Esta es la segunda parte de nuestra serie sobre carga de datos en Snowflake. En el primer artículo cubrimos las cinco opciones para cargar datos. En este vamos a profundizar en la técnica de ingesta más habitual: la carga de datos por lotes. Veremos:
- Cómo particionar y dimensionar tus archivos antes de cargarlos
- Cómo configurar tu Stage
- Cómo usar el comando COPY INTO
- Consideraciones sobre el tamaño del Virtual Warehouse
- Cuándo usar Serverless en lugar de warehouses autoadministrados
Preparación de archivos: panorama general
Tanto si cargas datos por lotes como en tiempo real, primero tienes que preparar el conjunto de archivos. Lo primero es decidir cómo se van a particionar (organizar) esos archivos en el almacenamiento en la nube. Esto incide directamente en el tiempo que Snowflake invierte escaneando el almacenamiento para listar todos los archivos disponibles. Después conviene pensar cómo agrupar los archivos en tamaños óptimos para que los virtual warehouses que uses durante la carga se aprovechen al máximo. Por último, hay que elegir un formato de archivo y configurar el objeto Stage.
Particionamiento de archivos
En lugar de listar todos los archivos en un solo directorio, conviene organizarlos siguiendo rutas o dimensiones lógicas, como la fecha o la hora.
Por ejemplo, si almacenas archivos en S3, podrías organizarlos por fecha:
s3://my-data-bucket/2023/12/01/dataFile1.csvs3://my-data-bucket/2023/12/01/dataFile2.csvs3://my-data-bucket/2023/12/02/dataFile3.csvs3://my-data-bucket/2023/12/02/dataFile4.csvs3://my-data-bucket/2023/12/03/dataFile5.csv
Incluso puedes ir un paso más allá y añadir dimensiones adicionales para agruparlos. Por ejemplo, si nos interesa organizar los datos por departamento, podríamos guardar los archivos así:
s3://my-data-bucket/finance/2023/12/01/dataFile1.csvs3://my-data-bucket/finance/2023/12/01/dataFile2.csvs3://my-data-bucket/marketing/2023/12/02/dataFile3.csvs3://my-data-bucket/marketing/2023/12/02/dataFile4.csv
La clave está en organizar los archivos en función de cómo planeas cargarlos en Snowflake. El objetivo es reducir la cantidad de archivos que Snowflake tiene que escanear. Aunque Snowflake lleva el control automático de los archivos que ya se cargaron, listar todos los que están dentro del stage puede tomar muchísimo tiempo.
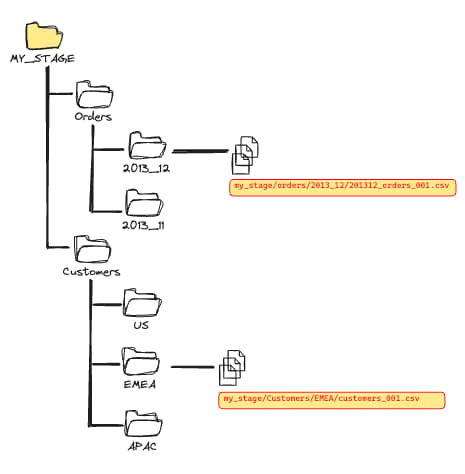
Al organizar los archivos en estos directorios, Snowflake solo tiene que escanear los archivos dentro de esos directorios y no todo el stage. Una vez que tengas esta estructura, debes usar los filtros de ruta combinándolos con la palabra clave PATTERN.
Veamos los siguientes dos ejemplos.
Este primer ejemplo escanea todos los archivos del stage indicado aun cuando se usa la palabra clave PATTERN. Esto sucede porque PATTERN se aplica después de escanear todos los archivos del stage.
COPY INTO raw_table
FROM @my_stage
PATTERN='.*[.]csv'
Para que Snowflake se ahorre el costoso escaneo de archivos innecesarios, hay que especificar un filtro de ruta. Este segundo ejemplo solo escaneará los archivos del directorio /orders/2023_12 y luego buscará todos los CSV dentro de esa ruta.
COPY INTO raw_table
FROM @my_stage/orders/2013_12
PATTERN='.*[.]csv'
Tamaños de archivo óptimos para la carga
Lo que más impacta en la eficiencia de la carga de datos es la cantidad y el tamaño de los archivos que cargas.
