Snowflake es una plataforma sumamente potente que escala sin esfuerzo para manejar volúmenes de datos cada vez mayores sin sacrificar el rendimiento. Pero, sin un control adecuado, los costos asociados a ese escalamiento se disparan rápido. Ya sea que busques reducir el precio de una próxima renovación, extender la vigencia de tu contrato actual o bajar los costos on-demand, aplica las estrategias de este post para generar ahorros significativos.
Todo lo que vamos a tratar se basa en estrategias reales que SELECT ha ayudado a implementar a más de 100 clientes de Snowflake. Si crees que se nos quedó algo en el tintero, ¡nos encantaría saberlo! Escríbenos por correo o usa la burbuja de chat al final de la pantalla.
Este post se centra en técnicas de optimización de costos y en cómo aprovecharlas para eliminar el consumo innecesario de créditos de Snowflake y liberar presupuesto para otros workloads. Si lo que buscas es que tus consultas en Snowflake corran más rápido, no dejes de revisar nuestro post sobre optimización de consultas en Snowflake, con tips accionables para acelerar el tiempo de ejecución.
Antes de empezar
Antes de empezar, es fundamental que primero entiendas cuáles son los verdaderos generadores de costos en Snowflake y su modelo de Precios. Vemos a muchos clientes de Snowflake lanzarse de lleno a optimizar consultas específicas o a reducir sus costos de almacenamiento, sin darse cuenta de que esos puntos quizá no son el problema ni el mejor lugar por dónde empezar.
Como punto de partida, recomendamos revisar el resumen de gestión de costos de Snowflake en la sección de admin de la UI y entender qué servicios (compute, almacenamiento, serverless, etc.) concentran la mayor parte de tus costos. En la mayoría de los casos, compute será el principal generador (suele superar el 80% del costo total de Snowflake). Una vez que lo tengas claro, el siguiente foco debe ser identificar qué workloads dentro de tus virtual warehouses concentran realmente la mayor parte de los costos. Esto se determina calculando un costo por consulta y luego agregando esos costos según la metadata de la consulta (por ejemplo, query tags o comentarios).
Técnicas de optimización de costos
Las técnicas de reducción de costos de este post se agrupan en seis grandes categorías:
1. Configuración del virtual warehouse
- Reducir el auto-suspend
- Reducir el tamaño del warehouse
- Asegurar que los clusters mínimos estén en 1
- Consolidar warehouses
2. Configuración del workload
- Reducir la frecuencia de las consultas
- Procesar solo datos nuevos o actualizados
3. Configuración de tablas
- Asegurar que tus tablas estén correctamente clusterizadas
- Eliminar tablas sin uso
- Reducir la retención de datos
- Usar tablas transient
5. Patrones de carga de datos
- Evitar operaciones DML frecuentes
- Asegurar que tus archivos tengan un tamaño óptimo antes de cargarlos
6. Aprovechar los controles nativos de Snowflake
- Usar control de acceso para restringir el uso y la modificación de los warehouses
- Habilitar timeouts en las consultas
- Configurar resource monitors de Snowflake
Vamos al grano.
1\. Reduce el auto-suspend a 60 segundos
Configura timeouts de auto-suspend de 60 segundos en todos los virtual warehouses. La única excepción son los workloads orientados al usuario final donde la baja latencia es prioritaria y la caché del warehouse se usa con frecuencia. Si tienes dudas, ve por 60 segundos y súbelo si el rendimiento se ve afectado.
alter warehouse compute_wh set
auto_suspend=60;
La configuración del auto-suspend tiene un impacto enorme en la factura, porque Snowflake cobra por cada segundo que un warehouse está corriendo, con un mínimo de 60 segundos. Por eso no recomendamos configurar el auto-suspend por debajo de 60 segundos: puede derivar en cobros duplicados. Configuraciones de auto-suspend superiores a 60 segundos hacen que los virtual warehouses sigan siendo facturables aun cuando no estén procesando ninguna consulta. Por defecto, todos los virtual warehouses creados desde la interfaz de usuario vienen con auto-suspend de 5 minutos, así que ojo al crear nuevos warehouses.
