Snowflake est une plateforme d'une puissance remarquable, qui absorbe sans peine des volumes de données toujours plus importants sans rogner sur la performance. Mais sans garde-fous, les coûts liés à cette montée en charge grimpent vite. Que vous cherchiez à négocier un renouvellement à la baisse, à prolonger la durée de votre contrat actuel ou à diminuer vos coûts à la demande, appuyez-vous sur les stratégies de cet article pour réaliser des économies significatives.
Tout ce que nous abordons ici repose sur des approches concrètes que SELECT a aidé plus de 100 clients Snowflake à mettre en œuvre. Si vous pensez qu'un sujet manque à l'appel, dites-le-nous ! Écrivez-nous par e-mail ou utilisez la bulle de chat en bas de l'écran.
Cet article porte sur les techniques d'optimisation des coûts et la façon de les exploiter pour éliminer la consommation inutile de crédits Snowflake et libérer du budget pour d'autres workloads. Si votre objectif est plutôt d'accélérer l'exécution de vos requêtes Snowflake, consultez notre article sur l'optimisation des requêtes Snowflake, qui propose des conseils concrets pour réduire leur temps d'exécution.
Avant de commencer
Avant de vous lancer, il est essentiel de comprendre quels sont vos véritables postes de coûts Snowflake ainsi que le modèle tarifaire de la plateforme. Beaucoup de clients Snowflake se précipitent pour optimiser certaines requêtes ou tenter de réduire leurs coûts de stockage, sans réaliser que ce n'est peut-être ni le bon problème ni le bon point de départ.
Pour démarrer, nous recommandons de consulter la vue d'ensemble de la gestion des coûts Snowflake dans la section admin de l'interface, afin d'identifier quels services (compute, stockage, serverless, etc.) pèsent le plus dans la facture. Chez la plupart des clients, c'est le compute qui domine (généralement plus de 80 % des coûts Snowflake). Une fois ce constat posé, concentrez-vous sur les workloads qui, au sein de vos virtual warehouses, représentent l'essentiel de vos coûts. Vous pouvez l'établir en calculant un coût par requête, puis en agrégeant ces coûts à partir des métadonnées de requête (par exemple les query tags ou les commentaires).
Techniques d'optimisation des coûts
Les techniques de réduction de coûts présentées ici se répartissent en six grandes catégories :
1. Configuration des virtual warehouses
- Réduire l'auto-suspend
- Réduire la taille du warehouse
- Fixer le nombre minimum de clusters à 1
- Consolider les warehouses
2. Configuration des workloads
- Réduire la fréquence des requêtes
- Ne traiter que les données nouvelles ou mises à jour
3. Configuration des tables
- Vérifier que vos tables sont correctement clusterisées
- Supprimer les tables inutilisées
- Réduire la rétention des données
- Utiliser des tables transitoires
5. Schémas de chargement de données
- Éviter les opérations DML fréquentes
- Veiller à ce que vos fichiers aient une taille optimale avant le chargement
6. Tirer parti des contrôles natifs de Snowflake
- Restreindre l'usage et les modifications des warehouses via le contrôle d'accès
- Activer les query timeouts
- Configurer les resource monitors Snowflake
Entrons dans le vif du sujet.
1\. Ramener l'auto-suspend à 60 secondes
Appliquez un délai d'auto-suspend de 60 secondes à tous les virtual warehouses. La seule exception concerne les workloads exposés aux utilisateurs, où la faible latence prime et où le cache du warehouse est sollicité en permanence. Dans le doute, partez sur 60 secondes et augmentez si la performance en pâtit.
alter warehouse compute_wh set
auto_suspend=60;
Le réglage de l'auto-suspend pèse lourd sur la facture, car Snowflake facture chaque seconde où un warehouse tourne, avec un minimum de 60 secondes. C'est pourquoi nous déconseillons de descendre sous 60 secondes, au risque d'une double facturation. Au-delà de 60 secondes, le warehouse continue d'être facturé alors qu'il ne traite plus aucune requête. Par défaut, tous les virtual warehouses créés via l'interface ont un auto-suspend de 5 minutes : restez vigilant à la création de nouveaux warehouses.
À chaque redémarrage d'un virtual warehouse Snowflake, vous êtes facturé pour 1 minute au minimum. Au-delà, la facturation se fait à la seconde. Il est techniquement possible de fixer une valeur d'auto-suspend inférieure à 60 s (vous pouvez même mettre 0 s !), mais Snowflake n'arrêtera le warehouse qu'après 30 secondes d'inactivité.