Snowflake recomienda apuntar a tamaños de archivo entre 100 y 250 MB comprimidos. Si tienes muchos archivos grandes que superan los 250 MB, conviene dividirlos antes de cargarlos. Del mismo modo, si tienes demasiados archivos pequeños (<10 MB), conviene combinarlos antes.
La idea es lograr un uso óptimo del virtual warehouse cargando archivos en paralelo y saturando todos los núcleos/hilos de CPU disponibles.
Mira la imagen a continuación. Hay una diferencia enorme entre cargar un único archivo de 200 GB y usar apenas el 2 % de un warehouse XL (que puede procesar hasta 128 archivos en paralelo), o dividir ese archivo en muchos más pequeños y saturarlo por completo.
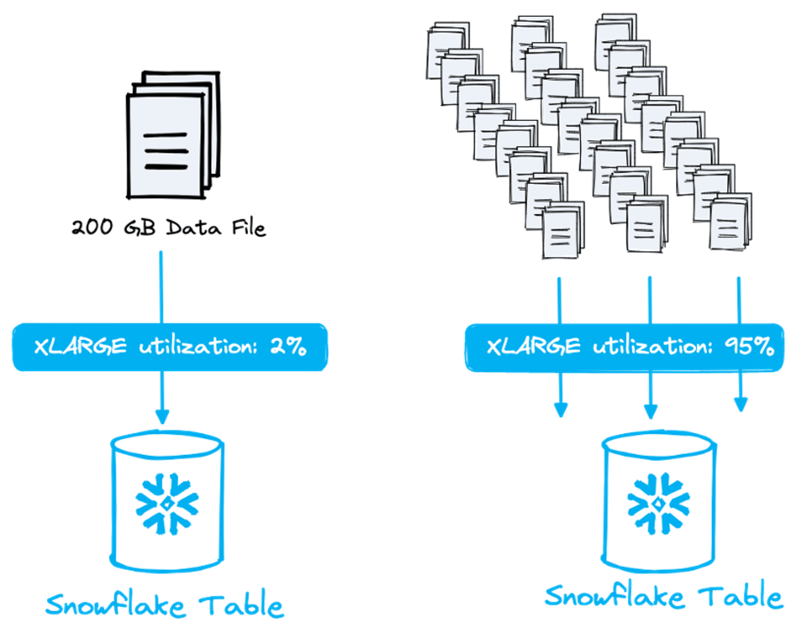
Cada tamaño de warehouse puede procesar una cantidad distinta de archivos en paralelo. A medida que aumentas el tamaño del warehouse, se duplica el número de nodos. Cada nodo tiene 8 hilos y cada hilo procesa 1 archivo. Esto significa que el warehouse más pequeño (XS), con un solo nodo y 8 hilos, puede procesar hasta 8 archivos en paralelo.
| Tamaño del warehouse | # Hilos / Archivos a procesar |
|---|---|
| XS | 8 |
| S | 16 |
| M | 32 |
| L | 64 |
| XL | 128 |
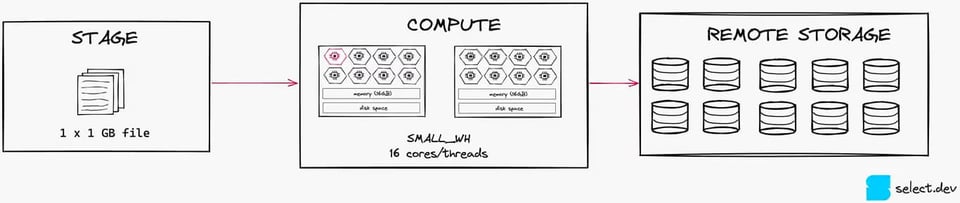
Para ilustrar mejor estos efectos, mira la imagen a continuación. Si tenemos un solo archivo de 1 GB, solo saturaremos 1 de los 16 hilos de un warehouse Small.
