In einem früheren Blogbeitrag haben wir die Grundlagen von semistrukturierten Daten und deren Unterstützung in Snowflake beleuchtet. Außerdem haben wir verschiedene Methoden vorgestellt, um semistrukturierte Daten nach Snowflake zu laden. Doch was kommt als Nächstes, sobald die Daten dort liegen? In diesem Beitrag dreht sich alles um den konkreten Umgang mit JSON-Daten. Wir schauen uns die Transformationsmöglichkeiten an und gehen auf die Funktionen ein, die Snowflake dafür bereitstellt. Vorab werfen wir noch einen kurzen Blick darauf, wie sich JSON-Daten in Snowflake laden lassen.
Snowflake-Funktionen zum Parsen von JSON
Snowflake stellt eine ganze Reihe von Funktionen für die Arbeit mit semistrukturierten JSON-Daten bereit. Die drei gängigsten sind:
PARSE_JSON: erwartet einen String als JSON-Dokument und liefert einenVARIANT-Wert zurückTRY_PARSE_JSON: funktioniert genauso wiePARSE_JSON, gibt abernullzurück, falls beim Parsen ein Fehler auftrittLATERAL FLATTEN: löst ein Array in mehrere Zeilen auf – eine Zeile pro Element.
Auf jede dieser Funktionen gehen wir gleich genauer ein. Zuvor brauchen wir aber ein paar Beispieldaten!
Beispiel-JSON-Daten anlegen
Im weiteren Verlauf arbeiten wir mit den folgenden JSON-Beispieldaten zu einer Person:
1{
2 "person":{
3 "name":"John Doe",
4 "address":{
5 "city":"London",
6 "street":"Oxford Street"
7 },
8 "phone":[\
\
9 "Apple iPhone",\
\
10 "Google Pixel",\
\
11 "Samsung Galaxy"\
\
12 ]
13 }
14}
Wir laden diese Daten in eine Tabelle namens sample_json_data und testen damit die einzelnen Funktionen. Die Tabelle speichert das JSON-Dokument in einer einzelnen VARIANT-Spalte namens src:
create table sample_json_data
(src variant)
;
PARSE_JSON einsetzen
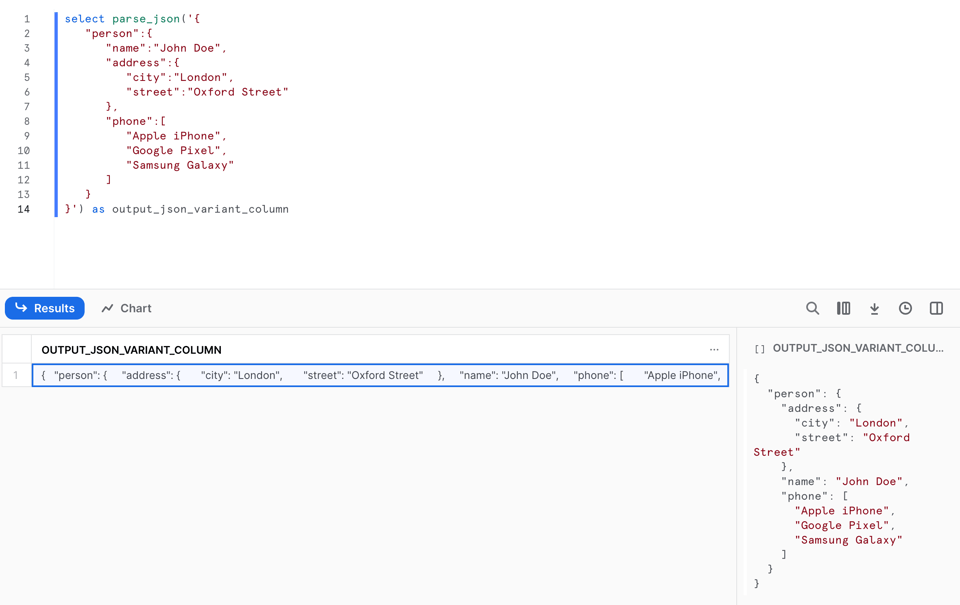
Um einen JSON-Dokument-String in einen VARIANT umzuwandeln, nutzen wir die Funktion PARSE_JSON.
