En un post anterior del blog exploramos los fundamentos de los datos semiestructurados y el soporte que Snowflake brinda para ellos. Además, repasamos varios métodos para ingestar datos semiestructurados en Snowflake. Ahora que ya tenemos esos datos en Snowflake, ¿cuál es el siguiente paso? En este post nos vamos a enfocar específicamente en cómo trabajar de forma efectiva con datos JSON. Profundizaremos en las capacidades de transformación y en las funciones puntuales que Snowflake ofrece para este propósito. También haremos un repaso rápido de cómo cargar datos JSON en Snowflake.
Funciones de Snowflake para parsear JSON
Snowflake ofrece un conjunto de funciones para trabajar con datos JSON semiestructurados. Las tres más comunes que vas a usar son:
PARSE_JSON: recibe una cadena como documento JSON y devuelve un valorVARIANT.TRY_PARSE_JSON: funciona exactamente igual quePARSE_JSON, pero devuelve un valor nulo si ocurre un error durante el parseo.LATERAL FLATTEN: se utiliza para aplanar un arreglo en varias filas, una por cada objeto del arreglo.
Cubriremos cada una con más detalle a continuación. Pero primero, ¡necesitamos algunos datos de ejemplo para trabajar!
Cómo crear datos JSON de ejemplo
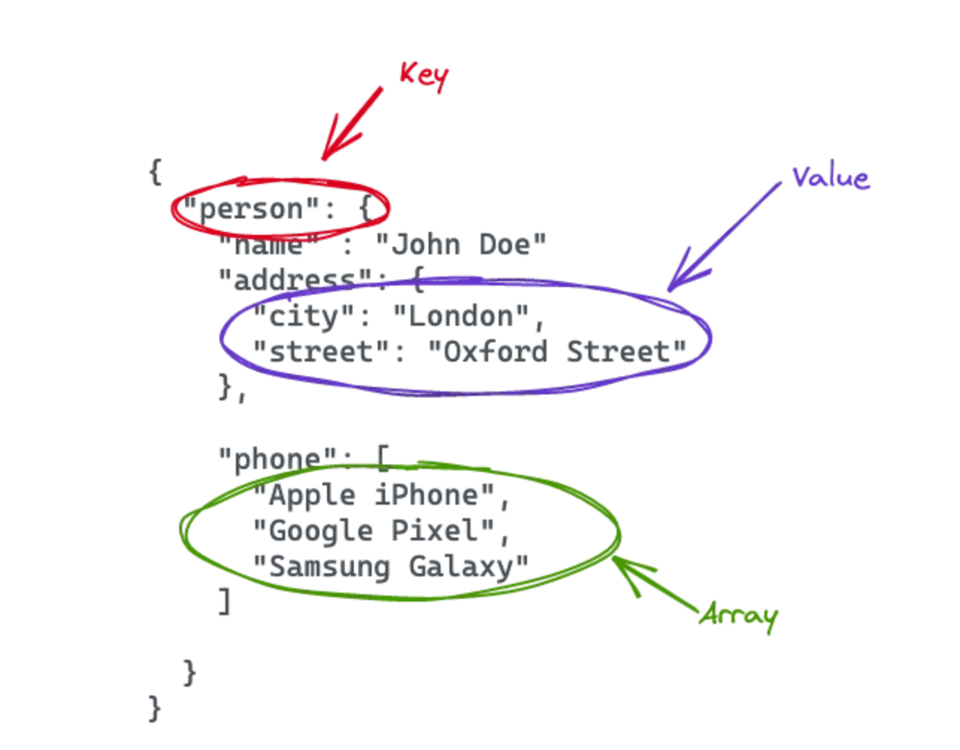
A lo largo del post vamos a trabajar con los siguientes datos JSON de ejemplo, que contienen información sobre una persona:
1{
2 "person":{
3 "name":"John Doe",
4 "address":{
5 "city":"London",
6 "street":"Oxford Street"
7 },
8 "phone":[\
\
9 "Apple iPhone",\
\
10 "Google Pixel",\
\
11 "Samsung Galaxy"\
\
12 ]
13 }
14}
Cargaremos estos datos en una tabla llamada sample_json_data y la usaremos para probar todas las funcionalidades. La tabla guardará el documento JSON en una única columna VARIANT llamada src:
create table sample_json_data
(src variant)
;
Cómo usar PARSE_JSON
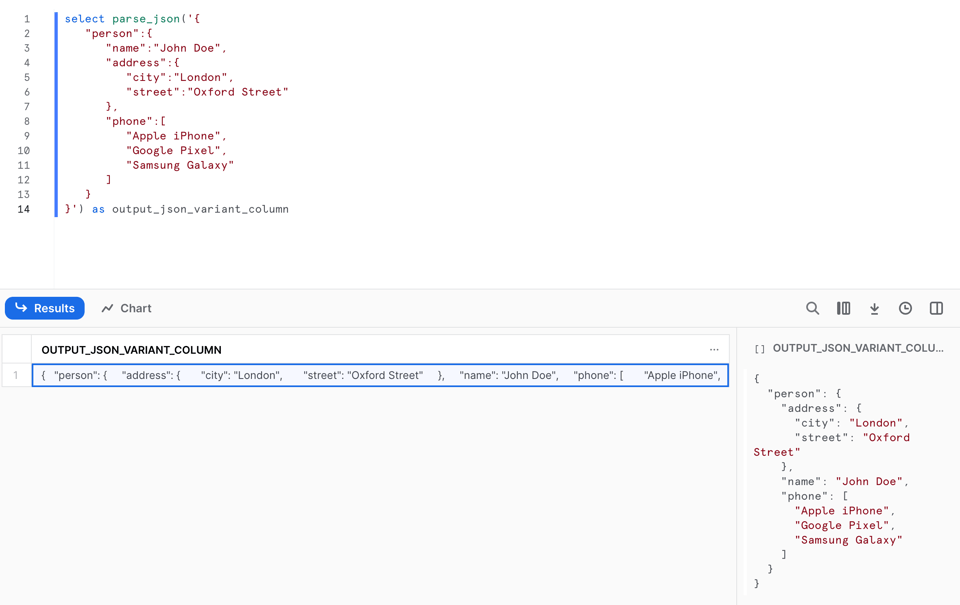
