Snowflakeは極めて強力なプラットフォームで、データ量が増え続けてもパフォーマンスを犠牲にせずスケールします。とはいえ、放置すればスケールに伴うコストはあっという間に膨らみます。次回の契約更新で価格を抑えたい、既存契約の予算をより長く使いたい、オンデマンドコストを下げたい——目的が何であれ、本記事の戦略を活用すれば大幅なコスト削減が見込めます。
ここで紹介する内容はすべて、SELECTが100社を超えるSnowflakeユーザーの支援を通じて積み上げてきた、現場発の実践に基づいています。「これも入れるべきでは?」というご意見があれば、ぜひお聞かせください。メールまたは画面下部のチャットからお気軽にどうぞ。
本記事のテーマはコスト最適化テクニックです。無駄なSnowflakeクレジット消費をなくし、他のworkloadsに予算を回す方法を解説します。クエリの高速化が目的の方は、実行時間を縮めるための実践的なコツをまとめたSnowflakeクエリ最適化の記事もあわせてご覧ください。
始める前に
取り組みを始める前に、まず自社のSnowflakeコストの実際の要因と料金モデルを理解しておくことが何より重要です。本当の問題箇所や最適な着手点を見極めないまま、特定クエリの最適化やストレージコスト削減に飛びついてしまうケースをよく目にします。
まずは管理画面のSnowflakeコスト管理概要を確認し、どのサービス(コンピュート、ストレージ、サーバーレスなど)がコストの大半を占めているかを把握しましょう。ほとんどのケースでは、コンピュートが最大の要因となります(通常はSnowflake全体コストの80%超)。それが見えたら、次は仮想ウェアハウス内のどのworkloadsがコストの大部分を生んでいるのかを突き止めることに集中します。具体的には、クエリあたりのコストを算出し、クエリのメタデータ(クエリタグやコメントなど)で集計すれば把握できます。
コスト最適化テクニック
本記事で紹介するコスト削減手法は、大きく6つのカテゴリに分かれます。
1. 仮想ウェアハウスの設定
- 自動サスペンドの短縮
- ウェアハウスサイズの縮小
- 最小クラスター数を1にする
- ウェアハウスの統合
2. Workloadsの設定
- クエリ実行頻度の削減
- 新規・更新データのみを処理
3. テーブルの設定
- テーブルを正しくクラスタリング
- 未使用テーブルの削除
- データ保持期間の短縮
- 一時テーブル(transient)の活用
5. データロードのパターン
- 頻繁なDML操作を避ける
- ロード前にファイルサイズを最適化
6. Snowflake標準の制御機能を活用
- アクセス制御でウェアハウスの利用・変更を制限
- クエリタイムアウトの有効化
- Snowflakeリソースモニターの設定
それでは順に見ていきましょう。
1\. 自動サスペンドを60秒に短縮する
すべての仮想ウェアハウスで、自動サスペンドのタイムアウトは60秒に設定しましょう。例外となるのは、低レイテンシが最優先で、かつウェアハウスキャッシュが頻繁に利用されるユーザー向けworkloadsだけです。迷ったらまず60秒に設定し、パフォーマンスに支障が出たら延ばす——これが基本です。
alter warehouse compute_wh set
auto_suspend=60;
