Questa è la seconda parte della serie dedicata al data loading in Snowflake. Nel primo articolo abbiamo analizzato le cinque opzioni di caricamento dati. In questo post approfondiamo la tecnica di ingestion più diffusa: il batch data loading. Vedremo:
- Come partizionare e dimensionare i file prima del caricamento
- Come configurare lo Stage
- Come usare il comando COPY INTO
- Considerazioni sulla dimensione del Virtual Warehouse
- Quando scegliere il Serverless rispetto ai warehouse gestiti
Panoramica sulla preparazione dei file
Che si carichino i dati in batch o in tempo reale, è sempre necessario preparare l'insieme di file da caricare. Per prima cosa occorre decidere come partizionare (organizzare) i file nel cloud storage: una scelta che incide in modo significativo sul tempo che Snowflake impiega a effettuare lo scan del cloud storage per elencare tutti i file disponibili. In secondo luogo, bisogna valutare come raggruppare i file nelle dimensioni ottimali, per sfruttare appieno i virtual warehouse usati per il caricamento. Infine, va scelto il formato dei file e configurato l'oggetto Stage.
Partizionamento dei file
Anziché elencare tutti i file in un'unica directory, conviene organizzarli secondo percorsi logici o dimensioni come data e ora.
Se ad esempio i file sono archiviati su S3, è possibile organizzarli per data:
s3://my-data-bucket/2023/12/01/dataFile1.csvs3://my-data-bucket/2023/12/01/dataFile2.csvs3://my-data-bucket/2023/12/02/dataFile3.csvs3://my-data-bucket/2023/12/02/dataFile4.csvs3://my-data-bucket/2023/12/03/dataFile5.csv
Si può andare anche oltre, introducendo ulteriori dimensioni di raggruppamento. Se ad esempio volessimo organizzare i dati per dipartimento, potremmo archiviare i file in questo modo:
s3://my-data-bucket/finance/2023/12/01/dataFile1.csvs3://my-data-bucket/finance/2023/12/01/dataFile2.csvs3://my-data-bucket/marketing/2023/12/02/dataFile3.csvs3://my-data-bucket/marketing/2023/12/02/dataFile4.csv
Il punto chiave è organizzare i file in funzione di come verranno caricati in Snowflake. L'obiettivo è ridurre il numero di file da scansionare. Anche se Snowflake tiene traccia automaticamente dei file già caricati, elencare tutti i file presenti nello stage può richiedere molto tempo.
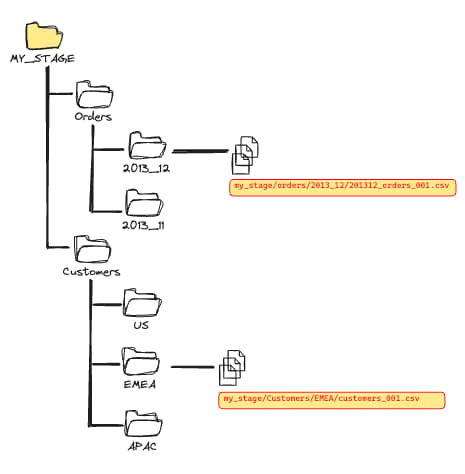
Organizzando i file in queste directory, Snowflake scansiona solo i file al loro interno e non l'intero stage. Definita questa struttura, occorre usare i filtri di percorso combinandoli con la parola chiave PATTERN.
Vediamo due esempi.
Questo esempio scansiona tutti i file dello stage indicato, anche se viene usata la parola chiave PATTERN. Il motivo è che PATTERN viene applicato dopo che tutti i file dello stage sono stati scansionati.
COPY INTO raw_table
FROM @my_stage
PATTERN='.*[.]csv'
Per fare in modo che Snowflake eviti il costoso scan dei file non necessari, occorre specificare un filtro di percorso. Questo secondo esempio scansiona solo i file nella directory /orders/2023_12 e poi individua tutti i CSV in quel percorso.
COPY INTO raw_table
FROM @my_stage/orders/2013_12
PATTERN='.*[.]csv'
Dimensioni ottimali dei file per il caricamento
L'impatto maggiore sull'efficienza del data loading è dato dal numero e dalla dimensione dei file caricati.