Para convertir una cadena de un documento JSON en un VARIANT, necesitamos usar la función PARSE_JSON.
1select parse_json('{
2 "person":{
3 "name":"John Doe",
4 "address":{
5 "city":"London",
6 "street":"Oxford Street"
7 },
8 "phone":[\
\
9 "Apple iPhone",\
\
10 "Google Pixel",\
\
11 "Samsung Galaxy"\
\
12 ]
13 }
14}') as output_json_variant_column
Este es el resultado:
Ahora podemos usar esta función para poblar nuestra tabla sample_json_data
1insert into sample_json_data
2select parse_json('{
3 "person":{
4 "name":"John Doe",
5 "address":{
6 "city":"London",
7 "street":"Oxford Street"
8 },
9 "phone":[\
\
10 "Apple iPhone",\
\
11 "Google Pixel",\
\
12 "Samsung Galaxy"\
\
13 ]
14 }
15}');
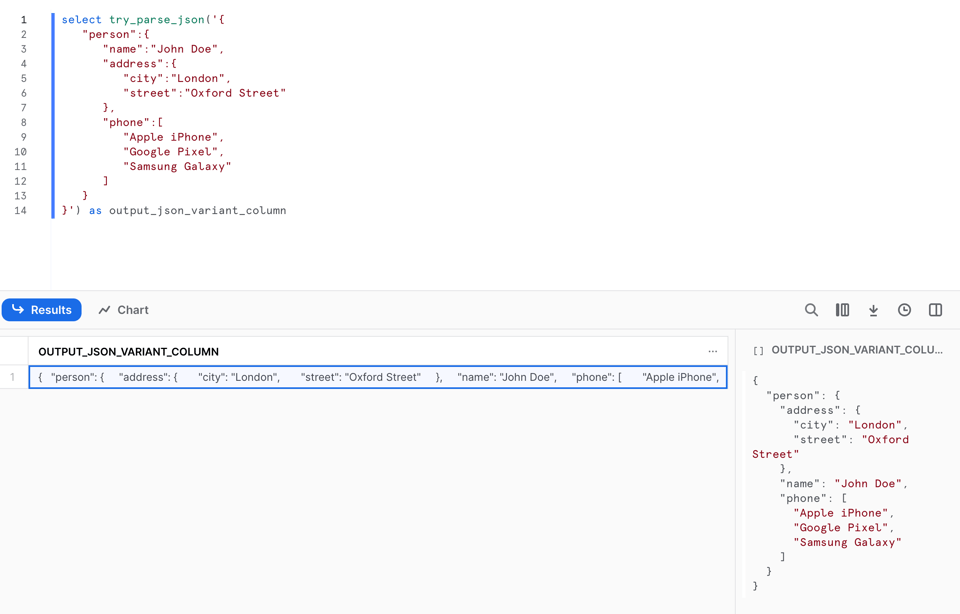
Cómo usar TRY_PARSE_JSON
TRY_PARSE_JSON funciona exactamente igual que PARSE_JSON:
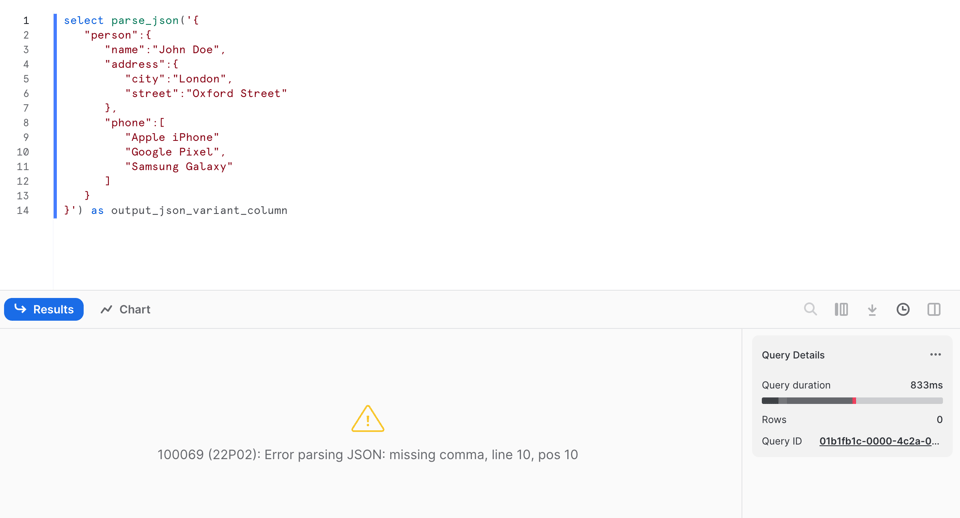
Sin embargo, a diferencia de PARSE_JSON, devuelve null si no puede parsear el JSON. Si miras la línea 9, ¡le quité la coma!