自動サスペンドの設定は請求額に大きな影響を与えます。Snowflakeはウェアハウスが稼働している秒単位(最低60秒)で課金するためです。そのため、自動サスペンドを60秒未満に設定するのはおすすめしません。二重課金が発生する可能性があるからです。一方、60秒を超える設定にすると、クエリを処理していない時間も仮想ウェアハウスに課金が発生します。UIから作成した仮想ウェアハウスはデフォルトで自動サスペンドが5分に設定されているため、新規作成時には特に注意が必要です。
Snowflake仮想ウェアハウスは再開のたびに最低1分の課金が発生し、その後は秒単位で課金されます。技術的には自動サスペンド値を60秒未満(0秒も指定可能)に設定できますが、Snowflakeは無稼働状態が30秒経過してからシャットダウンする仕様です。
最低1分の課金が発生するため、自動サスペンドを30秒に設定すると二重課金が起こりうるのです。具体例を見てみましょう。
- クエリが届き、1秒で処理が完了
- ウェアハウスは30秒後にシャットダウン
- シャットダウン直後に別のクエリが届き、ウェアハウスが再開して1秒で処理完了
- ウェアハウスは再び30秒後にシャットダウン
実際の稼働時間は合計1分程度にもかかわらず、このケースではウェアハウスが2回再開しており、再開ごとに最低1分の課金が発生するため、ユーザーは2分間分のコンピュート料金を請求されることになります。
2\. 仮想ウェアハウスのサイズを縮小する
仮想ウェアハウスのコンピュートリソースとコストは指数関数的にスケールします。1クレジット2.5ドルという一般的なレートを前提に、時間あたりのコンピュートコストをクレジット(ドル)で示した表が次のとおりです。
| ウェアハウスサイズ | 時間あたりの仮想ウェアハウス料金 |
|---|---|
| X-Small | 1 ($2.50) |
| Small | 2 ($5) |
| Medium | 4 ($10) |
| Large | 8 ($20) |
| X-Large | 16 ($40) |
| 2X-Large | 32 ($80) |
| 3X-Large | 64 ($160) |
| 4X-Large | 128 ($320) |
| 5X-Large | 256 ($640) |
| 6X-Large | 512 ($1280) |
続いて、各ウェアハウスを連続稼働させた場合の月額料金です(自動サスペンドがあるため実際の運用形態とは異なりますが、時間単価よりも総コスト感をつかみやすくなります)。
| ウェアハウスサイズ | 時間あたりの仮想ウェアハウス料金 |
|---|---|
| X-Small | 720 ($1,800) |
| Small | 1,440 ($3,600) |
| Medium | 2,880 ($7,200) |
| Large | 5,760 ($14,400) |
| X-Large | 11,520 ($28,800) |
| 2X-Large | 23,040 ($57,600) |
| 3X-Large | 46,080 ($115,200) |
| 4X-Large | 92,160 ($230,400) |
| 5X-Large | 184,320 ($460,800) |
| 6X-Large | 368,640 ($921,600) |
