Snowflake è una piattaforma straordinariamente potente, in grado di scalare per gestire volumi di dati sempre maggiori senza sacrificare le performance. Se non vengono tenuti sotto controllo, però, i costi legati a questa scalabilità salgono rapidamente. Che il suo obiettivo sia ridurre il prezzo di un rinnovo imminente, allungare la durata del contratto in essere o abbattere i costi on-demand, applichi le strategie di questo articolo per ottenere risparmi significativi.
Tutto quello di cui parliamo si basa su strategie reali che SELECT ha aiutato a mettere in pratica presso oltre 100 clienti Snowflake. Se pensa che ci sia qualcosa che abbiamo tralasciato, ci farebbe piacere saperlo: ci scriva via email oppure utilizzi la chat in basso a destra.
L'articolo si concentra sulle tecniche di cost optimization e su come sfruttarle per eliminare consumi di credit Snowflake superflui e liberare budget per altri workloads. Se invece il suo obiettivo è velocizzare l'esecuzione delle query Snowflake, le consigliamo di leggere il nostro articolo sulla Snowflake query optimization, ricco di suggerimenti pratici per ridurre i tempi di esecuzione.
Prima di iniziare
Prima di iniziare, è davvero importante capire quali siano i reali cost driver di Snowflake e il modello di pricing della piattaforma. Vediamo molti clienti Snowflake buttarsi direttamente sull'ottimizzazione di singole query o sulla riduzione dei costi di storage, senza accorgersi che quelle aree potrebbero non essere il vero problema, né il punto giusto da cui partire.
Come primo passo, suggeriamo di consultare la panoramica di Snowflake cost management nella sezione admin dell'interfaccia e di farsi un'idea di quali servizi (compute, storage, serverless, ecc.) pesino di più sui costi. Nella maggior parte dei casi il driver principale è il compute (tipicamente oltre l'80% del costo totale Snowflake). Chiarito questo, il passo successivo è capire quali workloads, all'interno dei virtual warehouse, incidano davvero sulla spesa. Lo si può fare calcolando un costo per query e aggregando poi tali costi in base ai metadati delle query (ad esempio query tag o commenti).
Tecniche di cost optimization
Le tecniche di riduzione dei costi proposte in questo articolo si articolano in sei macrocategorie:
1. Configurazione dei virtual warehouse
- Ridurre l'auto-suspend
- Ridurre la dimensione del warehouse
- Impostare il numero minimo di cluster a 1
- Consolidare i warehouse
2. Configurazione dei workloads
- Ridurre la frequenza delle query
- Elaborare solo dati nuovi o aggiornati
3. Configurazione delle tabelle
- Verificare che le tabelle siano clusterizzate correttamente
- Eliminare le tabelle inutilizzate
- Ridurre la data retention
- Utilizzare tabelle transient
5. Pattern di caricamento dei dati
- Evitare operazioni DML frequenti
- Assicurarsi che i file abbiano una dimensione ottimale prima del caricamento
6. Sfruttare i controlli nativi di Snowflake
- Usare l'access control per limitare utilizzo e modifiche dei warehouse
- Attivare i query timeout
- Configurare i resource monitor di Snowflake
Entriamo subito nel vivo.
1\. Ridurre l'auto-suspend a 60 secondi
Imposti timeout di auto-suspend a 60 secondi per tutti i virtual warehouse. L'unica eccezione riguarda i workloads rivolti agli utenti finali, in cui la bassa latenza è prioritaria e la cache del warehouse viene sfruttata di frequente. Nel dubbio, parta da 60 secondi e aumenti il valore solo se le performance ne risentono.
alter warehouse compute_wh set
auto_suspend=60;
Le impostazioni di auto-suspend hanno un impatto importante sulla fattura, perché Snowflake addebita ogni secondo di esecuzione di un warehouse, con un minimo di 60 secondi. Per questo sconsigliamo di scendere sotto i 60 secondi: si rischia di pagare due volte. Valori superiori a 60 secondi, viceversa, fanno sì che i warehouse risultino fatturabili anche quando non stanno elaborando alcuna query. Di default, tutti i virtual warehouse creati dall'interfaccia utente hanno auto-suspend a 5 minuti: faccia quindi attenzione quando ne crea di nuovi.
