O Snowflake é uma plataforma extremamente poderosa, que escala com facilidade para dar conta de volumes de dados cada vez maiores sem perder performance. Mas, sem controle, os custos associados a esse crescimento disparam rapidamente. Seja para reduzir o preço de uma próxima renovação, esticar o saldo do contrato atual ou diminuir os custos on-demand, use as estratégias deste post para gerar economias significativas.
Tudo o que abordamos aqui se baseia em estratégias reais que o SELECT já ajudou mais de 100 clientes Snowflake a colocar em prática. Se você acha que ficou algo de fora, vamos adorar ouvir! Fale com a gente por e-mail ou use o chat no canto da tela.
Este post trata de técnicas de otimização de custos e como aplicá-las para eliminar o consumo desnecessário de créditos do Snowflake e liberar orçamento para outros workloads. Se o seu objetivo é fazer as queries do Snowflake rodarem mais rápido, confira nosso post sobre otimização de queries no Snowflake, com dicas práticas para acelerar a execução.
Antes de começar
Antes de qualquer coisa, é fundamental entender quais são, de fato, os principais geradores de custo do seu Snowflake e como funciona o modelo de precificação da plataforma. Vemos muitos clientes Snowflake partirem direto para otimizar queries específicas ou tentar reduzir custos de armazenamento, sem perceber que talvez nem seja ali o problema — nem o melhor ponto de partida.
Para começar, recomendamos olhar o panorama de gestão de custos do Snowflake na seção de admin da interface e entender quais serviços (compute, storage, serverless etc.) concentram a maior parte dos seus custos. Para a maioria dos clientes, compute é o grande vilão (normalmente mais de 80% do custo total do Snowflake). Identificado isso, o próximo passo é entender quais workloads dentro dos seus virtual warehouses respondem pela maior parte dos custos. Dá para descobrir isso calculando um custo por query e depois agregando esses custos a partir dos metadados (por exemplo, query tags ou comentários).
Técnicas de otimização de custos
As técnicas de redução de custos deste post se dividem em seis grandes categorias:
1. Configuração de virtual warehouse
- Reduzir o auto-suspend
- Reduzir o tamanho do warehouse
- Garantir que o mínimo de clusters esteja em 1
- Consolidar warehouses
2. Configuração de workload
- Reduzir a frequência das queries
- Processar apenas dados novos ou atualizados
3. Configuração de tabelas
- Garantir que as tabelas estejam clusterizadas corretamente
- Eliminar tabelas não utilizadas
- Reduzir a retenção de dados
- Usar tabelas transient
5. Padrões de carga de dados
- Evitar operações DML frequentes
- Garantir que os arquivos tenham um tamanho ideal antes da carga
6. Aproveitar os controles nativos do Snowflake
- Usar controle de acesso para restringir o uso e as alterações de warehouses
- Habilitar query timeouts
- Configurar resource monitors do Snowflake
Vamos direto ao ponto.
1\. Reduza o auto-suspend para 60 segundos
Use timeouts de auto-suspend de 60 segundos em todos os virtual warehouses. A única exceção é para workloads voltados ao usuário final, em que baixa latência é essencial e o cache do warehouse é muito utilizado. Na dúvida, comece com 60 segundos e aumente se a performance cair.
alter warehouse compute_wh set
auto_suspend=60;
O auto-suspend tem grande impacto na conta porque o Snowflake cobra por cada segundo em que um warehouse fica rodando, com um mínimo de 60 segundos. Por isso, não recomendamos configurar o auto-suspend abaixo de 60 segundos, já que isso pode gerar cobrança em duplicidade. Valores acima de 60 segundos fazem com que virtual warehouses continuem sendo cobrados mesmo sem processar nenhuma query. Por padrão, todos os virtual warehouses criados pela interface vêm com auto-suspend de 5 minutos, então fique atento ao criar novos warehouses.