En raison de la minute minimale facturée, un auto-suspend réglé sur 30 s peut entraîner une double facturation. Exemple :
- Une requête arrive et s'exécute en 1 s
- Le warehouse s'arrête au bout de 30 s
- Une autre requête arrive juste après l'arrêt, réveille le warehouse et s'exécute en 1 s
- Le warehouse s'arrête à nouveau après 30 s
Bien que le warehouse n'ait été actif qu'environ 1 minute, l'utilisateur sera en réalité facturé pour 2 minutes de compute dans ce scénario, car le warehouse a redémarré deux fois et chaque redémarrage entraîne une facturation minimale d'une minute.
2\. Réduire la taille des virtual warehouses
Les ressources de calcul et les coûts des virtual warehouses progressent de manière exponentielle. Petit rappel ci-dessous, avec les coûts de compute exprimés à l'heure en crédits (et en dollars), sur la base d'un tarif typique de 2,50 $ par crédit.
| Taille du warehouse | Tarif horaire du virtual warehouse |
|---|---|
| X-Small | 1 (2,50 $) |
| Small | 2 (5 $) |
| Medium | 4 (10 $) |
| Large | 8 (20 $) |
| X-Large | 16 (40 $) |
| 2X-Large | 32 (80 $) |
| 3X-Large | 64 (160 $) |
| 4X-Large | 128 (320 $) |
| 5X-Large | 256 (640 $) |
| 6X-Large | 512 (1 280 $) |
Voici le tarif mensuel pour chaque warehouse en supposant une exécution continue (ce n'est pas le mode de fonctionnement habituel à cause de l'auto-suspend, mais cela donne une meilleure idée du coût qu'une vision horaire) :
| Taille du warehouse | Tarif horaire du virtual warehouse |
|---|---|
| X-Small | 720 (1 800 $) |
| Small | 1 440 (3 600 $) |
| Medium | 2 880 (7 200 $) |
| Large | 5 760 (14 400 $) |
| X-Large | 11 520 (28 800 $) |
| 2X-Large | 23 040 (57 600 $) |
| 3X-Large | 46 080 (115 200 $) |
| 4X-Large | 92 160 (230 400 $) |
| 5X-Large | 184 320 (460 800 $) |
| 6X-Large | 368 640 (921 600 $) |
Des warehouses surdimensionnés peuvent à eux seuls représenter l'essentiel de la consommation Snowflake. Réduisez leur taille et observez l'impact sur vos workloads. Si la performance reste acceptable, réduisez encore. Consultez notre guide complet sur le choix de la bonne taille de warehouse dans Snowflake, qui propose des heuristiques pratiques pour repérer les warehouses surdimensionnés.
Exemple de réduction de la taille d'un warehouse :
Prenons un exemple concret : un job de chargement qui ingère dix fichiers toutes les heures sur un warehouse de taille Small. Un warehouse Small comporte 2 nœuds et 16 cœurs au total pour le traitement. Ce job peut au mieux saturer 10 cœurs sur 16 (1 fichier par cœur) : le warehouse ne sera donc pas pleinement utilisé. Il serait nettement plus rentable de l'exécuter sur un warehouse X-Small.
3\. Fixer le nombre minimum de clusters à 1
Les éditions Snowflake Enterprise et supérieures proposent le multi-cluster warehousing, qui permet à un warehouse d'ajouter des clusters supplémentaires en parallèle pour absorber les pics de demande. Le paramètre nombre minimum de clusters doit toujours être réglé à 1 pour éviter le surprovisionnement. Snowflake ajoute ensuite automatiquement des clusters, dans la limite du maximum défini et avec un temps de provisionnement minimal, selon les besoins. Un minimum supérieur à 1 entraîne des clusters inutilisés mais facturés.
1alter warehouse compute_wh set min_cluster_count=1;
4\. Consolider les warehouses
Un problème majeur que nous observons chez de nombreux clients Snowflake, c'est la prolifération des warehouses. Quand ils sont trop nombreux, beaucoup ne sont pas saturés par les requêtes et restent inactifs, ce qui se traduit par une consommation inutile de crédits.
