Snowflake ist eine enorm leistungsstarke Plattform, die mühelos mit immer größeren Datenmengen skaliert – ohne Leistungseinbußen. Doch ohne Gegensteuern steigen die Kosten schnell. Ob Sie den Preis einer anstehenden Vertragsverlängerung drücken, die Laufzeit Ihres bestehenden Vertrags strecken oder On-Demand-Kosten senken wollen – mit den Strategien in diesem Beitrag holen Sie spürbare Einsparungen heraus.
Alle hier vorgestellten Ansätze stammen aus der Praxis: SELECT hat sie bereits gemeinsam mit über 100 Snowflake-Kunden umgesetzt. Falls Sie meinen, dass etwas fehlt, freuen wir uns über Ihre Rückmeldung – per E-Mail oder über das Chat-Fenster unten rechts.
Dieser Beitrag widmet sich Techniken zur Kostenoptimierung und zeigt, wie Sie damit unnötigen Verbrauch von Snowflake-Credits vermeiden und Budget für andere workloads frei machen. Wenn es Ihnen darum geht, Ihre Snowflake-Queries zu beschleunigen, werfen Sie einen Blick in unseren Beitrag zur Snowflake Query Optimization – dort finden Sie konkrete Tipps für kürzere Query-Laufzeiten.
Bevor Sie loslegen
Bevor Sie starten, sollten Sie unbedingt Ihre tatsächlichen Snowflake-Kostentreiber und das Snowflake-Preismodell kennen. Wir erleben immer wieder, dass Snowflake-Kunden direkt mit der Optimierung einzelner Queries oder der Senkung von Storage-Kosten beginnen – ohne zu prüfen, ob dort überhaupt der größte Hebel liegt.
Wir empfehlen, zunächst die Übersicht zum Snowflake Cost Management im Admin-Bereich der UI zu öffnen und sich einen Überblick zu verschaffen, welche Services (Compute, Storage, Serverless usw.) den Großteil Ihrer Kosten ausmachen. Bei den meisten Kunden ist Compute der mit Abstand größte Treiber – typischerweise über 80 % der gesamten Snowflake-Kosten. Im nächsten Schritt sollten Sie verstehen, welche workloads innerhalb Ihrer Virtual Warehouses den Löwenanteil der Kosten verursachen. Das ermitteln Sie, indem Sie die Kosten pro Query berechnen und anschließend anhand von Query-Metadaten aggregieren – etwa über Query Tags oder Kommentare.
Techniken zur Kostenoptimierung
Die Maßnahmen in diesem Beitrag lassen sich in sechs Kategorien einteilen:
1. Konfiguration der Virtual Warehouses
- Auto-Suspend verkürzen
- Warehouse-Größe reduzieren
- Mindestanzahl an Clustern auf 1 setzen
- Warehouses konsolidieren
2. Workload-Konfiguration
- Query-Frequenz reduzieren
- Nur neue oder aktualisierte Daten verarbeiten
3. Tabellenkonfiguration
- Tabellen korrekt clustern
- Ungenutzte Tabellen löschen
- Datenaufbewahrung verkürzen
- Transient Tables nutzen
5. Muster beim Laden von Daten
- Häufige DML-Operationen vermeiden
- Dateien vor dem Laden optimal dimensionieren
6. Eingebaute Snowflake-Kontrollen nutzen
- Per Zugriffssteuerung die Nutzung und Änderung von Warehouses beschränken
- Query-Timeouts aktivieren
- Snowflake Resource Monitors einrichten
Legen wir direkt los.
1\. Auto-Suspend auf 60 Sekunden setzen
Setzen Sie für alle Virtual Warehouses ein Auto-Suspend von 60 Sekunden. Eine Ausnahme gilt nur für nutzerseitige workloads, bei denen geringe Latenz oberste Priorität hat und der Warehouse-Cache häufig zum Einsatz kommt. Im Zweifel: erst mit 60 Sekunden starten und nur erhöhen, falls die Performance leidet.
alter warehouse compute_wh set
auto_suspend=60;
Die Auto-Suspend-Einstellung hat erheblichen Einfluss auf die Rechnung, denn Snowflake berechnet jede Sekunde, die ein Warehouse läuft – mit einem Minimum von 60 Sekunden. Aus diesem Grund raten wir davon ab, Auto-Suspend unter 60 Sekunden zu setzen, da es sonst zu Doppelabrechnungen kommen kann. Werte über 60 Sekunden führen wiederum dazu, dass Virtual Warehouses abgerechnet werden, obwohl sie gar keine Queries verarbeiten. Standardmäßig haben alle über die Oberfläche erstellten Virtual Warehouses ein Auto-Suspend von 5 Minuten – Vorsicht also beim Anlegen neuer Warehouses.