過大サイズのウェアハウスがSnowflake利用料の大半を占めているケースは少なくありません。まずはサイズを下げ、workloadsへの影響を観察してみましょう。パフォーマンスに問題がなければ、さらに下げてみる。過大サイズのウェアハウスを見つけるための実践的なヒューリスティックは、Snowflakeで最適なウェアハウスサイズを選ぶ方法の完全ガイドにまとめています。
サイズ縮小の具体例:
たとえば、Smallサイズのウェアハウスで1時間ごとに10ファイルをロードするジョブを考えてみましょう。Smallサイズはノード2基、処理に使えるコアは合計16個です。このジョブが使い切れるのは最大でも16コア中10コア(1ファイルにつき1コア)にとどまり、ウェアハウスを十分に活用できません。X-Smallで実行するほうがコスト効率は格段に高くなります。
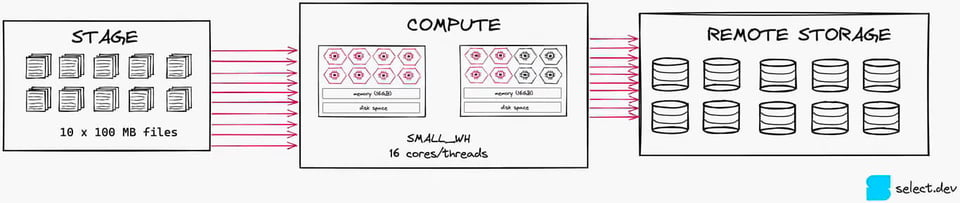
3\. 最小クラスター数を1に設定する
Snowflake Enterpriseエディション以上では、マルチクラスターウェアハウスが利用でき、需要に応じてクラスターを並列で追加できます。過剰プロビジョニングを避けるため、最小クラスター数は常に1に設定してください。Snowflakeは必要に応じて最小限のプロビジョニング時間でクラスターを最大クラスター数まで自動的に追加します。最小クラスター数を1より大きく設定すると、使われないままのクラスターにも課金が発生してしまいます。
1alter warehouse compute_wh set min_cluster_count=1;
4\. ウェアハウスを統合する
Snowflakeユーザーで頻繁に見られる大きな問題が、ウェアハウスの乱立です。数が増えすぎると、それぞれがクエリで埋まらずアイドル状態となり、無駄なクレジット消費を招きます。
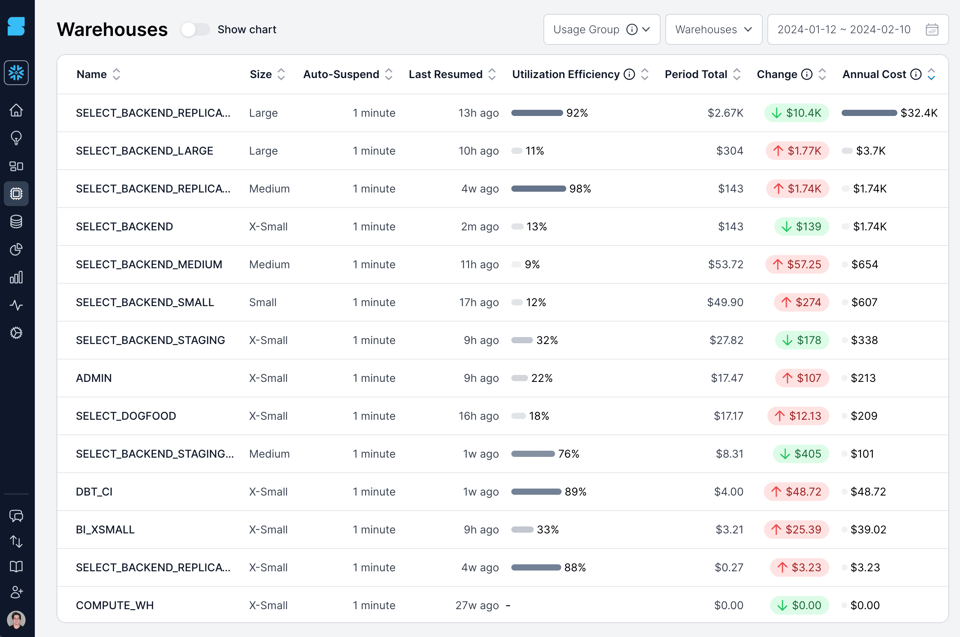
下の画像は、当社自身のSnowflakeアカウントのウェアハウスをSELECT製品で可視化したものです。私たちは「ウェアハウス稼働効率」という独自指標を算出して表示しています。これはウェアハウスが実際にクエリを処理している時間の割合を示すものです。2行目のSELECT_BACKEND_LARGEウェアハウスを見ると、稼働効率はわずか11%。つまり、料金を払っている時間のうち89%はアイドル状態でクエリを処理していないということです。同様に効率の低いウェアハウスが他にもいくつかあります。
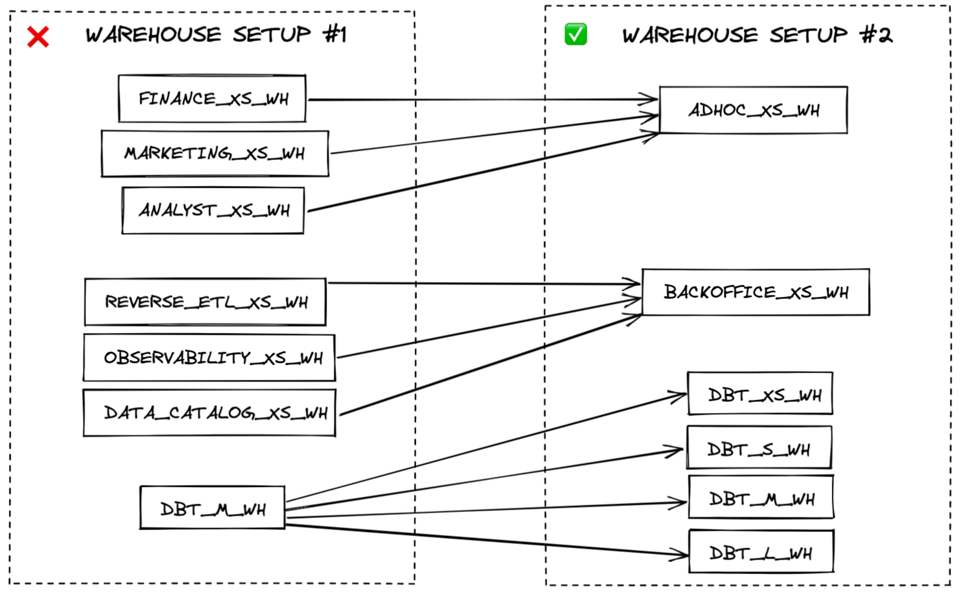
仮想ウェアハウスを効率よく使う一番の方法は、できる限り数を絞ることです。分ける必要がある場合も、workloadsの業務領域別ではなく、パフォーマンス要件別にウェアハウスを設けましょう。
たとえば、データロード用、変換用、リアルタイムBIクエリ用に1つずつ分ける方が、マーケティングデータ用と財務データ用に分けるよりもコスト効率は高くなります。データロード系のworkloadsはたいてい同じパフォーマンス要件(ある程度のキューイングを許容)を持ち、マルチクラスターのX-Smallウェアハウスを共有することが可能です。一方、ユーザー向けのリアルタイムクエリは、レイテンシを下げるために大きめのウェアハウスが有効な場合があります。