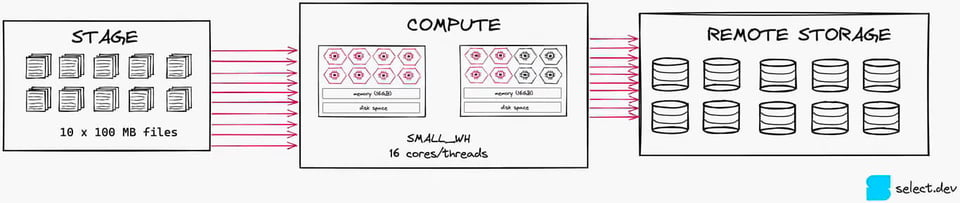
Si en cambio divides ese archivo en diez archivos de 100 MB cada uno, usarás 10 de los 16 hilos. Este nivel de paralelización es mucho mejor porque se aprovechan más los recursos de cómputo disponibles. Vale aclarar que, en este caso, un XSMALL sería la mejor opción.
Configurar un Stage
En la carga de datos por lotes hay tres recursos adicionales de Snowflake con los que vas a trabajar:
- El objeto FILE FORMAT, que define el formato de los archivos
- El objeto STORAGE INTEGRATION, que encapsula la información de acceso a las ubicaciones de almacenamiento en la nube.
- El objeto STAGE, que describe dónde se almacenan los archivos y cómo debe acceder Snowflake a esa ubicación
Veamos cada uno en detalle.
File Format
En Snowflake hay varias formas de definir el File Format:
- Como parte del comando
COPY - Como parte de la definición del
STAGE - Como un objeto independiente
Como buena práctica, se recomienda definir el File Format como un objeto independiente, lo que te permite reutilizarlo fácilmente en todas tus operaciones de carga. Además de la reutilización, el mantenimiento se vuelve mucho más simple. Si necesitas modificar algo en el formato (por ejemplo, cambiar el delimitador, omitir el encabezado, etc.), lo haces de forma centralizada en el objeto. No tienes que entrar a cada uno de tus pipelines y modificarlos todos. Otro beneficio es que puedes controlar el acceso a los formatos usando el modelo RBAC de Snowflake.
Ejemplo de creación de un File Format
Considera un archivo CSV como este:

El objeto File Format correspondiente se definiría así:
CREATE OR REPLACE FILE FORMAT my_csv
TYPE = csv
FIELD_DELIMITER = ‘,’
SKIP_HEADER = 1
NULL_IF = ''
Puedes consultar la documentación de Snowflake para más detalles.
Opciones de File Format en Snowflake
Snowflake admite varios formatos de archivo:
- CSV
- JSON
- AVRO
- ORC
- Parquet
- XML
Consulta la documentación para ver las opciones de cada formato.
Storage Integration
El objeto Storage Integration funciona como una capa de seguridad para un Stage. Te permite crear Stages en los que las credenciales no se comparten ni se almacenan dentro de Snowflake. Además, son reutilizables: se definen una sola vez y luego se usan con múltiples Stages. Con un Storage Integration en su lugar, los desarrolladores no necesitan saber qué roles o credenciales se requieren para acceder a los archivos; basta con apuntar su Stage al objeto Storage Integration correspondiente. Esto se alinea con la buena práctica de segregación de funciones.
A continuación, un ejemplo de cómo crear un objeto Storage Integration para Amazon S3:
CREATE STORAGE INTEGRATION s3_int
TYPE = EXTERNAL_STAGE
STORAGE_PROVIDER = 'S3'
ENABLED = TRUE
STORAGE_AWS_ROLE_ARN = 'arn:aws:iam::00123456789:role/myrole
STORAGE_ALLOWED_LOCATIONS = ('s3://bucket1', 's3://bucket2')
STORAGE_BLOCKED_LOCATIONS = ('s3://bucket3/sensitive_data/')
Notarás varias cosas:
- El objeto requiere el ARN de AWS del rol IAM. Esto significa que probablemente tengas que coordinar con tus administradores de AWS para crear un rol de acceso que Snowflake pueda usar, salvo que ya cuentes con ese acceso.
- Puedes definir varios buckets o ubicaciones para un único storage integration. Esto es útil porque te permite reutilizar el mismo Storage Integration en varios buckets de S3 o pipelines de datos.
Para conocer más sobre los Storage Integrations, consulta la documentación de Snowflake.
Stage
Ahora que ya creamos los objetos File Format y Storage Integration, estamos listos para crear nuestro Stage.