Cada vez que un virtual warehouse de Snowflake se reanuda, se cobra un mínimo de 1 minuto. A partir de ahí, el cobro es por segundo. Aunque técnicamente puedes poner el auto-suspend por debajo de 60s (¡incluso en 0s si quieres!), Snowflake solo lo apagará tras 30 segundos de inactividad.
Por ese período mínimo de facturación de 1 minuto, es posible que los usuarios reciban cobros duplicados si el auto-suspend está en 30s. Aquí va un ejemplo:
- Llega una consulta y corre durante 1s
- El warehouse se apaga tras 30s
- Llega otra consulta justo después y reactiva el warehouse, corre 1s
- El warehouse vuelve a apagarse tras 30s
A pesar de haber estado activo apenas ~1 minuto, en este escenario al usuario se le cobrarán 2 minutos de compute, ya que el warehouse se reanudó dos veces y se cobra un mínimo de 1 minuto por cada reanudación.
2\. Reduce el tamaño del virtual warehouse
Los recursos de cómputo y el costo del virtual warehouse escalan de forma exponencial. Aquí va un recordatorio rápido, con los costos de compute por hora expresados en créditos (dólares), asumiendo un precio típico de $2.5 por crédito.
| Tamaño del Warehouse | Precio por hora del virtual warehouse |
|---|---|
| X-Small | 1 ($2.50) |
| Small | 2 ($5) |
| Medium | 4 ($10) |
| Large | 8 ($20) |
| X-Large | 16 ($40) |
| 2X-Large | 32 ($80) |
| 3X-Large | 64 ($160) |
| 4X-Large | 128 ($320) |
| 5X-Large | 256 ($640) |
| 6X-Large | 512 ($1280) |
Aquí va el precio mensual de cada warehouse asumiendo ejecución continua (no es la forma habitual de operarlos debido al auto-suspend, pero da una mejor idea del costo que la cifra por hora):
| Tamaño del Warehouse | Precio por hora del virtual warehouse |
|---|---|
| X-Small | 720 ($1,800) |
| Small | 1,440 ($3,600) |
| Medium | 2,880 ($7,200) |
| Large | 5,760 ($14,400) |
| X-Large | 11,520 ($28,800) |
| 2X-Large | 23,040 ($57,600) |
| 3X-Large | 46,080 ($115,200) |
| 4X-Large | 92,160 ($230,400) |
| 5X-Large | 184,320 ($460,800) |
| 6X-Large | 368,640 ($921,600) |
Los warehouses sobredimensionados a veces concentran la mayor parte del uso de Snowflake. Reduce el tamaño de los warehouses y observa el impacto en los workloads. Si el rendimiento sigue siendo aceptable, vuelve a reducirlo. Revisa nuestra guía completa para elegir el tamaño correcto de warehouse en Snowflake, que incluye heurísticas prácticas para detectar warehouses sobredimensionados.
Ejemplo de reducción del tamaño del warehouse:
Como ejemplo práctico rápido, piensa en un job de carga de datos que carga diez archivos por hora en un warehouse de tamaño Small. Un warehouse Small tiene 2 nodos y un total de 16 cores disponibles para procesamiento. Este job puede, como mucho, saturar 10 de los 16 cores (1 archivo por core), por lo que el warehouse no se aprovecha al 100%. Resultaría mucho más costo-eficiente correr este job en un warehouse X-Small.
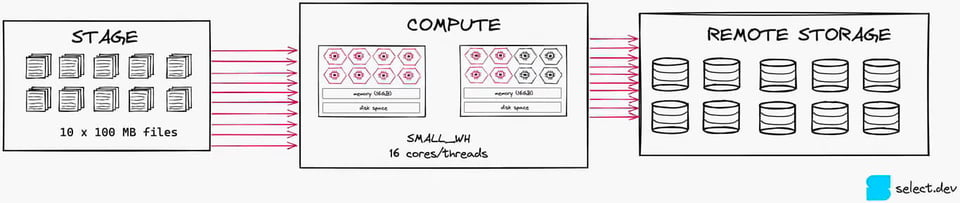
3\. Asegúrate de que los clusters mínimos estén en 1
Las ediciones Snowflake Enterprise o superiores ofrecen warehouses multi-cluster, lo que permite sumar clusters adicionales en paralelo para manejar mayor demanda. El conteo mínimo de clusters siempre debe estar en 1 para evitar el sobreaprovisionamiento. Snowflake agregará clusters automáticamente, hasta el conteo máximo y con un tiempo mínimo de aprovisionamiento, según se necesite. Un conteo mínimo de clusters superior a 1 deja clusters ociosos y facturables.