同じカテゴリ(ロード、変換、リアルタイムクエリなど)内でも、許容できる速度を出すためにより大きなサイズが必要なworkloadsがあれば、それ専用にもう1つ大きめのウェアハウスを用意しましょう。コスト効率の観点では、クエリは十分な速度で動く最小のウェアハウスで実行するのが理想です。
5\. クエリ実行頻度を減らす
多くの組織では、バッチデータ変換ジョブがデフォルトで1時間ごとに実行されています。しかし、下流のユースケースは本当にそれほど低いレイテンシを必要としているでしょうか。実行頻度を下げるだけでコストにすぐ効く例をいくつか紹介します。ここでは、すべてのworkloadsが非インクリメンタルで毎回フルリフレッシュを行い、毎時実行時の初期コストが10万ドルだったと仮定します。
| 実行頻度 | 年間コスト | 削減額 |
|---|---|---|
| 毎時 | $100,000 | $0 |
| 平日は毎時、週末は1日1回 | $75,000 | $75,000 |
| 営業時間中のみ毎時 | $50,000 | $50,000 |
| 始業時に1回、昼ごろに1回 | $8,000 | $92,000 |
| 1日1回 | $4,000 | $96,000 |
6\. 新規・更新データのみを処理する
大量のデータは多くの場合イミュータブルで、作成後に変更されることはありません。Webイベントや配送イベントなどが典型例です。変化するデータもありますが、一定期間を過ぎるとほぼ変わらなくなります。たとえば、購入から1か月以上経った注文が変更されることはまずありません。
バッチデータ変換ジョブのたびに全データを再処理するのではなく、インクリメンタル処理によって特定の時間範囲内で新規・更新されたレコードだけを抽出し、変換を行ったうえで最終テーブルに挿入または更新する方法が有効です。
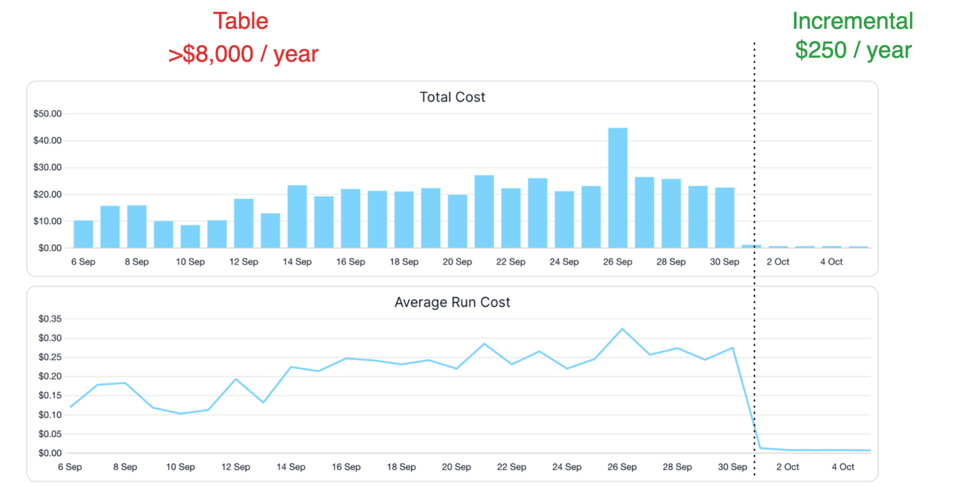
1年分のイベントテーブルなら、新規レコードのみを対象としたインクリメンタルかつインサート専用の変換に切り替えるだけで、コストを99%削減できる可能性があります。1年分の注文テーブルでも、直近1か月分と新規注文だけを再処理・更新する方式に切り替えれば、フルリフレッシュと比較して90%のコスト削減が見込めます。
当社のデータモデルのひとつを「新規データのみ処理する」方式に切り替えたときの、実際のコスト削減効果がこちらです。
7\. テーブルを正しくクラスタリングする
最も重要なクエリ最適化テクニックのひとつがクエリプルーニングです。これはクエリ実行時にスキャンするマイクロパーティションの数を減らす手法です。マイクロパーティションの読み取りはネットワーク越しのリモートアクセスを伴うため、クエリ処理の中でも特にコストの高い工程のひとつです。WHERE句、JOIN、サブクエリでフィルターが指定されると、Snowflakeは関連データを含まないと判断したマイクロパーティションをスキャン対象から除外しようとします。これが機能するには、フィルターをかける列の値の範囲が、マイクロパーティション内で十分に狭くまとまっている必要があります。
クエリプルーニングを効かせるには、クエリのアクセスパターンに合わせてSnowflake上のテーブルを適切にクラスタリングしておく必要があります。たとえば、ユーザーが特定の日付以降に作成された(created_at)注文を頻繁にフィルターするordersテーブルを考えてみましょう。このようなテーブルはcreated_atでクラスタリングしておくべきです。