1select parse_json('{
2 "person":{
3 "name":"John Doe",
4 "address":{
5 "city":"London",
6 "street":"Oxford Street"
7 },
8 "phone":[\
\
9 "Apple iPhone",\
\
10 "Google Pixel",\
\
11 "Samsung Galaxy"\
\
12 ]
13 }
14}') as output_json_variant_column
Das Ergebnis sieht so aus:
Damit können wir nun unsere Tabelle sample_json_data befüllen:
1insert into sample_json_data
2select parse_json('{
3 "person":{
4 "name":"John Doe",
5 "address":{
6 "city":"London",
7 "street":"Oxford Street"
8 },
9 "phone":[\
\
10 "Apple iPhone",\
\
11 "Google Pixel",\
\
12 "Samsung Galaxy"\
\
13 ]
14 }
15}');
TRY_PARSE_JSON einsetzen
TRY_PARSE_JSON funktioniert genauso wie PARSE_JSON:
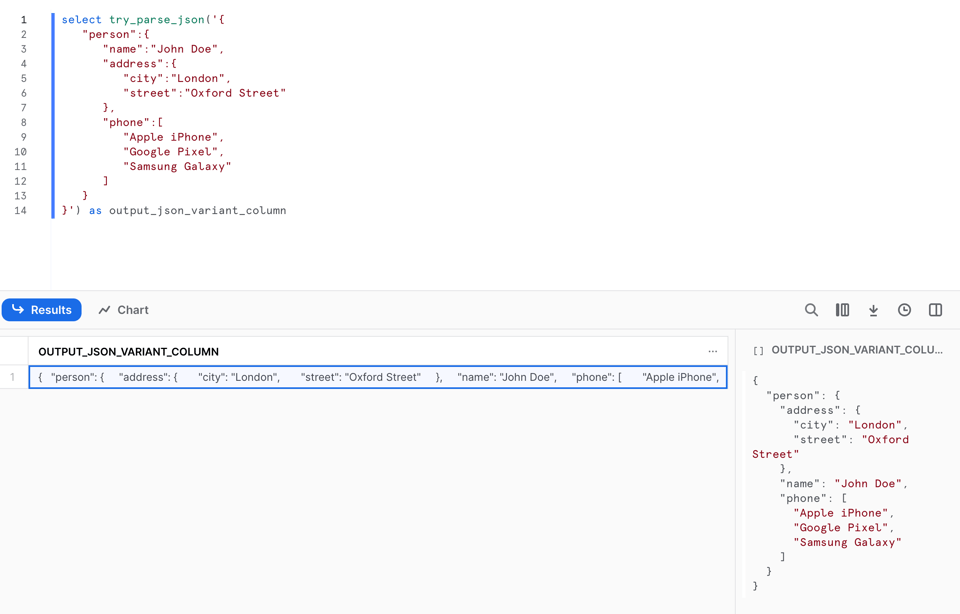