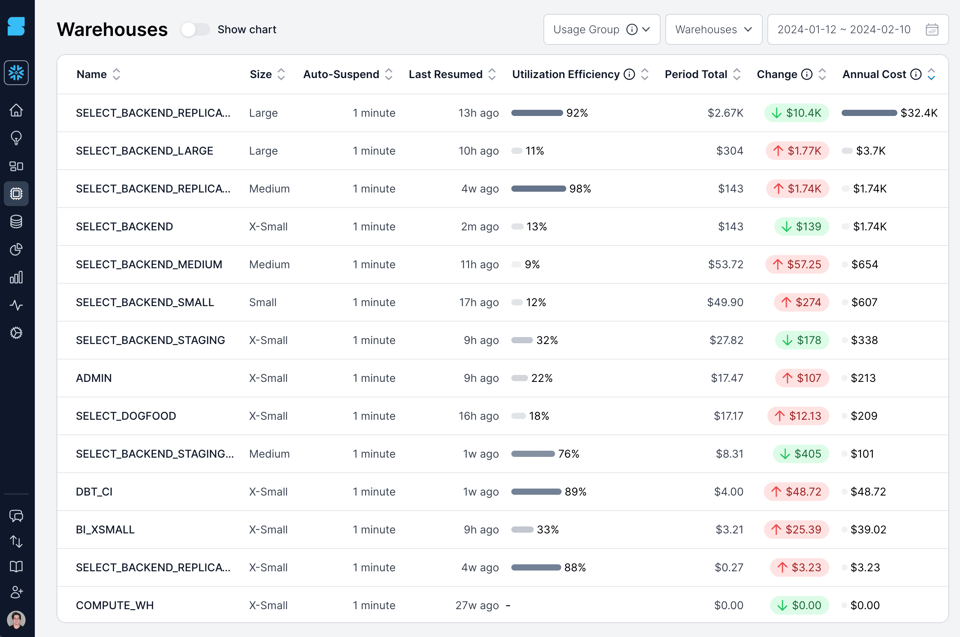
Voici un exemple tiré de notre propre compte Snowflake, visualisé dans le produit SELECT. Nous calculons et exposons une métrique maison, l'efficacité d'utilisation du warehouse, qui mesure le pourcentage de temps pendant lequel le warehouse est actif et traite des requêtes. Si l'on regarde le warehouse SELECT_BACKEND_LARGE sur la deuxième ligne, son efficacité n'est que de 11 % : 89 % du temps où nous le payons, il reste inactif sans traiter aucune requête. Plusieurs autres warehouses affichent eux aussi une faible efficacité.
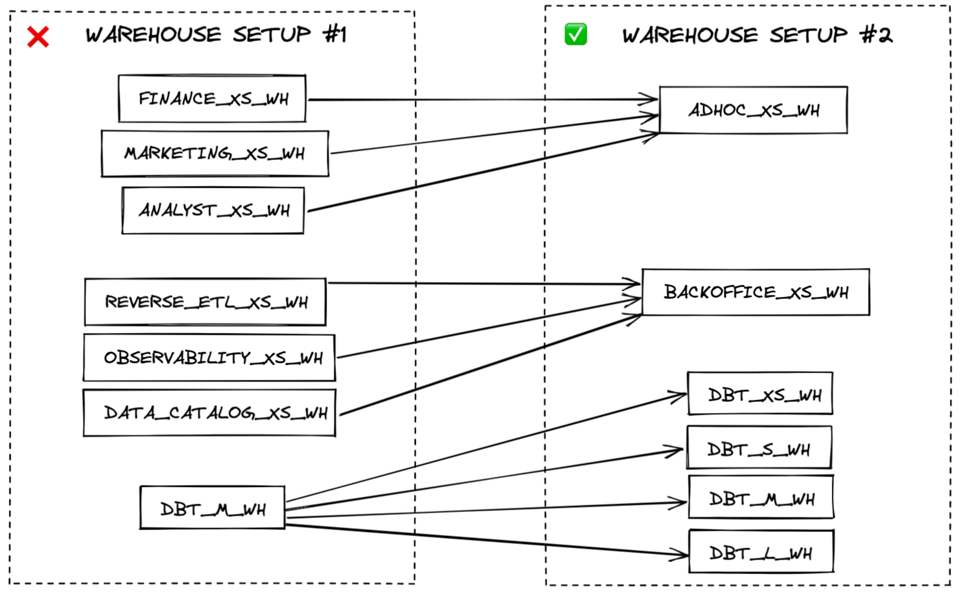
Le meilleur moyen de garantir une utilisation efficace des virtual warehouses est d'en avoir le moins possible. Au besoin, créez des warehouses distincts en fonction des exigences de performance plutôt que par domaine fonctionnel.