Toda vez que um virtual warehouse do Snowflake é retomado, você paga por, no mínimo, 1 minuto. Depois disso, a cobrança passa a ser por segundo. Apesar de ser tecnicamente possível configurar o auto-suspend abaixo de 60s (dá até para colocar 0s, se quiser!), o Snowflake só desliga o warehouse após 30 segundos de inatividade.
Por causa desse mínimo de 1 minuto de cobrança, é possível ser cobrado em dobro se o auto-suspend estiver em 30s. Veja um exemplo:
- Uma query chega e roda por 1s
- O warehouse desliga após 30s
- Outra query chega logo em seguida, retoma o warehouse e roda por 1s
- O warehouse desliga de novo após 30s
Apesar de o warehouse ter ficado ativo por apenas ~1 minuto, o usuário será cobrado por 2 minutos de compute nesse cenário, já que o warehouse foi retomado duas vezes e cada retomada gera o mínimo de 1 minuto de cobrança.
2\. Reduza o tamanho do virtual warehouse
Os recursos computacionais e o custo dos virtual warehouses escalam de forma exponencial. Veja um lembrete rápido, com os custos de compute por hora em créditos (dólares), considerando uma taxa típica de US$ 2,50 por crédito.
| Tamanho do Warehouse | Preço por hora do virtual warehouse |
|---|---|
| X-Small | 1 (US$ 2,50) |
| Small | 2 (US$ 5) |
| Medium | 4 (US$ 10) |
| Large | 8 (US$ 20) |
| X-Large | 16 (US$ 40) |
| 2X-Large | 32 (US$ 80) |
| 3X-Large | 64 (US$ 160) |
| 4X-Large | 128 (US$ 320) |
| 5X-Large | 256 (US$ 640) |
| 6X-Large | 512 (US$ 1.280) |
E aqui está o preço mensal de cada warehouse rodando de forma contínua (embora normalmente os warehouses não funcionem assim por conta do auto-suspend, isso dá uma noção melhor de custo do que a tarifa horária):
| Tamanho do Warehouse | Preço por hora do virtual warehouse |
|---|---|
| X-Small | 720 (US$ 1.800) |
| Small | 1.440 (US$ 3.600) |
| Medium | 2.880 (US$ 7.200) |
| Large | 5.760 (US$ 14.400) |
| X-Large | 11.520 (US$ 28.800) |
| 2X-Large | 23.040 (US$ 57.600) |
| 3X-Large | 46.080 (US$ 115.200) |
| 4X-Large | 92.160 (US$ 230.400) |
| 5X-Large | 184.320 (US$ 460.800) |
| 6X-Large | 368.640 (US$ 921.600) |
Warehouses superdimensionados muitas vezes respondem pela maior parte do uso do Snowflake. Diminua o tamanho dos warehouses e observe o impacto nos workloads. Se a performance continuar aceitável, reduza mais um pouco. Confira nosso guia completo sobre como escolher o tamanho certo de warehouse no Snowflake, que traz heurísticas práticas para identificar warehouses superdimensionados.
Exemplo de redução do tamanho do warehouse:
Como exemplo prático rápido, imagine um job de carga de dados que carrega dez arquivos por hora em um warehouse Small. Um warehouse Small tem 2 nós e um total de 16 cores disponíveis para processamento. Esse job, no máximo, satura 10 dos 16 cores (1 arquivo por core), ou seja, o warehouse não chega nem perto de ser totalmente utilizado. Seria muito mais econômico rodar esse job em um warehouse X-Small.