Snowflake consiglia di puntare a file compresi tra 100 e 250 MB compressi. Se si hanno molti file ben oltre i 250 MB, è meglio suddividerli prima del caricamento. Allo stesso modo, se i file piccoli (<10 MB) sono troppi, conviene unirli prima di caricarli.
L'obiettivo è massimizzare l'utilizzo del virtual warehouse caricando i file in parallelo e saturando tutti i core e i thread di elaborazione CPU disponibili.
Si guardi l'immagine qui sotto: c'è un'enorme differenza tra caricare un singolo file da 200 GB sfruttando solo il 2% di un warehouse XL (in grado di processare fino a 128 file in parallelo) e suddividere il file in tanti file più piccoli saturando completamente il warehouse.
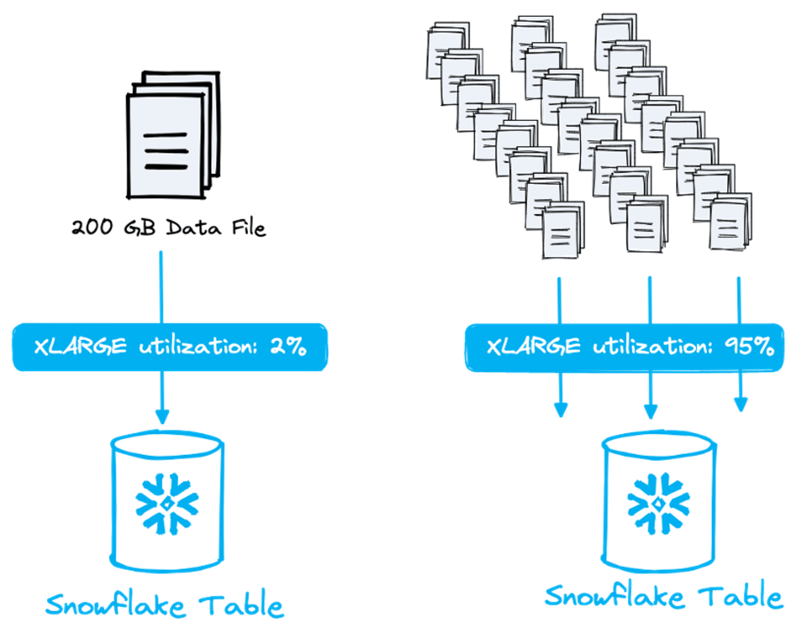
Ogni dimensione di warehouse può processare un numero diverso di file in parallelo. Aumentando la dimensione del warehouse, il numero di nodi raddoppia. Ogni nodo dispone di 8 thread e ogni thread può processare 1 file. Questo significa che il warehouse più piccolo (XS), con un solo nodo e 8 thread, può processare fino a 8 file in parallelo.
| Dimensione warehouse | N. thread / File processati |
|---|---|
| XS | 8 |
| S | 16 |
| M | 32 |
| L | 64 |
| XL | 128 |
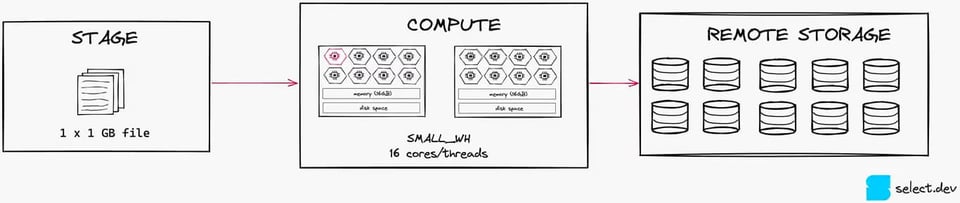
Per illustrare meglio il concetto, si veda l'immagine seguente. Con un solo file da 1 GB, satureremo appena 1 thread su 16 di un warehouse Small.
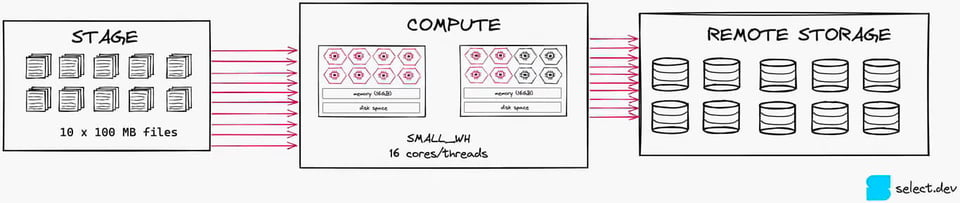
Suddividendo invece lo stesso file in dieci file da 100 MB ciascuno, occuperemo 10 thread su 16. Questo livello di parallelizzazione è decisamente migliore, perché consente un utilizzo più efficiente delle risorse di calcolo disponibili. Vale la pena notare che, in questo scenario, un XSMALL sarebbe la scelta più indicata.