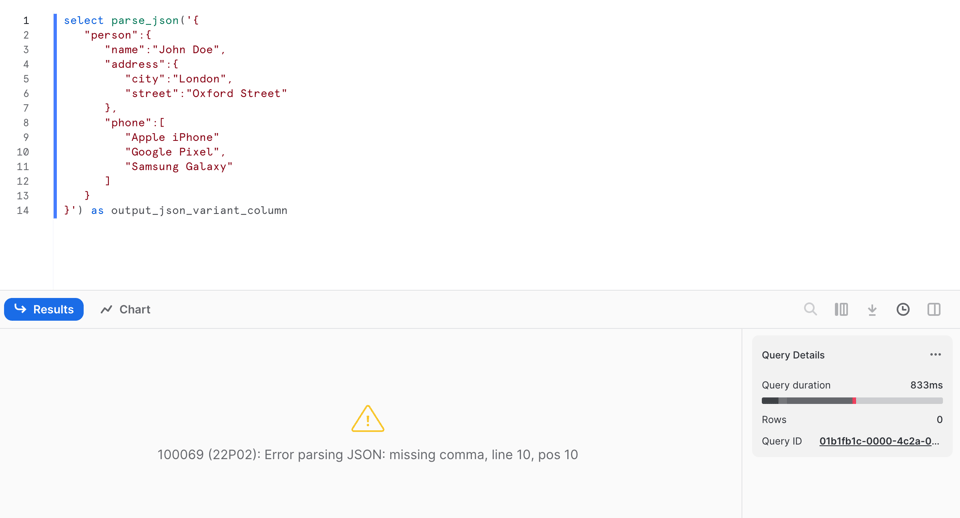
Im Unterschied zu PARSE_JSON liefert die Funktion jedoch null, wenn das JSON nicht geparst werden kann. In Zeile 9 habe ich das Komma entfernt:
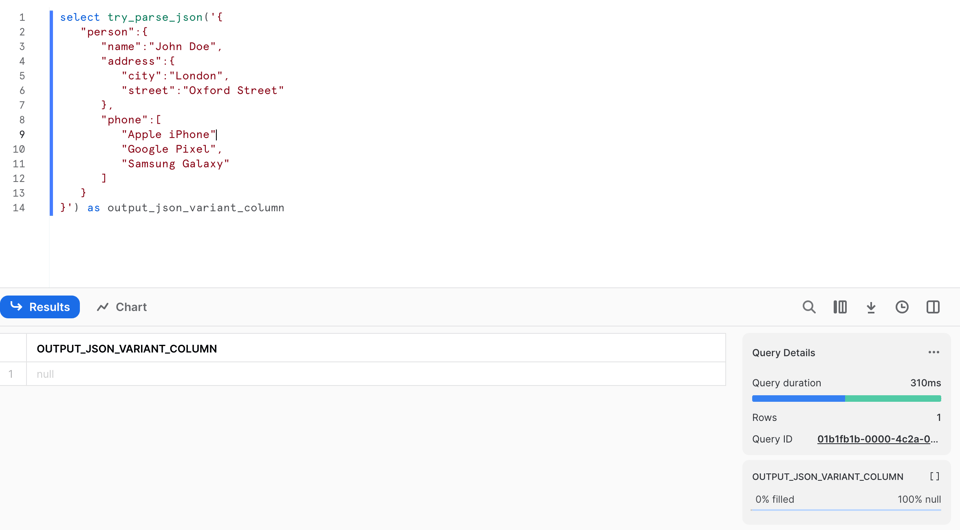
Führen wir PARSE_JSON auf diesen fehlerhaften Daten aus, bricht die Funktion mit einem Fehler ab:
Notation zum Abfragen einer JSON-Spalte
Jetzt greifen wir auf die Daten innerhalb dieses semistrukturierten Datentyps zu. Für einen Schlüssel der obersten Ebene reicht die Doppelpunkt-Notation, etwa src:person. Wer tiefer in die Objektstruktur einsteigen möchte, hat zwei Optionen: entweder die Punktnotation wie in src:person.address.city oder die Klammernotation in der Form src['person']['address']['city'].