1alter warehouse compute_wh set min_cluster_count=1;
4\. Consolida warehouses
Un problema grande que vemos en muchos clientes de Snowflake es la proliferación de warehouses. Cuando hay demasiados, muchos no se saturan con consultas y quedan ociosos, lo que genera consumo innecesario de créditos.
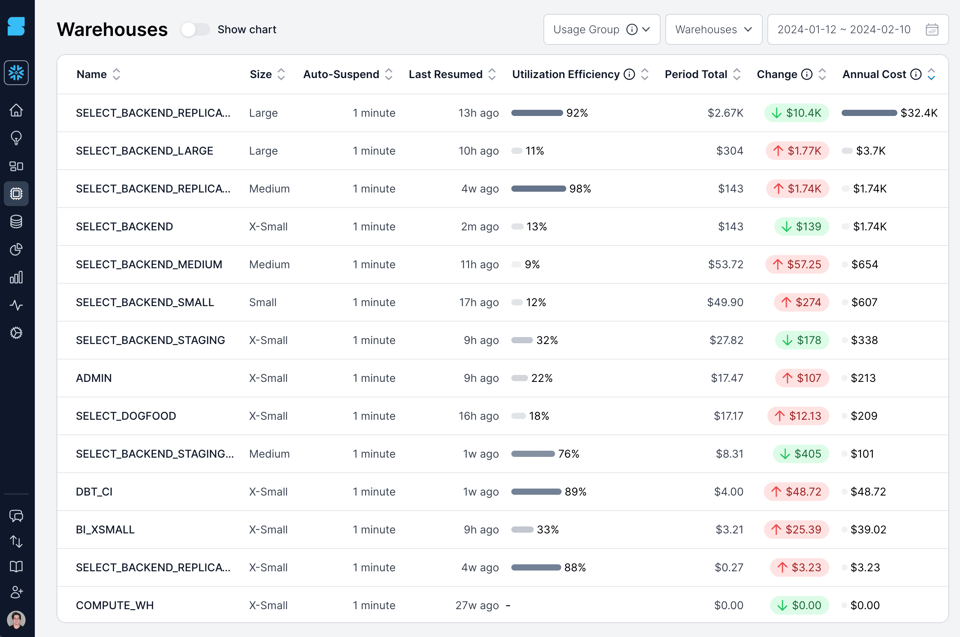
Aquí va un ejemplo de los warehouses de nuestra propia cuenta de Snowflake, visualizados en el producto SELECT. Calculamos y mostramos una métrica personalizada llamada eficiencia de utilización del warehouse, que mide el % del tiempo en que el warehouse está activo y procesando consultas. Si miras el warehouse SELECT_BACKEND_LARGE en la segunda fila, verás una eficiencia de utilización baja del 11%, lo que significa que el 89% del tiempo por el que estamos pagando, está ocioso sin procesar ninguna consulta. También hay varios otros warehouses con baja eficiencia.
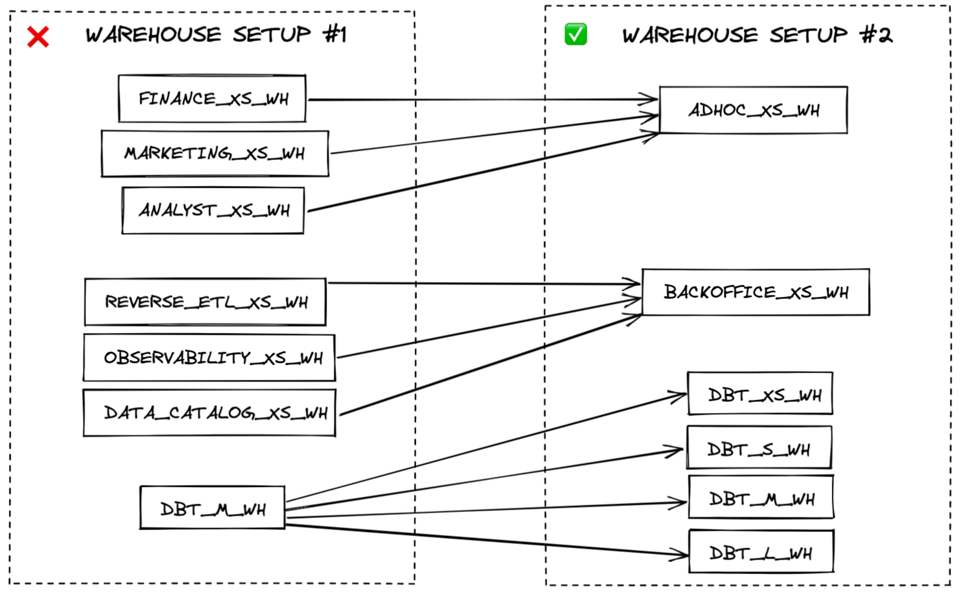
La mejor forma de asegurar que los virtual warehouses se aprovechen al máximo es usar la menor cantidad posible. Cuando haga falta, crea warehouses separados según los requisitos de rendimiento, no por dominio del workload.