Configurare uno Stage
Per il batch data loading occorre lavorare con tre risorse Snowflake aggiuntive:
- L'oggetto FILE FORMAT, che definisce il formato dei file
- L'oggetto STORAGE INTEGRATION, che incapsula le informazioni di accesso alle location di cloud storage.
- L'oggetto STAGE, che indica dove sono archiviati i file e come Snowflake deve accedere a tale location
Vediamo nel dettaglio ciascun elemento.
File Format
In Snowflake il File Format si può definire in diversi modi:
- All'interno del comando
COPY - All'interno della definizione dello
STAGE - Come oggetto a sé stante
La best practice è definire il File Format come oggetto a sé stante, così da poterlo riutilizzare con facilità nelle diverse operazioni di data loading. Oltre alla comodità di riutilizzo, ne guadagna molto anche la manutenibilità: se occorre modificare qualcosa del file format (ad esempio cambiare il delimitatore, saltare l'header, ecc.), lo si fa centralmente sull'oggetto, senza dover intervenire su ogni singola pipeline. Un ulteriore vantaggio è poter controllare l'accesso ai format tramite il modello RBAC di Snowflake.
Esempio di creazione di un File Format
Si consideri un file CSV come questo:

L'oggetto File Format corrispondente si definirebbe così:
CREATE OR REPLACE FILE FORMAT my_csv
TYPE = csv
FIELD_DELIMITER = ‘,’
SKIP_HEADER = 1
NULL_IF = ''
Per maggiori dettagli si rimanda alla documentazione di Snowflake.
Opzioni di File Format in Snowflake
Snowflake supporta numerosi formati di file:
- CSV
- JSON
- AVRO
- ORC
- Parquet
- XML
Per le opzioni disponibili per ciascun formato, consultare la documentazione.
Storage Integration
L'oggetto Storage Integration funge da livello di sicurezza per uno Stage. Consente di creare Stage le cui credenziali non vengono né condivise né memorizzate in Snowflake. Sono inoltre riutilizzabili: si definiscono una sola volta e si usano con più Stage. Con un oggetto Storage Integration, gli sviluppatori non devono conoscere i ruoli o le credenziali necessari per accedere ai file: basta puntare lo Stage al giusto oggetto Storage Integration. Tutto questo è in linea con la best practice della separazione dei compiti.
Ecco un esempio di creazione di un oggetto Storage Integration per Amazon S3:
CREATE STORAGE INTEGRATION s3_int
TYPE = EXTERNAL_STAGE
STORAGE_PROVIDER = 'S3'
ENABLED = TRUE
STORAGE_AWS_ROLE_ARN = 'arn:aws:iam::00123456789:role/myrole
STORAGE_ALLOWED_LOCATIONS = ('s3://bucket1', 's3://bucket2')
STORAGE_BLOCKED_LOCATIONS = ('s3://bucket3/sensitive_data/')
Possiamo notare diversi aspetti:
- L'oggetto richiede l'ARN AWS del ruolo IAM. Ciò significa che, salvo si disponga già dell'accesso, sarà probabilmente necessario coinvolgere gli admin cloud AWS per creare un ruolo di accesso da usare con Snowflake.
- Per una singola storage integration è possibile definire più bucket o location. È un vantaggio non da poco, perché consente di riutilizzare la stessa Storage Integration per più bucket S3 o pipeline di dati.
Per approfondire le Storage Integration, consultare la documentazione Snowflake.
Stage
Ora che abbiamo creato gli oggetti File Format e Storage Integration, siamo pronti a creare il nostro Stage.
