Voici le deuxième volet de notre série consacrée au chargement de données dans Snowflake. Dans le premier article, nous avons présenté les cinq options possibles pour charger vos données. Cette fois, nous explorons en profondeur la technique d'ingestion la plus répandue : le chargement par lots. Au programme :
- Comment partitionner et dimensionner vos fichiers avant le chargement
- Comment configurer votre Stage
- Comment utiliser la commande COPY INTO
- Les points à considérer pour dimensionner le Virtual Warehouse
- Quand privilégier le Serverless plutôt qu'un warehouse auto-géré
Vue d'ensemble de la préparation des fichiers
Que vous chargiez vos données par lots ou en temps réel, vous devez préparer un ensemble de fichiers. Première étape : choisir la manière dont vos fichiers seront partitionnés (organisés) dans le stockage cloud. C'est un facteur déterminant : il pèse directement sur le temps que Snowflake consacre à parcourir le stockage cloud pour lister les fichiers disponibles. Vient ensuite la question du regroupement des fichiers en lots de taille optimale, afin d'exploiter pleinement les virtual warehouses utilisés pour le chargement. Enfin, il vous reste à choisir un format de fichier et à configurer votre objet Stage.
Partitionnement des fichiers
Plutôt que de regrouper tous vos fichiers dans un même répertoire, organisez-les selon des chemins ou dimensions logiques, comme la date ou l'heure.
Par exemple, si vous stockez vos fichiers sur S3, vous pouvez les organiser par date :
s3://my-data-bucket/2023/12/01/dataFile1.csvs3://my-data-bucket/2023/12/01/dataFile2.csvs3://my-data-bucket/2023/12/02/dataFile3.csvs3://my-data-bucket/2023/12/02/dataFile4.csvs3://my-data-bucket/2023/12/03/dataFile5.csv
Vous pouvez même aller plus loin en ajoutant d'autres dimensions de regroupement. Si vous souhaitez par exemple organiser vos données par service, vous pouvez stocker les fichiers ainsi :
s3://my-data-bucket/finance/2023/12/01/dataFile1.csvs3://my-data-bucket/finance/2023/12/01/dataFile2.csvs3://my-data-bucket/marketing/2023/12/02/dataFile3.csvs3://my-data-bucket/marketing/2023/12/02/dataFile4.csv
L'idée à retenir : organisez vos fichiers en fonction de la manière dont vous prévoyez de les charger dans Snowflake. L'objectif est de réduire le nombre de fichiers que Snowflake doit parcourir. Même si Snowflake suit automatiquement les fichiers déjà chargés, lister l'ensemble des fichiers d'un stage peut vite devenir chronophage.
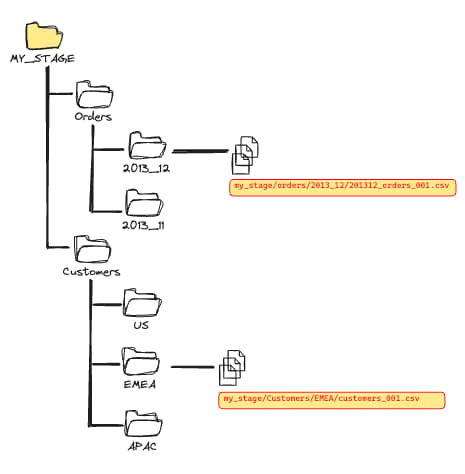
Avec cette organisation par répertoires, seul leur contenu est parcouru, et non l'intégralité du stage. Une fois cette structure en place, il faut utiliser les filtres de chemin associés au mot-clé PATTERN.
Examinons les deux exemples suivants.
Le premier parcourt tous les fichiers du stage indiqué, même avec le mot-clé PATTERN. Pourquoi ? Parce que le mot-clé PATTERN est appliqué après que tous les fichiers du stage ont été parcourus.
COPY INTO raw_table
FROM @my_stage
PATTERN='.*[.]csv'
Pour éviter à Snowflake ce parcours coûteux de fichiers inutiles, vous devez spécifier un filtre de chemin. Ce second exemple ne parcourt que les fichiers du répertoire /orders/2023_12, puis y recherche tous les CSV.
COPY INTO raw_table
FROM @my_stage/orders/2013_12
PATTERN='.*[.]csv'
Tailles de fichier optimales pour le chargement
Ce qui pèse le plus sur l'efficacité du chargement, c'est le nombre et la taille des fichiers à charger.