Par exemple, créer un warehouse pour l'ensemble du chargement de données, un autre pour les transformations et un troisième pour les requêtes BI en temps réel sera plus efficient qu'un warehouse pour les données marketing et un autre pour les données finance. Les workloads de chargement ont généralement les mêmes exigences de performance (ils tolèrent une certaine mise en file d'attente) et peuvent souvent partager un warehouse X-Small multi-cluster. À l'inverse, les requêtes en temps réel, exposées aux utilisateurs, gagneront à tourner sur un warehouse plus grand pour limiter la latence.
Lorsque, au sein d'une même catégorie (chargement, transformation, requêtes en temps réel, etc.), certains workloads nécessitent une taille de warehouse supérieure pour atteindre des vitesses acceptables, créez un nouveau warehouse plus grand dédié à ces seuls cas. Pour une efficience de coût optimale, les requêtes doivent toujours s'exécuter sur le plus petit warehouse capable de les traiter assez vite.
5\. Réduire la fréquence des requêtes
Dans de nombreuses organisations, les jobs de transformation de données en batch tournent par défaut toutes les heures. Mais les cas d'usage en aval ont-ils vraiment besoin d'une latence aussi faible ? Voici quelques exemples illustrant l'effet immédiat d'une baisse de fréquence sur les coûts. On suppose ici que tous les workloads sont non incrémentaux et effectuent donc un rafraîchissement complet à chaque exécution, et que le coût initial d'une exécution horaire était de 100 000 $.
| Fréquence d'exécution | Coût annuel | Économies |
|---|---|---|
| Toutes les heures | 100 000 $ | 0 $ |
| Toutes les heures en semaine, une fois par jour le week-end | 75 000 $ | 75 000 $ |
| Toutes les heures pendant les heures ouvrées | 50 000 $ | 50 000 $ |
| Une fois en début de journée, une fois vers midi | 8 000 $ | 92 000 $ |
| Quotidiennement | 4 000 $ | 96 000 $ |
6\. Ne traiter que les données nouvelles ou mises à jour
De gros volumes de données sont souvent immuables : ils ne changent plus une fois créés. C'est le cas des événements web ou des événements d'expédition, par exemple. D'autres évoluent, mais rarement au-delà d'un certain délai — comme les commandes, qui ne sont quasiment plus modifiées passé un mois après l'achat.
Plutôt que de retraiter l'intégralité des données à chaque job de transformation en batch, l'incrémentalisation permet de ne filtrer que les enregistrements nouveaux ou mis à jour sur une fenêtre temporelle donnée, d'appliquer les transformations, puis d'insérer ou de mettre à jour ces données dans la table finale.
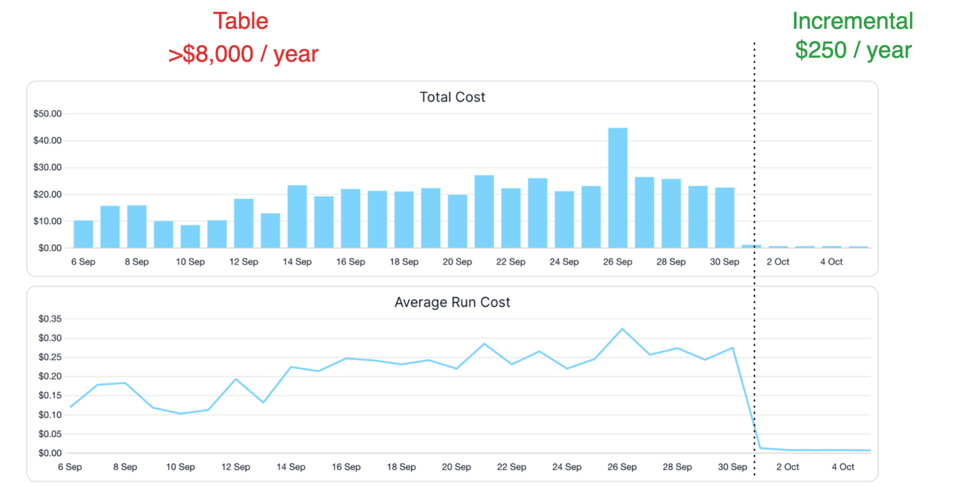
Sur une table d'événements vieille d'un an, passer à des transformations incrémentales en insert-only sur les seuls nouveaux enregistrements peut réduire les coûts de 99 %. Sur une table de commandes vieille d'un an, ne retraiter et ne mettre à jour que les commandes du dernier mois et les nouvelles peut réduire les coûts de 90 % par rapport à un rafraîchissement complet.