Lo Stage è la descrizione di una location di file: definisce dove sono archiviati i file destinati all'ingestion. Esistono due tipi di stage:
- Stage interni, che fanno parte del proprio account Snowflake
- Stage esterni, che tipicamente puntano a location di object storage (come un bucket AWS S3) del proprio cloud provider
Come best practice, consigliamo di usare gli stage esterni ove possibile, per due motivi:
- La maggior parte dei clienti Snowflake ha già i propri file di dati su Cloud Storage, quindi ha senso definire uno Stage esterno che punti a quei file.
- Conservando una copia dei dati grezzi al di fuori di Snowflake, quei file restano facilmente accessibili e utilizzabili anche da altri sistemi.
Se è stata seguita la best practice di definire separatamente gli oggetti File Format e Storage Integration, creare uno Stage diventa molto semplice. Ecco un esempio di comando per creare uno Stage esterno che punta a una location in AWS S3:
CREATE STAGE my_s3_stage
STORAGE_INTEGRATION =s3_int
URL = 's3://bucket1/path1/'
FILE_FORMAT= my_csv
Come anticipato, in alternativa si può fare a meno di creare oggetti File Format e Storage Integration separati e definire tutte le proprietà rilevanti direttamente nello Stage.
Come usare il comando COPY INTO
Una volta configurati gli oggetti FILE FORMAT, STAGE e STORAGE INTEGRATION necessari, siamo pronti a caricare i dati in Snowflake dal proprio cloud storage provider. Per farlo si utilizza il comando COPY.
Il comando COPY è una funzionalità Snowflake usata sia per il caricamento sia per lo scaricamento dei dati, con parametri diversi per ciascuna direzione. Vediamo come usare il comando COPY per l'import dei dati.
Utilizzo di base
Nella forma più semplice, COPY può presentarsi così:
COPY INTO mytable
FROM @my_s3_stage
Questa semplicità deriva dal fatto che il file format è stato definito come parte dell'oggetto stage. Di conseguenza non occorre specificare altri parametri o impostazioni. Per maggiori dettagli si rimanda alla documentazione del comando COPY.
Eseguire semplici trasformazioni sui dati
Il comando COPY supporta anche semplici trasformazioni dei dati tramite l'istruzione SELECT. Sono possibili operazioni come omettere colonne, riordinarle o farne il cast a un tipo di dato diverso. È inoltre possibile applicare FLATTEN ai dati semi-strutturati per ottenere singole colonne, oppure aggiungere un CURRENT_TIMESTAMP come colonna di audit.
Le singole colonne nell'istruzione SELECT si referenziano tramite il simbolo del dollaro seguito dalla posizione della colonna: $1, $2, $3, ecc.
Ecco un esempio in cui selezioniamo solo la prima, la seconda, la sesta e la settima colonna dal file in stage:
COPY INTO home_sales(city, zip, sale_date, price)
FROM (
SELECT t.$1, t.$2, t.$6, t.$7
FROM @mystage/sales.csv.gz t
)
Le seguenti operazioni non sono supportate nell'istruzione COPY:
WHEREORDER BYLIMITFETCHTOPJOINGROUP BY
Metadati del comando COPY
Il comando COPY genera metadati che si possono recuperare da diverse table function/view:
COPY_HISTORY- una table function nello schemasnowflake.information_schemaLOAD_HISTORY- una table function nello schemasnowflake.information_schemaLOAD_HISTORY- una view nello schemasnowflake.account_usage
Questi metadati contengono informazioni su ciascun file caricato: nome del file, numero di righe, numero di errori, tabella di destinazione, ecc. Sono i metadati stessi a impedire di caricare lo stesso file in Snowflake più di una volta. I metadati di caricamento scadono dopo 64 giorni. Se occorre ricaricare lo stesso file più volte, il comando COPY dispone dell'opzione FORCE = TRUE che lo consente.
Considerazioni sulla dimensione del Virtual Warehouse per il data loading
Il comando COPY richiede un virtual warehouse attivo per essere eseguito e per caricare i file. Con i virtual warehouse Snowflake si paga per ogni secondo di esecuzione, con un periodo di fatturazione minimo di 60 secondi a ogni riavvio del warehouse.
Quando si tratta di scegliere la dimensione corretta del warehouse specificamente per il data loading, vanno tenuti a mente due aspetti:
- Come anticipato, conviene raggruppare i file in batch da circa 100-250 MB (compressi). È importante per avere abbastanza file da sfruttare in modo efficace tutti i thread di elaborazione disponibili sul warehouse (al contrario di un unico file di grandi dimensioni, che può essere processato solo da un singolo thread). D'altra parte, un numero eccessivo di file piccoli può generare costi di overhead inutili.