Snowflake recommande de viser des fichiers compressés entre 100 et 250 Mo. Si vous avez de nombreux fichiers dépassant largement 250 Mo, mieux vaut les fractionner avant le chargement. À l'inverse, si vous avez trop de petits fichiers (<10 Mo), regroupez-les en amont.
L'objectif : tirer le meilleur parti de votre virtual warehouse en chargeant les fichiers en parallèle et en saturant tous les cœurs/threads CPU disponibles.
Regardez l'image ci-dessous. La différence est énorme entre charger un seul fichier de 200 Go en n'exploitant que 2 % d'un warehouse XL (qui peut traiter jusqu'à 128 fichiers en parallèle), ou fractionner ce fichier en plusieurs plus petits pour saturer entièrement le warehouse !
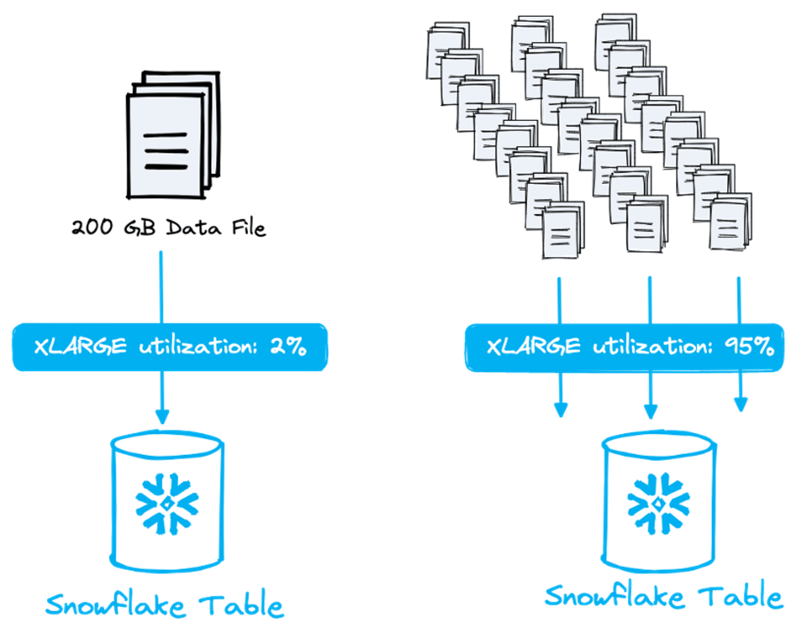
Chaque taille de warehouse traite un nombre différent de fichiers en parallèle. Augmenter la taille du warehouse, c'est doubler le nombre de nœuds. Chaque nœud dispose de 8 threads et chaque thread traite 1 fichier. Autrement dit, le plus petit warehouse (XS), avec un seul nœud et 8 threads, peut traiter jusqu'à 8 fichiers en parallèle !
| Taille de warehouse | Nb threads / fichiers traitables |
|---|---|
| XS | 8 |
| S | 16 |
| M | 32 |
| L | 64 |
| XL | 128 |
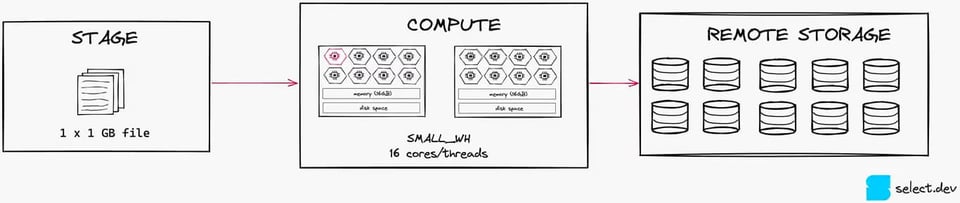
Pour illustrer davantage, regardez l'image ci-dessous. Avec un seul fichier de 1 Go, vous ne saturez qu'1 thread sur 16 sur un warehouse Small.
