Esta é a segunda parte da nossa série sobre carregamento de dados no Snowflake. No primeiro post, falamos sobre as cinco opções de carregamento de dados. Aqui, vamos nos aprofundar na técnica de ingestão mais comum: o batch data loading. Você vai ver:
- Como particionar e dimensionar seus arquivos antes do carregamento
- Como configurar seu Stage
- Como usar o comando COPY INTO
- Considerações sobre o tamanho do Virtual Warehouse
- Quando usar Serverless em vez de warehouses self-managed
Visão geral da preparação de arquivos
Seja para carregar dados em batch ou em tempo real, você precisa preparar um conjunto de arquivos. Primeiro, decida como esses arquivos vão ser particionados (organizados) no cloud storage. Isso pesa bastante no tempo que o Snowflake gasta escaneando o cloud storage para listar todos os arquivos disponíveis. Depois, pense em como agrupar os arquivos em tamanhos ideais para que os virtual warehouses usados no carregamento sejam aproveitados ao máximo. Por fim, escolha um formato de arquivo e configure seu objeto Stage.
Particionamento de arquivos
Em vez de jogar tudo em um único diretório, organize os arquivos por caminhos lógicos ou dimensões, como data/hora.
Por exemplo, se você guarda arquivos no S3, dá para organizá-los por data:
s3://my-data-bucket/2023/12/01/dataFile1.csvs3://my-data-bucket/2023/12/01/dataFile2.csvs3://my-data-bucket/2023/12/02/dataFile3.csvs3://my-data-bucket/2023/12/02/dataFile4.csvs3://my-data-bucket/2023/12/03/dataFile5.csv
Você pode ir além e adicionar outras dimensões para agrupar. Por exemplo, se quisermos organizar os dados por departamento, dá para armazenar os arquivos assim:
s3://my-data-bucket/finance/2023/12/01/dataFile1.csvs3://my-data-bucket/finance/2023/12/01/dataFile2.csvs3://my-data-bucket/marketing/2023/12/02/dataFile3.csvs3://my-data-bucket/marketing/2023/12/02/dataFile4.csv
A ideia central é: organize os arquivos pensando em como você vai carregá-los no Snowflake. O objetivo é reduzir a quantidade de arquivos que o Snowflake precisa escanear. Mesmo que o Snowflake controle automaticamente o que já foi carregado, listar todos os arquivos dentro do stage pode levar bastante tempo.
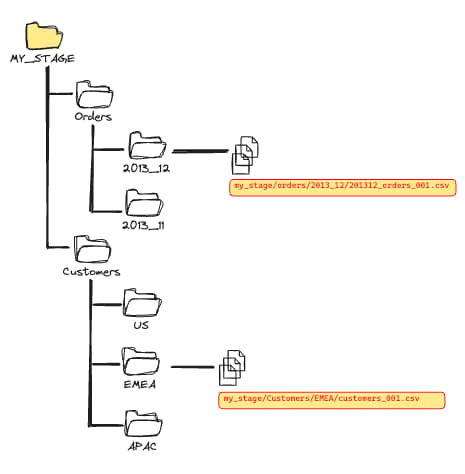
Quando os arquivos estão organizados nesses diretórios, o Snowflake só precisa escanear o que está dentro deles, e não o stage inteiro. Com essa estrutura no lugar, basta usar os filtros de caminho combinados com a palavra-chave PATTERN.
Veja os dois exemplos a seguir.
Este exemplo escaneia todos os arquivos do stage, mesmo com o uso da palavra-chave PATTERN. Isso acontece porque PATTERN é aplicada depois que todos os arquivos do stage são escaneados.
COPY INTO raw_table
FROM @my_stage
PATTERN='.*[.]csv'
Para o Snowflake pular o escaneamento custoso de arquivos desnecessários, é preciso especificar um filtro de caminho. Este segundo exemplo só escaneia os arquivos no diretório /orders/2023_12 e depois encontra todos os CSVs nesse caminho.
COPY INTO raw_table
FROM @my_stage/orders/2013_12
PATTERN='.*[.]csv'
Tamanhos ideais de arquivo para carregamento
O que mais impacta a eficiência do carregamento de dados é a quantidade e o tamanho dos arquivos.