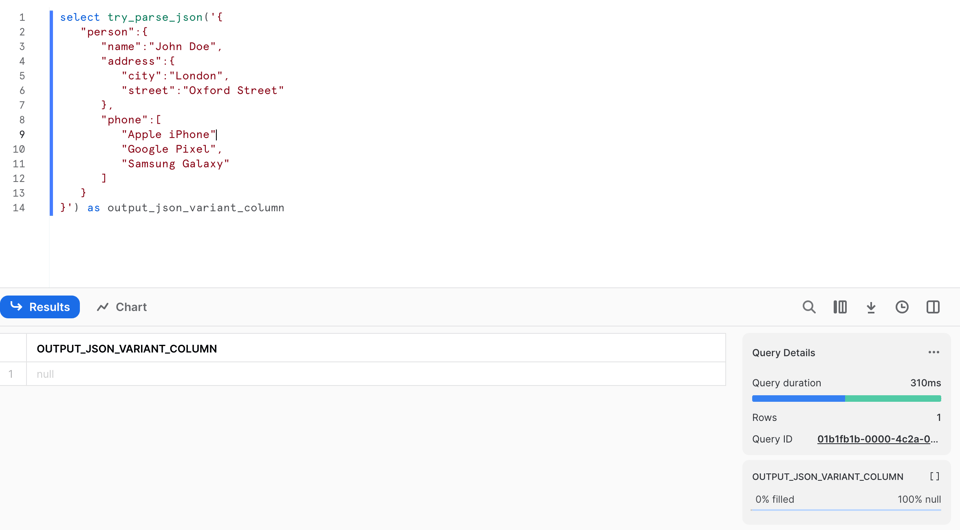
Si ejecutamos PARSE_JSON sobre estos datos defectuosos, falla con un error:
Notación para consultar una columna JSON
Ahora, empecemos a acceder a los datos dentro de este tipo de dato semiestructurado. Para recuperar datos desde una clave de nivel superior, podemos usar la notación de dos puntos, como src:person. Si necesitas adentrarte más en la estructura del objeto, tienes dos opciones. Puedes usar la notación de punto con una sentencia como src:person.address.city, o la notación de corchetes con una sentencia como src['person']['address']['city'].
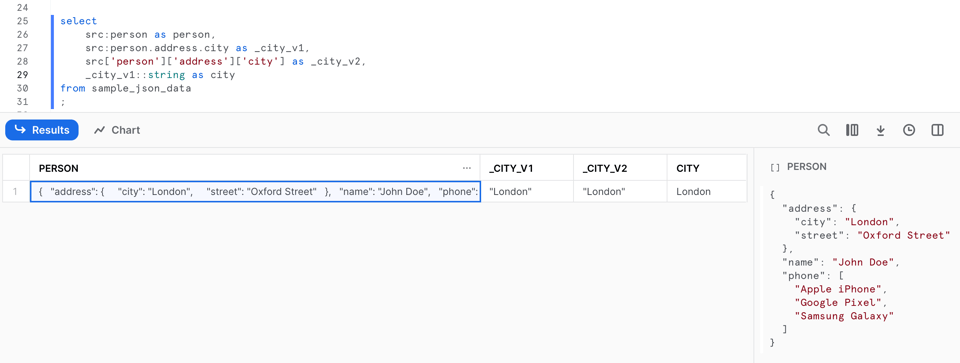
Estos métodos se pueden resumir con las siguientes sentencias generales:
- Notación de punto:
<column>:<level1_element>.<level2_element>.<level3_element> - Notación de corchetes:
<column>['<level1_element>']['<level2_element>']['<level3_element>']
Si algunas claves no cumplen con las reglas de identificadores SQL de Snowflake — por ejemplo, si tienen espacios — debes encerrar el nombre de la clave entre comillas dobles cuando uses notación de punto. Con la notación de corchetes, siempre se encierran los valores entre comillas simples.
Cómo usar LATERAL FLATTEN para procesar arreglos
En la sección anterior vimos los fundamentos para navegar un documento JSON con notación de punto y de corchetes. Pero, ¿qué pasa si tu documento contiene arreglos? Con la misma lógica, seleccionar src:person:phone devolvería el arreglo completo como un único valor, así: [ "Apple iPhone", "Google Pixel", "Samsung Galaxy" ].
Para iterar el arreglo y expandir cada valor, hay que aplanarlo. El resultado serán tres filas, cada una con un valor del arreglo.
Snowflake ofrece dos funciones para este propósito: LATERAL y FLATTEN, que suelen usarse juntas.