Jedes Mal, wenn ein Snowflake Virtual Warehouse wieder hochfährt, wird mindestens 1 Minute berechnet. Danach erfolgt die Abrechnung sekundengenau. Technisch lässt sich Auto-Suspend zwar auch auf unter 60 Sekunden setzen (sogar 0 ist möglich), doch Snowflake fährt das Warehouse erst nach 30 Sekunden Inaktivität wirklich herunter.
Wegen der Mindestabrechnungsdauer von 1 Minute kann es bei einem Auto-Suspend von 30 Sekunden zu doppelten Kosten kommen. Ein Beispiel:
- Eine Query trifft ein und läuft 1 Sekunde lang
- Das Warehouse fährt nach 30 Sekunden herunter
- Unmittelbar danach kommt die nächste Query, weckt das Warehouse auf und läuft 1 Sekunde
- Das Warehouse fährt nach weiteren 30 Sekunden erneut herunter
Obwohl das Warehouse insgesamt nur rund 1 Minute aktiv war, werden in diesem Szenario 2 Minuten Compute berechnet – das Warehouse ist zweimal hochgefahren, und pro Resume wird mindestens 1 Minute fällig.
2\. Virtual-Warehouse-Größe reduzieren
Rechenressourcen und Kosten von Virtual Warehouses skalieren exponentiell. Zur Erinnerung – Compute-Kosten pro Stunde in Credits (Dollar), bei einem typischen Preis von 2,50 $ pro Credit:
| Warehouse-Größe | Stündliche Kosten Virtual Warehouse |
|---|---|
| X-Small | 1 ($2.50) |
| Small | 2 ($5) |
| Medium | 4 ($10) |
| Large | 8 ($20) |
| X-Large | 16 ($40) |
| 2X-Large | 32 ($80) |
| 3X-Large | 64 ($160) |
| 4X-Large | 128 ($320) |
| 5X-Large | 256 ($640) |
| 6X-Large | 512 ($1280) |
Und hier die monatlichen Kosten pro Warehouse bei durchgehendem Betrieb (auch wenn Warehouses dank Auto-Suspend in der Praxis selten so laufen – das vermittelt aber ein besseres Kostengefühl als der Stundenwert):
| Warehouse-Größe | Stündliche Kosten Virtual Warehouse |
|---|---|
| X-Small | 720 ($1,800) |
| Small | 1,440 ($3,600) |
| Medium | 2,880 ($7,200) |
| Large | 5,760 ($14,400) |
| X-Large | 11,520 ($28,800) |
| 2X-Large | 23,040 ($57,600) |
| 3X-Large | 46,080 ($115,200) |
| 4X-Large | 92,160 ($230,400) |
| 5X-Large | 184,320 ($460,800) |
| 6X-Large | 368,640 ($921,600) |
Überdimensionierte Warehouses verursachen mitunter den Großteil der Snowflake-Nutzung. Verkleinern Sie die Warehouse-Größe und beobachten Sie, wie sich das auf Ihre workloads auswirkt. Bleibt die Performance akzeptabel, verkleinern Sie weiter. In unserem ausführlichen Leitfaden zur Wahl der richtigen Warehouse-Größe in Snowflake finden Sie praktische Heuristiken, um überdimensionierte Warehouses zu erkennen.
Beispiel für die Reduzierung der Warehouse-Größe:
Ein kurzes Praxisbeispiel: Ein Data-Loading-Job lädt stündlich zehn Dateien auf einem Small Warehouse. Ein Small Warehouse verfügt über 2 Nodes mit insgesamt 16 Kernen für die Verarbeitung. Dieser Job kann maximal 10 der 16 Kerne auslasten (1 Datei pro Kern) – das Warehouse wird also nicht voll genutzt. Auf einem X-Small Warehouse läuft derselbe Job deutlich kosteneffizienter.
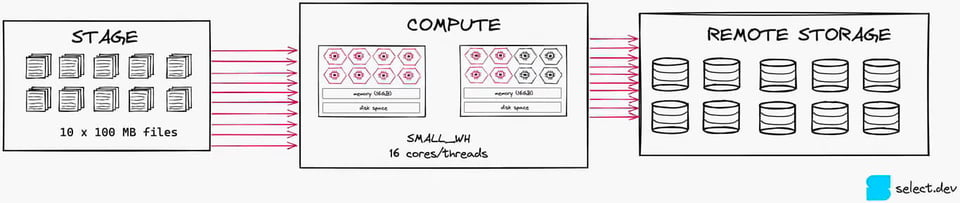
3\. Mindestanzahl an Clustern auf 1 setzen
Ab der Snowflake Enterprise Edition steht Multi-Cluster-Warehousing zur Verfügung: Warehouses können bei steigender Last parallel zusätzliche Cluster zuschalten. Die Mindestanzahl an Clustern sollte immer auf 1 stehen, um Überprovisionierung zu vermeiden. Snowflake schaltet bei Bedarf automatisch und nahezu verzögerungsfrei weitere Cluster bis zur konfigurierten Obergrenze zu. Werte über 1 führen zu ungenutzten, aber abrechenbaren Clustern.