Por ejemplo, crear un warehouse para toda la carga de datos, otro para transformaciones y otro para consultas BI en vivo dará mejor eficiencia de costos que tener un warehouse para datos de marketing y otro para datos de finanzas. Todos los workloads de carga de datos suelen tener los mismos requisitos de rendimiento (toleran cierto encolamiento) y muchas veces pueden compartir un warehouse multi-cluster X-Small. En cambio, las consultas en vivo orientadas al usuario pueden beneficiarse de un warehouse más grande para reducir la latencia.
Cuando los workloads dentro de cada categoría (carga, transformación, consultas en vivo, etc.) necesiten un tamaño de warehouse mayor para alcanzar tiempos de respuesta aceptables, crea un warehouse más grande solo para esos casos. Para máxima eficiencia de costos, las consultas siempre deberían correr en el warehouse más pequeño en el que se ejecutan con la rapidez suficiente.
5\. Reduce la frecuencia de las consultas
En muchas organizaciones, los jobs de transformación de datos en batch corren cada hora por defecto. Pero ¿los casos de uso downstream realmente necesitan una latencia tan baja? Aquí van algunos ejemplos de cómo bajar la frecuencia de ejecución impacta de inmediato en los costos. En el ejemplo asumimos que todos los workloads son no incrementales, por lo que hacen un refresh completo de datos en cada ejecución, y que el costo inicial de correr cada hora era de $100,000.
| Frecuencia de ejecución | Costo Anual | Ahorro |
|---|---|---|
| Cada hora | $100,000 | $0 |
| Cada hora entre semana, diario los fines de semana | $75,000 | $75,000 |
| Cada hora en horario laboral | $50,000 | $50,000 |
| Una vez al inicio de la jornada y otra al mediodía | $8,000 | $92,000 |
| Diario | $4,000 | $96,000 |
6\. Procesa solo datos nuevos o actualizados
Una buena parte de los datos suele ser inmutable, es decir, no cambia una vez creada. Algunos ejemplos: eventos web y eventos de envío. Otros sí cambian, pero rara vez más allá de cierto intervalo de tiempo, como las órdenes, que difícilmente se modifican pasado un mes desde la compra.
En lugar de reprocesar todos los datos en cada job de transformación en batch, se puede aplicar incrementalización para filtrar únicamente los registros que son nuevos o que se actualizaron dentro de una ventana de tiempo determinada, ejecutar las transformaciones y luego insertar o actualizar esos datos en la tabla final.