Un Stage es una descripción de la ubicación de los archivos. Define dónde se almacenan los archivos de datos para la ingesta. Hay dos tipos de stages:
- Stages internos, que forman parte de tu cuenta de Snowflake
- Stages externos, que normalmente apuntan a ubicaciones de almacenamiento de objetos (como un bucket de AWS S3) en tu proveedor de nube
Como buena práctica, recomendamos usar stages externos siempre que sea posible por dos motivos:
- La mayoría de los clientes de Snowflake ya tienen sus archivos de datos cargados en Cloud Storage, así que tiene sentido definir un Stage externo que apunte a esos archivos.
- Al mantener una copia de tus datos crudos fuera de Snowflake, puedes acceder fácilmente a esos archivos o usarlos con otros sistemas.
Si seguiste la buena práctica de definir los objetos File Format y Storage Integration por separado, crear un Stage se vuelve muy sencillo. Acá tienes un comando de ejemplo para crear un Stage externo que apunta a una ubicación en AWS S3:
CREATE STAGE my_s3_stage
STORAGE_INTEGRATION =s3_int
URL = 's3://bucket1/path1/'
FILE_FORMAT= my_csv
Como mencionamos antes, también puedes omitir la creación de los objetos File Format y Storage Integration por separado y, en su lugar, definir todas las propiedades relevantes directamente en el Stage.
Cómo usar el comando COPY INTO
Una vez que tengas configurados los objetos FILE FORMAT, STAGE y STORAGE INTEGRATION necesarios, ya estás listo para cargar datos en Snowflake desde tu proveedor de almacenamiento en la nube. Para hacerlo, puedes apoyarte en el comando COPY.
El comando COPY es una funcionalidad de Snowflake que sirve tanto para cargar como para descargar datos, con distintos parámetros según la dirección del movimiento. Veamos cómo se usa el comando COPY para importar datos.
Uso básico
En su forma más simple, el COPY se ve así:
COPY INTO mytable
FROM @my_s3_stage
Esta simplicidad se debe a que definimos el formato de archivo como parte del objeto stage. Por eso no hace falta especificar otros parámetros ni configuraciones. Puedes consultar la documentación del comando COPY para más detalles.
Cómo hacer transformaciones simples de datos
El comando COPY también admite transformaciones simples de datos usando la sentencia SELECT. Se pueden hacer operaciones como omitir columnas, reordenarlas o convertirlas a otro tipo de dato. También puedes hacer FLATTEN de datos semiestructurados en columnas individuales o agregar un CURRENT_TIMESTAMP como columna de auditoría.
Las columnas individuales dentro de la sentencia SELECT se referencian mediante el signo dólar junto con la posición de la columna: $1, $2, $3, etc.
Acá tienes un ejemplo en el que seleccionamos solo la primera, segunda, sexta y séptima columnas del archivo en stage:
COPY INTO home_sales(city, zip, sale_date, price)
FROM (
SELECT t.$1, t.$2, t.$6, t.$7
FROM @mystage/sales.csv.gz t
)
Las siguientes operaciones no se admiten en la sentencia COPY:
WHEREORDER BYLIMITFETCHTOPJOINGROUP BY
Metadatos del comando COPY
El comando COPY genera metadatos que pueden consultarse desde distintas funciones de tabla o vistas:
COPY_HISTORY: una función de tabla en el esquemasnowflake.information_schemaLOAD_HISTORY: una función de tabla en el esquemasnowflake.information_schemaLOAD_HISTORY: una vista en el esquemasnowflake.account_usage
Estos metadatos contienen información de cada archivo cargado, como el nombre del archivo, el conteo de filas, el conteo de errores, la tabla destino, etc. Gracias a estos metadatos, no se carga el mismo archivo más de una vez en Snowflake. Los metadatos de carga expiran a los 64 días. Si necesitas recargar el mismo archivo varias veces, existe la opción FORCE = TRUE del comando COPY, que permite volver a cargarlo.
Consideraciones sobre el tamaño del Virtual Warehouse para la carga de datos
El comando COPY requiere un virtual warehouse activo para ejecutarse e ingestar los archivos. Con los virtual warehouses de Snowflake, pagas por cada segundo que el warehouse está en ejecución, con un período mínimo de facturación de 60 segundos cada vez que el warehouse se reanuda.
A la hora de elegir el tamaño de warehouse adecuado específicamente para la carga de datos, hay dos cosas que tener en cuenta:
- Como ya mencionamos, conviene agrupar tus archivos en tamaños de 100 MB a 250 MB (comprimidos). Esto es importante para asegurar que tengas suficientes archivos como para usar de forma efectiva todos los hilos de procesamiento disponibles del warehouse (en lugar de tener un solo archivo grande que solo puede procesarse en un único hilo). Por otro lado, tener demasiados archivos pequeños puede generar costos de overhead innecesarios.