El join LATERAL permite que una vista en línea haga referencia a columnas de una expresión de tabla anterior. A diferencia de un join no lateral, la salida de un join lateral incluye solo las filas generadas a partir de la vista en línea. Vale la pena mencionar que, en mi experiencia, nunca he usado un join LATERAL sin la función FLATTEN, aunque técnicamente es posible.
La función FLATTEN descompone valores compuestos en varias filas. Recibe un tipo de dato semiestructurado (VARIANT, OBJECT o ARRAY) y produce una vista lateral. Ilustrémoslo con un ejemplo en el que expandimos nuestro arreglo de teléfonos móviles en varias filas usando estas dos funciones:
SELECT
p.*
FROM sample_json_data,
LATERAL FLATTEN(input => src:person.phone) p
Esta consulta produce el siguiente resultado:
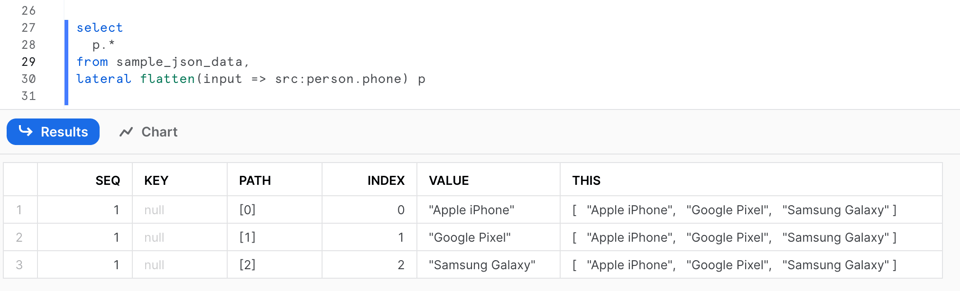
La salida de la función FLATTEN incluye varias columnas:
SEQ: un número de secuencia único asociado al registro de entrada; ten en cuenta que la secuencia puede no estar ordenada ni ser continua.KEY: para mapas u objetos, esta columna contiene la clave del valor descompuesto.PATH: la ruta al elemento dentro de la estructura de datos que se está aplanando.INDEX: el índice del elemento si forma parte de un arreglo; de lo contrario, NULL.VALUE: el valor del elemento en el arreglo u objeto aplanado.THIS: el elemento específico que se está aplanando, útil para aplanamientos recursivos.
Además, las columnas del lado izquierdo del join LATERAL siguen estando disponibles. Así que podemos modificar nuestra consulta para convertir los datos semiestructurados del documento JSON en una estructura plana:
SELECT
src:person.name::varchar AS person_name,
src:person.address.city::varchar AS city,
src:person.address.street::varchar AS street,
p.value::varchar AS mobile_phone
FROM sample_json_data,
LATERAL FLATTEN(input => src:person.phone) p;
Este es el resultado:

En esta consulta SQL es necesario castear explícitamente las columnas, porque la salida está en formato variant, lo que significa que los valores vienen entre comillas dobles. Hay que convertirlos explícitamente al tipo de dato deseado.
Trabajando con varios niveles de arreglos anidados
Si te topas con un escenario con varios niveles de arreglos anidados, donde un arreglo contiene a otro, puedes aplicar LATERAL FLATTEN sobre los valores expandidos del nivel 1 para seguir expandiendo los valores del nivel anidado. El pseudocódigo para una operación así se vería así:
SELECT
lvl_1.value,
lvl_2.value
FROM table
LATERAL FLATTEN (input => src:topLevelArray) AS lvl_1,
LATERAL FLATTEN (input => lvl_1.value:innerLevelArray) AS lvl_2;
Eso es básicamente todo. Combinando la notación de punto o de corchetes con LATERAL FLATTEN puedes construir una base sólida para trabajar con datos JSON almacenados en tablas de Snowflake. Este enfoque te permite transformar los datos al formato que necesites de forma eficiente.