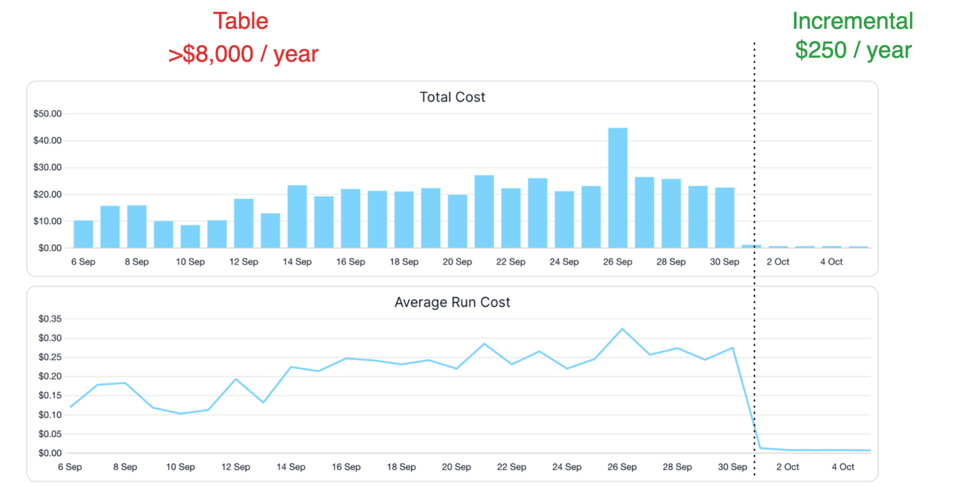
Para una tabla de eventos con un año de antigüedad, el impacto de pasar a transformaciones incrementales de solo inserción para registros nuevos podría reducir los costos en un 99%. Para una tabla de órdenes con un año de antigüedad, reprocesar y actualizar solo las órdenes del último mes y las nuevas podría reducir los costos en un 90% frente a refreshes completos.
Aquí va un ejemplo de la reducción de costos que conseguimos al convertir uno de nuestros modelos de datos para que procesara solo datos nuevos:
7\. Asegúrate de que las tablas estén correctamente clusterizadas
Una de las técnicas de optimización de consultas más importantes es el query pruning: una técnica para reducir el número de micro-particiones que se escanean al ejecutar una consulta. Leer micro-particiones es uno de los pasos más costosos de una consulta, ya que implica leer datos de forma remota a través de la red. Si se aplica un filtro en una cláusula where, un join o una subquery, Snowflake intentará descartar cualquier micro-partición que sepa que no contiene datos relevantes. Para que esto funcione, las micro-particiones deben contener un rango acotado de valores para la columna por la que estás filtrando.
Para que el query pruning sea posible, la tabla en Snowflake debe estar clusterizada correctamente según los patrones de acceso de las consultas. Considera una tabla orders en la que los usuarios filtran con frecuencia por órdenes creadas después de (created_at) una fecha determinada. Una tabla así debería estar clusterizada por created_at.

Cuando un usuario ejecuta la siguiente consulta contra la tabla orders, el query pruning permite descartar la mayoría de las micro-particiones del escaneo, lo que reduce enormemente el tiempo de ejecución y, por lo tanto, el costo.
select *
from orders
where created_at > '2022/08/14'
8\. Elimina tablas sin uso
Aunque suelen representar solo una porción menor (<20%) del costo total de Snowflake, las tablas sin uso y los respaldos de time-travel pueden ir comiéndose tus créditos de Snowflake. Ya hemos escrito antes sobre cómo identificar tablas no utilizadas si tienes Snowflake Enterprise edition o superior. Si no, usa la vista TABLE_STORAGE_METRICS ordenando por TOTAL_BILLABLE_BYTES para encontrar las tablas con los mayores costos de almacenamiento.
select
table_catalog as database_name,
table_schema as schema_name,
table_name,
(active_bytes + time_travel_bytes + failsafe_bytes + retained_for_clone_bytes) as total_billable_bytes
from snowflake.account_usage.table_storage_metrics
order by total_billable_bytes desc
limit 10
9\. Reduce la retención de datos
Como vimos en nuestro post sobre costos de almacenamiento en Snowflake, la configuración de time travel (retención de datos) puede generar costos adicionales, ya que debe mantener copias de todas las modificaciones y cambios hechos a una tabla durante el período de retención. Todo usuario de Snowflake debería preguntarse si realmente necesita acceder a una versión histórica de sus tablas. Y, si la necesita, cuántos días de historia debe conservar.
Para reducir el período de retención de datos de una tabla específica, ejecuta la siguiente consulta:
1alter table table set data_retention_time_in_days=0;
Y para aplicar el cambio a nivel de toda la cuenta, ejecuta:
1alter account set data_retention_time_in_days=0;
10\. Usa tablas transient
El almacenamiento Fail safe es otra fuente de costos de almacenamiento que puede ir sumando, sobre todo en tablas con mucha rotación (ampliamos más abajo).