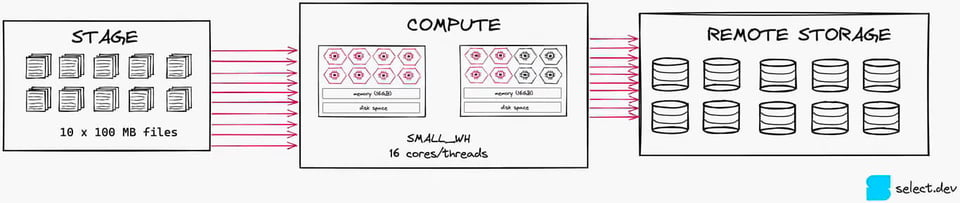
En découpant ce fichier en dix morceaux de 100 Mo, vous mobilisez 10 threads sur 16. Ce niveau de parallélisation est nettement plus efficace et exploite bien mieux les ressources de calcul. À noter qu'un XSMALL serait ici un choix encore plus pertinent.
Configurer un Stage
Pour le chargement par lots, trois ressources Snowflake supplémentaires entrent en jeu :
- L'objet FILE FORMAT, qui définit le format des fichiers
- L'objet STORAGE INTEGRATION, qui encapsule les informations d'accès aux emplacements de stockage cloud.
- L'objet STAGE, qui décrit où sont stockés les fichiers et comment Snowflake doit accéder à cet emplacement
Passons chacun en revue.
File Format
Dans Snowflake, vous pouvez définir le File Format de plusieurs façons :
- Directement dans la commande
COPY - Dans la définition du
STAGE - En tant qu'objet autonome
La bonne pratique consiste à définir le File Format en tant qu'objet autonome, ce qui permet de le réutiliser facilement dans vos opérations de chargement. Au-delà de la réutilisation, la maintenabilité s'en trouve grandement améliorée. Si vous devez modifier votre format de fichier (changer le délimiteur, ignorer l'en-tête, etc.), tout se fait de manière centralisée sur l'objet, sans avoir à toucher à chacun de vos pipelines. Dernier avantage : vous contrôlez l'accès à ces formats via le modèle RBAC de Snowflake.
Exemple de création de File Format
Prenons un fichier CSV comme celui-ci :

L'objet File Format correspondant se définirait ainsi :
CREATE OR REPLACE FILE FORMAT my_csv
TYPE = csv
FIELD_DELIMITER = ‘,’
SKIP_HEADER = 1
NULL_IF = ''
Pour plus de détails, consultez la documentation Snowflake.
Options de format de fichier Snowflake
Snowflake prend en charge de nombreux formats de fichier :
- CSV
- JSON
- AVRO
- ORC
- Parquet
- XML
Consultez la documentation pour découvrir les options propres à chaque format.
Storage Integration
L'objet Storage Integration sert de couche de sécurité pour un Stage. Il vous permet de créer des Stages sans que les identifiants soient partagés ni stockés dans Snowflake. Ces objets sont aussi réutilisables : définis une seule fois, ils peuvent servir à plusieurs Stages. Avec une Storage Integration en place, les développeurs n'ont plus besoin de connaître les rôles ou identifiants nécessaires pour accéder aux fichiers : il leur suffit de pointer leur Stage vers la bonne Storage Integration. Cela respecte le principe de séparation des responsabilités.
Voici un exemple de création d'une Storage Integration pour Amazon S3 :
CREATE STORAGE INTEGRATION s3_int
TYPE = EXTERNAL_STAGE
STORAGE_PROVIDER = 'S3'
ENABLED = TRUE
STORAGE_AWS_ROLE_ARN = 'arn:aws:iam::00123456789:role/myrole
STORAGE_ALLOWED_LOCATIONS = ('s3://bucket1', 's3://bucket2')
STORAGE_BLOCKED_LOCATIONS = ('s3://bucket3/sensitive_data/')
Plusieurs points à noter :
- L'objet requiert l'ARN AWS du rôle IAM. Il faudra donc sans doute solliciter vos administrateurs cloud AWS pour créer un rôle d'accès dédié à Snowflake, si vous ne disposez pas déjà de cet accès.
- Vous pouvez définir plusieurs buckets ou emplacements pour une même Storage Integration. Pratique : vous réutilisez la même Storage Integration pour plusieurs buckets S3 ou pipelines de données.
Pour en savoir plus sur les Storage Integrations, rendez-vous sur la documentation Snowflake.
Stage
Les objets File Format et Storage Integration étant créés, nous pouvons passer à la création de notre Stage.