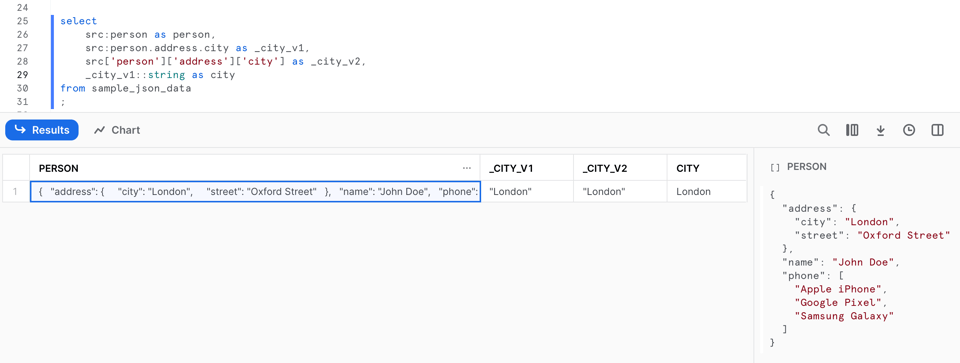
Allgemein lassen sich die Methoden so beschreiben:
- Punktnotation:
<column>:<level1_element>.<level2_element>.<level3_element> - Klammernotation:
<column>['<level1_element>']['<level2_element>']['<level3_element>']
Entsprechen Schlüsselwerte nicht den Bezeichnerregeln von Snowflake SQL – etwa weil sie Leerzeichen enthalten –, müssen Sie den Schlüsselnamen bei der Punktnotation in doppelte Anführungszeichen setzen. Bei der Klammernotation gehören die Werte stets in einfache Anführungszeichen.
Arrays mit LATERAL FLATTEN verarbeiten
Im vorherigen Abschnitt haben wir die Grundlagen der Navigation in einem JSON-Dokument mit Punkt- und Klammernotation behandelt. Aber was, wenn das Dokument Arrays enthält? Nach derselben Logik würde src:person:phone das gesamte Array als einen einzigen Wert zurückgeben, etwa [ "Apple iPhone", "Google Pixel", "Samsung Galaxy" ].
Um über das Array zu iterieren und die einzelnen Werte herauszuziehen, müssen wir es flatten. Das Ergebnis sind drei einzelne Zeilen mit je einem Wert aus dem Array.
Snowflake bietet dafür zwei Funktionen: LATERAL und FLATTEN, die meist gemeinsam zum Einsatz kommen.
Der LATERAL-Join erlaubt es einer Inline-View, auf Spalten eines vorangehenden Tabellenausdrucks zu verweisen. Anders als bei einem nicht-lateralen Join enthält das Ergebnis eines lateralen Joins ausschließlich die Zeilen, die aus der Inline-View hervorgehen. Aus meiner Erfahrung gilt: Einen LATERAL-Join habe ich noch nie ohne FLATTEN verwendet – technisch wäre das aber möglich.
Die Funktion FLATTEN löst zusammengesetzte Werte in mehrere Zeilen auf. Sie nimmt einen semistrukturierten Datentyp (VARIANT, OBJECT oder ARRAY) entgegen und erzeugt daraus eine laterale Sicht. Schauen wir uns an einem Beispiel an, wie sich unser Array mit Mobiltelefonen mithilfe dieser beiden Funktionen in mehrere Zeilen auflösen lässt:
SELECT
p.*
FROM sample_json_data,
LATERAL FLATTEN(input => src:person.phone) p
Die Abfrage liefert dieses Ergebnis:
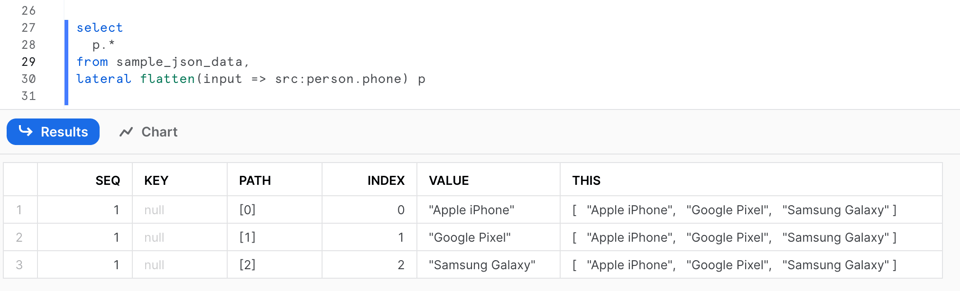
Die Ausgabe von FLATTEN umfasst mehrere Spalten:
SEQ: Eine eindeutige Sequenznummer für den Eingabedatensatz; sie kann unsortiert sein oder Lücken aufweisen.KEY: Bei Maps oder Objekten enthält diese Spalte den Schlüssel des aufgelösten Werts.PATH: Der Pfad zum Element innerhalb der Datenstruktur, die geflattet wird.INDEX: Der Index des Elements, sofern es Teil eines Arrays ist; andernfalls NULL.VALUE: Der Wert des Elements im aufgelösten Array oder Objekt.THIS: Das aktuell aufgelöste Element, hilfreich beim rekursiven Flattening.