Si tus tablas se eliminan y se recrean con regularidad como parte de algún proceso ETL, o si tienes una copia separada de los datos disponible en almacenamiento en la nube, en la mayoría de los casos no hace falta respaldar esos datos. Al cambiar una tabla de permanente a transient, evitas gastar de más en respaldos de Fail Safe y Time Travel.
-- consulta de ejemplo para crear una tabla como transient
create or replace transient table orders as (
select *
from raw.orders
...
)
11\. Evita las operaciones DML frecuentes
Un anti-patrón muy conocido en Snowflake es tratarlo como una base de datos operacional y actualizar, insertar o eliminar con frecuencia un puñado de registros.
¿Por qué hay que evitarlo? Por dos razones:
- Las tablas de Snowflake se almacenan en micro-particiones inmutables, que Snowflake intenta mantener alrededor de 16MB comprimidos. Una sola micro-partición puede contener cientos de miles de registros. Cada vez que actualizas o eliminas un solo registro, Snowflake debe recrear la micro-partición completa. Es decir, actualizar un registro puede equivaler a actualizar cientos de miles. Los
insertstambién pueden verse afectados, debido a un proceso conocido como small file compaction, en el que Snowflake intenta combinar los nuevos registros con micro-particiones existentes en vez de crear una nueva con solo unos pocos registros. - Para las funciones de almacenamiento de time travel y fail safe, Snowflake debe conservar copias de todas las versiones de una tabla. Si las micro-particiones se recrean a menudo, la cantidad de almacenamiento aumentará de forma significativa. En tablas con alta rotación (actualizaciones frecuentes), el almacenamiento de time travel y fail safe puede llegar a superar al almacenamiento activo de la propia tabla. Puedes leer sobre el ciclo de vida de una tabla de Snowflake para más detalles sobre este tema.
12\. Asegúrate de que los archivos tengan un tamaño óptimo
Para una carga de datos costo-eficiente, una buena práctica es mantener tus archivos en un rango de 100-250MB. Para ilustrar el efecto, observa la imagen de abajo. Si solo tenemos un archivo de 1GB, únicamente saturaremos 1/16 threads en un warehouse Small dedicado a la carga.
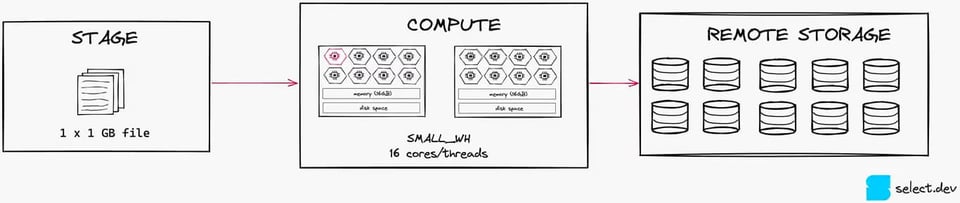
Si en cambio divides ese archivo en diez de 100 MB cada uno, usarás 10 de los 16 threads. Ese nivel de paralelización es mucho mejor, porque aprovecha más los recursos de compute disponibles (aunque vale la pena señalar que, en este escenario, un X-Small seguiría siendo la mejor opción).
Tener demasiados archivos pequeños también puede generar costos excesivos si usas Snowpipe para la carga de datos, ya que Snowflake cobra un overhead de 0.06 créditos por cada 1000 archivos cargados.
13\. Aprovecha el control de acceso
El control de acceso es una técnica poderosa para controlar costos en la que muchos clientes de Snowflake no piensan. Al restringir quién puede hacer cambios en los virtual warehouses, minimizas las posibilidades de que alguien modifique un recurso por accidente y termine generando costos inesperados. Hemos visto muchos casos en los que alguien aumenta el tamaño de un virtual warehouse y luego se olvida de volver a bajarlo. Con un control de acceso más estricto, las empresas pueden asegurarse de que las modificaciones de recursos pasen por un proceso controlado y reducir al mínimo los cambios no intencionados.
También puedes usar el control de acceso para limitar qué usuarios pueden correr consultas en determinados warehouses. Si solo dejas que los usuarios usen warehouses más pequeños, los obligas a escribir consultas más eficientes en lugar de tirar todo por defecto a un warehouse más grande. Cuando sea necesario, pueden existir políticas o procesos para permitir que ciertas consultas o usuarios corran en un warehouse más grande cuando sea estrictamente imprescindible.