Ogni volta che un virtual warehouse Snowflake riprende l'attività, le viene addebitato un minimo di 1 minuto. Superato quel minuto, l'addebito è al secondo. Anche se tecnicamente è possibile impostare un valore di auto-suspend inferiore a 60s (può perfino indicare 0s!), Snowflake spegnerà comunque il warehouse solo dopo 30 secondi di inattività.
Proprio per il minimo di fatturazione di 1 minuto, con auto-suspend a 30s ci si può ritrovare con addebiti doppi. Ecco un esempio:
- Arriva una query che gira per 1s
- Il warehouse si spegne dopo 30s
- Subito dopo lo spegnimento arriva un'altra query che riattiva il warehouse e gira per 1s
- Il warehouse si spegne di nuovo dopo 30s
Pur essendo rimasto attivo per circa 1 minuto, in questo scenario l'utente pagherà di fatto 2 minuti di compute, perché il warehouse è ripartito due volte e ogni avvio comporta un addebito minimo di 1 minuto.
2\. Ridurre la dimensione dei virtual warehouse
Le risorse di calcolo e i costi dei virtual warehouse scalano in modo esponenziale. Ecco un rapido promemoria, con i costi di compute orari espressi in credit (e dollari) ipotizzando una tariffa tipica di 2,5 $ per credit.
| Warehouse Size | Prezzo orario del virtual warehouse |
|---|---|
| X-Small | 1 ($2,50) |
| Small | 2 ($5) |
| Medium | 4 ($10) |
| Large | 8 ($20) |
| X-Large | 16 ($40) |
| 2X-Large | 32 ($80) |
| 3X-Large | 64 ($160) |
| 4X-Large | 128 ($320) |
| 5X-Large | 256 ($640) |
| 6X-Large | 512 ($1280) |
Ecco invece il prezzo mensile di ciascun warehouse ipotizzando un'esecuzione continua (non è lo scenario reale, vista la presenza dell'auto-suspend, ma rende l'idea del costo meglio del dato orario):
| Warehouse Size | Prezzo orario del virtual warehouse |
|---|---|
| X-Small | 720 ($1.800) |
| Small | 1.440 ($3.600) |
| Medium | 2.880 ($7.200) |
| Large | 5.760 ($14.400) |
| X-Large | 11.520 ($28.800) |
| 2X-Large | 23.040 ($57.600) |
| 3X-Large | 46.080 ($115.200) |
| 4X-Large | 92.160 ($230.400) |
| 5X-Large | 184.320 ($460.800) |
| 6X-Large | 368.640 ($921.600) |
I warehouse sovradimensionati possono talvolta rappresentare la quota maggiore dell'utilizzo di Snowflake. Riduca le dimensioni dei warehouse e osservi l'impatto sui workloads. Se le performance restano accettabili, provi a ridurle ancora. Consulti la nostra guida completa su come scegliere la dimensione giusta del warehouse in Snowflake, che include euristiche pratiche per individuare i warehouse sovradimensionati.
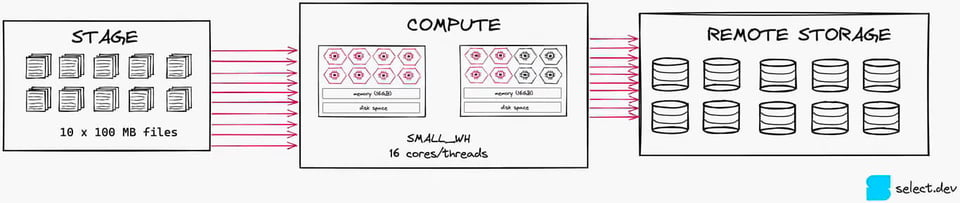
Esempio di riduzione della dimensione del warehouse:
A titolo di esempio pratico, consideri un job di data loading che carica dieci file ogni ora su un warehouse di dimensione Small. Un warehouse Small ha 2 nodi e 16 core complessivi a disposizione per l'elaborazione. Questo job può al massimo saturare 10 core su 16 (1 file per core), quindi il warehouse non verrà sfruttato appieno. Eseguirlo su un warehouse X-Small sarebbe nettamente più conveniente.