Voici un exemple de réduction des coûts obtenue en convertissant l'un de nos data models pour ne traiter que les nouvelles données :
7\. Vérifier que les tables sont correctement clusterisées
L'une des techniques d'optimisation des requêtes les plus importantes est le query pruning : une technique qui réduit le nombre de micro-partitions scannées lors de l'exécution d'une requête. La lecture des micro-partitions est l'une des étapes les plus coûteuses d'une requête, car elle implique de lire les données à distance sur le réseau. Si un filtre est appliqué dans une clause where, une jointure ou une sous-requête, Snowflake tentera d'éliminer toutes les micro-partitions dont il sait qu'elles ne contiennent pas de données pertinentes. Pour que cela fonctionne, les micro-partitions doivent contenir une plage de valeurs étroite pour la colonne sur laquelle vous filtrez.
Pour que le query pruning soit possible, la table Snowflake doit être clusterisée correctement en fonction des schémas d'accès des requêtes. Prenons une table orders sur laquelle les utilisateurs filtrent fréquemment les commandes créées après (created_at) une certaine date. Une telle table doit être clusterisée par created_at.

Quand un utilisateur exécute la requête ci-dessous sur la table orders, le query pruning peut écarter la plupart des micro-partitions du scan, ce qui réduit fortement le temps d'exécution et, par conséquent, le coût.
select *
from orders
where created_at > '2022/08/14'
8\. Supprimer les tables inutilisées
Bien qu'elles ne représentent généralement qu'une petite part (< 20 %) des coûts Snowflake globaux, les tables inutilisées et les sauvegardes de time travel peuvent grignoter vos crédits Snowflake. Nous avons déjà expliqué comment identifier les tables inutilisées si vous êtes sur Snowflake Enterprise ou une édition supérieure. Sinon, utilisez la vue TABLE_STORAGE_METRICS en triant par TOTAL_BILLABLE_BYTES pour repérer les tables aux coûts de stockage les plus élevés.
select
table_catalog as database_name,
table_schema as schema_name,
table_name,
(active_bytes + time_travel_bytes + failsafe_bytes + retained_for_clone_bytes) as total_billable_bytes
from snowflake.account_usage.table_storage_metrics
order by total_billable_bytes desc
limit 10
9\. Réduire la rétention des données
Comme nous l'évoquions dans notre article sur les coûts de stockage Snowflake, le paramètre de time travel (rétention des données) peut générer des coûts supplémentaires, puisqu'il faut conserver des copies de toutes les modifications apportées à une table pendant la période de rétention. Chaque utilisateur Snowflake devrait se demander s'il a réellement besoin d'accéder à une version historique de ses tables. Et si oui, sur combien de jours d'historique exactement.
Pour réduire la période de rétention d'une table spécifique, exécutez la requête suivante :
1alter table table set data_retention_time_in_days=0;
Ou, pour appliquer la modification à l'ensemble du compte :
1alter account set data_retention_time_in_days=0;
10\. Utiliser des tables transitoires
Le stockage Fail-safe est une autre source de coûts qui peut peser lourd, en particulier pour les tables à fort taux de churn (nous y revenons plus loin).
Si vos tables sont régulièrement supprimées puis recréées dans le cadre d'un processus ETL, ou si vous disposez déjà d'une copie séparée des données dans un stockage cloud, il n'est généralement pas nécessaire d'en conserver une sauvegarde. En passant une table de permanente à transitoire, vous évitez de dépenser inutilement pour les sauvegardes Fail Safe et Time Travel.
-- exemple de requête pour créer une table en mode transient
create or replace transient table orders as (
select *
from raw.orders
...
)
11\. Éviter les opérations DML fréquentes
Un anti-pattern bien connu sur Snowflake consiste à l'utiliser comme une base de données opérationnelle, en mettant à jour, insérant ou supprimant fréquemment un petit nombre d'enregistrements.