14\. Habilita timeouts en las consultas
Los timeouts de consultas son una configuración que evita que las consultas de Snowflake corran durante demasiado tiempo y, en consecuencia, que cuesten demasiado. Si una consulta se extiende más allá del timeout configurado, Snowflake la cancela automáticamente.
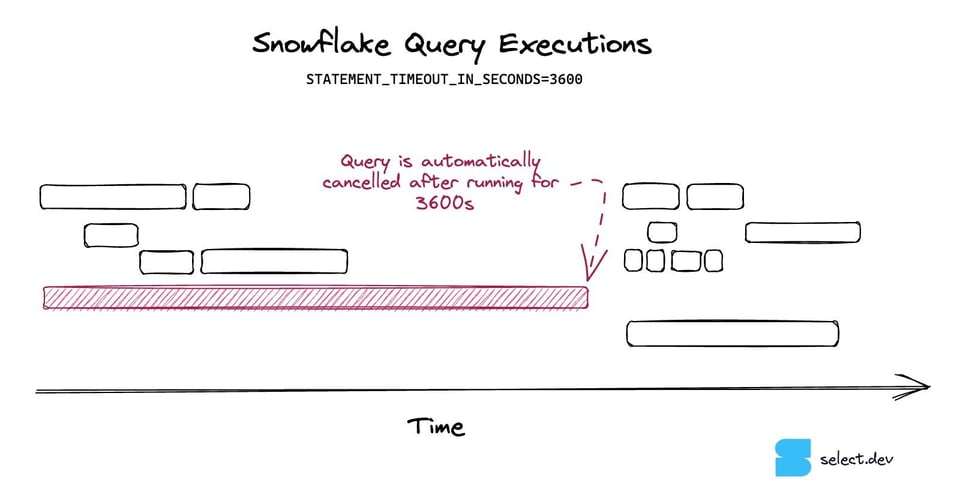
Los timeouts de consultas son una excelente forma de mitigar el impacto de consultas descontroladas. Por defecto, una consulta de Snowflake puede correr hasta dos días antes de cancelarse, acumulando costos enormes. Recomendamos poner timeouts en todos los warehouses para acotar el costo máximo que una sola consulta puede generar. Revisa nuestro post sobre el tema para más consejos sobre cómo configurarlos.
15\. Configura resource monitors
Al igual que los timeouts de consultas, los resource monitors te permiten limitar el costo total que un warehouse determinado puede generar. Los resource monitors sirven para dos propósitos:
- Enviarte una notificación cuando los costos alcanzan cierto umbral
- Evitar que un warehouse cueste más de cierto monto en un período de tiempo determinado. Snowflake puede impedir que se ejecuten consultas en un warehouse si superó su cuota.
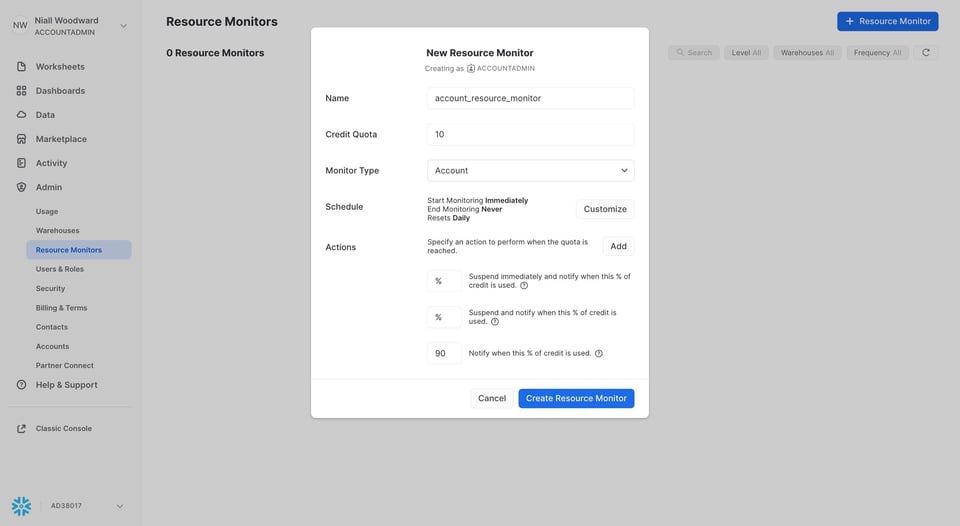
Los resource monitors son una excelente forma de evitar sorpresas en tu factura y de impedir que se generen costos innecesarios desde un comienzo.