3\. Impostare il numero minimo di cluster a 1
Le edizioni Snowflake Enterprise o superiori offrono il multi-cluster warehousing, che permette ai warehouse di aggiungere cluster in parallelo per assorbire un aumento della domanda. Il numero minimo di cluster dovrebbe essere sempre impostato a 1 per evitare over-provisioning. Snowflake aggiungerà automaticamente cluster fino al massimo configurato, con tempi di provisioning minimi, quando necessario. Un valore minimo superiore a 1 si traduce in cluster inutilizzati ma fatturabili.
1alter warehouse compute_wh set min_cluster_count=1;
4\. Consolidare i warehouse
Un grosso problema che riscontriamo in molti clienti Snowflake è il cosiddetto warehouse sprawl. Quando i warehouse sono troppi, parecchi non vengono saturati di query e restano inattivi, generando consumo di credit superfluo.
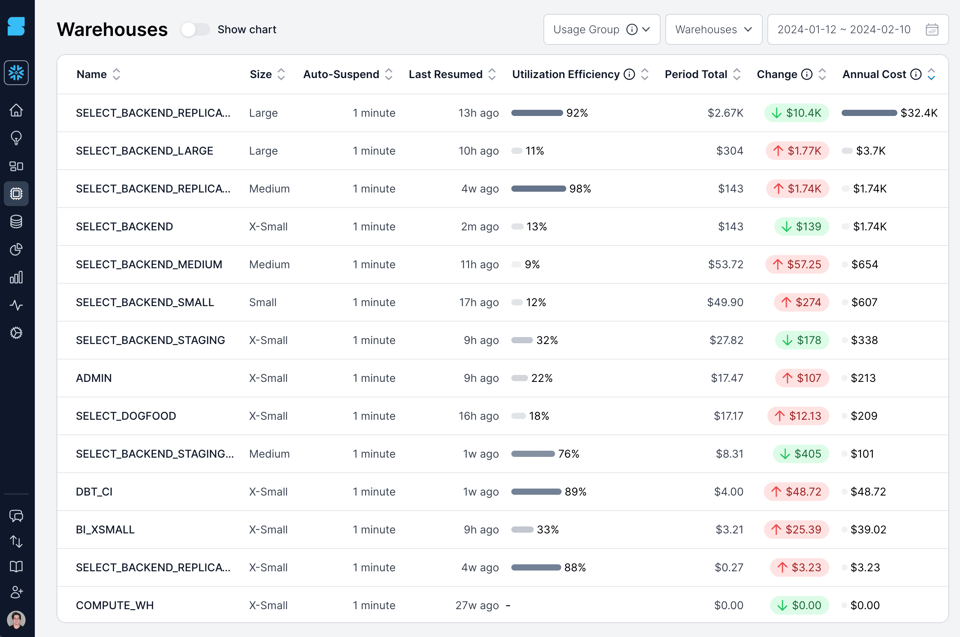
Ecco un esempio dei warehouse del nostro stesso account Snowflake, visualizzati nel prodotto SELECT. Calcoliamo ed esponiamo una metrica personalizzata, la warehouse utilization efficiency, che misura la percentuale di tempo in cui il warehouse è attivo ed elabora query. Guardando il warehouse SELECT_BACKEND_LARGE nella seconda riga, l'efficienza di utilizzo è bassa, all'11%: significa che per l'89% del tempo per cui paghiamo è fermo e non elabora alcuna query. Anche altri warehouse mostrano un'efficienza ridotta.