1alter warehouse compute_wh set min_cluster_count=1;
4\. Warehouses konsolidieren
Ein häufiges Problem bei Snowflake-Kunden ist Warehouse-Wildwuchs. Gibt es zu viele Warehouses, sind viele davon nicht ausgelastet und laufen leer mit – ein vermeidbarer Credit-Verbrauch.
Hier ein Beispiel aus unserem eigenen Snowflake-Account, visualisiert im SELECT-Produkt. Wir berechnen eine eigene Kennzahl, die Warehouse Utilization Efficiency, die den Zeitanteil angibt, in dem ein Warehouse aktiv Queries verarbeitet. Das Warehouse SELECT_BACKEND_LARGE in der zweiten Zeile kommt nur auf 11 % – in 89 % der bezahlten Zeit läuft es also leer, ohne eine einzige Query zu verarbeiten. Auch mehrere weitere Warehouses haben eine geringe Effizienz.
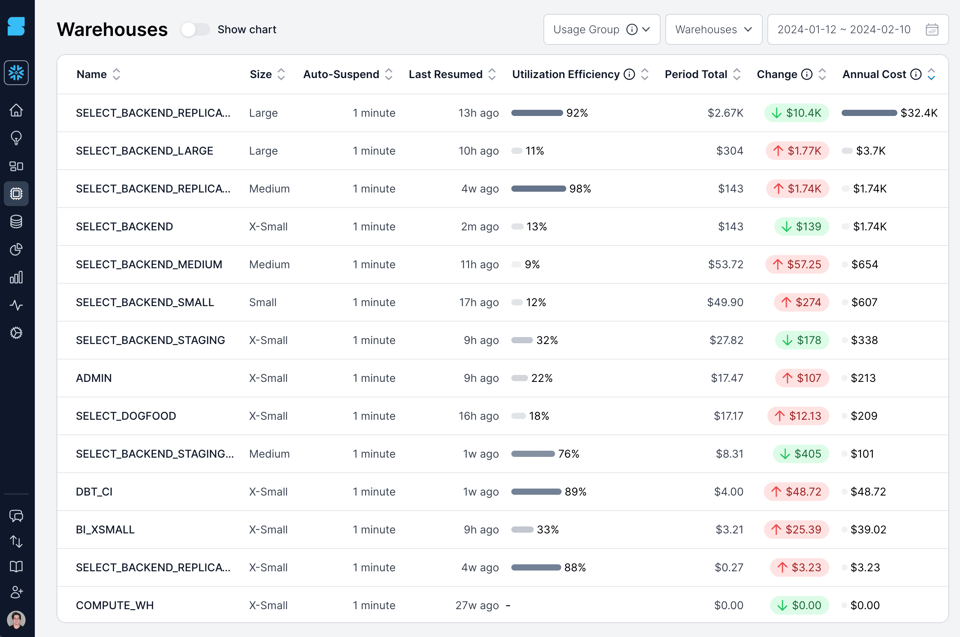
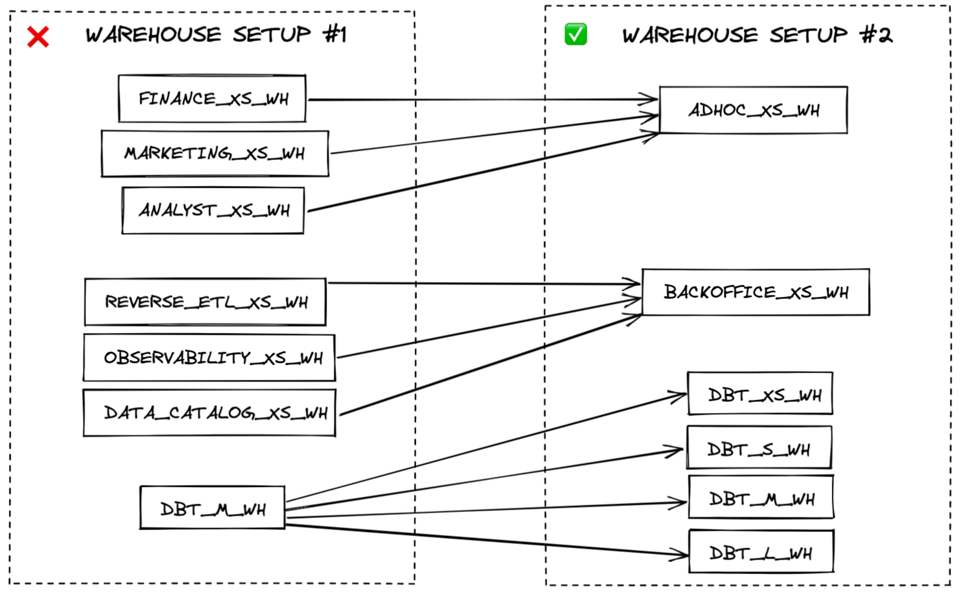
Der beste Weg zu effizient genutzten Virtual Warehouses: so wenige wie möglich. Wo nötig, sollten Sie separate Warehouses nach Performance-Anforderungen anlegen – nicht nach Fachdomänen.