O Snowflake recomenda arquivos entre 100 e 250 MB comprimidos. Se você tem muitos arquivos grandes, bem acima de 250 MB, tente dividi-los antes do carregamento. Da mesma forma, se há arquivos pequenos demais (<10 MB), vale a pena combiná-los antes.
A motivação é aproveitar ao máximo o virtual warehouse, carregando arquivos em paralelo e saturando todos os núcleos/threads de processamento disponíveis.
Veja a imagem abaixo. Faz uma diferença enorme carregar um único arquivo de 200 GB e usar só 2% de um warehouse XL (que processa até 128 arquivos em paralelo) ou dividir esse arquivo em vários menores e saturar o warehouse por completo!
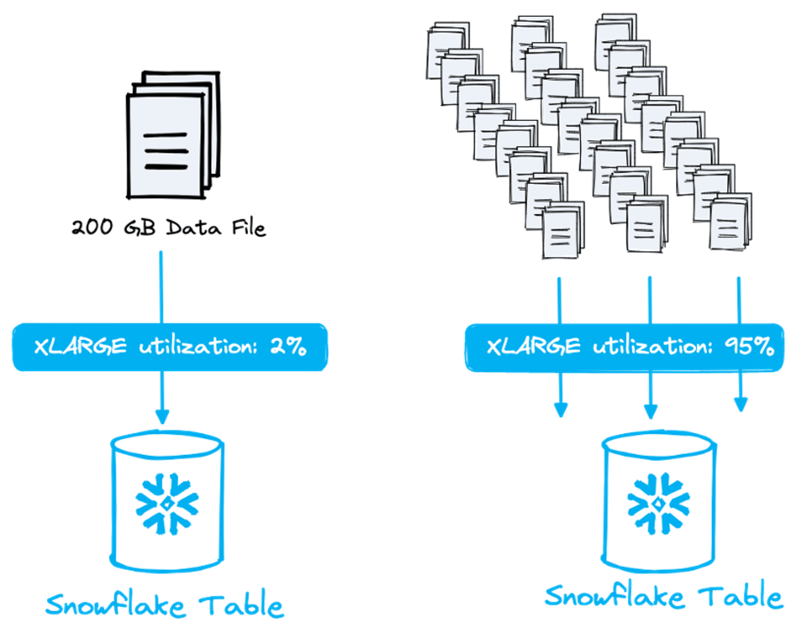
Cada tamanho de warehouse processa um número diferente de arquivos em paralelo. Ao aumentar o tamanho do warehouse, você dobra o número de nós. Cada nó tem 8 threads e cada thread processa 1 arquivo. Ou seja, o menor warehouse (XS), com um único nó e 8 threads, processa até 8 arquivos em paralelo!
| Tamanho do warehouse | nº de threads / arquivos a processar |
|---|---|
| XS | 8 |
| S | 16 |
| M | 32 |
| L | 64 |
| XL | 128 |
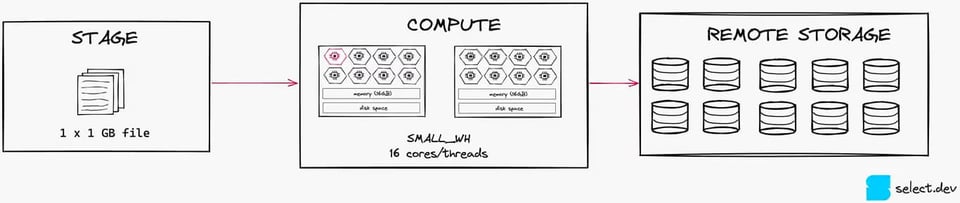
Para deixar esses efeitos ainda mais claros, veja a imagem abaixo. Com um arquivo de 1 GB, só saturamos 1 de 16 threads em um warehouse Small.