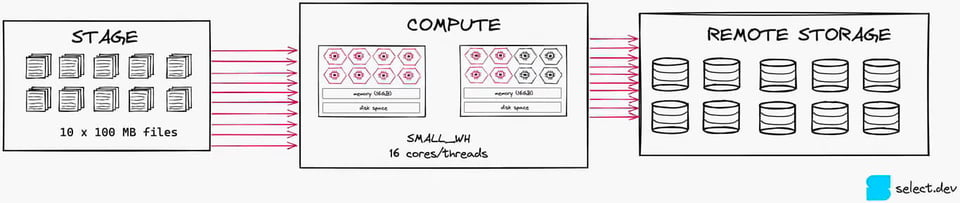
3\. Garanta que o mínimo de clusters esteja em 1
As edições Enterprise do Snowflake ou superiores oferecem warehouses multi-cluster, permitindo que os warehouses adicionem clusters em paralelo para atender a picos de demanda. A configuração de mínimo de clusters deve sempre ficar em 1 para evitar superprovisionamento. O Snowflake adiciona clusters automaticamente até o máximo configurado, com tempo mínimo de provisionamento, conforme a necessidade. Mínimos maiores que 1 deixam clusters ociosos — e cobrados.
1alter warehouse compute_wh set min_cluster_count=1;
4\. Consolide warehouses
Um problema grande que vemos em muitos clientes Snowflake é a proliferação de warehouses. Quando há warehouses demais, vários ficam sem queries suficientes para se manter saturados e acabam ociosos, gerando consumo desnecessário de créditos.
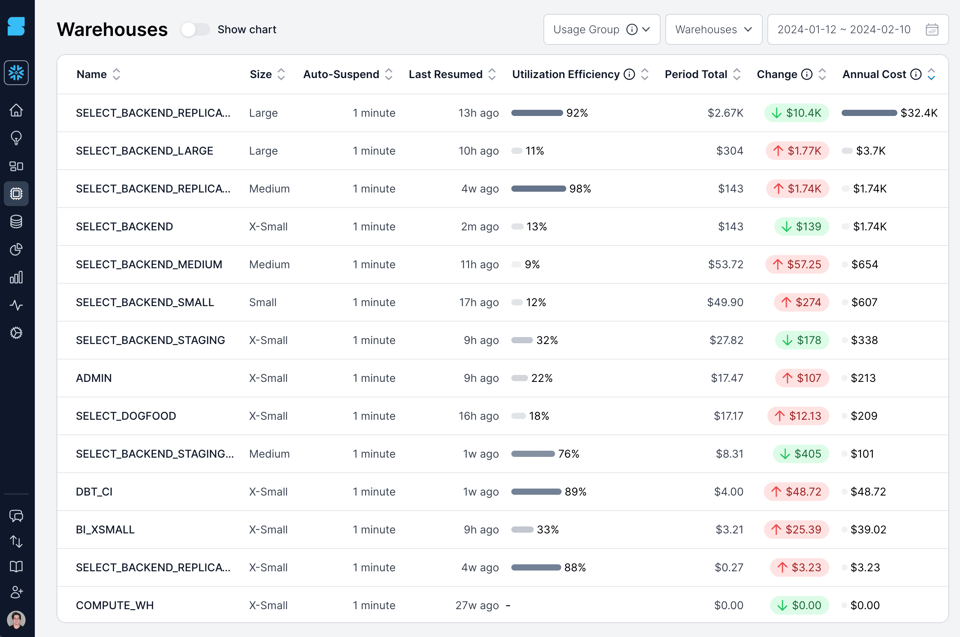
Veja um exemplo dos warehouses da nossa própria conta Snowflake, visualizados no produto SELECT. Nós calculamos e exibimos uma métrica customizada chamada eficiência de utilização do warehouse, que mede a % do tempo em que o warehouse está ativo e processando queries. Olhando o warehouse SELECT_BACKEND_LARGE na segunda linha, ele tem uma baixa eficiência de utilização, de 11%, ou seja, em 89% do tempo em que estamos pagando por ele, ele está ocioso, sem processar nenhuma query. E há vários outros com baixa eficiência também.