Außerdem bleiben die Spalten der linken Seite des LATERAL-Joins zugänglich. Damit lässt sich die Abfrage so anpassen, dass die semistrukturierten JSON-Daten in eine flache Struktur überführt werden:
SELECT
src:person.name::varchar AS person_name,
src:person.address.city::varchar AS city,
src:person.address.street::varchar AS street,
p.value::varchar AS mobile_phone
FROM sample_json_data,
LATERAL FLATTEN(input => src:person.phone) p;
Das Ergebnis:

In dieser SQL-Abfrage ist ein explizites Casting der Spalten nötig, da die Ausgabe im VARIANT-Format vorliegt – die Werte sind also in doppelte Anführungszeichen eingeschlossen. Sie müssen explizit in den gewünschten Datentyp gecastet werden.
Mehrere Ebenen verschachtelter Arrays verarbeiten
Treffen Sie auf ein Szenario mit mehreren Ebenen verschachtelter Arrays, bei dem ein Array ein weiteres enthält, lässt sich LATERAL FLATTEN auf die bereits aufgelösten Werte der ersten Ebene erneut anwenden, um die Array-Werte der nächsten Ebene weiter auszupacken. Der Pseudocode dazu sieht so aus:
SELECT
lvl_1.value,
lvl_2.value
FROM table
LATERAL FLATTEN (input => src:topLevelArray) AS lvl_1,
LATERAL FLATTEN (input => lvl_1.value:innerLevelArray) AS lvl_2;
Im Wesentlichen ist das schon alles. Mit der Kombination aus Punkt- bzw. Klammernotation und LATERAL FLATTEN legen Sie ein solides Fundament für die Arbeit mit JSON-Daten in Snowflake-Tabellen. So lassen sich die Daten effizient in jedes gewünschte Format überführen.
JSON-Dokumente aus relationalen Daten erzeugen
Wir haben gezeigt, wie sich JSON-Daten verarbeiten lassen. Doch wie funktioniert der umgekehrte Weg – strukturierte Daten in JSON umzuwandeln?
Relationale Daten aus einer Snowflake-Tabelle in das JSON-Format zu überführen, ist vor allem dann wichtig, wenn Sie Daten mit externen Systemen austauschen, die für API-Payloads häufig JSON erwarten. Sehen wir uns an, wie das mit den nativen Snowflake-Funktionen geht.