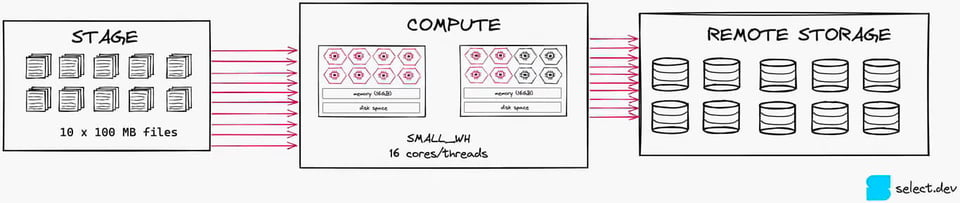
Se, em vez disso, você dividir esse arquivo em dez de 100 MB cada, vai usar 10 das 16 threads. Esse nível de paralelização é bem melhor, porque aproveita mais os recursos de computação disponíveis. Vale notar que, neste caso, um XSMALL seria uma escolha ainda melhor.
Configurando um Stage
No batch data loading, há três recursos adicionais do Snowflake com os quais você vai lidar:
- O objeto FILE FORMAT, que define o formato dos arquivos
- O objeto STORAGE INTEGRATION, que encapsula as informações de acesso aos locais de cloud storage.
- O objeto STAGE, que descreve onde os arquivos estão armazenados e como o Snowflake deve acessar esse local
Vamos detalhar cada um deles.
File Format
No Snowflake, há várias formas de definir o File Format:
- Como parte do comando
COPY - Como parte da definição do
STAGE - Como um objeto independente
Como boa prática, recomendamos definir o File Format como um objeto independente, para reutilizá-lo facilmente nas operações de carregamento. Além da reutilização, a manutenção também fica muito mais simples. Se precisar mudar algo no formato (trocar o delimitador, pular cabeçalho, etc.), você faz isso de forma centralizada no objeto, sem precisar mexer em cada pipeline. Outro benefício é poder controlar o acesso aos formatos pelo modelo RBAC do Snowflake.
Exemplo de criação de File Format
Considere um arquivo CSV como este:

O objeto File Format correspondente seria definido assim:
CREATE OR REPLACE FILE FORMAT my_csv
TYPE = csv
FIELD_DELIMITER = ‘,’
SKIP_HEADER = 1
NULL_IF = ''
Acesse a documentação do Snowflake para mais detalhes.
Opções de File Format do Snowflake
O Snowflake oferece suporte a vários formatos de arquivo:
- CSV
- JSON
- AVRO
- ORC
- Parquet
- XML
Confira a documentação para ver as opções de cada formato.
Storage Integration
O objeto Storage Integration funciona como uma camada de segurança para o Stage. Ele permite criar Stages em que as credenciais não são compartilhadas nem ficam armazenadas no Snowflake. Também é reutilizável: você define uma vez e usa em vários Stages. Com um Storage Integration configurado, os desenvolvedores não precisam saber quais roles ou credenciais são necessárias para acessar os arquivos — basta apontar o Stage para o Storage Integration certo. Isso segue a boa prática de segregação de funções.
Veja um exemplo de como criar um objeto Storage Integration para o Amazon S3:
CREATE STORAGE INTEGRATION s3_int
TYPE = EXTERNAL_STAGE
STORAGE_PROVIDER = 'S3'
ENABLED = TRUE
STORAGE_AWS_ROLE_ARN = 'arn:aws:iam::00123456789:role/myrole
STORAGE_ALLOWED_LOCATIONS = ('s3://bucket1', 's3://bucket2')
STORAGE_BLOCKED_LOCATIONS = ('s3://bucket3/sensitive_data/')
Algumas observações:
- O objeto exige o ARN da AWS da role IAM. Ou seja, provavelmente você vai precisar trabalhar com os admins de cloud da AWS para criar uma role de acesso que o Snowflake possa usar, a menos que já tenha esse acesso.
- Você pode definir vários buckets ou locais em uma única storage integration. Isso é útil, pois permite reutilizar o mesmo Storage Integration em vários buckets S3 ou pipelines de dados.
Para saber mais sobre Storage Integrations, acesse a documentação do Snowflake.
Stage
Agora que criamos os objetos File Format e Storage Integration, estamos prontos para criar o Stage.
Um Stage é uma descrição do local dos arquivos. Ele define onde os seus arquivos de dados para ingestão ficam armazenados. Há dois tipos de stages:
- Internal stages, que fazem parte da sua conta Snowflake
- External stages, que normalmente apontam para locais de object storage (como um bucket AWS S3) no seu provedor de nuvem
Como boa prática, recomendamos usar external stages sempre que possível, por dois motivos:
- A maioria dos clientes Snowflake já tem os arquivos de dados no Cloud Storage, então faz sentido definir um Stage externo apontando para esses arquivos.