下記のクエリをordersテーブルに対して実行すると、クエリプルーニングが大半のマイクロパーティションをスキャン対象から除外できるため、実行時間が大幅に短縮され、結果としてコストも下がります。
select *
from orders
where created_at > '2022/08/14'
8\. 未使用のテーブルを削除する
未使用テーブルやタイムトラベルのバックアップは、Snowflake全体コストでは通常小さな割合(20%未満)にとどまるものの、クレジットを着実に消費していきます。Snowflake Enterpriseエディション以上を利用している場合の未使用テーブルの特定方法は以前の記事で解説しました。それ以外の場合は、TABLE_STORAGE_METRICSビューをTOTAL_BILLABLE_BYTES順に並べ替え、ストレージコストの高いテーブルを見つけましょう。
select
table_catalog as database_name,
table_schema as schema_name,
table_name,
(active_bytes + time_travel_bytes + failsafe_bytes + retained_for_clone_bytes) as total_billable_bytes
from snowflake.account_usage.table_storage_metrics
order by total_billable_bytes desc
limit 10
9\. データ保持期間を短くする
Snowflakeストレージコストの記事で解説したように、タイムトラベル(データ保持)の設定は、保持期間中のテーブルへのあらゆる変更のコピーを保持するため、追加コストの要因になります。Snowflakeユーザーはまず、テーブルの過去バージョンへアクセスする必要が本当にあるのか、そして必要だとしても何日分の履歴を保持すべきかを問い直すべきです。
特定テーブルのデータ保持期間を短縮するには、下記のクエリを実行します。
1alter table table set data_retention_time_in_days=0;
アカウント全体に変更を適用するには、次のクエリを実行します。
1alter account set data_retention_time_in_days=0;
10\. 一時テーブル(transient)を活用する
フェールセーフストレージも、特に更新頻度の高いテーブルでは積み重なりがちなストレージコストの源です(詳しくは後述)。
ETLプロセスの一環として定期的に削除・再作成されるテーブルや、クラウドストレージにデータの別コピーがあるテーブルであれば、ほとんどの場合バックアップは不要です。テーブルを通常(permanent)から一時(transient)に変更することで、フェールセーフやタイムトラベルのバックアップに対する不要な支出を回避できます。
-- example query to create a table as transient
create or replace transient table orders as (
select *
from raw.orders
...