Pourquoi faut-il l'éviter ? Pour deux raisons :
- Les tables Snowflake sont stockées dans des micro-partitions immuables, que Snowflake cherche à maintenir autour de 16 Mo compressés. Une seule micro-partition peut donc contenir des centaines de milliers d'enregistrements. Chaque mise à jour ou suppression d'un enregistrement oblige Snowflake à recréer l'intégralité de la micro-partition. Mettre à jour un seul enregistrement peut donc revenir à en mettre à jour des centaines de milliers. Les
insertspeuvent aussi être concernés en raison d'un processus appelé small file compaction, par lequel Snowflake tente de combiner les nouveaux enregistrements avec des micro-partitions existantes plutôt que d'en créer une nouvelle ne contenant que quelques enregistrements. - Pour les fonctionnalités de stockage time travel et fail safe, Snowflake doit conserver des copies de toutes les versions d'une table. Si les micro-partitions sont fréquemment recréées, le volume de stockage augmente sensiblement. Sur les tables à fort taux de churn (mises à jour fréquentes), le stockage time travel et fail safe peut souvent dépasser le stockage actif de la table elle-même. Pour en savoir plus, consultez notre article sur le cycle de vie d'une table Snowflake.
12\. Veiller à ce que les fichiers soient de taille optimale
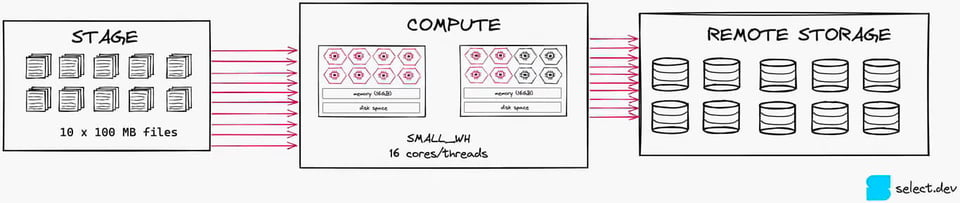
Pour un chargement de données efficient, la bonne pratique est de conserver des fichiers d'environ 100 à 250 Mo. Pour illustrer ces effets, regardez l'image ci-dessous. Avec un seul fichier de 1 Go, on ne sature qu'un seul des 16 threads d'un warehouse Small utilisé pour le chargement.
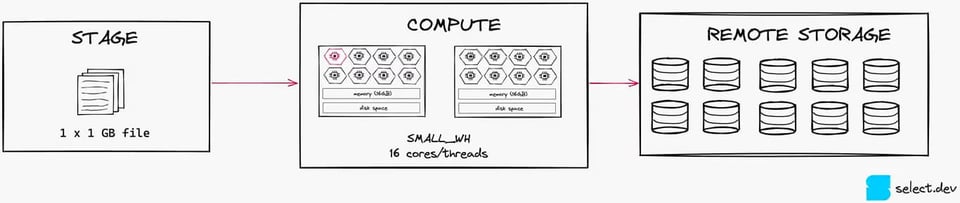
Si l'on découpe ce fichier en dix fichiers de 100 Mo chacun, on mobilise 10 threads sur 16. Ce niveau de parallélisation est bien plus efficace, car il assure une meilleure utilisation des ressources de calcul disponibles (à noter toutefois qu'un X-Small reste le meilleur choix dans ce scénario).
Avoir trop de petits fichiers peut aussi se traduire par des coûts excessifs si vous utilisez Snowpipe pour le chargement, puisque Snowflake facture des frais supplémentaires de 0,06 crédit pour 1 000 fichiers chargés.
13\. Tirer parti du contrôle d'accès
Le contrôle d'accès est un levier puissant de maîtrise des coûts auquel beaucoup de clients Snowflake ne pensent pas. En restreignant les personnes habilitées à modifier les virtual warehouses, vous limitez les risques qu'une manipulation involontaire de ressource entraîne des coûts inattendus. Nous avons vu de nombreux cas où quelqu'un augmente la taille d'un virtual warehouse et oublie ensuite de la rétablir. En mettant en place un contrôle d'accès plus strict, les entreprises s'assurent que les modifications de ressources passent par un processus encadré et limitent les changements non souhaités.
Vous pouvez également utiliser le contrôle d'accès pour limiter les utilisateurs autorisés à exécuter des requêtes sur certains warehouses. En ne donnant accès qu'à des warehouses de petite taille, vous poussez les utilisateurs à écrire des requêtes plus efficientes plutôt qu'à se rabattre sur un warehouse plus grand. Le cas échéant, des politiques ou des processus peuvent autoriser certaines requêtes ou certains utilisateurs à s'exécuter sur un warehouse plus grand lorsque c'est absolument nécessaire.