Beispiel: Ein Warehouse für sämtliches Data Loading, eines für Transformationen und eines für Live-BI-Abfragen ist kosteneffizienter als ein Warehouse für Marketingdaten und ein zweites für Finanzdaten. Data-Loading-workloads haben in der Regel ähnliche Performance-Anforderungen (eine gewisse Wartezeit ist tolerierbar) und können sich oft ein Multi-Cluster-X-Small-Warehouse teilen. Live-Abfragen für Endnutzer profitieren dagegen häufig von einem größeren Warehouse, um die Latenz niedrig zu halten.
Brauchen einzelne workloads innerhalb einer Kategorie (Loading, Transformation, Live-Abfragen usw.) für ausreichende Geschwindigkeit eine größere Warehouse-Größe, legen Sie speziell dafür ein eigenes größeres Warehouse an. Für maximale Kosteneffizienz gilt: Queries laufen idealerweise auf dem kleinsten Warehouse, auf dem sie noch schnell genug sind.
5\. Query-Frequenz reduzieren
In vielen Unternehmen laufen Batch-Datentransformationsjobs standardmäßig stündlich. Aber brauchen die nachgelagerten Anwendungsfälle wirklich eine so niedrige Latenz? Hier ein paar Beispiele, wie sich eine geringere Ausführungshäufigkeit unmittelbar auf die Kosten auswirkt. Wir nehmen an, dass alle workloads nicht-inkrementell sind und bei jedem Lauf ein vollständiger Daten-Refresh erfolgt, und dass die stündliche Ausführung ursprünglich 100.000 $ kostet.
| Ausführungsfrequenz | Jahreskosten | Ersparnis |
|---|---|---|
| Stündlich | $100,000 | $0 |
| Stündlich werktags, täglich am Wochenende | $75,000 | $75,000 |
| Stündlich während der Arbeitszeit | $50,000 | $50,000 |
| Einmal zu Arbeitsbeginn, einmal mittags | $8,000 | $92,000 |
| Täglich | $4,000 | $96,000 |
6\. Nur neue oder aktualisierte Daten verarbeiten
Ein erheblicher Teil der Daten ist unveränderlich – nach der Erstellung ändert sich nichts mehr. Beispiele sind Web- oder Versand-Events. Andere Daten ändern sich zwar, aber selten über ein bestimmtes Zeitfenster hinaus – etwa Bestellungen, die einen Monat nach dem Kauf kaum noch angepasst werden.
Statt bei jedem Batch-Job alle Daten neu zu verarbeiten, lässt sich per Inkrementalisierung gezielt auf Datensätze filtern, die innerhalb eines bestimmten Zeitfensters neu oder aktualisiert sind. Diese werden transformiert und anschließend per Insert oder Update in die Zieltabelle übernommen.
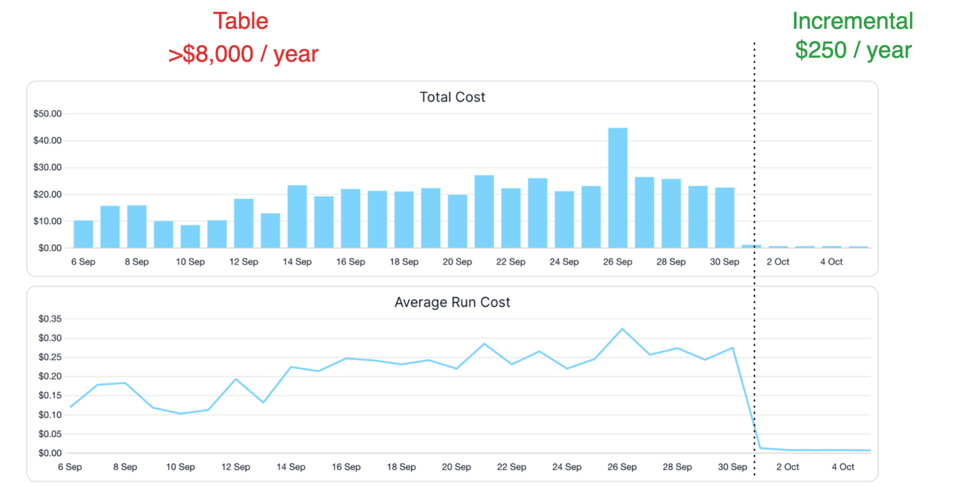
Bei einer ein Jahr alten Events-Tabelle kann die Umstellung auf inkrementelle, reine Insert-Transformationen für ausschließlich neue Datensätze die Kosten um 99 % senken. Bei einer ein Jahr alten Bestelltabelle lässt sich gegenüber vollständigen Refreshes eine Ersparnis von 90 % erzielen, wenn nur der letzte Monat und neue Bestellungen erneut verarbeitet und aktualisiert werden.