- Usare sempre la dimensione di warehouse più piccola in grado di soddisfare i propri SLA. Si veda il case study qui sotto per un esempio reale.
Usare un warehouse di dimensioni maggiori comporta spesso core e thread inutilizzati, perché i file non sono sufficienti. Inoltre i file verranno elaborati in pochi secondi, ma la fatturazione resterà comunque sul minimo di 1 minuto. Per questo consigliamo di partire dalla dimensione di warehouse più piccola possibile e di aumentarla solo se i dati non vengono caricati abbastanza in fretta per i propri SLA.
Dimensionamento ipotetico del warehouse per il data loading
Per chiarire questi concetti, vediamo un esempio ipotetico.
Immaginiamo di dover ingerire 1 GB di dati al giorno. Sapendo già che caricare un unico file di grandi dimensioni non è efficace, i file vengono prodotti in chunk da 100 MB (10 file). Ipotizziamo un prezzo Snowflake di 3 $ a credito.
| Dimensione warehouse | Numero di core | Rapporto di utilizzo | Tempo di esecuzione | Tempo fatturato | Costo/giorno | Costo/anno |
|---|---|---|---|---|---|---|
| XS | 32 | ~30% | 10s | 60s | $0.2 | $73 |
| M | 8 | ~100% | 50s | 60s | $0.05 | $18.25 |
Con il warehouse Medium si arriva al massimo a un utilizzo del ~30%, perché ci sono solo 10 file da processare a fronte di 32 core disponibili. Gli 8 core dell'X-Small, invece, possono essere completamente saturati. Anche se il Medium processa i file 5 volte più velocemente, finisce per costare 4 volte tanto a causa dei 50 secondi di tempo inattivo che si è comunque costretti a pagare.
Esempio reale di dimensionamento del warehouse per il data loading
Per vedere come questo si traduce nella pratica, ecco i risultati ottenuti su un account Snowflake reale.
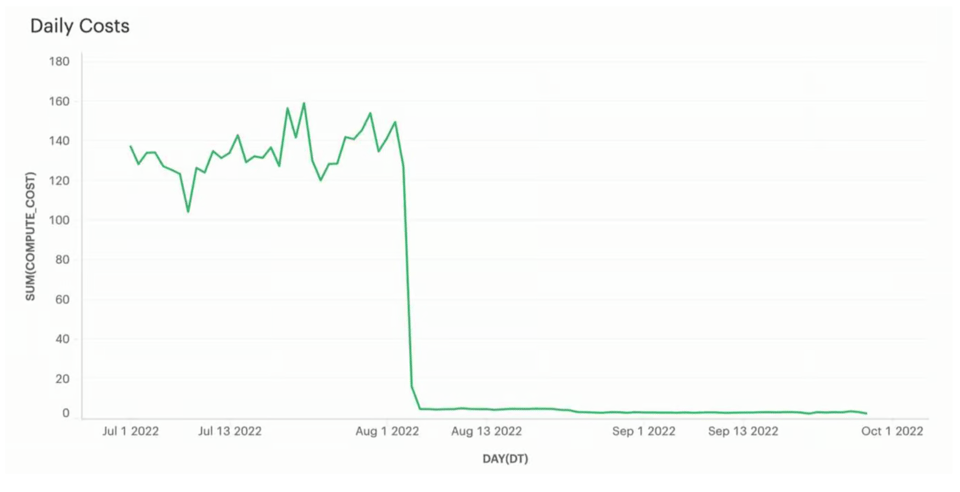
In origine questa pipeline di data loading utilizzava un warehouse Large. Caricava tutti i file in circa 5 secondi e poi restava inattiva per altri 55. Dopo aver ridotto il warehouse a una dimensione X-Small, il tempo di caricamento è salito a ~20 secondi in media.