14\. Activer les query timeouts
Les query timeouts sont un paramètre qui empêche les requêtes Snowflake de s'exécuter trop longtemps, et donc de coûter trop cher. Si une requête dépasse le délai défini, Snowflake l'annule automatiquement.
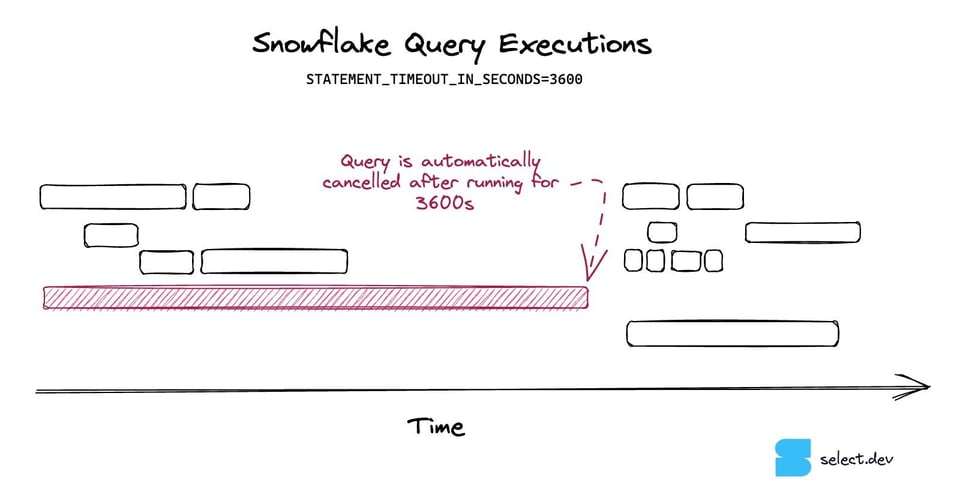
Les query timeouts sont un excellent moyen d'atténuer l'impact des requêtes qui s'emballent. Par défaut, une requête Snowflake peut tourner pendant deux jours avant d'être annulée, en accumulant des coûts considérables. Nous recommandons d'activer des query timeouts sur l'ensemble des warehouses pour plafonner le coût maximal qu'une seule requête peut générer. Consultez notre article à ce sujet pour davantage de conseils sur leur paramétrage.
15\. Configurer les resource monitors
À l'instar des query timeouts, les resource monitors permettent de plafonner le coût total qu'un warehouse peut générer. Ils servent à deux choses :
- Vous envoyer une notification dès que les coûts atteignent un certain seuil
- Empêcher un warehouse de dépasser un certain montant sur une période donnée. Snowflake peut bloquer l'exécution des requêtes sur un warehouse une fois son quota atteint.
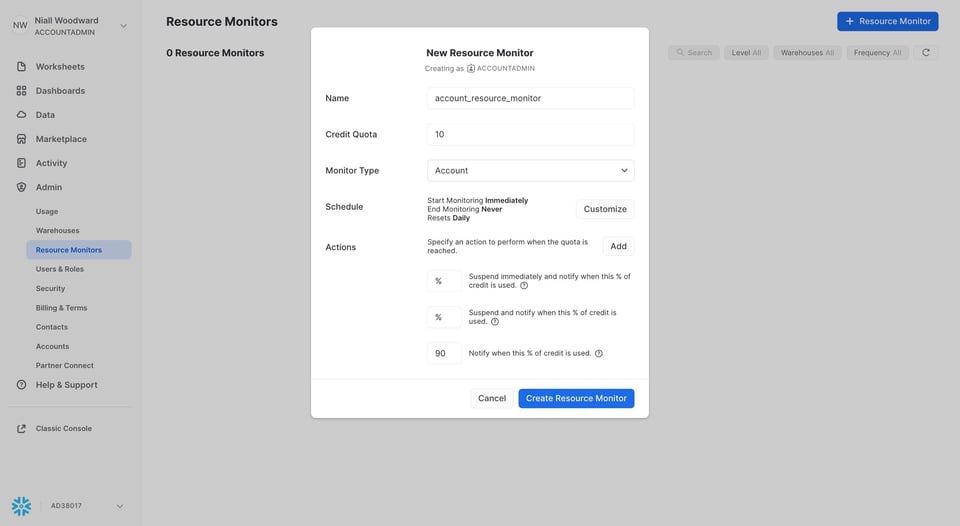
Les resource monitors sont un excellent moyen d'éviter les mauvaises surprises sur votre facture et d'empêcher les coûts inutiles à la source.