Hier ein Beispiel für die Kostenersparnis, die wir mit der Umstellung eines unserer Datenmodelle auf rein inkrementelle Verarbeitung erreicht haben:
7\. Tabellen korrekt clustern
Eine der wichtigsten Query-Optimierungstechniken ist Query Pruning: ein Verfahren, das die Anzahl der bei einer Query gelesenen Micro-Partitions verringert. Das Lesen von Micro-Partitions ist einer der teuersten Schritte einer Query, da Daten über das Netzwerk remote geladen werden müssen. Liegt ein Filter in einer WHERE-Klausel, einem Join oder einer Subquery vor, versucht Snowflake, alle Micro-Partitions auszuschließen, die nachweislich keine relevanten Daten enthalten. Damit das funktioniert, müssen die Micro-Partitions für die Filterspalte einen engen Wertebereich enthalten.
Voraussetzung für Query Pruning ist, dass die Tabelle in Snowflake passend zu den Query-Zugriffsmustern geclustert ist. Stellen Sie sich eine orders-Tabelle vor, in der häufig nach Bestellungen ab einem bestimmten Datum (created_at) gefiltert wird. Eine solche Tabelle sollte nach created_at geclustert sein.

Führt ein Nutzer die folgende Query gegen die orders-Tabelle aus, kann Query Pruning den Großteil der Micro-Partitions vom Scannen ausschließen – die Laufzeit sinkt deutlich und damit auch die Kosten.
select *
from orders
where created_at > '2022/08/14'
8\. Ungenutzte Tabellen löschen
Auch wenn sie meist nur einen kleinen Anteil (<20 %) der gesamten Snowflake-Kosten ausmachen, können ungenutzte Tabellen und Time-Travel-Backups Ihre Snowflake-Credits aufzehren. Wir haben bereits beschrieben, wie sich ungenutzte Tabellen identifizieren lassen, sofern Sie mindestens die Snowflake Enterprise Edition nutzen. Andernfalls können Sie über die View TABLE_STORAGE_METRICS nach TOTAL_BILLABLE_BYTES sortieren, um die Tabellen mit den höchsten Storage-Kosten zu finden.
select
table_catalog as database_name,
table_schema as schema_name,
table_name,
(active_bytes + time_travel_bytes + failsafe_bytes + retained_for_clone_bytes) as total_billable_bytes
from snowflake.account_usage.table_storage_metrics
order by total_billable_bytes desc
limit 10
9\. Datenaufbewahrung verkürzen
Wie in unserem Beitrag zu Snowflake Storage-Kosten beschrieben, kann die Time-Travel-Einstellung (Datenaufbewahrung) zusätzliche Kosten verursachen, da Snowflake während des Aufbewahrungszeitraums Kopien aller Tabellenänderungen vorhalten muss. Jeder Snowflake-Nutzer sollte sich fragen: Brauche ich überhaupt Zugriff auf historische Tabellenstände – und wenn ja, wie viele Tage Historie sind wirklich nötig?
Um den Aufbewahrungszeitraum für eine bestimmte Tabelle zu verkürzen, führen Sie folgende Query aus:
1alter table table set data_retention_time_in_days=0;
Für eine accountweite Änderung:
1alter account set data_retention_time_in_days=0;
10\. Transient Tables nutzen
Auch Fail-Safe-Storage ist eine Kostenquelle, die sich summieren kann – besonders bei Tabellen mit hoher Änderungsrate (mehr dazu weiter unten).
Wenn Ihre Tabellen im Rahmen eines ETL-Prozesses regelmäßig gelöscht und neu erstellt werden oder eine separate Datenkopie im Cloud-Storage vorliegt, ist ein Backup der Daten in den meisten Fällen überflüssig. Indem Sie eine Tabelle von permanent auf transient umstellen, vermeiden Sie unnötige Kosten für Fail-Safe- und Time-Travel-Backups.