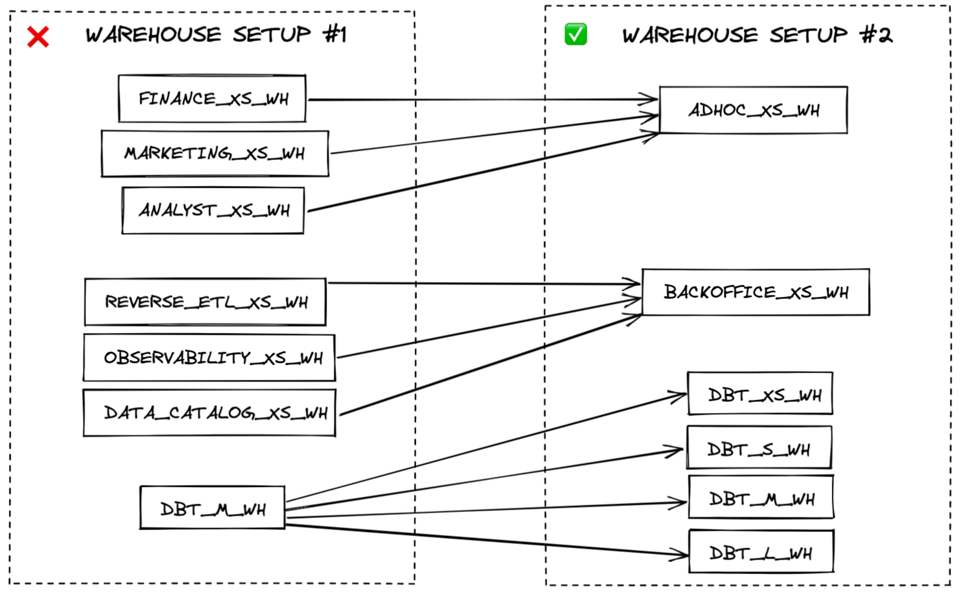
Il modo migliore per assicurarsi che i virtual warehouse siano usati in modo efficiente è impiegarne il minor numero possibile. Dove serve, crei warehouse separati in base ai requisiti di performance, non ai domini di workload.
Ad esempio, creare un warehouse per tutto il data loading, uno per le trasformazioni e uno per le query live di BI risulta più efficiente in termini di costi rispetto ad avere un warehouse per i dati marketing e uno per i dati finance. I workloads di data loading hanno tipicamente gli stessi requisiti di performance (tollerano un certo queueing) e spesso possono condividere un warehouse X-Small multi-cluster. Le query live rivolte agli utenti finali, invece, possono trarre beneficio da un warehouse più grande per ridurre la latenza.
Quando, all'interno di una categoria (loading, trasformazione, querying live, ecc.), un workload richiede una dimensione di warehouse maggiore per ottenere tempi di risposta accettabili, crei un nuovo warehouse più grande dedicato esclusivamente a quei casi. Per la massima efficienza di costo, le query dovrebbero sempre girare sul warehouse più piccolo su cui mantengono una velocità sufficiente.
5\. Ridurre la frequenza delle query
In molte aziende, i job di trasformazione dati in batch vengono eseguiti per impostazione predefinita ogni ora. Ma i casi d'uso a valle hanno davvero bisogno di una latenza così bassa? Vediamo qualche esempio di come la riduzione della frequenza di esecuzione possa avere un impatto immediato sui costi. Nell'esempio ipotizziamo che tutti i workloads siano non incrementali e quindi eseguano un refresh completo dei dati a ogni run, e che il costo iniziale dell'esecuzione oraria fosse di 100.000 $.
| Frequenza di esecuzione | Costo annuo | Risparmio |
|---|---|---|
| Ogni ora | $100.000 | $0 |
| Oraria nei giorni feriali, giornaliera nel weekend | $75.000 | $75.000 |
| Oraria durante l'orario di lavoro | $50.000 | $50.000 |
| Una volta a inizio giornata, una intorno a mezzogiorno | $8.000 | $92.000 |
| Giornaliera | $4.000 | $96.000 |
6\. Elaborare solo dati nuovi o aggiornati
Volumi significativi di dati sono spesso immutabili, ovvero non cambiano una volta creati. Pensi ad esempio agli eventi web o agli eventi di spedizione. Altri dati cambiano, ma raramente oltre un certo intervallo di tempo: è il caso degli ordini, difficilmente modificati a più di un mese dall'acquisto.
Anziché rielaborare tutti i dati a ogni job di trasformazione batch, l'incrementalizzazione permette di filtrare solo i record nuovi o aggiornati all'interno di una determinata finestra temporale, eseguire le trasformazioni e poi inserire o aggiornare quei dati nella tabella finale.
Per una tabella di eventi vecchia di un anno, passare a trasformazioni incrementali in sola insert sui nuovi record può ridurre i costi del 99%. Per una tabella di ordini vecchia di un anno, rielaborare e aggiornare solo gli ordini dell'ultimo mese e quelli nuovi può ridurre i costi del 90% rispetto a un refresh completo.