Un Stage décrit l'emplacement de fichiers. Il définit où sont stockés vos fichiers de données à ingérer. Il en existe deux types :
- Les Stages internes, qui font partie de votre compte Snowflake
- Les Stages externes, qui pointent généralement vers des emplacements de stockage objet (un bucket AWS S3, par exemple) chez votre fournisseur cloud
Côté bonne pratique, nous recommandons les Stages externes dès que possible, pour deux raisons :
- La plupart des clients Snowflake ont déjà leurs fichiers de données dans le Cloud Storage. Il est donc logique de définir un Stage externe pointant vers ces fichiers.
- En conservant une copie de vos données brutes hors de Snowflake, vous pouvez facilement y accéder ou les utiliser avec d'autres systèmes.
Si vous avez suivi la bonne pratique consistant à définir des objets File Format et Storage Integration distincts, créer un Stage devient très simple. Voici un exemple de commande pour créer un Stage externe pointant vers un emplacement dans AWS S3 :
CREATE STAGE my_s3_stage
STORAGE_INTEGRATION =s3_int
URL = 's3://bucket1/path1/'
FILE_FORMAT= my_csv
Comme mentionné plus haut, vous pouvez aussi vous passer d'objets File Format et Storage Integration distincts et définir toutes les propriétés directement dans le Stage.
Comment utiliser la commande COPY INTO
Une fois les objets FILE FORMAT, STAGE et STORAGE INTEGRATION configurés, vous êtes prêt à charger des données dans Snowflake depuis votre fournisseur de stockage cloud. La commande COPY est l'outil tout indiqué.
La commande COPY est une fonctionnalité Snowflake utilisée à la fois pour le chargement et le déchargement de données, avec des paramètres différents selon le sens du transfert. Voyons comment l'utiliser pour importer des données.
Utilisation de base
Dans sa forme la plus simple, la commande COPY ressemble à ceci :
COPY INTO mytable
FROM @my_s3_stage
Cette simplicité tient au fait que nous avons défini le format de fichier dans l'objet Stage. Aucun autre paramètre n'est nécessaire. Consultez la documentation de la commande COPY pour plus de détails.
Effectuer des transformations simples
La commande COPY prend aussi en charge des transformations simples via l'instruction SELECT. Vous pouvez omettre des colonnes, les réordonner ou les caster vers un autre type de données. Vous pouvez également utiliser FLATTEN pour éclater des données semi-structurées en colonnes distinctes, ou ajouter CURRENT_TIMESTAMP comme colonne d'audit.
Dans l'instruction SELECT, les colonnes sont référencées par le signe dollar suivi de leur position : $1, $2, $3, etc.
Voici un exemple où l'on ne sélectionne que les première, deuxième, sixième et septième colonnes du fichier stagé :
COPY INTO home_sales(city, zip, sale_date, price)
FROM (
SELECT t.$1, t.$2, t.$6, t.$7
FROM @mystage/sales.csv.gz t
)
Les opérations suivantes ne sont pas prises en charge dans la commande COPY :
WHEREORDER BYLIMITFETCHTOPJOINGROUP BY
Métadonnées de la commande COPY
La commande COPY génère des métadonnées récupérables via différentes fonctions de table ou vues :
COPY_HISTORY— une fonction de table dans le schémasnowflake.information_schemaLOAD_HISTORY— une fonction de table dans le schémasnowflake.information_schemaLOAD_HISTORY— une vue dans le schémasnowflake.account_usage
Ces métadonnées détaillent chaque fichier chargé : nom, nombre de lignes, nombre d'erreurs, table cible, etc. Elles empêchent Snowflake de charger plusieurs fois le même fichier. Les métadonnées de chargement expirent au bout de 64 jours. Si vous devez recharger un même fichier à plusieurs reprises, l'option FORCE = TRUE de la commande COPY le permet.
Dimensionnement du Virtual Warehouse pour le chargement
La commande COPY nécessite un virtual warehouse actif pour s'exécuter et ingérer les fichiers. Avec les virtual warehouses Snowflake, vous payez chaque seconde d'exécution, avec une période de facturation minimale de 60 secondes à chaque redémarrage du warehouse.