-- example query to create a table as transient
create or replace transient table orders as (
select *
from raw.orders
...
)
11\. Häufige DML-Operationen vermeiden
Ein bekanntes Anti-Pattern in Snowflake ist, die Plattform wie eine operative Datenbank zu nutzen und ständig wenige Datensätze zu aktualisieren, einzufügen oder zu löschen.
Warum sollte man das vermeiden? Aus zwei Gründen:
- Snowflake-Tabellen werden in unveränderlichen Micro-Partitions gespeichert, die Snowflake auf rund 16 MB komprimiert hält. Eine einzelne Micro-Partition kann also Hunderttausende Datensätze enthalten. Bei jedem Update oder Delete eines einzelnen Datensatzes muss Snowflake die komplette Micro-Partition neu erstellen – das Aktualisieren eines einzigen Datensatzes kann also das Neuschreiben von Hunderttausenden bedeuten. Auch
insert-Operationen sind davon betroffen, Stichwort Small File Compaction: Snowflake versucht, neue Datensätze mit bestehenden Micro-Partitions zu kombinieren, statt eine neue mit nur wenigen Datensätzen anzulegen. - Für Time Travel und Fail-Safe-Storage muss Snowflake Kopien aller Tabellenversionen vorhalten. Werden Micro-Partitions häufig neu erstellt, steigt der Storage-Bedarf erheblich. Bei Tabellen mit hoher Änderungsrate kann der Storage für Time Travel und Fail Safe schnell größer werden als der aktive Storage der Tabelle selbst. Mehr dazu finden Sie in unserem Beitrag zum Lebenszyklus einer Snowflake-Tabelle.
12\. Optimale Dateigrößen sicherstellen
Für kosteneffizientes Data Loading gilt als Best Practice eine Dateigröße zwischen 100 und 250 MB. Zur Veranschaulichung: Wenn Sie nur eine einzige 1-GB-Datei haben, lasten Sie auf einem Small Warehouse für das Loading nur 1 von 16 Threads aus.
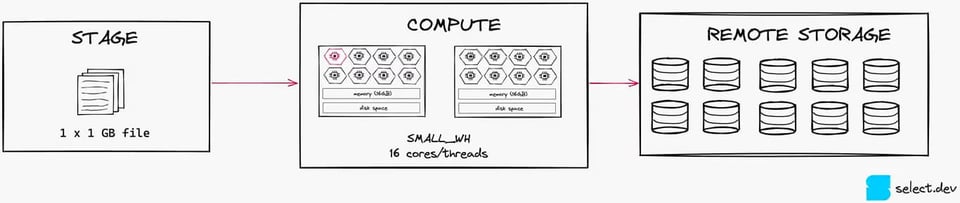
Teilen Sie diese Datei stattdessen in zehn Dateien à 100 MB, nutzen Sie 10 von 16 Threads. Diese Parallelisierung ist deutlich besser, weil sie die vorhandenen Compute-Ressourcen besser ausnutzt (wobei in diesem Szenario ein X-Small immer noch die bessere Wahl wäre).
Auch zu viele kleine Dateien können die Kosten in die Höhe treiben, wenn Sie Snowpipe für das Data Loading einsetzen – Snowflake berechnet einen Overhead von 0,06 Credits pro 1.000 geladene Dateien.
13\. Zugriffssteuerung nutzen
Zugriffssteuerung ist ein wirkungsvolles Instrument zur Kostenkontrolle, das viele Snowflake-Kunden gar nicht auf dem Schirm haben. Wenn Sie einschränken, wer Änderungen an Virtual Warehouses vornehmen darf, sinkt das Risiko, dass jemand versehentlich Ressourcen umstellt und damit unerwartete Kosten auslöst. Wir haben unzählige Fälle erlebt, in denen jemand die Warehouse-Größe hochgesetzt und vergessen hat, sie wieder zu reduzieren. Mit strengerer Zugriffssteuerung sorgen Unternehmen dafür, dass Ressourcenänderungen einen kontrollierten Prozess durchlaufen, und reduzieren das Risiko unbeabsichtigter Anpassungen.
Die Zugriffssteuerung lässt sich auch nutzen, um zu regeln, welche Nutzer Queries auf welchen Warehouses ausführen dürfen. Wer nur Zugriff auf kleinere Warehouses hat, wird quasi automatisch dazu angehalten, effizientere Queries zu schreiben, statt reflexhaft auf ein größeres Warehouse auszuweichen. Für berechtigte Ausnahmen können Sie Richtlinien oder Prozesse etablieren, damit bestimmte Queries oder Nutzer im Einzelfall ein größeres Warehouse verwenden dürfen.