Un dernier conseil
Il y a une excellente citation issue du monde du FinOps, qui mérite d'être partagée :
Les plus grandes économies cloud viennent des coûts qui n'ont jamais été engagés.
Dans cet article, nous avons partagé toute une série de moyens de réduire vos coûts Snowflake pour atteindre vos objectifs ou libérer du budget pour de nouveaux workloads. Mais en arriver au point où ces techniques deviennent indispensables, c'est aussi le signe que ces coûts ont déjà été engagés et que vous avez peut-être opéré de manière sous-optimale pendant un certain temps.
L'un des meilleurs moyens d'éviter les coûts inutiles, c'est de mettre en place dès le départ une stratégie de monitoring efficace. Construisez votre propre dashboard à partir des vues account usage de Snowflake et passez-le en revue chaque semaine, ou essayez un produit dédié au monitoring de coûts comme SELECT. En détectant tôt les dérives, vous empêchez les coûts inutiles de s'accumuler.
The Missing Manual : tout ce qu'il faut savoir sur l'optimisation des coûts Snowflake (avril 2023)
Si vous cherchez une présentation qui couvre une grande partie des sujets abordés dans cet article, nous vous recommandons de visionner la conférence que nous avons donnée à Data Council en avril 2023.
Dans cette intervention, nous couvrons tout ce qu'il faut savoir sur l'optimisation des coûts et de la performance dans Snowflake. Nous commençons par une plongée dans l'architecture et le modèle de facturation de Snowflake, en abordant des concepts clés comme les virtual warehouses, le micro-partitionnement, le cycle de vie d'une requête et le cache à deux niveaux de Snowflake. Nous détaillons ensuite les stratégies d'optimisation les plus importantes : configuration des virtual warehouses, clustering des tables et bonnes pratiques d'écriture des requêtes. Tout au long de l'intervention, nous partageons des extraits de code et d'autres ressources pour tirer le meilleur parti de Snowflake.
Enregistrement
L'enregistrement de la présentation est disponible sur YouTube.
Lecture
Si vous le souhaitez, nous serions ravis de venir présenter cette intervention (ou une variante) à votre équipe, qui pourra alors poser ses questions. Envoyez un e-mail à [email protected] pour organiser cela.
Slides
[COPIE PUBLIQUE] The Missing Manual - SELECT - Data Council - Google Slides
Chargement…
Cela peut prendre quelques instants
1
Chargement…
Certaines parties de cette diapositive ne se sont pas chargées. Essayez de recharger Recharger
Tout effacerMaj+A
Certaines diapositives ne se sont pas chargées. Actualiser
Ouvrir les notes du présentateurS
Activer le pointeur laserL
Désactiver le pointeur laserL
Activer le styloMaj+L
Désactiver le styloMaj+L
Passer en plein écranCtrl+Maj+F
Quitter le plein écranCtrl+Maj+F
Permuter les écransD
Quitter le diaporamaÉchap
Lecture automatique►
Préférences des sous-titres
Plus►
Q & RA
Télécharger au format PDF
Télécharger au format PPTX
ImprimerCtrl+P
Ouvrir dans l'éditeur
Raccourcis clavierCtrl+/
Signaler un problème
Signaler un abus
Ian Whitestone·Co-fondateur & CEO de SELECT
Ian est cofondateur et CEO de SELECT, une plateforme SaaS de gestion et d'optimisation des coûts Snowflake. Avant de lancer SELECT, Ian a passé 6 ans à la tête d'équipes data science et engineering full stack chez Shopify et Capital One. Chez Shopify, il a piloté les efforts d'optimisation du data warehouse et d'amélioration de l'observabilité des coûts.
Niall Woodward·Co-fondateur & CTO de SELECT
Niall est cofondateur et CTO de SELECT, une plateforme SaaS de gestion et d'optimisation des coûts Snowflake. Avant de lancer SELECT, Niall était data engineer chez Brooklyn Data Company et dans plusieurs startups. Passionné d'open-source, il est également mainteneur de SQLFluff et créateur de trois packages dbt : dbt_artifacts, dbt_snowflake_monitoring et dbt_query_tags.