- Usa siempre el tamaño de warehouse más pequeño posible que cumpla con tus SLAs. Mira el caso de estudio más abajo para ver un ejemplo real.
Usar un tamaño de warehouse más grande suele dejar núcleos/hilos sin uso porque no vas a tener suficientes archivos. Lo que también pasa es que procesas todos los archivos en pocos segundos, pero te facturan igual el período mínimo de 1 minuto. Por eso recomendamos empezar con el tamaño de warehouse más pequeño posible y solo subirlo si los datos no se cargan con la velocidad que tus SLAs requieren.
Dimensionamiento hipotético del warehouse para la carga de datos
Para afianzar estos conceptos, veamos un ejemplo hipotético.
Imagina que necesitas ingestar 1 GB de datos al día. Ya sabes que cargar un único archivo grande no es efectivo, así que los archivos se generan en bloques de 100 MB (10 archivos). Asumiremos un precio de crédito de Snowflake de USD 3/crédito.
| Tamaño del warehouse | Número de núcleos | Ratio de utilización | Tiempo de ejecución | Tiempo facturado | Costo/día | Costo/año |
|---|---|---|---|---|---|---|
| XS | 32 | ~30% | 10s | 60s | $0.2 | $73 |
| M | 8 | ~100% | 50s | 60s | $0.05 | $18.25 |
Con el warehouse Medium, solo se alcanza un ~30 % de utilización en el mejor de los casos, porque hay únicamente 10 archivos para procesar y 32 núcleos disponibles. Compara eso con el warehouse X-Small: sus 8 núcleos pueden saturarse por completo. Aunque el Medium procesa los archivos 5 veces más rápido que el X-Small, termina costando 4 veces más por los 50 s de tiempo inactivo que también se pagan.
Ejemplo real de dimensionamiento del warehouse para la carga de datos
Para ver cómo se da esto en la práctica, mira los resultados de una cuenta real de Snowflake.
Originalmente, este pipeline de carga de datos usaba un warehouse Large. Cargaba todos los archivos en unos 5 segundos y luego quedaba inactivo durante otros 55 segundos. Tras reducir el warehouse a un tamaño X-Small, el tiempo de carga aumentó a ~20 s en promedio.
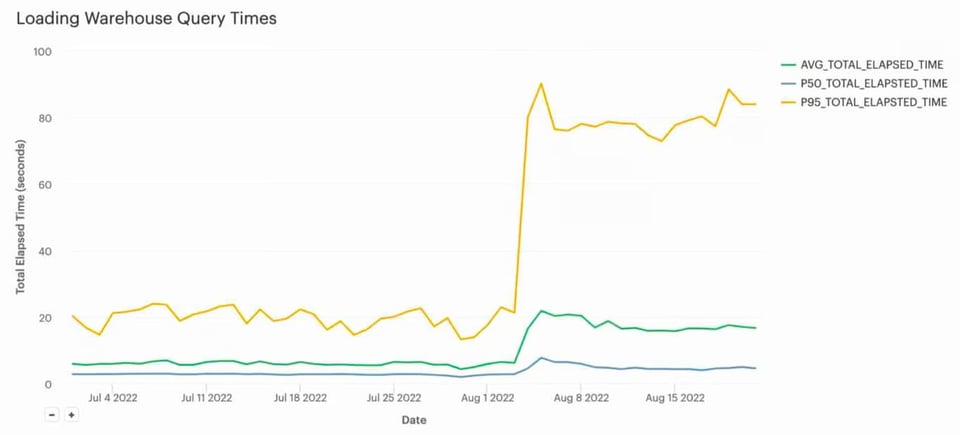
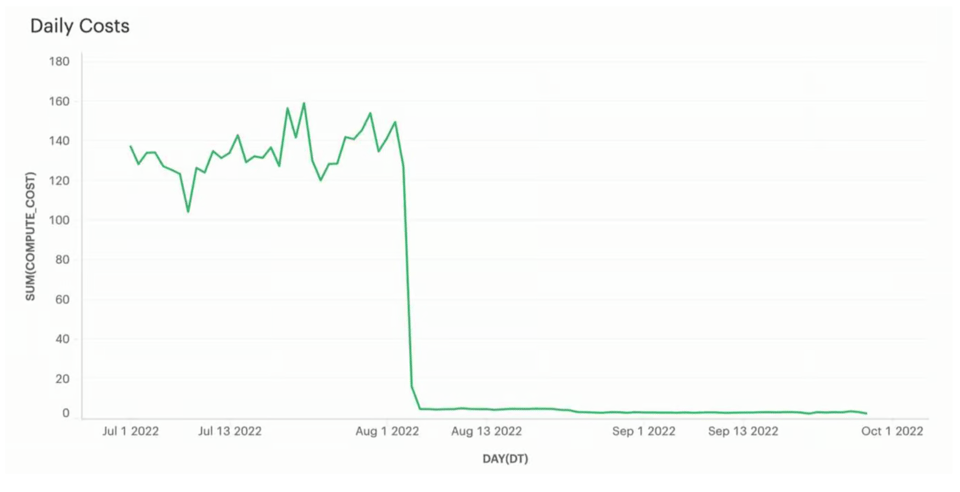
Más importante aún, los costos cayeron en picada: de ~$130/día a menos de $5/día, lo que representa un ahorro significativo de ~$45.000/año. Para este cliente, que la carga tardara ~20 s en lugar de ~5 s era aceptable según sus SLAs, así que el trade-off valió la pena.
¿Cuándo conviene usar cómputo serverless para la carga de datos?