- Mantendo uma cópia dos dados brutos fora do Snowflake, fica fácil acessar ou usar esses arquivos em outros sistemas
Se você seguiu a boa prática de definir objetos File Format e Storage Integration separados, criar um Stage fica bem simples. Veja um exemplo de comando para criar um Stage externo apontando para um local no AWS S3:
CREATE STAGE my_s3_stage
STORAGE_INTEGRATION =s3_int
URL = 's3://bucket1/path1/'
FILE_FORMAT= my_csv
Como mencionamos antes, você também pode pular a criação dos objetos separados de File Format e Storage Integration e definir todas as propriedades relevantes diretamente no Stage.
Como usar o comando COPY INTO
Depois de configurar os objetos FILE FORMAT, STAGE e STORAGE INTEGRATION necessários, você já pode carregar dados no Snowflake a partir do seu provedor de cloud storage. Para isso, é só usar o comando COPY.
O comando COPY é um recurso do Snowflake usado tanto para carregar quanto para descarregar dados, com parâmetros diferentes para cada direção. Vamos ver como usar o COPY para importações de dados.
Uso básico
Na forma mais simples, o COPY fica assim:
COPY INTO mytable
FROM @my_s3_stage
Essa simplicidade vem do fato de termos definido o file format como parte do objeto stage. Por isso, nenhum outro parâmetro ou configuração precisa ser especificado. Consulte a documentação do comando COPY para mais detalhes.
Realizando transformações simples de dados
O comando COPY também suporta transformações simples de dados usando a instrução SELECT. Operações como omitir colunas, reordená-las ou converter para outro tipo de dado são todas possíveis. Você também pode usar FLATTEN para transformar dados semiestruturados em colunas individuais ou adicionar um CURRENT_TIMESTAMP como coluna de auditoria.
As colunas individuais na instrução SELECT são referenciadas pelo cifrão junto da posição da coluna: $1, $2, $3, etc.
Veja um exemplo em que selecionamos apenas a primeira, a segunda, a sexta e a sétima coluna do arquivo no stage:
COPY INTO home_sales(city, zip, sale_date, price)
FROM (
SELECT t.$1, t.$2, t.$6, t.$7
FROM @mystage/sales.csv.gz t
)
As seguintes operações não são suportadas na instrução COPY:
WHEREORDER BYLIMITFETCHTOPJOINGROUP BY
Metadados do comando Copy
O comando COPY gera metadados que podem ser consultados em diferentes table functions/views:
COPY_HISTORY- uma table function no schemasnowflake.information_schemaLOAD_HISTORY- uma table function no schemasnowflake.information_schemaLOAD_HISTORY- uma view no schemasnowflake.account_usage
Esses metadados trazem informações sobre cada arquivo carregado, como nome do arquivo, contagem de linhas, contagem de erros, tabela de destino, etc. Isso evita que você carregue o mesmo arquivo no Snowflake mais de uma vez. Os metadados de carregamento expiram após 64 dias. Se precisar recarregar o mesmo arquivo várias vezes, o comando COPY tem a opção FORCE = TRUE, que libera o recarregamento.
Considerações sobre o tamanho do Virtual Warehouse para carregamento de dados
O comando COPY precisa de um virtual warehouse ativo para rodar e ingerir os arquivos. Nos virtual warehouses do Snowflake, você paga por cada segundo em que o warehouse está rodando, com cobrança mínima de 60 segundos sempre que ele é retomado.
Na hora de escolher o tamanho certo de warehouse especificamente para carregamento de dados, há dois pontos a ter em mente:
- Como falamos antes, agrupe os arquivos em torno de 100 MB a 250 MB (comprimidos). Isso garante que haja arquivos suficientes para aproveitar todas as threads de processamento disponíveis no warehouse (em vez de ter 1 arquivo grande, que só roda em uma thread). Por outro lado, arquivos pequenos demais podem gerar custos de overhead desnecessários.