Pour choisir la bonne taille de warehouse spécifiquement pour le chargement de données, gardez deux points en tête :
- Comme évoqué plus haut, regroupez vos fichiers pour atteindre une taille d'environ 100 à 250 Mo (compressés). C'est essentiel pour disposer d'assez de fichiers et exploiter efficacement tous les threads de traitement du warehouse (au lieu d'un seul gros fichier traité par un unique thread). À l'inverse, trop de petits fichiers entraînent des surcoûts inutiles.
- Choisissez toujours la plus petite taille de warehouse qui respecte vos SLA. Voir le cas pratique ci-dessous pour un exemple concret.
Un warehouse plus grand laisse souvent des cœurs/threads inutilisés, faute de fichiers en nombre suffisant. Autre conséquence : tous les fichiers sont traités en quelques secondes, mais la période minimale d'une minute reste facturée. Nous recommandons donc de partir de la plus petite taille possible, et de l'augmenter uniquement si le chargement ne tient pas vos SLA.
Dimensionnement hypothétique d'un warehouse pour le chargement
Pour bien fixer ces concepts, prenons un exemple hypothétique.
Imaginons que vous deviez ingérer 1 Go de données par jour. Sachant qu'un seul gros fichier n'est pas efficace, les fichiers sont produits en morceaux de 100 Mo (10 fichiers). Nous retiendrons un prix de 3 $/crédit Snowflake.
| Taille de warehouse | Nombre de cœurs | Taux d'utilisation | Durée d'exécution | Durée facturée | Coût/jour | Coût/an |
|---|---|---|---|---|---|---|
| XS | 32 | ~30 % | 10 s | 60 s | 0,2 $ | 73 $ |
| M | 8 | ~100 % | 50 s | 60 s | 0,05 $ | 18,25 $ |
Avec le warehouse Medium, on plafonne à environ 30 % d'utilisation, faute de fichiers en quantité suffisante : 10 fichiers à traiter pour 32 cœurs disponibles. Avec le X-Small, en revanche, les 8 cœurs sont pleinement saturés. Même si le Medium traite les fichiers cinq fois plus vite, il revient quatre fois plus cher, à cause des 50 secondes d'inactivité que vous payez quand même.
Exemple concret de dimensionnement pour le chargement
Pour voir ce que cela donne en conditions réelles, voici les résultats observés sur un compte Snowflake réel.
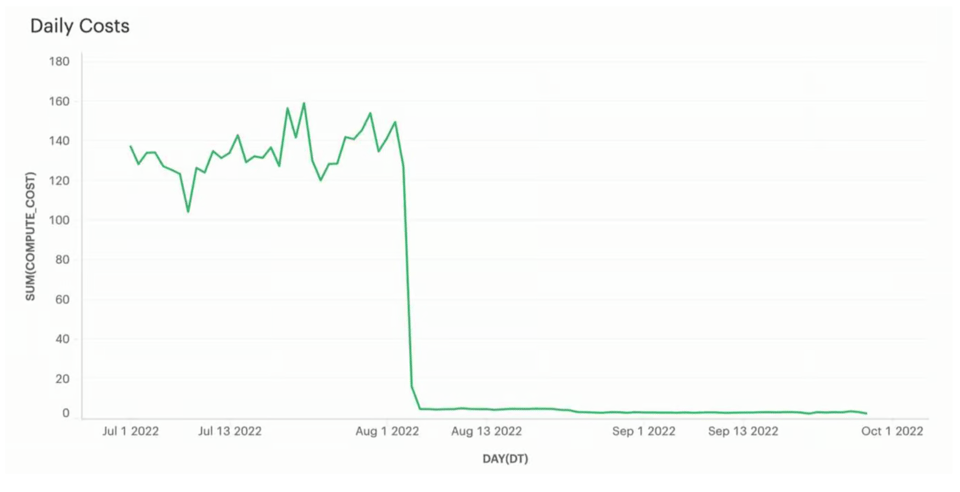
À l'origine, ce pipeline de chargement utilisait un warehouse Large. Il chargeait tous les fichiers en 5 secondes environ, puis restait inactif pendant 55 secondes. Après passage en X-Small, le temps de chargement est monté à environ 20 secondes en moyenne.