14\. Query-Timeouts aktivieren
Query-Timeouts sind eine Einstellung, die verhindert, dass Snowflake-Queries zu lange laufen – und damit zu teuer werden. Überschreitet eine Query den eingestellten Timeout, bricht Snowflake sie automatisch ab.
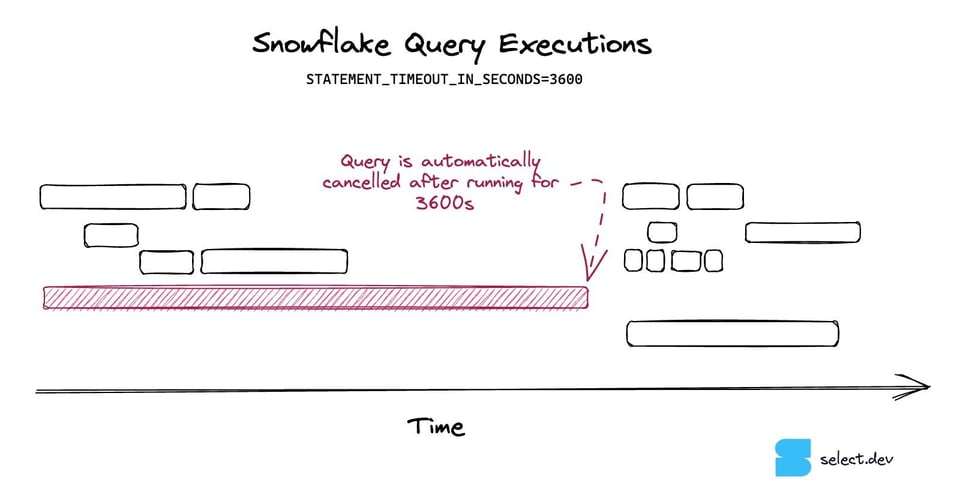
Query-Timeouts sind ein hervorragendes Mittel, um die Auswirkungen außer Kontrolle geratener Queries zu begrenzen. Standardmäßig kann eine Snowflake-Query bis zu zwei Tage laufen, bevor sie abgebrochen wird – und in dieser Zeit erhebliche Kosten verursachen. Wir empfehlen, auf allen Warehouses Query-Timeouts zu setzen, um die maximalen Kosten einer einzelnen Query zu deckeln. Hinweise zur konkreten Einrichtung finden Sie in unserem Beitrag zum Thema.
15\. Resource Monitors einrichten
Ähnlich wie Query-Timeouts ermöglichen Resource Monitors, die Gesamtkosten eines bestimmten Warehouses zu deckeln. Sie eignen sich für zwei Zwecke:
- Sie informieren Sie, sobald die Kosten einen bestimmten Schwellenwert erreichen.
- Sie verhindern, dass ein Warehouse in einem definierten Zeitraum mehr als einen festgelegten Betrag kostet. Snowflake kann Queries auf einem Warehouse blockieren, sobald dessen Kontingent ausgeschöpft ist.
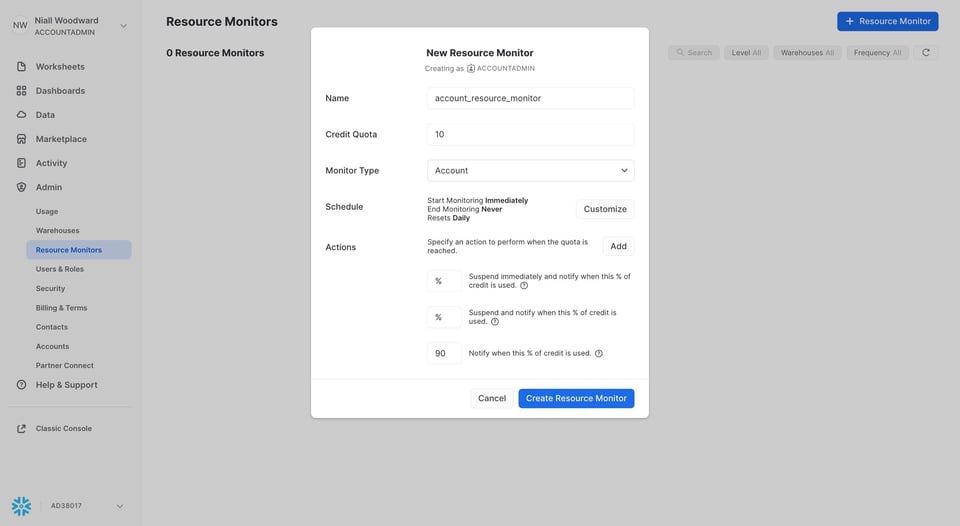
Resource Monitors sind ein hervorragendes Mittel, um Überraschungen auf der Rechnung zu vermeiden und unnötige Kosten gar nicht erst entstehen zu lassen.