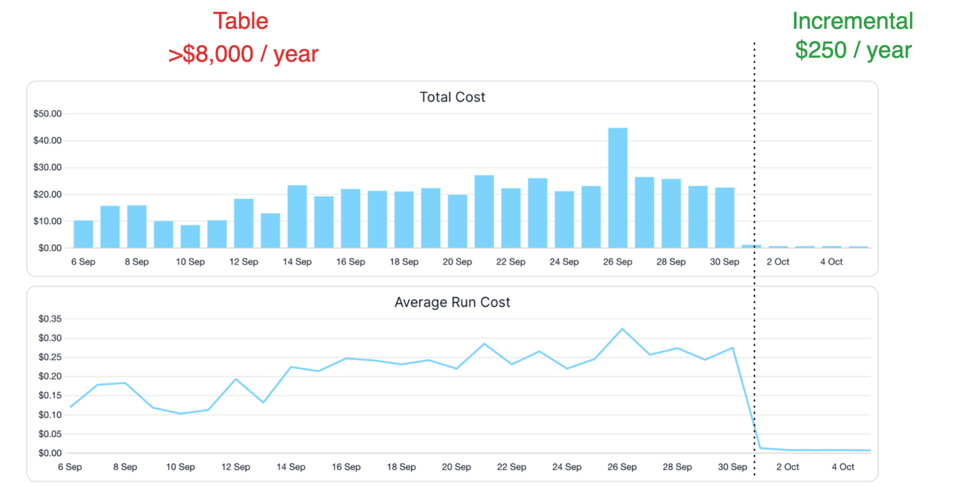
Ecco un esempio della riduzione dei costi che abbiamo ottenuto convertendo uno dei nostri data model affinché elaborasse solo i dati nuovi:
7\. Verificare che le tabelle siano clusterizzate correttamente
Una delle tecniche di query optimization più importanti è il query pruning: una tecnica per ridurre il numero di micro-partition scansionate durante l'esecuzione di una query. La lettura delle micro-partition è uno degli step più costosi di una query, perché comporta la lettura dei dati da remoto attraverso la rete. Quando viene applicato un filtro in una clausola where, in una join o in una subquery, Snowflake cerca di escludere tutte le micro-partition che sa non contenere dati rilevanti. Perché questo funzioni, le micro-partition devono contenere un intervallo ristretto di valori per la colonna su cui si sta filtrando.
Affinché il query pruning sia possibile, la tabella in Snowflake deve essere clusterizzata correttamente in base ai pattern di accesso delle query. Consideri una tabella orders, dove gli utenti filtrano spesso per ordini creati dopo (created_at) una certa data. Una tabella di questo tipo dovrebbe essere clusterizzata per created_at.

Quando un utente esegue la query qui sotto sulla tabella orders, il query pruning può evitare la scansione della maggior parte delle micro-partition, riducendo nettamente il tempo di esecuzione e, di conseguenza, abbattendo i costi.
select *
from orders
where created_at > '2022/08/14'
8\. Eliminare le tabelle inutilizzate
Pur rappresentando di solito solo una piccola quota (<20%) dei costi Snowflake complessivi, le tabelle inutilizzate e i backup di time-travel possono erodere i suoi credit Snowflake. In passato abbiamo già spiegato come identificare le tabelle inutilizzate con Snowflake Enterprise edition o superiore. In caso contrario, utilizzi la vista TABLE_STORAGE_METRICS ordinando per TOTAL_BILLABLE_BYTES per individuare le tabelle con i costi di storage più elevati.
select
table_catalog as database_name,
table_schema as schema_name,
table_name,
(active_bytes + time_travel_bytes + failsafe_bytes + retained_for_clone_bytes) as total_billable_bytes
from snowflake.account_usage.table_storage_metrics
order by total_billable_bytes desc
limit 10
9\. Ridurre la data retention
Come illustrato nel nostro articolo sui costi di storage di Snowflake, l'impostazione di time travel (data retention) può generare costi aggiuntivi, perché richiede di conservare copie di tutte le modifiche apportate a una tabella durante il periodo di retention. Tutti gli utenti Snowflake dovrebbero chiedersi se hanno davvero bisogno di poter accedere a una versione storica delle proprie tabelle. E, in caso affermativo, quanti giorni di storico vogliono mantenere.