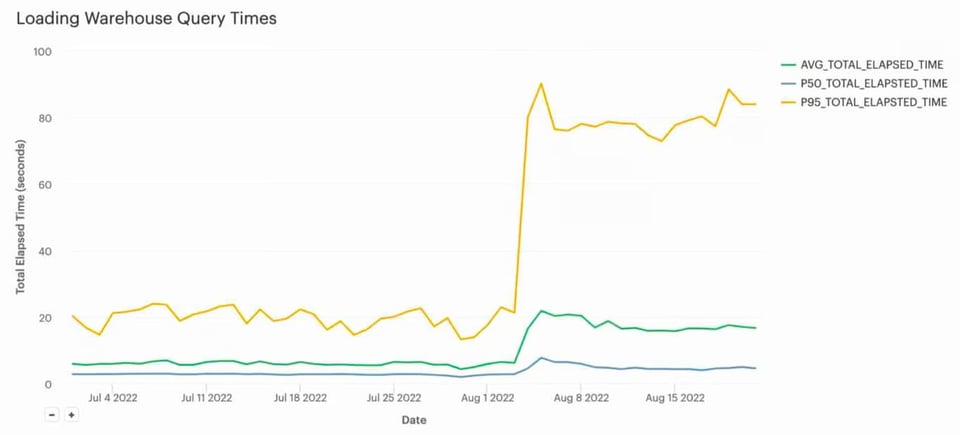
Surtout, les coûts se sont effondrés : d'environ 130 $/jour à moins de 5 $/jour, soit une économie significative d'environ 45 000 $/an. Pour ce client, un chargement en 20 secondes au lieu de 5 restait conforme à ses SLA : le compromis en valait largement la peine.
Quand utiliser le compute serverless pour le chargement ?
Dans notre précédent article sur les 5 options de chargement dans Snowflake, nous avons partagé quelques conseils pour arbitrer entre tâches serverless et warehouse auto-géré.
Nous vous invitons à le consulter pour plus de détails, mais en résumé : envisagez les tâches serverless si vos jobs de chargement durent moins de 40 secondes pour la taille de warehouse donnée. Pourquoi 40 s ? Parce que le compute des tâches serverless est facturé 1,5 fois plus cher que celui des warehouses auto-gérés. Voici un tableau illustratif (en supposant 3 $/crédit) :
| Taille de warehouse | Type de compute | Durée d'exécution | Coût |
|---|---|---|---|
| XS | Serverless | 10 s | 0,0125 $ |
| XS | Warehouse auto-géré | 10 s | 0,05 $ |
| XS | Serverless | 35 s | 0,0375 $ |
| XS | Warehouse auto-géré | 35 s | 0,05 $ |
| XS | Serverless | 40 s | 0,05 $ |
| XS | Warehouse auto-géré | 40 s | 0,05 $ |
| XS | Serverless | 50 s | 0,0625 $ |
| XS | Warehouse auto-géré | 50 s | 0,05 $ |
Si le détail des calculs vous intéresse, voici comment on arrive à la première ligne :
- Un warehouse X-Small consomme 1 crédit par heure
- Pour les tâches serverless, on multiplie par 1,5
- Les tâches serverless sont facturées à la seconde, soit 0,00125 $/seconde (
1 crédit/heure * 1,5 * 3 $/crédit / 3600 secondes/heure)
Et pour la deuxième ligne :
- Un warehouse X-Small est facturé pour un minimum de 60 secondes
- Le coût pour toute exécution inférieure à 60 secondes est de 0,05 $ (
1 crédit/heure * 3 $/crédit / 60 minutes/heure)
Tomáš Sobotík·Senior Data Engineer & Snowflake SME chez Norlys
Tomas est un Snowflake Data SuperHero de longue date et un expert reconnu de Snowflake. Fort de plus d'une décennie d'expérience dans le monde de la donnée, il a occupé les rôles de Snowflake data engineer, architecte et administrateur sur de nombreux projets, dans des secteurs et technologies variés. Membre actif de la communauté, il partage régulièrement son expertise et inspire les autres. Il est également formateur O'Reilly et anime des sessions de formation en direct en ligne.
Ian Whitestone·Co-fondateur & CEO de SELECT
Ian est co-fondateur et CEO de SELECT, plateforme SaaS de gestion et d'optimisation des coûts Snowflake. Avant SELECT, Ian a passé 6 ans à diriger des équipes full stack data science et engineering chez Shopify et Capital One. Chez Shopify, il a piloté l'optimisation du data warehouse et le renforcement de l'observabilité des coûts.