Cómo construir documentos JSON a partir de datos relacionales
Ya vimos cómo procesar datos JSON. ¿Y qué pasa con el camino inverso, cuando queremos convertir datos estructurados en datos JSON?
Convertir datos relacionales de una tabla de Snowflake a formato JSON es fundamental, sobre todo al compartir datos con sistemas externos que muchas veces requieren JSON para los payloads de API. Veamos cómo hacerlo con las funciones nativas de Snowflake.
Imaginemos que tenemos una tabla llamada relational_data, creada a partir del resultado de la función LATERAL FLATTEN. Nuestro objetivo es transformar estos datos relacionales nuevamente en una estructura JSON. Primero creamos y poblamos la tabla relational_data:
CREATE TABLE relational_data (
person_name VARCHAR,
city VARCHAR,
street VARCHAR,
mobile_phone VARCHAR
);
INSERT INTO relational_data
SELECT
src:"person".name::varchar AS person_name,
src:"person".address.city::varchar AS city,
src:"person".address.street::varchar AS street,
p.value::varchar AS mobile_phone
FROM sample_json_data,
LATERAL FLATTEN(input => src:person.phone) p;
Para construir un objeto JSON con pares clave-valor, usamos la función OBJECT_CONSTRUCT. Esta función recibe pares de argumentos, donde el primero es una clave y el segundo, un valor. Para objetos anidados, usamos otra llamada a OBJECT_CONSTRUCT. Para crear una estructura básica de persona con un nombre, la sentencia SQL sería:
SELECT OBJECT_CONSTRUCT('person',
OBJECT_CONSTRUCT('name', person_name)) AS src
FROM relational_data;
Esta consulta produce la siguiente estructura JSON:
{
"person": {
"name": "John Doe"
}
}
Ahora incluyamos el objeto address con valores para city y street:
SELECT OBJECT_CONSTRUCT('person',
OBJECT_CONSTRUCT('name', person_name,
'address', OBJECT_CONSTRUCT(
'city', city,
'street', street
)
)
) AS src
FROM relational_data;
Por último, para agregar un arreglo de teléfonos móviles, usamos la función ARRAY_AGG(), que crea un arreglo a partir de los valores de entrada. Esta es la consulta SQL completa para la estructura JSON final:
SELECT OBJECT_CONSTRUCT('person',
OBJECT_CONSTRUCT('name', person_name,
'address', OBJECT_CONSTRUCT(
'city', city,
'street', street
),
'phone', ARRAY_AGG(mobile_phone) WITHIN GROUP (ORDER BY person_name) OVER (PARTITION BY person_name)
)
) AS src
FROM relational_data;
Este proceso reconstruye con éxito el documento JSON:
1{
2 "person": {
3 "address": {
4 "city": "London",
5 "street": "Oxford Street"
6 },
7 "name": "John Doe",
8 "phone": [\
\
9 "Apple iPhone",\
\
10 "Google Pixel",\
\
11 "Samsung Galaxy"\
\
12 ]
13 }
14}
Con estos pasos hemos transformado de forma efectiva los datos relacionales en un documento JSON estructurado, listo para usarse en distintas aplicaciones.
Cómo cargar datos JSON
En los ejemplos anteriores usamos datos JSON de muestra. La mayoría de los clientes de Snowflake no los tendrán, y antes deberán cargar datos JSON en su cuenta.
Para cargar un archivo de datos JSON en una tabla de Snowflake, el comando SQL se vería más o menos así:
COPY INTO <table_name>
FROM (
SELECT
$1:person:name::STRING as name,
$1:person:address:city::STRING as city,
$1:person:address:street::STRING as street,
$1:person:phone[0]::STRING as phone1,
$1:person:phone[1]::STRING as phone2,
$1:person:phone[2]::STRING as phone3
FROM <my_stage>/<my_json_file.json>
);
Este comando asume que:
<table_name>es el nombre de tu tabla de destino en Snowflake.<my_stage>es el nombre del stage donde está almacenado el archivo JSON.<my_json_file.json>es el nombre de tu archivo JSON.