Per ridurre il periodo di data retention di una singola tabella, può eseguire la query seguente:
1alter table table set data_retention_time_in_days=0;
Per applicare la modifica all'intero account, esegua invece:
1alter account set data_retention_time_in_days=0;
10\. Usare tabelle transient
Lo storage Fail Safe è un'ulteriore voce di costo di storage che può accumularsi, in particolare per le tabelle con molte modifiche (ne parliamo più avanti).
Se le sue tabelle vengono regolarmente eliminate e ricreate nell'ambito di un processo ETL, oppure se ne ha già una copia separata su cloud storage, nella maggior parte dei casi non serve mantenerne un backup. Convertendo una tabella da permanente a transient evita spese inutili su Fail Safe e Time Travel.
-- example query to create a table as transient
create or replace transient table orders as (
select *
from raw.orders
...
)
11\. Evitare operazioni DML frequenti
Un anti-pattern ben noto in Snowflake è trattarlo come un database operazionale, eseguendo di frequente update, insert o delete su un numero limitato di record.
Perché è da evitare? Per due motivi:
- Le tabelle Snowflake sono memorizzate in micro-partition immutabili, che Snowflake cerca di mantenere intorno ai 16MB compressi. Una singola micro-partition può quindi contenere centinaia di migliaia di record. Ogni volta che si aggiorna o elimina un singolo record, Snowflake deve ricreare l'intera micro-partition. Aggiornare un singolo record può quindi equivalere a riscriverne centinaia di migliaia. Anche gli
insertne possono risentire, a causa di un processo noto come small file compaction, con cui Snowflake tenta di combinare i nuovi record con micro-partition esistenti invece di crearne una nuova con pochi record. - Per le funzionalità di storage time travel e fail safe, Snowflake deve conservare copie di tutte le versioni di una tabella. Se le micro-partition vengono ricreate spesso, la quantità di storage cresce in modo sensibile. Per le tabelle con elevato churn (aggiornamenti frequenti), lo storage di time travel e fail safe può facilmente superare lo storage attivo della tabella stessa. Per approfondire, può leggere il nostro articolo sul ciclo di vita di una tabella in Snowflake.
12\. Assicurarsi che i file abbiano una dimensione ottimale
Per un data loading efficiente in termini di costi, una best practice è mantenere i file intorno a 100-250MB. Per chiarire il concetto, osservi l'immagine seguente. Con un solo file da 1GB, si satura 1 thread su 16 di un warehouse Small dedicato al caricamento.
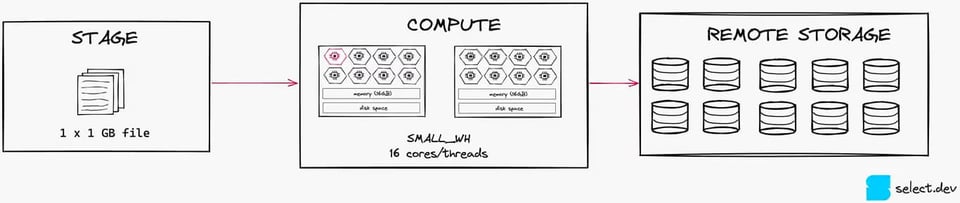
Se invece divide quello stesso file in dieci file da 100MB ciascuno, utilizzerà 10 thread su 16. Questo livello di parallelizzazione è molto migliore, perché sfrutta meglio le risorse di compute disponibili (anche se, in questo scenario, un X-Small resterebbe comunque la scelta migliore).
Avere troppi file di piccole dimensioni può inoltre generare costi eccessivi se utilizza Snowpipe per il data loading, perché Snowflake applica una commissione aggiuntiva di 0,06 credit ogni 1000 file caricati.
13\. Sfruttare l'access control
L'access control è una leva potente per il controllo dei costi a cui molti clienti Snowflake non pensano. Limitando chi può apportare modifiche ai virtual warehouse, riduce al minimo la probabilità che qualcuno cambi per errore una risorsa, generando costi imprevisti. Abbiamo visto molti casi in cui qualcuno aumenta la dimensione di un virtual warehouse e poi si dimentica di riportarla al valore iniziale. Con un access control più rigoroso, le aziende possono garantire che le modifiche alle risorse passino da un processo controllato, riducendo al minimo il rischio di cambiamenti involontari.