- Use sempre o menor tamanho de warehouse possível que atenda aos seus SLAs. Veja o estudo de caso abaixo para um exemplo real na prática.
Usar um warehouse maior costuma deixar núcleos/threads ociosos, porque não há arquivos suficientes. O que também acontece é que você processa todos os arquivos em poucos segundos, mas continua sendo cobrado pelo período mínimo de 1 minuto. Por isso, recomendamos começar pelo menor tamanho de warehouse possível e só aumentar se os dados não estiverem sendo carregados rápido o suficiente para os seus SLAs.
Dimensionamento hipotético de warehouse para carregamento de dados
Para fixar esses conceitos, vamos a um exemplo hipotético.
Imagine que você precisa ingerir 1 GB de dados por dia. Você já sabe que carregar um único arquivo grande não é eficiente, então os arquivos são gerados em pedaços de 100 MB (10 arquivos). Vamos considerar o preço do crédito Snowflake em US$ 3/crédito.
| Tamanho do warehouse | Número de núcleos | Taxa de utilização | Tempo de execução | Tempo cobrado | Custo/dia | Custo/ano |
|---|---|---|---|---|---|---|
| XS | 32 | ~30% | 10s | 60s | US$ 0,20 | US$ 73 |
| M | 8 | ~100% | 50s | 60s | US$ 0,05 | US$ 18,25 |
Com o warehouse Medium, conseguimos no máximo ~30% de utilização, porque temos apenas 10 arquivos para processar e 32 núcleos disponíveis. Compare com o X-Small: seus 8 núcleos podem ficar totalmente saturados. Mesmo o Medium processando os arquivos 5 vezes mais rápido que o X-Small, ele acaba custando 4 vezes mais por causa dos 50 segundos de tempo ocioso que também entram na conta.
Exemplo real de dimensionamento de warehouse para carregamento de dados
Para ver como isso funcionou no mundo real, confira os resultados de uma conta Snowflake de verdade.
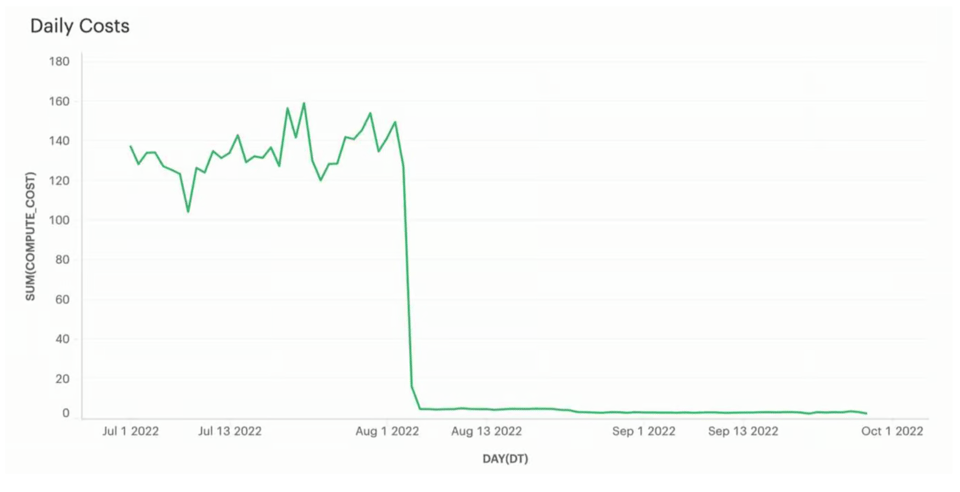
Originalmente, esse pipeline de carregamento usava um warehouse Large. Ele carregava todos os arquivos em cerca de 5 segundos e depois ficava ocioso por outros 55 segundos. Depois que o warehouse foi reduzido para X-Small, o tempo de carregamento subiu para ~20s em média.