En la sentencia SELECT:
- La notación
$1se usa para referirse a la primera columna del archivo que se está cargando, que en este caso es el blob JSON completo. - La notación de dos puntos
:se usa para navegar la estructura JSON. - El casteo
::STRINGconvierte los elementos JSON al tipo de dato apropiado, que esSTRINGen este ejemplo. Puedes ajustar el tipo de dato según tus necesidades.
Este ejemplo asume que la estructura JSON es consistente en todos los registros de tu archivo. Si la estructura varía, podrías necesitar lógica adicional de manejo de errores o de parseo.
Para profundizar en las distintas opciones para cargar datos semiestructurados (incluidos los datos JSON) en tu data warehouse de Snowflake, consulta nuestro post anterior del blog.
Tips para trabajar con datos JSON
Aquí van algunos tips útiles para tener en cuenta cuando trabajes con datos JSON:
- Usa un formateador de JSON gratuito en línea, como este, para dar formato a tus datos. Así es más fácil inspeccionar la estructura visualmente y entender la jerarquía de los datos.
- Construye tus consultas paso a paso y valida el resultado en cada paso. Por ejemplo, no intentes consultar 4 niveles de JSON anidado de una sola vez. Así será mucho más fácil detectar los errores, que inevitablemente van a ocurrir.
- Usa columnas temporales para simplificar tus operaciones. Por ejemplo, puedes parsear varios niveles de JSON a la vez en una sola columna y luego seguir procesando desde ahí. Después puedes descartar las columnas extra con el comando exclude de Snowflake. Aquí hay un ejemplo que muestra cómo evitar el procesamiento repetitivo del campo
address. Solo mostrará dos columnas:cityystreet:
with
data as (
select
src:person.address as address,
address:city::string as city,
address:street::string as street
from sample_json_data
)
select * exclude(address)
from data
- Al crear nuevos datasets a partir de datos JSON, intenta separar las columnas que se consultan con frecuencia en columnas independientes, en lugar de dejarlas dentro de una única columna
variant. Esto mejora bastante la experiencia del usuario final al consultar tus tablas. - Los atributos JSON distinguen entre mayúsculas y minúsculas. Si escribo
address.Cityen lugar deaddress:city, devolveránull.
Con esto cerramos nuestra guía. Ya entiendes cómo parsear un documento JSON, aplanarlo y guardarlo en una tabla relacional en Snowflake. Además, exploramos el proceso inverso: crear JSON a partir de una tabla de Snowflake. Nuestros ejemplos se enfocaron en estructuras de datos simples, pero los principios aplican a documentos JSON de cualquier complejidad o tamaño. Todo se trata de combinar estas funciones con criterio, como mostramos en los ejemplos sencillos. A medida que enfrentes estructuras más complejas, estas funciones podrían formar parte de Common Table Expressions (CTEs), pero el concepto de fondo sigue siendo el mismo.
¡Happy coding! 🧑💻
Tomáš Sobotík·Senior Data Engineer & Snowflake SME en Norlys
Tomas es un veterano Snowflake Data SuperHero y experto general en Snowflake. Su amplia experiencia en el mundo de los datos abarca más de una década, durante la cual se ha desempeñado como Snowflake data engineer, arquitecto y admin en diversos proyectos a lo largo de múltiples industrias y tecnologías. Tomas es un miembro central de la comunidad, que comparte activamente su experiencia e inspira a otros. También es instructor de O'Reilly y dirige sesiones de capacitación en vivo en línea.
Ian Whitestone·Cofundador & CEO de SELECT
Ian es Cofundador & CEO de SELECT, una plataforma SaaS de gestión y optimización de costos en Snowflake. Antes de fundar SELECT, Ian pasó 6 años liderando equipos full stack de data science e ingeniería en Shopify y Capital One. En Shopify, Ian lideró los esfuerzos para optimizar su data warehouse y aumentar la visibilidad de los costos.