En nuestro artículo anterior sobre las 5 opciones de carga de datos en Snowflake, compartimos algunos tips sobre cuándo conviene usar serverless tasks en vez de un warehouse autoadministrado.
Te invitamos a leer ese artículo para conocer más detalles, pero si quieres el resumen rápido: deberías plantearte usar Serverless Tasks si tus trabajos de carga de datos tardan menos de 40 segundos en el tamaño de warehouse dado. ¿Por qué 40 s? Porque el cómputo de Serverless Tasks se cobra a 1,5x el costo del cómputo de los warehouses autoadministrados. Acá tienes una tabla de ejemplo que lo desglosa (asumiendo USD 3/crédito):
| Tamaño del warehouse | Tipo de cómputo | Tiempo de ejecución | Costo |
|---|---|---|---|
| XS | Serverless | 10s | $0.0125 |
| XS | Warehouse autoadministrado | 10s | $0.05 |
| XS | Serverless | 35s | $0.0375 |
| XS | Warehouse autoadministrado | 35s | $0.05 |
| XS | Serverless | 40s | $0.05 |
| XS | Warehouse autoadministrado | 40s | $0.05 |
| XS | Serverless | 50s | $0.0625 |
| XS | Warehouse autoadministrado | 50s | $0.05 |
Si tienes curiosidad sobre el cálculo de costos, así se obtiene el de la primera fila:
- Un warehouse X-Small consume 1 crédito por hora
- Para serverless tasks, hay que multiplicar eso por 1,5
- Las serverless tasks se facturan por segundo, así que el costo queda en $0.00125/segundo (
1 crédito/hora * 1.5 * $3/crédito / 3600 segundos / hora)
Y para la segunda fila:
- Un warehouse X-Small se factura por un mínimo de 60 segundos
- El costo para cualquier ejecución menor a 60 segundos es: $0.05 (
1 crédito / hora * $3/crédito / 60 minutos / hora)
Tomáš Sobotík·Senior Data Engineer & Snowflake SME en Norlys
Tomas es un Snowflake Data SuperHero de larga trayectoria y un referente general en temas de Snowflake. Su amplia experiencia en el mundo de los datos abarca más de una década, durante la cual se ha desempeñado como data engineer, arquitecto y administrador de Snowflake en distintos proyectos de diversas industrias y tecnologías. Tomas es miembro central de la comunidad: comparte activamente su conocimiento e inspira a otros. También es instructor de O'Reilly y dicta sesiones de capacitación en vivo en línea.
Ian Whitestone·Cofundador y CEO de SELECT
Ian es cofundador y CEO de SELECT, una plataforma SaaS de gestión y optimización de costos de Snowflake. Antes de fundar SELECT, Ian pasó 6 años liderando equipos full stack de data science e ingeniería en Shopify y Capital One. En Shopify, lideró los esfuerzos para optimizar su data warehouse y aumentar la observabilidad de costos.