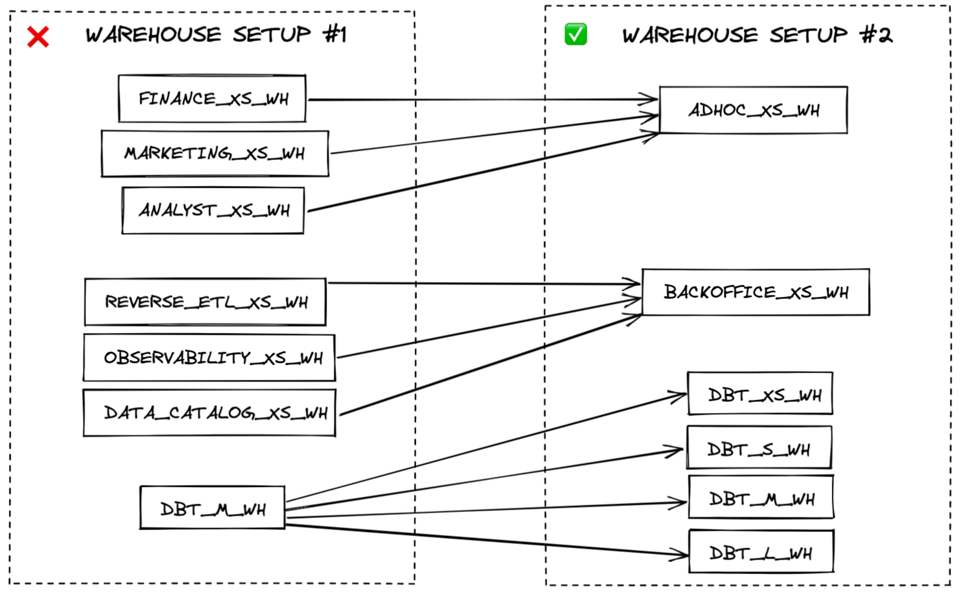
A melhor maneira de garantir o uso eficiente dos virtual warehouses é ter o menor número possível deles. Quando precisar, crie warehouses separados por requisito de performance — e não por domínio de workload.
Por exemplo: criar um warehouse para toda a carga de dados, outro para transformações e outro para queries de BI em tempo real gera mais eficiência de custo do que ter um warehouse para dados de marketing e outro para dados financeiros. Todos os workloads de carga de dados costumam ter os mesmos requisitos de performance (toleram algum enfileiramento) e podem, em muitos casos, compartilhar um warehouse X-Small multi-cluster. Já queries em tempo real, voltadas ao usuário final, podem se beneficiar de um warehouse maior para reduzir a latência.
Quando algum workload dentro de uma categoria (carga, transformação, query em tempo real etc.) precisar de um warehouse maior para atingir tempos de resposta aceitáveis, crie um novo warehouse maior exclusivo para ele. Para a melhor eficiência de custo, as queries devem sempre rodar no menor warehouse em que consigam performance suficiente.
5\. Reduza a frequência das queries
Em muitas empresas, jobs de transformação de dados em batch rodam de hora em hora por padrão. Mas será que os casos de uso downstream precisam mesmo de uma latência tão baixa? Veja alguns exemplos de como reduzir a frequência de execução pode impactar o custo imediatamente. Neste exemplo, assumimos que todos os workloads são não incrementais e fazem refresh completo a cada execução, e que o custo inicial rodando de hora em hora era de US$ 100.000.
| Frequência de execução | Custo anual | Economia |
|---|---|---|
| De hora em hora | US$ 100.000 | US$ 0 |
| De hora em hora nos dias úteis, diária nos fins de semana | US$ 75.000 | US$ 75.000 |
| De hora em hora no horário comercial | US$ 50.000 | US$ 50.000 |
| Uma vez no início do expediente, outra ao meio-dia | US$ 8.000 | US$ 92.000 |
| Diária | US$ 4.000 | US$ 96.000 |
6\. Processe apenas dados novos ou atualizados
Boa parte dos dados é imutável, ou seja, não muda depois de criada. É o caso, por exemplo, de eventos web e de envios. Outros mudam, mas raramente passado um certo intervalo de tempo — pedidos, por exemplo, dificilmente são alterados depois de um mês da compra.
