この考え方がどのように効いたかを見てみましょう。
もともと、このデータロードパイプラインはLargeウェアハウスを使っていました。約5秒で全ファイルをロードし、その後55秒はアイドル状態でした。ウェアハウスをX-Smallにダウンサイズしたところ、ロード時間は平均で約20秒に伸びました。
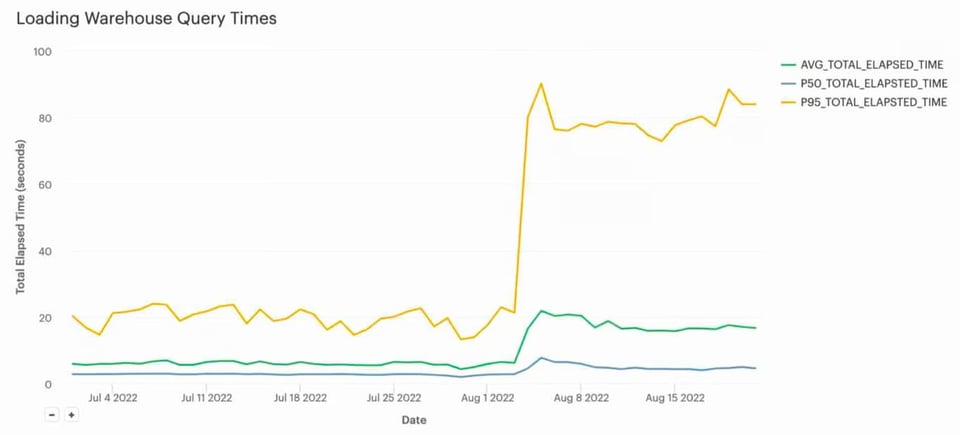
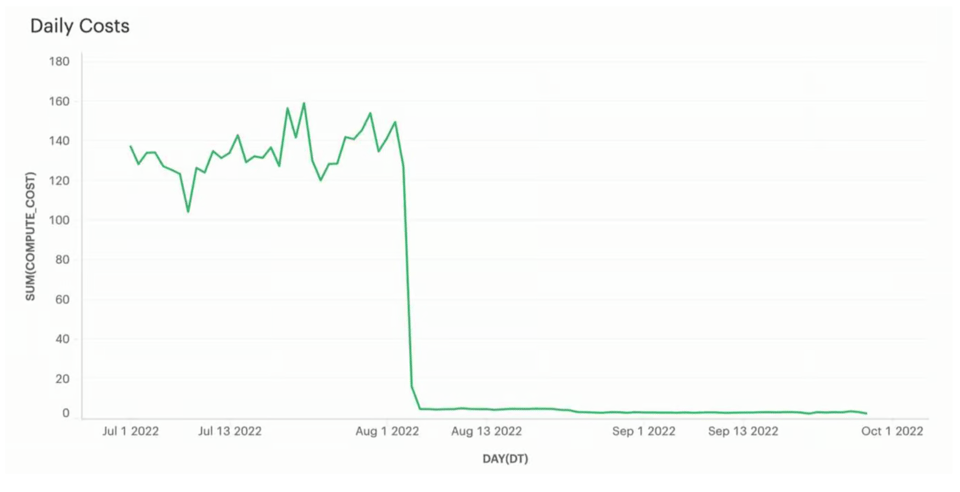
そして何より重要なのは、コストが約$130/日から$5/日未満まで大幅に下がり、年間で約$45,000のコスト削減を実現したことです。この顧客にとってロード時間が約5秒から約20秒になることはSLA上許容範囲だったため、十分に価値のあるトレードオフでした。
データロードでサーバーレスコンピュートを使うべきタイミング
前回のSnowflakeにおける5つのデータロード手法に関する記事では、サーバーレスタスクと自己管理ウェアハウスのどちらを使うべきかについてのヒントを紹介しました。
詳細はぜひそちらの記事をご覧いただきたいのですが、ひと言で言えば、データロードジョブが対象のウェアハウスサイズで40秒未満で完了するなら、サーバーレスタスクの利用を検討する価値があります。なぜ40秒なのか?それは、サーバーレスタスクのコンピュートは自己管理ウェアハウスのコンピュートの1.5倍のレートで課金されるためです。以下は$3/クレジットを前提にまとめた比較表です。
| ウェアハウスサイズ | コンピュート種別 | 実行時間 | コスト |
|---|---|---|---|
| XS | Serverless | 10秒 | $0.0125 |
| XS | 自己管理ウェアハウス | 10秒 | $0.05 |
| XS | Serverless | 35秒 | $0.0375 |
| XS | 自己管理ウェアハウス | 35秒 | $0.05 |
| XS | Serverless | 40秒 | $0.05 |
| XS | 自己管理ウェアハウス | 40秒 | $0.05 |
| XS | Serverless | 50秒 | $0.0625 |
| XS | 自己管理ウェアハウス | 50秒 | $0.05 |
コスト計算が気になる方のために、1行目の内訳を示します。
- X-Smallウェアハウスは1時間あたり1クレジットを消費
- サーバーレスタスクではこれを1.5倍する
- サーバーレスタスクは秒単位で課金されるため、コストは$0.00125/秒(
1 credit/hour * 1.5 * $3/credit / 3600 seconds / hour)
2行目は次のとおりです。
- X-Smallウェアハウスは最低60秒分が課金対象
- 60秒以下の場合のコストは$0.05(
1 credit / hour * $3/credit / 60 minutes / hour)
Tomáš Sobotík・Senior Data Engineer & Snowflake SME at Norlys
TomasはSnowflake Data SuperHeroとして長年活躍する、Snowflake全般のエキスパートです。データ業界での経験は10年以上にわたり、さまざまな業界・技術領域のプロジェクトでSnowflakeのデータエンジニア、アーキテクト、管理者を務めてきました。コミュニティの中心メンバーとして自らの知見を積極的に共有し、多くの人にインスピレーションを与えています。O'Reillyのインストラクターとして、ライブオンライントレーニングも担当しています。
Ian Whitestone・Co-founder & CEO of SELECT
IanはSnowflakeのコスト管理・最適化SaaSプラットフォームであるSELECTの共同創業者兼CEOです。SELECT創業以前は、ShopifyとCapital Oneでフルスタックのデータサイエンス/エンジニアリングチームを6年間率いてきました。Shopifyでは、データウェアハウスの最適化とコスト可視化の向上を主導しました。