)
11\. 頻繁なDML操作を避ける
Snowflakeでよく知られているアンチパターンが、オペレーショナルデータベースのように扱い、少数のレコードを頻繁に更新・挿入・削除することです。
これを避けるべき理由は2つあります。
- Snowflakeのテーブルはイミュータブルなマイクロパーティションに格納されており、Snowflakeは圧縮後で約16MBに保つことを目指します。そのため、1つのマイクロパーティションには数十万件のレコードが含まれる可能性があります。レコードを1件更新または削除するたびに、Snowflakeはマイクロパーティション全体を再作成します。つまり、1件のレコード更新が実質的に数十万件分の更新になることもあるのです。
insertsもスモールファイルコンパクションと呼ばれる仕組みの影響を受けます。これはSnowflakeが少数のレコードだけで新しいマイクロパーティションを作る代わりに、既存のマイクロパーティションへ新規レコードを統合しようとする処理です。 - タイムトラベルとフェールセーフのストレージ機能のため、Snowflakeはテーブルの全バージョンのコピーを保持する必要があります。マイクロパーティションが頻繁に再作成されると、ストレージ量は大きく膨らみます。更新頻度の高い(チャーンの大きい)テーブルでは、タイムトラベルとフェールセーフのストレージがアクティブストレージ自体を上回ることもしばしばです。詳細はSnowflakeテーブルのライフサイクルの記事をご覧ください。
12\. ファイルサイズを最適化する
コスト効率の良いデータロードを実現するには、ファイルサイズを100〜250MB程度に保つのがベストプラクティスです。下の画像でその効果を確認しましょう。1GBのファイルが1つしかない場合、ロード用Smallウェアハウスでは16スレッド中1スレッドしか使えません。
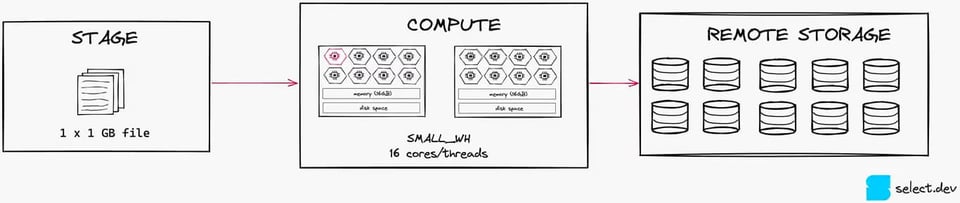
これを100MBずつ10個のファイルに分割すれば、16スレッド中10スレッドを使えます。この程度の並列化だけでもコンピュートリソースの活用度は大きく向上します(ただし、このケースであればX-Smallの方が依然として適切な選択肢である点に留意してください)。
小さなファイルが多すぎる場合も、データロードにSnowpipeを使っていると過剰なコストにつながります。Snowflakeはロードしたファイル1,000件ごとに0.06クレジットのオーバーヘッド料金を課すためです。
13\. アクセス制御を活用する
アクセス制御はコスト管理に効く強力な手段ですが、多くのSnowflakeユーザーは見落としがちです。仮想ウェアハウスを変更できるユーザーを絞ることで、誰かがうっかりリソースを変更し、想定外のコストが発生するリスクを最小化できます。実際、ウェアハウスサイズを大きくしたまま戻し忘れるケースは数えきれないほど見てきました。アクセス制御を厳格にすることで、リソース変更は管理されたプロセスを経るようになり、意図しない変更が起きる可能性を抑えられます。