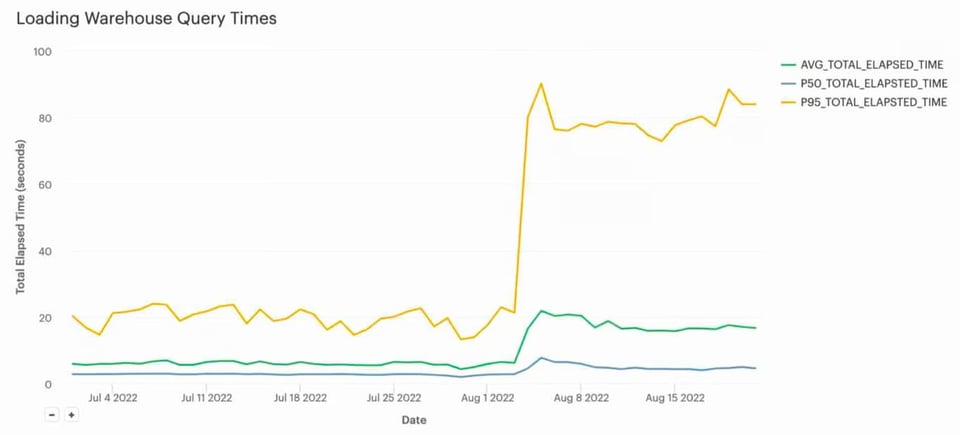
Mais importante: os custos despencaram, de ~US$ 130/dia para menos de US$ 5/dia, o que representa uma economia significativa de ~US$ 45.000/ano. Para esse cliente, carregar os dados em ~20s em vez de ~5s atendia aos SLAs, então o trade-off valeu muito a pena.
Quando usar serverless compute para carregamento de dados?
No nosso post anterior sobre as 5 opções de carregamento de dados no Snowflake, demos algumas dicas sobre quando considerar o uso de serverless tasks em vez de um warehouse self-managed.
Vale ler aquele post para se aprofundar, mas, em resumo: considere usar Serverless Tasks se os seus jobs de carregamento de dados levarem menos de 40 segundos no tamanho de warehouse em questão. Por que 40s? Porque o compute de Serverless Tasks é cobrado a uma taxa 1,5x maior que o compute de warehouses self-managed. Veja uma tabela de exemplo para detalhar (assumindo US$ 3/crédito):
| Tamanho do warehouse | Tipo de compute | Tempo de execução | Custo |
|---|---|---|---|
| XS | Serverless | 10s | US$ 0,0125 |
| XS | Self Managed Warehouse | 10s | US$ 0,05 |
| XS | Serverless | 35s | US$ 0,0375 |
| XS | Self Managed Warehouse | 35s | US$ 0,05 |
| XS | Serverless | 40s | US$ 0,05 |
| XS | Self Managed Warehouse | 40s | US$ 0,05 |
| XS | Serverless | 50s | US$ 0,0625 |
| XS | Self Managed Warehouse | 50s | US$ 0,05 |
Se ficou curioso sobre os cálculos de custo, veja como é feito na primeira linha:
- Um warehouse X-Small usa 1 crédito por hora
- Para serverless tasks, multiplicamos esse valor por 1,5
- Serverless tasks são cobradas por segundo, então o custo fica em US$ 0,00125/segundo (
1 crédito/hora * 1,5 * US$ 3/crédito / 3600 segundos / hora)
E na segunda linha:
- Um warehouse X-Small é cobrado por no mínimo 60 segundos
- O custo para qualquer execução abaixo de 60 segundos é: US$ 0,05 (
1 crédito / hora * US$ 3/crédito / 60 minutos / hora)
Tomáš Sobotík·Senior Data Engineer & Snowflake SME na Norlys
Tomas é Snowflake Data SuperHero de longa data e referência em Snowflake. Sua ampla experiência no mundo de dados ultrapassa uma década, atuando como Snowflake data engineer, arquiteto e admin em diversos projetos, setores e tecnologias. Tomas é membro ativo da comunidade, compartilhando seu conhecimento e inspirando outras pessoas. Também é instrutor na O'Reilly, conduzindo sessões de treinamento ao vivo online.
Ian Whitestone·Co-fundador & CEO da SELECT
Ian é Co-fundador e CEO da SELECT, uma plataforma SaaS de gestão e otimização de custos no Snowflake. Antes de fundar a SELECT, Ian passou 6 anos liderando times full stack de data science e engenharia na Shopify e na Capital One. Na Shopify, Ian liderou os esforços para otimizar o data warehouse e ampliar a observabilidade de custos.