Em vez de reprocessar todos os dados em cada job de transformação em batch, dá para usar a incrementalização para filtrar apenas os registros novos ou atualizados dentro de uma janela de tempo, aplicar as transformações e então inserir ou atualizar esses dados na tabela final.
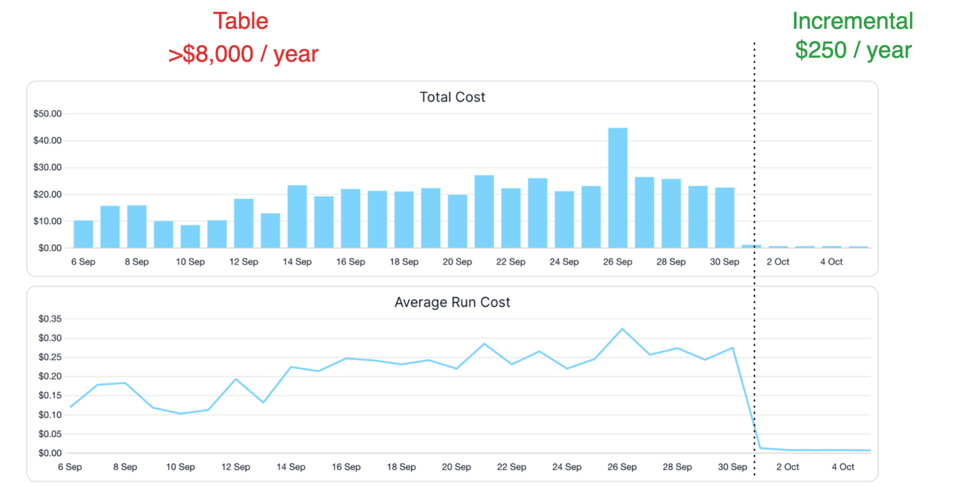
Para uma tabela de eventos com um ano de dados, mudar para transformações incrementais e apenas inserts para novos registros pode reduzir os custos em 99%. Para uma tabela de pedidos com um ano de dados, reprocessar e atualizar apenas os pedidos do último mês e os novos pode reduzir os custos em 90% em comparação com refreshes completos.
Veja um exemplo da redução de custo que obtivemos ao converter um dos nossos modelos de dados para processar apenas os dados novos:
7\. Garanta que as tabelas estejam clusterizadas corretamente
Uma das técnicas mais importantes de otimização de queries é o query pruning: uma técnica para reduzir o número de micro-partições lidas durante a execução de uma query. Ler micro-partições é uma das etapas mais caras de uma query, pois envolve ler dados remotamente pela rede. Quando há um filtro em uma cláusula where, em um join ou em uma subquery, o Snowflake tenta eliminar todas as micro-partições que ele sabe não conterem dados relevantes. Para que isso funcione, as micro-partições precisam conter um intervalo estreito de valores para a coluna usada no filtro.
Para que o query pruning seja possível, a tabela no Snowflake precisa estar clusterizada de acordo com os padrões de acesso das queries. Considere uma tabela orders, em que os usuários frequentemente filtram por pedidos criados depois (created_at) de certa data. Uma tabela assim deve ser clusterizada por created_at.

Quando um usuário roda a query abaixo na tabela orders, o query pruning elimina a maior parte das micro-partições da varredura, o que reduz drasticamente o tempo de execução e, consequentemente, o custo.
select *
from orders
where created_at > '2022/08/14'
8\. Elimine tabelas não utilizadas
Embora normalmente representem apenas uma pequena parcela (<20%) do custo total do Snowflake, tabelas não utilizadas e backups de time-travel podem corroer seus créditos. Já falamos antes sobre como identificar tabelas não utilizadas em quem está na edição Enterprise do Snowflake ou superior. Se esse não for o caso, use a view TABLE_STORAGE_METRICS e ordene por TOTAL_BILLABLE_BYTES para encontrar as tabelas com os maiores custos de armazenamento.