Angenommen, wir haben eine Tabelle relational_data, die aus der Ausgabe der LATERAL FLATTEN-Funktion entstanden ist. Ziel ist es, diese relationalen Daten zurück in eine JSON-Struktur zu überführen. Zunächst erstellen und befüllen wir die Tabelle relational_data:
CREATE TABLE relational_data (
person_name VARCHAR,
city VARCHAR,
street VARCHAR,
mobile_phone VARCHAR
);
INSERT INTO relational_data
SELECT
src:"person".name::varchar AS person_name,
src:"person".address.city::varchar AS city,
src:"person".address.street::varchar AS street,
p.value::varchar AS mobile_phone
FROM sample_json_data,
LATERAL FLATTEN(input => src:person.phone) p;
Für ein JSON-Objekt mit Schlüssel-Wert-Paaren nutzen wir die Funktion OBJECT_CONSTRUCT. Sie erwartet Argumentpaare, wobei das erste den Schlüssel und das zweite den Wert darstellt. Für verschachtelte Objekte verwenden wir einen weiteren OBJECT_CONSTRUCT-Aufruf. Eine einfache Personenstruktur mit Namen lässt sich so erzeugen:
SELECT OBJECT_CONSTRUCT('person',
OBJECT_CONSTRUCT('name', person_name)) AS src
FROM relational_data;
Die Abfrage erzeugt folgende JSON-Struktur:
{
"person": {
"name": "John Doe"
}
}
Als Nächstes ergänzen wir das Adressobjekt mit Werten für Stadt und Straße:
SELECT OBJECT_CONSTRUCT('person',
OBJECT_CONSTRUCT('name', person_name,
'address', OBJECT_CONSTRUCT(
'city', city,
'street', street
)
)
) AS src
FROM relational_data;
Um schließlich ein Array mit Mobiltelefonen hinzuzufügen, nutzen wir die Funktion ARRAY_AGG(), die aus den Eingabewerten ein Array erstellt. Hier die vollständige SQL-Abfrage für die finale JSON-Struktur:
SELECT OBJECT_CONSTRUCT('person',
OBJECT_CONSTRUCT('name', person_name,
'address', OBJECT_CONSTRUCT(
'city', city,
'street', street
),
'phone', ARRAY_AGG(mobile_phone) WITHIN GROUP (ORDER BY person_name) OVER (PARTITION BY person_name)
)
) AS src
FROM relational_data;
Damit lässt sich das JSON-Dokument vollständig rekonstruieren:
1{
2 "person": {
3 "address": {
4 "city": "London",
5 "street": "Oxford Street"
6 },
7 "name": "John Doe",
8 "phone": [\
\
9 "Apple iPhone",\
\
10 "Google Pixel",\
\
11 "Samsung Galaxy"\
\
12 ]
13 }
14}
Mit diesen Schritten haben wir relationale Daten in ein strukturiertes JSON-Dokument überführt, das sich in den unterschiedlichsten Anwendungen einsetzen lässt.
So laden Sie JSON-Daten
In den obigen Beispielen haben wir mit vorgefertigten Beispieldaten gearbeitet. Die meisten Snowflake-Kunden haben diese natürlich nicht parat und müssen ihre JSON-Daten erst einmal in ihren Account laden.
Um eine JSON-Datei in eine Snowflake-Tabelle zu laden, sieht der SQL-Befehl in etwa so aus:
COPY INTO <table_name>
FROM (
SELECT
$1:person:name::STRING as name,
$1:person:address:city::STRING as city,
$1:person:address:street::STRING as street,
$1:person:phone[0]::STRING as phone1,
$1:person:phone[1]::STRING as phone2,
$1:person:phone[2]::STRING as phone3
FROM <my_stage>/<my_json_file.json>
);
Der Befehl setzt Folgendes voraus:
<table_name>ist der Name der Zieltabelle in Snowflake.<my_stage>ist der Name der Stage, in der die JSON-Datei abgelegt ist.<my_json_file.json>ist der Name der JSON-Datei.
Im SELECT-Statement gilt:
- Die Notation
$1verweist auf die erste Spalte der geladenen Datei – in diesem Fall der gesamte JSON-Blob. - Die Doppelpunkt-Notation
:dient der Navigation innerhalb der JSON-Struktur. - Der Cast
::STRINGkonvertiert die JSON-Elemente in den passenden Datentyp – in diesem BeispielSTRING. Den Datentyp können Sie an Ihre Anforderungen anpassen.
Das Beispiel setzt voraus, dass die JSON-Struktur über alle Datensätze in der Datei hinweg konsistent ist. Variiert sie, brauchen Sie unter Umständen zusätzliche Fehlerbehandlung oder weitere Parsing-Logik.