Un último consejo
Hay una gran cita del mundo del FinOps que vale la pena compartir:
Los mayores ahorros en la nube vienen de costos que nunca se llegaron a generar
En este post compartimos un montón de formas de bajar tus costos de Snowflake para alcanzar tus metas de reducción o liberar presupuesto para nuevos workloads. Pero llegar al punto de necesitar estas técnicas significa que ya incurriste en esos costos y posiblemente operaste de forma subóptima durante un buen tiempo.
Una de las mejores formas de prevenir costos innecesarios es implementar una estrategia efectiva de monitoreo de costos desde el principio. Arma tu propio dashboard sobre las vistas de account usage de Snowflake y revísalo cada semana, o prueba un producto de monitoreo de costos creado a propósito, como SELECT. Al detectar a tiempo los problemas de gasto, evitas que se acumulen costos innecesarios desde el inicio.
The Missing Manual: Todo lo que necesitas saber sobre Snowflake Cost Optimization (Abril 2023)
Si buscas una presentación que cubra muchos de los temas tratados en el post, te recomendamos ver la charla que dimos en Data Council en abril de 2023.
En esta charla cubrimos todo lo que necesitas saber sobre optimización de costos y rendimiento en Snowflake. Empezamos con un análisis a fondo de la arquitectura y el modelo de facturación de Snowflake, repasando conceptos clave como los virtual warehouses, las micro-particiones, el ciclo de vida de una consulta y la caché de dos niveles de Snowflake. Profundizamos en las estrategias de optimización más importantes, como la configuración de virtual warehouses, el clustering de tablas y las mejores prácticas para escribir consultas. A lo largo de la charla compartimos fragmentos de código y otros recursos que puedes aprovechar para sacarle el máximo provecho a Snowflake.
Grabación
La grabación de la presentación está disponible en YouTube.
Reproducir
Si te interesa, con mucho gusto vamos y damos esta presentación (o una variación) a tu equipo, para que tengan la oportunidad de hacer preguntas. Envía un correo a [email protected] si quieres coordinarlo.
Diapositivas
[COPIA PÚBLICA] The Missing Manual - SELECT - Data Council - Google Slides
Cargando…
Esto podría tardar unos momentos
1
Cargando…
Algunas partes de esta diapositiva no se cargaron. Intenta recargar Recargar
Borrar todoShift+A
Algunas diapositivas no se cargaron. Actualizar
Abrir notas del oradorS
Activar el puntero láserL
Desactivar el puntero láserL
Activar el lápizShift+L
Desactivar el lápizShift+L
Pantalla completaCtrl+Shift+F
Salir de pantalla completaCtrl+Shift+F
Intercambiar pantallasD
Salir de la presentaciónEsc
Reproducción automática►
Preferencias de subtítulos
Más►
Preguntas y respuestasA
Descargar como PDF
Descargar como PPTX
ImprimirCtrl+P
Abrir en el editor
Atajos de tecladoCtrl+/
Reportar un problema
Reportar abuso
Ian Whitestone·Co-founder & CEO de SELECT
Ian es Co-founder y CEO de SELECT, una plataforma SaaS de gestión y optimización de costos para Snowflake. Antes de fundar SELECT, Ian pasó 6 años liderando equipos full stack de data science y engineering en Shopify y Capital One. En Shopify, Ian lideró los esfuerzos para optimizar su data warehouse y aumentar la observabilidad de costos.
Niall Woodward·Co-founder & CTO de SELECT
Niall es Co-Founder y CTO de SELECT, una plataforma SaaS de gestión y optimización de costos para Snowflake. Antes de fundar SELECT, Niall fue data engineer en Brooklyn Data Company y varias startups. Como entusiasta del open-source, también es maintainer de SQLFluff y creador de tres paquetes de dbt: dbt_artifacts, dbt_snowflake_monitoring y dbt_query_tags.