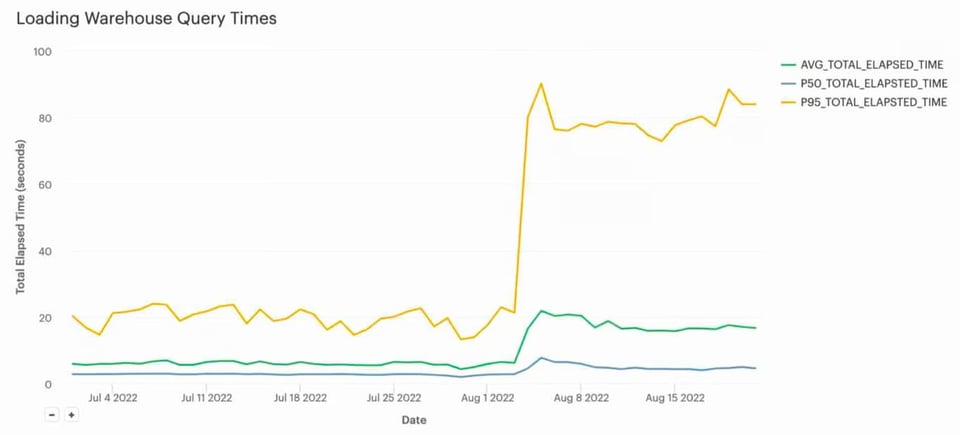
Ma soprattutto i costi sono crollati, passando da ~130 $/giorno a meno di 5 $/giorno, con un risparmio significativo di ~45.000 $ all'anno. Per questo cliente, vedere i dati caricati in ~20 secondi anziché in ~5 era pienamente compatibile con i propri SLA, quindi il compromesso si è rivelato decisamente vantaggioso.
Quando usare il calcolo serverless per il data loading?
Nel precedente articolo sulle 5 opzioni di data loading in Snowflake abbiamo condiviso alcuni consigli su quando valutare l'uso dei serverless tasks rispetto a un warehouse gestito.
Vi invitiamo a leggere quel post per i dettagli, ma in sintesi: conviene considerare i Serverless Tasks se i propri job di data loading durano meno di 40 secondi per la dimensione di warehouse scelta. Perché proprio 40 secondi? Perché il calcolo dei Serverless Tasks è tariffato 1,5 volte di più rispetto a quello dei warehouse gestiti. Ecco una tabella esemplificativa (ipotizzando 3 $ a credito):
| Dimensione warehouse | Tipo di calcolo | Tempo di esecuzione | Costo |
|---|---|---|---|
| XS | Serverless | 10s | $0.0125 |
| XS | Warehouse gestito | 10s | $0.05 |
| XS | Serverless | 35s | $0.0375 |
| XS | Warehouse gestito | 35s | $0.05 |
| XS | Serverless | 40s | $0.05 |
| XS | Warehouse gestito | 40s | $0.05 |
| XS | Serverless | 50s | $0.0625 |
| XS | Warehouse gestito | 50s | $0.05 |
Per chi è curioso di capire come si arriva ai costi indicati, ecco il calcolo della prima riga:
- Un warehouse X-Small usa 1 credito all'ora
- Per i serverless tasks va moltiplicato per 1,5
- I serverless tasks sono fatturati al secondo, quindi il costo è di 0,00125 $/secondo (
1 credito/ora * 1,5 * 3$/credito / 3600 secondi / ora)
E per la seconda riga:
- Un warehouse X-Small viene fatturato per un minimo di 60 secondi
- Il costo per qualsiasi durata inferiore a 60 secondi è di 0,05 $ (
1 credito / ora * 3$/credito / 60 minuti / ora)
Tomáš Sobotík·Senior Data Engineer & Snowflake SME presso Norlys
Tomas è da tempo Snowflake Data SuperHero e riconosciuto esperto di Snowflake. Vanta oltre un decennio di esperienza nel mondo dei dati, durante il quale ha ricoperto i ruoli di Snowflake data engineer, architect e admin in progetti che hanno toccato settori e tecnologie diversi. Tomas è un membro attivo della community, dove condivide con costanza la propria expertise e ispira gli altri. È inoltre istruttore O'Reilly e tiene sessioni di formazione live online.
Ian Whitestone·Co-founder & CEO di SELECT
Ian è Co-founder & CEO di SELECT, piattaforma SaaS per il cost management e l'ottimizzazione di Snowflake. Prima di fondare SELECT, Ian ha trascorso 6 anni alla guida di team full stack di data science & engineering in Shopify e Capital One. In Shopify ha guidato i progetti di ottimizzazione del data warehouse e di incremento dell'osservabilità dei costi.