Ein letzter Rat
Aus der Welt der FinOps stammt ein passendes Zitat:
Die größten Cloud-Einsparungen ergeben sich aus Kosten, die nie anfallen.
In diesem Beitrag haben wir zahlreiche Wege aufgezeigt, mit denen Sie Ihre Snowflake-Kosten senken können – sei es, um Einsparziele zu erreichen oder Budget für neue workloads frei zu machen. Doch wer überhaupt erst an diesen Punkt gelangt, hat die Kosten bereits getragen und unter Umständen über längere Zeit suboptimal gearbeitet.
Einer der besten Wege, unnötige Kosten gar nicht erst entstehen zu lassen, ist eine konsequente Cost-Monitoring-Strategie von Anfang an. Bauen Sie sich Ihr eigenes Dashboard auf Basis der Snowflake Account-Usage-Views und prüfen Sie es wöchentlich – oder nutzen Sie ein spezialisiertes Cost-Monitoring-Produkt wie SELECT. Wer Kostenprobleme früh erkennt, verhindert, dass sich unnötige Ausgaben überhaupt erst aufbauen.
The Missing Manual: Everything You Need to Know about Snowflake Cost Optimization (April 2023)
Wenn Sie eine Präsentation suchen, die viele der hier behandelten Themen abdeckt, empfehlen wir Ihnen unseren Vortrag vom Data Council im April 2023.
In diesem Talk behandeln wir alles, was Sie zu Kosten- und Performance-Optimierung in Snowflake wissen müssen. Wir starten mit einem Deep Dive in Snowflakes Architektur und Abrechnungsmodell und gehen auf zentrale Konzepte wie Virtual Warehouses, Micro-Partitioning, den Lebenszyklus einer Query und Snowflakes zweistufigen Cache ein. Anschließend beleuchten wir die wichtigsten Optimierungsstrategien im Detail: Konfiguration von Virtual Warehouses, Table Clustering und Best Practices beim Schreiben von Queries. Im gesamten Vortrag teilen wir Code-Snippets und weitere Ressourcen, mit denen Sie das Maximum aus Snowflake herausholen.
Aufzeichnung
Eine Aufzeichnung der Präsentation ist auf YouTube verfügbar.
Play
Auf Wunsch kommen wir auch gerne zu Ihnen, halten diese Präsentation (oder eine angepasste Variante) vor Ihrem Team und beantworten Fragen. Schreiben Sie uns einfach eine E-Mail an [email protected], um einen Termin zu vereinbaren.
Folien
[PUBLIC COPY] The Missing Manual - SELECT - Data Council - Google Slides
Wird geladen…
Das kann einen Moment dauern
1
Wird geladen…
Teile dieser Folie konnten nicht geladen werden. Erneut versuchen Neu laden
Alles löschenShift+A
Einige Folien konnten nicht geladen werden. Aktualisieren
Sprechernotizen öffnenS
Laserpointer einschaltenL
Laserpointer ausschaltenL
Stift einschaltenShift+L
Stift ausschaltenShift+L
Vollbild aktivierenStrg+Shift+F
Vollbild verlassenStrg+Shift+F
Displays tauschenD
Präsentation beendenEsc
Automatische Wiedergabe►
Untertitel-Einstellungen
Mehr►
Fragen & AntwortenA
Als PDF herunterladen
Als PPTX herunterladen
DruckenStrg+P
Im Editor öffnen
TastaturkürzelStrg+/
Problem melden
Missbrauch melden
Ian Whitestone·Co-Founder & CEO von SELECT
Ian ist Co-Founder & CEO von SELECT, einer SaaS-Plattform für Snowflake Cost Management und Optimierung. Vor SELECT hat Ian sechs Jahre lang Full-Stack-Data-Science- und Engineering-Teams bei Shopify und Capital One geleitet. Bei Shopify verantwortete er die Optimierung des Data Warehouse und den Ausbau der Cost Observability.
Niall Woodward·Co-Founder & CTO von SELECT
Niall ist Co-Founder & CTO von SELECT, einer SaaS-Plattform für Snowflake Cost Management und Optimierung. Vor SELECT war Niall Data Engineer bei Brooklyn Data Company und mehreren Startups. Als Open-Source-Enthusiast ist er außerdem Maintainer von SQLFluff und Schöpfer von drei dbt-Paketen: dbt_artifacts, dbt_snowflake_monitoring und dbt_query_tags.