Può anche usare l'access control per limitare quali utenti possono lanciare query su determinati warehouse. Permettendo agli utenti di usare solo warehouse più piccoli, li costringe a scrivere query più efficienti, anziché ripiegare di default su un warehouse più grande. Quando serve, può prevedere policy o processi che consentano a determinate query o utenti di girare su un warehouse più grande nei casi in cui sia davvero indispensabile.
14\. Abilitare i query timeout
I query timeout sono un'impostazione che impedisce alle query Snowflake di restare in esecuzione troppo a lungo e, quindi, di costare troppo. Se una query gira oltre il timeout impostato, Snowflake la annulla automaticamente.
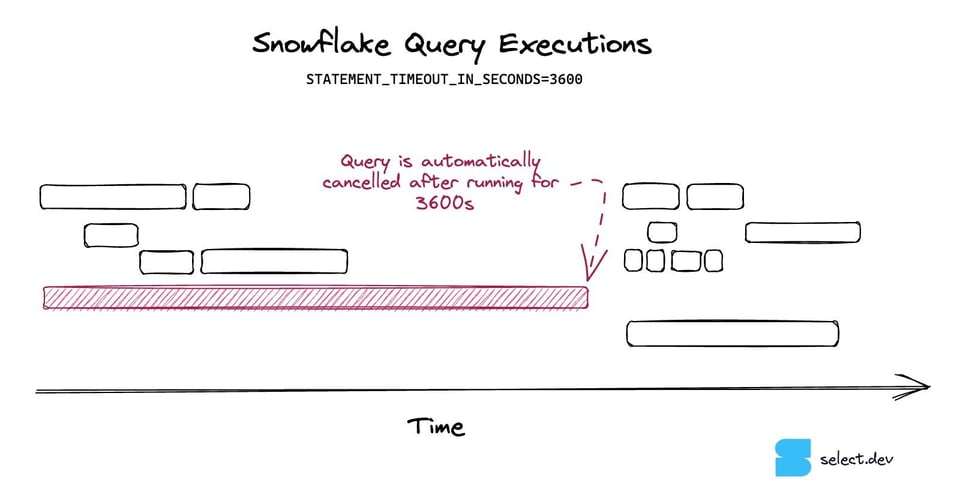
I query timeout sono un ottimo strumento per contenere l'impatto delle query fuori controllo. Di default, una query Snowflake può girare per due giorni prima di essere annullata, accumulando costi notevoli. Consigliamo di applicare i query timeout su tutti i warehouse per limitare il costo massimo che una singola query può generare. Per ulteriori indicazioni su come impostarli, veda il nostro articolo dedicato.
15\. Configurare i resource monitor
Come i query timeout, anche i resource monitor consentono di limitare il costo totale che un determinato warehouse può generare. Può utilizzarli per due finalità:
- Ricevere una notifica quando i costi raggiungono una certa soglia
- Impedire che un warehouse superi un determinato costo in un dato intervallo di tempo. Snowflake può bloccare l'esecuzione delle query su un warehouse che ha superato la propria quota.
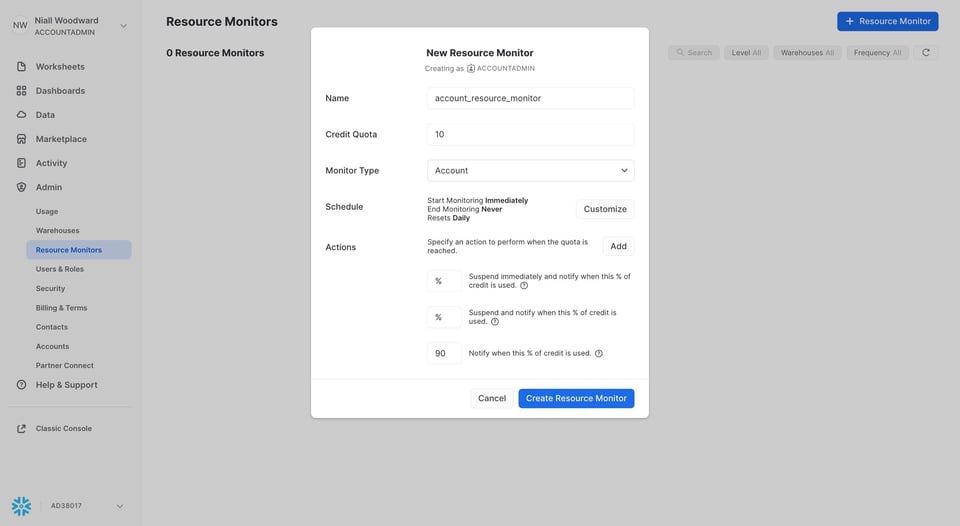
I resource monitor sono un ottimo strumento per evitare sorprese in fattura e prevenire a monte costi non necessari.