また、特定のウェアハウスでクエリを実行できるユーザーを制限する目的にもアクセス制御は有効です。使えるウェアハウスを小さなサイズに限定することで、大きなサイズに頼らず効率的なクエリを書く習慣をユーザーに促せます。本当に必要な場合に備えて、特定のクエリやユーザーが大きなウェアハウスを利用できるようなポリシーやプロセスを整えておきましょう。
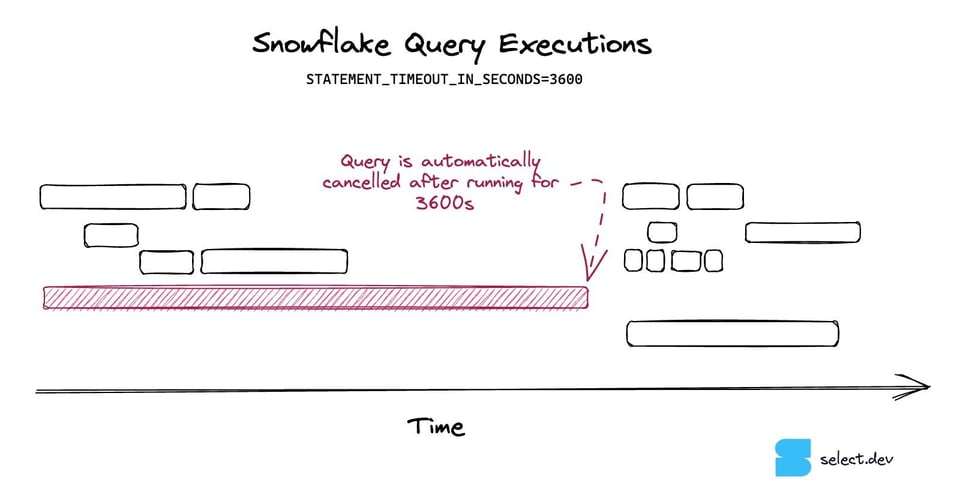
14\. クエリタイムアウトを有効にする
15\. リソースモニターを設定する
クエリタイムアウトと同様、リソースモニターを使えば、特定のウェアハウスが発生させる総コストを制限できます。リソースモニターには主に2つの用途があります。
- コストが特定のしきい値に達した時点で通知を送る
- 一定期間内にウェアハウスが発生させるコストの上限を設ける。クォータを超えた場合、Snowflakeは該当ウェアハウスでのクエリ実行を停止できます。
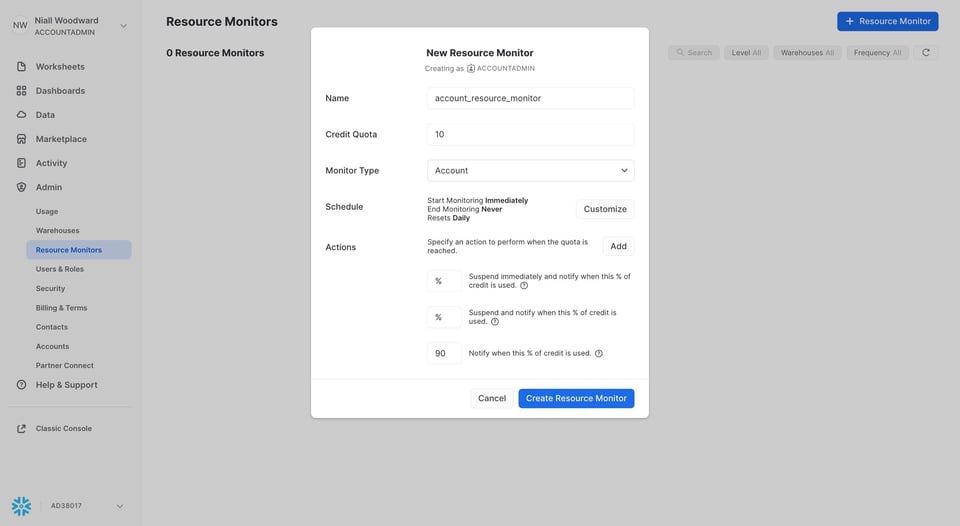
リソースモニターは、請求額のサプライズを防ぎ、不要なコストの発生そのものを未然に防ぐための優れた仕組みです。
最後に
FinOpsの世界で語られる、印象的な一節を紹介します。
最大のクラウド節約は、そもそも発生しなかったコストから生まれる
本記事では、コスト削減目標を達成したり、新たなworkloadsのために予算を空けたりするために、Snowflakeのコストを下げる多くの方法を紹介してきました。しかし、こうしたテクニックが必要になった段階というのは、すでにそれらのコストが発生し、長い間最適とは言えない運用が続いてきた可能性が高い、ということでもあります。
不要なコストを防ぐ最善策のひとつは、最初から効果的なコストモニタリング戦略を導入することです。Snowflakeのアカウント使用状況ビューの上に独自のダッシュボードを構築して毎週レビューするか、SELECTのような専用のコストモニタリング製品を試してみてください。支出の異常を早期に検知できれば、不要なコストの積み上がりをそもそも防げます。
The Missing Manual:Snowflakeコスト最適化のすべて(2023年4月)
本記事で扱ったトピックの多くをカバーするプレゼンテーションをお探しなら、2023年4月のData Councilで行った講演の視聴をおすすめします。