select
table_catalog as database_name,
table_schema as schema_name,
table_name,
(active_bytes + time_travel_bytes + failsafe_bytes + retained_for_clone_bytes) as total_billable_bytes
from snowflake.account_usage.table_storage_metrics
order by total_billable_bytes desc
limit 10
9\. Reduza a retenção de dados
Como discutimos no nosso post sobre custos de armazenamento do Snowflake, a configuração de time travel (retenção de dados) pode gerar custos adicionais, já que ela precisa manter cópias de todas as modificações feitas em uma tabela durante o período de retenção. Todo usuário do Snowflake deveria se perguntar se realmente precisa acessar uma versão histórica das suas tabelas. E, se precisar, por quantos dias.
Para reduzir o período de retenção de dados de uma tabela específica, rode a query abaixo:
1alter table table set data_retention_time_in_days=0;
Ou, para aplicar a mudança em toda a conta, rode:
1alter account set data_retention_time_in_days=0;
10\. Use tabelas transient
O armazenamento Fail safe é outra fonte de custos de armazenamento que pode pesar bastante, principalmente em tabelas com muito churn (mais sobre isso a seguir).
Se suas tabelas são deletadas e recriadas regularmente como parte de algum processo de ETL, ou se você tem uma cópia separada dos dados no cloud storage, na maior parte dos casos não há necessidade de manter backup desses dados. Ao mudar uma tabela de permanent para transient, você evita gastar à toa com backups de Fail Safe e Time Travel.
-- exemplo de query para criar uma tabela como transient
create or replace transient table orders as (
select *
from raw.orders
...
)
11\. Evite operações DML frequentes
Um anti-padrão clássico no Snowflake é tratá-lo como um banco de dados operacional, fazendo updates, inserts ou deletes frequentes em poucos registros.
Por que evitar isso? Por dois motivos:
- As tabelas do Snowflake são armazenadas em micro-partições imutáveis , que o Snowflake tenta manter em torno de 16MB comprimidos. Uma única micro-partição pode, portanto, conter centenas de milhares de registros. Toda vez que você atualiza ou deleta um único registro, o Snowflake precisa recriar a micro-partição inteira. Ou seja, atualizar um registro pode significar reescrever centenas de milhares de registros. Os
insertstambém podem ser afetados por isso, por causa de um processo chamado small file compaction, em que o Snowflake tenta combinar os novos registros com micro-partições existentes em vez de criar uma nova só com poucos registros. - Para os recursos de time travel e fail safe storage, o Snowflake precisa manter cópias de todas as versões da tabela. Se as micro-partições são recriadas com frequência, o volume de armazenamento aumenta bastante. Em tabelas com alto churn (updates frequentes), o time travel e o fail safe storage podem facilmente superar o storage ativo da própria tabela. Você pode ler mais sobre o ciclo de vida de uma tabela no Snowflake para mais detalhes sobre o assunto.
12\. Garanta que os arquivos tenham um tamanho ideal
Para garantir uma carga de dados econômica, uma boa prática é manter os arquivos entre 100 e 250MB. Para ilustrar isso, olhe a imagem abaixo. Se temos apenas um arquivo de 1GB, vamos saturar só 1 das 16 threads em um warehouse Small usado para carga.
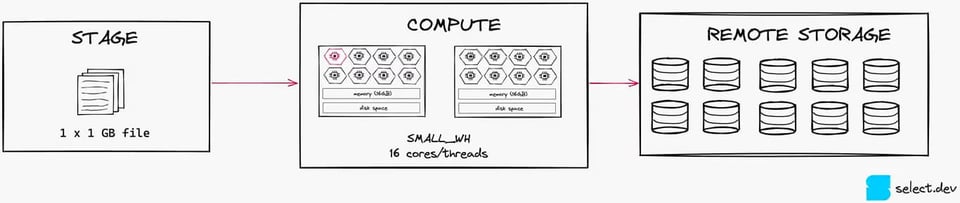
Se, em vez disso, dividirmos esse arquivo em dez arquivos de 100MB cada, vamos usar 10 das 16 threads. Esse nível de paralelização é muito melhor, pois aproveita mais os recursos computacionais disponíveis (mas vale lembrar que um X-Small ainda seria a melhor escolha nesse cenário).