Un ultimo consiglio
C'è una bella frase dal mondo del FinOps che vale la pena condividere:
I maggiori risparmi sul cloud arrivano dai costi mai sostenuti
In questo articolo abbiamo condiviso diversi modi per ridurre i costi Snowflake, sia per centrare obiettivi di cost reduction sia per liberare budget da destinare a nuovi workloads. Arrivare al punto di aver bisogno di queste tecniche, però, significa che quei costi sono già stati sostenuti e che probabilmente si è operato in modo subottimale per un periodo prolungato.
Uno dei modi migliori per prevenire costi superflui è impostare fin da subito una strategia efficace di monitoraggio della spesa. Costruisca una dashboard personalizzata sopra le viste account usage di Snowflake e la analizzi ogni settimana, oppure provi un prodotto pensato appositamente per il cost monitoring come SELECT. Intercettando per tempo i problemi di spesa, evita che i costi superflui si accumulino.
The Missing Manual: tutto quello che deve sapere sulla Snowflake Cost Optimization (aprile 2023)
Se sta cercando una presentazione che riprenda molti dei temi affrontati in questo articolo, le consigliamo di guardare il talk che abbiamo tenuto al Data Council nell'aprile 2023.
In questo intervento copriamo tutto quello che c'è da sapere sull'ottimizzazione di costi e performance in Snowflake. Partiamo con un deep dive nell'architettura e nel modello di billing di Snowflake, toccando concetti chiave come virtual warehouse, micro-partitioning, ciclo di vita di una query e cache a due livelli di Snowflake. Approfondiamo poi le strategie di ottimizzazione più importanti, come la configurazione dei virtual warehouse, il clustering delle tabelle e le best practice di scrittura delle query. Per tutto il talk condividiamo snippet di codice e altre risorse utili per sfruttare al meglio Snowflake.
Registrazione
La registrazione della presentazione è disponibile su YouTube.
Play
Se desidera, siamo ben lieti di venire a tenere questa presentazione (o una sua variante) al suo team, dandogli l'opportunità di fare domande. Scriva un'email a [email protected] per organizzarla.
Slide
[PUBLIC COPY] The Missing Manual - SELECT - Data Council - Google Slides
Caricamento in corso…
L'operazione potrebbe richiedere qualche istante
1
Caricamento in corso…
Alcune parti di questa slide non sono state caricate. Provi a ricaricare Ricarica
Cancella tuttoShift+A
Alcune slide non sono state caricate. Aggiorna
Apri note del relatoreS
Attiva il puntatore laserL
Disattiva il puntatore laserL
Attiva la pennaShift+L
Disattiva la pennaShift+L
Entra in modalità schermo interoCtrl+Shift+F
Esci dalla modalità schermo interoCtrl+Shift+F
Scambia displayD
Esci dalla presentazioneEsc
Riproduzione automatica►
Preferenze sottotitoli
Altro►
Q & AA
Scarica come PDF
Scarica come PPTX
StampaCtrl+P
Apri nell'editor
Scorciatoie da tastieraCtrl+/
Segnala un problema
Segnala abuso
Ian Whitestone·Co-founder & CEO di SELECT
Ian è Co-founder & CEO di SELECT, piattaforma SaaS di cost management e ottimizzazione per Snowflake. Prima di fondare SELECT, ha trascorso 6 anni alla guida di team full stack di data science e ingegneria in Shopify e Capital One. In Shopify si è occupato dell'ottimizzazione del data warehouse e dell'aumento della cost observability.
Niall Woodward·Co-founder & CTO di SELECT
Niall è Co-Founder & CTO di SELECT, piattaforma SaaS di cost management e ottimizzazione per Snowflake. Prima di fondare SELECT, è stato data engineer in Brooklyn Data Company e in diverse startup. Appassionato di open-source, è anche maintainer di SQLFluff e autore di tre dbt package: dbt_artifacts, dbt_snowflake_monitoring e dbt_query_tags.