この講演では、Snowflakeにおけるコスト・パフォーマンス最適化について知っておくべき内容を一通り解説しています。まずSnowflakeのアーキテクチャと課金モデルを深掘りし、仮想ウェアハウス、マイクロパーティション、クエリのライフサイクル、Snowflakeの2層キャッシュといった重要な概念を取り上げます。続いて、仮想ウェアハウスの設定、テーブルクラスタリング、クエリ記述のベストプラクティスなど、特に重要な最適化戦略を詳しく紹介します。講演全体を通して、Snowflakeを最大限活用するためのコードスニペットや関連リソースも共有しています。
録画
講演の録画はYouTubeで公開中です。
再生
ご希望であれば、このプレゼンテーション(またはその派生版)を貴社チーム向けに直接お届けし、質疑応答の場を設けることも可能です。ご興味があれば[email protected]までメールでご連絡ください。
スライド
[PUBLIC COPY] The Missing Manual - SELECT - Data Council - Google Slides
読み込み中…
少々お待ちください
1
読み込み中…
このスライドの一部が読み込めませんでした。再読み込みをお試しください
すべて消去Shift+A
一部のスライドが読み込めませんでした。更新してください
スピーカーノートを開くS
レーザーポインターをオンにするL
レーザーポインターをオフにするL
ペンをオンにするShift+L
ペンをオフにするShift+L
全画面表示Ctrl+Shift+F
全画面表示を終了Ctrl+Shift+F
ディスプレイを切り替えるD
スライドショーを終了Esc
自動再生►
字幕設定
その他►
Q&AA
PDFとしてダウンロード
PPTXとしてダウンロード
印刷Ctrl+P
エディタで開く
キーボードショートカットCtrl+/
問題を報告
不正使用を報告
Ian Whitestone・SELECT共同創業者兼CEO
IanはSaaS型Snowflakeコスト管理・最適化プラットフォームSELECTの共同創業者兼CEO。SELECTを立ち上げる前は、ShopifyとCapital Oneでフルスタックのデータサイエンス・エンジニアリングチームを6年間にわたり率いてきました。Shopifyでは、データウェアハウスの最適化とコスト可視化を高める取り組みをリードしました。
Niall Woodward・SELECT共同創業者兼CTO
NiallはSaaS型Snowflakeコスト管理・最適化プラットフォームSELECTの共同創業者兼CTO。SELECTを立ち上げる前は、Brooklyn Data Companyや複数のスタートアップでデータエンジニアを務めました。オープンソースの愛好家でもあり、SQLFluffのメンテナー、またdbt_artifacts、dbt_snowflake_monitoring、dbt_query_tagsという3つのdbtパッケージの作者でもあります。