Ter arquivos pequenos demais também pode gerar custos excessivos se você usar o Snowpipe para a carga, porque o Snowflake cobra uma taxa adicional de 0,06 créditos a cada 1.000 arquivos carregados.
13\. Use controle de acesso
O controle de acesso é uma técnica poderosa de controle de custos em que muitos clientes Snowflake nem pensam. Ao restringir quem pode alterar virtual warehouses, você diminui as chances de alguém modificar um recurso por engano e gerar custos inesperados. Já vimos vários casos em que alguém aumenta o tamanho de um virtual warehouse e esquece de voltar ao tamanho original. Com um controle de acesso mais rigoroso, as empresas garantem que mudanças em recursos passem por um processo controlado, reduzindo a chance de alterações indesejadas.
Você também pode usar o controle de acesso para limitar quais usuários podem rodar queries em determinados warehouses. Permitindo apenas warehouses menores para certos usuários, você os força a escrever queries mais eficientes em vez de simplesmente recorrer a um warehouse maior. Quando necessário, podem existir políticas ou processos para liberar determinadas queries/usuários em um warehouse maior, mas só quando for realmente indispensável.
14\. Habilite query timeouts
Os query timeouts são uma configuração que impede que queries do Snowflake rodem por tempo demais e, portanto, custem demais. Se uma query passar do tempo limite, o Snowflake a cancela automaticamente.
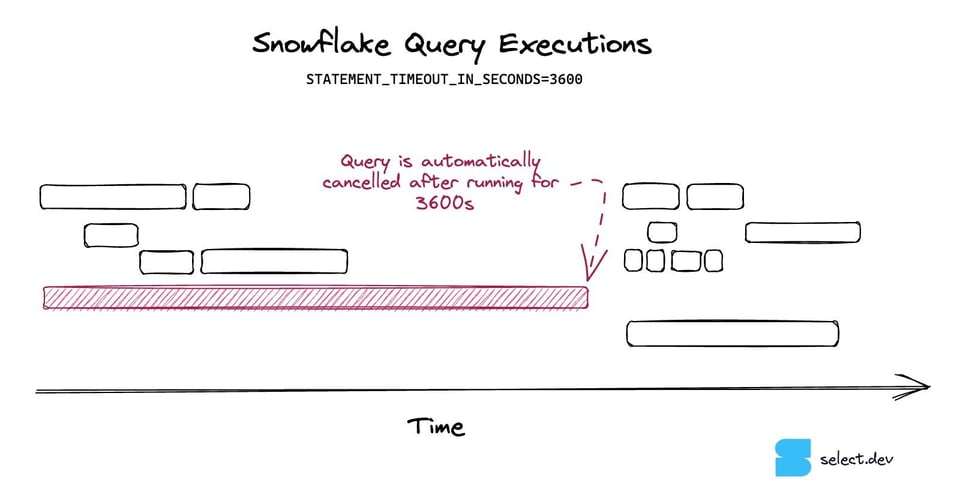
Os query timeouts são uma ótima maneira de mitigar o impacto de queries fora de controle. Por padrão, uma query do Snowflake pode rodar por dois dias antes de ser cancelada, acumulando custos enormes. Recomendamos configurar query timeouts em todos os warehouses para limitar o custo máximo que uma única query pode gerar. Veja nosso post sobre o tema para mais orientações sobre como definir esses valores.
15\. Configure resource monitors
Assim como os query timeouts, os resource monitors permitem restringir o custo total que um warehouse pode gerar. Dá para usar os resource monitors com duas finalidades:
- Receber uma notificação assim que os custos atingirem um determinado limite
- Impedir que um warehouse ultrapasse um valor de custo em um determinado período. O Snowflake pode bloquear a execução de queries em um warehouse se ele tiver passado da cota.