Wer tiefer in die verschiedenen Möglichkeiten zum Laden semistrukturierter Daten (einschließlich JSON) in ein Snowflake Data Warehouse einsteigen möchte, findet die Details in unserem vorherigen Blogbeitrag.
Tipps für die Arbeit mit JSON-Daten
Hier noch ein paar weitere Tipps für die Arbeit mit JSON-Daten:
- Nutzen Sie einen kostenlosen Online-JSON-Formatter wie diesen hier, um Ihre Daten zu formatieren. So lassen sich Struktur und Datenhierarchie visuell viel leichter erfassen.
- Bauen Sie Ihre Abfragen Schritt für Schritt auf und prüfen Sie das Ergebnis nach jedem Schritt. Versuchen Sie zum Beispiel nicht, vier Ebenen verschachteltes JSON auf einmal abzufragen. So lassen sich Fehler – die sich unweigerlich einschleichen – deutlich schneller finden.
- Nutzen Sie temporäre Spalten, um Operationen zu vereinfachen. Sie können zum Beispiel mehrere JSON-Ebenen auf einmal in eine Spalte parsen und von dort aus weiterverarbeiten. Die Hilfsspalten lassen sich später per EXCLUDE-Befehl von Snowflake wieder entfernen. Das folgende Beispiel zeigt, wie sich die wiederholte Verarbeitung des Felds
addresseinsparen lässt. Zurückgegeben werden nur zwei Spalten:cityundstreet:
with
data as (
select
src:person.address as address,
address:city::string as city,
address:street::string as street
from sample_json_data
)
select * exclude(address)
from data
- Wenn Sie aus JSON-Daten neue Datensätze erstellen, lagern Sie häufig genutzte Spalten in eigene Spalten aus, statt sie in einer einzigen
variant-Spalte zu belassen. Das verbessert die Abfrage-Experience für Endnutzer deutlich. - JSON-Attribute sind case-sensitiv. Wer
address.Citystattaddress:cityschreibt, bekommtnullzurück.
Damit endet unser Leitfaden. Sie wissen nun, wie sich ein JSON-Dokument parsen, flatten und in einer relationalen Tabelle in Snowflake ablegen lässt. Außerdem haben wir den umgekehrten Weg betrachtet – das Erzeugen von JSON aus einer Snowflake-Tabelle. Unsere Beispiele behandelten einfache Datenstrukturen, doch die Prinzipien gelten für JSON-Dokumente beliebiger Komplexität und Größe. Entscheidend ist, diese Funktionen geschickt zu kombinieren, wie unsere überschaubaren Beispiele zeigen. Bei komplexeren Strukturen werden diese Funktionen ggf. Teil von Common Table Expressions (CTEs) – das zugrunde liegende Konzept bleibt jedoch gleich.
Happy Coding! 🧑💻
Tomáš Sobotík·Senior Data Engineer & Snowflake SME bei Norlys
Tomas ist seit Langem Snowflake Data SuperHero und ausgewiesener Snowflake-Experte. Seine Erfahrung im Datenumfeld erstreckt sich über mehr als ein Jahrzehnt, in dem er als Snowflake Data Engineer, Architect und Admin in zahlreichen Projekten unterschiedlichster Branchen und Technologien tätig war. Tomas ist ein aktives Mitglied der Community, teilt sein Wissen großzügig und inspiriert andere. Außerdem ist er Instructor bei O'Reilly und leitet Live-Online-Trainings.
Ian Whitestone·Co-Founder & CEO von SELECT
Ian ist Co-Founder und CEO von SELECT, einer SaaS-Plattform für Kostenmanagement und Optimierung in Snowflake. Vor der Gründung von SELECT leitete Ian sechs Jahre lang Full-Stack-Data-Science- und Engineering-Teams bei Shopify und Capital One. Bei Shopify verantwortete er die Optimierung des Data Warehouse und den Ausbau der Kostentransparenz.