Os resource monitors são uma ótima forma de evitar surpresas na fatura e impedir que custos desnecessários aconteçam logo de saída.
Um último conselho
Existe uma ótima frase do mundo de FinOps que vale compartilhar:
As maiores economias na nuvem vêm dos custos que nunca chegaram a existir
Neste post, mostramos várias formas de reduzir seus custos com o Snowflake para atingir suas metas de redução ou liberar orçamento para novos workloads. Mas chegar ao ponto de precisar dessas técnicas significa que você já incorreu nesses custos e, possivelmente, operou de forma subótima por um bom tempo.
Uma das melhores formas de evitar custos desnecessários é colocar uma estratégia eficaz de monitoramento de custos em prática desde o começo. Crie seu próprio dashboard em cima das views de account usage do Snowflake e revise-o toda semana, ou experimente um produto especializado em monitoramento de custos como o SELECT. Identificando os problemas de gasto cedo, você evita que custos desnecessários se acumulem desde o início.
O Manual que Faltava: Tudo o que Você Precisa Saber sobre Otimização de Custos no Snowflake (abril de 2023)
Se você quer uma apresentação que cobre muitos dos tópicos discutidos neste post, recomendamos assistir à palestra que demos no Data Council em abril de 2023.
Nela, falamos sobre tudo o que você precisa saber a respeito de otimização de custos e performance no Snowflake. Começamos com um mergulho profundo na arquitetura e no modelo de cobrança do Snowflake, passando por conceitos-chave como virtual warehouses, micro-particionamento, o ciclo de vida de uma query e o cache de dois níveis do Snowflake. Nos aprofundamos nas estratégias de otimização mais importantes, como configuração de virtual warehouse, clustering de tabelas e boas práticas de escrita de queries. Ao longo da palestra, compartilhamos trechos de código e outros recursos que você pode usar para tirar o máximo do Snowflake.
Gravação
A gravação da apresentação está disponível no YouTube.
Play
Se quiser, ficamos felizes em ir até a sua empresa e apresentar esse conteúdo (ou uma variação dele) para o seu time, com espaço para perguntas. Mande um e-mail para [email protected] se quiser agendar.
Slides
[CÓPIA PÚBLICA] The Missing Manual - SELECT - Data Council - Google Slides
Carregando…
Isso pode levar alguns instantes
1
Carregando…
Algumas partes deste slide não carregaram. Tente recarregar Recarregar
Apagar tudoShift+A
Alguns slides não carregaram. Atualizar
Abrir notas do apresentadorS
Ativar o ponteiro laserL
Desativar o ponteiro laserL
Ativar a canetaShift+L
Desativar a canetaShift+L
Entrar em tela cheiaCtrl+Shift+F
Sair da tela cheiaCtrl+Shift+F
Trocar telasD
Sair da apresentaçãoEsc
Reprodução automática►
Preferências de legendas
Mais►
Perguntas e respostasA
Baixar como PDF
Baixar como PPTX
ImprimirCtrl+P
Abrir no editor
Atalhos de tecladoCtrl+/
Reportar um problema
Denunciar abuso
Ian Whitestone·Co-founder & CEO do SELECT
Ian é Co-founder e CEO do SELECT, uma plataforma SaaS de gestão e otimização de custos do Snowflake. Antes de fundar o SELECT, Ian passou 6 anos liderando times full stack de data science e engineering na Shopify e na Capital One. Na Shopify, ele liderou os esforços para otimizar o data warehouse e aumentar a observabilidade de custos.
Niall Woodward·Co-founder & CTO do SELECT
Niall é Co-Founder e CTO do SELECT, uma plataforma SaaS de gestão e otimização de custos do Snowflake. Antes de fundar o SELECT, Niall foi data engineer na Brooklyn Data Company e em várias startups. Entusiasta de open-source, ele também é mantenedor do SQLFluff e criador de três pacotes dbt: dbt_artifacts, dbt_snowflake_monitoring e dbt_query_tags.